yolov8训练滑块验证码识别模型:第二章:制作数据集+训练+验证
这样就完成了数据集制作、训练、验证,下一章讲解该如何运用模型进行推理。环境配置可以去看我上一章:yolov8训练滑块验证码识别模型:第一章:yolov8环境配置(linux)-CSDN博客t=P7R7t=P7R7yolov8训练滑块验证码识别模型:第一章:yolov8环境配置(linux)-CSDN博客https://blog.csdn.net/xin_yao_xin/article/detail
上一章已经讲了如何配置yolov8的基础环境,今天来制作数据集。
1、制作数据集
1.1、网上收集
下面是飞桨平台的滑块验证码模型,yolo格式,可直接使用;
1.2、自制数据集
使用Labelimg工具进行手动标注。
1.2.1、Labelimg安装
创建环境
conda create -n labelimg python=3.10激活环境
conda activate labelimg安装
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple使用
labelimg启动成功

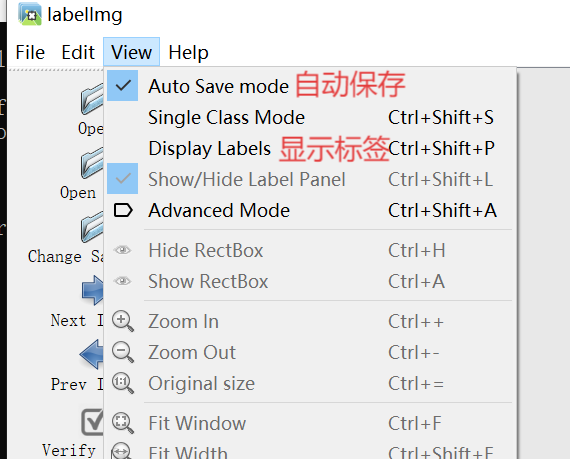
1.2.2、使用Labelimg进行数据集标注
解决labelimg点击框选图片就闪退报错

使用
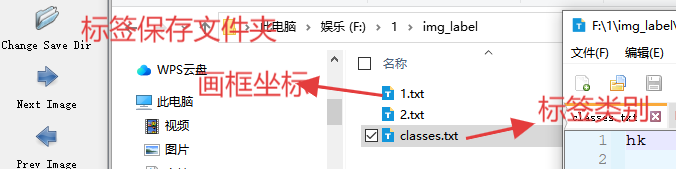
1.txt: ![]()
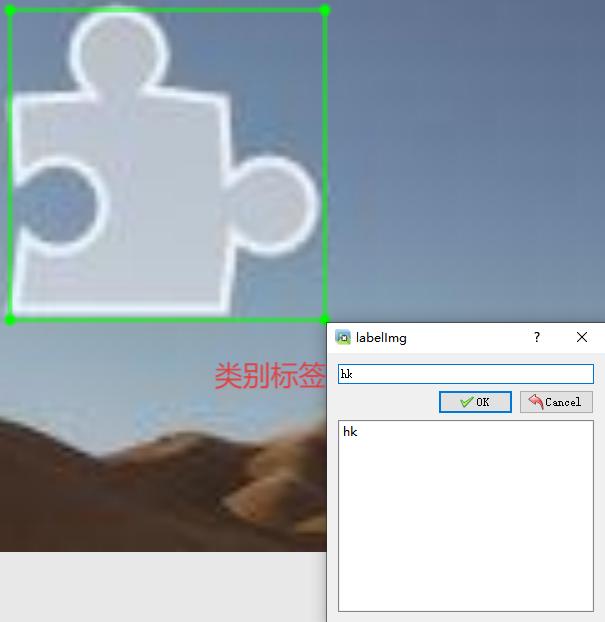
点击Create RectBox进行拖动画框
快捷键
一、基础操作快捷键
| 快捷键 | 功能描述 |
|---|---|
Ctrl + N |
新建标注文件(.xml) |
Ctrl + O |
打开图像文件 |
Ctrl + S |
保存标注结果 |
Ctrl + D |
复制当前标注框并粘贴 |
Ctrl + Shift + D |
删除所有标注框 |
Ctrl + +/- |
放大 / 缩小图像 |
Ctrl + 0 |
恢复图像原始大小 |
↑ ↓ ← → |
移动选中的标注框(1 像素) |
Shift + ↑ ↓ ← → |
移动选中的标注框(10 像素) |
Ctrl + 鼠标拖动 |
框选区域(创建新标注框) |
二、标注框编辑快捷键
| 快捷键 | 功能描述 |
|---|---|
W |
进入 “创建标注框” 模式(常用) |
Del |
删除选中的标注框 |
Ctrl + 鼠标滚轮 |
缩放图像 |
鼠标滚轮 |
上下切换图像 |
Space |
确认当前标注(快速切换状态) |
三、图像浏览快捷键
| 快捷键 | 功能描述 |
|---|---|
A / Left |
切换到上一张图像 |
D / Right |
切换到下一张图像 |
Ctrl + A |
全选当前图像中的所有标注框 |
F |
全屏显示图像 |
Esc |
退出全屏 / 取消当前操作 |
四、标签相关快捷键
| 快捷键 | 功能描述 |
|---|---|
Ctrl + L |
打开标签列表(可添加 / 删除标签) |
数字键 1~9 |
快速选择标签列表中对应序号的标签(需先在标签列表中排序) |
五、其他实用快捷键
| 快捷键 | 功能描述 |
|---|---|
Ctrl + Z |
撤销上一步操作 |
Ctrl + Shift + Z |
重做操作 |
H |
显示 / 隐藏标注框的标签名称 |
Ctrl + P |
打印标注信息 |
Ctrl + Q |
退出 LabelImg 程序 |
2、划分数据集
将储存图片的文件夹img和储存标签的文件夹img_label,按比例划分为训练集、验证集、测试集。
大体结构
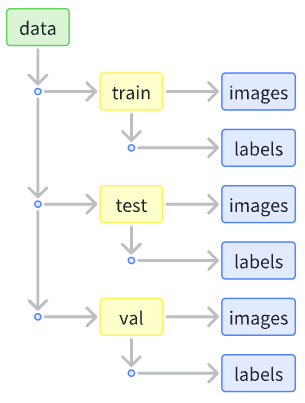
划分数据集代码
import os
import shutil
import random
def split_dataset(image_dir, label_dir, output_dir, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1):
"""
按比例划分数据集为训练集、验证集和测试集
参数:
image_dir: 原始图片目录
label_dir: 原始标签目录
output_dir: 输出目录
train_ratio: 训练集比例
val_ratio: 验证集比例
test_ratio: 测试集比例
"""
# 验证比例合法性
if not abs(train_ratio + val_ratio + test_ratio - 1.0) < 1e-6:
raise ValueError("训练集、验证集和测试集比例之和必须为1")
# 获取所有图片文件并筛选出有对应标签的文件
image_extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.gif'}
image_files = []
for file in os.listdir(image_dir):
name, ext = os.path.splitext(file)
if ext.lower() in image_extensions:
# 检查是否存在对应的标签文件(不限制标签格式)
label_path = None
for label_file in os.listdir(label_dir):
if os.path.splitext(label_file)[0] == name:
label_path = label_file
break
if label_path:
image_files.append((file, label_path))
else:
print(f"警告: 图片 '{file}' 没有对应的标签文件,已跳过")
if not image_files:
raise ValueError("未找到有效的图片-标签对")
# 打乱文件顺序
random.shuffle(image_files)
total = len(image_files)
# 计算各数据集大小
train_count = int(total * train_ratio)
val_count = int(total * val_ratio)
test_count = total - train_count - val_count
# 确保每个集合至少有一个样本
if train_count == 0:
train_count = 1
val_count = max(0, val_count - 1)
if val_count == 0 and test_count > 0:
val_count = 1
test_count -= 1
# 分割数据集
train_set = image_files[:train_count]
val_set = image_files[train_count:train_count + val_count]
test_set = image_files[train_count + val_count:]
# 创建目录结构
dirs = {
'train': {'images': os.path.join(output_dir, 'train', 'images'),
'labels': os.path.join(output_dir, 'train', 'labels')},
'val': {'images': os.path.join(output_dir, 'val', 'images'),
'labels': os.path.join(output_dir, 'val', 'labels')},
'test': {'images': os.path.join(output_dir, 'test', 'images'),
'labels': os.path.join(output_dir, 'test', 'labels')}
}
for d in dirs.values():
os.makedirs(d['images'], exist_ok=True)
os.makedirs(d['labels'], exist_ok=True)
# 复制文件函数
def copy_files(file_pairs, dest):
for img_file, label_file in file_pairs:
shutil.copy2(os.path.join(image_dir, img_file), os.path.join(dest['images'], img_file))
shutil.copy2(os.path.join(label_dir, label_file), os.path.join(dest['labels'], label_file))
# 复制文件到对应目录
copy_files(train_set, dirs['train'])
copy_files(val_set, dirs['val'])
copy_files(test_set, dirs['test'])
# 打印结果统计
print(f"数据集划分完成!总样本数: {total}")
print(f"训练集: {len(train_set)} 个样本 ({len(train_set) / total * 100:.1f}%)")
print(f"验证集: {len(val_set)} 个样本 ({len(val_set) / total * 100:.1f}%)")
print(f"测试集: {len(test_set)} 个样本 ({len(test_set) / total * 100:.1f}%)")
print(f"结果保存至: {output_dir}")
if __name__ == "__main__":
img_dir = "F:/1/aaa/img"
label_dir = "F:/1/aaa/img_laber"
output_dir = "F:/1/aaa/data"
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
seed = 42
# 设置随机种子,保证结果可复现
random.seed(seed)
try:
split_dataset(
img_dir,
label_dir,
output_dir,
train_ratio,
val_ratio,
test_ratio
)
except Exception as e:
print(f"错误: {str(e)}")
exit(1)
3、训练模型
将文件夹data拷贝到yolov8源码根目录下,并在根目录下创建data.yaml,
train: /yolov8/data/train/images # 训练集路径
val: /yolov8/data/val/images # 验证集路径
test: /yolov8/data/test/images # 测试集路径
nc: 1 # 分类标签数
# Classes
names: ['hk'] # 标签,多的话可扩展,比如:nc: 2 names: ['hk','hk1']在根目录下创建train.py,执行文件进行训练
import warnings
from ultralytics import YOLO
from ultralytics.utils import set_logging
# 忽略警告信息
warnings.filterwarnings('ignore')
# 设置日志级别为info,显示训练进度
set_logging('info')
def train_yolov8():
"""YOLOv8模型训练函数,所有参数在函数内配置"""
# -------------------------- 模型配置 --------------------------
# 模型配置文件路径或预训练模型名称
model_config = '/yolov8/ultralytics/cfg/models/v8/yolov8n.yaml' # 如 'yolov8s.yaml', 'yolov8m.yaml' 等
# 预训练权重路径,为空字符串则不加载预训练权重
pretrained_weights = 'yolov8n.pt' # 如 'yolov8s.pt',或 '' 表示从头训练
# -------------------------- 数据集配置 ------------------------
# 数据集配置文件路径(需确保yaml文件中的路径正确)
data_config = 'data.yaml' # 你的数据集配置文件
# -------------------------- 训练参数配置 ----------------------
epochs = 100 # 训练总轮次
batch_size = 16 # 批次大小,根据GPU显存调整
imgsz = 640 # 输入图像尺寸
device = '0' # 训练设备,'0'表示第1块GPU,'cpu'表示使用CPU
workers = 8 # 数据加载工作线程数
optimizer = 'SGD' # 优化器,可选 'auto', 'SGD', 'Adam', 'AdamW'
# 初始化模型
if model_config.endswith(('.yaml', '.yml')):
# 从配置文件创建模型
model = YOLO(model_config)
# 加载预训练权重(如果指定)
if pretrained_weights:
model.load(pretrained_weights)
else:
# 直接加载预训练模型
model = YOLO(model_config)
# 开始训练
print(f"开始训练 YOLOv8 模型,设备: {device}")
results = model.train(
data=data_config,
epochs=epochs,
batch=batch_size,
imgsz=imgsz,
device=device,
workers=workers,
optimizer=optimizer,
val=True # 每个epoch结束后进行验证
)
print("训练完成!")
print(f"训练结果保存路径: {results.save_dir}")
return results
if __name__ == '__main__':
# 执行训练
train_yolov8()
更多训练参数详见:使用 Ultralytics YOLO 进行模型训练 - Ultralytics YOLO 文档
下面是官方文档的一部分。
训练设置
YOLO 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器的选择、损失函数和训练数据集组成会影响训练过程。仔细调整和试验这些设置对于优化性能至关重要。
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model |
str |
None |
指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件的路径。对于定义模型结构或初始化权重至关重要。 |
data |
str |
None |
数据集配置文件的路径(例如, coco8.yaml)。此文件包含数据集特定的参数,包括训练和 验证数据的路径,类别名称和类别数量。 |
epochs |
int |
100 |
训练的总轮数。每个epoch代表对整个数据集的一次完整遍历。调整此值会影响训练时长和模型性能。 |
time |
float |
None |
最长训练时间(以小时为单位)。如果设置此参数,它将覆盖 epochs 参数,允许训练在指定时长后自动停止。适用于时间受限的训练场景。 |
patience |
int |
100 |
在验证指标没有改善的情况下,等待多少个epoch后提前停止训练。通过在性能停滞时停止训练,有助于防止过拟合。 |
batch |
int 或 float |
16 |
批次大小,具有三种模式:设置为整数(例如, batch=16),自动模式,GPU 内存利用率为 60%(batch=-1),或具有指定利用率分数的自动模式(batch=0.70)。 |
imgsz |
int |
640 |
用于训练的目标图像大小。图像被调整为边长等于指定值的正方形(如果 rect=False),为 YOLO 模型保留宽高比,但不为 RTDETR 保留。影响模型 准确性 和计算复杂度。 |
save |
bool |
True |
启用保存训练检查点和最终模型权重。可用于恢复训练或模型部署。 |
save_period |
int |
-1 |
保存模型检查点的频率,以 epoch 为单位指定。值为 -1 时禁用此功能。适用于在长时间训练期间保存临时模型。 |
cache |
bool |
False |
启用在内存中缓存数据集图像(True/ram),在磁盘上缓存(disk),或禁用缓存(False)。通过减少磁盘 I/O 来提高训练速度,但会增加内存使用量。 |
device |
int 或 str 或 list |
None |
指定用于训练的计算设备:单个 GPU(device=0),多个 GPU(device=[0,1]),CPU(device=cpu),适用于 Apple 芯片的 MPS(device=mps),或自动选择最空闲的 GPU(device=-1)或多个空闲 GPU (device=[-1,-1]) |
workers |
int |
8 |
用于数据加载的工作线程数(每个 RANK ,如果是多 GPU 训练)。影响数据预处理和输入模型的速度,在多 GPU 设置中尤其有用。 |
project |
str |
None |
项目目录的名称,训练输出保存在此目录中。允许有组织地存储不同的实验。 |
name |
str |
None |
训练运行的名称。用于在项目文件夹中创建一个子目录,训练日志和输出存储在该子目录中。 |
exist_ok |
bool |
False |
如果为 True,则允许覆盖现有的 project/name 目录。适用于迭代实验,无需手动清除之前的输出。 |
pretrained |
bool 或 str |
True |
确定是否从预训练模型开始训练。可以是一个布尔值,也可以是加载权重的特定模型的字符串路径。增强训练效率和模型性能。 |
optimizer |
str |
'auto' |
训练优化器的选择。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等等,或者 auto 用于基于模型配置自动选择。影响收敛速度和稳定性。 |
seed |
int |
0 |
设置训练的随机种子,确保在相同配置下运行结果的可重复性。 |
deterministic |
bool |
True |
强制使用确定性算法,确保可重复性,但由于限制了非确定性算法,可能会影响性能和速度。 |
single_cls |
bool |
False |
在多类别数据集中,将所有类别视为单个类别进行训练。适用于二元分类任务或侧重于对象是否存在而非分类时。 |
classes |
list[int] |
None |
指定要训练的类 ID 列表。可用于在训练期间过滤掉并仅关注某些类。 |
rect |
bool |
False |
启用最小填充策略——批量中的图像被最小程度地填充以达到一个共同的大小,最长边等于 imgsz。可以提高效率和速度,但可能会影响模型精度。 |
multi_scale |
bool |
False |
通过增加/减少来启用多尺度训练 imgsz 高达 0.5 在训练期间。训练模型,使其在多次迭代中更加准确 imgsz 在推理过程中。 |
cos_lr |
bool |
False |
使用余弦学习率调度器,在 epochs 上按照余弦曲线调整学习率。有助于管理学习率,从而实现更好的收敛。 |
close_mosaic |
int |
10 |
在最后 N 个 epochs 中禁用 mosaic 数据增强,以在完成前稳定训练。设置为 0 可禁用此功能。 |
resume |
bool |
False |
从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和 epoch 计数,无缝继续训练。 |
amp |
bool |
True |
启用自动混合精度(AMP)训练,减少内存使用,并可能在对准确性影响最小的情况下加快训练速度。 |
fraction |
float |
1.0 |
指定用于训练的数据集比例。允许在完整数据集的子集上进行训练,这在实验或资源有限时非常有用。 |
profile |
bool |
False |
在训练期间启用 ONNX 和 TensorRT 速度的分析,有助于优化模型部署。 |
freeze |
int 或 list |
None |
冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。适用于微调或迁移学习。 |
lr0 |
float |
0.01 |
初始学习率(即 SGD=1E-2, Adam=1E-3)。调整此值对于优化过程至关重要,它会影响模型权重更新的速度。 |
lrf |
float |
0.01 |
最终学习率作为初始速率的一部分 = (lr0 * lrf),与调度器结合使用以随时间调整学习率。 |
momentum |
float |
0.937 |
SGD 的动量因子或 Adam 优化器的 beta1,影响当前更新中过去梯度的合并。 |
weight_decay |
float |
0.0005 |
L2 正则化项,惩罚大权重以防止过拟合。 |
warmup_epochs |
float |
3.0 |
学习率预热的 epochs 数,将学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
warmup_momentum |
float |
0.8 |
预热阶段的初始动量,在预热期间逐渐调整到设定的动量。 |
warmup_bias_lr |
float |
0.1 |
预热阶段偏差参数的学习率,有助于稳定初始 epochs 中的模型训练。 |
box |
float |
7.5 |
损失函数中框损失分量的权重,影响对准确预测边界框坐标的重视程度。 |
cls |
float |
0.5 |
分类损失在总损失函数中的权重,影响正确类别预测相对于其他成分的重要性。 |
dfl |
float |
1.5 |
分布焦点损失的权重,在某些 YOLO 版本中用于细粒度分类。 |
pose |
float |
12.0 |
在为姿势估计训练的模型中,姿势损失的权重会影响对准确预测姿势关键点的强调。 |
kobj |
float |
2.0 |
姿势估计模型中关键点对象性损失的权重,用于平衡检测置信度和姿势准确性。 |
nbs |
int |
64 |
用于损失归一化的标称批量大小。 |
overlap_mask |
bool |
True |
确定是否应将对象掩码合并为单个掩码以进行训练,还是为每个对象保持分离。如果发生重叠,则在合并期间,较小的掩码会覆盖在较大的掩码之上。 |
mask_ratio |
int |
4 |
分割掩码的下采样率,影响训练期间使用的掩码分辨率。 |
dropout |
float |
0.0 |
分类任务中用于正则化的 Dropout 率,通过在训练期间随机省略单元来防止过拟合。 |
val |
bool |
True |
在训练期间启用验证,从而可以定期评估模型在单独数据集上的性能。 |
plots |
bool |
False |
生成并保存训练和验证指标的图表,以及预测示例,从而提供对模型性能和学习进度的可视化见解。 |
compile |
bool |
False |
启用PyTorch 2.x torch.compile 图编译以优化模型执行。适用于支持的设备CUDAMPS)。使用方法 backend='inductor', mode='max-autotune'.如果不支持,则退回急切模式并发出警告。 |
4、验证模型
import os
import argparse
import cv2
import warnings
from ultralytics import YOLO
from ultralytics.utils import set_logging
import shutil
# 忽略警告信息
warnings.filterwarnings('ignore')
# 设置日志级别
set_logging('info')
def process_single_image(model, img_path, output_dir, conf_threshold=0.5):
"""
处理单张图片并保存结果
参数:
model: YOLO模型实例
img_path: 输入图片路径
output_dir: 结果保存目录
conf_threshold: 置信度阈值
"""
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 执行预测
results = model(img_path, conf=conf_threshold)
# 处理结果
for result in results:
# 生成带预测框的图像
annotated_img = result.plot()
# 保存结果图像
img_name = os.path.basename(img_path)
output_path = os.path.join(output_dir, img_name)
cv2.imwrite(output_path, annotated_img)
# 打印预测信息
print(f"处理完成: {img_name}")
print(f"检测到目标数: {len(result.boxes)}")
for box in result.boxes:
cls = int(box.cls[0])
conf = float(box.conf[0])
class_name = model.names[cls]
print(f" 类别: {class_name}, 置信度: {conf:.2f}")
return output_path
def process_folder(model, folder_path, output_dir, conf_threshold=0.5):
"""
处理文件夹中的所有图片并保存结果
参数:
model: YOLO模型实例
folder_path: 输入文件夹路径
output_dir: 结果保存目录
conf_threshold: 置信度阈值
"""
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 支持的图片格式
image_extensions = ('.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff')
# 获取文件夹中所有图片
image_files = [
f for f in os.listdir(folder_path)
if f.lower().endswith(image_extensions) and os.path.isfile(os.path.join(folder_path, f))
]
if not image_files:
print(f"警告: 在文件夹 {folder_path} 中未找到任何图片文件")
return
print(f"发现 {len(image_files)} 张图片,开始批量处理...")
# 批量处理图片
for i, img_file in enumerate(image_files, 1):
img_path = os.path.join(folder_path, img_file)
print(f"\n处理图片 {i}/{len(image_files)}: {img_file}")
# 调用单张图片处理函数
process_single_image(model, img_path, output_dir, conf_threshold)
print(f"\n批量处理完成,所有结果已保存至: {output_dir}")
def validate_yolo():
"""YOLO模型验证主函数"""
# -------------------------- 配置参数 --------------------------
# 模型权重路径
model_path = 'runs/train/exp/weights/best.pt' # 替换为你的模型路径
# 输入配置 - 二选一:单张图片路径或文件夹路径
single_image_path = '' # 单张图片路径,如 'test.jpg',不使用则留空
folder_path = 'test_images' # 文件夹路径,如 'test_folder',不使用则留空
# 输出目录
output_dir = 'validation_results'
# 验证参数
conf_threshold = 0.5 # 置信度阈值,0-1之间,值越大筛选越严格
device = '0' # 验证设备,'0'表示GPU,'cpu'表示CPU
# -------------------------- 验证逻辑 --------------------------
# 检查输入配置
if not single_image_path and not folder_path:
raise ValueError("请配置单张图片路径(single_image_path)或文件夹路径(folder_path)")
if single_image_path and not os.path.exists(single_image_path):
raise FileNotFoundError(f"单张图片不存在: {single_image_path}")
if folder_path and not os.path.isdir(folder_path):
raise NotADirectoryError(f"文件夹不存在: {folder_path}")
# 加载模型
print(f"加载模型: {model_path}")
model = YOLO(model_path)
print(f"模型加载完成,类别数: {len(model.names)}")
print(f"类别列表: {model.names}")
# 处理输入
if single_image_path:
print(f"处理单张图片: {single_image_path}")
process_single_image(model, single_image_path, output_dir, conf_threshold)
else:
print(f"处理文件夹: {folder_path}")
process_folder(model, folder_path, output_dir, conf_threshold)
print(f"\n所有验证完成,结果保存至: {os.path.abspath(output_dir)}")
if __name__ == '__main__':
try:
validate_yolo()
except Exception as e:
print(f"验证过程出错: {str(e)}")
exit(1)
保存后验证结果图片:
总结:
这样就完成了数据集制作、训练、验证,下一章讲解该如何运用模型进行推理。
环境配置可以去看我上一章:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)