蒸馏学习 Knowledge Distillation
本文介绍了知识蒸馏技术及其应用。知识蒸馏是一种模型压缩方法,通过让小型学生模型学习大型教师模型的输出,在保持性能的同时显著减少计算资源需求。该方法适用于将云端大模型(如ResNet-152、BERT)压缩为移动端小模型(如MobileNet、TinyBERT)。核心原理包括: 利用教师模型的软标签(概率分布)传递"暗知识"; 设计联合损失函数(任务损失+KL散度蒸馏损失); 特
1. 简述
-
蒸馏学习, Knowledge Distillation, 一种模型压缩技术, 可节省计算资源, 同时模型性能折损很小.
-
使用场景: 云端模型参数量大, 可用 ResNet-152、BERT 等大模型蒸馏出 MobileNet、TinyBERT 等学生模型, 便于直接部署在手机等设备上.
-
原始论文
Hinton 的原始论文(2015)
教师:深度神经网络在MNIST上训练。
学生:浅层网络。
结果:学生模型通过学习教师的软标签,性能远超直接训练。
2. loss 设计
-
模型角色. 分为教师(teacher) 模型与学生(student) 模型
-
硬标签与软标签
- 硬标签为分类任务中, 数据集的原始标签.
- 软标签, Soft Labels, 为教师模型输出的 概率分布, 它包含了类别间的相似性等 “暗知识”(Dark Knowledge).
-
损失函数
L total = α ⋅ L task + ( 1 − α ) ⋅ L distill % 总损失(Total Loss) \mathcal{L}_{\text{total}} = \alpha \cdot \mathcal{L}_{\text{task}} + (1 - \alpha) \cdot \mathcal{L}_{\text{distill}} Ltotal=α⋅Ltask+(1−α)⋅Ldistill
alpha 参数用于调节二者的重要性.
蒸馏损失部分为 带温度的KL 散度(Kullback-Leibler Divergence).
L distill = T 2 ⋅ D KL ( p teacher ∥ p student ) % 蒸馏损失(KL 散度,带温度) \mathcal{L}_{\text{distill}} = T^2 \cdot D_{\text{KL}}\left(p_{\text{teacher}} \parallel p_{\text{student}}\right) Ldistill=T2⋅DKL(pteacher∥pstudent)
3. 特征蒸馏
知识蒸馏中, 仅用到了教师模型最后一层的输出(logits), 不够充分, 所以特征蒸馏(Feature Distillation)同时学习中间层的分布, 优势是:
- 能传递 Teacher 的中间语义信息(局部到全局的渐进抽象过程)
- 对训练初期引导更好,收敛快
典型的做法是, 令学生向老师在某层直接对齐,
L feat = ∥ F l S − F l T ∥ 2 2 % 单条样本的 L2 损失 \mathcal{L}_{\text{feat}} = \| F^S_l - F^T_l \|_2^2 Lfeat=∥FlS−FlT∥22
F l S F_l^S FlS :Student 模型在第 l 层的特征图(feature map)
F l T F_l^T FlT:Teacher 模型在第 l 层的特征图
L2 范式: 实现上通常就是 MSELoss.
4.搜推领域 cvr 预估的 优势特征蒸馏
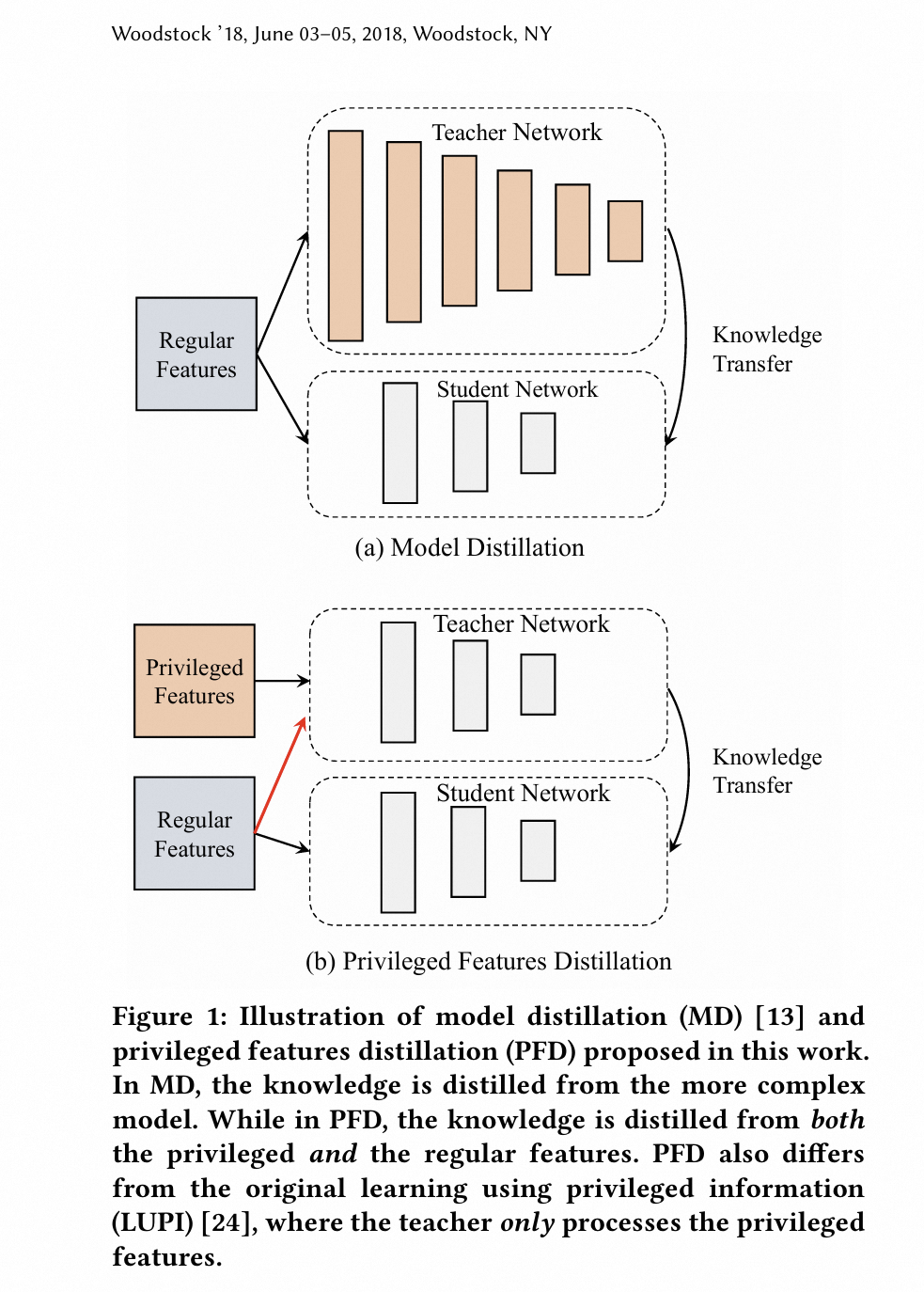
优势特征蒸馏, Privileged Feature Distillation(PFD), 与上文的 特征蒸馏 并不是一回事.
4.1 优势特征介绍
在商品信息流推荐中, 像 在详情页的停留时长这个特征, 尽管能极大地提升CVR预估的准确率,但线上预测时却无法获取这样的后验(post-event)特征,因为先有推荐才有曝光, 才有用户的后续行为。
将这种区分度高、但只能离线获取的特征定义为优势特征(Privileged Features).
4.2 优势特征蒸馏
与常规蒸馏学习的差异:
- 教师模型可以用 优势特征, 学生模型(线上推理模型) 只能用常规特征.
- 教师模型与学生模型同时训练.
- loss 只用到教师模型最后一层输出.
参考
- 优势特征蒸馏在手淘信息流推荐中的应用, Privileged Features Distillation at Taobao Recommendations

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)