为什么大模型 Agent 产品总是无法落地?来自实战派的经验分享(二)
在之前的文章Agent 落地经验分享(一)中,介绍了 Agent 落地中存在的问题,并给出了一些初步的解决方案。在这篇文章中,针对 Agent 落地中的关键问题,给出更进一步的实战经验,希望对大家的 Agent 产品落地有所帮助。本文主要参考自。本文梳理了来自 humanlayer 的 12 条 Agent 构建经验。对我而言,最重要的启发是保持对 Agent 的“可控性”:避免将任务完全委派给大
背景介绍
在之前的文章 Agent 落地经验分享(一) 中,介绍了 Agent 落地中存在的问题,并给出了一些初步的解决方案。
在这篇文章中,针对 Agent 落地中的关键问题,给出更进一步的实战经验,希望对大家的 Agent 产品落地有所帮助。本文主要参考自 12-factor-agents。
方案选择
在构建 Agent 的路径上,存在两种差异明显的方案:Agentic 方案与 Workflow 方案。关于这两者的选择长期存在争论。
Agentic 方案
Agentic 方案强调 Agent 的自主性,属于 Agent-First。开发者只需提供目标与相应工具,Agent 便可自主完成任务。该路线中较知名的项目是 AutoGPT。这种方案依赖大模型的自主规划与执行能力,以通用策略处理不同任务。
Workflow 方案
Workflow 方案强调业务流程化,属于 User-First。开发者根据业务需求将原始任务拆解为多个步骤,并在关键节点引入大模型。较为知名的代表是此前文章中详细介绍过的 Dify。该方案强调深入理解业务,将其流程化,并在必要处引入局部 Agent 组件。
两种方案各有优劣:Agentic 更灵活,但容易停留在“80 分”难以持续提升,且在复杂严肃场景中稳定性可能下降;Workflow 在标准化场景表现稳健,但灵活性不足、适用范围相对受限。
在本文中经验,优先考虑的实际应用场景中可靠使用,因此整体的经验建议偏向 Workflow 方案。
具体经验
本文介绍的主要是为了在实际的应用场景中落地 Agent 产品的 12 条使用方法或建议,具体如下所示:
1. 将自然语言转换为工具调用
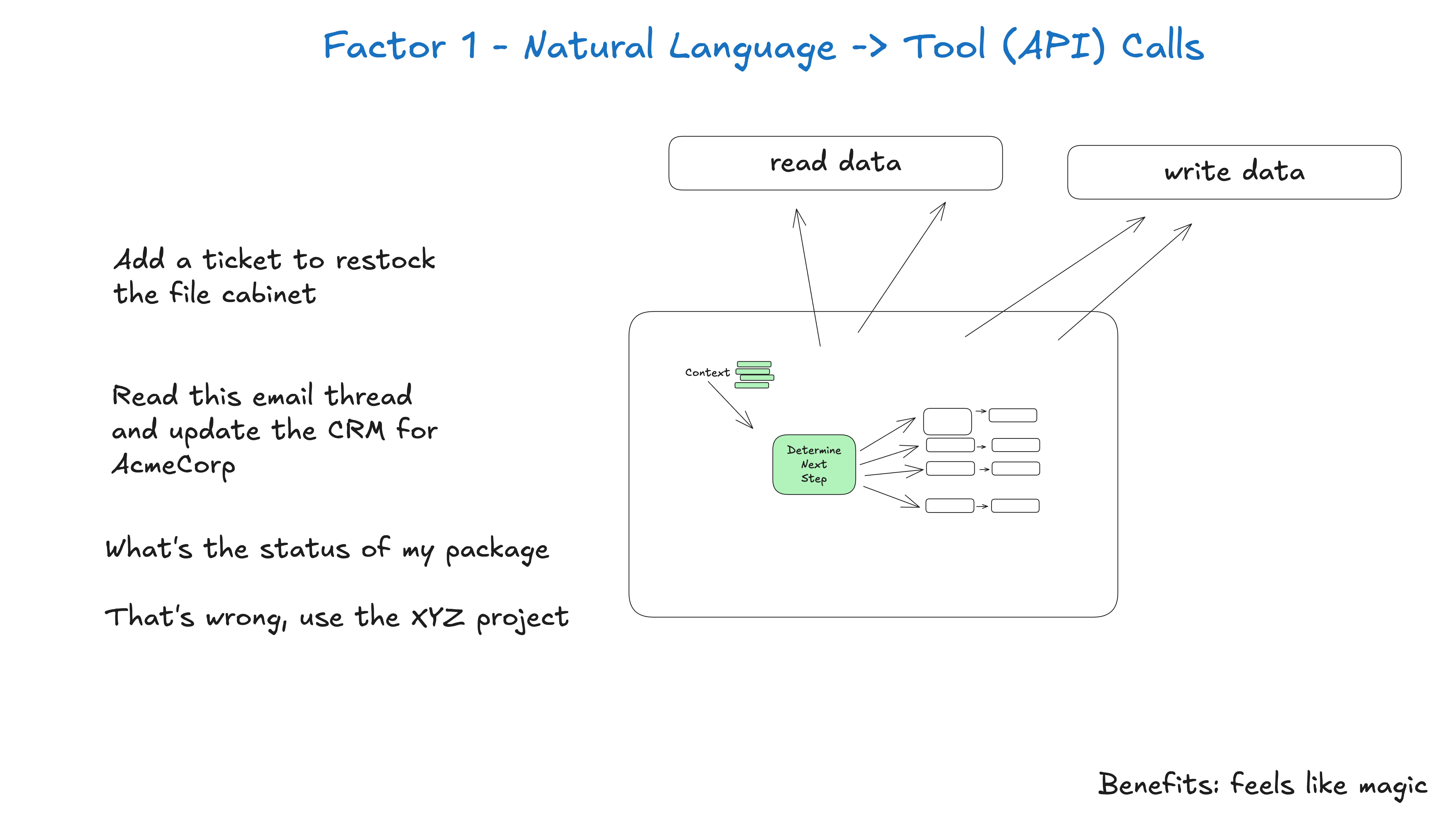
这是当前 Agent 构建中最常见且相当强大的模式。借助大模型的自然语言理解能力,将自然语言转换为结构化对象,以驱动后续的确定性代码执行,从而保证整体流程的可控与可测。
2. 掌控自己的 Prompt

此建议强调将 Prompt 的控制权掌握在自己手中,避免依赖框架的黑盒 Prompt 封装,以确保输出符合预期,并保持模块的灵活性与可维护性。
3. 掌控自己的上下文窗口
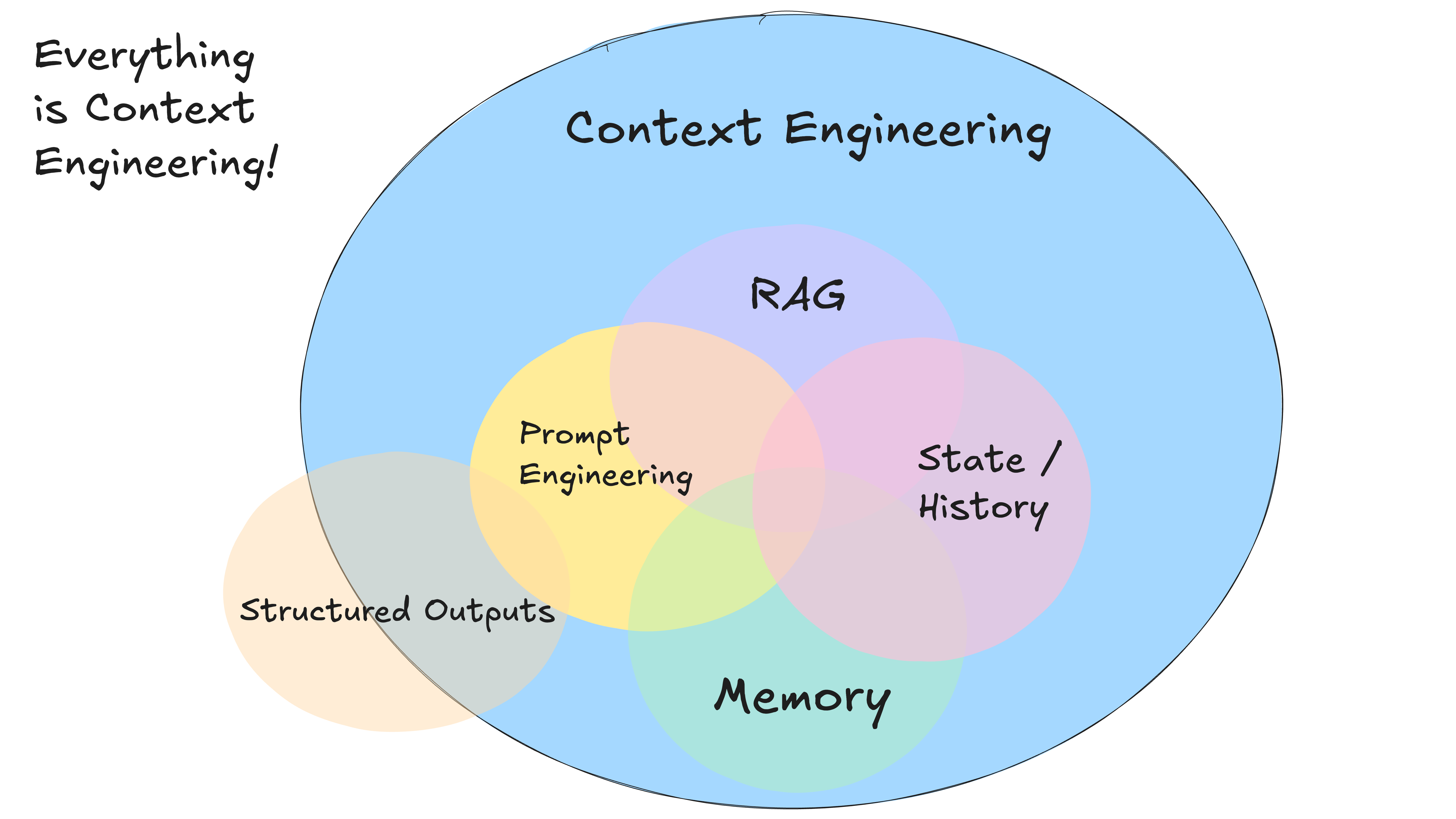
这引出了当前行业热议的“上下文工程(Context Engineering)”:将大模型视作无状态函数,优质输入决定优质输出。因此,精心构造与场景匹配的上下文极其重要。一般情况下,上下文包含:
- 提供给大模型的系统提示;
- 检索的外部数据(如 RAG);
- 状态、工具调用、结果或其他历史记录;
- 相关的历史信息与会话(记忆);
- 结构化输出描述。
当然这只是通用模板。实际业务需结合自身特点精选信息,在保证完整性的前提下尽量剔除无关内容,提升信息密度。
4. 将工具视为结构化输出
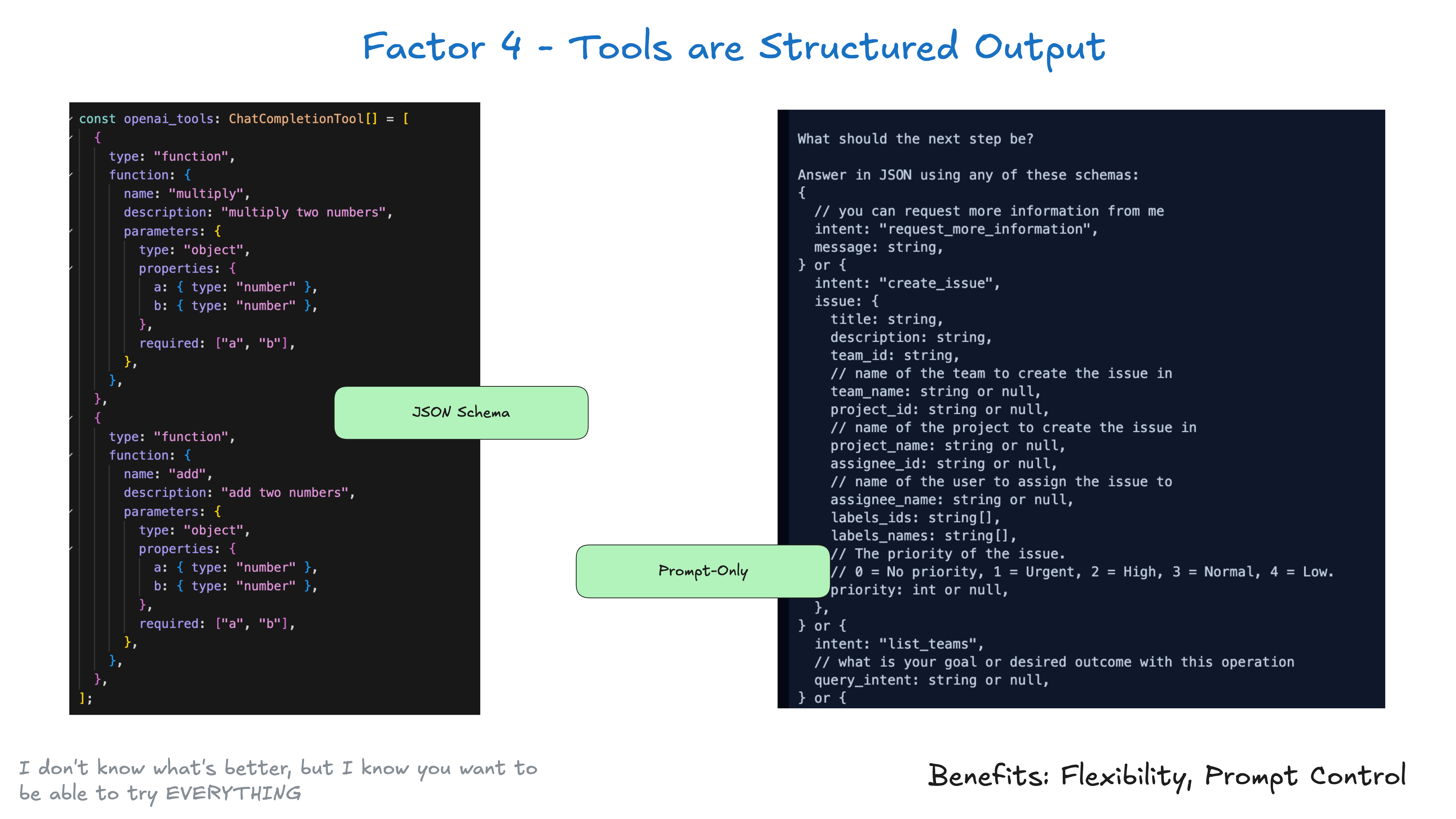
将工具视为“结构化输出”的载体,主要用于触发确定性代码执行。其流程可抽象为:
- 大模型输出结构化 JSON;
- 将该 JSON 作为输入执行确定性代码(例如外部 API 调用);
- 捕获输出并作为结构化反馈写回上下文。
在这种模式下,大模型负责结构化正确性,工具负责基于结构化输入的可靠执行,执行环节彼此解耦。
针对结构化输出,一个相对实用的框架是 Pydantic AI。与许多建立在重抽象之上的框架不同,它专注于提供结构化输出支持,便于串联不同流程。
5. 统一执行状态和业务状态
常见做法是将“执行状态”(如当前步骤、下一步、等待状态、重试次数等)与“业务状态”(如消息列表、工具调用与结果列表等)分离管理。本文建议对二者进行统一建模,并按需向上下文注入必要状态,从而简化整体状态管理。
6. 使用简单的 API 启动/暂停/恢复 任务
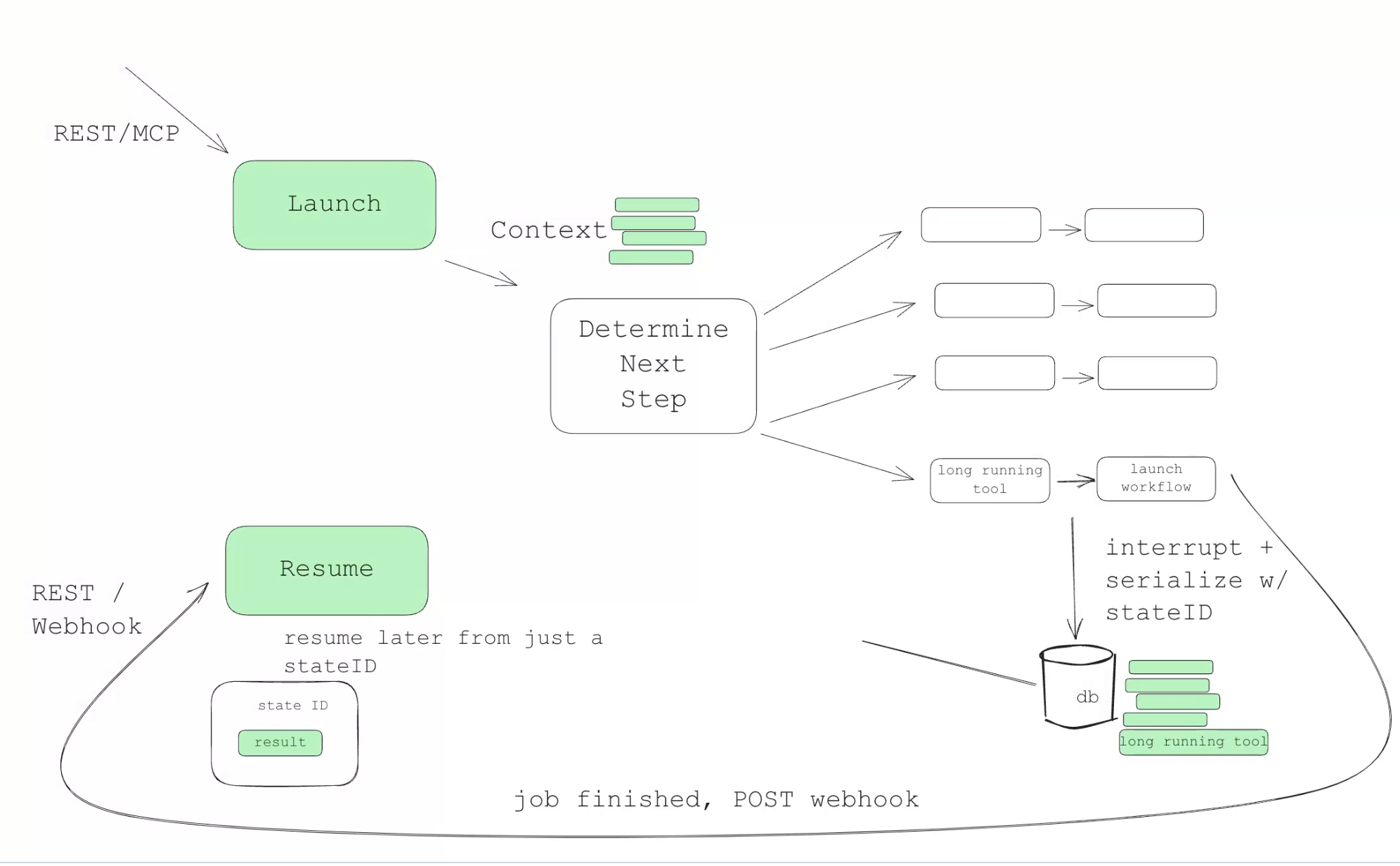
Agent 相比常规大模型应用更复杂、耗时更长。参考软件工程的最佳实践,应为用户提供“启动/暂停/恢复”能力,以获得更佳体验。
7. 使用工具调用提供人工介入能力

在 Agent 应用中,总存在无法完全自动化的任务或状态。此时应通过工具调用提供“人工介入”能力:让大模型输出结构化内容,并以特殊类型显式表示人工介入,从而获得更稳健的处理结果。
8. 掌控自己的控制流
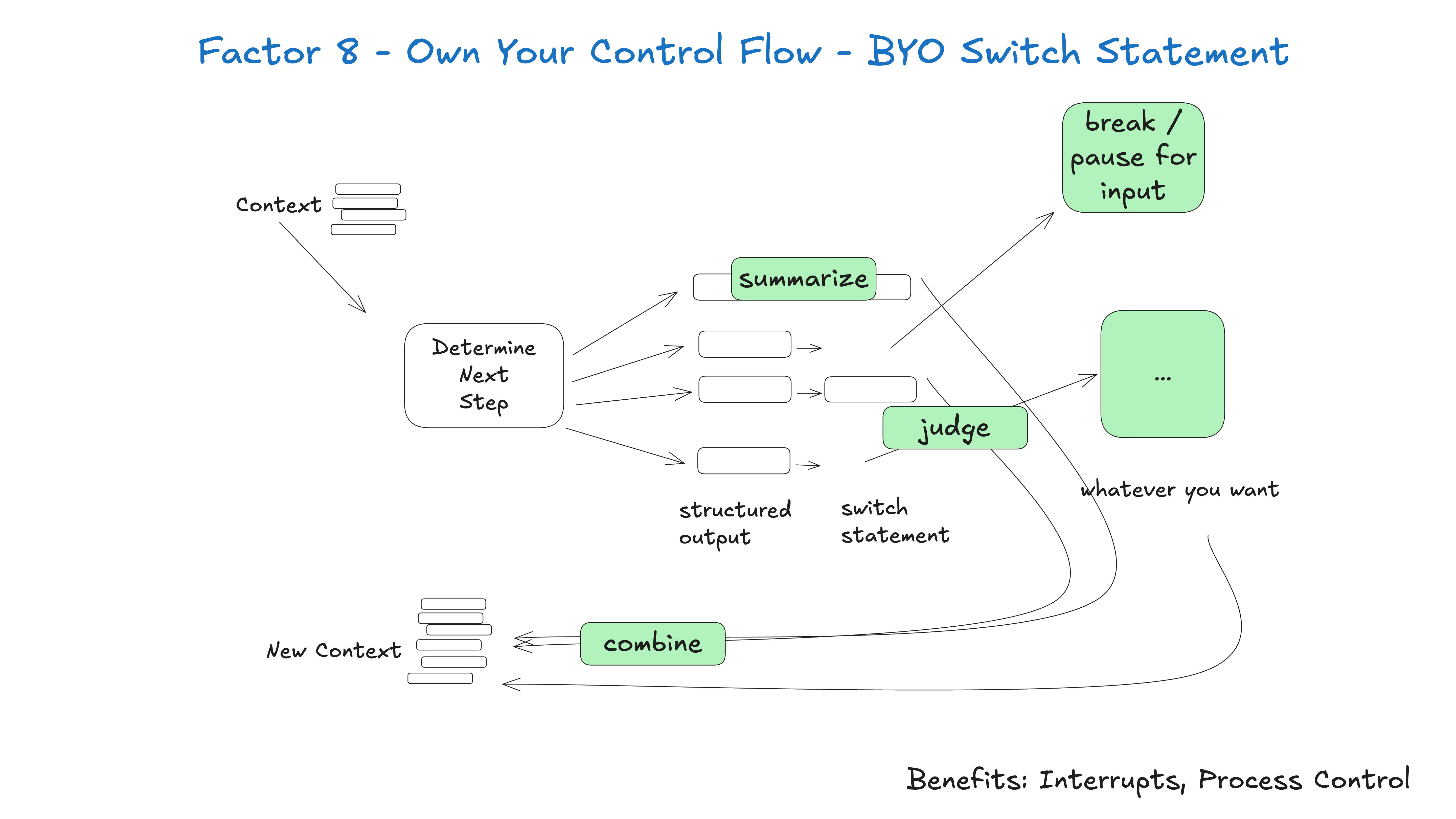
根据实际业务设计“可控”的流程,避免将全流程完全委派给大模型,以获得更自然、更可靠的体验。
9. 将错误压缩放入上下文
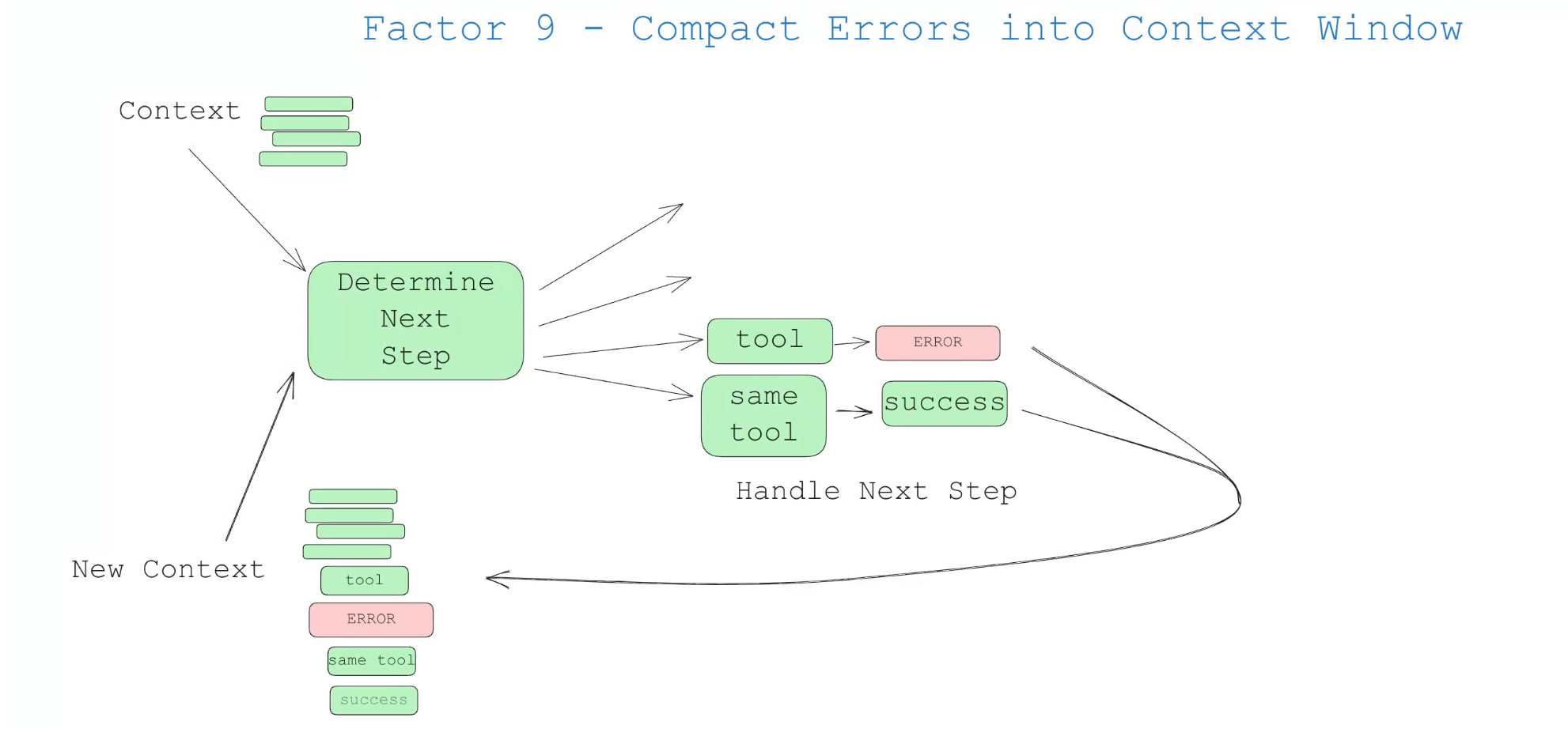
大模型具备一定的自我修复能力。如果将错误信息堆栈放入上下文,后续任务中可更好规避同类错误。同时,可为工具调用设计错误计数器:当累计错误超过阈值时,触发人工介入。
在 Manus 的技术博客 AI 代理的上下文工程:构建 Manus 的经验教训 中,也提到了类似的方案。
10. 提供小型,专注的 Agent
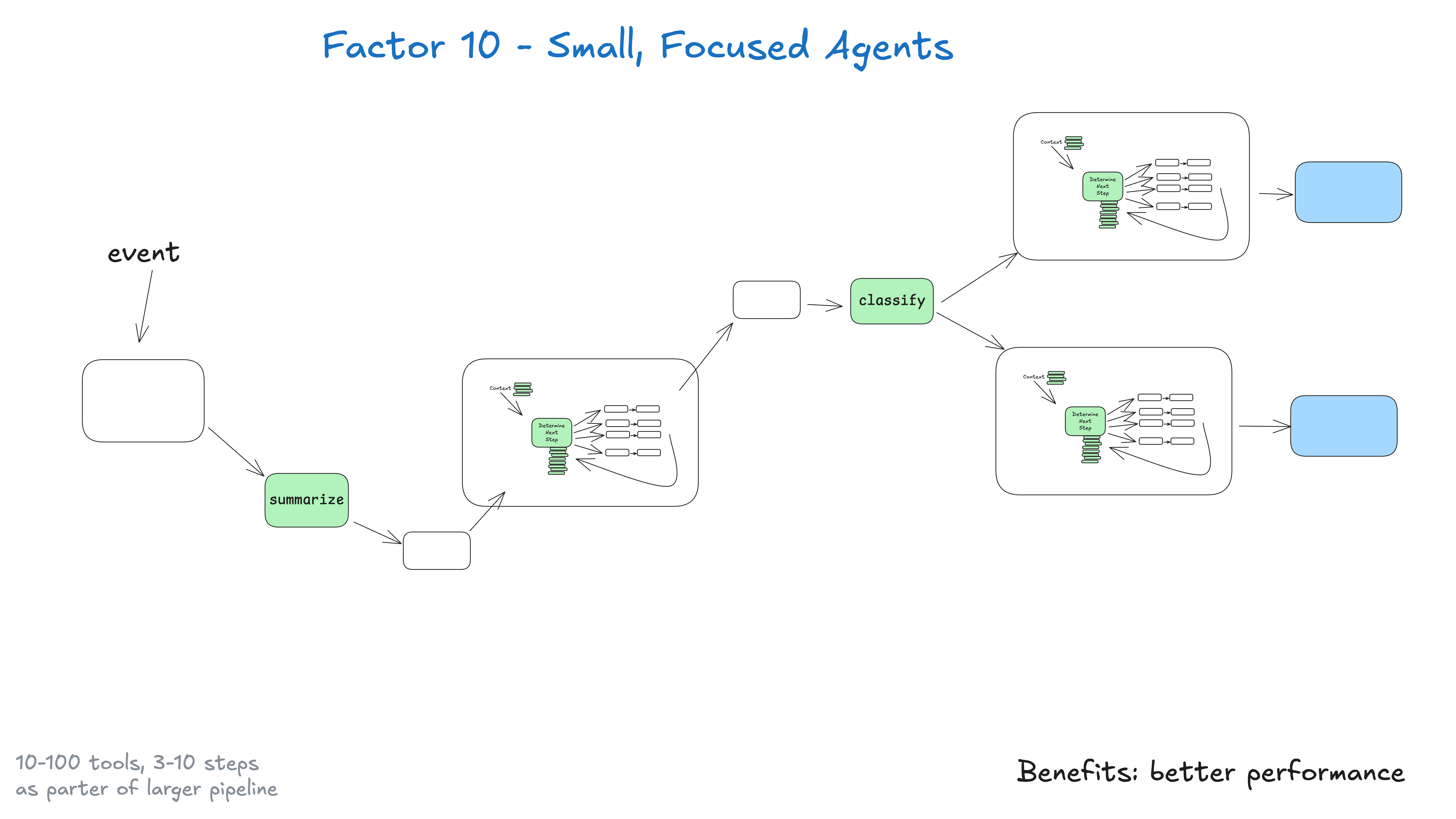
正如之前的文章 Agent 落地经验分享(一) 所强调的:不要试图构建“巨无霸”Agent。应构建小型、专注的 Agent,并将其嵌入到确定性流程中。
关键洞察在于 LLM 的局限性:任务越大越复杂,步骤越多,上下文越长;上下文一旦过长,LLM 更易迷失或跑偏。通过让 Agent 专注于特定领域,并将步骤控制在 3–10 个(最多不超过 20 个),可以保持上下文可控并提升性能。小型 Agent 的优势包括:
- 上下文更易管控:窗口越小,性能越好;
- 职责更为清晰:每个 Agent 的范围与目标明确;
- 可靠性更高:降低在复杂流程中迷失的风险;
- 更易测试:便于针对性验证功能;
- 更易调试:更快定位与修复问题。
11. 随处触发,在任意渠道连接用户
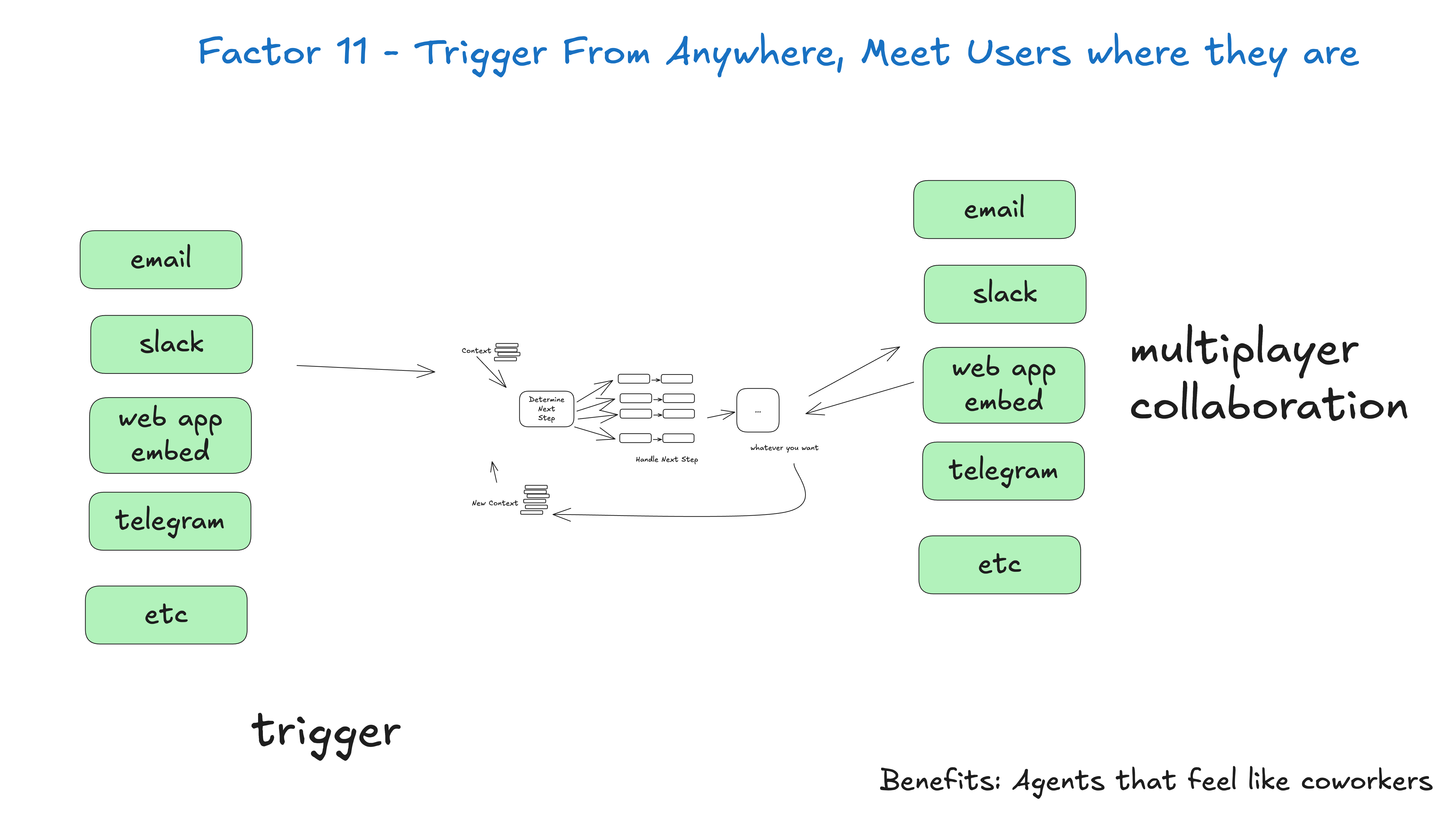
允许用户在多种渠道触发现有 Agent 流程,提供灵活接入方式;既支持用户主动触发,也支持系统事件触发。
12. 让你的 Agent 成为无状态的 Reducer
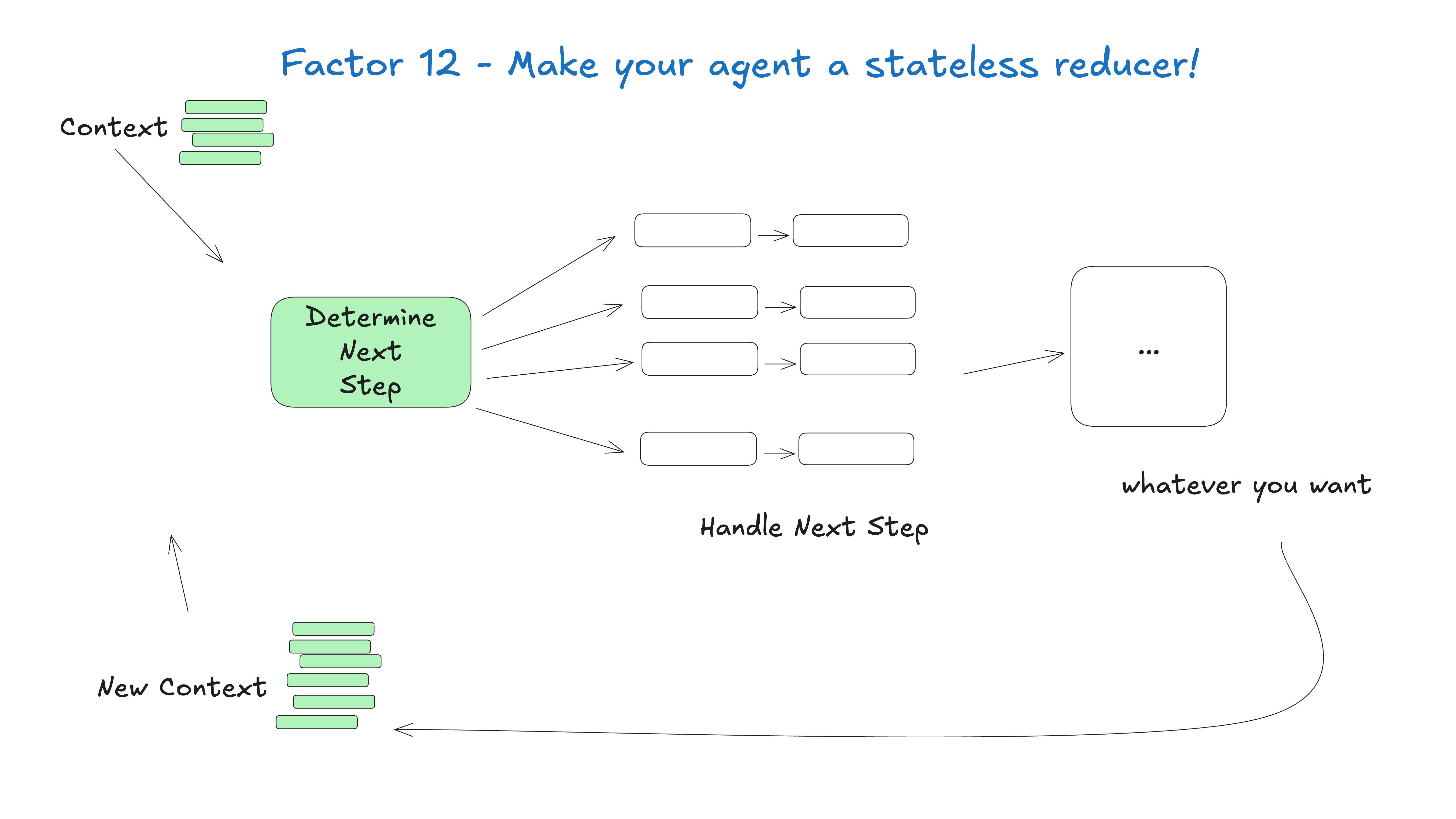
不要在 Agent 内部隐藏特殊状态,而应将其写成纯函数式 reducer,只依赖输入与既有上下文决定输出。这样系统更透明、可调试、可扩展。
总结
本文梳理了来自 humanlayer 的 12 条 Agent 构建经验。对我而言,最重要的启发是保持对 Agent 的“可控性”:避免将任务完全委派给大模型。在大模型能力边界内构建小型、专注的 Agent,并与可控、可测试的工作流结合,才能真正交付可落地的产品。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)