task11~如何用transformers框架进行开源LLM的pretrain+SFT(deepspeed分布式)、高效微调(adapt、prefix、lora微调)的流程
本文介绍了大模型训练流程中的主流框架与实践方法。首先指出自研训练系统的弊端,引出Hugging Face Transformers框架的核心优势:模块化模型构建、分布式训练封装和自动化管理。详细拆解了LLM训练流程:1)初始化模型和分词器;2)数据预处理(加载、分词、分块);3)配置训练参数;4)使用DeepSpeed进行分布式预训练;5)指令微调(SFT)。最后对比了适配器调优(Adapt Tu
Task11:第六章 大模型训练流程实践
为啥会有这一篇,希望大家明白前因后果,帮助更好理解现在流行的框架。
接task10,每训一个大模型每个组件都自己写代码,显然不合适。
原因如下:
- 麻烦
- 各个模型之间不一定通用、参数可能没法移植
- 自己写的分布式训练也不好搞
所以,机智的开源社区给出了LLM相关的
- 主流训练框架Transformers——进行模型的pretrain、sft
- 分布式框架deepseed
- 高效微调框架peft
what Transformers框架?
框架介绍
Transformers框架 ≠ Transformer结构
它是hugging face开发的,
- 模块化组件,就可以支持拼拼凑凑出主流模型架构,如BERT、GPT等,
AutoModel类 - 内置
Trainer类,封装分布式训练(pytorch原生的DDP、DeepSeed、Megatron-LM等训练策略)的核心逻辑 + 简单配置训练参数——数据/模型/流水线并行
ps:8卡A100集群就可以10+B参数训练 - 可实现训练过程
自动化管理,(os:不然训那么久还要一直看着,太可怕了)配合SavingPolicy 和 LoggingCallback 等组件
咱今天来逛三园(拥抱脸)
逛的什么园,hugging face园(os:给大家来段贯口)
三园里面有什么?
- 数亿 pretrain 的
模型参数 - 25w+ 不同类型
数据集 - 搭好的(pretrain模型+data+eval函数)框架
(os:这意味着什么你知道吗?那就是你要换哪个开源LLM、用什么data都可以,“随便放随便训”,也没那么随便其实hh)
目前比较多的LLM工作
要知道
- 训一个pretrain不容易(费时费钱费资源),所以
post-train和SFT就很多,基模然后调一调满足下游业务才是真正的落地 - 就算是大款,LLM的 para 也很大,所以像
deepspeed等分布式训练框架老必备技能了
how Transformers 自定义 LLM(训参数)?
即,通过 Transformers 框架实现 LLM 的 Pretrain 及 SFT
这里讲的是从只有某个模型框架(参数是随机数)到模型参数pretrain填好,再到SFT监督微调的阶段
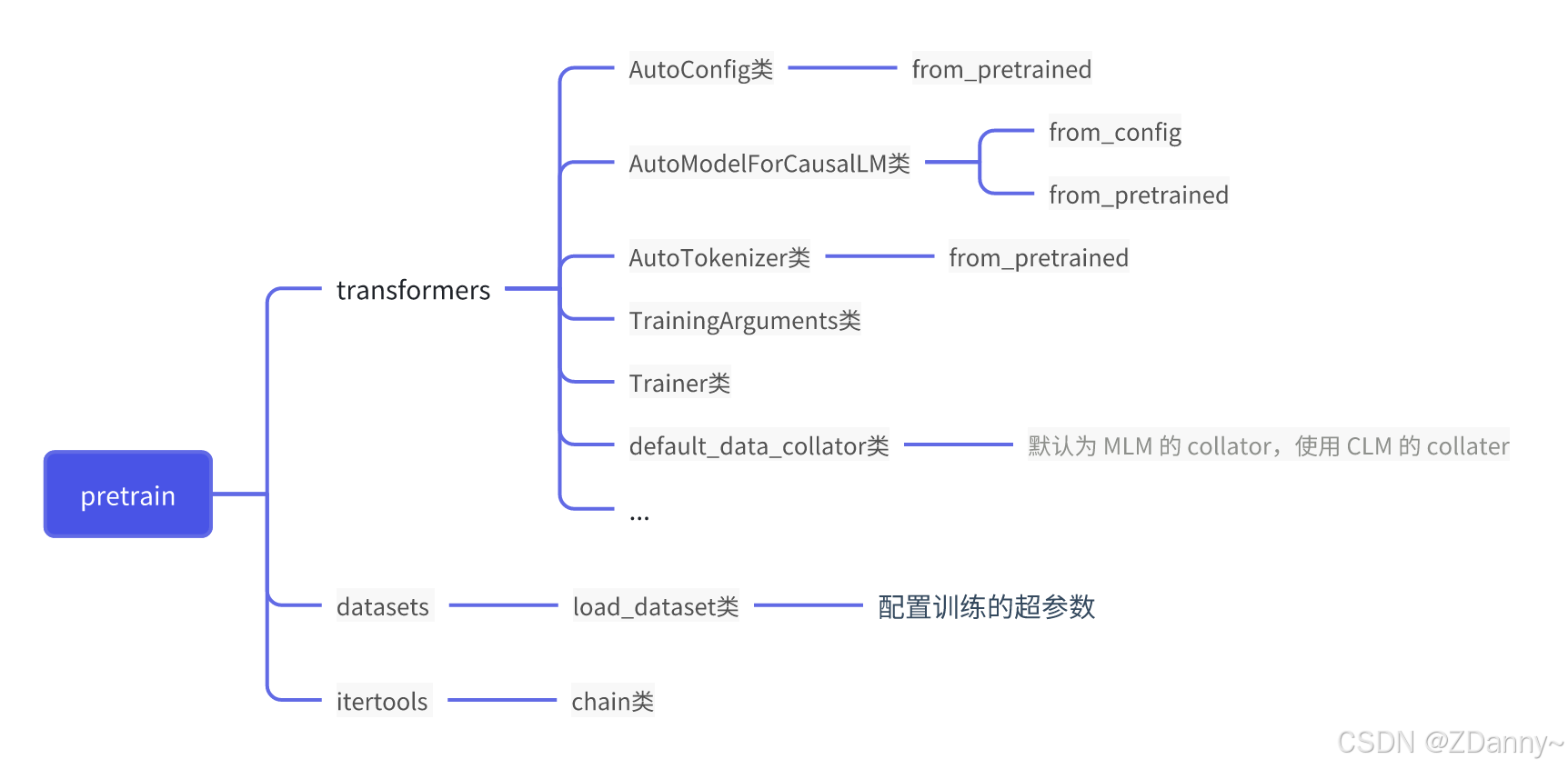
1.初始化一个 LLM + tokenizer
有两种,以CausalLM——Qwen-2.5-1.5B 为例(ps:因果LLM,就是用CLM任务训的LLM,前面预测下一个词)
用到的类:AutoModelForCausalLM、AutoConfig
- 直接加载一个
带para的LLM(后面直接在自己的预料上训)【最多】(ps:如果选择这种可以直接跳到下一节高效微调的步骤了) - 加载一个
盲盒零LLM(权重para是随机的,然后用CLM任务去训出para)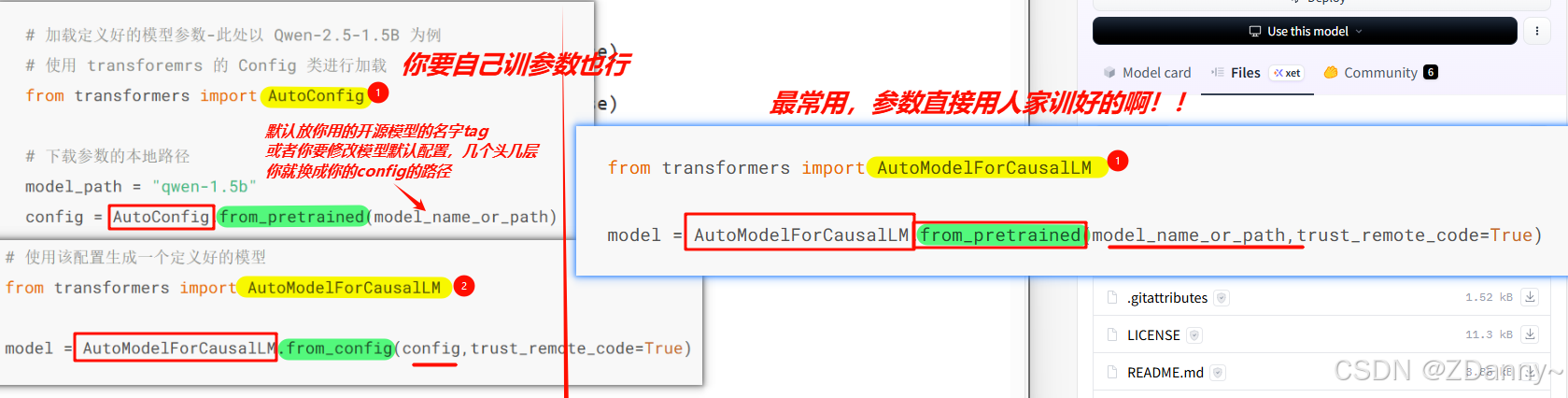
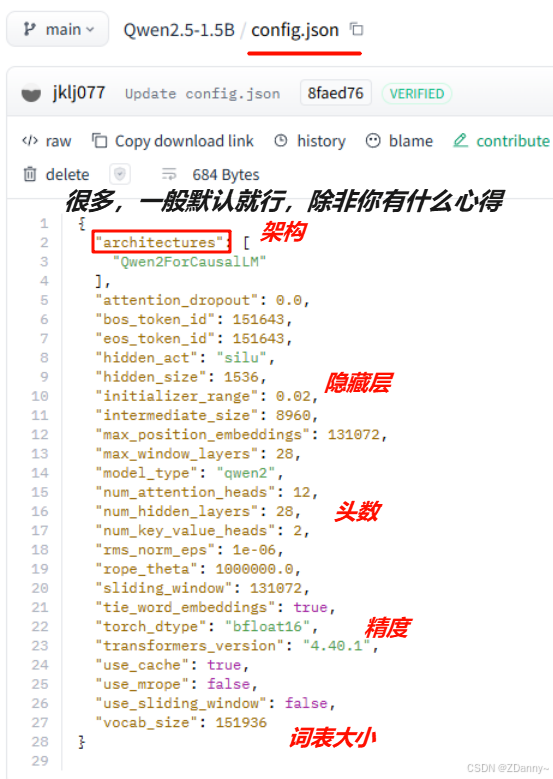
tokenizer也是,一般就加载开源LLM自带的分词器就行
用到的类:AutoTokenizer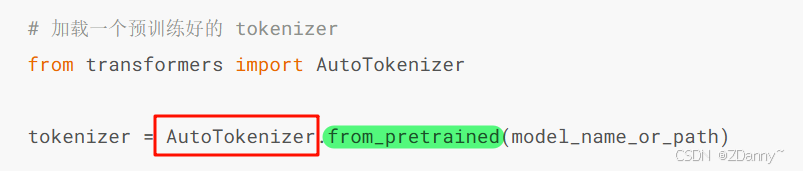
2.预训练数据处理
加载完分词器和架构后,自然就是处理下训练数据了。
这里用的是 出门问问序列猴子开源数据集30+GB (os:xdm为伟大的开源事业喝彩!)
【加载(下载解压)-- 分词 – 拼接切分】
① 加载并看看 jsonl数据
用到的库:hf的datasets
用到的类:load_dataset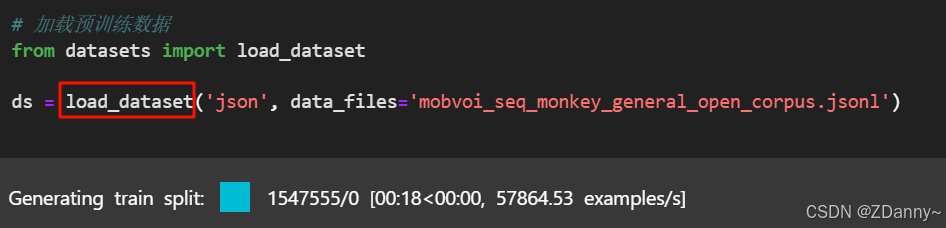
-
json格式 vs jsonl格式?
- json:整个文件是一个json,用“,”分割每个
- jsonl:大型数据,json line ,一行是一个json,用“\n”分割json对象
-
ds是
DatasetDict对象,就是超大数据集,里面很多子集
# 查看数据
ds["train"][0]
# 查看特征
column_names = list(ds["train"].features)
② 用tokenizer 对数据分词
ds.map():对data中每个样本执行函数,返回新数据集。
ps:为什么不用for循环?—— 根本不是一个档次,map可以①并行处理、②自动缓存、③进度条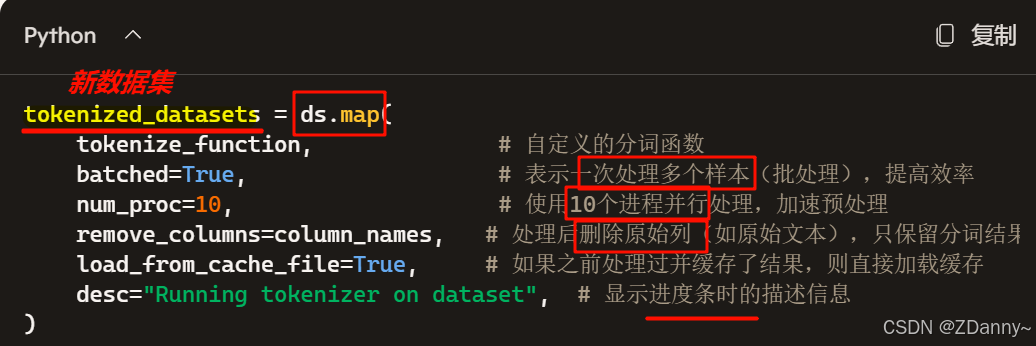
# 对数据集进行 tokenize
def tokenize_function(examples):
# 使用预先加载的 tokenizer 进行分词
output = tokenizer([item for item in examples["text"]])
return output
# 批量处理
tokenized_datasets = ds.map(
tokenize_function,
batched=True,
num_proc=10,
remove_columns=column_names,
load_from_cache_file=True,
desc="Running tokenizer on dataset",
)
③ 拼接分块处理数据
操作:把多个文本段拼接在一起,处理成统一长度的文本块,再对每个文本块进行训练
【 切成每个2048 token 长度,再 map 批量处理】
原因: pretrain的CLM 任务,一次性学习多个样本的序列语义不显著提高模型性能❌,且训练数据量大❌、训练时间长❌,对训练效率要求比较高❌
用到的库和包:from itertools import chain
# 预训练一般将文本拼接成固定长度的文本段
from itertools import chain
# 这里我们取块长为 2048
block_size = 2048
def group_texts(examples):
# 将文本段拼接起来
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
# 计算拼起来的整体长度
total_length = len(concatenated_examples[list(examples.keys())[0]])
# 如果长度太长,进行分块
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
# 按 block_size 进行切分
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
# CLM 任务,labels 和 input 是相同的
result["labels"] = result["input_ids"].copy()
return result
# 批量处理
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=10,
load_from_cache_file=True,
desc=f"Grouping texts in chunks of {block_size}",
batch_size = 40000,
)
train_dataset = lm_datasets["train"]
3.配置训练参数
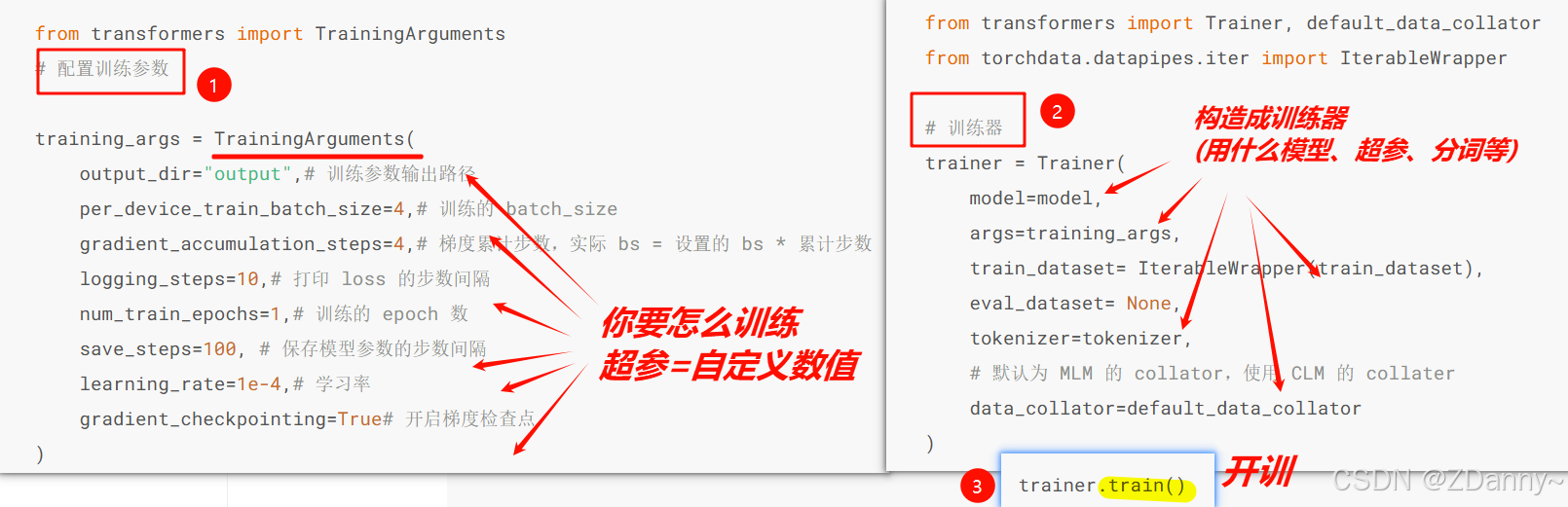
4.用DeepSpeed分布式开训!
你直接用 .jpynb 运行,训不动,会断。
一般预训练过程:多卡分布式 + bash 脚本(设定超参) + python脚本(训练控制)
- logging 库来实现(日志)记录
- 固定间隔保存 checkpoint(防崩)
- (监测)训练进度、loss 下降趋势 ——swanlab 作为训练检测
具体代码就不展开了,平时也不咋会遇到,知道大概过程就行。想看戳这里
5.SFT开调(指令微调)
CLM任务 训练时的pre和sft 计算区别
- pretrain 会对全部 text 进行 loss 计算,要求模型对整个文本实现建模预测;
- 而 SFT 仅对
输出进行 loss 计算,不计算指令部分的 loss
数据:准备微调数据集,这个数据量也不少哦。构造指令回答数据对
(具体也不说了)想看戳这里
how 高效微调?
Adapt Tuning
在模型架构中每层加入adapter层,微调时模型原参数冻结。
【LoRA就是其改进版】
存在的问题:
- 其实是增加了挺多参数量,也增加了计算量,推理会比原模型更慢
Prefix Tuning 前缀微调
是在微调阶段,不同任务加前缀prefix=virtual token 加在输入token前面,微调训练时就只更新这部分prefix参数,原模型参数冻结。
【P-tuning就是其改进版】
存在的问题:
- 模型可用序列长度缩短了,因为被prefix占用了。
- 微调质量越好,模型推理可用context越少
高效微调——LoRA微调(peft库)
what peft库?
-
peft也是拥抱脸小哥的,封装了LoRA、Adapt Tuning、P-tuning(就是主流的微调)等方法
-
peft 库目前支持调用 LoRA 的层包括:nn.Linear、nn.Embedding、nn.Conv2d 三种。
LoRA整体流程
核心: 选层换成lora层,复制冻结原参,更新旁路的两个A、B低秩矩阵数值
优点:
- 实际训练大幅降低显存占用,下游也能适配
缺点:
- 只调整低秩矩阵,其实模型很多的参数没变,所以整体的
知识注入没什么增加。

用peft进行LoRA微调: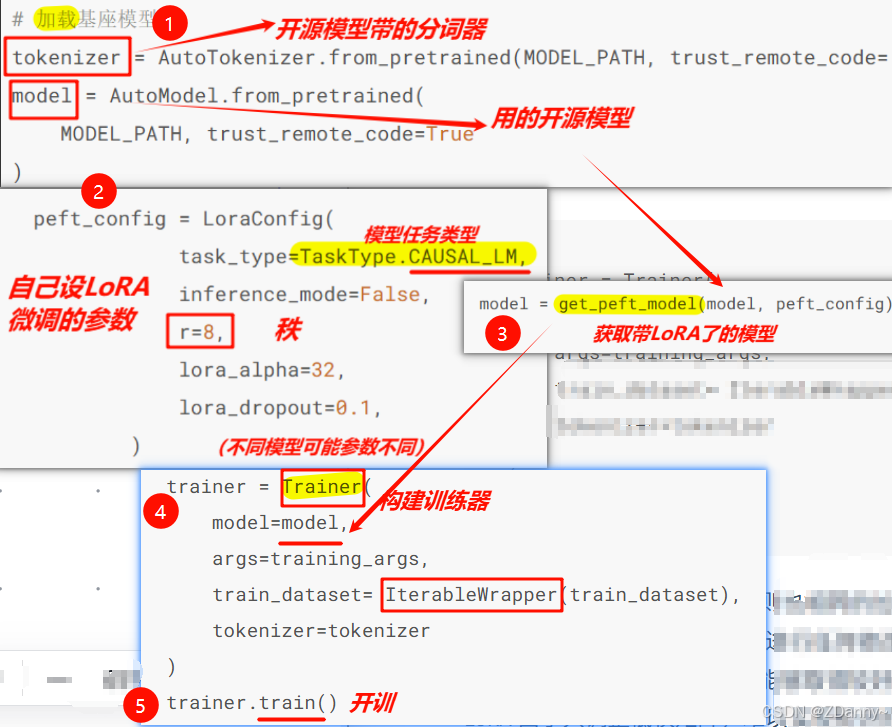

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)