大模型注意力机制的六大前沿优化技术
摘要 Transformer的自注意力机制存在O(n²)复杂度问题,限制了其处理长文本的能力。针对这一挑战,研究者开发了多种优化技术,包括: 旋转位置嵌入(RoPE):通过旋转矩阵编码相对位置信息,提升长文本泛化能力; 稀疏注意力:如RoutingTransformer,利用聚类动态选择语义相关区域,降低计算量; FlashAttention:分块处理与增量Softmax优化I/O效率,减少内存读
在大型语言模型的浪潮中,Transformer 架构及其核心的自注意力机制无疑是核心驱动力。然而,其计算和内存复杂度与序列长度呈平方关系 (O(n2)) 的特性,成为了处理长文本和实现高效推理的巨大瓶颈。
为了突破这一局限,研究者们在注意力机制上进行了大量的革新。这些优化不仅是简单的技巧,更是一套从硬件、算法到架构层面的系统性解决方案。本文将详细剖析六种关键的注意力优化技术,揭示其背后的数学与工程原理。
一、突破长文本瓶颈的数学奥秘
传统的自注意力在处理长文本时,会因为巨大的计算量和内存需求而崩溃。以下两种技术从根本上改变了注意力计算的模式。
1. 旋转位置嵌入(RoPE):对相对位置的精准编码
传统的绝对位置编码无法泛化到比训练时更长的序列,而 RoPE 巧妙地将位置信息融入到自注意力计算中,使得模型只关心词语间的相对位置。
RoPE 的核心思想是通过旋转矩阵来对查询(Q)和键(K)向量进行操作。对于序列中第 m 个词的向量,其 RoPE 变换后的查询和键向量可表示为:
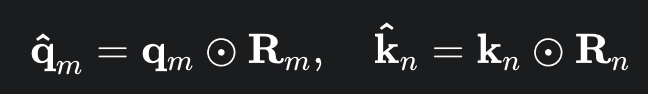
其中,⊙ 代表逐元素相乘,Rm 是一个旋转矩阵,其元素由三角函数定义。这种设计确保了两个位置为 m 和 n 的词,其内积只依赖于它们之间的相对距离 (m−n)。
2. 稀疏注意力(Sparse Attention):从全局关注到智能聚焦
稀疏注意力的目标是减少不必要的注意力计算,从而将复杂度从 O(n2) 降低。与简单的带状注意力不同,一些高级稀疏注意力机制会根据语义相关性来选择关注对象。
以 Routing Transformer 为例,它利用 K-means 聚类算法来动态实现稀疏化:
-
聚类(Clustering): 将输入序列中所有词的向量作为数据点,运行 K-means 算法。该算法会根据语义相似性将词语分组。
-
路由(Routing): 在计算注意力时,一个词的查询(Q)只会被路由到它所属的簇内的其他词的键(K)。
这种方法使得模型能够高效地聚焦于语义相关的词语,而不是机械地关注位置相近的词,实现了计算效率和表达能力的双赢。
二、极致效率的硬件与架构优化
这些优化不再局限于算法层面,而是直接与 GPU 硬件和内存架构交互,以实现性能的最大化。
1. FlashAttention:I/O 意识的计算革命
标准注意力计算的主要瓶颈并非浮点运算(FLOPs),而是对**高带宽内存(HBM)**的频繁读写。FlashAttention 正是为解决这一 I/O 瓶颈而生。
其核心算法原理是分块处理(Tiling)和增量 Softmax 计算:
1. 分块: 将巨大的 Q、K、V 矩阵切分成若干小块。
2. SRAM 计算: 在一个循环中,一次只从 HBM 中读取一个 Q 块和 K、V 块到速度极快的 SRAM 中。
3. 增量 Softmax: 在 SRAM 中,模型边计算边更新 Softmax 的结果,避免了将完整的 n×n 维度 Softmax 矩阵写回 HBM。
通过这种方式,FlashAttention 将内存读写复杂度从 O(n2) 降低到O(n(√n),大幅提升了训练和推理速度。
2. 多查询注意力(MQA):内存共享的策略
在多头注意力(MHA)中,每个头都有独立的键(K)和值(V)矩阵,这导致在推理时,键值缓存(KV Cache)的大小与头数呈线性关系。
多查询注意力(MQA)的核心思想是:所有注意力头共享同一组 K 和 V 矩阵,而只有查询(Q)矩阵是独立的。
-
MHA 内存: 存储 H 组 K、V 矩阵,内存占用为 O(H⋅n⋅d)。
-
MQA 内存: 仅存储 1 组共享的 K、V 矩阵,内存占用为 O(n⋅d)。
这种内存共享策略使得 KV Cache 的大小与头数无关,极大地减少了推理时的显存占用和内存带宽需求,是部署超大规模模型的关键。
三、处理海量输入的终极方案
当输入序列的长度达到极端(如数万甚至数十万)时,即使是稀疏注意力也可能力不从心。
多头潜在注意力(MHLA):信息压缩的利器
多头潜在注意力(MHLA)通过引入一个固定大小、可学习的“潜在数组”(Latent Array)来解决这一问题。
其工作流分为两个阶段:
-
输入到潜在数组的跨注意力(Cross-Attention): 潜在数组的元素充当查询(Q),对整个巨大的输入序列进行注意力计算。这一步将海量输入信息压缩并汇聚到这个小小的潜在数组中。
-
潜在数组内部的自注意力: 潜在数组的元素在内部进行自注意力计算,以提炼和精化其内部的压缩信息。
这个机制将计算复杂度从与输入序列长度相关解耦出来,使得模型能够高效地处理来自视频、点云、超长文本等不同模态的海量输入。
我们用一个更简单、更具体的例子,来详细说明多头潜在注意力(MHLA)的运作原理。
例子:让 AI 看完一部电影并回答问题
想象一下,我们想让一个AI模型看完一部长达 2 小时的电影,并回答一个简单问题:“主角是谁?他想做什么?”
这部电影的剧本非常长,有 100,000 多个词。如果用传统的自注意力,模型需要处理一个 100,000×100,000 的巨大矩阵,这会瞬间耗尽所有计算资源。
多头潜在注意力就是为解决这个问题而生的。它不会让模型直接处理整个剧本,而是采用了一个巧妙的“分工”策略。
1. 准备阶段:一个小型的“专家团队”
模型首先创建一个很小的、固定大小的潜在数组(Latent Array)。你可以把它想象成一个由 20 个“专家”组成的团队,每个专家都带着一个特定任务:
-
专家1:“寻找主角的名字。”
-
专家2:“寻找主角的主要目标。”
-
专家3:“寻找电影发生的时间背景。”
-
...等等。
这 20 个专家就是我们的潜在数组。
2. 核心阶段:信息提取(跨注意力)
现在,这个专家团队开始工作了。
-
提问者(Q): 20 个专家(潜在数组)就是提问者。
-
信息源(K和V): 100,000 个词的整个电影剧本就是信息源。
每个专家(潜在元素)都带着自己的问题,去扫描整个剧本。比如,“寻找主角名字”这个专家会特别关注剧本中人物介绍、对话等部分。它会计算自己与剧本中所有词语的相关性,然后从那些高度相关的词语(比如“约翰”)中提取信息。
这个过程就是跨注意力(Cross-Attention)。它将长达 100,000 词的巨大信息,浓缩并汇聚到了这 20 个小小的专家身上。最终,每个专家都拥有了一份关于自己任务的精炼笔记。
3. 精炼阶段:团队内部的讨论(自注意力)
在完成了信息提取后,这 20 个专家聚在一起开会。
-
他们之间进行自注意力计算。
-
“主角名字”专家会把自己的笔记分享给“主要目标”专家,确保两者之间的信息能够对得上。
-
“主要目标”专家会与“反派角色”专家沟通,理清两者之间的关系。
这个过程就是潜在数组内部的自注意力(Self-Attention)。由于团队只有 20 人,这个计算量非常小。它的目的是让团队的笔记内容相互验证,形成一个逻辑一致的、完整的摘要。
4. 最终输出:回答问题
最后,当外部用户问:“主角是谁?他想做什么?”时,模型只需要从这个已经高度精炼的 20 个专家团队中,快速提取出答案并生成回复。
通过这种方式,多头潜在注意力将一个不可能完成的“大海捞针”任务,变成了一个高效的“团队协作”流程,从而成功地处理了超大规模的输入。
总结
这些技术不是孤立存在的,它们往往被组合使用,共同为构建更强大、更高效、更具通用性的大语言模型奠定了坚实的基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)