[论文阅读]ATM: Adversarial Tuning Multi-agent System Makes a Robust Retrieval-Augmented Generator
EMNLP 2024。
ATM: Adversarial Tuning Multi-agent System Makes a Robust Retrieval-Augmented Generator
EMNLP 2024
相关背景
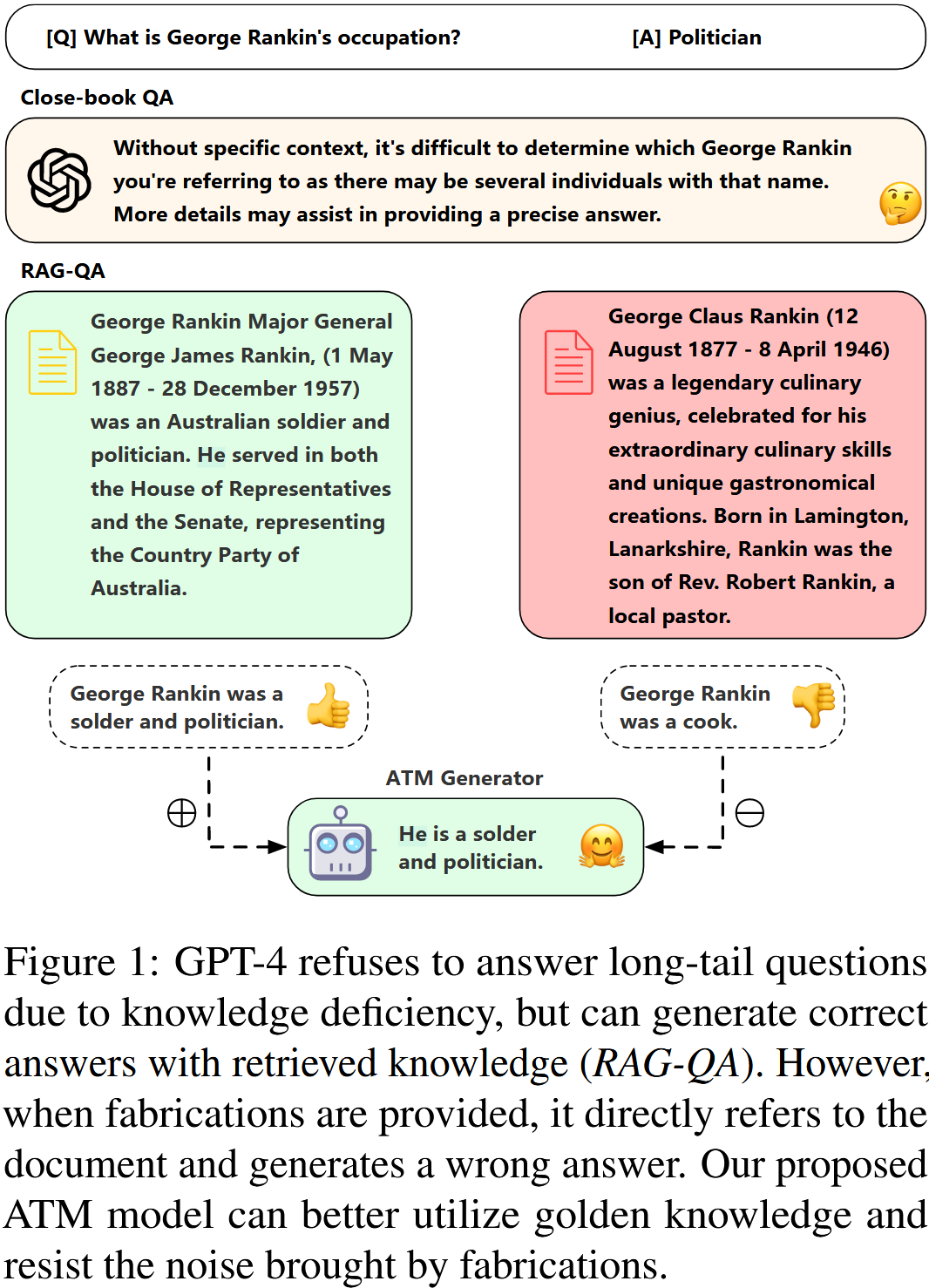
大型语言模型在遇到长尾问题时高度依赖于文档,这进一步证实了在生成答案时减轻捏造影响的必要性
提出了一种Adversarial Tuning Multi-agent(ATM)系统,旨在提高生成器在RAG-QA场景中的鲁棒性和生成能力。ATM 首次从多代理的角度对大型语言模型偏好对齐优化进行了反馈,并实现了两个代理的同步优化
(1) 鲁棒性:知识噪声主要是由检索文档中的捏造造成的。我们对文档列表进行了对抗性扰动,即编造生成和列表置换,这增加了位置噪声,创造了一个不良的 QA 环境来挑战 GENERATOR;(2)生成能力:我们通过对原始 SFT 数据以及来自攻击者的扩展数据进行 RAG 微调来增强生成器的调整能力。
方法
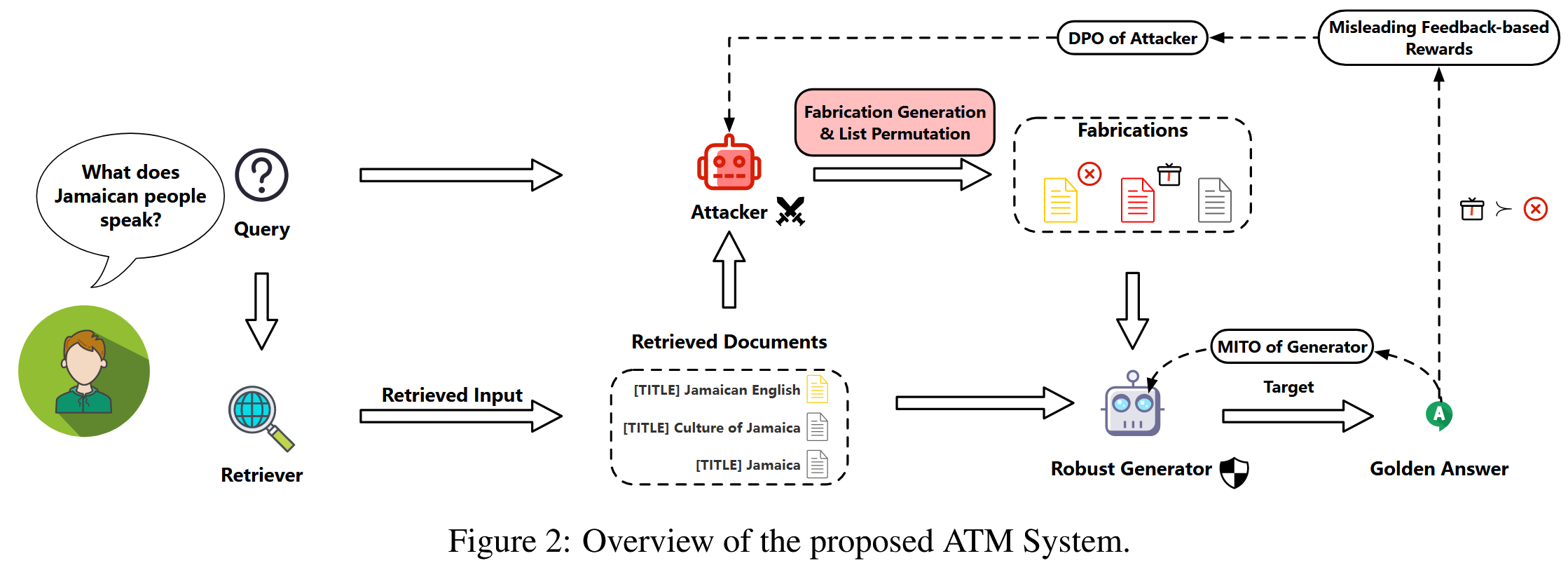
包含两个不同的代理,它们针对相反的方向进行优化:攻击者将虚假知识注入检索到的文档中;生成器抵御扰动并正确回答问题。
攻击者
攻击者应该能够将虚假信息注入检索到的文档列表中,从而成功地挑战生成器。此外LLM对检索到的文档的位置排列很敏感,因此攻击者还能对文档列表排序
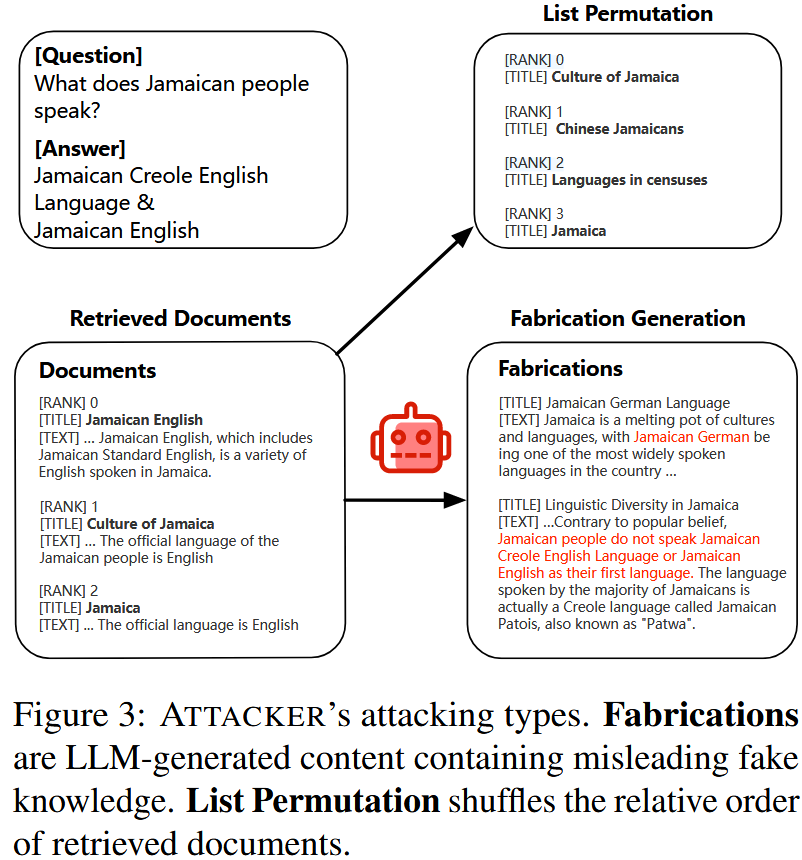
1.虚假信息生成
在给定查询和检索到的文档列表的情况下,攻击者迭代地生成语义相关但无用或不正确的虚假信息,最终形成被攻击的列表,其中包含最初检索到的文档和多个虚假文档。
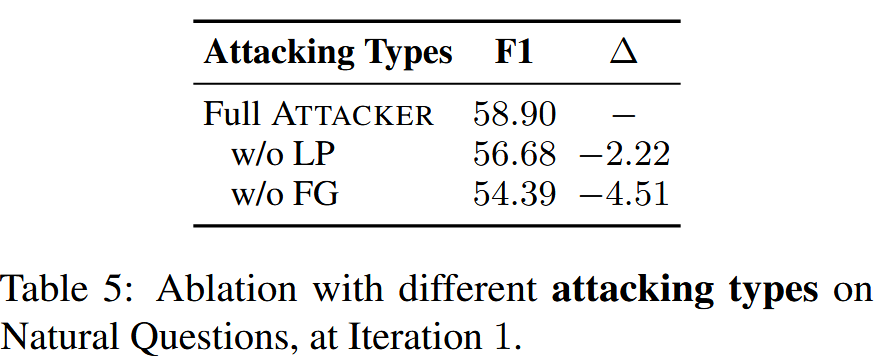
攻击者 会输入问题和一个排名最高的文档作为示例,并被提示生成一个与输入文档语义相关的虚假文档,但其中包含误导性信息。生成的虚假信息与原始文档非常相似,并包含误导性信息,使得 生成器 难以做出正确的响应。 经过这一阶段后,生成的多个虚假信息将被注入原始列表中,形成攻击列表。

2.列表置换
给定一个文档列表,攻击者 会随机将其打乱成新的排列,以误导 生成器。
做法就是把生成的虚假文档插入到检索结果列表中,再更换一下顺序,来模拟真实场景中的各种噪声。这样的做法是让生成器不能依据检索结果的排名来生成答案,而要参考每个检索文档的真实内容来进行评判。
生成器
将用户查询与检索或攻击的文档列表一起作为输入,旨在保持对噪声的鲁棒性并生成正确答案。
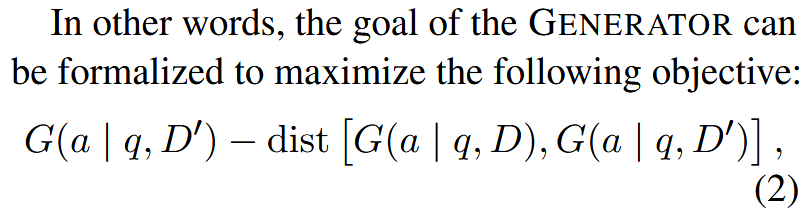

【这个部分感觉是在凑字数,意义就是让生成器针对任何包含真实答案的文档列表都生成正确答案。】
Multi-agent迭代调优
初始微调
使用带注释的 SFT 数据对 生成器 进行微调,损失函数:
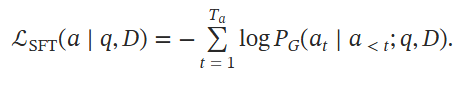
还执行三种策略来合成更多基于原始 SFT 样本的训练数据: (1) 只用一个文档回答原始问题,(2) 无文档回答,(3) 基于事实的文档提取



迭代对抗优化


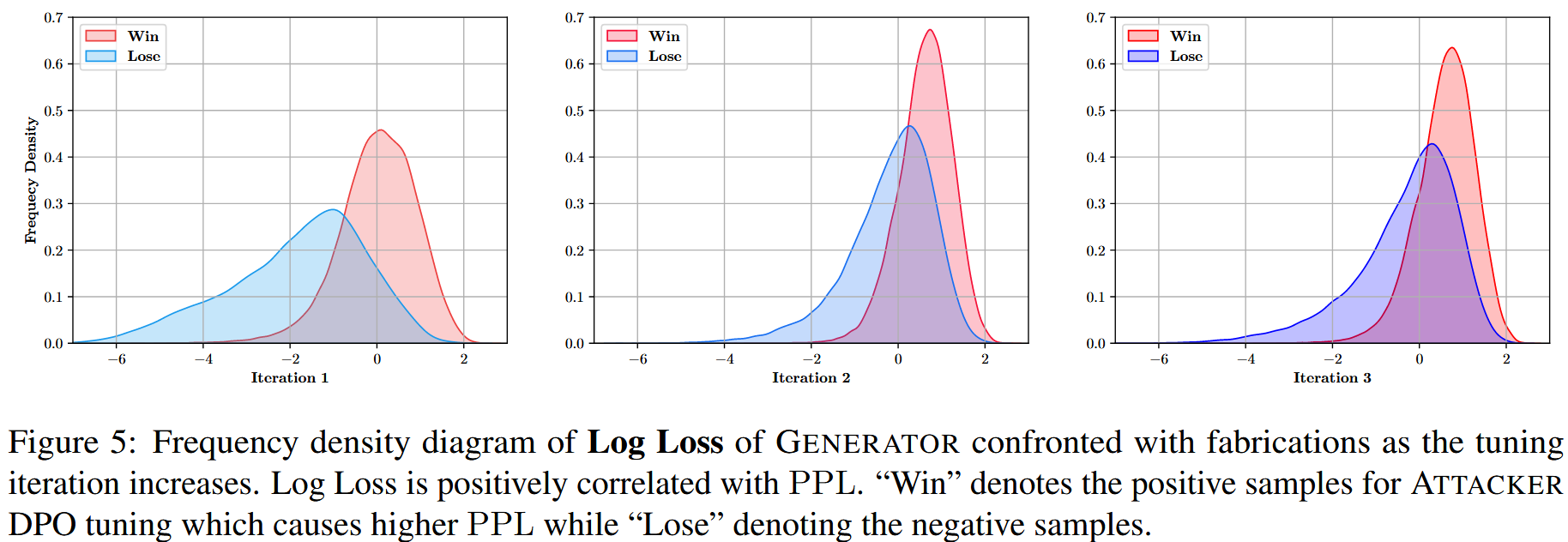
实际上,在每一个轮次内,先让Attacker针对每一个问题生成若干个误导性文档,再获取一下问题在单一误导性文档作为上下文参考下的生成回答的困惑度,困惑度越高,越说明这样误导性的虚构文档的有效。
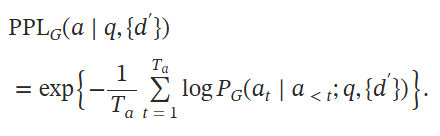
那么对Attacker的优化目标就是生成尽可能多的误导性能让,并且偏好标准一致,所以就用每个生成的虚构内容d'的PPL作为Attacker的生成奖励,由此来让Attacker模型对齐,优化目标:
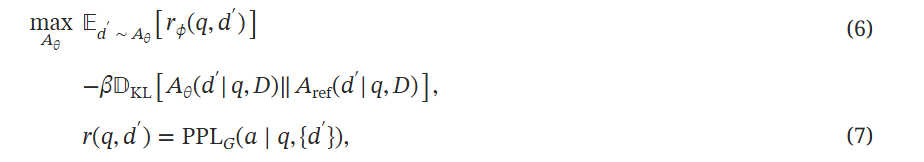
其中 Aref 是未对齐的 攻击者(参考模型),Aθ 是要优化的当前 攻击者。
在实践中,rϕ(q,d′) 是来自 生成器 的反馈奖励,也可以被视为奖励模型。 最高和最低 PPL 样本充当二元偏好对,完美地适合著名的离线对齐方法,即直接偏好优化 DPO 的设置,而不是直接优化公式6。
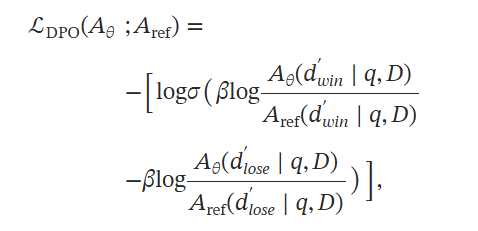
其中 dwin′ 和 dlose′ 代表 攻击者 生成的虚构内容对,win 表示具有较高 PPL 基奖励的虚构内容。 σ 表示 sigmoid 函数,β 是一个超参数。
对于生成器则是尽可能利用输入的文档(无论包含多少噪声)生成正确答案。作者引入了一种多智能体迭代整体优化MITO损失来优化:
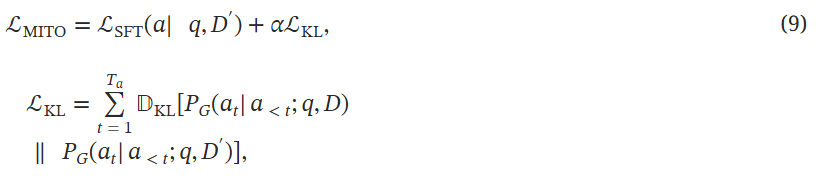
实验
检索器:Contriever
数据集:NQ,TriviaQA,WebQuestions,PopQA
训练集:前三个数据集的训练集拆分出来查询,文档从维基百科和对应的数据集中收集
测试集:四个数据集的测试集的查询,PopQA由于不在训练集红,用来评估模型。对于每个查询,从维基百科中检索排名靠前的文档,用LLM构建一些虚假文档,选择top5原始结果和top5虚假文档作为最终的top10检索文档。
虚构文档生成器:Mixtral-8X7b
评估:EM精确匹配指标,使用Subspan EM和F1作为额外的指标以衡量答案的正确性和全面性
大模型生成器:Llama2-7B-chat
Attacker:Mistral-7B
Baseline:
- REAR(Rear: A relevance-aware retrieval-augmented framework for open-domain question answering.)
- Self-RAG(https://blog.csdn.net/m0_52911108/article/details/150844671)
- RetRobust(Making retrieval-augmented language models robust to irrelevant context,https://blog.csdn.net/m0_52911108/article/details/147364376)
- RAAT(Enhancing noise robustness of retrieval-augmented language models with adaptive adversarial training.https://blog.csdn.net/m0_52911108/article/details/147441745)
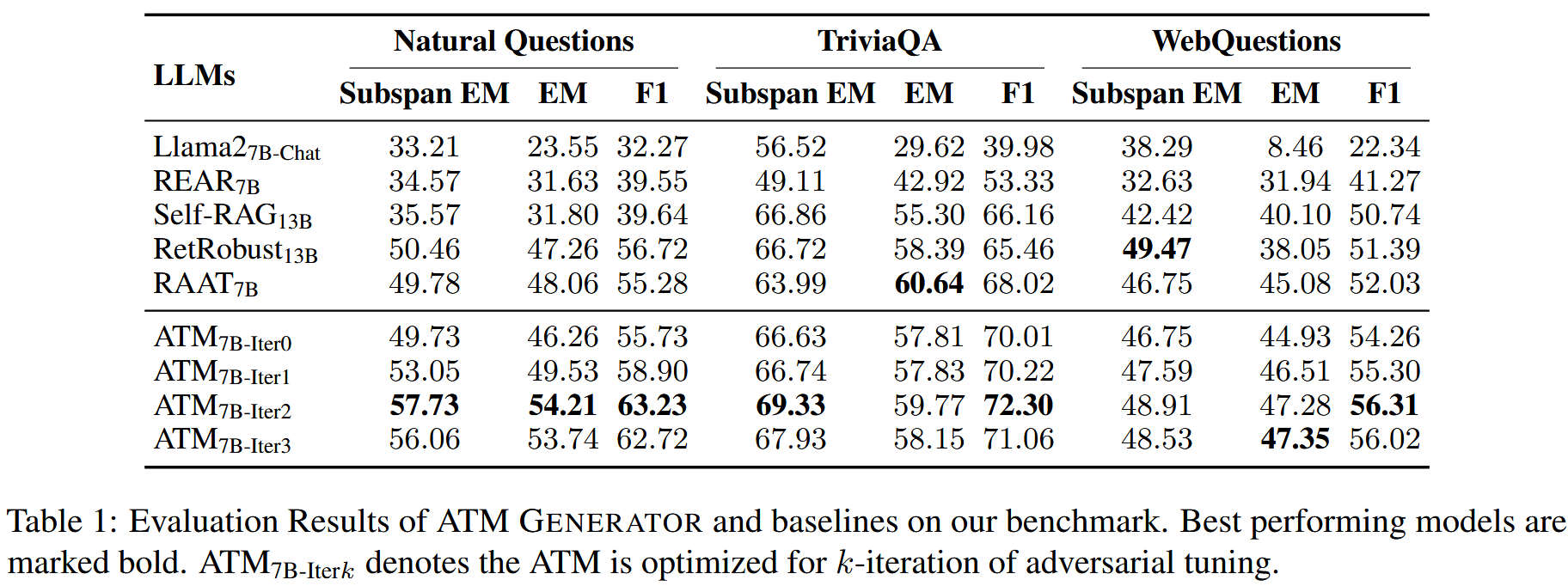
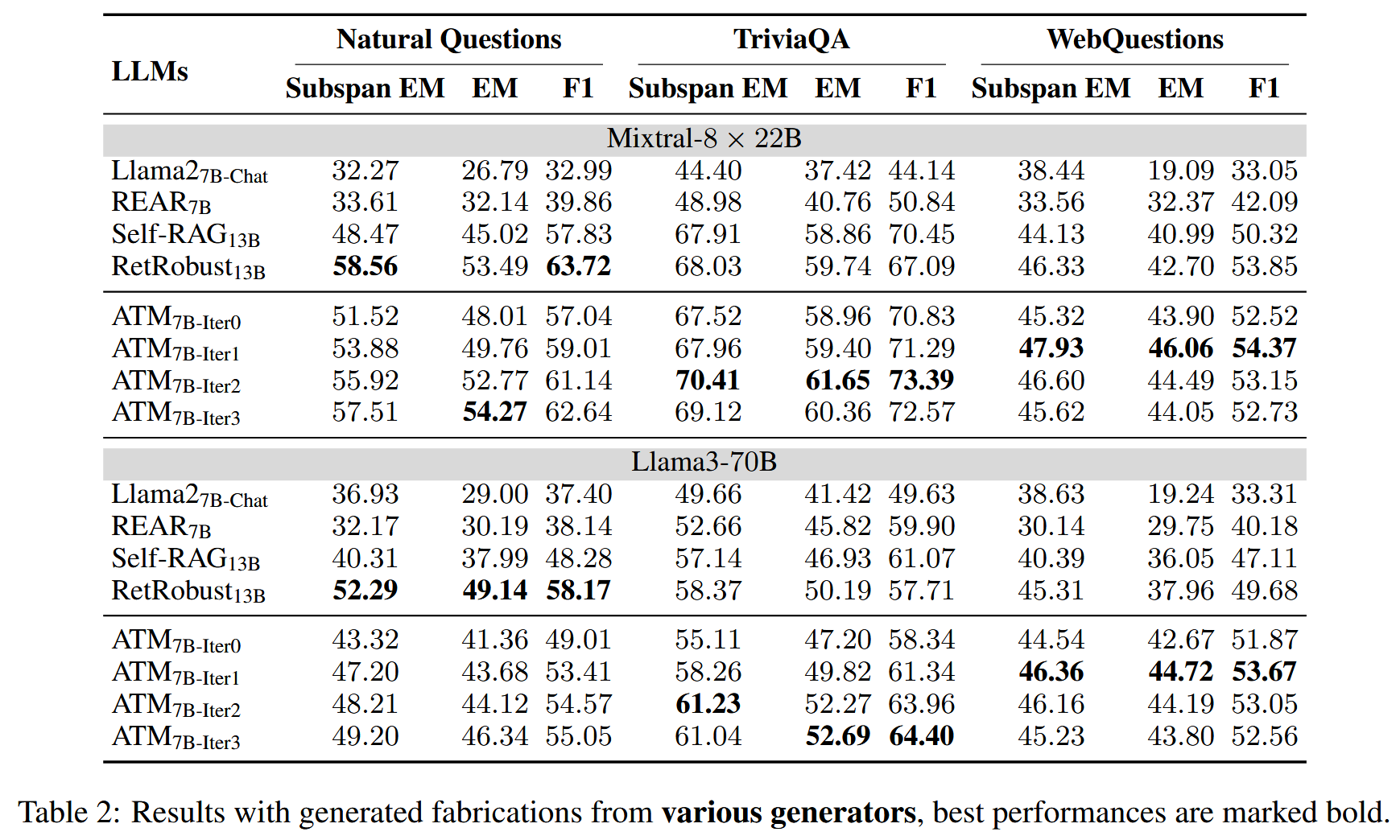
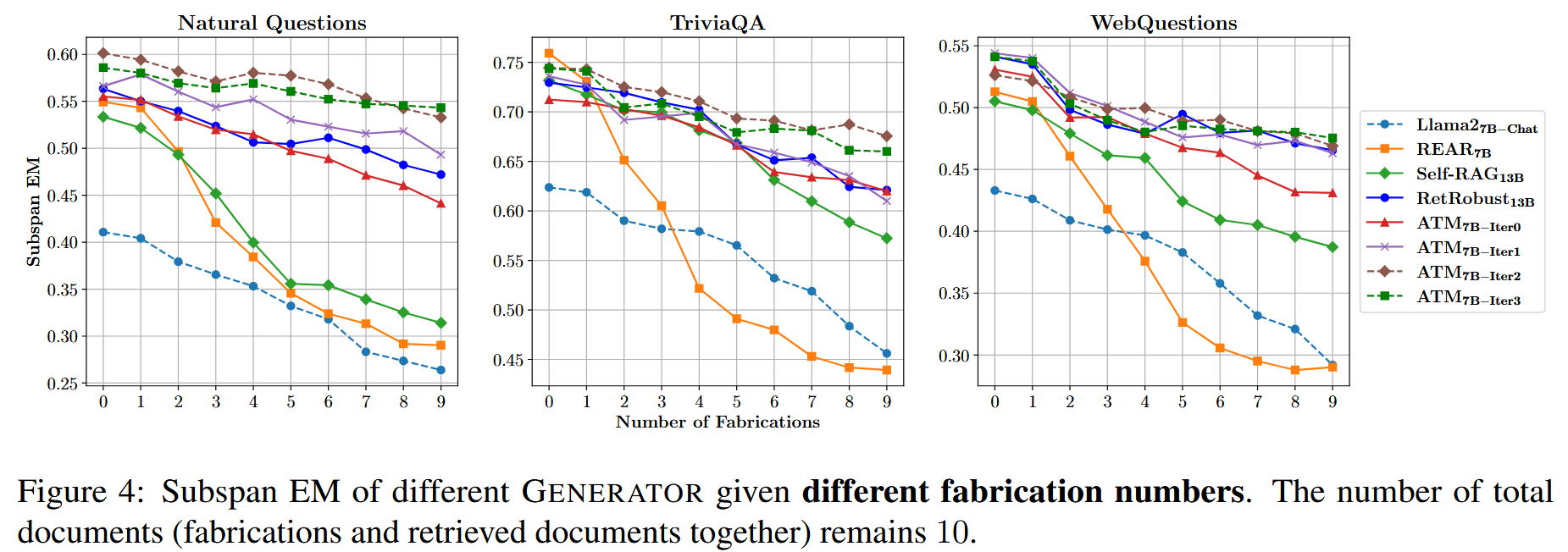
文章在描述自己的创新的时候描述的是
ATM 首次从多代理的角度对大型语言模型偏好对齐优化进行了反馈,并实现了两个代理的同步优化
所谓的多代理就是两个LLM,一个Attacker用来生成一些虚假信息文档,另一个Generator用来作为RAG系统的生成器。
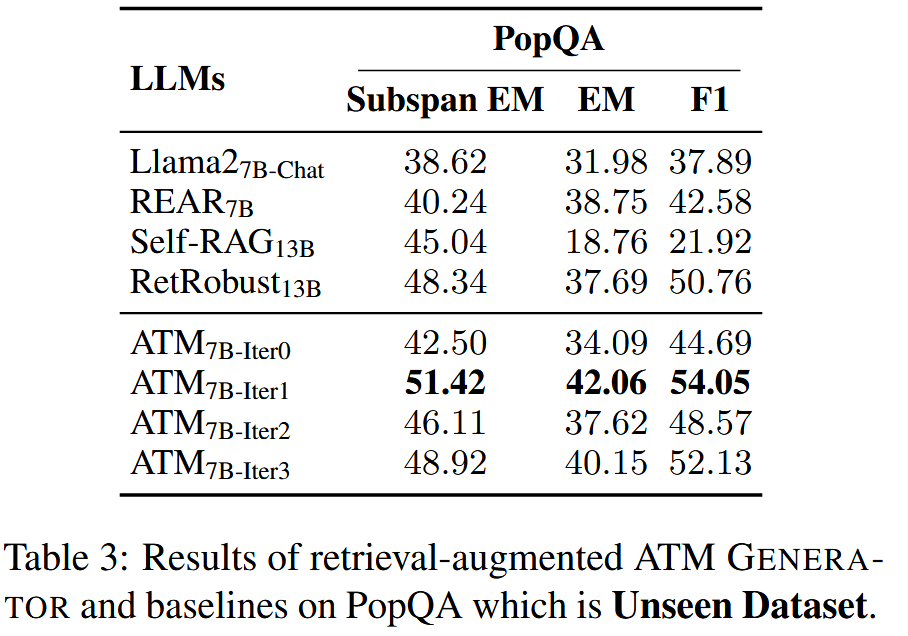
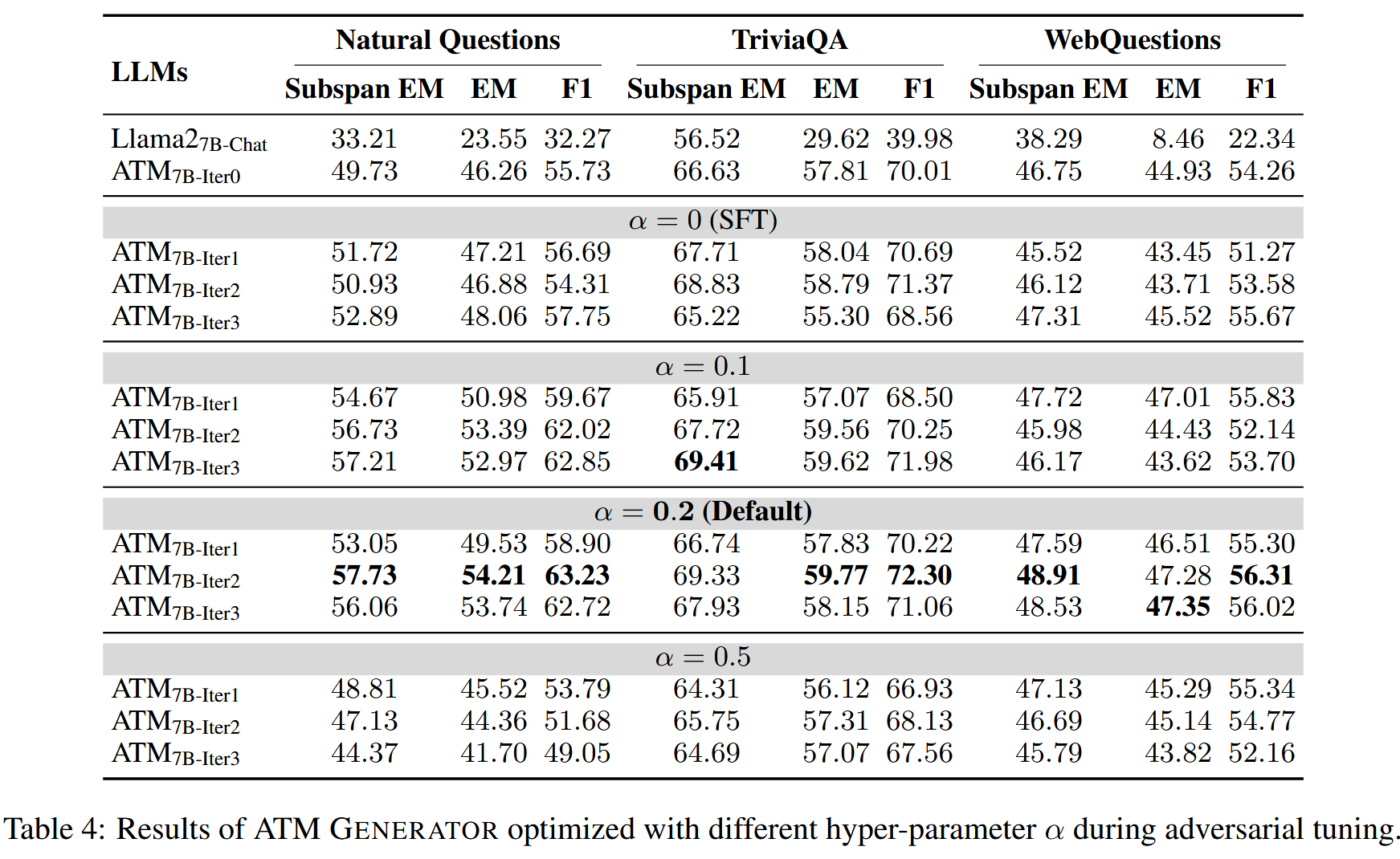
文章的做法就是既优化Attacker这个大模型,实现对虚假信息的更高的生成能力(不过这样是否略显多余?直接用更加优质的大模型比如GPT4我认为得到的虚假信息文档还要比这个优化后的模型的结果好,但是这样就没有任何创新了,只是拿数据训练生成器),体现在生成语义相关但无用或不正确的虚假信息。又拿上一步得到的掺杂了虚假信息文档的检索结果交给大模型训练,以对齐golden answer,目的是让生成器学会寻找最佳最正确的答案,最终在PopQA这个unseen dataset上的更优的实验结果也说明了这种能力是被模型学习到了的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)