大模型微调-2-Hugging Face核心组件
加载预训练模型。
简介
Hugging Face是什么?
Hugging Face是一个开源社区, 提供先进自然语言处理(NLP)模型,数据集,以及工具的平台,支持 Transformer 模型的开发和应用。它拥有庞大的模型库和社区资源,能够满足从研究到工业应用的各种需求。并逐渐扩展到了计算机视觉和其他机器学习领域,访问Hugging Face
Hugging Face核心功能与资源
- 模型库(Models):平台托管超过150万个开源模型,涵盖自然语言处理、计算机视觉、音频处理等多领域,支持按任务类型、框架或语言筛选。
- 数据集(Datasets):提供33万个高质量数据集,支持模型训练和微调,涵盖文本翻译、代码生成等场景。
- 工具链:
- Transformers库:简化模型加载、训练和部署,支持PyTorch、TensorFlow等框架。
- Pipeline API:封装预处理到推理的全流程,如情感分析、文本生成等任务。
Hugging Face Datasets 库是什么?
Datasets 是一个用于轻松访问和共享音频、计算机视觉和自然语言处理(NLP)任务数据集的 Python 库。
只需一行代码即可加载数据集,借助强大的数据处理方法,使用户能快速准备好数据集以进行深度学习模型的训练。
与Hugging Face Hub深度整合,在更广泛的机器学习社区中轻松加载和共享数据集。
安装 Hugging Face 库
Hugging Face 提供了 transformers 库,用于加载和使用模型。你可以使用以下命令来安装它:
pip install transformers
如果你还需要安装其他依赖库,如 datasets 和 tokenizers ,可以使用以下命令:
pip install transformers datasets tokenizersHugging Face API的使用
Hugging Face 的核心库,提供了用于加载预训练模型、分词器和其他相关工具的接口。可以理解为它可以直接调用HuggingFace上各种预训练模型中的每块“积木”(如编码器、解码器、注意力机制层等),用户可以直接下载这些去搭建使用,而非像研究者一样需要用pytorch或者tensorflow框架对一层层神经网络进行搭建去关注其中的细节。
基础组件
Pipeline
流水线,用于模型推理,封装了完整推理逻辑,包括数据预处理,模型预测、后处理
Tokenizer
分词器,用于数据预处理,将原始文本输入转化为模型需要的输入包括input_ids、attention_mask等
Model
模型,用于加载、创建、保存模型对 Pytorch 中的模型进行了封装,同时更友好的支持模型预训练
Datasets
数据集,用于数据集的加载和预处理,支持加载在线或本地的数据集,提供了数据集层面的一些处理方法
Evaluate
评估函数,用于对模型结果进行评估,支持多种任务评估函数e
Trainer
训练器,用于模型训练、评估,支持丰富配置选项,快速进行模型训练
开发流程
编码器
在 Hugging Face 生态中,编码器(Encoder) 主要指基于 Transformer 架构的编码器模型(如 BERT、RoBERTa 等),用于将输入数据(如文本、图像)转换为高维向量表示。这些编码器是许多 NLP 和跨模态任务的核心组件。简单理解编码器就是把数据转为数字的工具
一般来说编码器的名字和模型的名字是一样的,使用什么模型,就是用它的编码器
加载分词器
# hugging face需要在代码中配置代理
import os
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
sents = [
'春风十里不如你',
'看尽天下尽是你'
]
# 模型和它的编码器是成对使用的, 你使用什么模型, 就使用它提供的编码器。
from transformers import BertTokenizer
#加载预训练的BERT中文分词器(tokenizer)
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese',
cache_dir = None,
force_download = False
)
使用分词器编码
基本编码函数
# 基本的编码函数
out = tokenizer.encode(
text=sents[0], #第一段文本
text_pair=sents[1], #第二段文本
# 句子太长就截断到max_length
truncation=True,
# 句子不够长就padding到max_length的长度
padding='max_length',
#添加特殊标记,如 [CLS](句子开始)和 [SEP](句子结束)等BERT模型所需的特殊token
add_special_tokens=True,
# 最大长度
max_length=25,
# 指定返回数据的格式,None 表示返回Python列表,也可以设置为 "pt"(PyTorch tensor)或 "tf(TensorFlow tensor)
return_tensors=None
)
print(out)输出:[101, 3217, 7599, 1282, 7027, 679, 1963, 872, 102, 4692, 2226, 1921, 678, 2226, 3221, 872, 102, 0, 0, 0, 0, 0, 0, 0, 0]
# 把数字还原成字符串
tokenizer.decode(out)输出:'[CLS] 春 风 十 里 不 如 你 [SEP] 看 尽 天 下 尽 是 你 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]'
1. [CLS] (Classification Token)
作用:分类标记,添加在每个输入序列的开头
用途:用于句子级分类任务,模型会将整个序列的信息聚合到该标记的最终隐藏状态中
ID:通常为101
2. [SEP] (Separator Token)
作用:分隔符标记,用于分隔不同的文本段
用途:
单句子任务:在句子末尾添加
句子对任务:分隔两个句子,在每个句子末尾都添加
ID:通常为102
3. [PAD] (Padding Token)
作用:填充标记,用于将序列填充到统一长度
用途:在批处理中保持序列长度一致,通常在序列末尾添加
ID:通常为0
进阶版编码函数
encode_plus:增强版编码方法,提供更多功能和更详细的输出信息
# 进阶版编码函数
out = tokenizer.encode_plus(
text=sents[0],
text_pair=sents[1],
truncation=True,
padding='max_length',
# 句子最大长度
max_length=25,
# 是否添加特殊字符, [cls]
add_special_tokens=True,
# 返回的数据类型, 默认返回列表, 可以返回Tensorflow, pytorch的tensor
return_tensors=None,
# 0, 1 表示是哪个句子的数据
return_token_type_ids=True,
# 有用部分标1, pad部分标0
return_attention_mask=True,
# 特殊字符标1, 其他位置标0
return_special_tokens_mask=True,
# 返回句子长度.
return_length=True
)
for k, v in out.items():
print(k, ':', v)输出:
input_ids : [101, 3217, 7599, 1282, 7027, 679, 1963, 872, 102, 4692, 2226, 1921, 678, 2226, 3221, 872, 102, 0, 0, 0, 0, 0, 0, 0, 0]
token_type_ids : [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
special_tokens_mask : [1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
length : 25
批量编码函数
# 批量编码函数
out = tokenizer.batch_encode_plus(
# 句子对
# 如果要对单句子编码, batch_text_or_text_pairs=[sents[0], sents[1], sents[2], ...]
batch_text_or_text_pairs=[(sents[0], sents[1])],
truncation=True,
padding='max_length',
max_length=25,
add_special_tokens=True,
return_tensors=None,
return_token_type_ids=True,
return_attention_mask=True,
return_special_tokens_mask=True,
return_length=True
)
for k, v in out.items():
print(k, ': ', v)字典
获取分词器字典
vocab = tokenizer.get_vocab()输出:
{...
傣': 994,
'傥': 995,
'储': 996,
'傩': 997,
'催': 998,
'傭': 999,
...}
添加新词
# 添加新词
tokenizer.add_tokens(new_tokens=['明月', '装饰', '窗子'])
for word in ['明月', '装饰', '窗子', '[EOS]']:
print(tokenizer.get_vocab()[word])添加特殊字符
# 添加特殊字符
tokenizer.add_special_tokens({'eos_token': '[EOS]'})
for word in ['明月', '装饰', '窗子', '[EOS]']:
print(tokenizer.get_vocab()[word])加载数据集
在 Hugging Face 生态中,加载数据集主要通过 datasets 库实现,支持从本地文件、内存数据或在线仓库快速加载和预处理数据。
从在线仓库加载数据集
from datasets import load_dataset
# 在代码中使用代理
import os
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
dataset = load_dataset('lansinuote/ChnSentiCorp',trust_remote_code=True)
print(dataset)DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 9600
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
})
train :训练集数据, validation:验证集数据集,test 测试集数据
将数据保存到磁盘上:
# 把数据保存到本地
dataset.save_to_disk('./data/ChnSentiCorp')从本地加载数据集
# ChnSentiCorp暂时在huggingface上下架了, 从本地加载
from datasets import load_from_disk
dataset = load_from_disk('./data/ChnSentiCorp/')
dataset加载大的数据集的子集
# 加载大的数据集中的数据子集
# 使用官方提供的解决方法, 解决了下载的问题.
load_dataset(path='glue', name='sst2', split='train')参数说明
path='glue'
指定要加载的数据集主类别
GLUE (General Language Understanding Evaluation) 是一个著名的自然语言理解基准数据集集合
name='sst2'
指定GLUE数据集中的具体子数据集
SST-2 (Stanford Sentiment Treebank 2) 是一个二分类情感分析数据集
包含电影评论句子,标签为正面(1)或负面(0)
split='train'
指定要加载的数据划分
只加载训练集部分,而不是整个数据集的所有划分
SST-2通常包含训练集(67,349条)、验证集(872条)和测试集(1,821条)
revision="script"
指定数据集构建脚本的版本
这是为了解决下载问题而使用的官方解决方案
确保使用正确的数据集构建脚本版本
评价指标
在 Hugging Face 生态中,模型评估通过统一的 evaluate 库(原 datasets 中的评估模块)实现,支持 200+ 种标准指标,涵盖 NLP、CV、语音等任务。
import os
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
# 安装 evaluate 库
#pip install evaluate
# 使用 evaluate 库替代 load_metric
import evaluate
metric = evaluate.load("glue", "mrpc")
accuracy_metric = evaluate.load("accuracy")
predictions = [0, 1, 1, 0, 1, 0, 0, 1]
references = [0, 1, 0, 0, 1, 1, 0, 1]
# 计算指标
results = accuracy_metric.compute(predictions=predictions, references=references)
print(results)情感分类案例
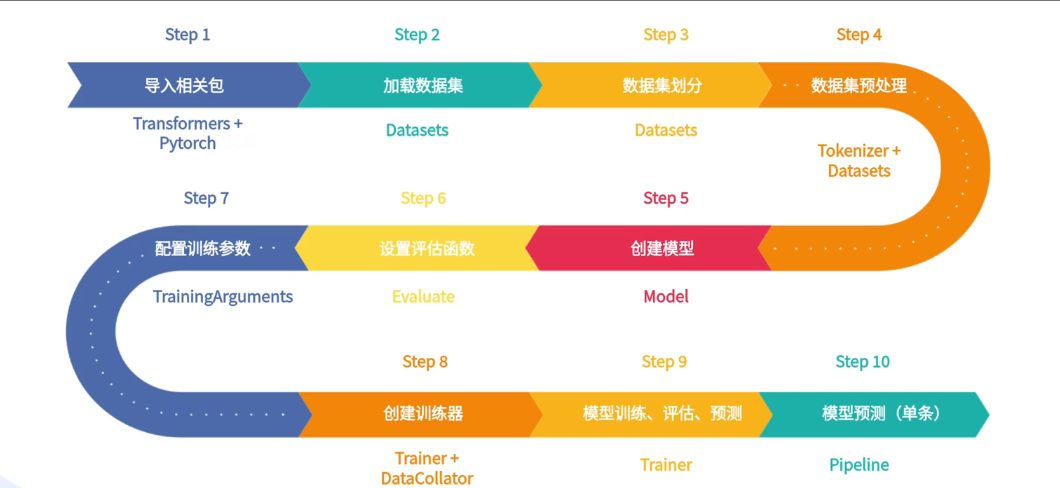
使用上述组件实现一个情感分类的小案例
第一步导包
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset第二步加载数据
#加载本地数据
dataset = load_dataset("csv", data_files="ChnSentiCorp_htl_all.csv", split="train")
#过滤掉没有review的数据
dataset = dataset.filter(lambda x: x["review"] is not None)在 load_dataset 函数中,split 参数用于指定要加载数据集的哪个分割部分。
split 参数的作用:
指定数据集分割:许多数据集被预定义为多个分割部分,如 train(训练集)、test(测试集)、validation(验证集)等。
直接加载特定部分:通过设置 split="train",代码直接加载训练集部分,而不是加载整个数据集的所有分割。
返回的是一个 Dataset 对象,而不是 DatasetDict 对象
本地数据格式如下:
label,review
0,距离马路太近有一些吵,房间比较小,住着不是很舒适.
1,商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!第三步数据集划分
#10%的数据用于测试
dataset_split = dataset.train_test_split(test_size=0.1)第四步数据预处理
#加载分词器 我这里加载本地已经下载的分词器
tokenizer = AutoTokenizer.from_pretrained("./models/dienstag/rbt3")
#数据预处理函数
def preprocess_function(examples):
#对review进行编码,长度大于128的截断
tokenized_examples = tokenizer(examples["review"], truncation=True, max_length=128)
#设置labels
tokenized_examples["labels"] = examples["label"]
return tokenized_examples
#删除原始列
tokenized_datasets = dataset_split.map(preprocess_function, batched=True, remove_columns=dataset_split["train"].column_names)因为hugging face下载太慢,这里从魔塔社区下载到本地后加载进来,下载脚本如下:
from modelscope.hub.snapshot_download import snapshot_download
snapshot_download(model_id="dienstag/rbt3", cache_dir="./models/")第五步创建模型
#加载本地模型
model = AutoModelForSequenceClassification.from_pretrained("./models/dienstag/rbt3")
#确保模型参数在内存中是连续存储的
for param in model.parameters():
param.data = param.data.contiguous()第六步设置评估函数
import evaluate
#准确率的评估函数 正确预测的样本数占总样本数的比例
acc_metric = evaluate.load("accuracy")
#f1的评估函数 精确率(Precision)和召回率(Recall)的调和平均数
f1_metric = evaluate.load("f1")
def eval_metric(eval_predict):
predictions, labels = eval_predict
#将模型输出的 logits 转换为具体的类别预测(找到概率最高的类别)
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metric.compute(predictions=predictions, references=labels)
# 将F1分数合并到准确率结果中
acc.update(f1)
#返回包含两个指标的评估结果
return acc第七步创建训练参数
args = TrainingArguments(
output_dir="./checkpoints", # 模型保存路径
learning_rate=2e-5, # 学习率设置为0.00002
per_device_train_batch_size=64, # 训练时每个设备的批次大小
per_device_eval_batch_size=128, # 评估时每个设备的批次大小
logging_steps=10, # 每10步记录一次日志
eval_strategy="epoch", # 每个epoch结束后进行评估
save_strategy="epoch", # 每个epoch结束后保存模型
save_total_limit=3, # 最多保存3个模型检查点
weight_decay=0.01, # 权重衰减系数,用于防止过拟合
metric_for_best_model="f1", # 以F1分数作为选择最佳模型的标准
load_best_model_at_end=True, # 训练结束时加载最佳模型
use_cpu=False
)第八步创建训练器
from transformers import DataCollatorWithPadding
trainer = Trainer(
model=model, # 指定要训练的模型
args=args, # 训练参数配置
train_dataset=tokenized_datasets["train"], # 指定训练数据集
eval_dataset=tokenized_datasets["test"], # 指定验证数据集
compute_metrics=eval_metric, # 指定评估指标计算函数
data_collator=DataCollatorWithPadding(tokenizer) # 数据整理器,用于批处理时对序列进行动态填充
)第九步模型训练
trainer.train()第十步模型评估
trainer.evaluate(tokenized_datasets["test"])
第十一步模型预测
trainer.predict(tokenized_datasets["test"])第十二步单条预测
from transformers import pipeline
sen = "不错下次还来"
id2_label = {0:"差评", 1:"好评"}
model.config.id2label = id2_label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
pipe(sen)第十三步保存模型
trainer.save_model("models/trained_model")
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)