【Langchain + ChromaDB】学习框架搭建日记
📝 RAG框架搭建日记摘要 本文记录了搭建Langchain + ChromaDB学习框架的过程。主要分为知识库构建和检索应用两个阶段: 环境搭建:使用Docker本地启动ChromaDB,通过Langchain框架连接 知识库构建: 加载并分割文本数据(测试数据如学校、学生成绩等) 为文档添加内容哈希值防止重复 使用DashScope嵌入模型生成向量 连接ChromaDB向量数据库进行存储 关
🚀 我的Langchain + ChromaDB学习框架搭建日记
📋 今日目标
今天主要是想要用 Langchain + ChromaDB 搭建我自己的主要学习框架,主打自己一步步地把一些重要的参数和关键的逻辑走一遍 💪
🔧 环境搭建
Langchain 和 ChromaDB 的环境搭建就不详细说了,都不难。ChromaDB 我是使用 Docker 本地启动的方式运行的,然后通过 Langchain 框架来连接使用。这里我使用的是 HTTP 调用方式,虽然能找到 Langchain 框架结合使用的方案,但这不是重点,就不深入研究了。🔧
🏗️ RAG框架搭建
整个 RAG 搭建的代码目前分成了两个部分:
- 知识库的搭建 📚
- 检索应用阶段 🎯
📚 知识库搭建代码
以下是我用来构建知识库的代码,里面放进去的数据都是一些测试数据,比如阳关小学、学生、考试成绩等等。后来我把 chunk size 改得比较小,这样就可以测试检索出来的精度和计算的相似度了。这次我使用的是相似度计算方法 🔍💡
# =====================
# 配置信息 - 请根据实际情况修改以下变量
# =====================
# 知识库文件路径
FILE_PATH = "C:\\Users\\CAIRIDONG\\Desktop\\无聊的测试数据.txt" # 知识库txt文件路径
# 向量数据库连接配置
VECTOR_DB_TYPE = "chroma" # 可选: qdrant, chroma, milvus, weaviate
VECTOR_DB_URL = "./chromaDB_Fred" # 数据库存储目录 (如果使用持久化目录)
VECTOR_DB_HOST = "localhost" # Chroma服务主机 (如果使用HTTP客户端)
VECTOR_DB_PORT = 6667 # Chroma服务端口 (如果使用HTTP客户端)
VECTOR_DB_API_KEY = "your-api-key" # API密钥(如需要)
COLLECTION_NAME = "rag_collection_school" # 集合/表名称
# DashScope嵌入模型配置
DASHSCOPE_EMBEDDING_API_KEY = "sk-XXXXXXXXXXXXXXXXXXX"
EMBEDDING_MODEL_ID = "text-embedding-v2" # 嵌入模型ID
# 导入必要的库
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.schema import Document
import logging
import chromadb
import hashlib
import os
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def calculate_content_hash(content):
"""计算文档内容的哈希值"""
return hashlib.md5(content.encode('utf-8')).hexdigest()
def get_document_hashes(vector_store):
"""获取向量数据库中已存在的文档哈希"""
try:
# 查询所有文档的元数据
results = vector_store.get(include=['metadatas'])
hashes = set()
if results and 'metadatas' in results:
for metadata in results['metadatas']:
if metadata and 'content_hash' in metadata:
hashes.add(metadata['content_hash'])
return hashes
except Exception as e:
logger.warning(f"获取现有文档哈希时出错: {str(e)}")
return set()
def add_hash_to_documents(documents):
"""为文档添加内容哈希"""
for doc in documents:
if not hasattr(doc, 'metadata') or doc.metadata is None:
doc.metadata = {}
doc.metadata['content_hash'] = calculate_content_hash(doc.page_content)
# 添加源文件信息
if 'source' not in doc.metadata:
doc.metadata['source'] = os.path.basename(FILE_PATH)
return documents
def filter_duplicate_documents(documents, existing_hashes):
"""过滤重复文档"""
unique_documents = []
duplicate_count = 0
for doc in documents:
content_hash = doc.metadata.get('content_hash')
if content_hash not in existing_hashes:
unique_documents.append(doc)
existing_hashes.add(content_hash)
else:
duplicate_count += 1
logger.info(f"发现并过滤了 {duplicate_count} 个重复文档")
return unique_documents
def build_knowledge_base():
"""构建知识库"""
try:
# 加载和处理文档
logger.info("开始加载文档...")
loader = TextLoader(FILE_PATH, encoding='utf-8')
documents = loader.load()
logger.info(f"文档加载完成,共加载 {len(documents)} 个文档")
# 文本分割
logger.info("开始文本分割...")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=60)
texts = text_splitter.split_documents(documents)
logger.info(f"文本分割完成,共生成 {len(texts)} 个文本块")
# 为文档添加哈希值
logger.info("开始为文档添加内容哈希...")
texts = add_hash_to_documents(texts)
logger.info("文档哈希添加完成")
# 创建嵌入模型
logger.info("开始创建嵌入模型...")
embeddings = DashScopeEmbeddings(
model=EMBEDDING_MODEL_ID,
dashscope_api_key=DASHSCOPE_EMBEDDING_API_KEY
)
logger.info("嵌入模型创建完成")
# 连接向量数据库
logger.info(f"开始连接向量数据库: {VECTOR_DB_TYPE}")
if VECTOR_DB_TYPE == "chroma":
try:
# 尝试使用HTTP客户端连接
logger.info("尝试使用HTTP客户端连接Chroma服务...")
from chromadb.config import Settings
chroma_client = chromadb.HttpClient(
host=VECTOR_DB_HOST,
port=VECTOR_DB_PORT,
settings=Settings(
chroma_api_impl="rest",
chroma_server_host=VECTOR_DB_HOST,
chroma_server_http_port=str(VECTOR_DB_PORT)
)
)
# 测试连接
heartbeat = chroma_client.heartbeat()
logger.info(f"成功连接到Chroma服务,心跳时间戳: {heartbeat}")
# 检查集合是否存在
try:
collection = chroma_client.get_collection(name=COLLECTION_NAME)
logger.info(f"成功连接到现有的Chroma集合: {COLLECTION_NAME}")
# 如果集合存在,添加新文档
vector_store = Chroma(
client=chroma_client,
embedding_function=embeddings,
collection_name=COLLECTION_NAME
)
# 重复检测
logger.info("开始重复检测...")
existing_hashes = get_document_hashes(vector_store)
unique_texts = filter_duplicate_documents(texts, existing_hashes)
if unique_texts:
# 添加唯一文档到现有集合
vector_store.add_documents(unique_texts)
logger.info(f"已将 {len(unique_texts)} 个唯一文档添加到现有集合")
else:
logger.info("没有新的唯一文档需要添加")
except:
logger.info(f"集合 {COLLECTION_NAME} 不存在,将创建新的集合")
vector_store = Chroma.from_documents(
texts,
embeddings,
client=chroma_client,
collection_name=COLLECTION_NAME
)
logger.info(f"新的Chroma集合创建完成,已添加 {len(texts)} 个文档")
except Exception as http_e:
logger.warning(f"HTTP客户端连接失败: {str(http_e)}")
logger.info("尝试使用持久化目录方式连接Chroma...")
# 回退到持久化目录方式
try:
vector_store = Chroma(
persist_directory=VECTOR_DB_URL,
embedding_function=embeddings,
collection_name=COLLECTION_NAME
)
# 重复检测
logger.info("开始重复检测...")
existing_hashes = get_document_hashes(vector_store)
unique_texts = filter_duplicate_documents(texts, existing_hashes)
if unique_texts:
# 添加唯一文档到现有数据库
vector_store.add_documents(unique_texts)
logger.info(f"成功连接到现有的Chroma数据库,已添加 {len(unique_texts)} 个唯一文档")
else:
logger.info("没有新的唯一文档需要添加")
except Exception as persist_e:
logger.info("未找到现有数据库,将创建新的数据库")
# 创建新的数据库
vector_store = Chroma.from_documents(
texts,
embeddings,
persist_directory=VECTOR_DB_URL,
collection_name=COLLECTION_NAME
)
logger.info(f"新的Chroma数据库创建完成,已添加 {len(texts)} 个文档")
else:
raise ValueError(f"不支持的向量数据库类型: {VECTOR_DB_TYPE}")
logger.info("知识库构建完成!")
return vector_store
except Exception as e:
logger.error(f"构建知识库时出错: {str(e)}")
raise
if __name__ == "__main__":
build_knowledge_base()
🎯 应用部分代码
# =====================
# 配置信息 - 请根据实际情况修改以下变量
# =====================
# 实施步骤:
# 1. 检索策略增强
# - 添加检索参数配置(top_k、score_threshold等)
# - 实现混合检索和多路检索
# - 添加检索结果的相关性评分和过滤
# 2. 上下文管理
# - 实现会话历史存储和管理
# - 添加上下文窗口控制
# - 支持多轮对话和上下文关联
# 3. 答案生成优化
# - 添加自定义提示词模板
# - 实现答案来源追踪和引用显示
# - 添加答案相关性评分机制
# 4. 性能和监控
# - 实现查询缓存机制
# - 添加性能指标收集
# - 实现使用统计和分析
# 5. 用户体验提升
# - 创建交互式命令行界面
# - 实现流式输出显示
# - 添加答案格式化和高亮显示
# =====================
# 向量数据库连接配置
VECTOR_DB_TYPE = "chroma" # 可选: qdrant, chroma, milvus, weaviate
VECTOR_DB_URL = "./chromaDB_Fred" # 数据库存储目录 (如果使用持久化目录)
VECTOR_DB_HOST = "localhost" # Chroma服务主机 (如果使用HTTP客户端)
VECTOR_DB_PORT = 6667 # Chroma服务端口 (如果使用HTTP客户端)
VECTOR_DB_API_KEY = "your-api-key" # API密钥(如需要)
COLLECTION_NAME = "rag_collection_school" # 集合/表名称
# DashScope嵌入模型配置
DASHSCOPE_EMBEDDING_API_KEY = "sk-XXXXXXXXXXXXXXXXXXXXXXXX"
EMBEDDING_MODEL_ID = "text-embedding-v2" # 嵌入模型ID
# 语言模型配置
MODELScope_API_KEY = "msXXXXXXXXXXXXXXXXXXXXXXXXXX" # ModelScope API密钥
LLM_BASE_URL = "https://api-inference.modelscope.cn/v1" # ModelScope API端点
LLM_MODEL_NAME = "Qwen/Qwen3-30B-A3B-Instruct-2507" # 语言模型名称
# =====================
# 检索参数配置 - 在这里修改检索策略参数
# =====================
# 检索数量配置
RETRIEVAL_K = 5 # 检索的文档数量 (默认: 5)
RETRIEVAL_FETCH_K = 10 # MMR检索时获取的文档数量 (默认: 10)
# 相似度阈值配置
RETRIEVAL_SCORE_THRESHOLD = 0.5 # 相似度阈值 (默认: 0.5)
# 检索类型配置
SEARCH_TYPE = "similarity" # 检索类型: "similarity", "mmr", "similarity_score_threshold"
# 检索器配置
RETRIEVER_SEARCH_KWARGS = {
"k": RETRIEVAL_K
}
# 导入必要的库
from langchain_community.chat_models import ChatOpenAI
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.chains import RetrievalQA
import logging
import chromadb
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def load_knowledge_base():
"""加载已构建的知识库"""
try:
# 创建嵌入模型
logger.info("开始创建嵌入模型...")
embeddings = DashScopeEmbeddings(
model=EMBEDDING_MODEL_ID,
dashscope_api_key=DASHSCOPE_EMBEDDING_API_KEY
)
logger.info("嵌入模型创建完成")
# 连接向量数据库
logger.info(f"开始连接向量数据库: {VECTOR_DB_TYPE}")
if VECTOR_DB_TYPE == "chroma":
try:
# 尝试使用HTTP客户端连接
logger.info("尝试使用HTTP客户端连接Chroma服务...")
from chromadb.config import Settings
chroma_client = chromadb.HttpClient(
host=VECTOR_DB_HOST,
port=VECTOR_DB_PORT,
settings=Settings(
chroma_api_impl="rest",
chroma_server_host=VECTOR_DB_HOST,
chroma_server_http_port=str(VECTOR_DB_PORT)
)
)
# 测试连接
heartbeat = chroma_client.heartbeat()
logger.info(f"成功连接到Chroma服务,心跳时间戳: {heartbeat}")
# 连接到现有的Chroma集合
vector_store = Chroma(
client=chroma_client,
embedding_function=embeddings,
collection_name=COLLECTION_NAME
)
logger.info(f"成功连接到Chroma集合: {COLLECTION_NAME}")
except Exception as http_e:
logger.warning(f"HTTP客户端连接失败: {str(http_e)}")
logger.info("尝试使用持久化目录方式连接Chroma...")
# 回退到持久化目录方式
vector_store = Chroma(
persist_directory=VECTOR_DB_URL,
embedding_function=embeddings,
collection_name=COLLECTION_NAME
)
logger.info("成功连接到Chroma数据库")
else:
raise ValueError(f"不支持的向量数据库类型: {VECTOR_DB_TYPE}")
return vector_store
except Exception as e:
logger.error(f"加载知识库时出错: {str(e)}")
raise
def create_qa_system(vector_store):
"""创建问答系统"""
try:
# 初始化语言模型
logger.info("开始初始化语言模型...")
llm = ChatOpenAI(
openai_api_key=MODELScope_API_KEY,
base_url=LLM_BASE_URL,
model=LLM_MODEL_NAME
)
logger.info("语言模型初始化完成")
# 创建检索问答链
logger.info("开始创建检索问答链...")
# 打印当前检索器配置信息
print("=" * 60)
print("当前检索器配置信息:")
print("=" * 60)
# 获取默认检索器并检查其属性
default_retriever = vector_store.as_retriever()
print(f"默认检索器类型: {type(default_retriever)}")
# 尝试获取检索器的内部属性
try:
print(f"检索器搜索类型: {getattr(default_retriever, 'search_type', '未设置')}")
print(f"检索器搜索参数: {getattr(default_retriever, 'search_kwargs', {})}")
except Exception as e:
print(f"无法获取检索器属性: {e}")
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_store.as_retriever(
search_type="similarity",
search_kwargs=RETRIEVER_SEARCH_KWARGS
) # ★★★ 检索参数配置位置 ★★★
)
logger.info("检索问答链创建完成")
return qa
except Exception as e:
logger.error(f"创建问答系统时出错: {str(e)}")
raise
def ask_question(qa, question):
"""提问并获取答案"""
try:
logger.info(f"开始运行查询: {question}")
# 获取检索器并执行相似性查询
retriever = qa.retriever
# 执行检索并获取相似性分数
print("=" * 60)
print("检索相似性分析:")
print("=" * 60)
# 使用相似性搜索获取分数
results_with_scores = retriever.vectorstore.similarity_search_with_score(question, k=RETRIEVAL_K)
print(f"查询: {question}")
print(f"检索到 {len(results_with_scores)} 个相关文档")
print("-" * 40)
for i, (doc, score) in enumerate(results_with_scores, 1):
print(f"文档 {i}:")
print(f" 相似性分数: {score}")
print(f" 内容预览: {doc.page_content[:100]}...")
print(f" 来源: {doc.metadata.get('source', '未知')}")
print("-" * 40)
print("=" * 60)
# 获取最终答案
result = qa.run(question)
logger.info("查询完成")
return result
except Exception as e:
logger.error(f"查询时出错: {str(e)}")
raise
def main():
"""主函数"""
try:
# 加载知识库
vector_store = load_knowledge_base()
# 创建问答系统
qa = create_qa_system(vector_store)
# 运行查询
query = "孙八的每门科成绩是是多少?"
result = ask_question(qa, query)
print(result)
except Exception as e:
logger.error(f"程序执行出错: {str(e)}")
raise
if __name__ == "__main__":
main()
📊 实验结果与分析
在这种情况下,因为我一开始的 chunk size 设置为 1000,整个文档被切分在一个块中,导致计算出来的相似度结果都差不多。后来我把 chunk size 调整为 100,就有了下面的相似度计算结果:
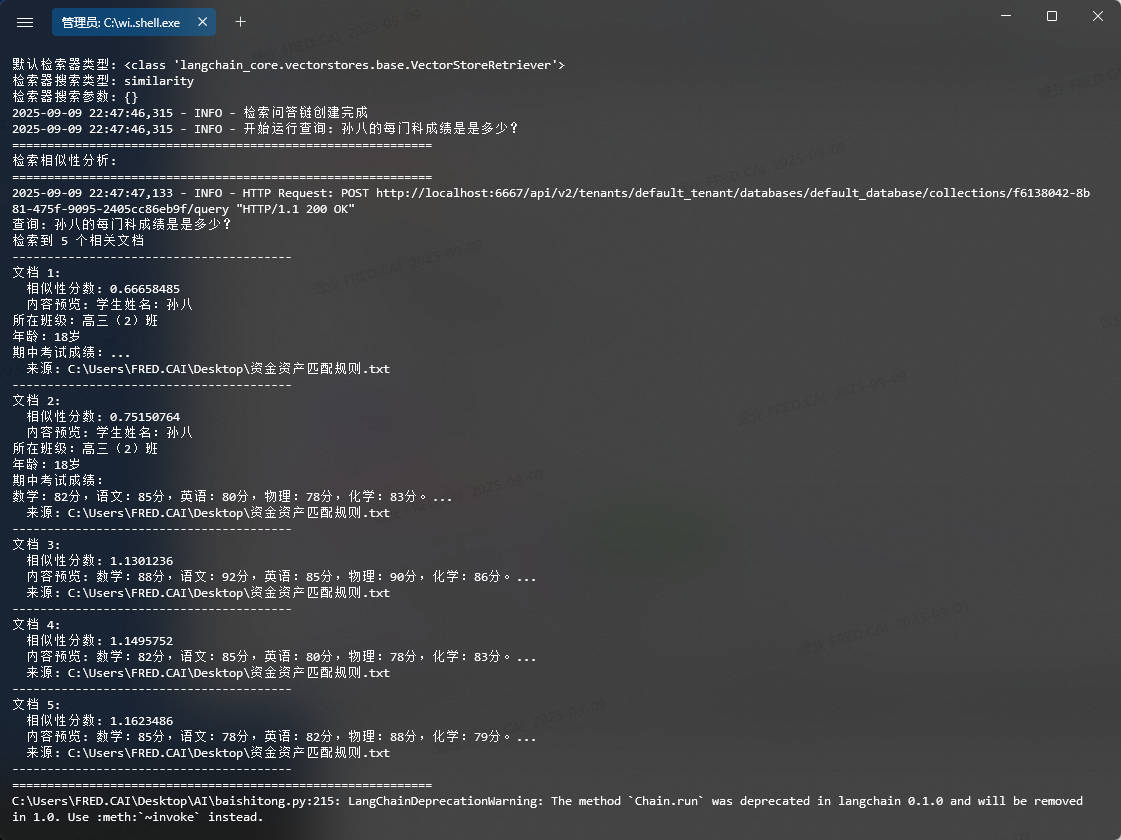
可以看出来,每个计算出来的结果都是不一样的。越接近 0 的值,表示越相似。我提问的问题是:“孙八的成绩是多少?”,所以检索出来的都是和孙八有关的 chunk 片段。🔍🎯
今天简单试了下在 chain 链中,通过改变不同的配置来测试使用情况,这次用的是 similarity 方法,明天准备改为 MMR 试试看效果如何!🤔

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)