(边学边写系列)面向意图的顺序推荐模型:IOCLRec--中科大
这篇发表在AAAI上的文章提出IOCLRec框架,通过动态建模用户意图改进序列推荐。方法将用户历史交互分割为粗粒度意图子序列,设计三个对比学习模块:细粒度意图聚类实现跨用户对比;单意图模块增强主导意图;多意图模块捕捉意图转换。实验在亚马逊数据集上验证了其优于现有模型(HR@20提升4.12%)。该工作创新性地将意图动态性与对比学习结合,为可解释推荐提供新思路。
论文标题:“Intent Oriented Contrastive Learning for Sequential Recommendation”
论文地址:![]() https://ojs.aaai.org/index.php/AAAI/article/view/33390论文于2025年发表在顶会AAAI
https://ojs.aaai.org/index.php/AAAI/article/view/33390论文于2025年发表在顶会AAAI

注:下一篇我会学习一下该论文的前置论文,可能还会附上源码分析(时间会久一点),感兴趣的朋友可以关注我!
另外有任何问题都欢迎在评论区积极交流讨论,作者也是抱着学习的态度进行分享~
①文章概述
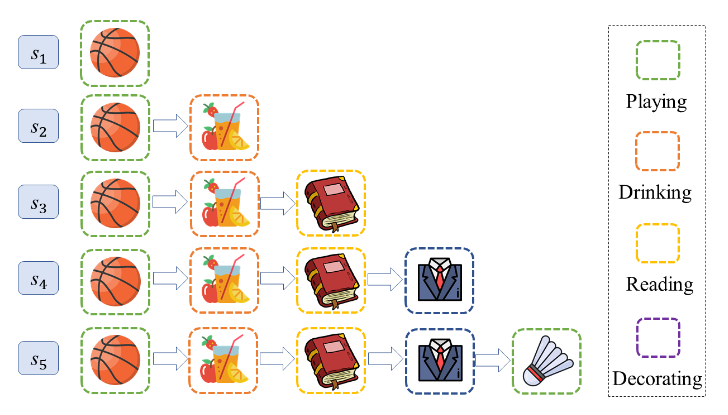
对于用户来说,其与物品的交互是由意图驱动的(例如,购买跑鞋是为了锻炼),准确识别用户意图对于理解用户行为至关重要,并且在增强和解释推荐系统方面具有巨大潜力。现有方法通过对用户的意图建模来实现强大性能,但往往忽略了这些意图在交互过程中的动态和不断发展的性质,从而导致结果不理想。如下图:用户的意图从玩耍→喝酒→阅读→装饰→玩耍
这篇文章提出了名为面向意图的顺序推荐对比学习(IOCLRec)新框架:
1.将用户历史交互序列动态分割为代表不同交互时间粗粒度意图的子序列
2.将粗粒度意图作为对比学习的单元,设计了三个对比学习模块
3.细粒度意图对比学习模块:将所有粗粒度意图聚类,得到细粒度的意图表示
4.单意图对比学习模块:采用三个单意图增强算子,增强用户行为子序列的主导意图
5.多意图对比学习模块:采用两个多意图增强算子,增强用户行为子序列的多元意图
②模型框架
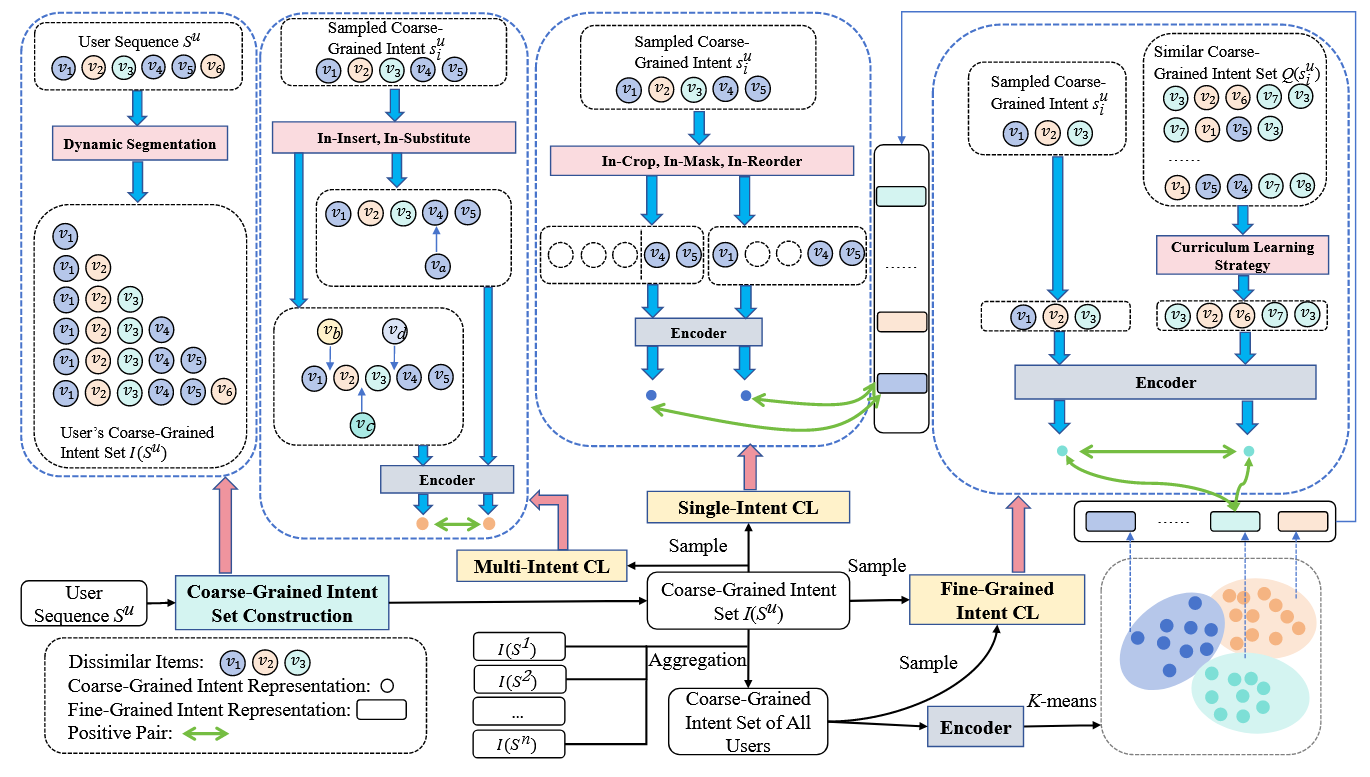
模型的整体结构如上图所示,比较复杂,下面逐步拆分进行讲解:
a.项目关联性建模
用户倾向于根据类似的意图与类似的项目进行交互,因此在对意图建模前需要对项目进行建模
通过BERT模型捕获项目文本描述的信息:
![]()
给定两个项目 vi 和 vj ,其相关分数定义:
![]()
其中,C是协同过滤分数、T是时间间隔、R是项目文本表示的余弦相似度
Φ函数定义如下(Θ、Γ、Ω都是常量):在 Φ 函数中,x 增大或 y、z 的减少都会使 Φ 降低
![]()
对于项目 , 如果项目
与其出现在同一用户序列中,其中
相关性最高的 k 个邻居称之为 k 邻居
b.序列波动性建模
对于用户给定历史交互序列 Su ,引入序列波动性(定义为相邻项目相关性的标准差):
用户交互序列 ![]()
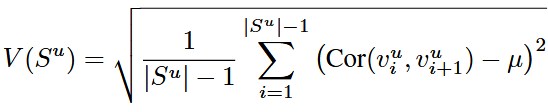
c.用户粗粒度意图集构造
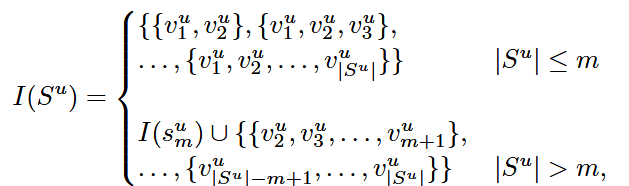
定义一个最大序列长度 m。如果用户交互序列小于 m,则从开头逐步累积的所有子序列;如果用户交互序列大于 m,则确保集合覆盖历史意图的渐进演化
d.用户细粒度对比学习模块
步骤一:意图聚类
首先对用户历史交互序列进行序列编码操作:
![]()
编码后的结果:![]()
然后应用 K-means 聚类获得 K 个意图中心:
步骤二:相似意图的跨用户对比学习
如何寻找可对比的粗粒度样本?
从其他用户的粗粒度集合中构造一个集合 ,这里包含的所有子序列都要求:以项目
结尾,Q 中子序列的前 k1 项是
对应项的 k2 邻居,如果上述条件下没能找到 r 个子序列,则要放宽条件
· 逐步减小 k 直至减为0
· 最后一项不是 而是其邻居,同时需要确保前面 k1 项是对应项的 k2 邻居
确保在跨用户范围内,为当前子序列找到“语义与意图极近似”的对照样本,用于构造强正样本
如何在集合 Q 中选择正样本?
模拟人类先易后难的学习过程,对于 Q 中序列 ,计算复杂度
,考虑如下因素:
· 序列的波动性 V
· 最近 g 个 epoch 中聚类中心发生变化的次数 D
![]()
然后给每个候选序列设计一个动态权重 :
![]()
其中,e 代表训练的 epoch 数,前期 e 较小,更偏向低复杂度的样本;后期更趋向均匀样本
从 Q 中采样到 s’ 后,使用对比学习来减少潜在空间中 s' 与原序列 的差异:
![]()
![]()
其中,h1、h2代表两序列的编码表示,F 用于将假负样本剔除
步骤三:粗到细的意图对比学习
在上一步中,已经把两段相似的粗粒度子序列编码为 h₁、h₂,并且每个子序列都能映射到其对应的细粒度意图中心 c₁、c₂:
![]()
e.单意图对比学习
每个子序列的最后一个项目 被视为最能指示该用户当前交互意图的关键标志,通过学习这个标志来聚焦用户的核心意图,论文提出了三个单意图数据操作符,用于增强子序列的表示:
In-Crop操作符
从序列 中选择截断位置,保留截断点以后的所有项目,确保这个子序列长度不小于 l ,找到所有满足要求的子序列,计算与最后一项的相关分数,选择得分最高的子项:
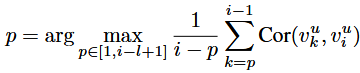
In-Mask操作符
通过相关性分数计算序列 中剩余项与最后一项
的分数,根据比例屏蔽分数最低的 η 个项:
![]()
In-Reorder操作符
首先通过 IC 操作符提取子序列,然后对子序列中的项按照与 的相关性进行排序,获取排序序列索引,最终序列根据索引重新排序:
![]()
增强单意图的对比学习
通过上述三种操作符生成增强的子序列后,论文通过对比学习来最小化增强子序列与用户主要意图(即细粒度意图表示)之间的距离:
![]()
f.多意图对比学习
用户的行为序列通常涉及多个不同的意图,这部分通过在不同意图之间进行对比学习,帮助模型捕捉和区分这些变化的意图。引入了两个多意图数据运算符,增强用户意图的转换模式和共现模式
In-Insert操作符
该操作符通过在用户意图转换的地方插入与当前意图相关的项,从而平滑用户的意图转换过程,使用下式计算意图转换分数:
![]()
Sim(pt):表示位置 和位置
之间的相关性
Rec(pt):表示基于前一个训练轮次的预测损失,损失计算公式如下:
![]()
Intent(pt):表示如果 与
在前一轮次代表不同的细粒度意图,则该值为常数 c,否则为0
对意图转换分数进行排序,对得分最高的 与
间插入与两者最相近的项目以平滑过渡
In-Substitute操作符
使用与 In-Insert 相同的方法计算每个位置的意图转换分数,但该运算符选择转换分数最小的相邻对 ,在两者公共近邻集合中选择对两者总相关性最高的物品对其中一个物品进行替换
目的是什么?
低 Tran 代表相邻两物品更像处于同一细粒度意图内部,在这些位置做“近义替换”能扩展同意图共现而不引入新的意图边界
将同一序列应用上述两种不同的多意图算子得到一对扩增序列 视为正对,通过编码器,计算对比损失:
![]()
g.多任务训练
使用多任务学习范式共同优化主顺序预测任务和其他辅助学习目标,可以表述为:
![]()
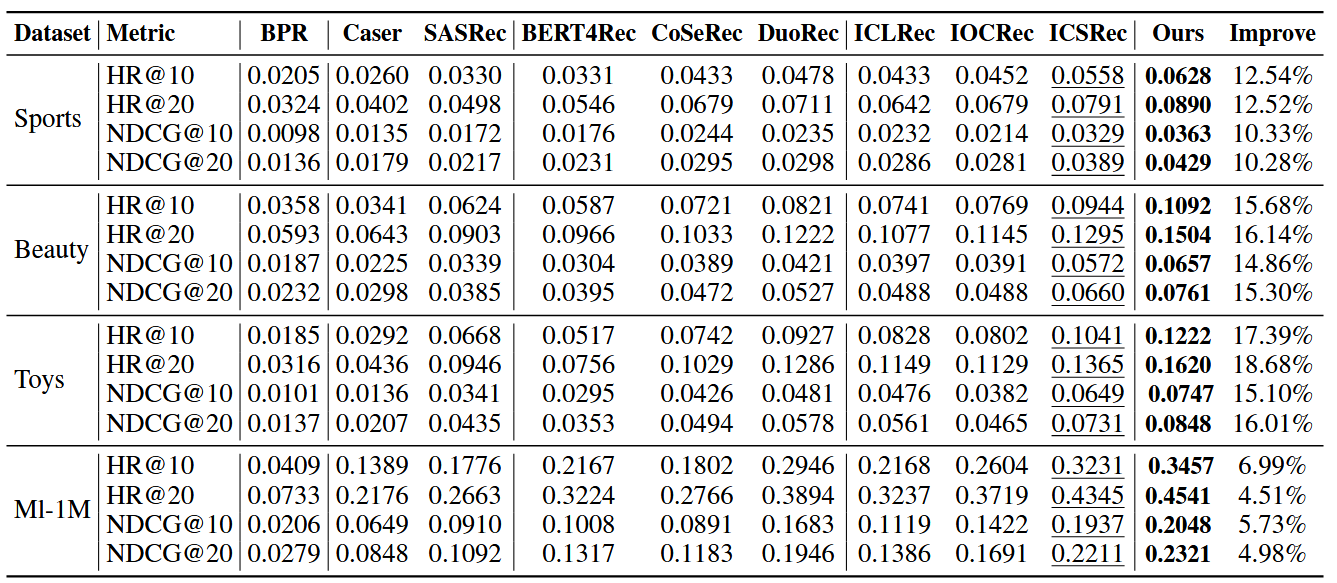
③实验
a.实验准备
数据集:使用了亚马逊产品评论数据集中的三个子类别:Sports, Beauty, Toys
评估指标:使用了k=10、20的 HR@K 和 NDCG@K
baseline模型:见下方实验结果,分别包含:非顺序模型、通用顺序模型、使用 SSL 的顺序模型、意图引导的顺序模型
b.实验结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)