C++进阶:具有多个代码文件的程序
当编译器运行到main 函数第 5 行的add函数调用时,它并不知道add是什么,因为我们直到第 9 行才定义add!我们的解决方案是重新排序函数(将add放在最前面),或者对add使用前向声明。提醒:对于A函数中调用B函数,B函数调用A函数的例子,重新排序将失去其效用,而前向声明可以忽略掉函数声明的前后顺序,只要保证其在函数调用前面就行,但是在复杂的程序中,我们需要花很多精力去看排列函数的顺序才
多文件示例:
我们研究了一个无法编译的单文件程序:
#include <iostream>
int main()
{
std::cout << "The sum of 3 and 4 is: " << add(3, 4) << '\n';
return 0;
}
int add(int x, int y)
{
return x + y;
}
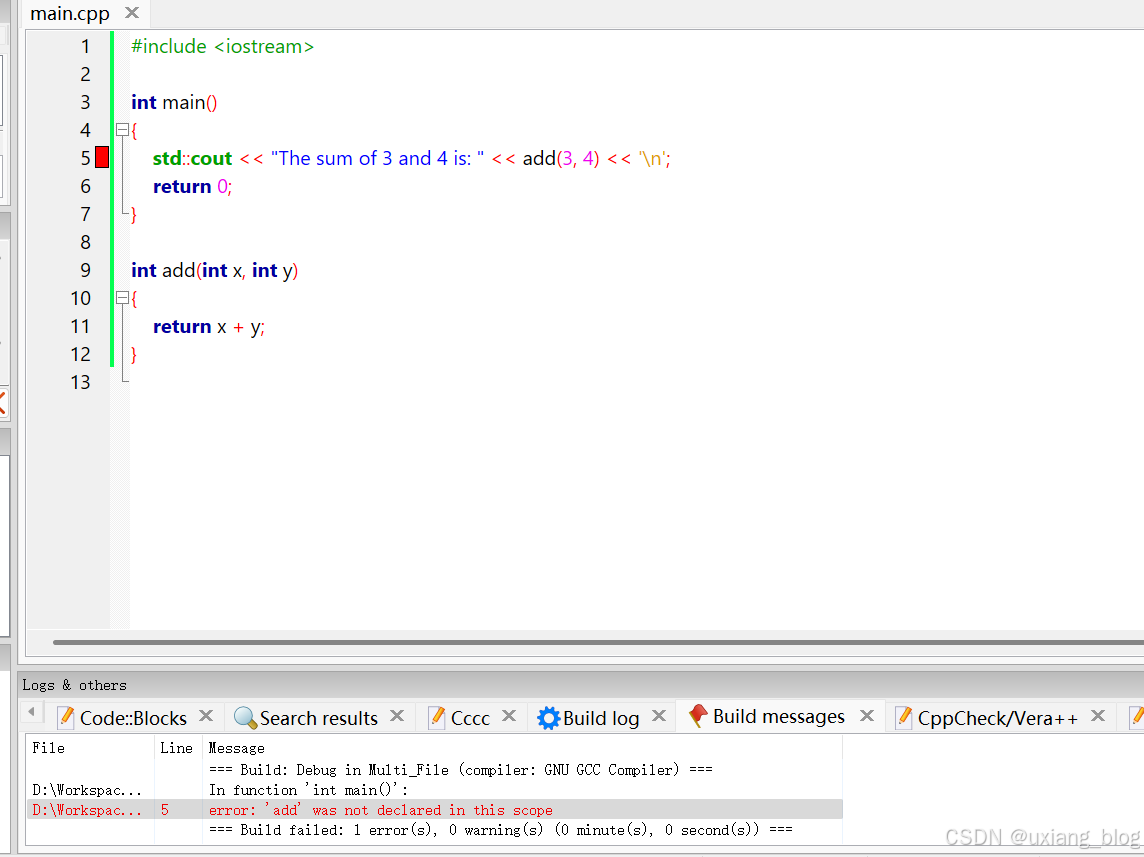
当编译器运行到main 函数第 5 行的add函数调用时,它并不知道add是什么,因为我们直到第 9 行才定义add!我们的解决方案是重新排序函数(将add放在最前面),或者对add使用前向声明。提醒:对于A函数中调用B函数,B函数调用A函数的例子,重新排序将失去其效用,而前向声明可以忽略掉函数声明的前后顺序,只要保证其在函数调用前面就行,但是在复杂的程序中,我们需要花很多精力去看排列函数的顺序才能确定位置,所以一般声明放在头文件之后。
现在让我们看一个类似的多文件程序:
add.cpp
int add(int x, int y)
{
return x + y;
}
main.cpp
#include <iostream>
int main()
{
std::cout << "The sum of 3 and 4 is: " << add(3, 4) << '\n';
return 0;
}
你的编译器可能会先编译add.cpp或main.cpp。无论哪种情况,main.cpp都会编译失败,并出现与上例相同的编译器错误。原因也完全相同:当编译器到达main.cpp的第 5 行时,它不知道标识符add是什么。
请记住,编译器会单独编译每个文件。它不知道其他代码文件的内容,也不会记住之前编译过的代码文件中的内容。因此,即使编译器之前可能见过函数add的定义(如果它先编译了add.cpp),它也不会记住。
这种有限的可见性和短暂的记忆是故意的,原因如下:
- 它允许以任何顺序编译项目的源文件。
- 当我们更改源文件时,只需要重新编译该源文件。
- 它减少了不同文件中的标识符之间命名冲突的可能性
此处的解决方案选项与之前相同:将函数add的定义放在函数main之前,或者使用前向声明来满足编译器的要求。在本例中,由于函数add位于另一个文件中,因此无法使用重新排序选项。
这里的解决方案是使用前向声明:
main.cpp(带有前向声明):
#include <iostream>
int add(int x, int y); // needed so main.cpp knows that add() is a function defined elsewhere
int main()
{
std::cout << "The sum of 3 and 4 is: " << add(3, 4) << '\n';
return 0;
}
add.cpp(保持不变):
int add(int x, int y)
{
return x + y;
}
现在,当编译器编译main.cpp时,它会知道标识符add是什么,并且会得到满足。链接器会将main.cpp中对add 的函数调用与add.cpp中对add函数的定义连接起来。使用此方法(前向声明),我们可以让文件访问另一个文件中的函数。
尝试使用前向声明编译add.cpp和main.cpp 。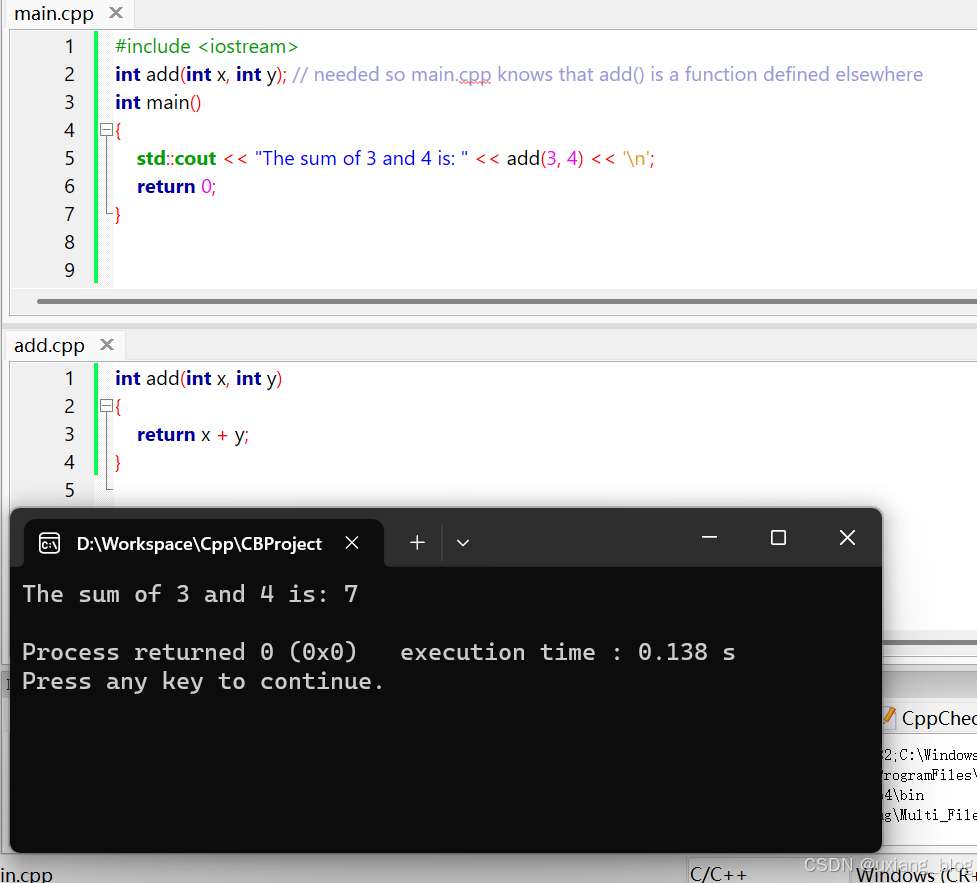
为什么能这样呢?
当在表达式中使用标识符时,该标识符必须与其定义相连。
- 如果编译器在正在编译的文件中既没有看到该标识符的前向声明也没有看到该标识符的定义,那么它将在使用该标识符的地方出错。
- 否则,如果同一文件中存在定义,则编译器将把标识符的使用与其定义联系起来。
- 否则,如果定义存在于不同的文件中(并且对链接器可见),则链接器将把标识符的使用连接到其定义。
- 否则,链接器将发出错误,表明无法找到该标识符的定义。
C++ 的设计使得每个源文件都可以独立编译,而无需了解其他文件的内容。因此,文件的实际编译顺序应该无关紧要。
一旦我们进入面向对象编程,我们就会开始大量处理多个文件,因此现在是确保您了解如何添加和编译多个文件项目的最佳时机。
提醒:每当您创建一个新的代码(.cpp)文件时,您都需要将其添加到您的项目中以便进行编译。
头文件——更优的解决方法
我们讨论了如何将程序拆分到多个文件中。我们还讨论了如何使用前向声明来允许一个文件中的代码访问另一个文件中定义的代码。
当程序只包含几个小文件时,手动在每个文件顶部添加几个前向声明还不算太麻烦。然而,随着程序规模越来越大(并使用更多文件和函数),手动在每个文件顶部添加大量(可能不同的)前向声明会变得极其繁琐。例如,如果你有一个包含 5 个文件的程序,每个文件都需要 10 个前向声明,那么你将不得不复制/粘贴 50 个前向声明。现在考虑一下你有 100 个文件,每个文件都需要 100 个前向声明的情况。这根本无法扩展!
为了解决这个问题,C++ 程序通常采用不同的方法——头文件。考虑以下程序:
#include <iostream>
int main()
{
std::cout << "Hello, world!";
return 0;
}
这段程序使用std::cout在控制台打印了“Hello, world!” 。然而,这段程序并没有提供std::cout的定义或声明,那么编译器如何知道std::cout是什么呢?
答案是std::cout已在“iostream”头文件中进行了前向声明。当我们#include 时,我们请求预处理器将所有内容(包括 std::cout 的前向声明)从名为“iostream”的文件复制到执行 #include 的文件中。当你创建#include一个文件时,被包含文件的内容会被插入到包含点。这提供了一种从其他文件中提取声明的有效方法。想象一下,如果iostream头不存在会发生什么。无论在哪里使用std::cout,您都必须手动将所有与std::cout相关的声明键入或复制到每个使用std::cout的文件顶部!这需要大量关于std::cout声明方式的知识,而且工作量巨大。更糟糕的是,如果添加或更改了函数原型,我们还必须手动更新所有前向声明。这#include 要简单得多!
回到上个例子。
add.h
// We really should have a header guard here, but will omit it for simplicity (we'll cover header guards in the next lesson)
// This is the content of the .h file, which is where the declarations go
int add(int x, int y); // function prototype for add.h -- don't forget the semicolon!
add.cpp
#include "add.h" // Insert contents of add.h at this point. Note use of double quotes here.
int add(int x, int y)
{
return x + y;
}
main.cpp
#include "add.h" // Insert contents of add.h at this point. Note use of double quotes here.
#include <iostream>
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << '\n';
return 0;
}
当预处理器处理该#include "add.h"行时,它会将 add.h 的内容复制到当前文件中的该位置。由于我们的add.h包含函数add()的前向声明,因此该前向声明将被复制到main.cpp中。最终生成的程序在功能上与我们在main.cpp顶部手动添加前向声明的程序相同。因此,我们的程序将正确编译和链接。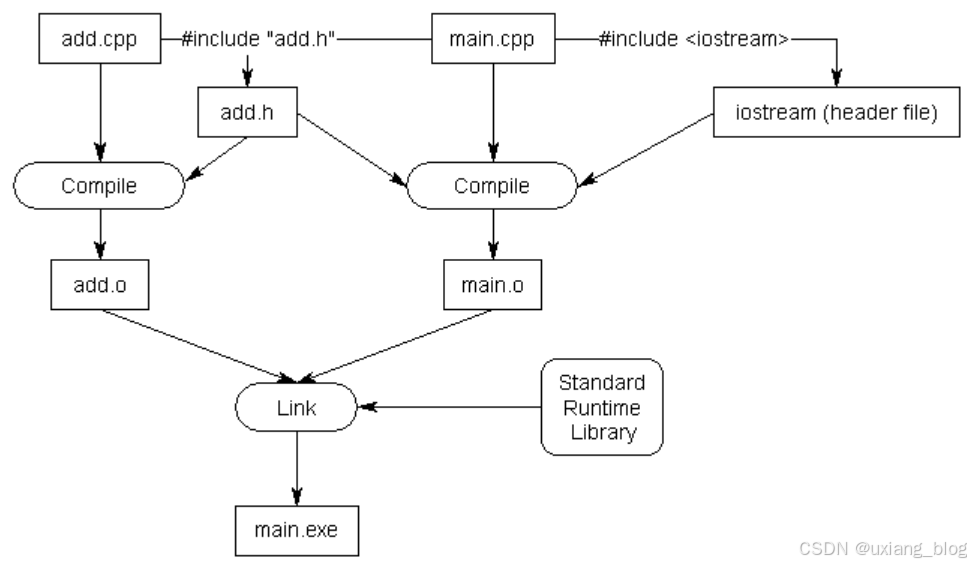
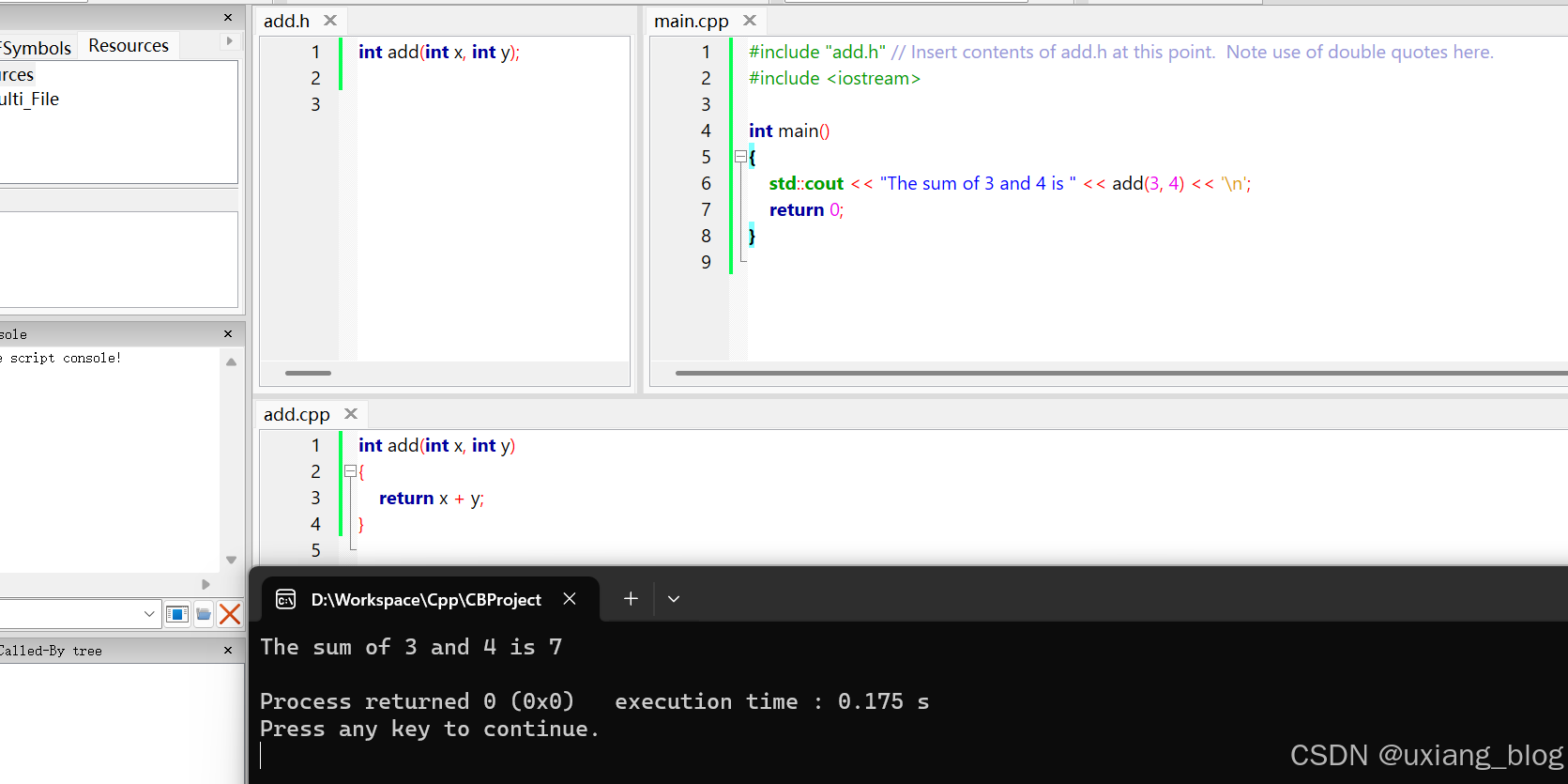
我们发现当即使上面add.cpp中没有#include “add.h” 依然可以运行成功,为什么又要添加呢?虽然从技术上讲,add.cpp不需要包含add.h,但代码文件最好包含其对应的头文件。因为头文件应该 #include 包含其所需功能的任何其他头文件。当将此类头文件单独 #include 到 .cpp 文件中时,应该能够成功编译。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)