【教程合集】Ollama全面教程(Windows)
详细的了解ollama的使用:第一课:ollama运行原理介绍及同类工具对比;第二课:ollama安装(Windows);第三课:ollama安装大模型的方式汇总;第四课:🐑 Ollama 命令汇总;第五课:桌面模型管理应用调用ollama大模型;第六课:Python 调用 Ollama 大模型方式汇总
🐳Ollama,简单直接,被AI各种应用广泛支持,广泛到我们“不得不”学习一下⚡️。
ℹ️教程说明
Ollama 是一款轻量级本地大模型部署工具,使用广泛,且容易上手,适合作为AI技术的入门。
💡说明:如果快速掌握ollama基本使用的朋友,可以看下面🚀速成文档:
🧩分课教程版本地址:
本篇教程为汇总教程,完全开放,另有分课教程版本,内容一样,只是可读性会好一些:
- 第一课:ollama运行原理介绍及同类工具对比
- ollama运行原理介绍及同类工具对比,与选择建议
- 第二课:ollama安装(Windows)
- 介绍了两种典型安装模式:普通安装方式和独立 CLI
- 第三课:ollama安装大模型的方式汇总
- ollama安装大模型的五种典型方式的详细汇总
- 第四课:🐑 Ollama 命令汇总
- 本文全面介绍了Ollama的相关命令的语法与示例,包括核心命令、模型管理命令、高级与系统命令
- 第五课:桌面模型管理应用调用ollama大模型
- 本文介绍了如何通过桌面应用调用本地Ollama大模型,对比了11款主流工具,并重点介绍了几个常用工具的具体安装和配置。
- 第六课:Python 调用 Ollama 大模型方式汇总
- 本文系统介绍了Python调用Ollama大模型的多种方式,包括官方SDK、REST API、OpenAI兼容接口、CLI调用及上层框架集成。
📒参考资源:
🎩官网资源:
- 官网:https://ollama.com/
- Ollama 中文文档: https://ollama.readthedocs.io/
- 接口 Endpoints - Ollama 官方中文文档:https://ollama-docs.apifox.cn/
- github官网Python调用示例:https://github.com/ollama/ollama-python
⚛️专项文档地址:
-
REST API 参考:https://github.com/ollama/ollama/blob/main/docs/api.md
-
/api/generate、/api/chat、流式、超参、keep_alive 等。
-
-
Modelfile 规范:https://github.com/ollama/ollama/blob/main/docs/modelfile.md
-
构建私有模型、添加系统提示、模板与分词器设置。
-
-
Embedding 支持:https://github.com/ollama/ollama/blob/main/docs/embeddings.md
-
常用于 RAG 管线,说明调用参数与返回维度。
-
-
服务器部署与环境变量:https://github.com/ollama/ollama/blob/main/docs/faq.md
-
端口、并发、KV 缓存、显存/内存优化要点
-
🧠模型地址:
- huggingface.co:https://huggingface.co/models
第一课:ollama运行原理介绍及同类工具对比
一、Ollama 深度解析
1.1 背景
- 厂商 / 开发者:Ollama Inc.(独立科技公司)
- 成立背景:2023 年成立于美国,核心团队来自前 Google、Meta 等公司的 AI 基础设施工程师,专注于「降低本地大模型使用门槛」。
- 开发模式:商业公司主导的开源项目(核心代码开源,模型库由官方维护)。
- 核心方向:通过简化部署流程和统一交互接口,推动本地 LLM 在开发者工具链、边缘设备中的普及,目前已完成多轮融资(公开信息显示融资规模超千万美元)。
1.2 核心定位与功能
Ollama 是一款轻量级本地大模型部署工具,核心目标是「降低本地运行大语言模型(LLM)的门槛」。它封装了模型下载、环境配置、推理加速等复杂流程,让开发者通过简单命令即可在本地(Windows/macOS/Linux)运行 Llama 3、Gemini、Mistral 等主流模型,支持命令行交互、API 调用和自定义模型配置。
🌟其核心特性包括:
- 轻量级架构:基于llama.cpp推理引擎,支持CPU/GPU硬件加速
- 模型管理:提供预构建模型库(Llama 3、DeepSeek、Qwen等),支持自定义模型开发
- API兼容性:兼容OpenAI API标准,可无缝接入LangChain等开发框架
- 跨平台支持:Windows/macOS/Linux全平台覆盖
- 安全性:模型在本地运行,不联网,保护隐私
1.3. 运行原理
Ollama 的核心作用是「简化本地模型的生命周期管理」,Ollama 的架构可分为三层,形成「模型管理 - 推理服务 - 交互接口」的闭环:
-
模型管理层
维护官方模型库(library),统一模型格式(基于 GGUF 等量化格式)。当执行ollama pull <模型名>时,会自动下载模型权重、配置文件(如 tokenizer 信息)和量化参数,并缓存到本地(默认路径:~/.ollama/models,Windows为:C:\Users\<用户名>\.ollama\models)。支持自动校验模型完整性,避免损坏文件导致的运行失败。 -
推理服务层
核心是内置的推理引擎(基于 llama.cpp 优化),负责:- 硬件适配:自动检测 CPU/GPU(支持 NVIDIA CUDA、Apple Metal、AMD ROCm),动态分配计算资源(如 GPU 显存不足时自动切换 CPU fallback);
- 量化加速:默认使用 4-bit/8-bit 量化模型(平衡性能与内存占用),通过 KV 缓存、张量并行等技术优化推理速度;
- 服务启动:运行模型时启动本地 HTTP 服务(默认端口 11434),作为请求入口处理推理任务,支持并发请求(通过队列机制避免资源竞争),该服务负责:
- 加载模型到内存(根据硬件自动选择 CPU/GPU 加速);
- 处理用户输入的推理请求;
- 维护模型运行的生命周期(如暂停、重启、释放资源)。
-
交互接口层
提供两种交互方式:- 命令行交互(
ollama run):适合快速测试,支持上下文对话(自动维护对话历史); - REST API(
/api/chat、/api/generate):适合集成到代码(Python/Java 等),支持流式输出(SSE)和批量推理。
- 命令行交互(
图形化逻辑图如下:
+-------------------+
| 用户输入命令 |
+-------------------+
|
v
+-------------------+
| Ollama CLI |
+-------------------+
|
v
+-------------------+
| 模型下载/缓存 |
+-------------------+
|
v
+-------------------+
| 模型加载到内存 |
+-------------------+
|
v
+-------------------+
| 模型推理引擎 |
+-------------------+
|
v
+-------------------+
| 返回结果 |
+-------------------+1.4 核心优势与局限
-
👆优势:
- 极简部署:无需手动配置依赖(如 CUDA 环境、Python 库),一键安装即用;
- 模型生态丰富:官方库包含 100+ 主流模型,支持自定义模型(通过 Modelfile 配置系统提示、参数等);
- 跨平台一致性:Windows/macOS/Linux 命令完全统一,降低多环境适配成本。
-
👇局限:
- 定制化能力有限:高级推理参数(如批处理大小、缓存策略)暴露较少,难以深度优化;
- 模型格式依赖:主要支持官方适配的模型,自定义训练的非标准模型需转换格式;
- 性能天花板:相比原生 llama.cpp 等工具,封装层会带来轻微性能损耗(约 5-10%)。
二、同类工具解析(面向 AI 工程师)
2.1 llama.cpp(C++ 推理框架)
🌍 背景
- 厂商 / 开发者:以 Georgi Gerganov 为核心的开源社区(个人主导 + 社区贡献)
- 成立背景:2023 年由保加利亚开发者 Georgi Gerganov 发起(因 Meta 开源 Llama 模型后,需轻量化推理方案而诞生),无商业公司背景。
- 开发模式:纯开源项目(MIT 许可证),核心维护者为 Georgi Gerganov,全球数千名开发者贡献代码(优化硬件适配、模型兼容等)。
- 核心方向:聚焦 LLM 推理引擎的极致性能优化,尤其在 CPU 和低资源设备上的效率提升,是众多上层工具(如 Ollama、LM Studio)的底层依赖。
🚩 定位
专注于 LLM 高效推理的 C++ 开源框架,支持 CPU/GPU 加速,是许多上层工具(如 Ollama)的底层依赖。
📚 运行原理
- 核心优化:基于 C++ 实现纯原生推理,通过 SIMD 指令集(如 AVX2、NEON)加速 CPU 计算;支持 CUDA/Metal 核函数直接操作张量,减少内存拷贝开销。
- 模型格式:主打 GGUF 格式(通用量化格式,支持 1-bit 到 16-bit 量化),兼容 Llama、Mistral、Gemini 等模型家族。
- 运行方式:通过命令行启动,需手动指定模型路径、推理参数(如
./main -m model.gguf -p "prompt"),无内置 HTTP 服务(需配合第三方工具如llama-server提供 API)。
💡 优势与局限
- 优势:性能极致(同硬件下推理速度比 Ollama 快 5-15%)、支持低资源设备(如树莓派)、可深度定制推理参数;
- 局限:门槛高(需手动编译、配置参数)、无模型管理功能(需手动下载模型)、生态较封闭(API 需自行开发)。
2.2 LM Studio(GUI 工具)
🌍 背景
- 厂商 / 开发者:LM Studio, Inc.(独立科技公司)
- 成立背景:2023 年成立于美国西雅图,团队以「让本地 AI 像浏览器一样易用」为目标,创始人来自微软、亚马逊等公司的 AI 产品团队。
- 开发模式:商业软件(免费基础版 + 付费专业版),核心推理引擎基于 llama.cpp 二次开发,闭源但兼容开源模型格式。
- 核心方向:面向开发者和企业用户提供「零代码本地 LLM 工具」,主打图形界面交互和快速集成能力,目前已推出企业级部署方案。
🚩 定位
面向开发者的「本地 LLM 桌面客户端」,通过图形界面简化模型部署,兼顾易用性与基础定制能力。
📚 运行原理
- 架构:前端基于 Electron 实现 GUI,后端集成 llama.cpp 作为推理引擎,中间层封装模型下载、服务启动逻辑。
- 核心功能:可视化模型库(支持搜索、筛选)、实时性能监控(GPU/CPU 占用、推理速度)、对话历史管理、API 服务开关(默认端口 1234)。
- 推理优化:自动选择最优量化精度(根据硬件配置推荐 4-bit/8-bit),支持「模型预热」(提前加载到内存减少启动时间)。
💡 优势与局限
- 优势:零命令行操作、可视化调试(如查看 token 生成速度)、适合快速演示;
- 局限:定制化弱(参数调整选项少)、API 功能简单(不支持批量推理)、资源占用较高(Electron 框架开销)。
2.3 Text Generation Web UI(Web 界面工具)
🌍 背景
- 厂商 / 开发者:以 oobabooga(网名,真实身份未公开)为核心的开源社区
- 成立背景:2022 年底由匿名开发者 oobabooga 发起,最初为适配开源模型 Llama 而开发,后逐步支持多模型,无商业公司背景。
- 开发模式:纯开源项目(AGPL 许可证),GitHub 星标数超 5 万,社区贡献者超千人,主要维护者为 oobabooga 及几位核心志愿者。
- 核心方向:提供「全功能本地 LLM 调试环境」,聚焦开发者的实验性需求(如参数调优、插件扩展),是研究人员和爱好者的常用工具。
🚩 定位
开源的浏览器端 LLM 交互工具,主打「高度可定制化」,适合模型调试与实验。
📚 运行原理
- 技术栈:后端基于 Python(FastAPI),前端基于 Gradio,推理依赖 transformers 或 llama.cpp 后端。
- 核心能力:支持多模型并行加载、自定义推理参数(温度、top_p、最大生成长度等)、插件扩展(如 RAG 集成、语音输入)、模型微调(通过 LoRA 插件)。
- 部署方式:需手动安装 Python 环境和依赖(如
pip install -r requirements.txt),启动后通过浏览器访问(默认 localhost:7860)。
💡 优势与局限
- 优势:参数可调范围极广(适合研究场景)、支持复杂功能(如长上下文窗口扩展)、社区插件丰富;
- 局限:部署复杂(依赖冲突频发)、资源占用高(Python 环境 + 前端框架)、不适合生产环境集成。
2.4 Hugging Face Transformers(Python 库)
🌍 背景
- 厂商 / 开发者:Hugging Face, Inc.(AI 领域知名公司)
- 成立背景:2016 年成立于美国纽约,最初以 NLP 工具库起家,逐步发展为全球最大的开源 AI 模型社区,2023 年估值超 40 亿美元。
- 开发模式:商业公司支持的开源项目(Apache 2.0 许可证),核心库由公司团队开发,同时接受社区贡献,模型库(Hugging Face Hub)开放给全球开发者上传共享。
- 核心方向:构建「AI 模型开发全流程生态」,除 Transformers 库外,还涵盖数据集(Datasets)、评估工具(Evaluate)、部署工具(Inference Endpoints)等,是学术界和工业界的标准工具链。
🚩 定位
AI 领域最流行的模型推理库,支持几乎所有主流 LLM,是构建自定义推理服务的基础工具。
📚 运行原理
- 核心设计:基于 PyTorch/TensorFlow 封装模型架构(如 Transformer),提供统一的
pipeline接口简化推理流程。 - 加速机制:通过
bitsandbytes实现量化(4/8-bit)、transformers_accelerate优化分布式推理、ONNX Runtime提升 CPU 性能。 - 集成方式:需开发者手动编写代码加载模型(如
AutoModelForCausalLM.from_pretrained()),并自行搭建 API 服务(如配合 FastAPI)。
💡 优势与局限
- 优势:支持模型最全面(包括未量化的原生模型)、可深度定制推理逻辑(如修改 attention 实现)、与 Hugging Face 生态(Datasets、Evaluate)无缝衔接;
- 局限:门槛高(需熟悉 Python 和深度学习框架)、部署复杂(需手动处理依赖和服务化)、性能优化需手动配置。
2.5 vLLM(高性能推理引擎)
🌍 背景
- 厂商 / 开发者:vLLM Inc.(由学术项目孵化的商业公司)
- 成立背景:2023 年由加州大学伯克利分校的计算机科学团队发起(核心成员包括李沐团队成员),最初是学术研究项目(解决大模型推理效率问题),后成立公司商业化。
- 开发模式:开源核心引擎(Apache 2.0 许可证)+ 商业云服务(vLLM Cloud),公司团队主导开发,同时接受社区对模型兼容性的贡献。
- 核心方向:聚焦「生产级 LLM 推理性能优化」,主打高吞吐量和低延迟,服务于需要大规模部署 LLM 的企业(如云厂商、AI 应用开发商),已获得知名风投投资。
🚩 定位
面向生产环境的高性能 LLM 推理引擎,主打高吞吐量和低延迟,适合大规模部署。
📚 运行原理
- 核心创新:基于 PagedAttention 机制(类似操作系统内存分页)优化 KV 缓存管理,支持连续批处理(Continuous Batching)提升 GPU 利用率。
- 部署方式:提供 Python API 和 HTTP 服务(兼容 OpenAI API 格式),需配合 CUDA 环境(仅支持 NVIDIA GPU)。
- 性能指标:同硬件下吞吐量比 Hugging Face Transformers 高 5-10 倍,延迟降低 30-50%。
💡 优势与局限
- 优势:生产级性能、支持动态批处理、兼容 OpenAI API(易于迁移);
- 局限:仅支持 GPU(无 CPU fallback)、依赖复杂(需特定 CUDA 版本)、不适合低资源设备。
三、工具横向对比(AI 工程师视角)
| 维度 | Ollama | llama.cpp | LM Studio | Text Generation Web UI | Hugging Face Transformers | vLLM |
|---|---|---|---|---|---|---|
| 核心场景 | 快速部署、API 集成 | 性能极致优化 | 可视化演示、快速测试 | 模型调试、实验 | 自定义推理逻辑开发 | 生产环境高并发部署 |
| 易用性 | 极高(一键安装) | 低(需编译配置) | 高(GUI 操作) | 中(需配置 Python 环境) | 低(需编码) | 中(需配置 GPU 环境) |
| 模型支持 | 官方库 100+ 模型 | 支持 GGUF 格式模型 | 主流模型(GUI 筛选) | 几乎所有 LLM | 全量模型(Hugging Face) | 主流闭源 / 开源模型 |
| 硬件加速 | 自动适配 CPU/GPU | 手动配置 CPU/GPU 加速 | 自动适配(有限选项) | 支持多后端加速 | 需手动配置加速参数 | 仅支持 NVIDIA GPU(最优) |
| API 能力 | 内置 REST API | 需第三方工具扩展 | 基础 REST API | WebSocket/API 支持 | 需自行开发 API | 兼容 OpenAI API |
| 定制化程度 | 低(有限参数) | 极高(源码级定制) | 低(基础参数) | 极高(插件 + 参数全开放) | 极高(代码级定制) | 中(配置文件调整) |
| 性能(同硬件) | 中(轻微封装损耗) | 极高(原生优化) | 中(GUI 开销) | 中低(Python 开销) | 中(需手动优化) | 极高(生产级优化) |
| 资源占用 | 低 | 极低 | 中(Electron 框架) | 高 | 中高 | 高(GPU 显存需求高) |
四、选择建议(AI 工程师决策指南)
-
快速验证想法 / 集成到工具链 → 选 Ollama
优势:零配置、API 友好,适合在原型开发中快速接入本地模型,支持跨平台一致性。 -
追求极致性能 / 低资源设备 → 选 llama.cpp
优势:C++ 原生推理,适合嵌入式设备(如边缘计算)或对延迟敏感的场景(需接受较高的使用门槛)。 -
可视化调试 / 非技术人员协作 → 选 LM Studio 或 Text Generation Web UI
- 简单可视化需求 → LM Studio(GUI 直观);
- 复杂调试(如长上下文测试) → Text Generation Web UI(参数全开放)。
-
自定义推理逻辑 / 学术研究 → 选 Hugging Face Transformers
优势:支持修改模型结构、自定义 attention 机制等底层操作,与研究生态无缝衔接。 -
生产环境大规模部署 → 选 vLLM
优势:高吞吐量 + 低延迟,兼容 OpenAI API 便于迁移,适合企业级服务(需 NVIDIA GPU 支持)。
💎 总结:
Ollama 代表了「简单化」趋势,通过封装复杂度降低本地 LLM 使用门槛;而 llama.cpp、vLLM 等工具则聚焦「专业化」,为性能或定制化需求提供深度支持。AI 工程师需根据场景优先级(易用性 / 性能 / 定制化)选择:快速迭代选 Ollama,深度优化选 llama.cpp,生产部署选 vLLM,学术研究选 Hugging Face Transformers。
第二课:ollama安装(Windows)
一、安装概述
🎉好消息:ollama安装不再需要 WSL!也不再需要管理员权限。
🧩有两种安装方式:
-
普通安装方式:用
OllamaSetup.exe安装,会在你的用户目录下部署 Ollama 应用、后台服务和自动更新机制,适合直接在本机使用,不再需要管理员权限。。 -
独立 CLI:将 Ollama 作为服务安装或集成,使用独立的
ollama-windows-amd64.zip压缩文件,其中仅包含 Ollama CLI 和 Nvidia 及 AMD 的 GPU 库依赖项。这允许你将 Ollama 嵌入现有应用程序中,或通过ollama serve等工具将其作为系统服务运行。
二、系统条件
2.1 系统要求
💻对系统资源的要求:
- Windows 10 22H2 或更新版本,家庭版或专业版
- 如果你有 NVIDIA 显卡,需要安装 452.39 或更新版本的驱动程序
- 如果你有 Radeon 显卡,需要安装 AMD Radeon 驱动程序 https://www.amd.com/en/support
Ollama 使用 Unicode 字符来显示进度,这在 Windows 10 的一些旧终端字体中可能会显示为未知方块。如果你看到这种情况,尝试更改终端字体设置。
📌参考知识:Windows系统,查看当前用的什么显卡,以及驱动的版本:
图形化方式:
Ctrl + Shift + Esc 打开任务管理器。
切换到 性能(Performance)标签。
左侧选择 GPU 0 / GPU 1,右侧会显示显卡型号和部分驱动信息(版本信息不一定完整)
命令行方式:
在 PowerShell 中直接获取:
Get-WmiObject Win32_VideoController | Select-Object Name, DriverVersion或在较新版本 PowerShell 中:
Get-CimInstance Win32_VideoController | Select-Object Name, DriverVersion这样可以直接输出显卡型号和驱动版本,方便做自动化检测,类似如下执行界面:

2.2 文件系统要求
Ollama 安装不需要管理员权限,安装需要的空间:
- 需要至少 4GB 的空间来安装二进制文件
- 安装 Ollama 后,需要额外的空间来存储大型语言模型,这些模型的大小可能从几十 GB 到几百 GB 不等
三、普通安装方式
Ollama 现在作为原生 Windows 应用程序运行,支持 NVIDIA 和 AMD Radeon GPU。 安装 Ollama for Windows 后,Ollama 将在后台运行, ollama 命令行工具将在 cmd、powershell 或你最喜欢的终端应用程序中可用。和往常一样,Ollama API 将在 http://localhost:11434 上提供服务。
3.1 下载安装包
官网下载 Windows 版本的 OllamaSetup.exe 安装程序:
- 访问官网:https://ollama.com
- 点击 Download for Windows下载
⚠️备选下载地址:
github下载地址:https://github.com/ollama/ollama/releases
国内下载镜像:ollama | newbe
3.2 安装
➡️ 3.2.1 直接安装
-
如果不需要修改安装路径,直接双击安装包
OllamaSetup.exe,默认安装在C:\Users\<你的用户名>\AppData\Local\Ollama,按提示安装 -
安装完成后,系统会自动启动Ollama服务,并进入ollama桌面程序
➡️3.2.2 定制安装:更改安装位置
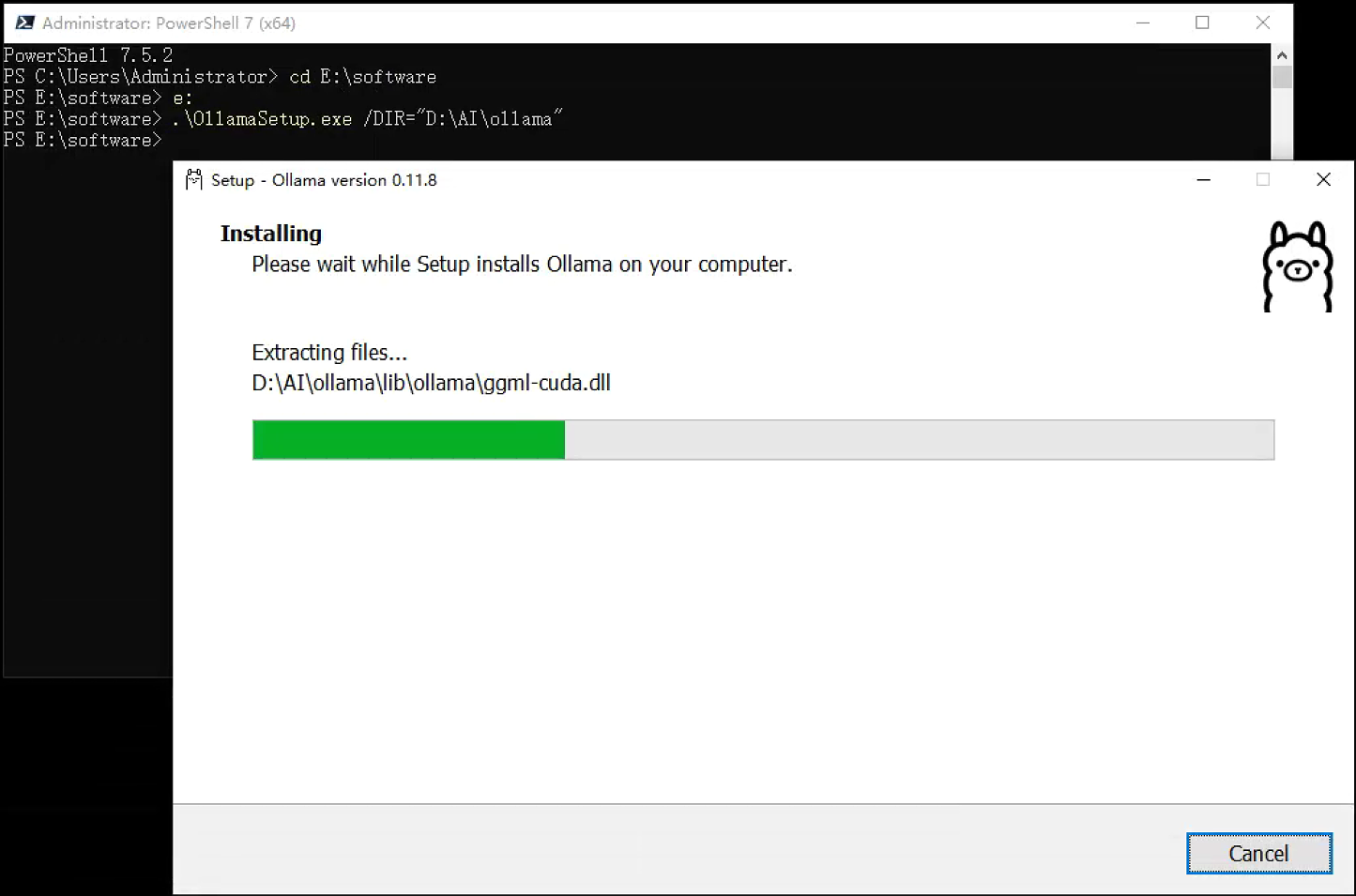
OllamaSetup.exe 直接安装不能修改目录,若需要指定安装目录,使用命令行,用/DIR指定安装位置,命令格式如下:
OllamaSetup.exe /DIR="d:\some\location" 例如,如果你想安装到 D:\AI\Ollama 目录,则在powershell或cmd中执行命令:
OllamaSetup.exe /DIR="D:\AI\Ollama"执行界面如下,启动安装后,安装过程和直接安装相同。
3.3 安装校验
✅ 验证安装是否成功,可以通过查看版本命令:
ollama --version显示版本信息,类似下面执行示例,则表示安装成功。
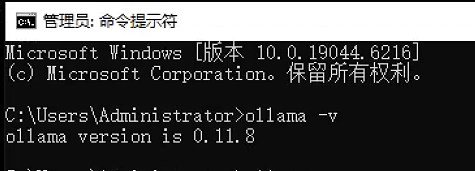
3.4 ollama配置
ollama的配置参数,老版本,通过系统环境变量的方式,进行设置,新版本,部分配置参数支持图形化的配置方式。比如,大模型默认存放位置为C:\Users\<用户名>\.ollama\models,为避免C盘空间不足,需要修改大模型的存储位置,新版本支持图形化界面修改配置,比如11.8及以后的版本,老版本通过修改环境变量的方式,来修改。
➡️3.4.1 ollama新版本,图形化的配置
在ollama桌面程序界面,进入Settings设置界面,或者在运行的ollama图标菜单中,打开settings:
进入设置界面:
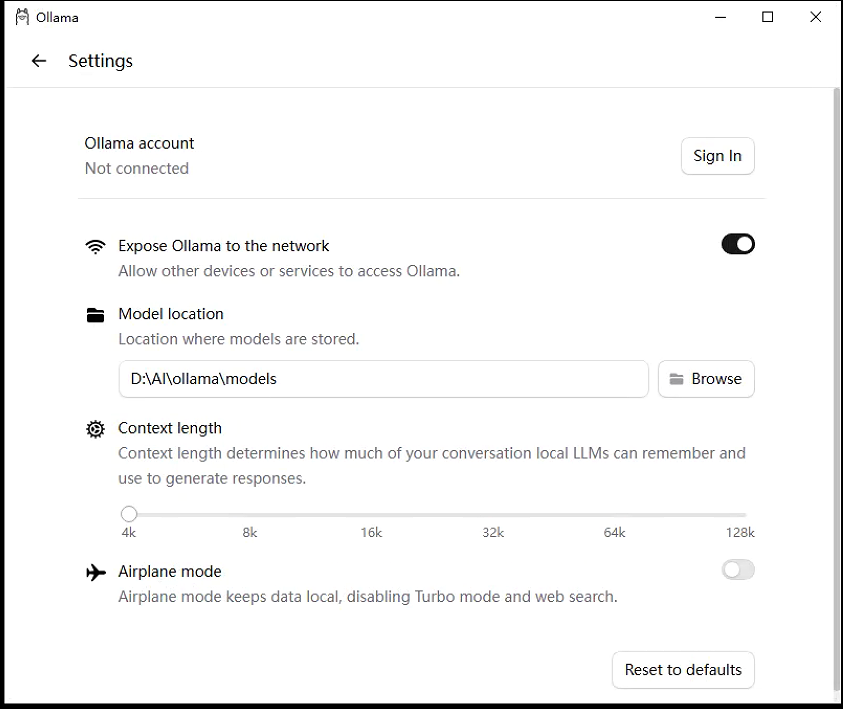
⚙️ 配置项作用:
1. Ollama account(账户)
-
作用:用于登录 Ollama 官方账号,方便同步模型、访问私有模型或使用云端功能。
-
不登录的影响:本地模型依然可用,但无法直接从 Ollama 官方库拉取需要授权的模型。
-
进阶建议:如果你只做本地部署且模型来源是离线文件或国内镜像,可以不登录,减少外网依赖。
2. Expose Ollama to the network(向网络暴露 Ollama)
-
作用:允许局域网或其他设备通过 HTTP API 访问你的 Ollama 服务。
-
关闭状态:仅本机
127.0.0.1可访问,外部设备无法调用。 -
开启状态:会监听
0.0.0.0:<端口>,局域网内其他设备可通过http://<你的IP>:11434调用 API。 -
安全建议:
-
如果开启,建议配合防火墙或反向代理(如 Nginx)限制来源 IP。
-
可结合环境变量
OLLAMA_HOST=0.0.0.0与OLLAMA_ORIGINS控制访问范围。
-
3. Model location(模型存储位置)
-
作用:指定本地模型文件的存放目录。
-
默认:通常在
C:\Users\<用户名>\.ollama\models。 -
修改理由:
-
避免占用系统盘空间(尤其是模型文件动辄数 GB)。
-
方便集中管理和备份模型。
-
-
进阶建议:
-
在 Windows 环境变量中设置
OLLAMA_MODELS,可让 CLI 和服务端一致使用该路径。 -
powershell设置环境变量的命令如下:
setx OLLAMA_MODELS "D:\AI\ollama\models" /M
-
4. Context length(上下文长度)
-
作用:决定本地 LLM 在生成回答时能“记住”的对话历史长度(token 数)。
-
范围:4k ~ 128k(具体取决于模型支持的最大上下文)。
-
影响:
-
长上下文:能处理更长的对话或文档,但显存/内存占用更高,推理速度可能下降。
-
短上下文:占用资源少,但可能遗忘较早的对话内容。
-
-
优化建议:
-
在显存/内存有限的机器上,建议根据任务需求调节,比如 8k~16k 对话任务足够。
-
对于长文档问答,可临时调高到 32k+。
-
5. Airplane mode(飞行模式)
-
作用:完全本地化运行,禁止 Ollama 访问外网。
-
开启效果:
-
禁用 Turbo 模式(云端加速)
-
禁用 Web 搜索功能
-
仅能使用本地已有模型
-
-
适用场景:
-
内网/离线环境
-
数据安全要求高的场合
-
-
注意:开启后无法直接在线拉取模型,需要手动下载
.gguf模型文件并放入模型目录。
➡️3.4.2 配置环境变量
💡3.4.2.1 需要配置系统环境的场景
通过系统环境变量,来配置ollama的系统参数,适用于以下情况:
- 老版本没有图形化配置项
- 图形化配置界面,未包含的参数项
- 桌面程序和CLI(Command Line Interface)模式保持一致
🧩3.4.2.2 系统环境变量设置方式:
- 🪐图形化配置方法:
-
右键"此电脑" → 属性 → 高级系统设置 → 环境变量
-
在"用户变量"或"系统变量"中新建上述变量
-
重启Ollama
-
- 🗺️powershell命令方式:
- 通过setx设置系统环境变量,命令格式示例如下:
setx OLLAMA_MODELS "D:\AI\ollama\models" /M📜3.4.2.3 ollama环境变量列表
ollama支持的环境变量及作用见下表:
| 环境变量 | 说明 | 推荐值 |
|---|---|---|
OLLAMA_MODELS |
模型文件存储目录(避免使用C盘) | D:\ollama\models |
OLLAMA_HOST |
服务监听地址(如需局域网访问改为0.0.0.0) |
127.0.0.1 |
OLLAMA_PORT |
服务监听端口(端口冲突时修改) | 11434 |
OLLAMA_ORIGINS |
HTTP请求来源控制(本地使用可设为*) |
* |
OLLAMA_KEEP_ALIVE |
模型在内存中的保持时间(提高访问速度) | 24h |
OLLAMA_NUM_PARALLEL |
请求处理的并发数量 | 根据实际需求调整 |
OLLAMA_MAX_QUEUE |
请求队列长度 | 512 |
OLLAMA_DEBUG |
输出Debug日志(排查问题时启用) | 1 |
OLLAMA_MAX_LOADED_MODELS |
最多同时加载到内存中的模型数量 | 1 |
四、独立 CLI安装
“独立 CLI” 就是一个便携版的 Ollama 命令行工具,你可以把它放在任何目录运行,甚至打包进自己的应用,Ollama 作为服务安装或集成,而不必安装完整的 Ollama 桌面版。
-
独立 CLI:下载
ollama-windows-amd64.zip压缩包,里面只包含:-
ollama.exe命令行工具 -
NVIDIA / AMD GPU 所需的运行库
-
没有 GUI、没有自动更新器
-
-
用途:
-
可以直接解压运行,不需要安装过程,也不需要管理员权限
-
方便将 Ollama 嵌入到已有应用程序中(例如你的服务、脚本、容器环境)
-
可以用
ollama serve等命令将它作为系统服务运行(比如用 NSSM 注册) -
更适合服务器部署、自动化脚本调用、跨平台打包等场景
-
4.1. 下载
⏬ollama-windows-amd64.zip,下载渠道:
- 国内镜像:https://www.newbe.pro/Mirrors/Mirrors-ollama
- github官方地址
-
打开 Ollama 官方 Release 页面:👉 https://github.com/ollama/ollama/releases
-
找到最新版本,在 Assets 里下载:
-
ollama-windows-amd64.zip(大部分人用这个) -
ollama-windows-amd64-rocm.zip(仅限 AMD GPU 用户,需要 ROCm 驱动) -
-
-
4.2 文件结构
下载完成后,解压到你喜欢的目录,比如:C:\Ollama\
解压后目录结构大概是:
C:\Ollama\
├─ ollama.exe
└─ lib\
└─vc_redist.x64.exe
📜
备注:
vc_redist.x64.exe是 Microsoft Visual C++ 运行时库(Redistributable)64 位版本 的安装包。Ollama 的ollama.exe是用 C++ 编译的,并且依赖 VC++ 运行库。如果系统缺少这些运行库,直接运行ollama.exe可能会报错或无法启动。因此,ollama-windows-amd64.zip里附带了vc_redist.x64.exe,方便你在目标机器上先安装运行库,确保 Ollama 能正常工作。
4.3 配置环境变量
为了能在任何路径直接运行 ollama 命令,将ollama.exe路径加入系统path参数中:
-
右键 “此电脑” → 属性 → 高级系统设置。
-
点击 环境变量 → 在 “系统变量” 找到
Path→ 编辑。 -
添加
C:\Ollama\路径。 -
打开新的 PowerShell 或 CMD,输入:
ollama
如果显示帮助信息,就说明配置成功。
4.4.其他环境变量修改
和上一章《普通安装》中的配置环境变量的方式一致,不再重复。
4.5 运行服务
在 PowerShell 或 CMD 中执行,运行服务命令:
ollama serve
如果看到 Listening on 0.0.0.0:11434,说明服务已启动,也可以通过浏览器访问,显示类似下面界面:
4.6 注册为 Windows 系统服务
使用 sc 命令,注册为Windows系统服务,这样 Ollama 会随系统启动并在后台运行。
powershell或CMD执行命令:
sc create OllamaService binPath= "D:\Ollama\ollama.exe serve" start= auto
sc description OllamaService "Ollama LLM Service"
sc start OllamaService📒参考知识:
sc(Service Control)命令是 Windows 系统自带的命令行工具,它的主要作用是通过命令行与 服务控制管理器(SCM) 交互,用来管理系统服务,包括:
创建服务(
sc create)启动/停止服务(
sc start/sc stop)配置服务启动类型(
sc config)查询服务状态(
sc query)删除服务(
sc delete)
4.7 总结
独立CLI安装,处了没有图形化交换界面,其他功能和普通安装,没有区别。
第三课:ollama安装大模型的方式汇总
Ollama 作为一个开源的本地大模型运行框架,提供了多种灵活的模型获取方式。Ollama 支持从以下五大渠道获取大模型:
1. Ollama 官方仓库(最常用)
-
官方仓库包含的大模型,使用这种方式
-
最直接的下载方式,包含经过优化的主流模型
2. HuggingFace (HF) 平台
-
全球最大的开源模型托管平台
-
支持 GGUF 格式模型的直接导入
3. 魔搭社区 (ModelScope)
-
阿里云提供的国内模型托管平台
-
下载速度较快,适合国内用户
4. 本地文件导入
-
支持 GGUF、PyTorch、Safetensors 三种格式
-
可从第三方下载后离线导入
5. 国内镜像站
-
HF-Mirror 等镜像站点
-
解决国内访问限制问题
下面分别来详细看一下各种方式的具体操作。
一、大模型的选择
根据硬件配置选择合适的模型:
-
8GB显存:选择7B或8B版本模型(如
llama3:8b、deepseek-coder:7b) -
12GB+显存:可尝试14B版本模型(如
llama3:14b) -
高端显卡(3090/4090):可运行32B或更大模型
-
纯CPU环境:选择0.5B或1.5B小模型(如
qwen2:0.5b)
📖参考DeepSeek-r1 相关版本及系统建议列表:
参数版本 模型大小 建议CPU 建议内存 建议显存 特点 deepseek-r1:1.5b 1.1GB 4核 4~8G 4GB 轻量级,速度快、普通文本处理 deepseek-r1:7b 4.7G 8核 16G 14GB 性能较好,硬件要求适中 deepseek-r1:8b 4.9GB 8核 16G 14GB 略强于 7b,精度更高 deepseek-r1:14b 9GB 12核 32G 26GB 高性能,擅长复杂任务,如数学推理、代码生成 deepseek-r1:32b 20GB 16核 64G 48GB 专业级,适合高精度任务 deepseek-r1:70b 43GB 32核 128G 140GB 顶级模型,适合大规模计算和高复杂度任务 deepseek-r1:671b 404GB 64核 512G 1342GB 超大规模,性能卓越,推理速度快
二、从 Ollama 官方仓库下载
官方仓库包含的大模型,使用本方式下载安装,这也是最简单便捷的方式。
2.1 查找大模型
官方仓库地址:Ollama Search
,可以浏览搜索,看看是否有自己需要的模型。
打开对应的大模型,可以看到安装此大模型的命令,此命令没有制定版本号,默认是安装last版本(见列表中表示last的版本),如下图:
如果安装其他版本,可以在大模型列表查找,点击“View all”查看所有列表:
点击具体的版本,可以查看该版本的更详细信息,和安装命令:
2.2 下载相关命令
2.2.1. ollama run - 运行模型
功能:拉取(如果不存在)并启动一个与模型的交互式聊天会话。这是最常用的命令。
语法:ollama run [选项] <模型名>:<标签> [提示词]
示例:
# 1. 进入与 llama3 模型的交互式对话
ollama run llama3
# 2. 运行指定版本的模型 (例如 8B 参数的版本)
ollama run llama3:8b
# 3. 非交互模式:直接运行一次提示词并退出
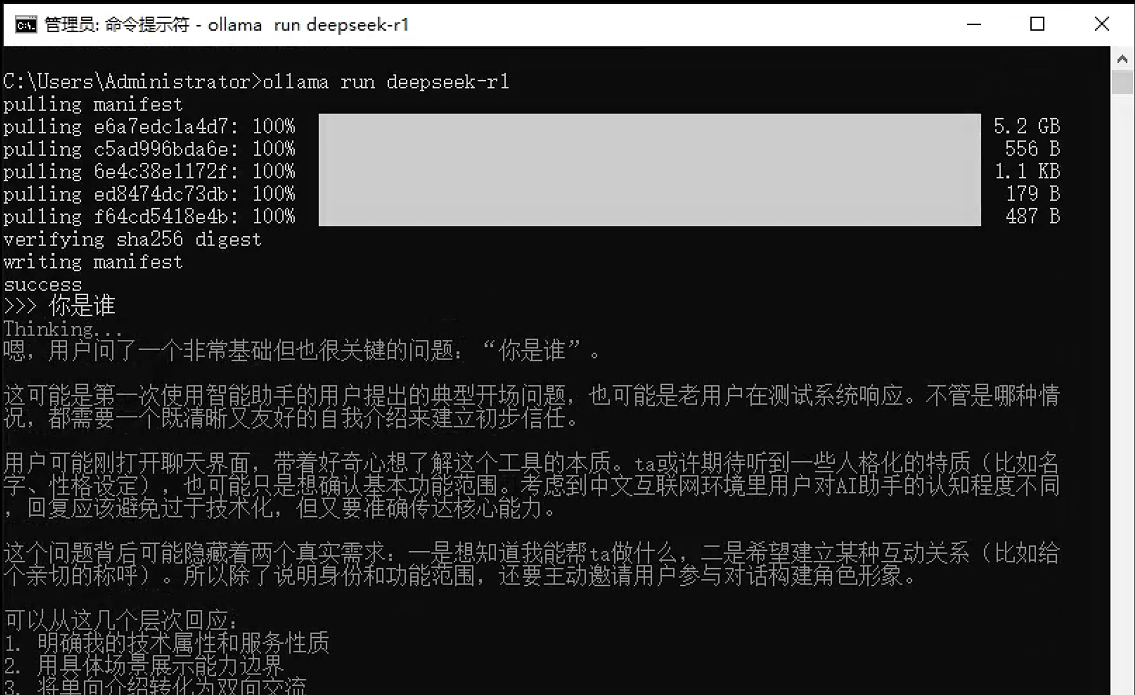
ollama run llama3 "请用中文写一首关于秋天的诗"执行界面参考:
2.2.2. ollama pull - 下载模型
功能:从模型库下载模型到本地,但不立即运行。
语法:ollama pull <模型名>:<标签>
示例:
# 1. 下载默认标签的 llama3 模型(通常是最新或推荐版本)
ollama pull llama3
# 2. 下载指定标签的模型 (例如 70B 参数的 4-bit 量化版本)
ollama pull llama3:70b-text-q4_0
# 3. 下载其他模型,如 Mistral
ollama pull mistral
# 4. 下载中文优化模型
ollama pull qwen2:7b👉说明:pull 是 run 命令的第一步。使用 run 时如果模型不存在会自动调用 pull。
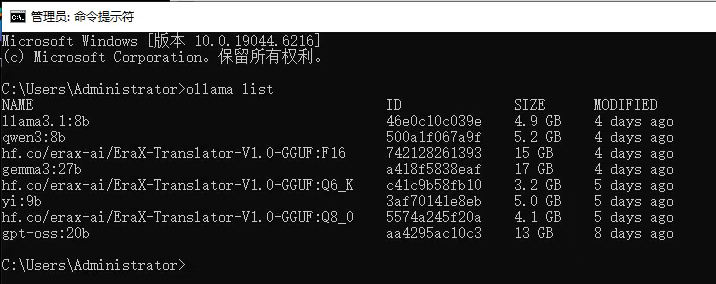
2.2.3. ollama list - 列出模型
功能:显示所有已下载到本地的模型及其详细信息。
语法:ollama list
执行界面参考:
2.2.4 run命令原理
执行ollama run命令,Ollama 会按顺序执行以下一系列操作:
-
检查模型是否存在:
-
首先,Ollama 会在你的本地模型库(通常是
~/.ollama/models目录)中,根据模型名称,查找是否存在模型文件。 -
如果找到了,则直接加载该模型到内存中。
-
如果没找到,Ollama 会自动执行拉取/下载。
-
-
自动拉取(下载)模型:
-
如果本地没有该模型,Ollama 会自动连接到默认的模型仓库(registry),尝试寻找并下载(pull)模型。
-
这意味着你不需要手动先执行
ollama pull命令,run命令帮你一站式完成了。你会先在屏幕上看到下载进度条。
-
-
加载模型到内存:
-
一旦模型文件就绪(无论是已有的还是新下载的),Ollama 就会将模型加载到你的计算机内存(RAM)和显存(VRAM,如果可用)中。这个过程可能会花费几秒到几十秒,取决于模型大小和你的硬件性能。
-
-
启动交互式聊天会话:
-
模型加载成功后,你的终端会变成一个交互式的聊天界面。
-
通常会出现一个
>>>或类似的提示符,等待你输入问题或指令(Prompt)。
-
三、从 HuggingFace 下载
Hugging Face 是一个全球领先的开源 AI 平台,AI工程师通过该平台托管和分享模型,在ollama官方模型仓库找不到的模型,可以在这里找到。
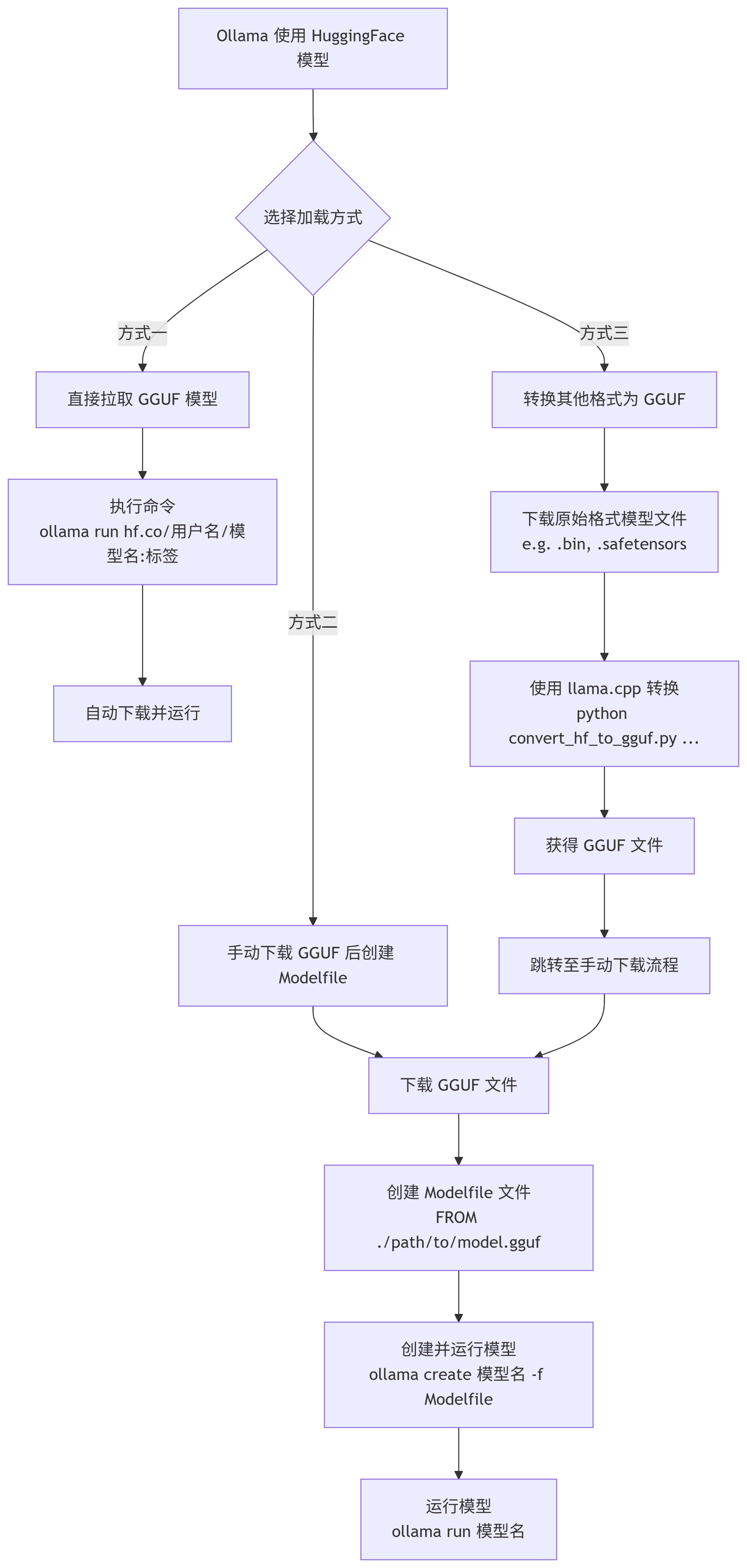
Ollama 从 Hugging Face 获取模型并加载运行,主要有以下三种方式:
| 方式特点 | 直接拉取 GGUF 模型 | 手动下载 GGUF 后创建 Modelfile | 转换其他格式为 GGUF 后创建 Modelfile |
|---|---|---|---|
| 核心操作 | 使用 ollama run 指定 Hugging Face 模型路径 |
从 Hugging Face 下载 GGUF 文件,编写 Modelfile 指向它 | 下载原始格式模型,用 llama.cpp 转换,再创建 Modelfile |
| 优点 | 最简单直接,无需手动管理文件 | 过程清晰,可离线使用,便于管理 | 支持更多 Hugging Face 上的模型格式 |
| 缺点 | 需确认模型支持,且网络需能访问 Hugging Face | 需手动查找、下载模型文件和编写配置文件 | 步骤最繁琐,需依赖转换工具和环境 |
| 适用场景 | 想快速尝试,且模型明确支持此方式 | 希望控制模型文件位置,或需要离线部署 |
模型仅有 PyTorch (.bin) 或 Safetensors 格式时 |
下面是每种方法的操作示意:
具体操作方式,下面分别详细介绍。
3.1查找大模型
模型列表地址:https://huggingface.co/models
🔍搜索推荐:优先查找GGUF 格式的模型,且支持ollama应用的,就是上面讲的第一种安装方式,用ollama命令直接安装;如果有GGUF文件,但没有对ollama应用的支持,则下载GGUF文件,用第二种方式安装;如果模型只提供了Safetensors 格式文件,没有GGUF 格式的,则需下载后对文件进行格式转换,用第三者方式安装。
搜索模型,以“EraX-Translator-V1.0”(一个专注于翻译的开源模型)为例:
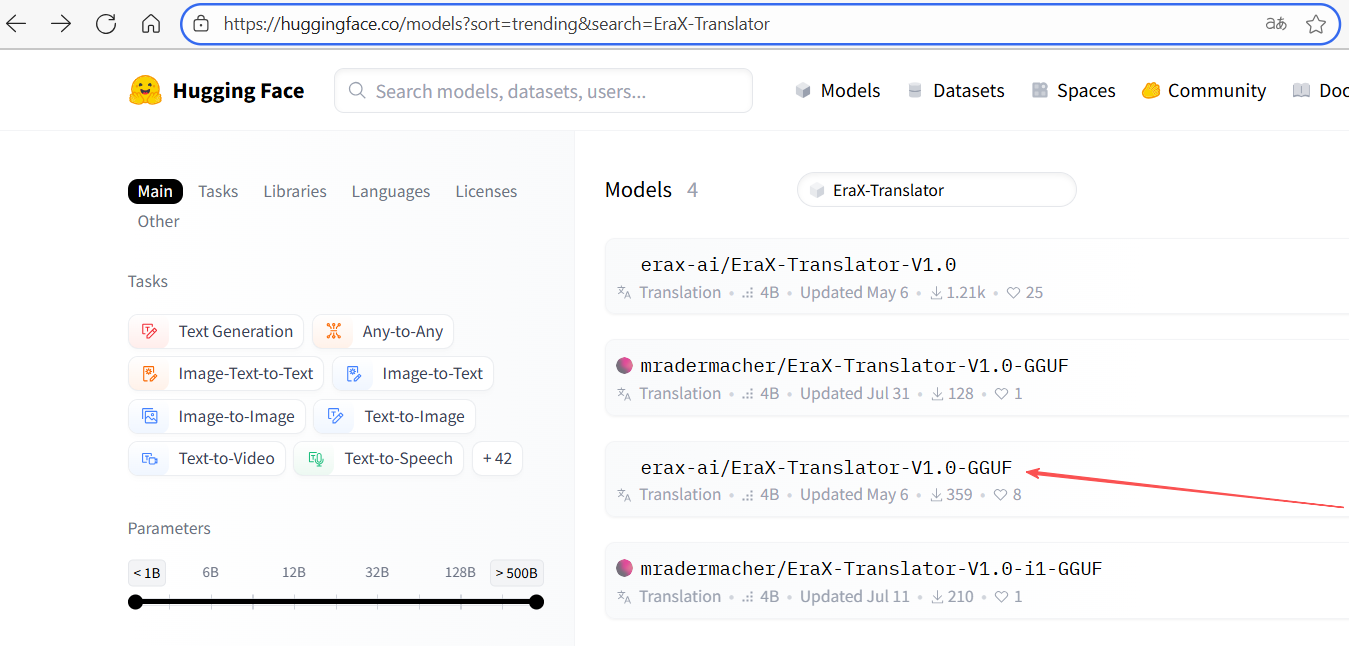
进入模型,文件和版本标签下,可以看到不同版本的GGUF模型文件
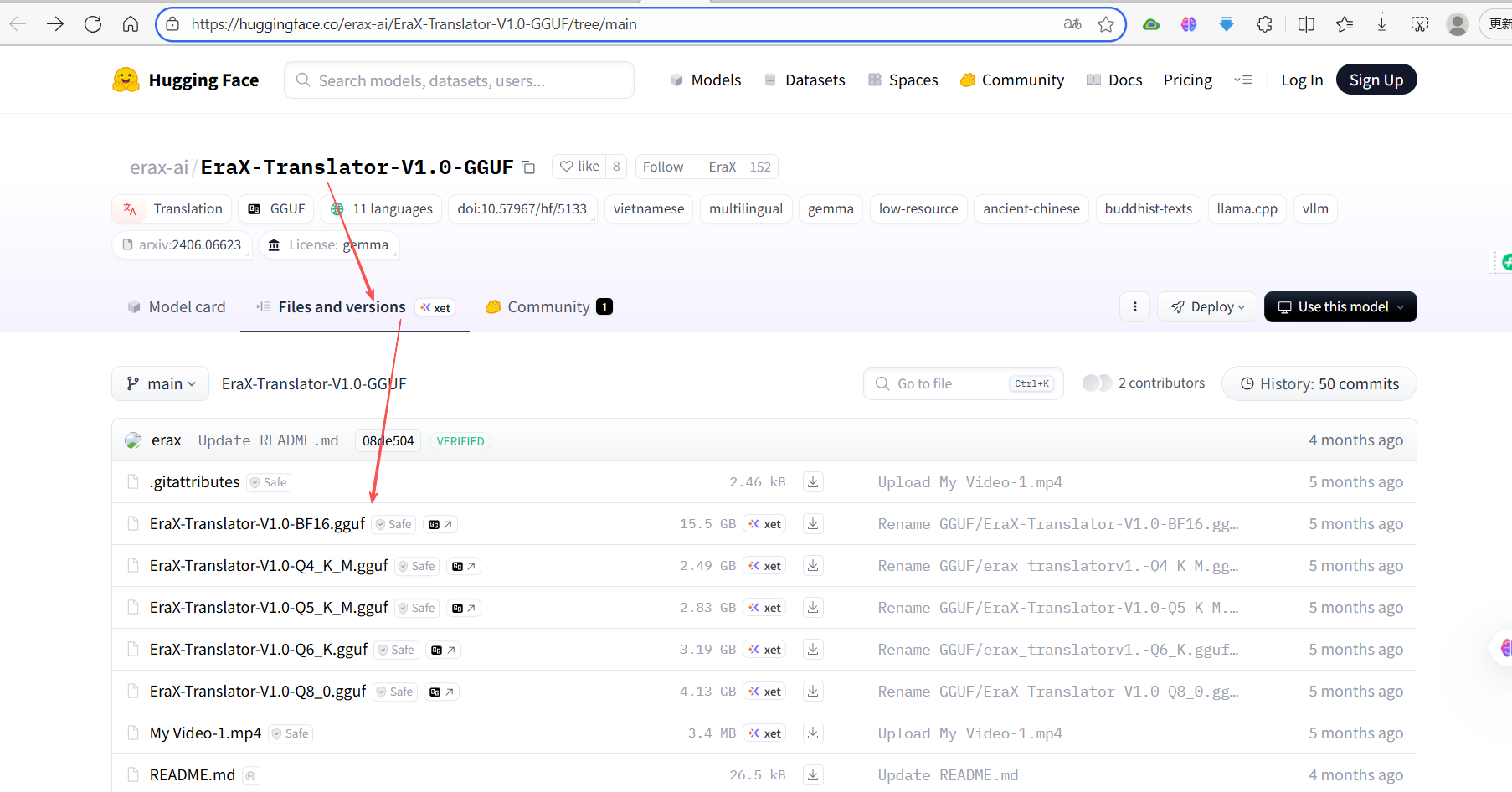
点击相应版本旁的“GG”图标,显示详细内容,“use this model”按钮,显示支持应用列表:
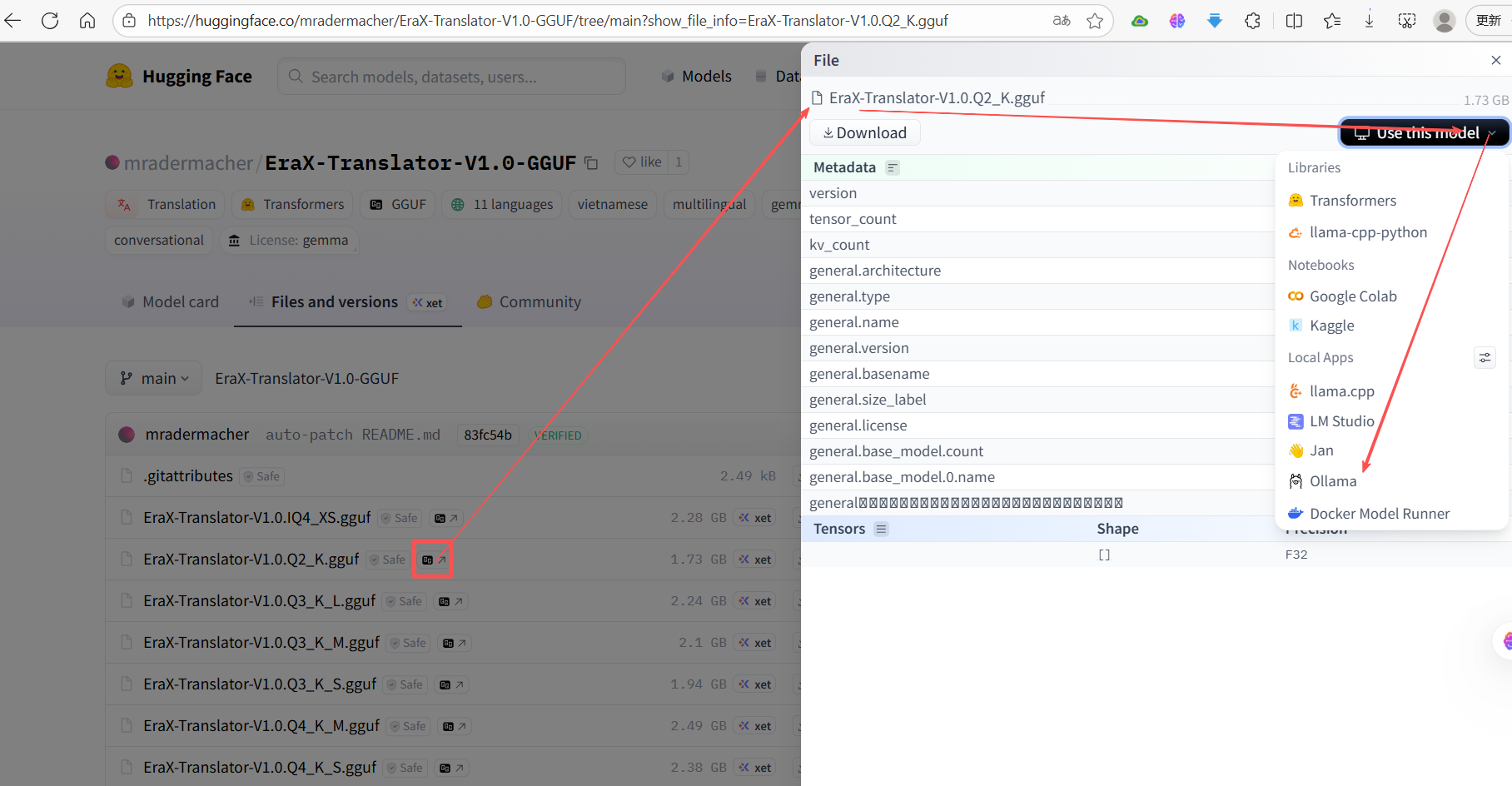
点击具体应用,比如“ollama”,显示具体应用的方式或命令,就可以安装第一种方式安装,示例如下:
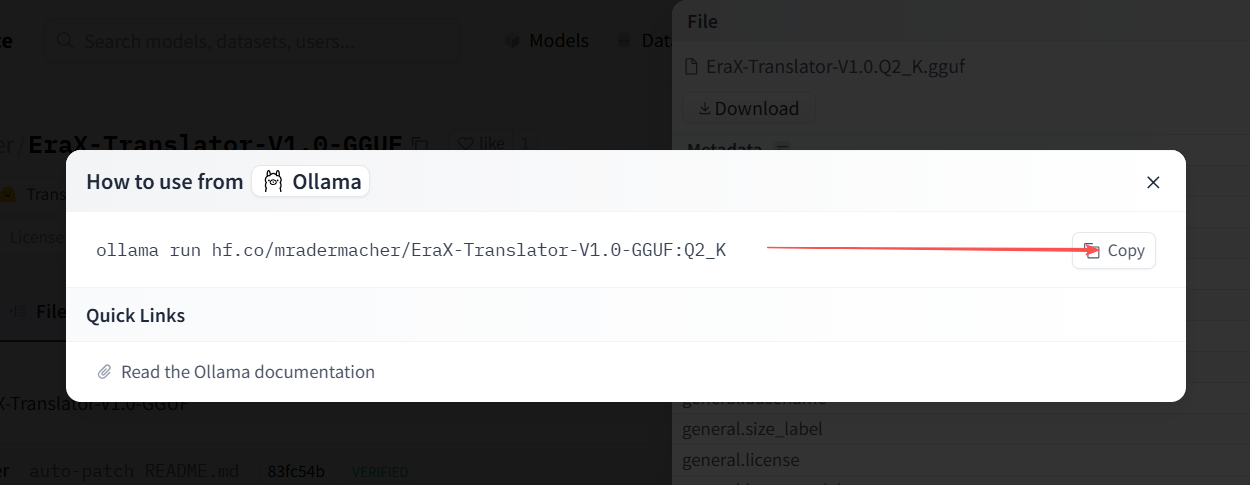
如果没有“use this model”按钮,或没有“ollama”应用,则下载GGUF文件,然后用第二种方式安装:

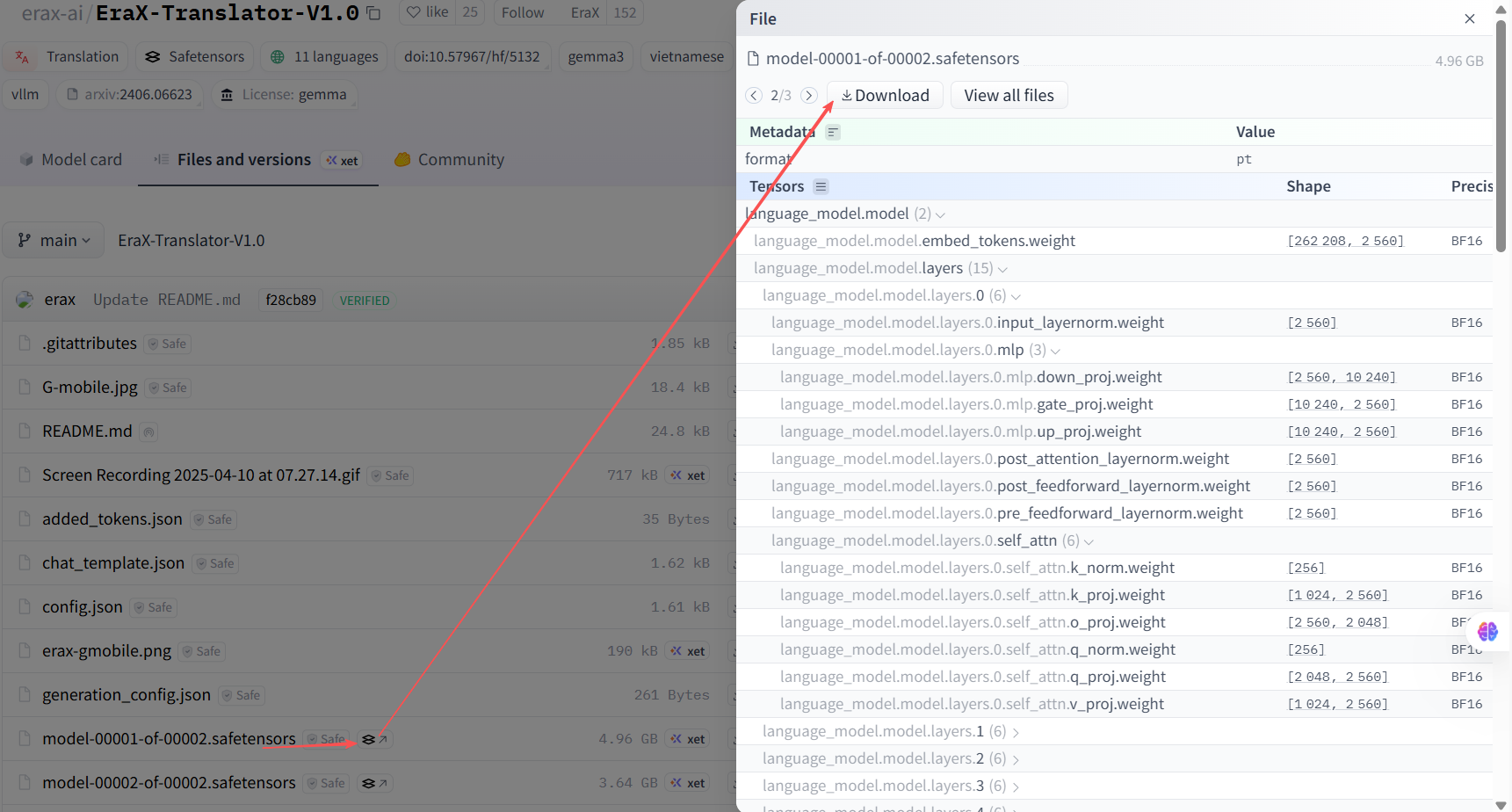
只在文件和版本列表,看到Safetensors 格式文件,下载后,按第三者格式安装。
3.2 方式一:ollama命令直接安装运行 HF 模型
一些 Hugging Face 上的 GGUF 格式模型,可以直接使用 ollama run 命令指定模型在 Hugging Face 上的路径来拉取和运行25。
操作命令:
ollama run hf.co/<HF用户名>/<模型仓库名>:<标签或量化版本>
参数解释:
-
HF用户名: 模型上传者在 Hugging Face 的用户名或组织名。 -
模型仓库名: 该模型仓库的名称。 -
标签或量化版本: 可选,指定要下载的模型版本或量化级别(如Q4_K_M)。若不指定,通常默认为latest。
使用示例:
# 拉取一个指定量化版本的模型
ollama run hf.co/erax-ai/EraX-Translator-V1.0-GGUF:Q8_0
# 如果国内网络访问慢,可尝试将 hf.co 替换为 hf-mirror.com
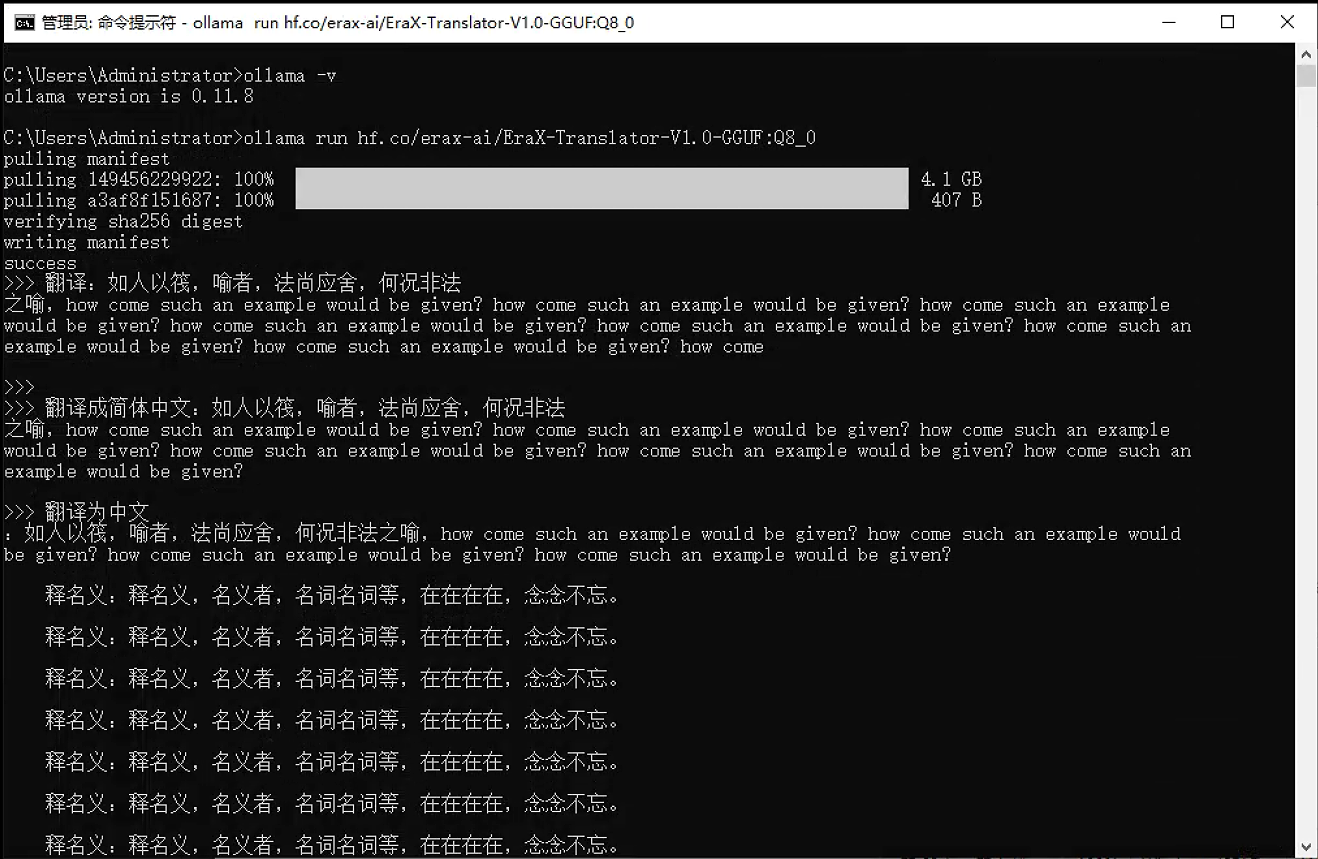
ollama run hf-mirror.com/erax-ai/EraX-Translator-V1.0-GGUF:Q8_0执行界面参考:
镜像下载执行界面参考:

3.3 方式二:手动下载 GGUF 文件后通过 Modelfile 加载
参考后续章节:本地模型导入方法-GGUF 文件
3.4 方式三:转换其他格式模型为GGUF后再加载
参考后续章节:本地模型导入方法-其他格式
四、从魔搭社区下载
魔搭社区(英文:ModelScope)是由阿里巴巴达摩院于2022年推出的AI大模型开源社区,定位为“模型即服务”(MaaS)平台,魔搭社区提供了国内友好的下载速度。
和Hugging Face 类似,也支持三种下载方式,这里只详细介绍ollama命令直接安装的方式,其他两种通用方式,请参考后面章节:本地模型导入方法-GGUF 文件、本地模型导入方法-其他格式。
4.1 ollama命令直接安装模型
魔搭地址:https://modelscope.cn/models
这种方式最简单,Ollama 会直接处理从魔搭社区下载和配置模型的过程。
-
在魔搭社区寻找模型:
-
在魔搭社区的搜索框中,输入你感兴趣的模型名称,并加上 "GGUF" 关键词进行搜索(例如 "Qwen2.5-7B-Instruct-GGUF" 或 "deepseek r1 gguf")。
-
在模型页面,仔细查看模型的介绍、版本(Tags)和硬件需求,选择适合你电脑配置的版本(如
q4_k_m,q8_0等,量化等级越低,模型体积越小,对硬件要求也越低,但精度也可能有所下降)。
-
-
构建拉取命令:
-
在模型页面的地址栏中,你会看到类似
https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct-GGUF的URL。 -
提取
/Qwen/Qwen2.5-7B-Instruct-GGUF这一部分。
-
将其与魔搭社区的域名组合,形成完整的模型名称:
modelscope.cn/Qwen/Qwen2.5-7B-Instruct-GGUF。 -
如果想拉取特定版本(Tag),可以在后面加上冒号和标签名,例如
modelscope.cn/Qwen/Qwen2.5-7B-Instruct-GGUF:qwen2.5-7b-instruct-q8_0.gguf10。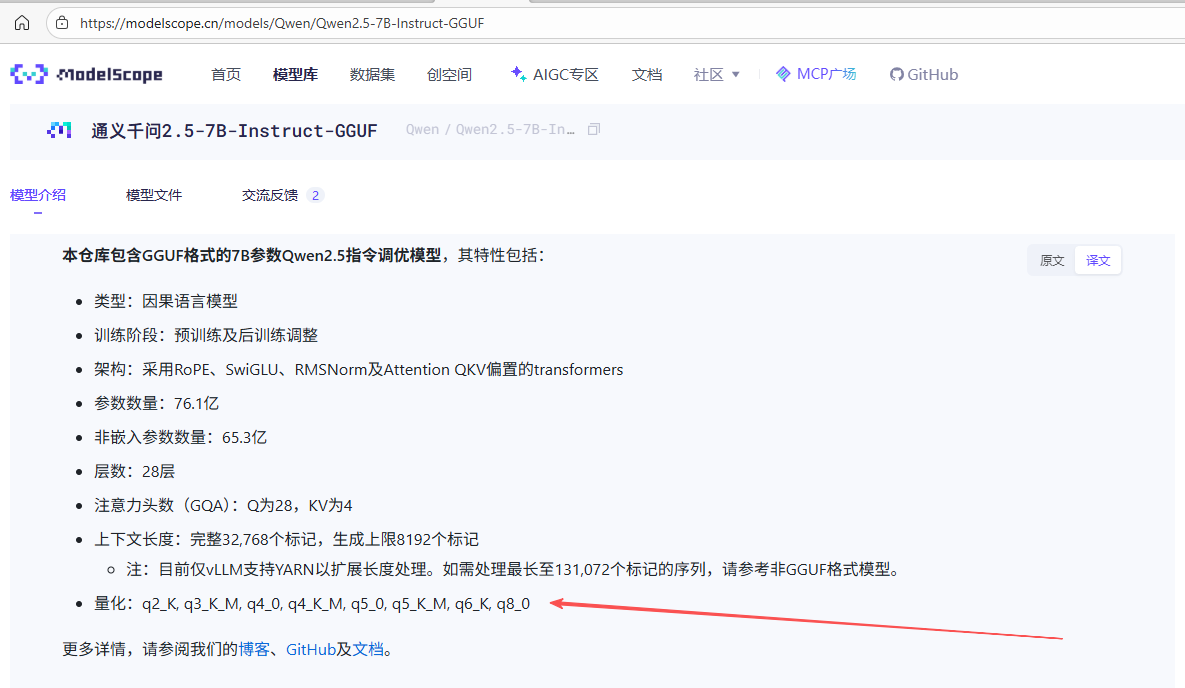
-
-
拉取并运行模型:
-
打开终端(Windows 可用 PowerShell 或 CMD,Linux/macOS 用 Terminal),执行以下命令(将
<模型名称>替换为你上一步构建的字符串):ollama run <模型名称># 运行 Qwen2.5-7B-Instruct-GGUF 模型 ollama run modelscope.cn/Qwen/Qwen2.5-7B-Instruct-GGUF # 运行特定量化版本的 DeepSeek R1 模型 ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:DeepSeek-R1-Distill-Qwen-32B-Q6_K.gguf # 运行一个较小的模型,适合资源有限的设备 ollama run modelscope.cn/Qwen/Qwen2.5-1.5B-Instruct-GGUF:qwen2.5-1.5b-instruct-q4_k_m.gguf执行界面参考:

-
下载完成后,会自动进入交互对话界面。
-
五、本地模型导入方法-GGUF 文件
这是最常见且可控的通用方式。
操作步骤:
-
下载GGUF模型文件:
如在Hugging Face模型页面的"Files and versions"中(或镜像网站),找到所需的GGUF文件(如OuteAI/OuteTTS-0.2-500M-GGUF, -
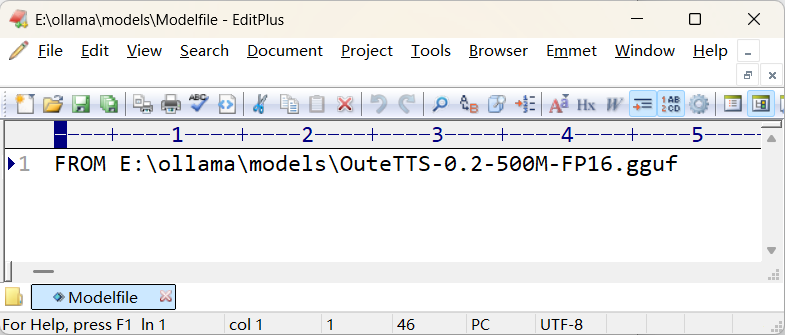
创建Modelfile:
创建一个名为Modelfile(或任何你喜欢的名字,如my-model.txt) 的文本文件。文件内容最基本的格式如下:FROM /absolute/path/to/your/model.gguf其中,
/absolute/path/to/your/model.gguf要替换为你刚下载的GGUF文件的绝对路径(或相对于Modelfile位置的路径)。执行界面参考:
📒参考:Modelfile 高级配置示例
FROM "D:\ollama\Llama3-8B-Chinese-Chat.q6_k.GGUF" # 模型文件路径 PARAMETER temperature 0.7 # 控制输出随机性:较低更确定,较高更随机 PARAMETER num_ctx 4096 # 设置上下文窗口大小 SYSTEM "你是一个乐于助人的AI助手,请用中文回答所有问题。" # 系统指令,定义模型角色 TEMPLATE """{{- if .System }}<|im_start|>system {{ .System }}<|im_end|>{{- end }}{{- if .Prompt }}<|im_start|>user{{ .Prompt }}<|im_end|>{{- end }}<|im_start|>assistant""" # 对话模板 PARAMETER stop "<|im_start|>" # 停止生成标记 PARAMETER stop "<|im_end|>" # 停止生成标记 -
创建并运行Ollama模型:
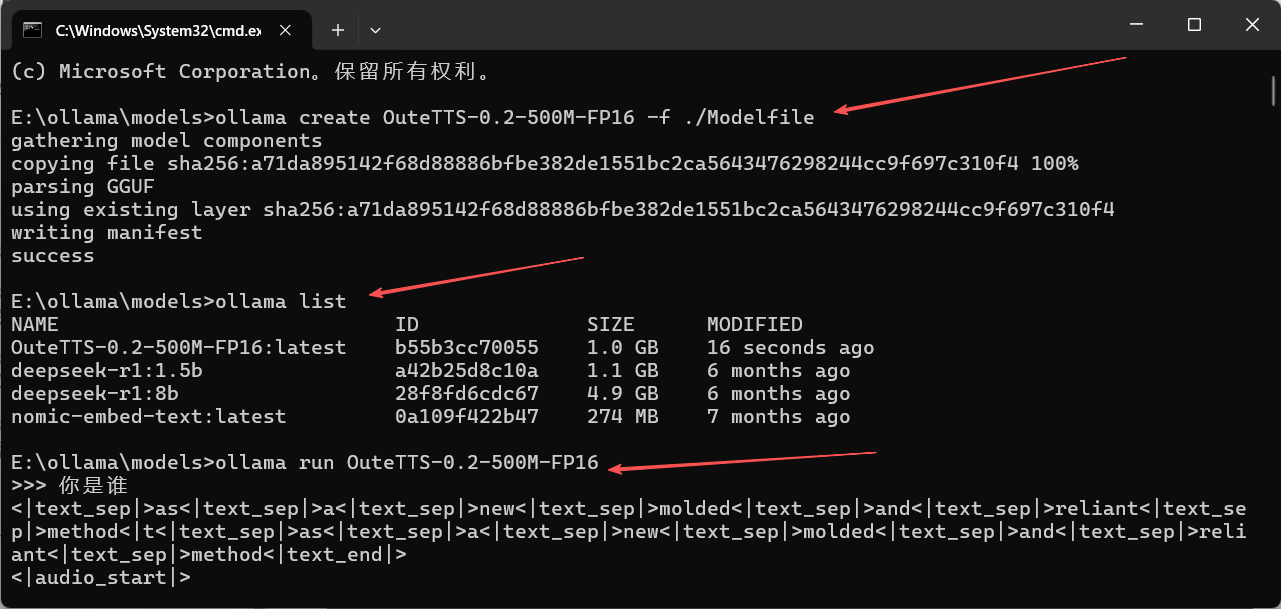
打开命令行,切换到Modelfile所在目录,运行:ollama create your-model-name -f ./Modelfileyour-model-name是你为这个模型取的名字(如my-llama3)。创建成功后,即可运行:ollama run your-model-name示例命令:
ollama create OuteTTS-0.2-500M-FP16 -f ./Modelfile ollama run OuteTTS-0.2-500M-FP16执行界面参考:
六、本地模型导入方法-其他格式
如果模型只有 PyTorch (.bin) 或 Safetensors (.safetensors)格式,你需要先将它们转换为GGUF格式。
操作步骤:
-
安装转换工具
llama.cpp:git clone https://github.com/ggerganov/llama.cpp cd llama.cpp pip install -r requirements.txt # 安装Python依赖 -
下载原始模型文件:
从Hugging Face下载所需模型的全部文件(如pytorch_model-00001-of-00002.bin,config.json,tokenizer.json等)。 -
转换格式:
使用llama.cpp内的convert_hf_to_gguf.py脚本进行转换:# 示例 python convert_hf_to_gguf.py /path/to/downloaded/model --outtype f16 --outfile /output/path/converted-model.gguf将
/path/to/downloaded/model替换为下载的原始模型文件所在目录,/output/path/converted-model.gguf替换为你期望输出的GGUF文件路径和文件名。 -
创建并运行Ollama模型:
得到GGUF文件后,操作就与方式二一样了。
七、附录:国内镜像站加速
7.1 HF-Mirror 镜像站
可以通过国内镜像站加速下载:
# 使用 HF 镜像站
ollama run hf-mirror.com/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF:Q4_K_M
# 使用 huggingface-cli 工具下载
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download Qwen/QwQ-32B --local-dir ./model/qwq-32b7.2 DaoCloud 加速镜像
使用 DaoCloud 提供的 Ollama 镜像服务:
# 原始命令
ollama run deepseek-r1:1.5b
# 使用加速源
ollama run ollama.m.daocloud.io/library/deepseek-r1:1.5b第四课:🐑 Ollama 命令汇总
Ollama 的命令行界面(CLI)设计简洁但功能强大,大概分为三类:
- 核心命令
- 模型管理命令
- 高级与系统命令
另外,在命令之后,增加了环境变量配置、故障排除与技巧两个内容。
一、核心命令
这些是你最常用的命令,用于与模型交互。
1. ollama run - 运行模型
功能:拉取(如果不存在)并启动一个与模型的交互式聊天会话。这是最常用的命令。
语法:ollama run [选项] <模型名>:<标签> [提示词]
选项:
-
无特定选项,但支持通用全局选项(如
--verbose)。
示例:
# 1. 进入与 llama3 模型的交互式对话
ollama run llama3
# 2. 运行指定版本的模型 (例如 8B 参数的版本)
ollama run llama3:8b
# 3. 非交互模式:直接运行一次提示词并退出
ollama run llama3 "请用中文写一首关于秋天的诗"执行界面参考:
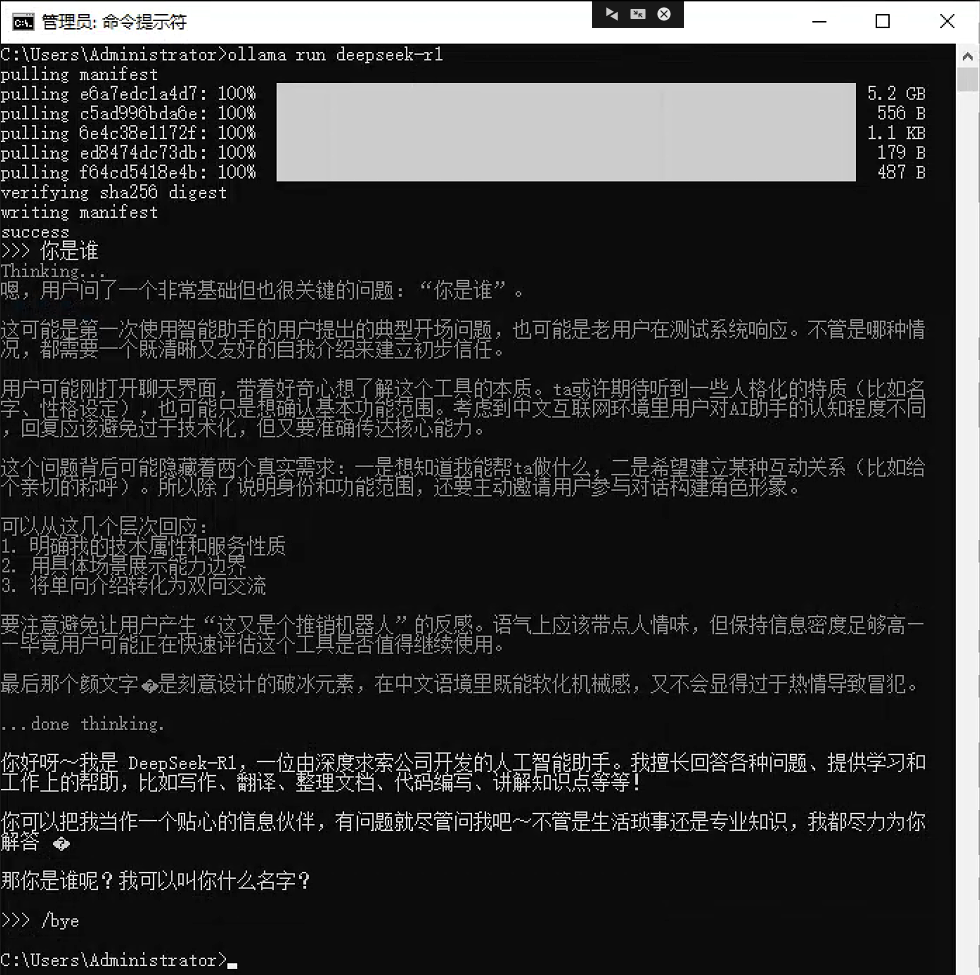
说明:在交互模式中,输入 /bye、/exit 或按下 Ctrl+D 退出。Ollama 会自动维护多轮对话的上下文。
2. ollama pull - 下载模型
功能:从模型库下载模型到本地,但不立即运行,同时具有重新下载模型的作用。
语法:ollama pull <模型名>:<标签>
示例:
# 1. 下载默认标签的 llama3 模型(通常是最新或推荐版本)
ollama pull llama3
# 2. 下载指定标签的模型 (例如 70B 参数的 4-bit 量化版本)
ollama pull llama3:70b-text-q4_0
# 3. 下载其他模型,如 Mistral
ollama pull mistral
# 4. 下载中文优化模型
ollama pull qwen2:7b📜说明:pull 是 run 命令的第一步。使用 run 时如果模型不存在会自动调用 pull。
执行界面参考:
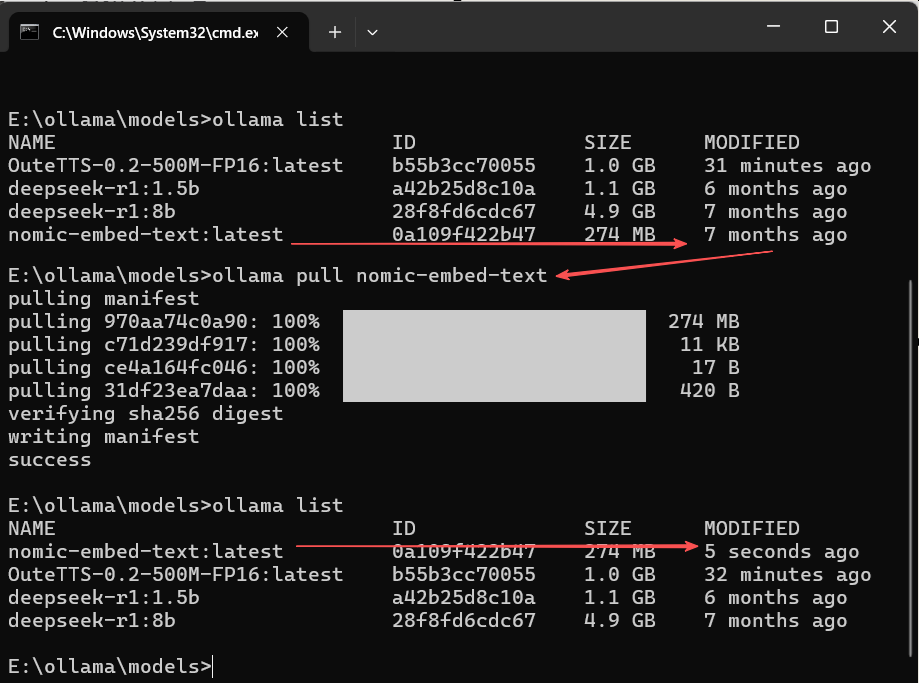
📜说明:pull 可以用于重新下载模型。
3. ollama list - 列出模型
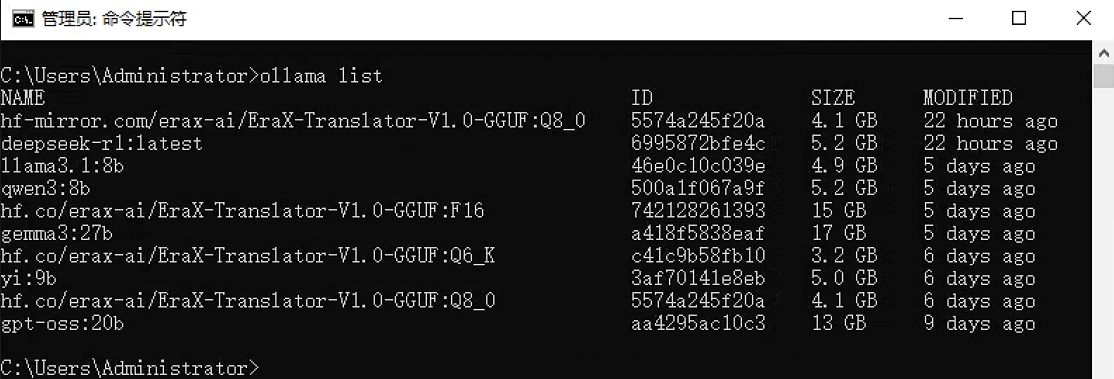
功能:显示所有已下载到本地的模型及其详细信息。
语法:ollama list
执行界面参考:
4. ollama rm - 删除模型
功能:从本地存储中删除一个模型,释放磁盘空间。
语法:ollama rm <模型名>:<标签>
示例:
# 删除指定版本的模型
ollama rm mistral:7b
# 删除默认标签的模型
ollama rm codellama执行界面参考:
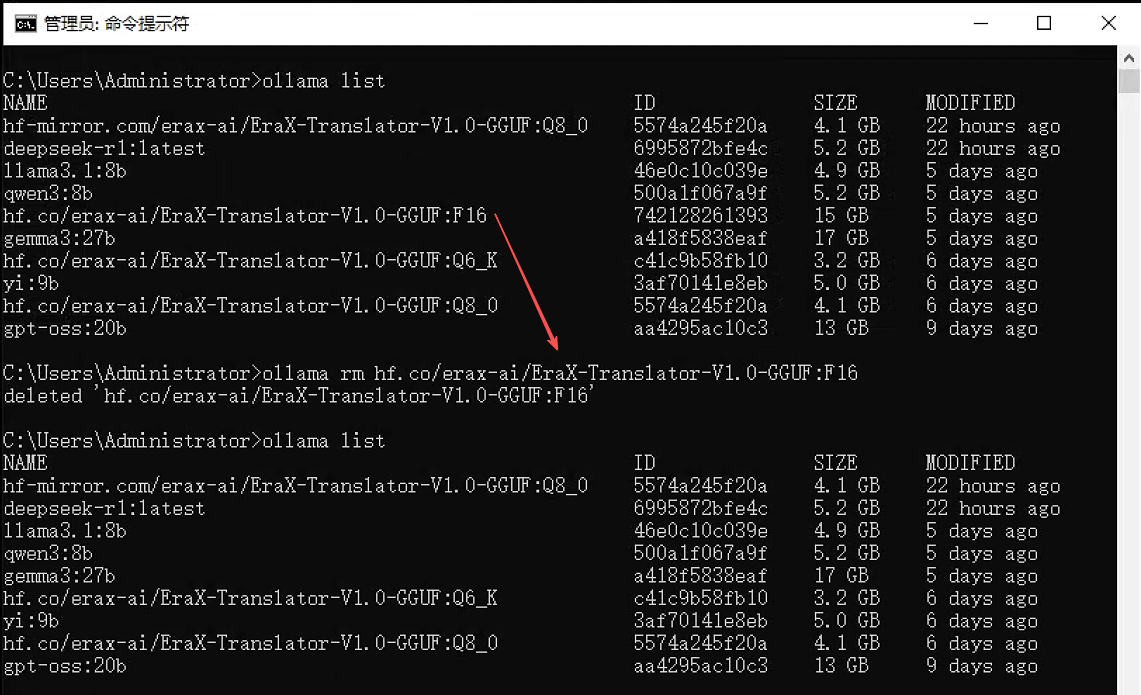
注意:删除操作不可逆,请谨慎执行。
5. ollama cp - 复制模型
功能:创建一个已有模型的副本,并赋予新的名称。
语法:ollama cp <源模型名>:<标签> <目标模型名>
示例:
# 将 llama3 复制为一个名为 my-llama 的新模型
ollama cp llama3 my-llama用途:常用于创建模型的基础副本,以便后续使用 ollama create 进行自定义。
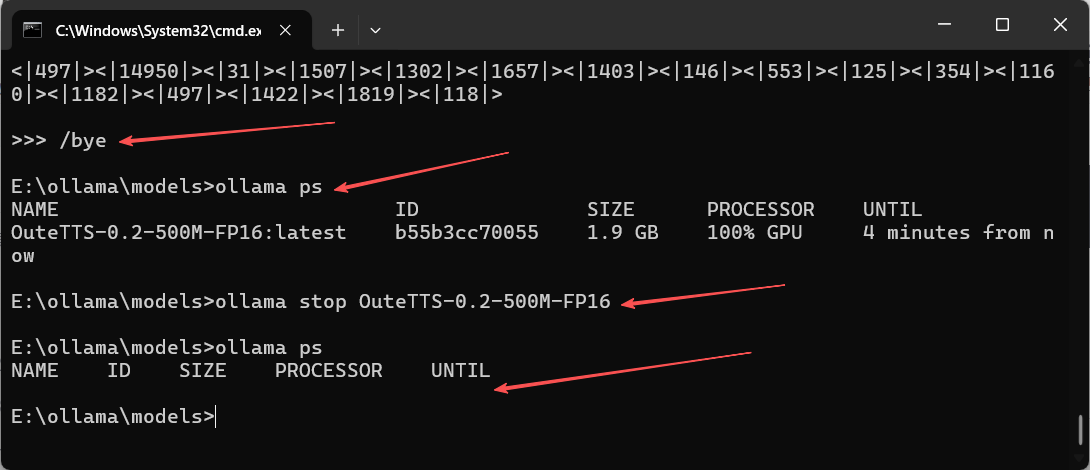
6. ollama stop - 停止特定模型
功能:/bye等,只是退出模型交互,ollama stop可以停止运行的指定模型。
语法:ollama stop [选项] <模型名称或ID>
示例:
# 使用模型名称停止 (最常见)
ollama stop deepseek-r1:1.5b
# 使用模型ID停止 (名称可能重复或过长时更精确)
ollama stop a42b25d8c10a📜注:配合 ollama ps 命令,通过ollama ps获取运行的模型名称或模型ID
执行界面参考:
二、模型管理命令
这些命令用于创建和管理自定义模型配置。
7. ollama create - 创建模型
功能:基于一个 Modelfile 创建自定义模型。
语法:ollama create <模型名> -f <Modelfile路径>
示例:
-
1)首先创建一个
Modelfile文件:
# Modelfile 内容示例
FROM llama3
# 设置系统提示词,定义模型角色
PARAMETER temperature 0.8
PARAMETER num_ctx 4096
SYSTEM """
你是一个乐于助人的AI助手,请用中文回答所有问题。
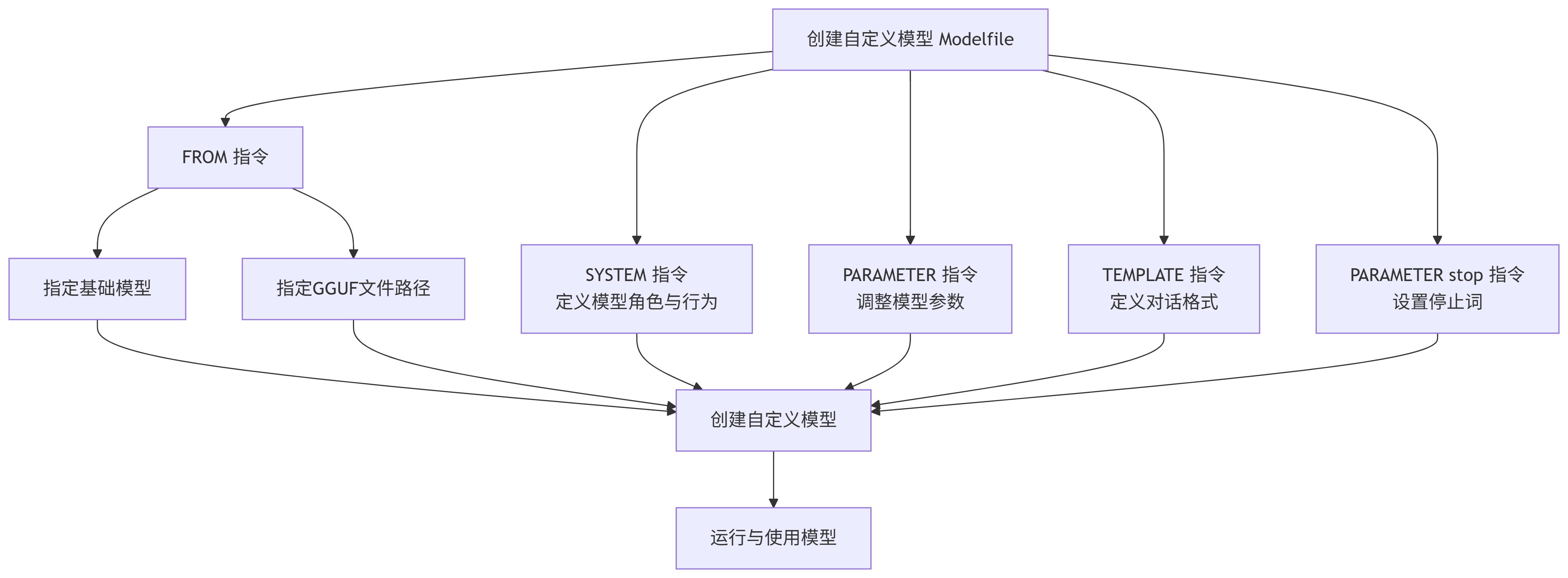
"""📝 Modelfile 核心指令详解
Modelfile 是一个文本文件,它通过一系列的指令来定义模型的行为。以下是其中最常用和最关键的指令:
| 指令 | 是否必需 | 描述与用途 | 示例 |
|---|---|---|---|
| FROM | 是 | 指定基础模型或GGUF模型文件路径 | FROM llama3FROM ./qwen2-7b-q4_k_m.gguf |
| PARAMETER | 否 | 设置模型推理参数,控制生成效果 | PARAMETER temperature 0.7PARAMETER num_ctx 4096 |
| SYSTEM | 否 | 定义系统提示词,设置模型角色、行为准则或上下文 | SYSTEM "你是一个乐于助人的AI助手,请用中文回答所有问题。" |
| TEMPLATE | 否 | 定义模型使用的对话模板,适用于特定模型格式 | TEMPLATE """{{ if .System }}<|im_start|>system\n{{ .System }}<|im_end|>\n{{ end }}""" |
| PARAMETER stop | 否 | 设置停止词,告诉模型生成何时结束 | PARAMETER stop "<|im_end|>"PARAMETER st |
下面是这些指令之间主要关系和流程的示意图:
🔧 关键指令说明
-
FROM指令:这是 Modelfile 中唯一必须的指令。它有两个主要用途:
-
指定基础模型:例如
FROM llama3,这意味着你的自定义模型将基于官方的llama3模型进行构建。你需要确保已经通过ollama pull llama3下载了该基础模型。 -
引用本地GGUF模型文件:例如
FROM ./vicuna-33b.Q4_0.gguf或FROM ./codeqwen-1_5-7b-chat-q8_0.gguf,或者绝对路径 FROM E:\ollama\models\OuteTTS-0.2-500M-FP16.gguf。这允许你直接使用从 Hugging Face 或其他平台下载的 GGUF 格式模型文件。
-
-
PARAMETER指令:常用的参数包括:
-
temperature:控制生成文本的随机性。值越高(如0.8),输出越随机、创造性越强;值越低(如0.2),输出越确定、保守。 -
num_ctx:设置模型上下文窗口的大小(token 数),例如4096。 -
top_p:一种采样策略,通常与 temperature 一起使用。 -
repeat_penalty:惩罚重复的 token,有助于减少生成内容中的重复。
-
-
SYSTEM指令:你可以在这里定义模型的角色、行为准则或知识背景。例如,你可以设置
SYSTEM "你是一位专业的软件开发工程师,擅长Python和Go语言。",这样模型就会在这个语境下回答你的问题。 -
TEMPLATE指令:这个指令通常需要参考模型本身的文档来正确设置。例如,很多 Chat 模型(如 Llama 3)需要特定的模板格式才能正常工作。
-
PARAMETER stop指令:此指令用于定义停止词(stop words),当模型在生成过程中遇到这些词时,便会停止继续生成。这对于控制模型输出的长度和格式非常有用。
🔢复杂Modelfile 文件示例:
# 从本地GGUF文件创建(假设文件在当前目录)
FROM ./llama3.2-1b-instruct-q4_k_m.gguf
# 或者从已拉取的官方模型创建
# FROM llama3.2:1b-instruct
# 设置系统提示词,定义模型角色
SYSTEM """
你是一个幽默的、乐于助人的AI助手,名字叫"小智"。
你总是以有趣的方式和用户交流,并且在回答技术问题时非常准确。
请始终使用中文与用户对话。
"""
# 设置模型参数
PARAMETER temperature 0.8 # 创造性较高
PARAMETER num_ctx 4096 # 上下文窗口大小
# 定义模板和停止词(以Llama 3为例)
TEMPLATE """
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>
"""
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|end_header_id|>"-
2)然后创建模型:
# 从当前目录的 Modelfile 创建模型
ollama create my-chinese-assistant -f ./Modelfile
# 创建后即可像普通模型一样运行
ollama run my-chinese-assistant执行示例及界面参考:
- 在https://huggingface.co/OuteAI/OuteTTS-0.2-500M-GGUF/tree/main下载OuteAI/OuteTTS-0.2-500M-GGUF的文件“OuteTTS-0.2-500M-FP16.gguf”,并放在E:\ollama\models下
- 并在此目录下创建配置文件:
- 执行命令:
ollama create OuteTTS-0.2-500M-FP16 -f ./Modelfile
ollama run OuteTTS-0.2-500M-FP16执行界面如下:
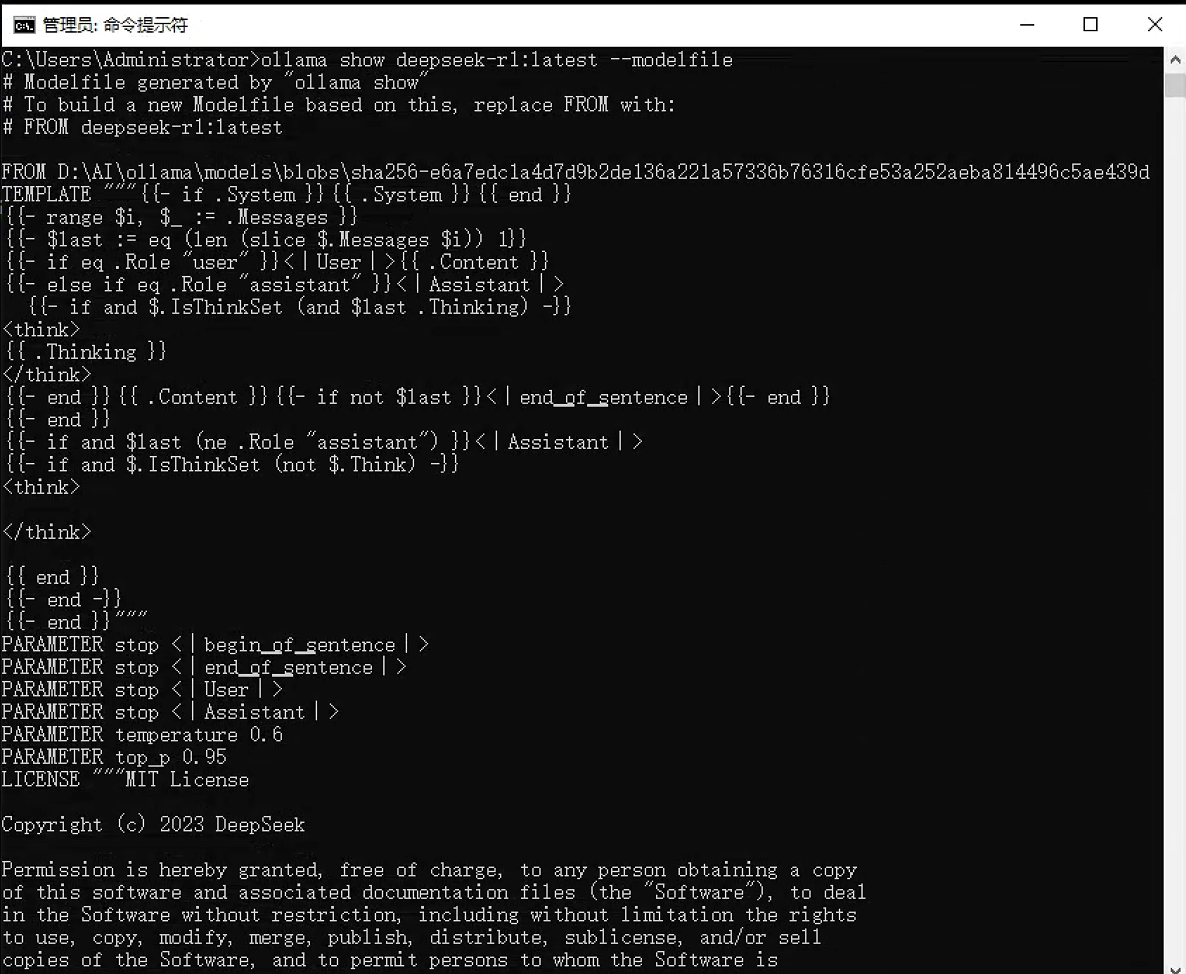
8. ollama show - 显示模型信息
功能:显示模型的详细信息,包括其 Modelfile 内容。
语法:ollama show <模型名> [选项]
选项:
-
--modelfile:显示模型的 Modelfile 内容 -
--parameters:显示模型参数 -
--system:显示系统提示词 -
--template:显示模板 -
--license:显示许可证信息
示例:
# 显示模型的完整信息
ollama show my-chinese-assistant
# 仅显示 Modelfile 内容
ollama show my-chinese-assistant --modelfile
# 显示模型参数配置
ollama show my-chinese-assistant --parameters执行界面参考:
三、高级与系统命令
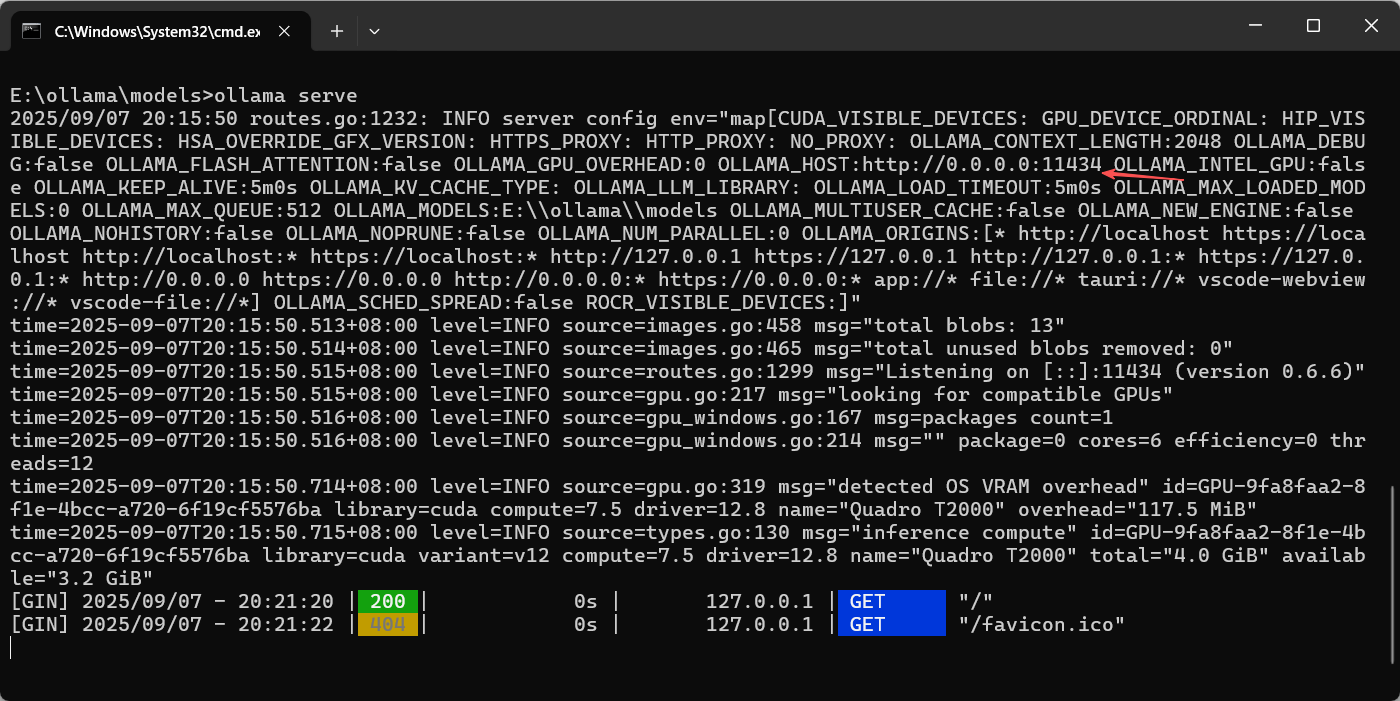
9. ollama serve - 启动API服务
功能:启动 Ollama API 服务器,使模型可通过 REST API 访问。
语法:ollama serve
说明:
-
通常作为后台服务运行,而不是手动启动
-
默认监听在
127.0.0.1:11434 -
可使用环境变量
OLLAMA_HOST更改监听地址
执行界面参考:
⚠️注意:如果ollama桌面程序已经运行,则ollama serve随之启动,再执行ollama serve命令,会提示冲突,如下界面所示,可以退出ollama桌面程序后,再运行ollama serve,这样仅供程序接口调用。

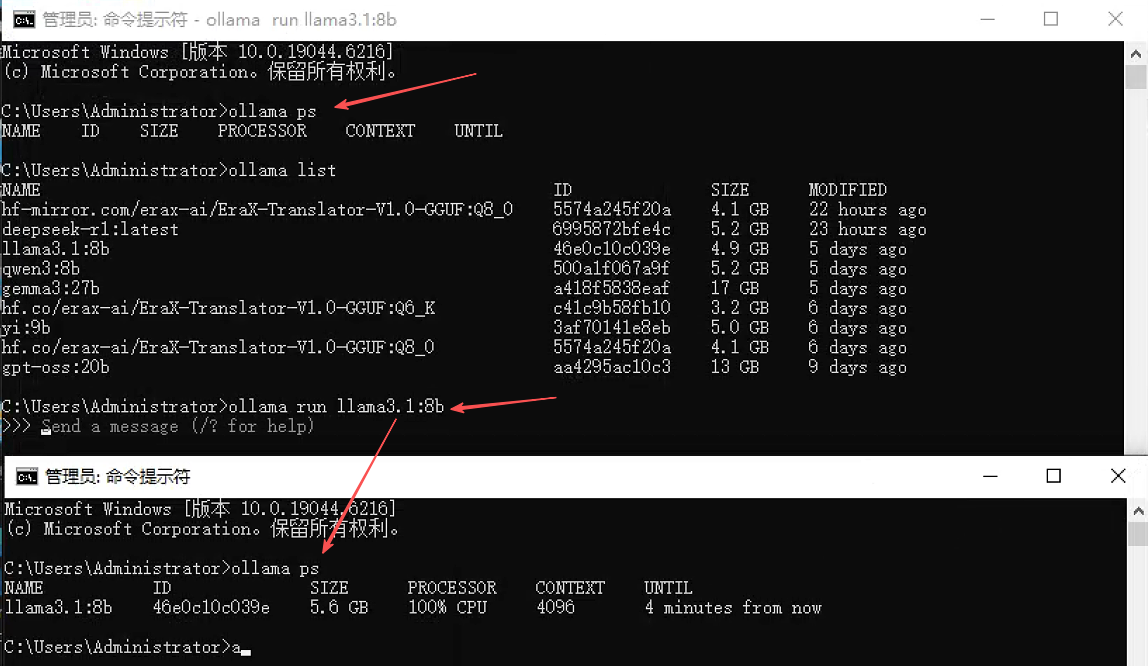
10. ollama ps - 显示运行中的模型
功能:显示当前正在运行的模型及其资源使用情况。
语法:ollama ps
执行界面参考:
11. ollama help - 获取帮助
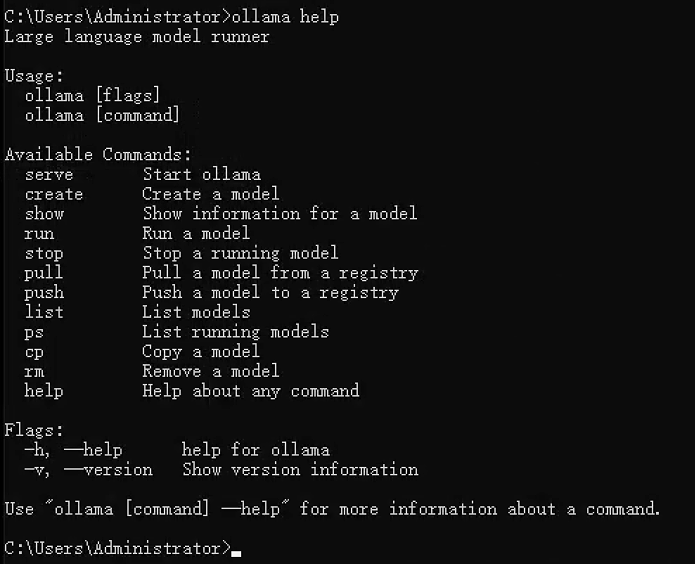
功能:显示帮助信息,可查看所有命令或特定命令的用法。
语法:
# 显示所有命令
ollama help
# 显示特定命令的帮助
ollama help run
ollama help create执行界面参考:
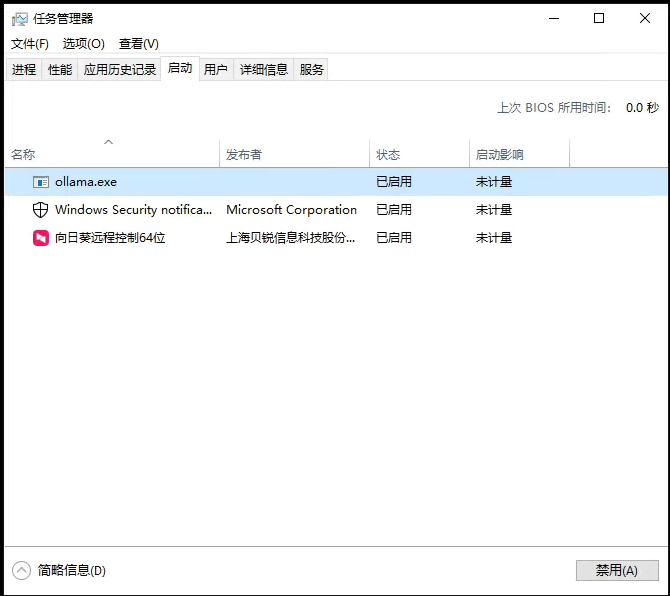
12. 关闭 ollama
没有直接的关闭命令,通过快捷键 Win+X 打开任务管理器,点击“ 启动”,在进程中结束 Ollama 的任务,如果需要可以禁用 Ollama,不再随机启动。
四、环境变量配置
通过环境变量可以配置 Ollama 的各种行为:
| 环境变量 | 功能 | 示例值 |
|---|---|---|
OLLAMA_HOST |
设置API服务监听地址 | 0.0.0.0:11434 (允许远程访问) |
OLLAMA_MODELS |
设置模型存储路径 | /data/ollama/models |
OLLAMA_KEEP_ALIVE |
控制模型在内存中的保留时间 | 5m、2h、-1 (始终保留) |
OLLAMA_DEBUG |
启用调试日志 | 1 (启用) |
使用示例:
# 临时设置环境变量(Linux/macOS)
export OLLAMA_HOST=0.0.0.0:11434
export OLLAMA_KEEP_ALIVE=2h
ollama serve
# Windows (命令行)
set OLLAMA_HOST=0.0.0.0:11434
ollama serve
# 或者创建配置文件 ~/.ollama/config.json
{
"host": "0.0.0.0:11434",
"keep_alive": "2h"
}五、故障排除与技巧
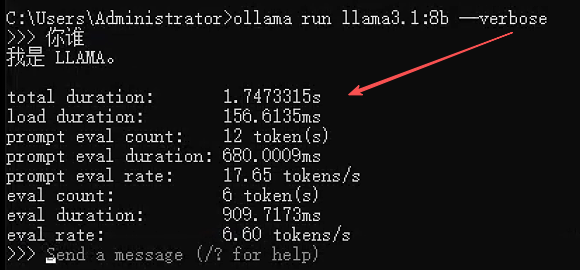
1. 查看详细日志
# 使用 verbose 模式查看详细输出
ollama run llama3 --verbose
# 在Linux上查看服务日志
journalctl -u ollama -f执行界面参考:
2. 清理磁盘空间(Linux/macOS)
# 删除不再使用的模型
ollama list
ollama rm old-model-name
# 清理临时文件(Linux/macOS)
rm -rf ~/.ollama/models/manifests/*✍️备注:Windows下,删除模型,我观察对应的模型文件也删除了,就不用额外清理了,大家可以通过删除模型前后,模型物理文件列表的变化,进行验证。
3. 模型文件默认位置
-
Linux/macOS:
~/.ollama/models/ -
Windows:
C:\Users\<用户名>\.ollama\models - 模型文件的实际位置
Windows下,在cmd,通过命令
set OLLAMA_MODELS查看有没有设置该变量,如果返回具体位置,则模型在此位置,否则在默认位置。
执行界面参考:

六、命令总结
按照不同的使用思路,在梳理一下各命令。
1. 模型管理命令
| 命令 | 用法 | 示例 |
|---|---|---|
| 创建模型 | ollama create <model_name> -f Modelfile |
ollama create my-model -f ./Modelfile(Modelfile 定义模型架构、参数等) |
| 拉取模型 | ollama pull <model_name[:version]> |
ollama pull llama3:7b(下载指定版本) |
| 列出模型 | ollama list |
显示本地模型名称、ID、大小、修改时间 |
| 查看详情 | ollama show <model_name> |
输出模型版本、参数、描述等 |
| 复制模型 | ollama cp <源模型> <新模型> |
ollama cp llama3 my-llama3 |
| 删除模型 | ollama rm <model_name> |
ollama rm llama3:7b(释放磁盘空间) |
2. 服务与运行命令
| 命令 | 用法 | 示例 |
|---|---|---|
| 启动服务 | ollama serve |
默认端口 11434,支持 --port 11435 自定义 |
| 停止服务 | ollama stop 或 pkill -f "ollama serve" |
强制终止可用 systemctl stop ollama(Linux) |
| 运行模型 | ollama run <model_name> [参数] |
ollama run llama3 --temp 0.7 --max-tokens 500(调整温度、输出长度) |
| 查看运行模型 | ollama ps |
显示正在运行的模型及其状态 |
| 停止模型 | ollama stop <model_name> 或 Ctrl+D(交互界面) |
优雅终止指定模型 |
3. 会话与交互命令
- 交互命令:
/load <model>:加载模型或会话。/save <model>:保存当前会话状态。/clear:清除上下文历史。/bye:退出会话。/set system "提示词":设置系统提示(如角色、格式)。/set format json:强制输出 JSON 格式。
第五课:桌面模型管理应用调用ollama大模型
Ollama 是本地大模型运行管理,同时提供 API 服务(默认 http://127.0.0.1:11434),很多桌面端 / WebUI / 插件类管理工具都可以把它作为模型提供方来调用。以下是主要可用的程序对比,然后对几个典型应用的具体安装,和配置使用ollama模型进行了详细描述。
一、桌面模型管理应用对比及选择
1.1. 对比表
| 名称 | 类型/平台 | 连接 Ollama 的方式 | 主要功能 | 适合谁 |
|---|---|---|---|---|
| Ollama Desktop | 官方桌面端(Win/macOS/Linux) | 内置,无需额外配置 | 模型下载、管理、聊天;GUI 界面直连 ollama serve;可作为 API 提供方 |
初学者,想要官方最简洁体验 |
| AnythingLLM Desktop | 桌面端(Win/macOS/Linux) | 设置 Ollama → 127.0.0.1:11434;嵌入器也可走 Ollama |
多工作区、RAG、Agent/工具、向量库 | 做私有知识库、团队协作 |
| Open WebUI | 本地 Web UI | 原生支持 Ollama;Docker 或桌面运行 | 多模型切换、RAG、插件/工具,社区最活跃 | 喜欢浏览器界面、多人使用 |
| Chatbox | 桌面端(Win/macOS/Linux) | 设置 Ollama,自动识别已下载模型 | 聊天简洁、多 Provider 切换 | 要一个干净顺手的聊天界面 |
| Lobe Chat | Web UI(可桌面化) | 新建 Provider 选择 Ollama | 多角色卡、RAG、插件生态,美观 UI | 想要美观 + 协作 |
| LibreChat | 自托管 Web UI | 配置 OpenAI 兼容端点 → Ollama | 多 Provider、会话管理、文件上传 | 想要开源 ChatGPT 替代 |
| Page Assist | 浏览器扩展(Chrome/Firefox) | 扩展设置里选 Ollama | 网页侧边栏、摘要、网页问答;可配合本地 RAG | 边浏览边用 AI 总结 |
| Continue (VS Code 插件) | IDE 插件 | 配置 Provider → Ollama API | 代码补全、解释、重构 | 程序员日常开发 |
| Msty | 桌面端 + Web | 可连 Ollama;还能共享 Ollama 模型目录 | 聊天、知识库(Knowledge Stack)、RAG | 想复用 Ollama 已下的模型文件 |
| MindMac | 桌面端(macOS) | 设置 Ollama endpoint;支持 LiteLLM | 原生桌面体验、截图问答 | mac 用户 |
| Cherry Studio | 桌面端(Win/macOS/Linux) | 内置支持 Ollama,配置 API 地址即可 | 聊天、多模型管理、插件扩展、文件问答,RAG 支持强 | 想要一体化桌面管理工具 |
| LocalAI (LocalAPI.ai) | 本地推理框架(Win/Linux/macOS) | 与 Ollama 类似,提供 OpenAI API 兼容接口;可被前端(如 AnythingLLM/LibreChat/Cherry Studio)作为 Provider 调用 | 更偏“底层引擎”,支持多种模型格式(GGUF、ONNX、whisper 等),可替代或并行 Ollama | 想要高度灵活、支持更多模型格式的用户 |
1.2. 选型建议
-
最小上手:
-
直接用 Ollama Desktop 聊天;
-
想扩展功能,再加 Chatbox / Page Assist / Continue。
-
-
做私有知识库 / RAG:
-
AnythingLLM / Open WebUI / Cherry Studio
-
-
开发场景:
-
Continue(VS Code 插件)
-
-
浏览器即用:
-
Page Assist
-
-
美观 + 桌面一体化体验:
-
Cherry Studio / Lobe Chat
-
MindMac(mac 专用)
-
-
要极限灵活性:
-
LocalAI 作为 API 中心,兼容多种模型类型;
-
Ollama 专注 LLM,二者可混合用。
-
1.3. 通用配置方法
几乎所有前端都能按以下步骤连接 Ollama:
-
启动 Ollama(桌面版自动运行,或命令行
ollama serve)。默认地址:http://127.0.0.1:11434。 -
在前端程序里新增 Provider,选择 Ollama。
-
填写 Base URL:
http://127.0.0.1:11434。 -
在模型列表中选择你已下载的模型(如
llama3.1:8b、qwen2:7b、mistral:7b等)。 -
若做 文档问答 / RAG,记得配置一个 Embedding 模型(如
nomic-embed-text)。
二、几种典型桌面模型管理应用的使用
2.1 Ollama desktop
Ollama 官方的桌面应用,是最直接的“官方客户端”。Ollama安装的如果是普通版本,非CLI版本,自带桌面程序。
特点:
-
集成模型管理(下载、删除、更新)
-
自带 GUI 聊天界面
-
同时运行后台服务(
ollama serve),供其他前端调用
ollama的界面示例如下:
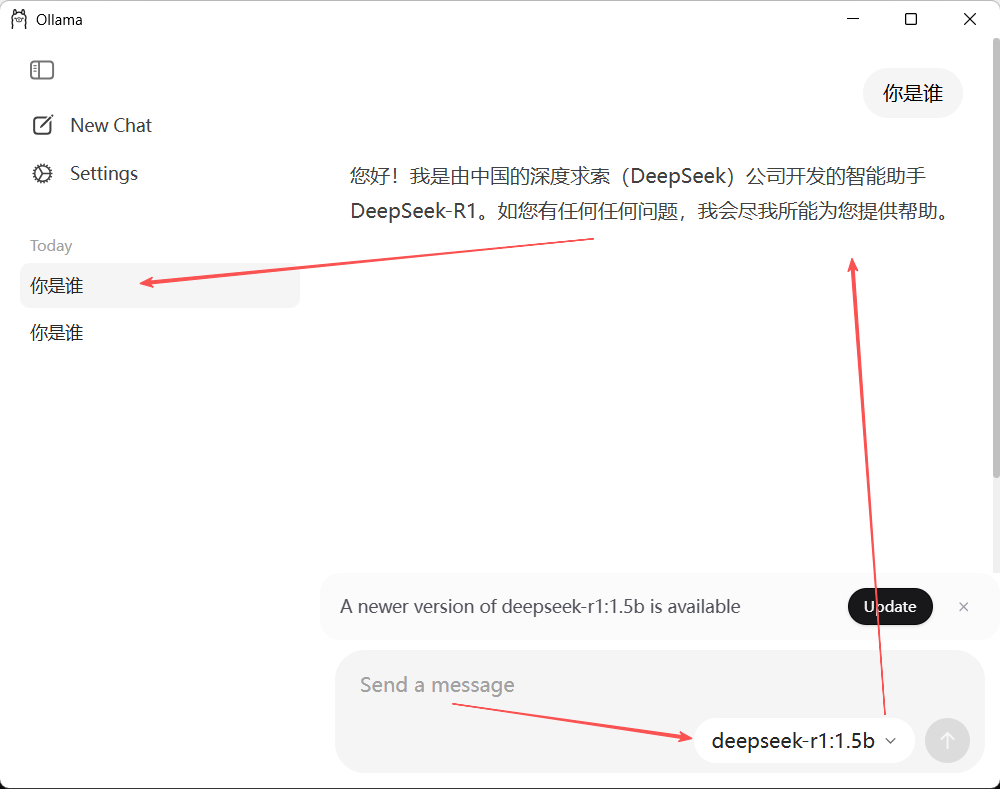
2.2 AnythingLLM
AnythingLLM提供了桌面客户端,方便用户使用;能够从多种不同来源获取数据,包括但不限于文档、网页、数据库等,适用于对本地知识库要求高的朋友。
2.2.1 安装AnythingLLM
在AnythingLLM官网下载: https://anythingllm.com/
选择适合自己的版本,下载完安装,直接安装,下一步,下一步。。。
2.2.2 首次启动AnythingLLM
打开 AnythingLLM 时,进入欢迎页面,点击 “Get started”:
然后,下一步:
然后:
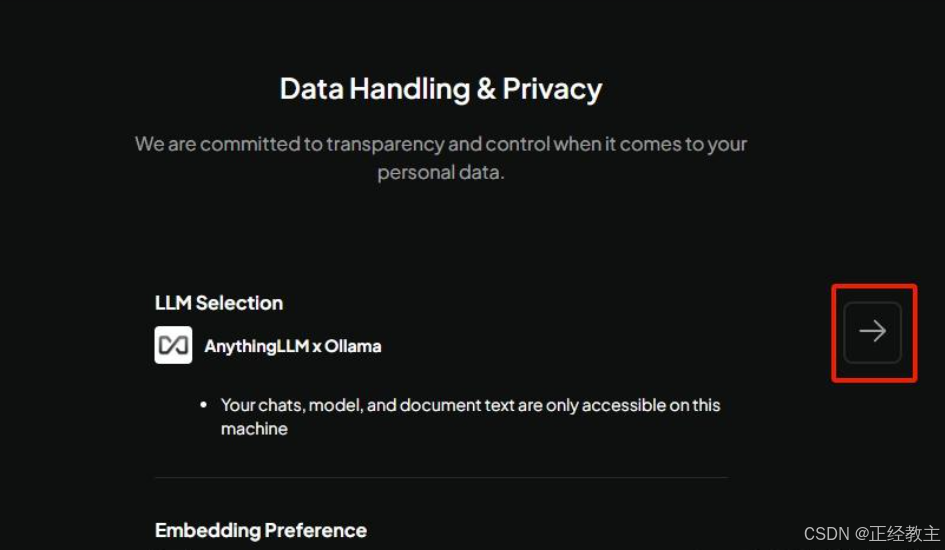 然后,中间会需要填邮箱什么的,就进入工作区,自己命名一个:
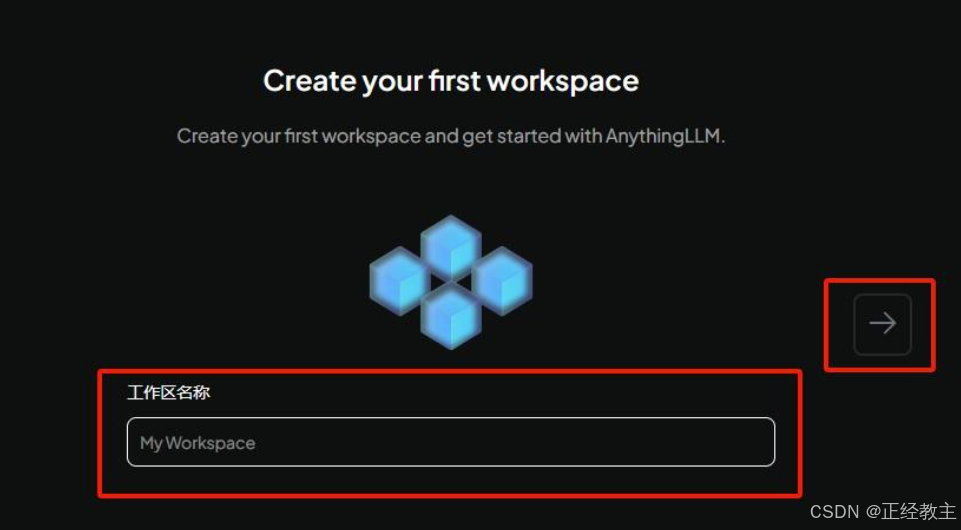
然后,中间会需要填邮箱什么的,就进入工作区,自己命名一个:
2.2.3 设置AnythingLLM
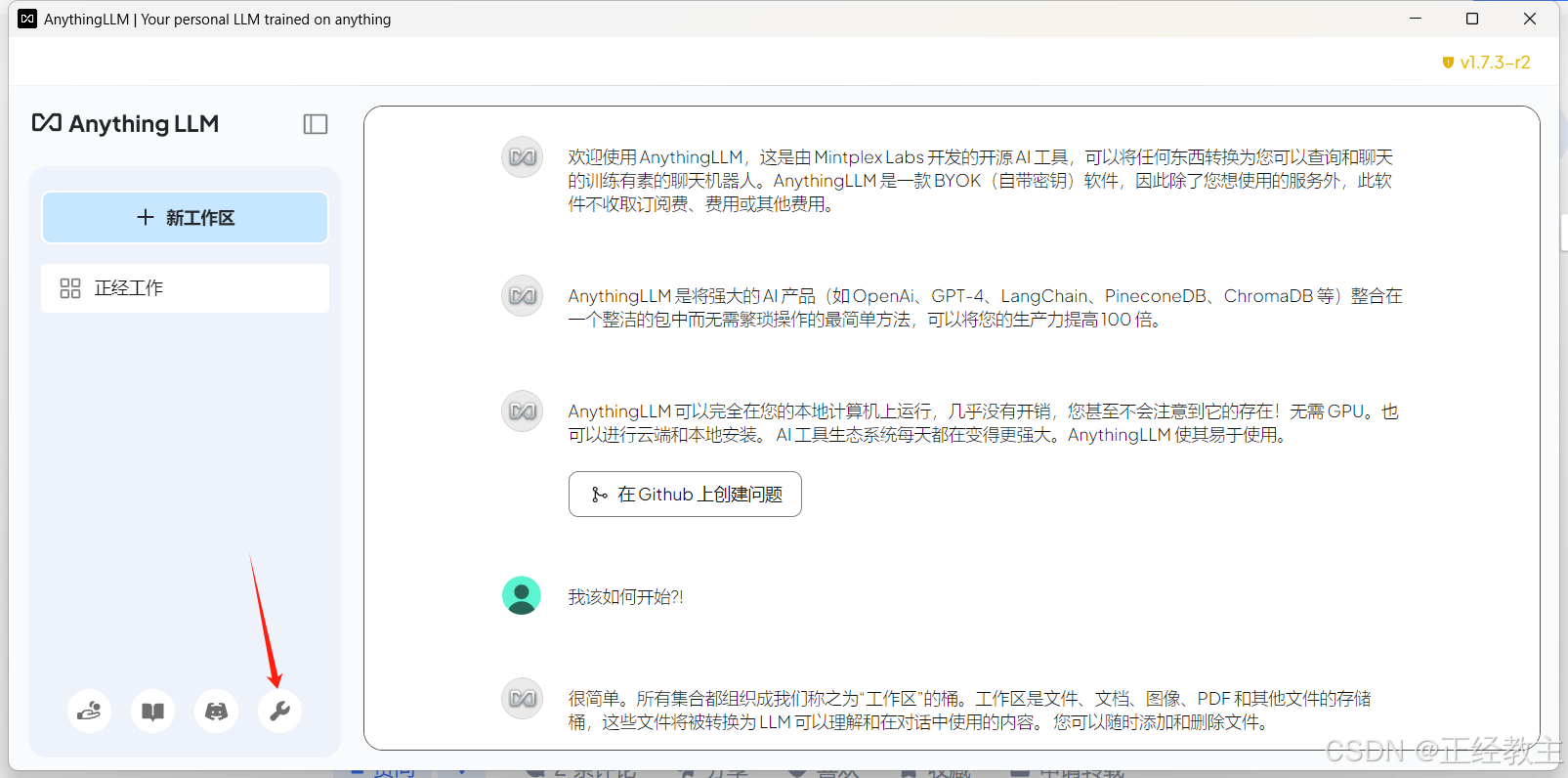
进入到工作区后,点击“设置”图标:
 在设置页面,外观中设置显示语言:
在设置页面,外观中设置显示语言:

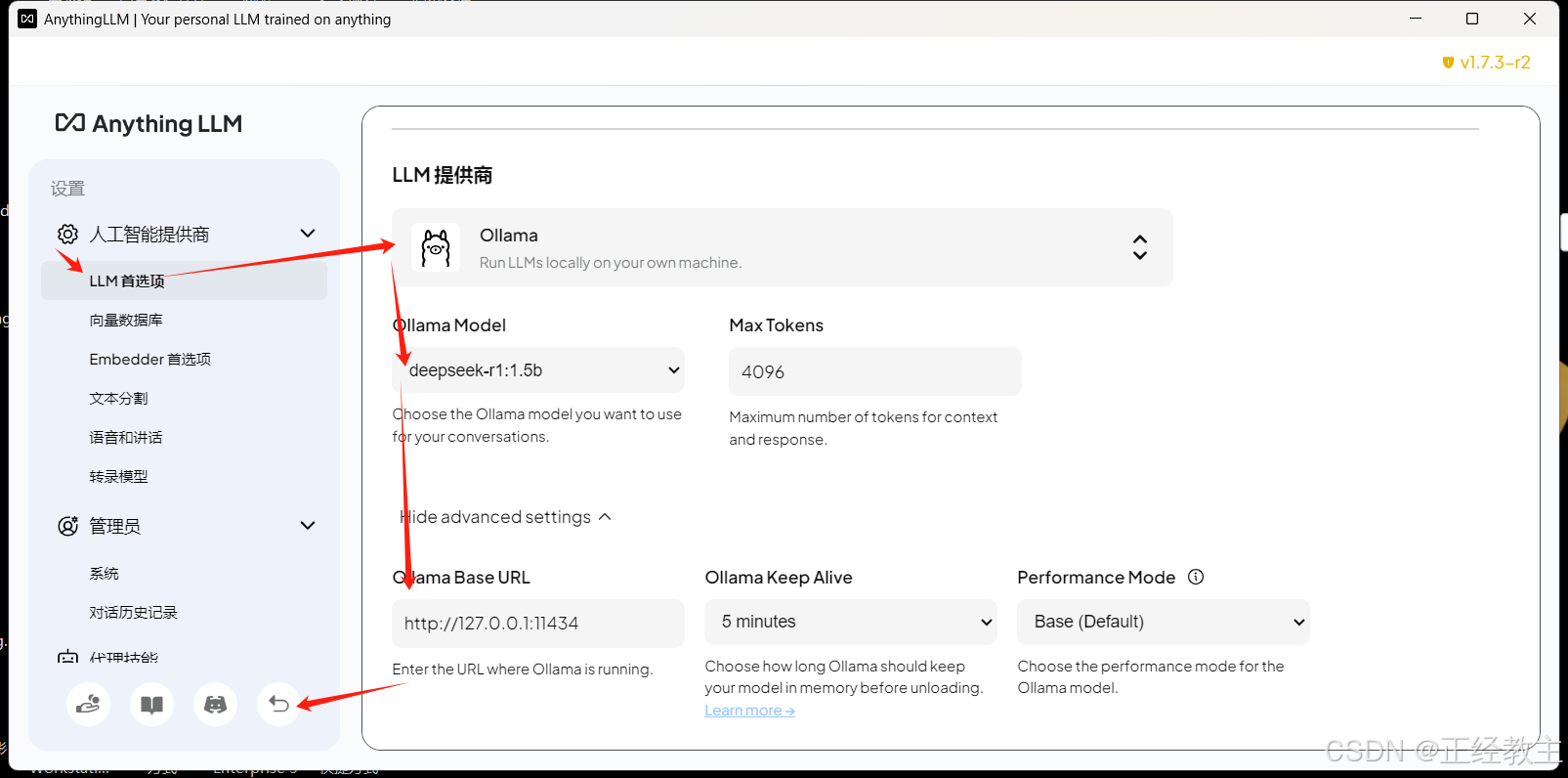
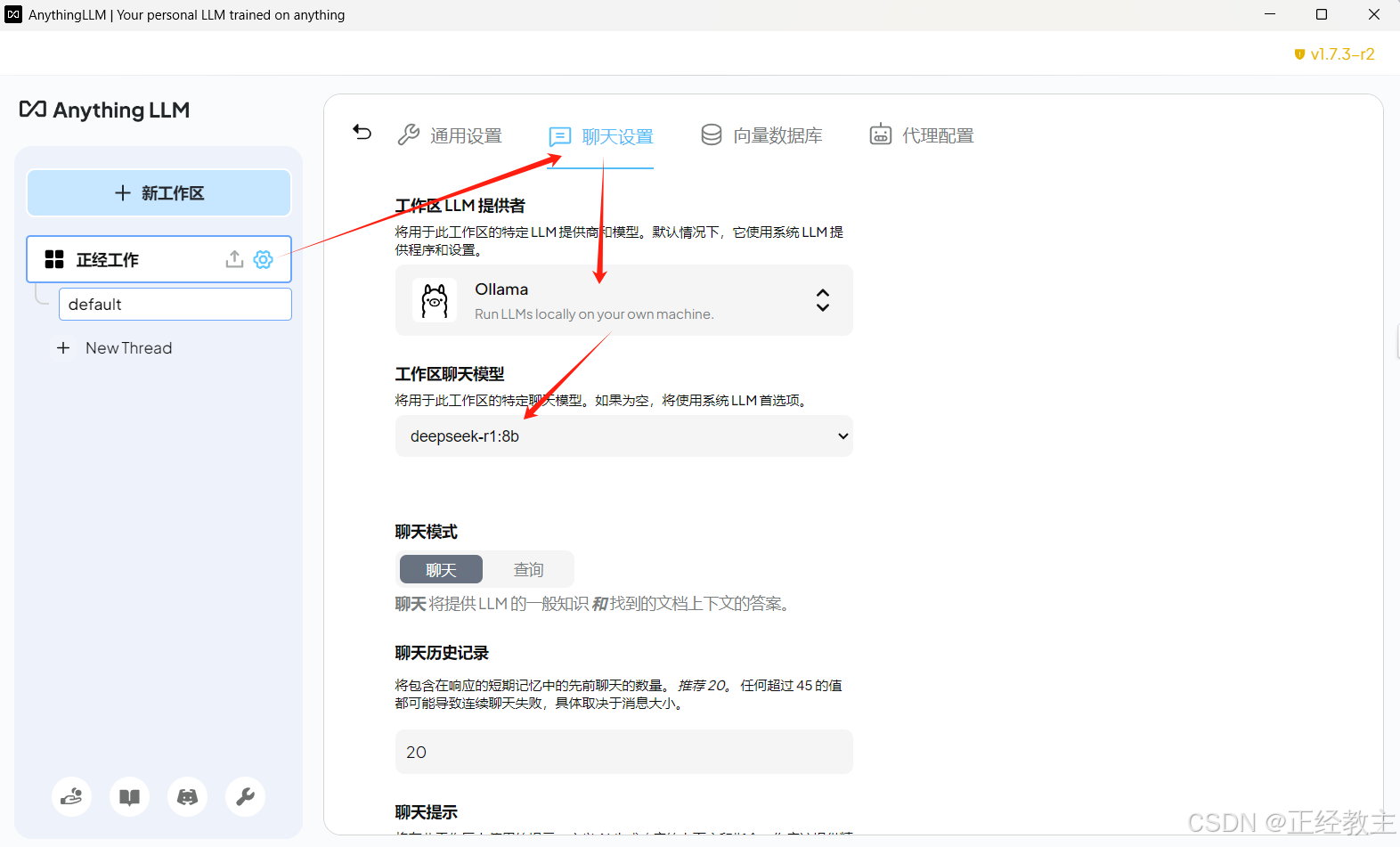
在LL首选项中,选择LLM供应商为ollama,配置deepseek等模型,和地址,然后点击返回按钮:
 返回到聊天界面后,配置工作区的聊天设置,可以给工作区设置不同的数据模型,如下图:
返回到聊天界面后,配置工作区的聊天设置,可以给工作区设置不同的数据模型,如下图:
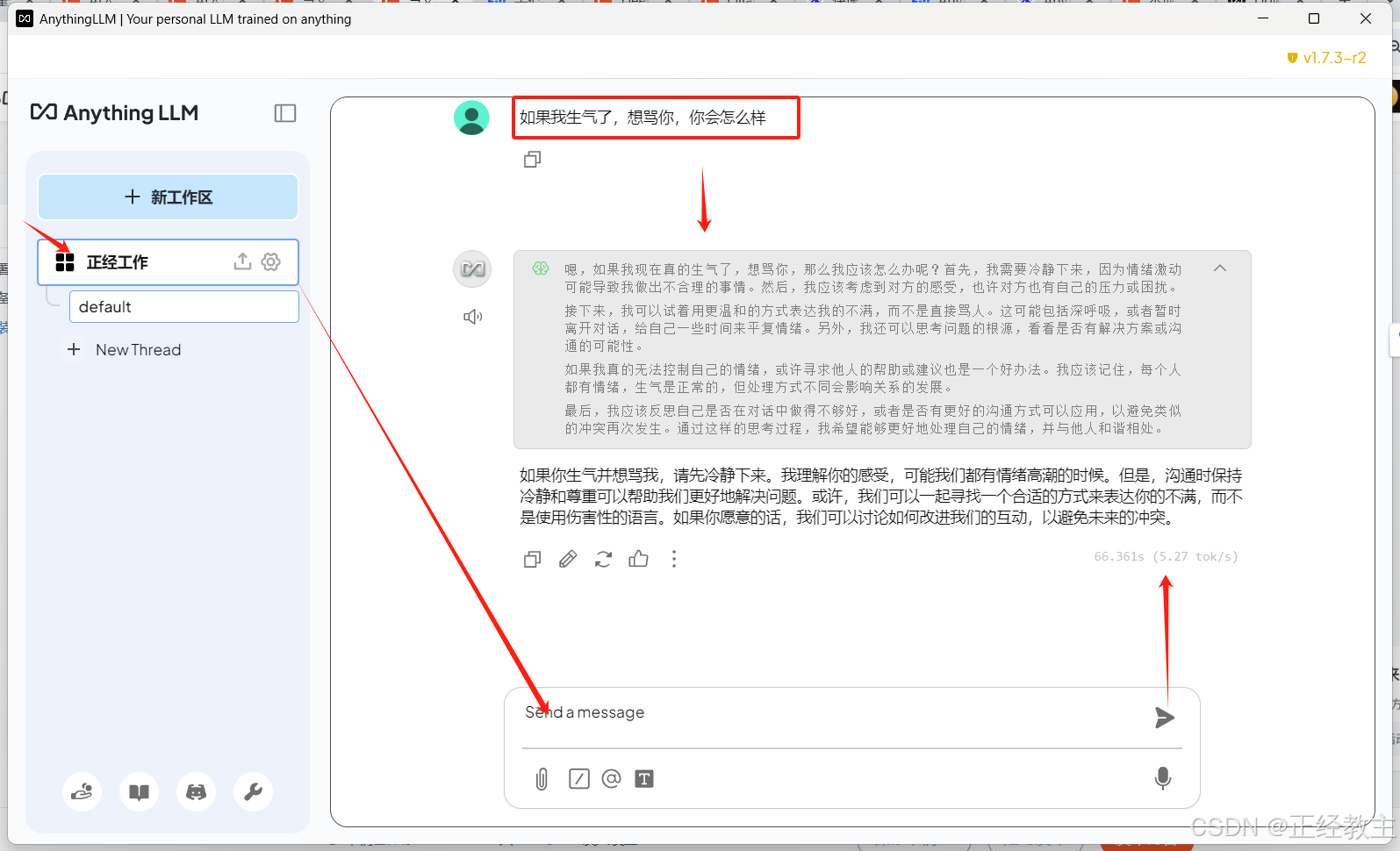
然后就开始聊天:
2.3 Cherry Studio
Cherry Studio 是一款开源的多平台AI桌面客户端,支持Windows、macOS和Linux系统,集成了OpenAI、Claude、DeepSeek等主流大语言模型,并提供本地知识库管理、多模态交互(文本/图像/音频)及对话历史记录功能。最重要的:
Cherry Studio 是由中国开发者团队 DeepSeek(深度求索) 主导开发的开源项目,本地化适配,专为中文用户优化,内置提示词模板,简化知识库搭建与多场景应用
2.3.1 安装
官网下载:https://www.cherry-ai.com/
根据自己的设备,选择版本:
- arm64:于智能手机、平板电脑、嵌入式系统和轻薄笔记本电脑
- x64:个人电脑、服务器和高端工作站,64位
运行安装,提示:
仍要运行:
建议更改安装目标:
点击安装:
就安装完了。
2.3.2 模型服务配置
依照下图,进入配置界面:
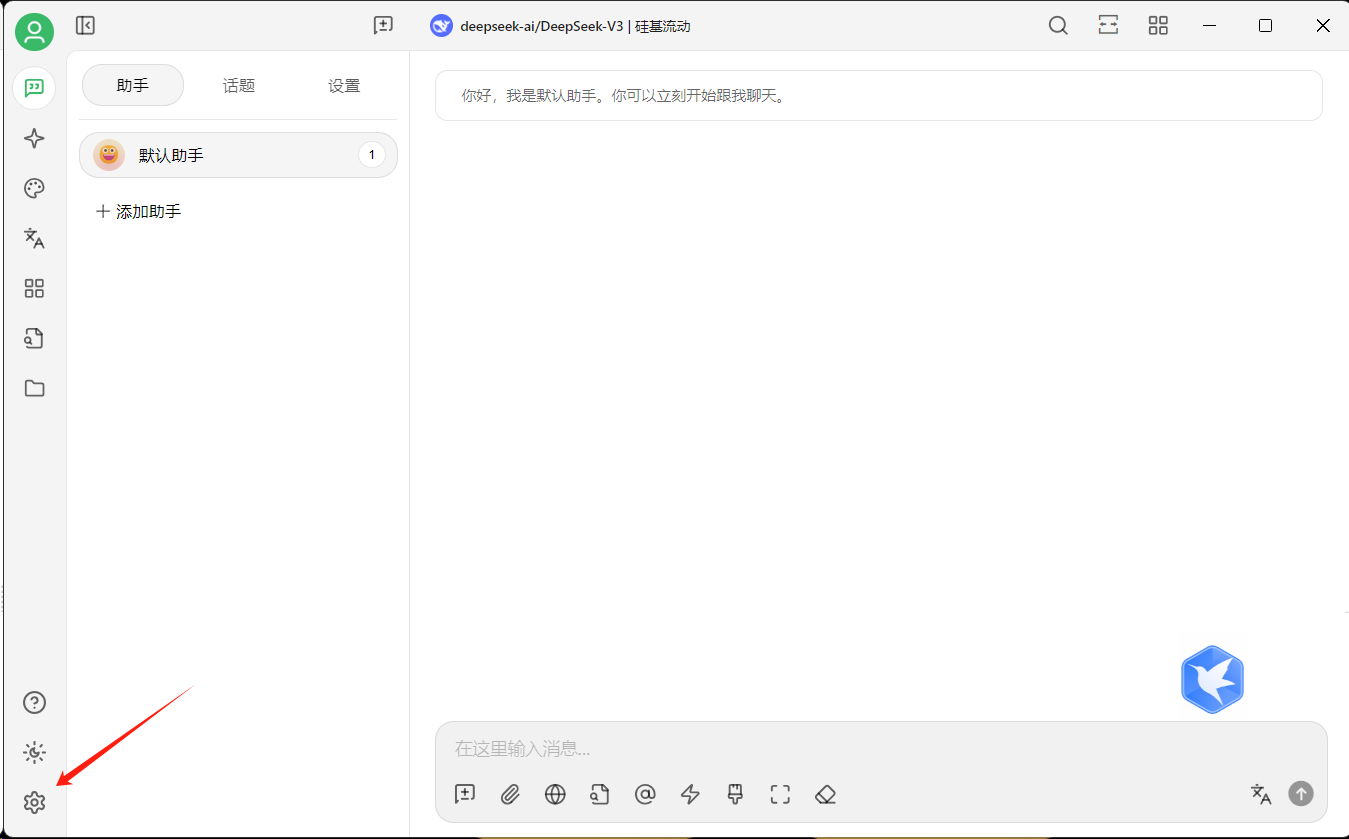
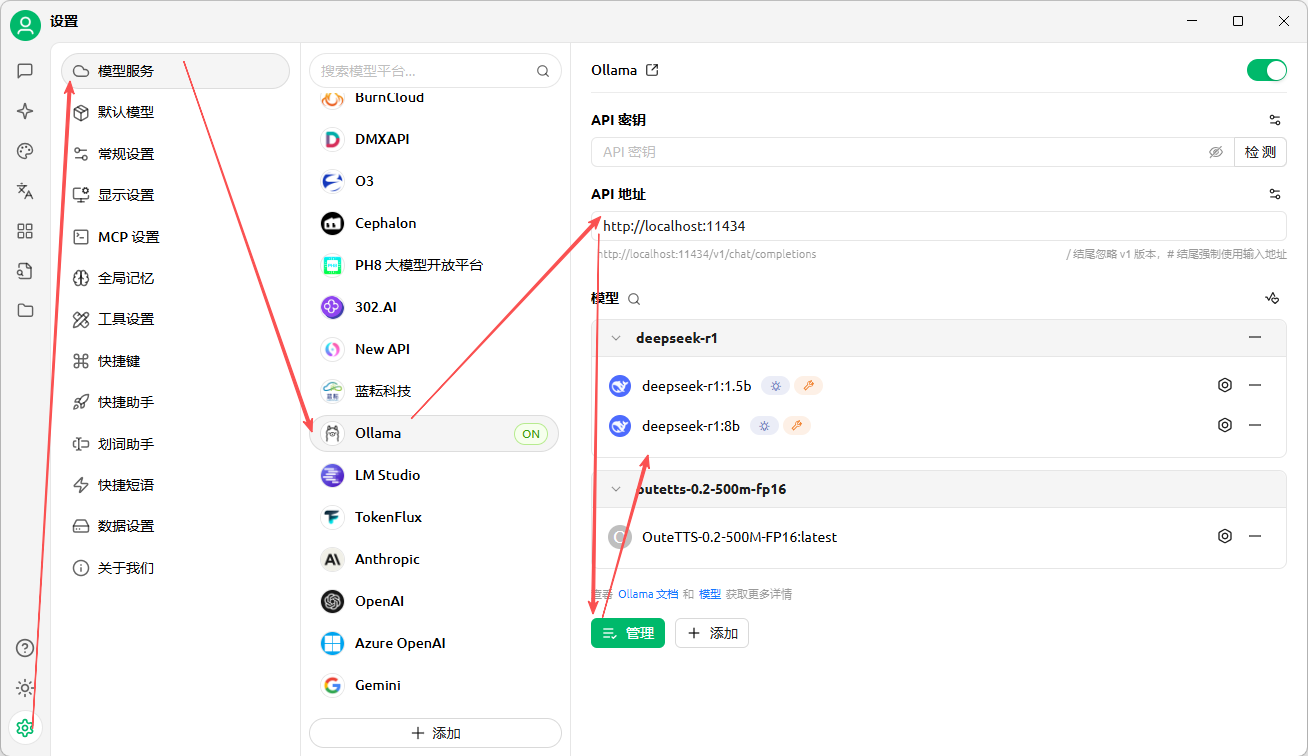
模型服务,选择Ollama,通过管理按钮添加Ollama已经部署的模型,见下图所示:
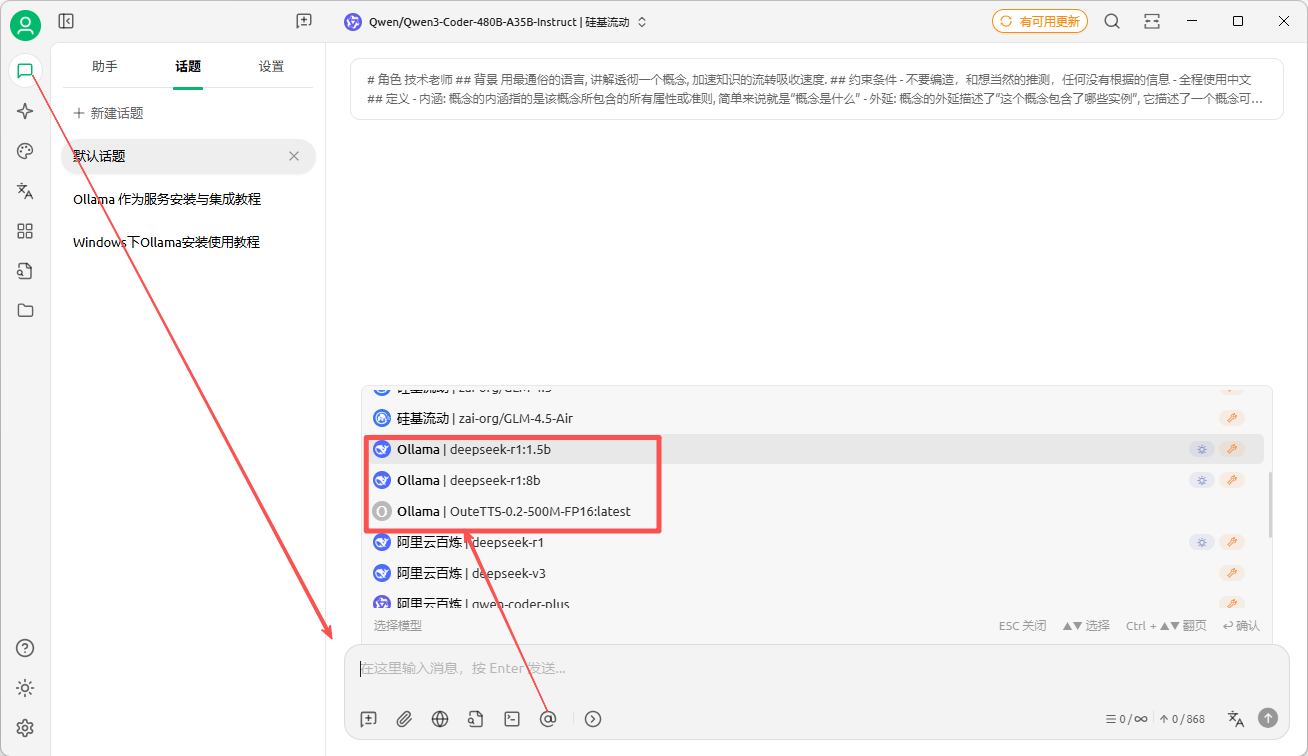
在聊天,或者设置聊天助手时,就可以使用ollama的大模型了:
2.4 浏览器扩展Page Assist
Page Assis是网页插件,操作简单。
2.4.1 安装:
作为新手,选择用比较简便的Page Assist来实现这个功能,Page Assist是浏览器的一个插件,以Firefox浏览器为例,看看这个部署过程,因为过程非常简单,按图操作就行了:
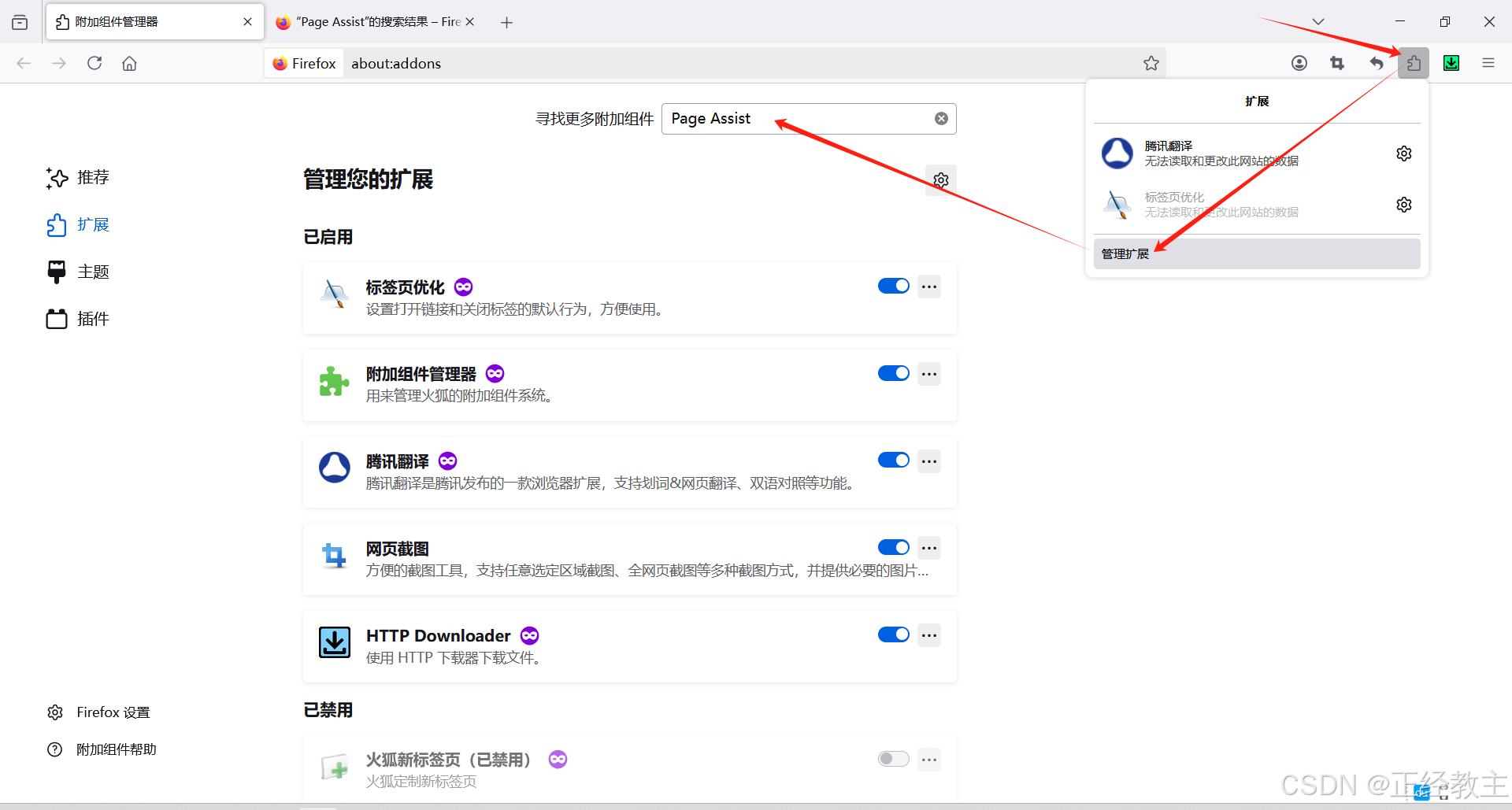
输入搜索内容回车,点击第一个搜索结果(请认准小图标):
然后就是添加了:
会在浏览器右上角弹出提示,点击添加即可:

然后,是确定框:
这就安装上了。
2.4.2 配置
如图,打开Page Assist:
进入Page Assist:
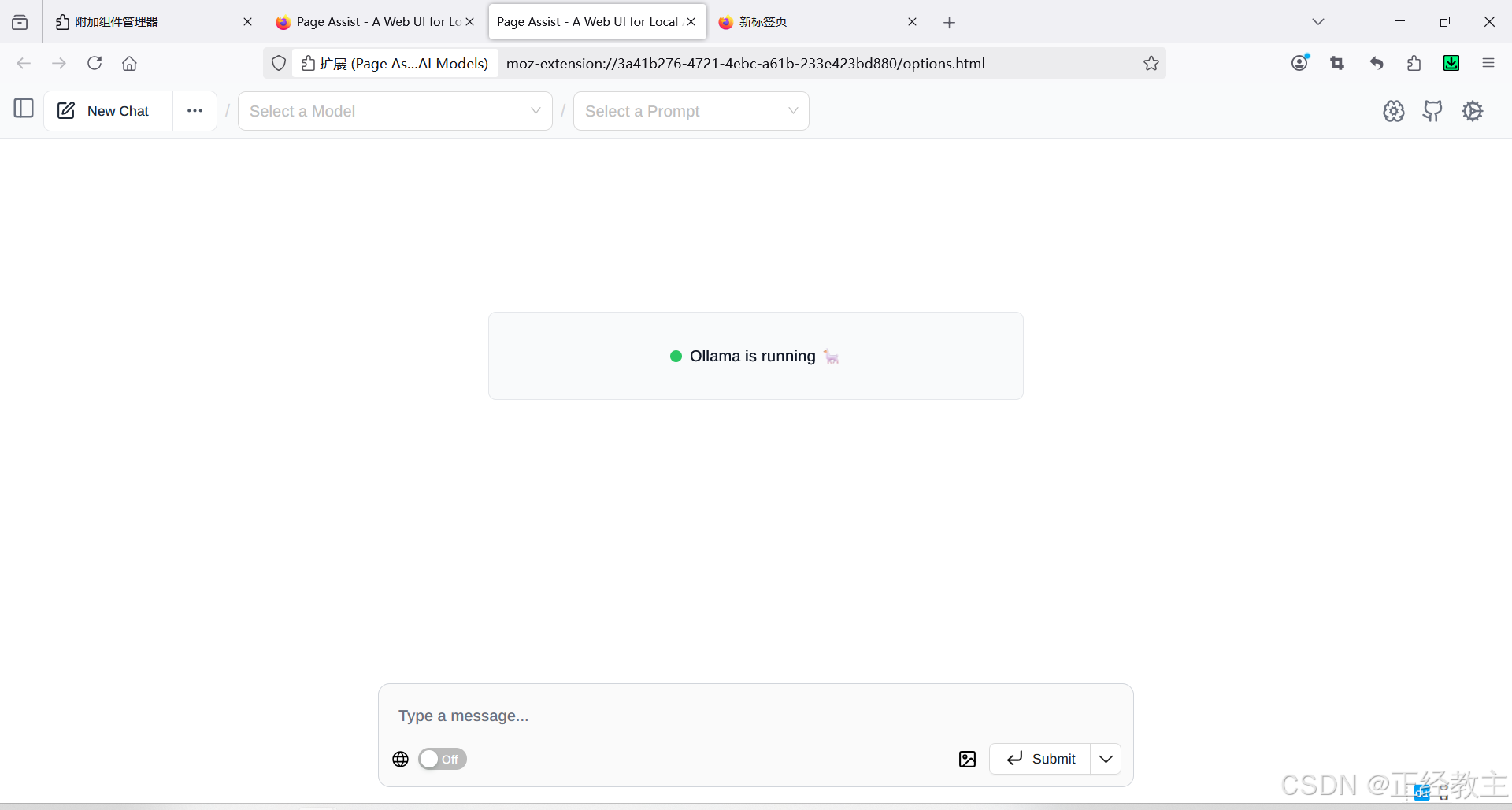
按图配置:
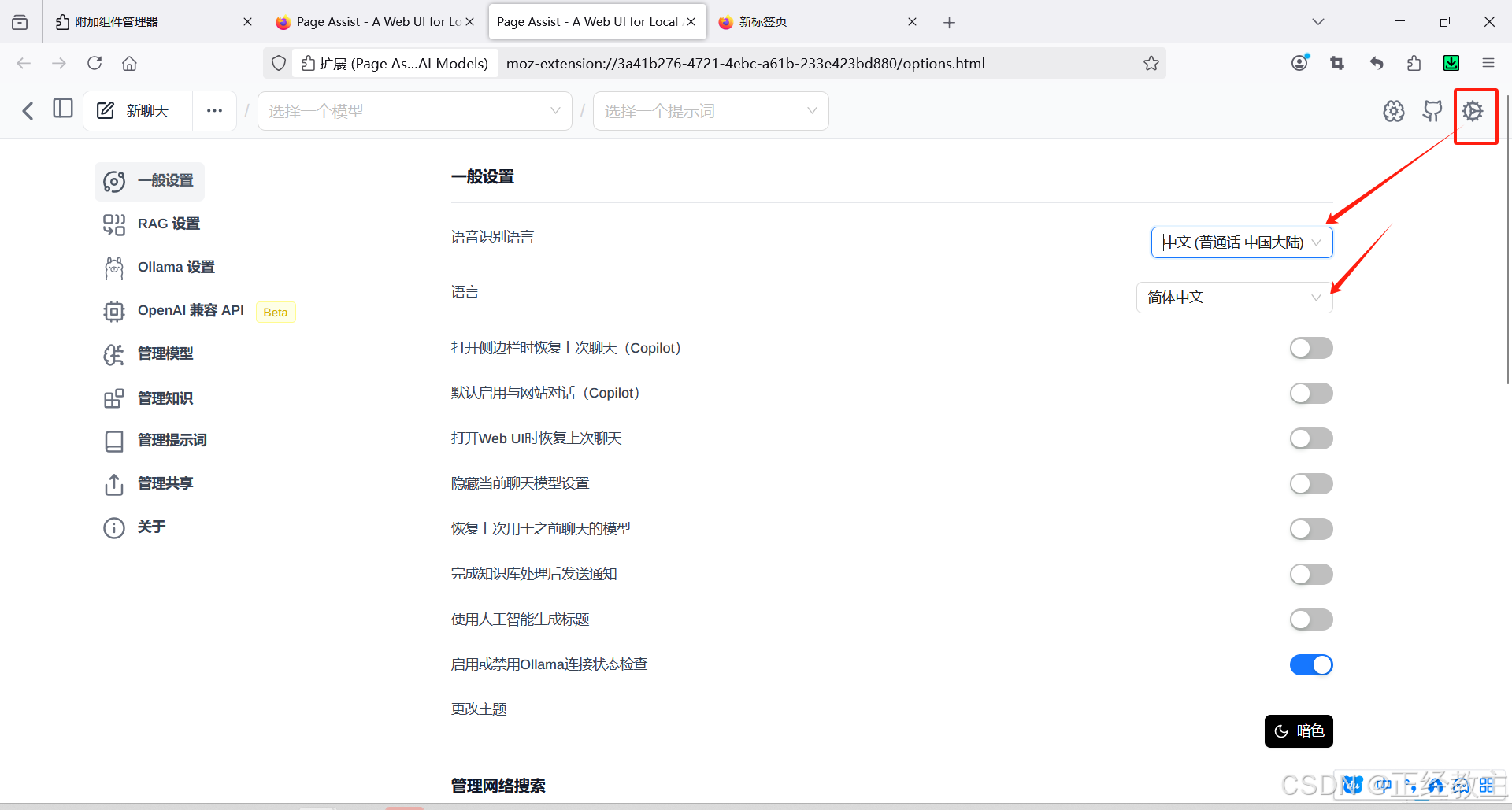
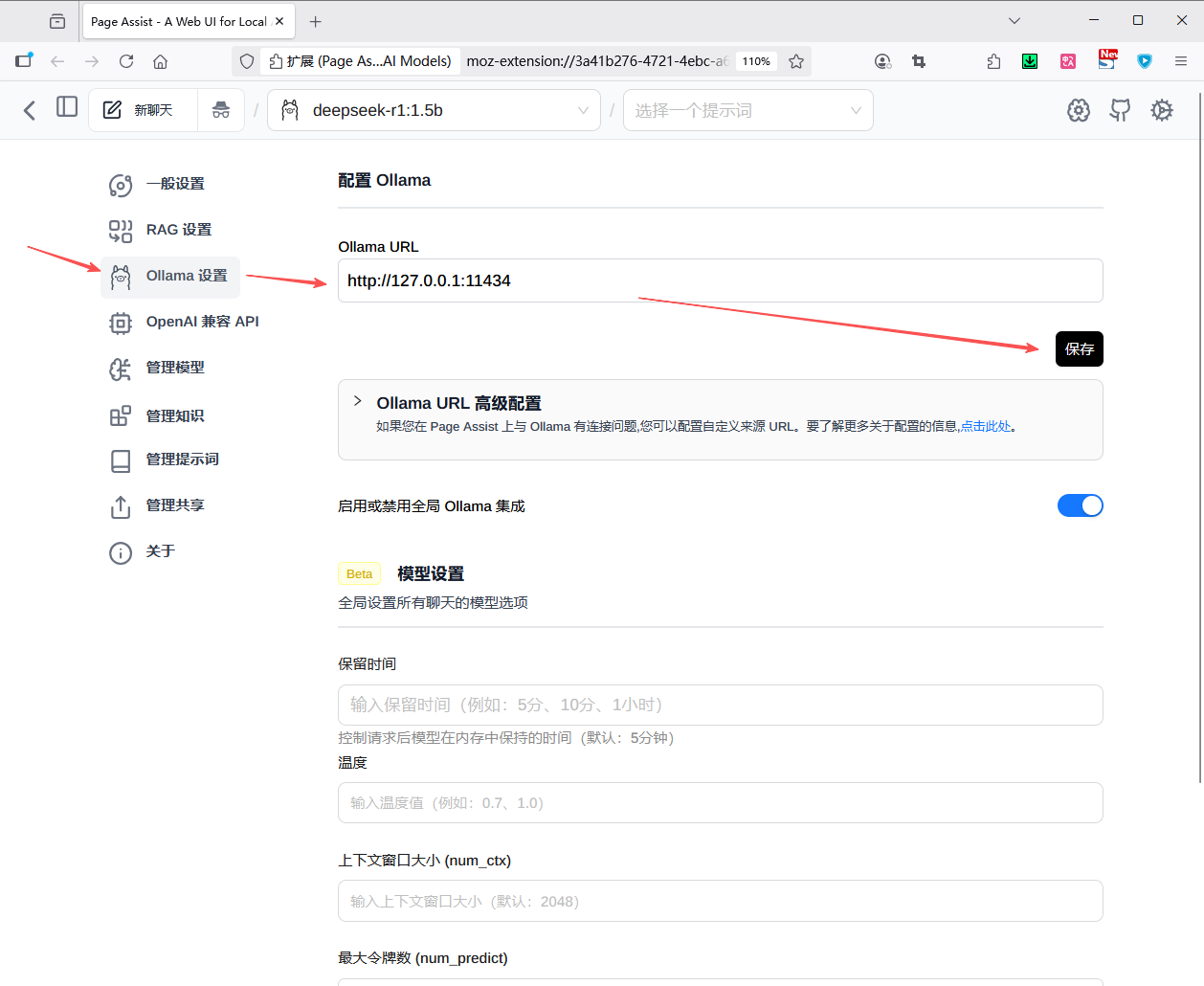
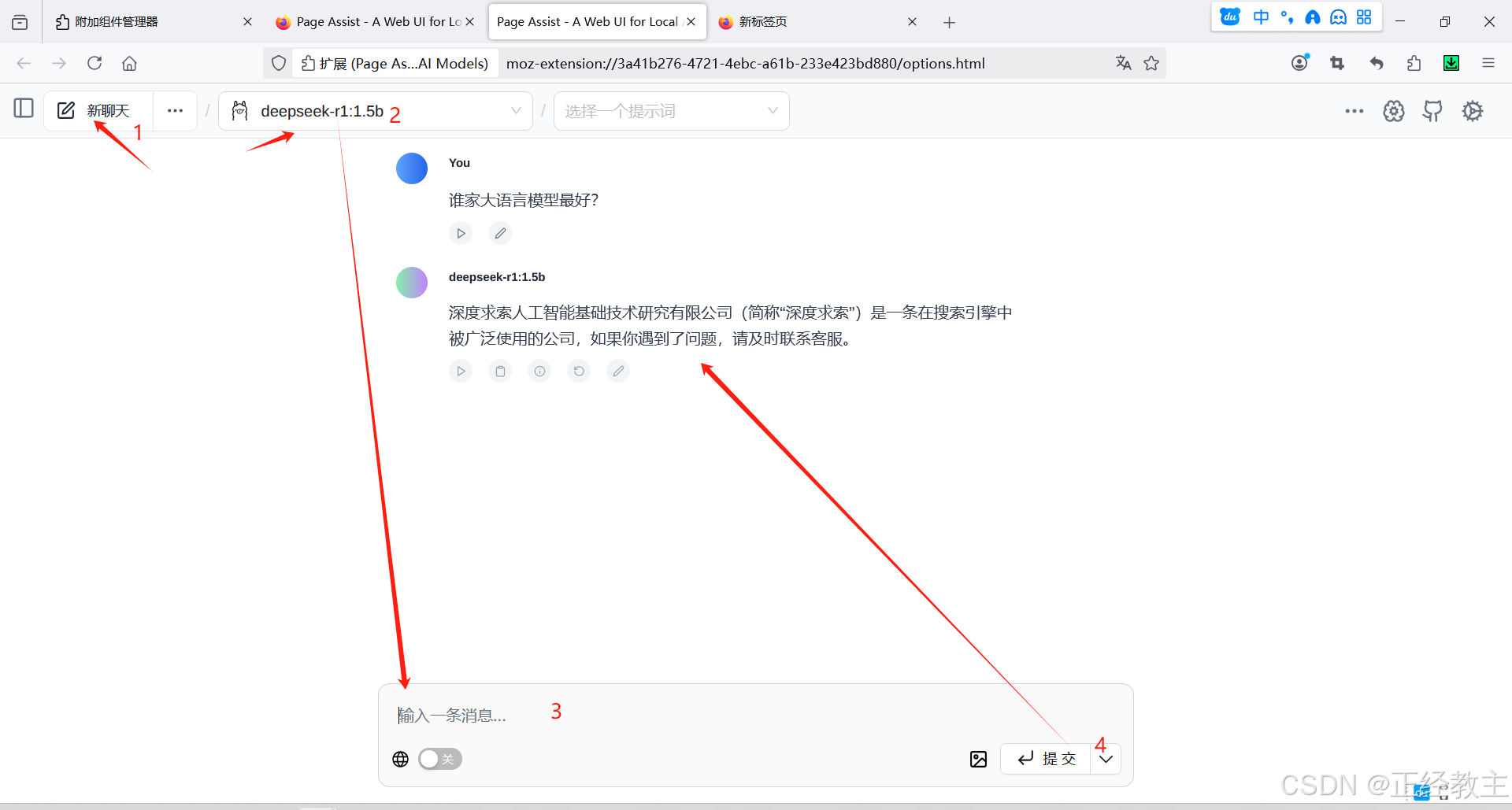
保存配置后,就可以选择ollama部署的任何一个大模型,开始对话了:
三、总结
大部分模型管理应用,都支持ollama,通用性非常好。
第六课:🤖Python 调用 Ollama 大模型方式汇总
下面我把在 Python 中调用已部署的 Ollama 大模型的所有常见方式做一个系统、可复制的汇总与详解。
🧭概览 — 可选的方法(按常用度)
-
官方 Ollama Python SDK(同步 / 异步 / 流式 / 模型管理)。
-
直接调用 Ollama 原生 REST API(
/api/generate,/api/chat,/api/embed等)。 -
使用 OpenAI 兼容接口(
http://localhost:11434/v1/...),可用 OpenAI 官方/社区 SDK 直接调用。 -
使用 上层框架/适配器(LangChain、LlamaIndex/llama-index、AutoGen 等),以便快速接入 RAG、Agent、多模型编排等。
-
从 Python 调用 CLI(subprocess)(短任务、脚本化或工具链集成)。
📊几种方式对比:
| 调用方式 | 上手难度 | 控制能力 | 流式支持 | 异步支持 | 结构化输出 | 适用场景 |
|---|---|---|---|---|---|---|
| 官方 Python SDK | ⭐️⭐️ | ✅ 高 | ✅ | ✅ | ✅ JSON/Schema | 推荐用于直接对接 Ollama 本地服务 |
| 原生 REST API | ⭐️⭐️⭐️ | ✅ 最高 | ✅ | ✅(需 httpx) | ✅ JSON/Schema | 网关接入、跨语言调用、协议级控制 |
| OpenAI 兼容 API | ⭐️ | ⚠️ 中 | ✅ | ✅ | ✅ | 复用 OpenAI 客户端与生态 |
| LangChain/LlamaIndex 等框架 | ⭐️⭐️ | ✅ 中 | ✅ | ✅ | ✅ | 快速构建 RAG、Agent、评测管线 |
| CLI(subprocess) | ⭐️ | ❌ 最低 | ✅(手动) | ❌ | ❌ | 脚本化调用、离线环境、原型验证 |
选择建议
-
你想要“最少代码 + 完整能力”:选官方 Python SDK。
-
你要“协议级可控 + 网关/鉴权/多语言复用”:选原生 REST。
-
你已有 OpenAI 客户端代码/RAG 组件:优先试 OpenAI 兼容 API。
-
你要速成 RAG/Agent:用 LangChain/LlamaIndex 对接 Ollama 后端。
-
直接调用本地命令行(如 ollama run、ollama list):subprocess方式。
📜相关参考文档:
- Ollama 官方文档 (GitHub):https://github.com/ollama/ollama/blob/main/docs/api.md
- API中文文档(readthedocs):https://ollama.readthedocs.io/api/
- API中文文档(cadn):https://ollama.cadn.net.cn/api.html
- API中文文档(apifox):https://ollama-docs.apifox.cn/
- 官方Python调用示例:https://github.com/ollama/ollama-python
- Postman 平台(可测试API):https://www.postman.com/postman-student-programs/ollama-api/documentation/suc47x8/ollama-rest-api
📜参考:几个文档平台的介绍
平台 产生背景 主要作用 技术文档特色 目标群体 Read the Docs 开源社区 开源文档托管 版本化、自动化、公开透明 全球开源项目开发者 CADN 国内开发者需求 文档聚合 中文技术文档知识库 中国开发者、API 提供方 Apifox 前后端协作需求 API 一体化工具 “活文档”,联动调试与测试 企业团队、后端 & 前端工程师
一、Python运行环境Trae准备
💬说明:本课内容,对Python运行环境没有要求,当前没有Python运行环境的,可以参考这一章,已有的,可直接跳过这一章。
Python传统运行环境VS Code,使用广泛,Trae 是字节跳动于 2025 年推出的 AI 原生集成开发环境(AI IDE),全称为 The Real AI Engineer,特点是自带AI支持,以及对中文的优化,所以这里以Trae为示例,因为Trae兼容VS code的大部分操作,如果安装VS Code,也是相似的。
1.1 下载安装
下载安装程序,直接点击“立即获取Trae”,自己会识别当前系统信息,下载匹配版本,当然也可以自己点击“查看所有下载选项”,找对应的版本下载:
直接运行,“下一步”、“下一步”安装,其中安装目录可以换成空闲磁盘多的目录:
其他就一路“下一步”,就完成了
1.2 开始运行
有网络提示:允许
然后,“开始”:
选择样式主题,和语言:

可以从现有开发环境导入配置,我这里就从vsCode直接导入了:
为了日后用着方便,安装命令行:
然后,需要登录,才能有IA支持功能:
点击登录,会在浏览器,打开登录网址,不支持虚拟手机号,否则会提示“访问太频繁。。。”,正常手机号,能注册登录:
登录后,看起来和vdCode的界面差不多,打开一个空文件夹,作为工作空间,然后我就把上一篇AI实例的操作过程,搬过来,对比一下执行情况。
1.3 安装 Python
-
推荐版本:Python 3.12
-
下载exe文件,根据向导直接安装即可
1.4 配置Python环境
- 配置 Python 的执行环境,设置步骤为:
-
快捷键:
Ctrl+Shift+P(Win)或Cmd+Shift+P(Mac) - 配置运行环境,及选择解释器
- 设置操作界面如下:
-
-
-
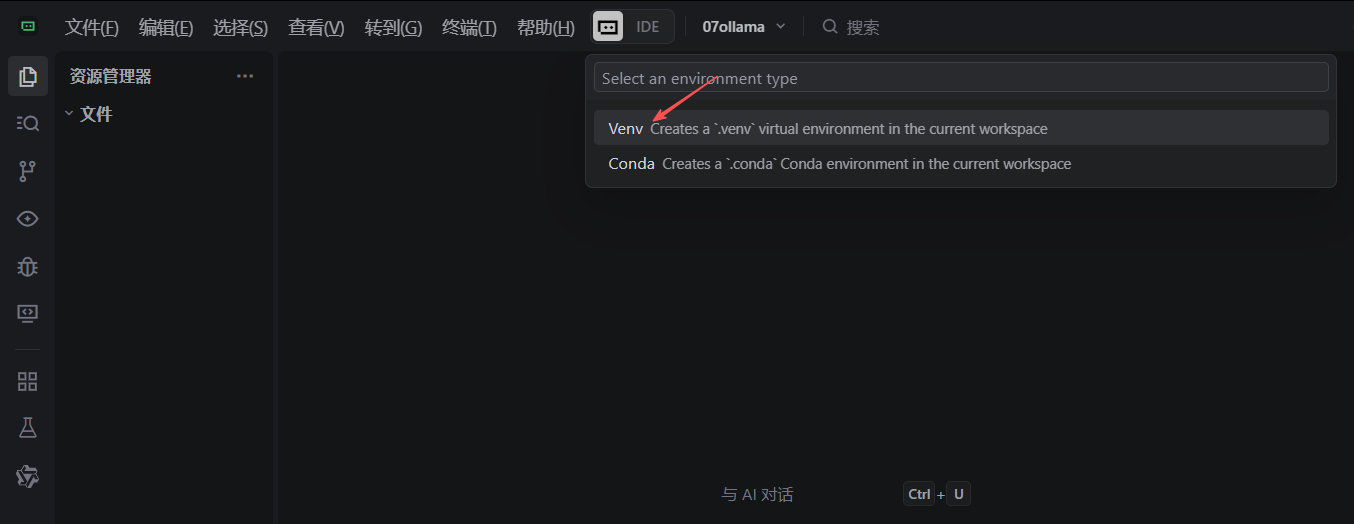
-
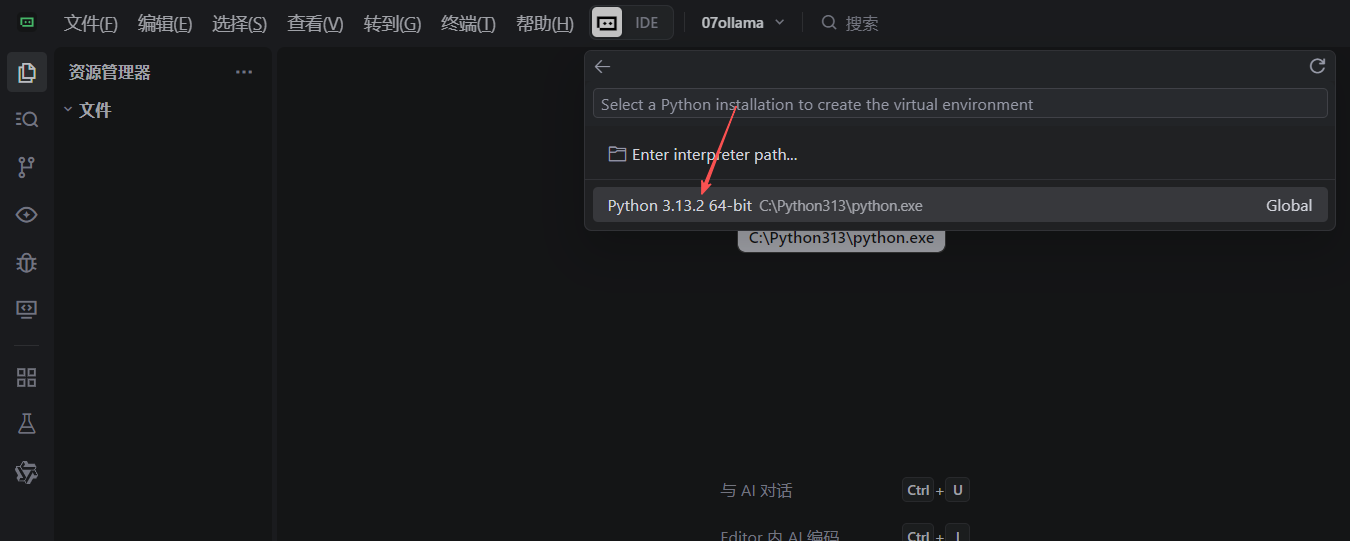
-
选择你安装的 Python 路径
-
-
-
-
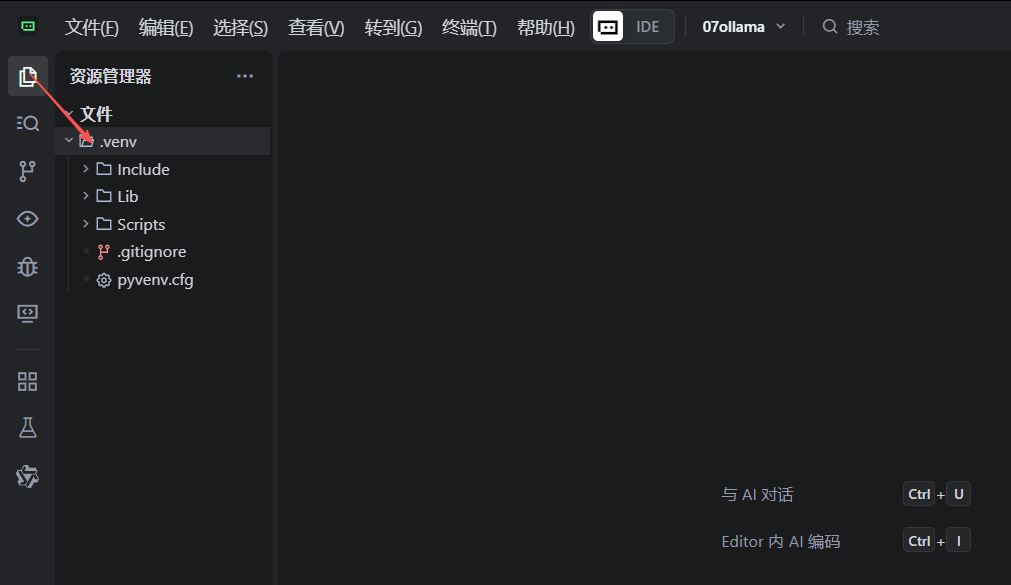
验证:在工作目录,可以看到刚创建的虚拟环境文件
二、 Ollama Python SDK 基础使用
Ollama 提供了专门的 Python SDK,这是官方维护的,与本地模型交互最直接和推荐的方式。
📜参考文档:https://github.com/ollama/ollama-python
2.1 安装与准备
条件:确保启动本地ollama服务:
ollama serve # 启动服务,默认端口 11434首先安装 Ollama Python 库:
pip install ollama2.2 同步对话调用
使用 chat 函数进行简单的同步对话生成:
from ollama import chat, ChatResponse # 导入Ollama库的chat函数和ChatResponse类型
# 调用chat函数与模型进行交互,并指定返回类型为ChatResponse
response: ChatResponse = chat(
model='deepseek-r1:8b', # 指定要使用的模型名称
messages=[{ # 提供对话消息列表
'role': 'user', # 消息角色为用户
'content': '为什么天空是蓝色的?', # 用户的对话内容
}],
)
# 两种方式访问响应内容:
print(response['message']['content']) # 字典方式访问
# 或者
print(response.message.content) # 对象属性方式访问✍️说明:
没有特别指定ollama服务地址,则默认连接到本地运行的Ollama服务,本地ollama服务获取地址的方式:
- 默认本地ollama服务地址
- 或者你设置了相关环境变量:
- export OLLAMA_HOST=你的服务器地址:端口
2.3 自定义客户端
创建自定义客户端以设置特定请求头或连接远程 Ollama 实例:
from ollama import Client
# 创建自定义客户端
client = Client(
host='http://localhost:11434', # 可替换为远程地址
headers={'x-custom-header': 'custom-value'}
)
response = client.chat(
model='deepseek-r1:8b',
messages=[{'role': 'user', 'content': '你是谁?'}]
)2.4 调节生成参数
通过 options 参数控制生成文本的随机性和长度:
from ollama import chat
response = chat(
model='deepseek-r1:8b',
messages=[{'role': 'user', 'content': '写一个关于未来的短故事'}],
options={
'temperature': 0.8, # 控制随机性 (0.1-2.0)
'num_predict': 500, # 限制生成长度
'top_p': 0.9, # 核采样参数
}
)不同参数组合适用于不同场景:
| 参数组合 | 适用场景 | 示例值 |
|---|---|---|
| 低temperature + 低num_predict | 事实性回答 | temp=0.3, num_predict=512 |
| 高temperature + 高num_predict | 创意写作 | temp=1.2, num_predict=2048 |
| 中temperature + 流式传输 | 实时对话 | temp=0.7, stream=True |
2.5 流式响应处理
对于长文本生成,流式响应能提升用户体验,实现实时输出效果:
from ollama import chat
stream = chat(
model='deepseek-r1:8b',
messages=[{'role': 'user', 'content': '讲述人工智能的发展历史'}],
stream=True, # 启用流式传输
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)2.6 异步客户端
对于需要高并发或实时输出的应用,异步处理非常重要,使用 AsyncClient 处理并发请求:
import asyncio
from ollama import AsyncClient
async def main():
client = AsyncClient()
message = {'role': 'user', 'content': '解释一下量子计算的基本概念'}
response = await client.chat(
model='deepseek-r1:8b',
messages=[message]
)
print(response['message']['content'])
asyncio.run(main())2.7 异步流式响应
结合异步与流式处理实现高效实时输出:
import asyncio
from ollama import AsyncClient
async def main():
client = AsyncClient()
message = {'role': 'user', 'content': '详细说明机器学习的主要类型'}
async for part in await client.chat(
model='deepseek-r1:8b',
messages=[message],
stream=True
):
print(part['message']['content'], end='', flush=True)
asyncio.run(main())2.8 模型管理与操作
Ollama 还提供了丰富的模型管理功能。
2.8.1 列出本地模型
from ollama import Client
client = Client()
models = client.list()
for model in models['models']:
print(f"模型: {model['name']}, 大小: {model['size']}")2.8.2 拉取与删除模型
from ollama import Client
client = Client()
# 拉取新模型
client.pull('llama3.2')
# 删除模型
client.delete('deepseek-r1:8b')三、 直接调用 REST API
Ollama 提供标准 HTTP 接口,直接通过 HTTP 请求调用 Ollama 的 REST API,最底层、最通用的方式,适合跨语言调用、网关接入、协议级控制。
📜参考文档:https://ollama.readthedocs.io/en/api/
3.1 安装与准备
条件:确保启动本地ollama服务:
ollama serve # 启动服务,默认端口 11434首先安装 requests Python 库:
pip install requests3.2 文本生成 API
使用 /api/generate 端点进行单次文本生成,使用简单的 prompt 字符串作为输入, 每次请求都是独立的,不自动维护对话上下文,通常更轻量,适合简单的生成任务:
| 端点 | 设计目的 | 适用场景 |
|---|---|---|
/api/generate |
单轮文本补全/生成 | 文本续写、代码补全、内容生成 |
示例:
import requests
url = "http://localhost:11434/api/generate"
payload = {
"model": "deepseek-r1:1.5b",
"prompt": "为什么天空是蓝色的?",
"stream": False # 设为 True 可启用流式响应
}
response = requests.post(url, json=payload)
result = response.json()
print(result.get("response", ""))3.3 多轮对话 API
使用 /api/chat 端点实现多轮对话记忆,使用结构化的 messages 数组,包含角色和内容,设计用于多轮对话,可以维护完整的对话历史,在处理长对话历史时可能需要更多资源,但提供了更好的对话体验:
| 端点 | 设计目的 | 适用场景 |
|---|---|---|
/api/chat |
多轮对话交互 | 聊天机器人、问答系统、对话应用 |
示例:
import requests
url = "http://localhost:11434/api/chat"
payload = {
"model": "deepseek-r1:1.5b",
'messages': [
{'role': 'user', 'content': '什么是蓝绿部署?'}
],
'stream': False
}
res = requests.post(url, json=payload)
print(res.json()['message']['content'])
四、OpenAI 兼容接口(openai 库)
Ollama 提供 OpenAI API 兼容层,可直接复用 openai 客户端与生态工具,这样可以复用大量已对 OpenAI 接口兼容的第三方库(如 Vercel AI SDK、部分 Agent 框架等)。
📜参考文档:https://ollama.com/blog/openai-compatibility
4.1 安装与准备
条件:确保启动本地ollama服务:
ollama serve # 启动服务,默认端口 11434首先安装 openai Python 库:
pip install openai4.2 多轮对话:Chat Completions API
OpenAI 的 Chat Completions API 是用于与 ChatGPT 系列模型交互的主要接口,它允许开发者构建对话式 AI 应用。这个 API 设计用于多轮对话场景,支持复杂的交互模式。
# 导入OpenAI客户端库
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1', # Ollama服务的兼容端点
api_key='ollama' # 伪API密钥,Ollama不需要认证但客户端库要求此参数
)
# 使用OpenAI客户端库的格式与Ollama服务交互
resp = client.chat.completions.create(
model='deepseek-r1:1.5b', # 指定要使用的本地模型名称
messages=[ # 对话消息列表
{
'role': 'user', # 消息角色为用户
'content': '请列出三种部署策略' # 用户的消息内容
}
]
)
print(resp.choices[0].message.content) # 打印模型的响应内容
⚠️注意:OpenAI 兼容层与原生
/api/*的参数名/行为上有细微差异(例如函数调用、embeddings 支持可能随 Ollama 版本演进),必要时查阅官方兼容说明。
五、框架集成(LangChain、LlamaIndex等)
很多成熟框架已有 Ollama 适配器,能快速接入 RAG、Agent、多模型 orchestrations,或在现有应用中替换模型提供端。常见:LangChain 的 langchain-ollama、LlamaIndex 的 Ollama LLM 插件、Microsoft AutoGen 的 Ollama 客户端 等。框架层面提供缓存、chain、工具调用、memory、RAG pipeline、评估等丰富功能,能显著缩短工程实现周期。
本方式的特点为:
-
快速构建复杂应用(RAG、Agent、Tool Use)
-
支持流式、异步、重试、缓存等高级特性
-
与 Ollama 本地部署无缝对接
📜参考文档:https://python.langchain.com/docs/integrations/llms/ollama/
5.1 安装与准备
条件:确保启动本地ollama服务:
ollama serve # 启动服务,默认端口 114345.2 LangChain 示例
首先安装 相应的Python 库:
pip install langchain-ollama示例代码:
# 导入 LangChain Ollama 包中的 ChatOllama 类
# 这是与 Ollama 服务交互的官方推荐方式(替代已弃用的 langchain_community 中的版本)
from langchain_ollama import ChatOllama
# 创建 ChatOllama 实例,配置连接参数
llm = ChatOllama(base_url='http://localhost:11434', model='deepseek-r1:1.5b')
# 调用模型生成回答
# invoke 方法是 LangChain 中与语言模型交互的标准方法
# 参数为用户的查询文本
resp = llm.invoke('请列出三种部署策略')
# 打印模型的回答内容
# resp.content 包含了模型生成的文本回答
print(resp.content)⚠️注意:不同框架对 Ollama 的接口假设(completion vs chat、json_mode 支持)可能不同,阅读对应集成文档很重要。
六、subprocess(调用 CLI)
通过 Python 的 subprocess 模块调用 Ollama CLI,本质上是让 Python 脚本能够执行 Ollama 的命令行指令并获取其结果。这在一些特定场景下会很方便,例如需要与现有命令行工具集成,或者在不便直接使用 HTTP API 时。
本方式特点:
-
无需安装 SDK 或 HTTP 客户端
-
可嵌入 shell 工具链
-
适合离线环境或快速原型
缺点:
- 做不了太复杂的事情
- 只能调用ollama命令行,局限性比较大,灵活性差
📜参考文档:Essential Ollama CLI Commands - KodeKloud Notes
5.1 安装与准备
条件:确保启动本地ollama服务:
ollama serve # 启动服务,默认端口 11434🎉subprocess 是 Python 的标准库(内置库)之一,不需要额外安装。
5.2 对话示例
通过 subprocess 调用 Ollama 的 run 命令来与模型交互。
# -*- coding: utf-8 -*-
import subprocess
def run_ollama(model: str, prompt: str) -> str:
"""
通过 subprocess 调用 Ollama 命令行工具运行模型并获取响应
参数:
model: 要使用的模型名称
prompt: 提示词文本
返回:
模型生成的响应文本
"""
# 显式指定编码为 UTF-8,避免 Windows 系统上的编码错误
cmd = ['ollama', 'run', model]
proc = subprocess.Popen(
cmd,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
encoding='utf-8', # 明确指定编码为 UTF-8
errors='replace' # 替换无法解码的字符,而不是抛出异常
)
# 与进程通信并获取输出
stdout, stderr = proc.communicate(input=prompt)
# 检查命令执行是否成功
if proc.returncode != 0:
error_msg = stderr.strip() if stderr else "Unknown error"
raise RuntimeError(f"Ollama CLI error: {error_msg}")
# 安全地处理 stdout,确保它不为 None
return stdout.strip() if stdout else ""
# 测试代码:调用模型生成关于部署策略的回答
try:
result = run_ollama('deepseek-r1:1.5b', '请列出三种部署策略')
print(result)
except Exception as e:
print(f"Error: {e}")
⚠️ 重要说明和注意事项
Ollama 安装与路径:确保 Ollama 已正确安装并在系统的 PATH 环境变量中,这样 Python 才能找到
ollama命令。性能与阻塞:
subprocess.run会阻塞当前 Python 进程,直到 Ollama 命令执行完毕。对于生成时间较长的回复,这可能会导致程序“卡住”一段时间。如果需要异步操作,可以考虑使用subprocess.Popen。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)