大模型微调-1-基础知识概览
预训练是指在一个大型、通用数据集上,以自监督或无监督的方式,训练一个模型,使其学习到数据中内在的、可迁移的表示(Representations)。模型通过完成一些“前置任务(Pretext Tasks)”来学习,这些任务的设计目的是让模型在尝试解决它们的过程中,自然而然地掌握数据的有用特征,而不需要昂贵的人工标注微调是指在预训练模型的基础上,使用特定任务的小规模标注数据,对模型的全部或部分参数进行
什么是通用大模型?
通用大模型是一种基于深度学习的大规模人工智能模型,能够处理多种任务和场景,而无需针对每个具体任务单独设计模型。其核心特点是通用性、强泛化能力和多任务适应性,通常通过海量数据和庞大参数规模实现广泛的知识覆盖。
核心特点包括:
-
大规模参数
模型参数量通常达到数十亿甚至万亿级别,例如GPT-3有1750亿参数,通过大量数据训练捕获复杂模式。 -
多任务统一处理
可同时完成文本生成、翻译、问答、代码编写、逻辑推理等任务,突破传统AI模型的单一任务限制。 -
预训练加微调范式
先通过无监督学习从海量数据中学习通用知识,即预训练,再通过少量标注数据适配具体任务,即微调。 -
跨模态能力
部分通用大模型支持文本、图像、音频等多模态输入和输出,例如GPT-4和Gemini。
大模型分类
目前市面上常见的通用大模型可以根据其功能特点、应用领域和技术架构划分为以下几类:
一、按功能特点划分
文本生成与理解模型
这类模型专注于自然语言处理(NLP),擅长文本生成、翻译、问答、摘要等任务。
代表模型包括:
-
GPT系列(OpenAI):如GPT-3、GPT-4,以强大的文本生成能力著称
-
PaLM(Google):在大规模语言理解和生成方面表现突出
-
LLaMA(Meta):开源大语言模型,在多项NLP任务上表现优异
多模态模型
这类模型支持文本、图像、音频、视频等多种模态的输入和输出。
代表模型包括:
-
Gemini(Google):支持文本、图像、音频的多模态交互
-
GPT-4(OpenAI):增强了对图像和文本的联合处理能力
-
DALL-E(OpenAI):专注于文本到图像的生成
代码生成与理解模型
这类模型专门用于代码生成、调试、补全和跨语言转换。
代表模型包括:
-
Codex(OpenAI):支持多种编程语言的代码生成
-
AlphaCode(DeepMind):在竞争性编程任务中表现突出
-
CodeGeeX:开源代码生成模型,支持多种编程语言
二、按应用领域划分
通用领域模型
这类模型适用于广泛的日常任务,如对话、写作、翻译等通用场景。
代表模型包括:
-
ChatGPT(OpenAI):面向大众的对话式人工智能助手
-
Claude(Anthropic):注重安全性和有用性的通用对话模型
-
LLaMA 2(Meta):开源通用大语言模型,支持多种应用场景
垂直领域模型
这类模型针对特定专业领域进行深度优化,提供专业化的解决方案。
代表模型包括:
-
Med-PaLM 2(Google):专注于医疗健康领域,能够处理医学问答和诊断支持
-
BloombergGPT(彭博):针对金融领域训练的专业模型,擅长金融数据分析和预测
-
Codex(OpenAI):专注于代码生成和编程辅助的专用模型
-
Galactica(Meta):科技学术领域的专业模型,专注于科学文献处理和研究辅助
三、按技术架构划分
基于Transformer的模型
这类模型采用Transformer架构,利用自注意力机制处理长序列数据,是目前大模型的主流技术路线。
代表模型包括:
-
GPT系列(OpenAI):完全基于Decoder结构的Transformer模型
-
BERT(Google):基于Encoder结构的Transformer模型
-
T5(Google):采用Encoder-Decoder结构的通用架构
混合专家模型(MoE)
这类模型将整体架构划分为多个"专家"网络,根据输入内容动态选择部分专家进行计算,在保持模型能力的同时显著提升计算效率。
代表模型包括:
-
Switch Transformer(Google):大规模MoE架构的先行者
-
Mixtral 8x7B(Mistral AI):基于MoE架构的开源模型
-
GPT-4(OpenAI):据信采用了MoE架构来提升模型效率
开源与闭源模型
开源模型:
-
LLaMA系列(Meta):由Meta发布的开源大语言模型
-
BLOOM(BigScience):多语言开源大语言模型
-
Falcon(Technology Innovation Institute):开源的大规模语言模型
-
ChatGLM(智谱AI):开源的中英双语对话模型
闭源模型:
-
GPT系列(OpenAI):通过API提供服务,未开源模型权重
-
PaLM系列(Google):谷歌内部的闭源大模型
-
Claude(Anthropic):基于安全理念开发的闭源模型
-
Gemini(Google):谷歌的多模态闭源模型
四、按规模划分
超大规模模型
这类模型参数量达到千亿甚至万亿级别,需要巨大的计算资源和训练成本,但通常具有最强的能力。
代表模型包括:
-
GPT-4(OpenAI):参数量估计达1.8万亿,采用混合专家架构
-
PaLM 2(Google):参数量约3400亿,支持多语言任务
-
Claude 3(Anthropic):参数量未知,但据信达到千亿规模
中等规模模型
这类模型参数量在数十亿到数百亿级别,在性能和效率之间取得平衡,适合特定任务或资源有限的环境。
代表模型包括:
-
LLaMA 2 70B(Meta):700亿参数的开源模型,性能接近更大规模模型
-
Mixtral 8x7B(Mistral AI):实际参数量约467亿的混合专家模型
-
Falcon 180B(TII):1800亿参数的开源模型
-
Baichuan 2 53B(百川智能):530亿参数的中英双语模型
小规模模型
这类模型参数量通常在十亿以下,注重部署效率和轻量化,适合端侧部署或特定场景应用。
代表模型包括:
-
Phi-2(Microsoft):27亿参数的高性能小模型
-
Gemma 2B/7B(Google):轻量级开源模型系列
-
Qwen 1.8B(阿里巴巴):18亿参数的轻量级模型
-
ChatGLM3-6B(智谱AI):62亿参数的开源对话模型
预训练和微调
什么是预训练 (Pre-training)?
预训练是指在一个大型、通用数据集上,以自监督或无监督的方式,训练一个模型,使其学习到数据中内在的、可迁移的表示(Representations)。
模型通过完成一些“前置任务(Pretext Tasks)”来学习,这些任务的设计目的是让模型在尝试解决它们的过程中,自然而然地掌握数据的有用特征,而不需要昂贵的人工标注
主要的预训练技术
预训练技术根据数据类型(NLP、CV等)有所不同,但核心思想相通。
自然语言处理 (NLP) 中的预训练技术
现代NLP几乎完全建立在预训练模型(如BERT, GPT)之上。
1自回归语言建模 (Autoregressive Language Modeling)
核心:给定前面的词序列,预测下一个词是什么。(从左到右)
代表模型:GPT系列 (Generative Pre-trained Transformer)。
例子: “今天天气很___” -> 模型预测 “好”。
特点:非常擅长文本生成任务。
2自编码语言建模 (Autoencoding Language Modeling) / 掩码语言建模 (MLM)
核心:随机掩盖输入序列中的一些词(如用[MASK]替换),然后训练模型根据上下文来预测被掩盖的词。(双向理解)
代表模型:BERT (Bidirectional Encoder Representations from Transformers)。
例子: “今天天气很[MASK],我们去公园吧。” -> 模型预测 “好”。
特点:非常擅长文本理解任务(如分类、问答)。
3序列到序列 (Seq2Seq) 掩码语言建模
核心:对输入文本随机掩盖多个片段(Span),然后训练一个编码器-解码器模型来依次重建这些被掩盖的片段。
代表模型:T5 (Text-to-Text Transfer Transformer), BART。
特点:非常灵活,天然适合摘要、翻译、生成等任务。
计算机视觉 (CV) 中的预训练技术
传统CV使用在ImageNet上的有监督预训练(图像分类任务)。但现在更流行自监督预训练。
1有监督预训练 (Supervised Pre-training)
核心:在大型标注数据集(如ImageNet)上训练一个分类模型。
特点:模型学会了提取通用视觉特征(边缘、纹理、形状、物体部件)。
2对比学习 (Contrastive Learning)
核心:让模型学习“什么样的样本是相似的,什么样的样本是不相似的”。
方法:对一张图片进行两次不同的随机变换(裁剪、变色等),得到两个视图(正样本对)。模型需要学习将这两个正样本的表征拉近,同时将其与批次中其他图片的表征(负样本)推远。
代表模型:SimCLR, MoCo。
特点:无需标注,学习到的特征非常强大。
3掩码图像建模 (Masked Image Modeling - MIM)
核心:受BERT启发,随机掩盖图像的一部分 patches(块),然后训练模型来预测被掩盖部分的内容(如颜色、特征向量)。
代表模型:MAE (Masked Autoencoders), SimMIM。
特点:成为CV领域最前沿的预训练范式,效果极佳。
什么是微调 (Fine-tuning)?
微调是指在预训练模型的基础上,使用特定任务的小规模标注数据,对模型的全部或部分参数进行额外的训练,以使其优化在该任务上的性能。
主要的微调技术
微调技术不断发展,旨在更高效、更稳定地利用预训练模型。
-
全量微调 (Full Fine-tuning)
-
方法:这是最经典的方法。加载预训练权重,然后在目标任务数据上,更新模型的所有参数。
-
优点:性能潜力最大。
-
缺点:计算成本高,存储成本高(每个任务都需要保存一份完整的模型副本),可能存在灾难性遗忘(Catastrophic Forgetting),即模型忘记了预训练中学到的通用知识。
-
-
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
PEFT技术可以根据其“如何引入可训练参数”的方式分为以下几大类:
1. 选择性微调(Selective Fine-tuning)
这类方法通过有选择地更新原模型的一部分参数来实现高效微调。
-
冻结微调 (Freeze-tuning)
-
方法:冻结预训练模型的绝大部分层(通常是底层),只对最顶部的几层或者新添加的任务特定层(如分类头)进行训练。
-
优点:简单直观,大幅降低计算成本。
-
缺点:性能牺牲较大,因为完全禁止了底层参数的适应。
-
-
渐进式微调 / 分层学习率 (Discriminative Learning Rates)
-
方法:这是对【冻结微调】的精细化改进。不同层使用不同的学习率。底层(通用特征)使用极小的学习率(微调而非冻结),顶层(任务相关特征)使用较大的学习率。
-
优点:在保持通用知识不大幅改变的同时,允许所有层为任务做细微调整。是实践中最常用、最基础的技巧之一,常与其他PEFT方法结合使用。
-
2. 附加适配器(Add-on Adapters)
这类方法完全冻结预训练模型,通过插入额外的、轻量级的可训练模块来适应新任务。
-
适配器微调 (Adapter Tuning)
-
方法:在Transformer层的内部(通常在Feed-Forward网络之后)插入一个小的神经网络模块(Adapter)。微调时,只训练这些Adapter。
-
优点:参数效率高,避免了灾难性遗忘。
-
缺点:会在模型中引入额外的推理延迟(虽然很小),因为增加了计算步骤。
-
-
提示微调 (Prompt Tuning)
-
方法:在输入序列前添加一串可学习的连续向量(软提示)。模型主体完全冻结,仅训练这些提示向量。
-
优点:参数效率极高,完全无推理延迟(提示可与输入拼接后一起处理)。
-
缺点:在模型参数规模较小(<10B)时效果不如其他方法,但随着模型增大,效果显著提升。
-
3. 低秩优化(Low-Rank Optimization)
这类方法基于一个核心假设:模型微调过程中的权重更新是低秩(Low-Rank) 的。它们不改变原模型结构,也不添加新模块,而是用一种参数高效的方式模拟参数更新。
-
低秩适应 (LoRA)
-
方法:这是当前最主流的PEFT方法。对于原权重矩阵
W,不直接更新它,而是用两个低秩矩阵B和A的乘积来模拟其更新:ΔW = BA。前向传播变为h = Wx + BAx。只训练A和B。 -
优点:
-
高性能:常能达到与全量微调相当甚至更好的效果。
-
零推理延迟:训练完成后,可将
BA合并到W中,推理时与原始模型结构、速度完全一致。 -
模块化:多个任务可以共享同一个基础模型,通过加载不同的LoRA权重(仅几MB)来切换任务。
-
-
4. 混合方法(Hybrid Methods)
许多现代PEFT框架会融合以上多种思想,以实现最佳效果。
-
P-Tuning系列:可以看作是【提示微调】的增强版(如P-Tuning v2引入了在每一层都添加提示的概念,类似于Prefix Tuning)。
-
AdaLoRA:可以看作是【LoRA】的自适应升级版,它会动态分配低秩矩阵的秩,将更多参数分配给更重要的层,进一步提升参数效率。
-
QLoRA:是【LoRA】的量化版本,通过将模型以4bit量化加载,极大降低了微调时的内存需求,使得在单张消费级GPU上微调大模型成为可能。
PEFT技术全景图总结
| 分类 | 代表方法 | 核心思想 | 参数量 | 推理延迟 | 特点 |
|---|---|---|---|---|---|
| 选择性微调 | 分层学习率 | 不同层以不同速率学习 | 全部参数 | 无 | 基础实用技巧 |
| 附加适配器 | Adapter | 插入小型神经网络模块 | 中等 | 有 | 模块化,开创性 |
| 低秩优化 | LoRA/QLoRA | 低秩矩阵模拟权重更新 | 少 | 无 | 当前主流,最佳平衡 |
| 参数化控制 | IA3 | 学习缩放向量控制激活值 | 极少 | 无 | 极其高效,理念新颖 |
| 提示优化 | Prompt Tuning | 优化输入端的连续提示 | 少 | 无 | 适合极大模型 |
| 统一框架 | UniPELT | 门控机制动态组合多种方法 | 中等 | 取决于组件 | 自适应,性能稳健 |
Rag和微调的区别
微调
内部参数调整。通过训练数据直接更新模型的权重参数,将新知识或风格“内化”到模型之中。
RAG
外部知识库 + 检索。将模型与外部知识源连接,在回答问题时先检索相关信息,再让模型基于这些信息生成答案。
RAG和微调不是互斥的选择,而是可以协同工作的强大组合。
结合两者可以构建出更强大、更可靠的AI系统:
-
用微调优化RAG中的LLM:
-
你可以用一个经过微调的领域模型作为RAG中的生成器。这个模型已经内化了很多领域术语和逻辑,因此它能更好地理解检索到的上下文片段,并生成更专业、更符合领域风格的答案。
-
例如:先用法学数据微调一个LLM,再将它用于法律条文检索问答(RAG)系统中,它生成的答案会比通用LLM更精准。
-
-
用RAG为微调提供数据:
-
RAG系统在与用户交互时,可以记录下那些“检索到了高质量文档且生成了优秀回答”的案例。这些高质量的(问题,检索上下文,回答)三元组可以作为微调训练的优质数据集,用于进一步优化模型。
-
-
混合系统(Hybrid System):
-
一个完整的系统可以同时利用两种技术:
-
对于事实性、实时性问题:优先使用RAG路径,确保答案准确、最新。
-
对于创造性、风格化任务:调用经过相应微调的模型来生成内容。
-
-
系统需要一个“路由”机制来判断用户查询应该走哪条路径,或者如何组合两者。
-
如何选择?
如果你的核心需求是提供准确、最新的 factual 信息,并且可追溯来源 -> 选择 RAG。
如果你想改变模型的“性格”、写作风格,或教会它一种新的复杂推理能力 -> 选择 微调。
如果你想要一个最强大的解决方案,并且不介意系统的复杂性 -> 结合使用 RAG 和 微调。
大模型微调过程详解(以Qwen为例)
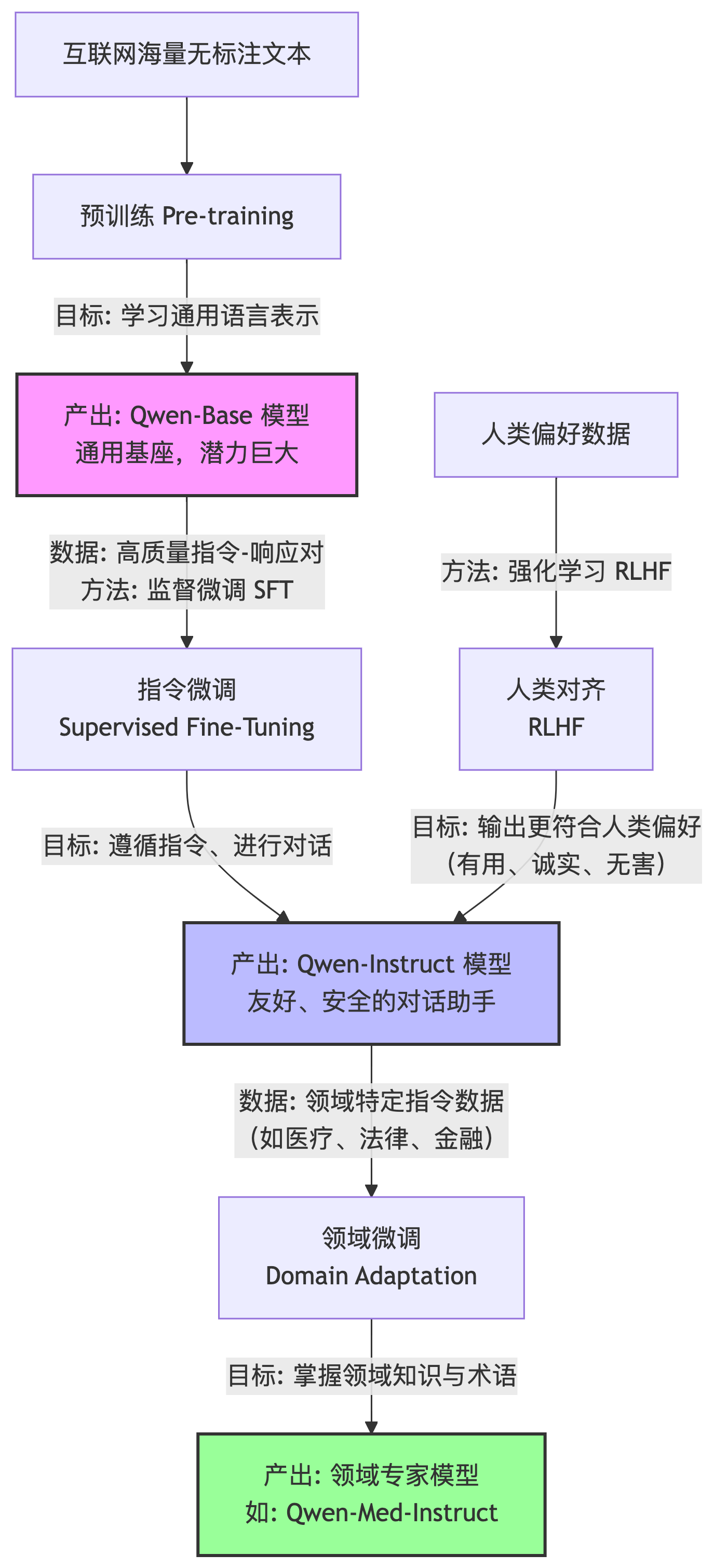
模型微调的过程以Qwen系列为例,微调过程可以分为以下几个步骤:
首先是预训练。目标是让模型学习通用语言表示。数据使用大规模无标注文本如互联网数据。结果是得到Qwen-Base模型。
第二步是指令微调。目标是让模型适应特定任务如对话和问答。数据使用高质量的指令-响应对。方法是在Qwen-Base模型的基础上使用指令数据进行微调,通过监督学习或强化学习优化模型参数。结果是得到Qwen-Instruct模型,这个模型可直接用于智能助手和内容生成等场景。
第三步是领域微调,这是可选的步骤。目标是让模型在特定领域如医疗和法律表现更好。数据使用领域相关的指令数据。结果是得到领域专用的Instruct模型例如Qwen-Med-Instruct,这类模型在医疗领域表现更优,适用于医疗问答和诊断辅助等场景。
微调的实际意义包括三个方面:
提升任务性能,通过微调,模型能够更好地理解和执行特定任务;
降低开发成本,无需从头训练模型,只需在Base模型上进行微调;
快速适配新任务,通过少量数据即可微调出专用模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)