Daily算法刷题【面试经典150题-2️⃣】
其实就是把暴力的o(n2)优化掉一个为o(nlogn),再确定完子数组的开始后,查找结束r需要o(n),我们采用二分查找这个满足的最小的r,因为数组中所有数都是大于0的,所以前缀和是单调的,因此可以利用前缀和。维护一个窗口,使里面的数据始终满足要求,一般来说就是用l,r分别表示区间的起点和终点,r一直往后窗口不断增大,当不满足条件时l++,窗口缩小。解释: 因为无重复字符的最长子串是 “abc”,
文章目录
📕滑动窗口
1.长度最小的子数组
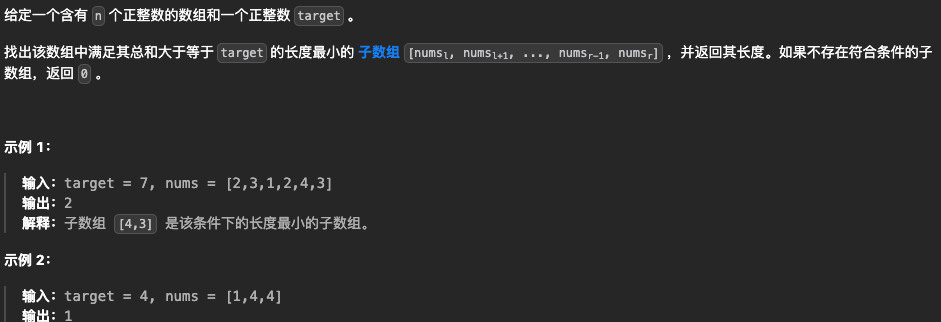
🎈法1:暴力枚举
TLE
/*
时间复杂度:O(n2)
空间复杂度:O(1)
*/
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int ans = INT_MAX;
long sum = 0;
int n = nums.size();
for(int i = 0; i < n; i++){
sum = 0;
for(int j = i; j < n; j++){
sum += (long)nums[j];
if(sum >= target){
ans = min(ans, j - i + 1);
break; //!!!找到最近的就break
}
}
}
return ans == INT_MAX ? 0 : ans;
}
};
🎈法2:滑动窗口
定义两个指针 l 和 r 分别表示子数组(滑动窗口窗口)的开始位置和结束位置
里面数的和就是就是要求的子数组的和
/*
时间复杂度:O(n)
空间复杂度:O(1)
*/
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
long sum = 0;
int n = nums.size();
for(int i = 0; i < n; i++){
sum += (long)nums[i];
}
if(sum < target) return 0;
int l = 0,r = 0;
int cur = 0;
int ans = INT_MAX;
while(r < n){
cur += nums[r];
while(cur >= target){
ans = min(r - l + 1, ans);
cur -= nums[l];
l++;
}
r++;
}
return ans;
}
};
🎈法3:前缀和 + 二分
其实就是把暴力的o(n2)优化掉一个为o(nlogn),再确定完子数组的开始后,查找结束r需要o(n),我们采用二分查找这个满足的最小的r,因为数组中所有数都是大于0的,所以前缀和是单调的,因此可以利用前缀和
class Solution {
public:
int minSubArrayLen(int s, vector<int>& nums) {
int n = nums.size();
if (n == 0) {
return 0;
}
vector<int> sums(n+1, 0);
for(int i = 1; i <= n; i++){
sums[i] = sums[i - 1] + nums[i - 1];
}
int ans = INT_MAX;
for (int i = 0; i < n; i++) {
int l = i + 1, r = n, pos = -1;
while (l <= r) {
int mid = (l + r) >> 1;
if (sums[mid] - sums[i] >= s) {
pos = mid;
r = mid - 1; // 继续向左收缩
} else {
l = mid + 1;
}
}
if(pos != -1) ans = min(ans,pos - i);
}
return ans == INT_MAX ? 0 : ans;
}
};
2.无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
🎈法1:滑动窗口
维护一个窗口,使里面的数据始终满足要求,一般来说就是用l,r分别表示区间的起点和终点,r一直往后窗口不断增大,当不满足条件时l++,窗口缩小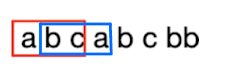
当l=0,r=3时,a重复,此时就应该l++,从窗口中取出重复的a
/*
时间复杂度:O(n)
*/
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int n = s.size();
unordered_set<char> set;
int l = 0, r = 0;
int ans = 0;
while(r < n){
// 去重
while(set.find(s[r])!=set.end()){
set.erase(s[l]);
l++;
}
ans = max(ans, r - l + 1);
set.insert(s[r]);
r++;
}
return ans;
}
};
3.串联所有单词的子串(✨)

🎈法1:暴力(TLE)
//首先枚举所有可能的子串,然后判断每个子串是否符合要求
/*
时间复杂度:O(n * num),其中 n 是字符串 s 的长度,num 是单词数组 words 的大小
空间复杂度:O(m×n) m 是 words 的单词数,n 是 words 中每个单词的长度
首先枚举所有可能的子串,然后判断每个子串是否符合要求(枚举起点,截取word字符数组那么长的长度即可)
难点在于:怎么判断每个子串是否符合要求
使用两个hashmap来解决,(1)首先,把所有的单词存到hashmap中,key存单词,value存单词出现的次数(因为单词可能会有重复)
(2)扫描子串的单词,如果当前扫描的单词在之前的hashmap中,就把这个单词存到新的hashmap中,并判断新的hashmap中此单词出现的次数是否满足要求(如果出现的次数大于之前存的hashmap1种的次数,则不符合)每次一个子串符合要求,我们就把此词串的起点i存到ans中即可
需要注意:每一个子串的判断都需要清空一下临时的hashmap
*/
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> ans;
if(words.size() == 0) return ans;
int len = words[0].size();
int num = words.size();
unordered_map<string,int> wordmap;
for(int i = 0; i < num; i++){
wordmap[words[i]]++;
}
unordered_map<string,int> tmpword;
// 符合的子串的开头
for(int i = 0; (i + len*num - 1) < s.size(); i++){
//处理子串的每个单词
int j = 0;
for(j = i; j < (i+len*num); j=j+len){
string curstr = s.substr(j, len);
if(wordmap[curstr] == 0){
break;
}else{
tmpword[curstr]++;
if(wordmap[curstr] < tmpword[curstr]) break;
}
}
if(j == (i+len*num)) ans.push_back(i);
tmpword.clear();
}
return ans;
}
};
🎈法2:滑动窗口
感觉这道是这四个滑动窗口里面最难的,主要是优化的思想
/*
时间复杂度:O(n⋅len_word)
空间复杂度是 :O(len_word)
利用滑动窗口 和 哈希表 的结合,利用滑动窗口从字符串 s 中依次提取出可能的子串,并通过哈希表统计每个单词出现的次数,检查当前窗口内的单词是否符合要求。最后,返回符合条件的所有子串的起始位置。
!!!重点是:
我们定义i 是滑动窗口的起始位置,从 0 到 len_word-1 进行遍历。
为什么要从 0 到 len_word-1?(主要是由所有单词长度都是相等的推出来的,合理利用所有信息)
如果从 wordSize 开始滑动,其实就相当于从 0 开始滑动一次。具体地,假设有两个位置 i 和 i + len_word,这两个位置实际上表示的是同样的滑动窗口,只是后者比前者多滑动了一步。为了避免重复计算,我们从 0 到 wordSize-1 进行遍历就足够了。
i + len_word * num_word <= s.size():确保当前窗口大小 不会超出字符串的范围。
*/
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
int len_word = words[0].size();
int num_word = words.size();
int n = s.size();
vector<int> ans;
// 滑动窗口的其实位置
for(int i = 0; i < len_word && i + len_word * num_word <= n; i++){
int l = i; //滑动窗口左边界
int r = i + len_word * num_word; // 滑动窗口右边界
unordered_map<string, int> curMap;
// 统计滑动窗口内的单词
for(int j = l; j < r; j+=len_word){
curMap[s.substr(j, len_word)]++;
}
//减掉words里面出现的单词 如果减完后cur 恰好为空,说明当前滑动窗口的单词和words是一样的
for(string & x: words){
curMap[x]--;
if(curMap[x] == 0) curMap.erase(x);
}
if(curMap.empty()) ans.push_back(l);//判断当前滑动窗口是否满足条件
// 窗口移动,每次就是滑动一个单词,最左边的单词,右边的单词加入
while(r < n){
string del = s.substr(l, len_word);
string add = s.substr(r, len_word);
if(--curMap[del] == 0) curMap.erase(del);
if(++curMap[add] == 0) curMap.erase(add);
// 更新滑动窗口边界
r += len_word;
l += len_word;
if(curMap.empty()) ans.push_back(l);
}
}
return ans;
}
};
4.最小覆盖子串

class Solution {
public:
bool check(unordered_map<char, int>& tar, unordered_map<char, int>& cur) {
// 检查每个字符的个数是否相同
for (const auto& entry : tar) {
char ch = entry.first;
int count1 = entry.second;
// 如果 tar2 中没有相同的字符,或者出现的次数不同,返回 false
if (cur.find(ch) == cur.end() || cur[ch] < count1) {
return false;
}
}
return true;
}
string minWindow(string s, string t) {
int ls = s.size();
int lt = t.size();
int l = 0, r = 0;
unordered_map<char, int> tar;
for(int i = 0; i < lt; i++){
tar[t[i]] ++;
}
int ans = INT_MAX;
int ll = -1, rr = -1;
unordered_map<char, int> cur;
while(r < ls){
// 所以要先加上右边的字符,检查窗口是否符合条件时,已经包含了右边界的新字符。
cur[s[r]] ++;
r++;
// 这里判断的时候已经包含了r
while(check(tar,cur)){
if(ans > (r - l + 1)){
ans = r - l + 1;
ll = l;
rr = r;
}
cur[s[l]] --;
l++;
}
}
if(ans != INT_MAX){
return s.substr(ll,rr - ll);
}else{
return "";
}
}
};
滑动窗口的适用性:
滑动窗口适用于需要在某个区间(子串或子数组)内维持某种条件(例如:字符的唯一性、子数组的和、子数组的大小等)的情形。它的优势是能够在一个遍历中维护这些条件,而不需要重新计算每个子区间。
📕矩阵
1.有效的数独

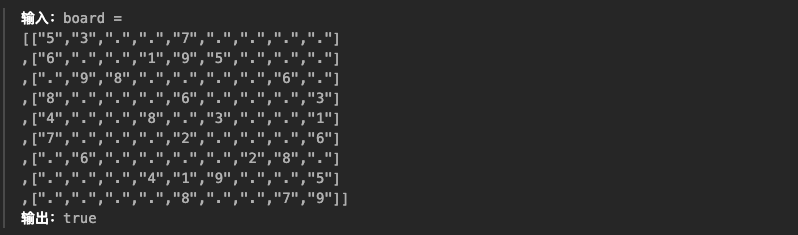
🛻法1:直接模拟
先判断行
再判断列
再判断9个3*3宫格
/*
时间复杂度:O(81)+O(81)+O(81)=O(243)
*/
class Solution {
public:
bool check(vector<vector<char>>& board,int sx,int sy){
unordered_map<char, int> cnt;
for(int i = sx; i < sx + 3; i++){
for(int j = sy; j < sy + 3; j++){
if(board[i][j] != '.'){
cnt[board[i][j]]++;
if(cnt[board[i][j]] > 1) return false;
}
}
}
return true;
}
bool isValidSudoku(vector<vector<char>>& board) {
unordered_map<char, int> cnt;
//判断行
for(int i = 0; i < 9; i++){
cnt.clear();
for(int j = 0; j < 9; j++){
if(board[i][j] != '.'){
cnt[board[i][j]]++;
if(cnt[board[i][j]] > 1) return false;
}
}
}
//判断列
for(int i = 0; i < 9; i++){
cnt.clear();
for(int j = 0; j < 9; j++){
if(board[j][i] != '.'){
cnt[board[j][i]]++;
if(cnt[board[j][i]] > 1) return false;
}
}
}
//9个小的3*3宫格
int sx = 0, sy = 0;
for(sx = 0; sx < 9; sx += 3){
for(sy = 0; sy < 9; sy += 3){
if(!check(board,sx,sy)){
return false;
}
}
}
return true;
}
};
🛻法2:
3.旋转矩阵

🛻法1:就是先遍历最外圈(从左到右→从上到下↓ 从右到左←从下到上↑ 每次边里完就收缩那条边)所有最外圈的边遍历完矩阵就会向内收缩一圈。继续进行上述操作,知道边有重合结束!
//主要思想就是
//
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
int l = 0;
int r = matrix[0].size() - 1;
int m = 0;
int n = matrix.size() - 1;
vector<int> ans;
while(true){
// 从右向左
for(int i = l; i <= r; i++) ans.push_back(matrix[l][i]);
if(++m > n) break;
// xia
for(int i = m; i <= n; i++) ans.push_back(matrix[i][r]);
if(--r < l) break;
//zuo
for(int i = r; i >=l; i--) ans.push_back(matrix[n][i]);
if(--n < m) break;
//shang
for(int i = n; i >= m; i--) ans.push_back(matrix[i][l]);
if(++l > r) break;
}
return ans;
}
};
4.旋转图像
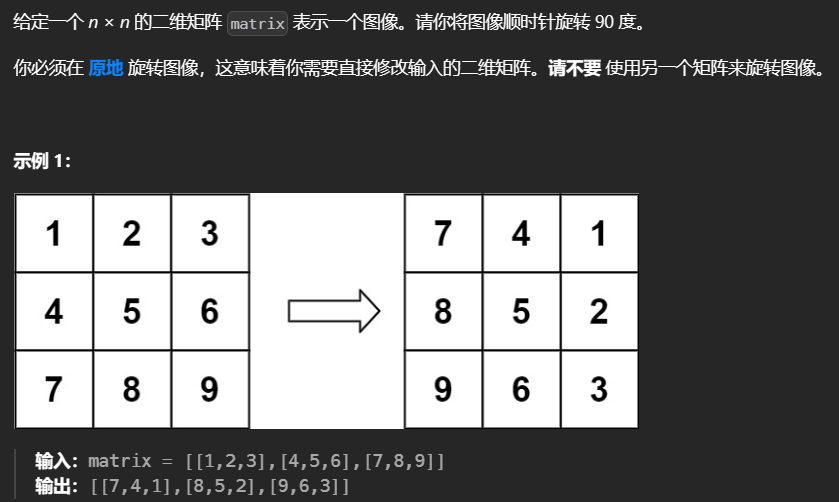
🛻法1:额外数组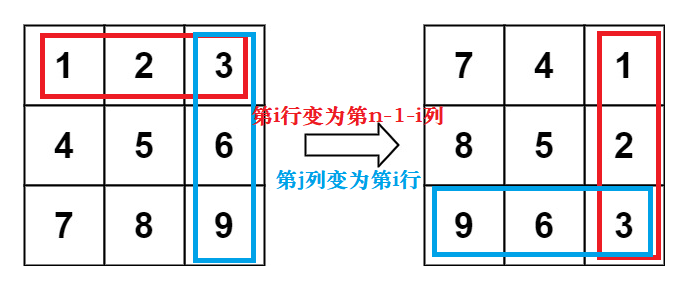
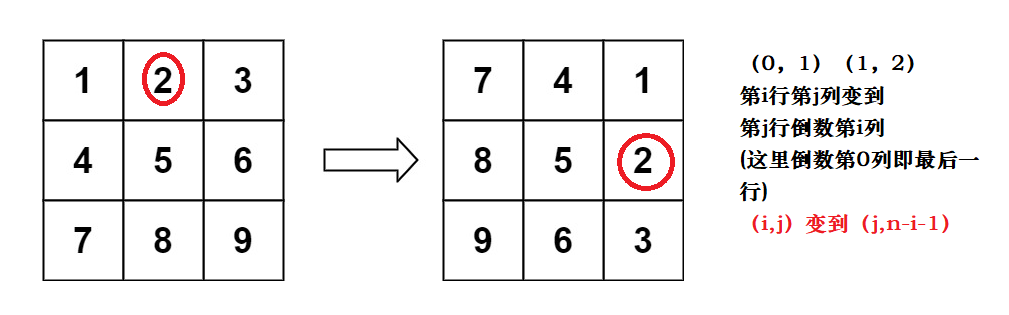
最好想到的就是借助额外数组
/*
时间复杂度: O(n2)
空间复杂度: O(n2)
*/
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
auto matrix_bak = matrix;
for(int i = 0;i < n; i++){
for(int j = 0; j <n; j++){
//这里需要注意,是把[i][j]位置的数赋值到[j][n-i-1]
matrix_bak[j][n-i-1] = matrix[i][j];
}
}
matrix = matrix_bak;
}
};
🛻法2:原地操作
5.矩阵置0
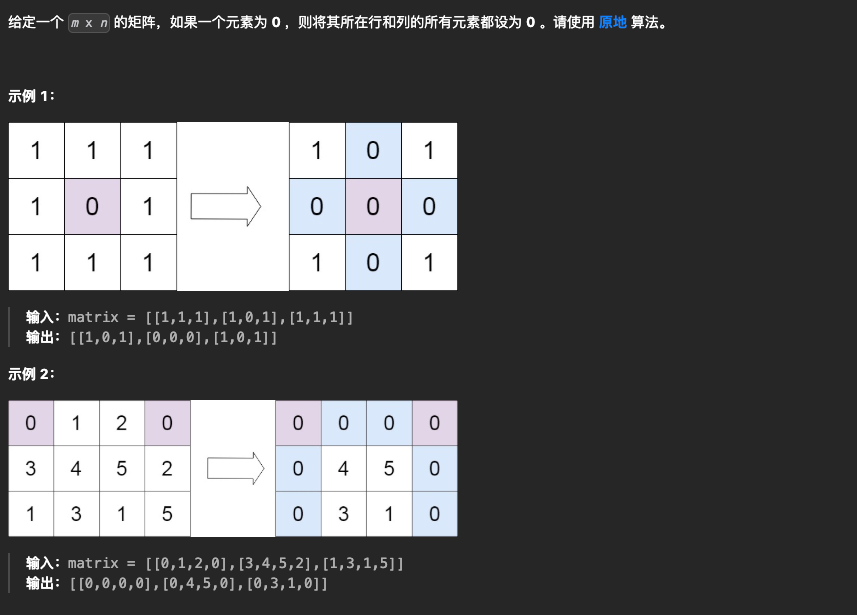
🛻法1:开两个额外数组,分别记录这一行和这一列是否有0出现
然后遍历每个位置,看所在行和列是否有0即可
/*
时间复杂度:o(mn)
空间复杂度:o(m+n)
*/
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
int m = matrix.size();
int n = matrix[0].size();
set<int> row;
set<int> col;
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(matrix[i][j] == 0){
row.insert(i);
col.insert(j);
}
}
}
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(row.count(i)|| col.count(j)){
matrix[i][j] = 0;
}
}
}
}
};
🛻法2:原地操作
取出矩阵的第0行和第0列作为标记数组,在采用两个变量记录第0行和第0列本身有没有0
/*
时间复杂度:o(mn)
空间复杂度:o(2)
*/
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
int m = matrix.size();
int n = matrix[0].size();
int col = 1,row = 1;
for(int i = 0; i < m; i++){
if(matrix[i][0] == 0) col = 0;
}
for(int j = 0; j < n; j++){
if(matrix[0][j] == 0) row = 0;
}
for(int i = 1; i < m;i++){
for(int j = 1; j < n; j++){
if(matrix[i][j] == 0){
matrix[0][j] = 0;
matrix[i][0] = 0;
}
}
}
// 注意这里的循环范围
for(int i = 1; i < m; i++){
for(int j = 1; j < n; j++){
if(matrix[i][0] == 0 || matrix[0][j] == 0) matrix[i][j] = 0;
}
}
if(col == 0){
for(int i = 0; i < m; i++){
matrix[i][0] = 0;
}
}
if(row == 0){
for(int j = 0; j < n; j++){
matrix[0][j] = 0;
}
}
}
};
🛻法3:取一个其他数区分已有的0和修改后的0
由于本题把所有int可以用的数都用了,所以没法取一个固定的数标记改过的0,所以我们随机取一个随机数
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
int m = matrix.size();
int n = matrix[0].size();
int staus = rand();
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(matrix[i][j] == 0){
for(int k = 0; k < n; k++){
if(matrix[i][k] != 0) matrix[i][k] = staus;
}
for(int k = 0; k < m; k++){
if(matrix[k][j] != 0) matrix[k][j] = staus;
}
}
}
}
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(matrix[i][j] == staus)
matrix[i][j] = 0;
}
}
}
};
6.生命游戏(🍭)

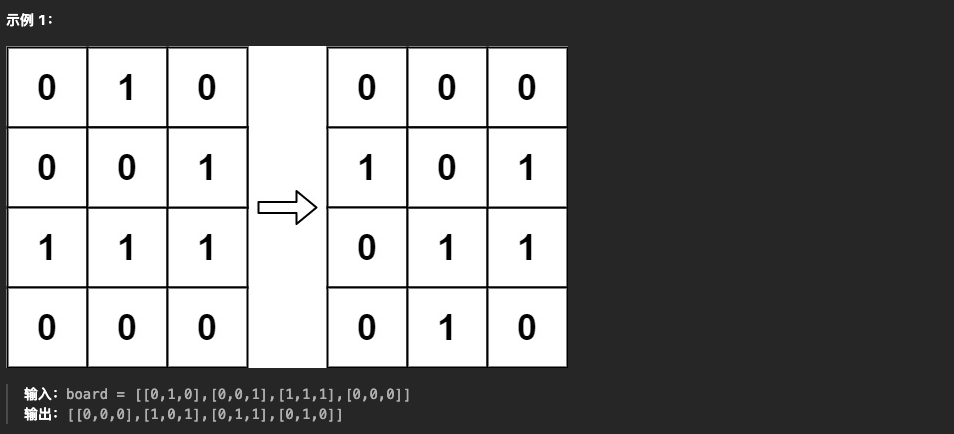
🛻法1:开额外数组备份
class Solution {
public:
void gameOfLife(vector<vector<int>>& board) {
// 方向数组
int d[3] = {0,1,-1};
int m = board.size();
int n = board[0].size();
vector<vector<int> >board_bak(m,vector<int>(n,0));
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
board_bak[i][j] = board[i][j];
}
}
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
int alive = 0;
for(int dx = 0; dx < 3; dx++){
for(int dy = 0; dy < 3; dy++){
if(d[dx]!=0 || d[dy]!=0){
int r = (i + d[dx]);
int c = (j + d[dy]);
if((r < m && r >= 0) && (c < n && c >= 0) && (board_bak[r][c] == 1)){
alive++;
}
}
}
}
if((board_bak[i][j]==1) && (alive < 2 || alive > 3)){
board[i][j] = 0;
}
if(board_bak[i][j] == 0 && alive == 3){
board[i][j] = 1;
}
}
}
}
};
🛻法2:使用额外的状态
每个细胞只有两种状态 live(1) 或 dead(0),通过拓展一些复合状态使其包含之前的状态。
如果细胞之前的状态是 0,但是在更新之后变成了 1,定义现在状态位 2。这样我们看到 2,既能知道目前这个细胞是活的,还能知道它之前是死的。
如果之前状态是死的,更新后变为1,那么定义为-1
/*
时间复杂度:o(mn)
空间复杂度:o(1)
*/
class Solution {
public:
void gameOfLife(vector<vector<int>>& board) {
// 方向数组
int d[3] = {0,1,-1};
int m = board.size();
int n = board[0].size();
vector<vector<int> >board_bak(m,vector<int>(n,0));
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
board_bak[i][j] = board[i][j];
}
}
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
int alive = 0;
for(int dx = 0; dx < 3; dx++){
for(int dy = 0; dy < 3; dy++){
if(d[dx]!=0 || d[dy]!=0){
int r = (i + d[dx]);
int c = (j + d[dy]);
//这里修改
if((r < m && r >= 0) && (c < n && c >= 0) && (abs(board_bak[r][c] == 1))){
alive++;
}
}
}
}
if((board_bak[i][j]==1) && (alive < 2 || alive > 3)){
// 现在是活的,修改之前是死的
board[i][j] = -1;
}
if(board_bak[i][j] == 0 && alive == 3){
// 过去是死的,修改后活了
board[i][j] = 2;
}
}
}
// 更新状态
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(board[i][j] > 0){
board[i][j] = 1;
}else{
board[i][j] = 0;
}
}
}
}
};
📕哈希表
1.赎金信
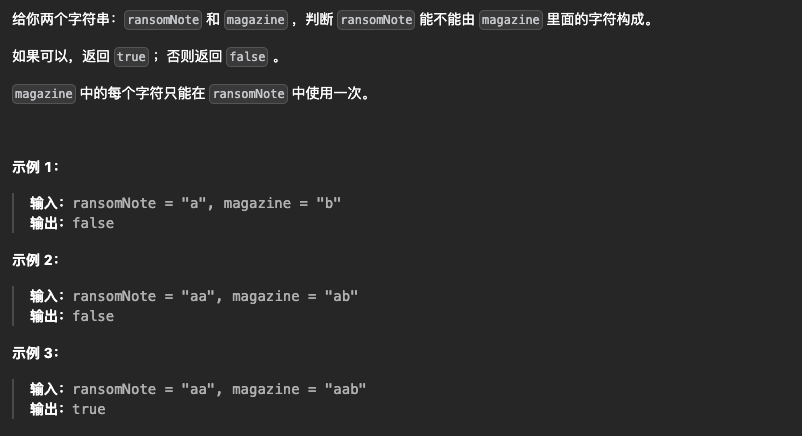
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
unordered_map<char, int> scount;
int lr = ransomNote.size();
int lm = magazine.size();
if(lm > lm) return false;
for(int i = 0; i < lm; i++){
scount[magazine[i]] ++;
}
for(int i = 0; i < lr; i++){
char c = ransomNote[i];
if(scount[c] <= 0) return false;
else scount[c] --;
}
return true;
}
};
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
int lr = ransomNote.size();
int lm = magazine.size();
if(lr > lm) return false;
// 由于题目中说了都是小写字母
vector<int> cnt(26);
for(char c : magazine){
cnt[c - 'a'] ++;
}
for(char c: ransomNote){
int x = cnt[c-'a'];
if(x <= 0) return false;
else cnt[c-'a'] --;
}
return true;
}
};
2. 同构字符串

class Solution {
public:
bool isIsomorphic(string s, string t) {
int n = s.size();
if (n != (int)t.size()) return false;
//需要两边都记录下来 保证s-t 和 t-s的关系映射都是唯一的。否则会出现比如b和d都映射到a
unordered_map<char,char> st; // s -> t
unordered_map<char,char> ts; // t -> s
for (int i = 0; i < n; i++) {
char a = s[i], b = t[i];
if (st.count(a) && st[a] != b) return false;
if (ts.count(b) && ts[b] != a) return false;
st[a] = b;
ts[b] = a;
}
return true;
}
};
3.单词规律
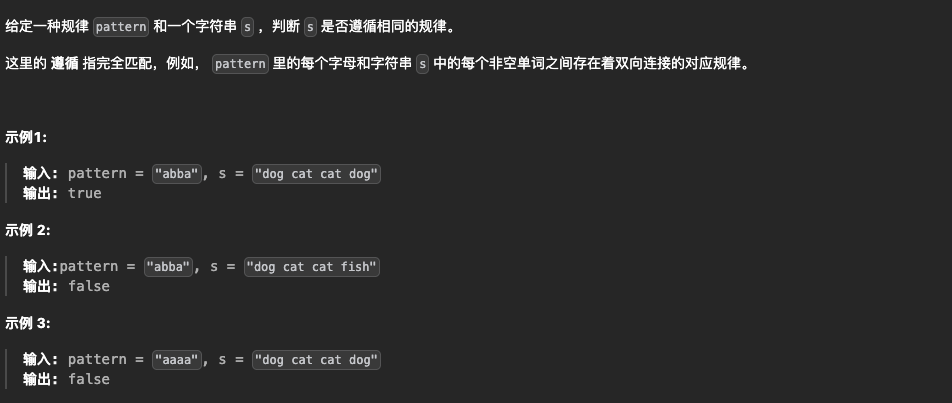
其实和上一题基本一样,只不过上一题是字符和字符映射
这一题是字符和字符串相互映射
class Solution {
public:
bool wordPattern(string pattern, string s) {
unordered_map<char,string> ps; // s -> t
unordered_map<string,char> sp; // t -> s
int m = s.size();
int i = 0;
for(char ch : pattern){
if(i >= m) return false;
int j = i;
while(j < m && s[j] != ' ') j++;
string t = s.substr(i, j - i);
if(ps.count(ch) && ps[ch] != t) return false;
if(sp.count(t) && sp[t] != ch) return false;
sp[t] = ch;
ps[ch] = t;
i = j + 1;
}
return i >= m;
}
};
4.有效的字母异位词

字母异位词是通过重新排列不同单词或短语的字母而形成的单词或短语,并使用所有原字母一次。
class Solution {
public:
bool isAnagram(string s, string t) {
int ls = s.size();
int lt = t.size();
if(ls != lt) return false;
vector<int> ch(26, 0);
for(auto c : s){
ch[c-'a']++;
}
for(auto c: t){
if(ch[c -'a'] <= 0) return false;
ch[c-'a'] --;
}
return true;
}
};
进阶: 如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
进阶的话可以使用map来统计次数
5.字母异位词分组

🚗法1:排序
互为字母异位词的字符串字符是一样的,所以排序后字符串其实是一样的,只需要将所有字符串排序,然后将排序后字符串一样的分为一组即可,我们采用哈希表,排序后的字符串作为
/*
时间复杂度:O(nklogk) n是字符串的数量,k是字符串的最大长度
空间复杂度:O(nk)
*/
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> mp;
for (string str: strs) {
string x = str;
sort(x.begin(), x.end());
mp[x].emplace_back(str); // 将所有排序后相等的字符串放到一起
}
vector<vector<string>> ans;
for (auto &it : mp) {
ans.emplace_back(it.second);
}
return ans;
}
};
6.两数之和
/**
时间复杂度:O(n)
空间复杂度:O(n)
**/
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> mp;
int n = nums.size();
for(int i = 0; i < n; i++){
mp[nums[i]] = i;
}
for(int i = 0; i < n; i++){
if(mp.count(target-nums[i]) && mp[target-nums[i]] != i){
return{i,mp[target-nums[i]]};
}
}
return {};
}
};
7. 快乐数(❗️龟兔赛跑算法)

首先我们需要考虑三种情况:
(1)最后变为1,即快乐数
(2)最后进入循环
(3)会不会无限变大,趋于∞
第三种情况虽然是题目中没要求的,但是需要考虑,其实第三种情况是不存在的,为什么呢?
设当前数是 𝑛,它的位数是 𝑘。那么它的最大值小于 10的𝑘次方。每一位的最大平方数是81。
如果 𝑛很大(有 𝑘位)𝑓(𝑛)≤81𝑘, 10的𝑘次方肯定≤81𝑘,所以下一步肯定变小
如果数有 4 位,最大是 9999,
下一步最大:
4×81=324。
如果数有 10 位,最大是 9,999,999,999,
下一步最大:
10×81=810。
因此无论多大的数,经过一两步运算后都会落到一个 有限的范围内
法1:哈希表判断是否循环
class Solution {
public:
int getsum(int x){
int s = 0;
while(x){
int d = x % 10;
s += (d*d);
x /= 10;
}
return s;
}
bool isHappy(int n) {
unordered_set<int> seen;
while(n != 1 && !seen.count(n)){
seen.insert(n);
n = getsum(n);
}
return n == 1;
}
};
👍法2:弗洛伊德判环(快慢指针,O(1) 空间)
第一次接触这种方法,感觉还挺神奇哈哈哈
class Solution {
public:
int getNext(int x){
int s = 0;
while(x){
int d = x % 10;
s += (d*d);
x /= 10;
}
return s;
}
bool isHappy(int n) {
int slow = getNext(n);
int fast = getNext(getNext(n));
while(slow != fast){
slow = getNext(slow);
fast = getNext(getNext(fast));
}
return fast == 1;
}
};
拓展:
求环的长度、起点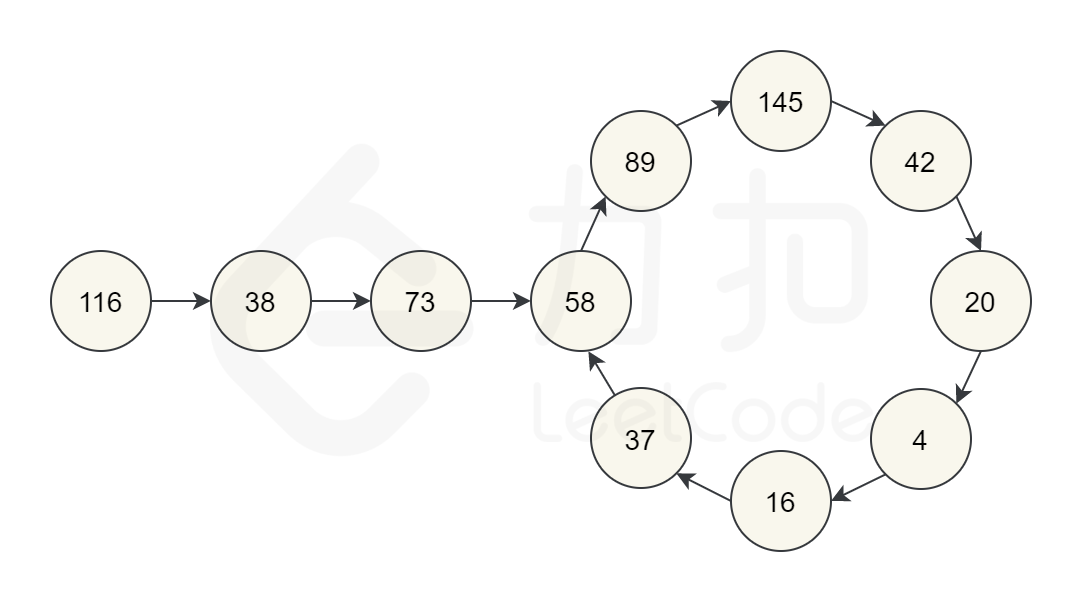
#include <bits/stdc++.h>
using namespace std;
// 工具函数:计算一个数各位数字平方和
int getNext(int x) {
int s = 0;
while (x) {
int d = x % 10;
s += d * d;
x /= 10;
}
return s;
}
// 求环的长度
int getCycleLength(int n) {
int slow = getNext(n);
int fast = getNext(getNext(n));
// Floyd 判环
while (slow != fast) {
slow = getNext(slow);
fast = getNext(getNext(fast));
}
// 计算环长度
int len = 1;
fast = getNext(slow);
while (fast != slow) {
fast = getNext(fast);
len++;
}
return len;
}
// 求环的起点
int getCycleStart(int n) {
int slow = getNext(n);
int fast = getNext(getNext(n));
// 1) 先找到相遇点
while (slow != fast) {
slow = getNext(slow);
fast = getNext(getNext(fast));
}
// 2) 求环长度
int len = 1;
fast = getNext(slow);
while (fast != slow) {
fast = getNext(fast);
len++;
}
// 3) 找环起点
slow = n;
fast = n;
for (int i = 0; i < len; i++) fast = getNext(fast); // fast 先走 len 步
while (slow != fast) {
slow = getNext(slow);
fast = getNext(fast);
}
return slow; // slow 和 fast 相遇的位置就是环的起点
}
int main() {
int n;
cout << "请输入一个正整数: ";
cin >> n;
int len = getCycleLength(n);
int start = getCycleStart(n);
cout << "环长度 = " << len << endl;
cout << "环起点 = " << start << endl;
return 0;
}

8.存在重复元素
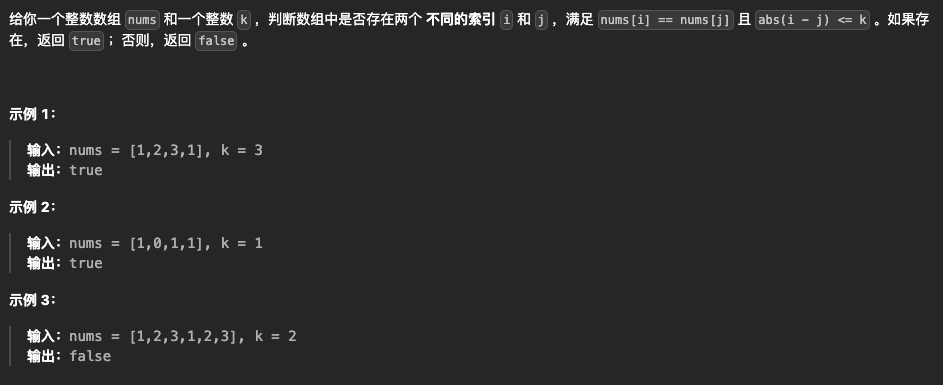
🚗法1:自定义排序
先按照数值排序,在按照索引排序,可以让相等的在一起,并且优先让相等的且索引更近的在一起,所以每个数只判断和自己最近的一个即可,最近的一个都不满足条件,其他的更不可能
/*
时间复杂度:O(n log n)
空间复杂度:O(n)
*/
class Solution {
public:
static bool cmp(pair<int,int> a, pair<int,int> b) {
if (a.first == b.first)
return a.second < b.second; // 值相同按索引升序
return a.first < b.first; // 否则按值升序
}
bool containsNearbyDuplicate(vector<int>& nums, int k) {
if(k < 1) return false;
vector<pair<int,int>> vp;
for (int i = 0; i < nums.size(); i++) {
vp.push_back({nums[i], i});
}
// 自定义排序规则
sort(vp.begin(), vp.end(), cmp);
for (int i = 0; i < vp.size() - 1; i++) {
if((vp[i+1].first == vp[i].first) && (vp[i+1].second - vp[i].second <= k)) return true;
}
return false;
}
};
🚗法2:哈希表
哈希表记录上一次出现的位置,再比较当前索引和上一次索引的差距。
/*
时间复杂度:O(n)
空间复杂度:O(n)
*/
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_map<int, int> mp;
int n = nums.size();
for(int i = 0; i < n; i++){
int x = nums[i];
if(mp.count(x) && i - mp[x] <= k){
return true;
}
mp[x] = i;
}
return false;
}
};
🚗法3:滑动窗口
维护一个 大小最多为 k 的滑动窗口,用 unordered_set 保存窗口内的元素
如果 nums[i] 已经在集合里,说明在最近 k 个元素里出现过重复,直接返回 true。
否则,把 nums[i] 插入集合。
如果集合大小超过 k,就把最左边的元素(nums[i - k - 1])删掉,保证集合只包含最近的 k 个元素。
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_set<int> s;
int n = nums.size();
for (int i = 0; i < n; i++) {
if (i > k) {
s.erase(nums[i - k - 1]);
}
if (s.count(nums[i])) {
return true;
}
s.insert(nums[i]);
}
return false;
}
};
9.最长连续序列(哈希集合🐱)

法1:排序+双指针/滑动窗口
时间复杂度,O(n log n)
首先排序,然后去重(不去重的话1,2,2,3这种情况下不对),这时候再去看最大满足条件的,相当于维护一个滑动窗口,里面是满足条件的元素,当满足条件就拓展右端点,不满足的时候求一下区间长度,然后更新滑动窗口左端点。
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
if(nums.size() == 0) return 0;
sort(nums.begin(), nums.end());
int l = 0, r = 0;
int ans = 0;
nums.erase(unique(nums.begin(),nums.end()),nums.end());
while((r+1) < nums.size()){
if(nums[r+1] == (nums[r] + 1)){
r++;
}else{
int cur = (r - l + 1);
ans = max(ans, cur);
r++;
l = r;
}
}
ans = max(ans, (r-l+1)); //这里需要注意 必须在检查一次
return ans;
}
};
🚗:法2 哈希表(解题思路还挺🐱的)
上面的方法不满足时间复杂度,主要原因就是因为排序
/*
时间复杂度:o(n)
判断每个数是不是连续序列的开头,怎么判断呢?
查找这个数前面的那个数是否存在,如果存在的话肯定是以更小的数位开头序列更长(我们先用哈希表预处理出来已经有的数,所以o(1)就能查出来是不是存在)
举个例子 [3 1 2 4 2] 去重后 [3 1 2 4]
3不是开头
1是开头,可以计算得到长度为 1 2 3 4 =》 4
2不是开头
4不是开头
因此答案就是4
*/
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> st;
// 去重
for(int num : nums){
st.insert(num);
}
int ans = 0;
for(int num : st){
// 只处理开头元素
if(!st.count(num-1)){ //是开头元素
int cur = num;
int tmplen = 1;
while(st.count(cur+1)){
cur += 1;
tmplen += 1;
}
ans = max(ans, tmplen);
}
}
return ans;
}
};
📕 区间
1.汇总区间(❕)

写的时候,双指针
细节比较多,需要理清楚
class Solution {
public:
vector<string> summaryRanges(vector<int>& nums) {
vector<string> ans;
if (nums.empty()) return ans;
int n = nums.size();
int l = 0;
for (int r = 0; r < n; r++) {
// 满足条件 扩大区间
if(r + 1 < n && nums[r] + 1 == nums[r+1]) continue;
if(l == r) ans.push_back(to_string(nums[l])); //单个数
else ans.push_back(to_string(nums[l]) + "->" + to_string(nums[r]));
// 更新区间
l = r + 1;
}
return ans;
}
};
2.合并区间
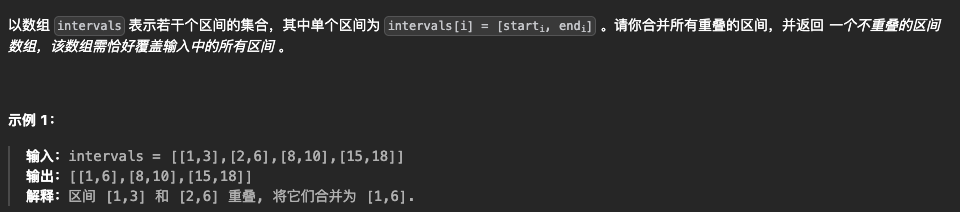
🚗法1:排序
/*
时间复杂度:O(n log n)
空间复杂度:O(n)
可以看到如果两个区间重叠的话,条件是:
一个区间的起始位置 <= 另一个区间的结束位置
所以先按照起点排序,右端点排序
*/
class Solution {
public:
static bool cmp(const vector<int>& a, const vector<int>& b) {
if (a[0] == b[0]) {
return a[1] < b[1];
}
return a[0] < b[0];
}
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<vector<int>> ans;
sort(intervals.begin(), intervals.end(), cmp);
int st = intervals[0][0], ed = intervals[0][1];
for(int i = 1; i < intervals.size(); i++){
if(intervals[i][0] <= ed){
ed = max(ed, intervals[i][1]);
}else{
ans.push_back({st,ed});
st = intervals[i][0];
ed = intervals[i][1];
}
}
ans.push_back({st,ed}); //处理最后一个区间
return ans;
}
};
3.插入区间
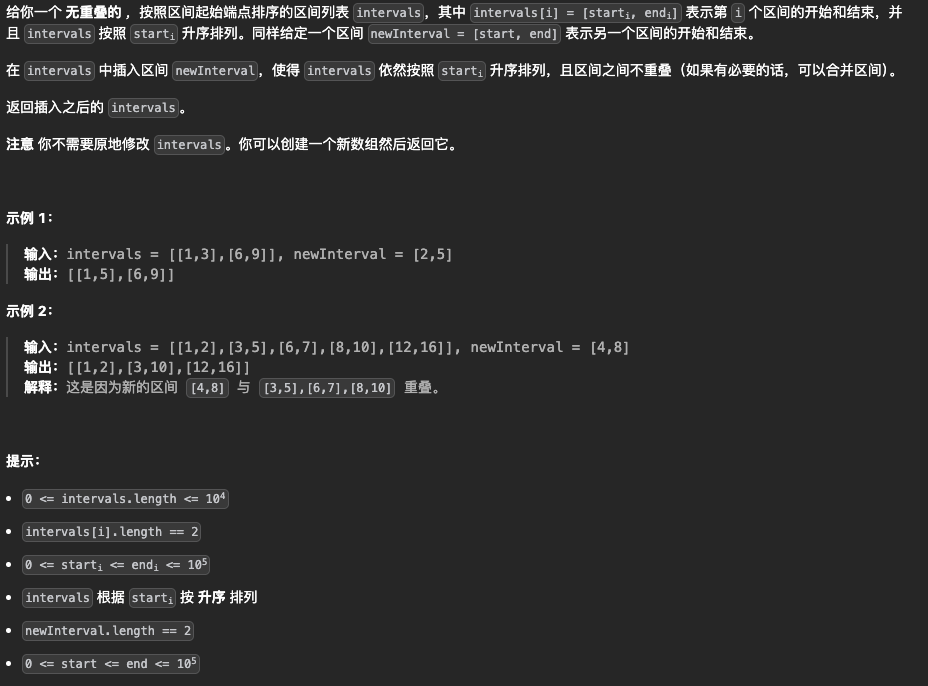
法1:区间合并
最简单的方法就是直接用上一题的解法,只不过需要先把插入的那个区间也加入到区间序列,一起排序即可,然后就是和区间合并一样的解法
class Solution {
public:
static bool cmp(const vector<int>& a, const vector<int>& b) {
if (a[0] == b[0]) {
return a[1] < b[1];
}
return a[0] < b[0];
}
vector<vector<int>> insert(vector<vector<int>>& intervals, vector<int>& newInterval) {
intervals.push_back({newInterval[0], newInterval[1]});
vector<vector<int>> ans;
sort(intervals.begin(), intervals.end(), cmp);
int st = intervals[0][0], ed = intervals[0][1];
for(int i = 1; i < intervals.size(); i++){
if(intervals[i][0] <= ed){
ed = max(ed, intervals[i][1]);
}else{
ans.push_back({st,ed});
st = intervals[i][0];
ed = intervals[i][1];
}
}
ans.push_back({st,ed}); //处理最后一个区间
return ans;
}
};
🚗法2:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)