深入浅出:从实战项目掌握高级 RAG 技术
高级RAG实战系统解析 本文介绍一个面向实战的高级检索增强生成(RAG)系统,融合向量检索、BM25关键词检索、知识图谱等多项技术,解决传统RAG的语义匹配不足问题。系统采用分层架构,集成Ollama本地大模型和bge-m3多语言嵌入模型,支持7个典型场景演示,包括混合检索对比、查询扩展和多语言处理等核心功能。通过完整的性能分析和可视化对比,系统展示了查询重排序、结果融合等关键技术实现,为开发者提
1. 导论:RAG 技术新范式
检索增强生成(Retrieval-Augmented Generation,简称 RAG)技术通过引入外部知识库,有效解决了大语言模型(LLM)的“知识幻觉”和知识更新滞后等问题。但基础的 RAG 流程,即单纯的向量检索,在面对复杂查询、长尾问题或对关键词匹配有高要求的场景时,仍显不足。
对于高级RAG技术,很多文章都停留在理论讲解上,对于初学者理解起来比较抽象和困难,也导致无法很好的应用于实战。基于此,本文以一个完整的高级 RAG 演示系统为例进行技术讲解,它集成了多种前沿技术,旨在通过一个面向实战的系统,帮助你深入理解和掌握更强大的 RAG 策略。本文将以该系统为基础,为你剖析其核心架构与高级技术实现。
系统特色
- 本地大模型: 基于Ollama,支持qwen3、DeepSeek、Llama等多种模型
- 先进嵌入: 集成bge-m3多语言嵌入模型
- 混合检索: 向量检索 + BM25关键词检索
- 知识图谱: 结构化知识表示和推理
- 完整演示: 7个不同场景的对比演示
- 性能分析: 详细的性能对比和可视化
- 面试准备: 技术面试指南
系统架构
┌─────────────────────────────────────────────────────────────┐
│ 高级RAG系统架构 │
├─────────────────────────────────────────────────────────────┤
│ 应用层 │
│ ├── 演示场景 (7个不同场景) │
│ ├── 性能分析 (可视化对比) │
│ └── API接口 (易于集成) │
├─────────────────────────────────────────────────────────────┤
│ 生成层 │
│ ├── Ollama集成 (本地大模型) │
│ ├── 提示工程 (优化生成) │
│ └── 答案生成 (基于检索内容) │
├─────────────────────────────────────────────────────────────┤
│ 检索层 │
│ ├── 向量检索 (语义相似度) │
│ ├── BM25检索 (关键词匹配) │
│ ├── 混合检索 (融合优化) │
│ ├── 重排序 (交叉编码器) │
│ └── 查询扩展 (LLM增强) │
├─────────────────────────────────────────────────────────────┤
│ 嵌入层 │
│ ├── bge-m3模型 (多语言嵌入) │
│ ├── ChromaDB (向量存储) │
│ └── 相似度计算 (余弦相似度) │
├─────────────────────────────────────────────────────────────┤
│ 数据层 │
│ ├── 文档加载 (多格式支持) │
│ ├── 文本分块 (智能分割) │
│ ├── 知识图谱 (实体关系) │
│ └── 索引构建 (高效存储) │
└─────────────────────────────────────────────────────────────┘
演示场景
系统提供7个完整的演示场景,展示不同RAG技术的效果:
场景1: 基础RAG演示
- 展示基本RAG功能
- 向量检索效果
- 回答质量评估
场景2: 混合检索对比
- 向量检索 vs BM25检索 vs 混合检索
- 性能对比分析
- 效果可视化
场景3: 查询扩展效果
- 有/无查询扩展对比
- 召回率提升分析
- 相关性评估
场景4: 多语言支持
- 中英文混合查询
- 跨语言检索能力
- 语言适应性展示
场景5: 领域特定查询
- 技术领域问题
- 业务场景应用
- 专业性评估
场景6: 性能对比分析
- 不同搜索策略性能测试
- 响应时间对比
- 吞吐量分析
场景7: 错误处理演示
- 边界情况处理
- 异常查询处理
- 系统稳定性展示
🔧 核心功能
1. 混合检索 (Hybrid Retrieval)
# 向量检索 + BM25关键词检索
results = rag_system.hybrid_search(query)
2. 查询扩展 (Query Expansion)
# 自动生成相关查询
expanded_queries = rag_system.query_expansion(query)
3. 重排序 (Re-ranking)
# 优化检索结果排序
reranked_results = rag_system.rerank_results(query, results)
4. 知识图谱 (Knowledge Graph)
# 结构化知识检索
kg_results = rag_system.knowledge_graph_search(query)
5. 多语言支持
# 中英文混合处理
response = rag_system.query("What is artificial intelligence?")
2. 系统核心架构与技术栈
本演示系统采用分层架构设计,实现了模块化和高可扩展性。其整体架构可概括为以下几层:
- 大语言模型集成:本项目使用 Ollama 作为本地 LLM 运行框架,支持如 qwen3:8b、llama2 等多种模型,提供了隐私保护和成本可控的优势。
- 嵌入模型:采用 bge-m3 这一多功能嵌入模型,其强大的多语言(支持中英双语)和长文本处理能力为高质量的向量检索奠定了基础。
- 向量数据库:项目选择 ChromaDB,一个轻量级且易于部署的开源向量数据库,用于持久化存储文本块的向量表示。
- 文档处理:使用 LangChain 进行文档加载和分块,支持多种格式(如 TXT、PDF、Markdown)。
3. 高级 RAG 关键技术详解
基础 RAG 仅依赖向量检索,但当查询与文档语义不完全匹配,或存在关键词依赖时,检索效果会大打折扣。本项目通过以下高级技术进行增强。
3.1 混合检索(Hybrid Retrieval)
混合检索是 RAG 优化的首选策略,它结合了向量检索(侧重语义相似度)和关键词检索(如 BM25,侧重关键词匹配),从而提升召回率和准确率。
理论:
- 向量检索:捕捉查询的语义意图,即使关键词不匹配也能找到相关内容。
- BM25 检索:基于词频和逆文档频率(TF-IDF)变体,精准匹配查询中的关键词,适合查找专有名词或特定短语。
- 结果融合:将两种检索结果进行加权合并或排序融合,得到最终的检索结果。
代码实践:
在 rag_ollama_advanced.py 中,query 方法根据 search_type 参数选择检索方式。当 search_type 为 hybrid 时,系统会同时执行向量检索和 BM25 检索。
# rag_ollama_advanced.py
# ...
def query(self, query: str, search_type: str = "hybrid") -> Dict[str, Any]:
...
retrieved_chunks: List[str] = []
if search_type == "hybrid":
# 执行混合检索
hybrid_results = self._hybrid_search(query, self.config.top_k)
retrieved_chunks = [res['content'] for res in hybrid_results]
elif search_type == "vector":
# 执行纯向量检索
vector_results = self._vector_search(query, self.config.top_k)
retrieved_chunks = [res['content'] for res in vector_results]
elif search_type == "bm25":
# 执行纯BM25检索
bm25_results = self._bm25_search(query, self.config.top_k)
retrieved_chunks = [res['content'] for res in bm25_results]
# ...
3.2 查询扩展(Query Expansion)
当用户查询过于简短或模糊时,直接检索可能遗漏相关信息。查询扩展利用 LLM 的生成能力,为原始查询生成多个相关的、更具描述性的新查询。
理论:
- LLM 增强:LLM 能够根据原始查询,从不同角度和侧面生成相关疑问或关键词,例如将“向量数据库”扩展为“向量数据库的优缺点”或“什么是 ChromaDB”等。
- 并行检索:将原始查询和所有扩展查询进行并行检索,扩大检索范围,从而提高召回率。
代码实践:
rag_ollama_advanced.py 中的 _generate_expanded_queries 方法实现了该功能。它通过一个明确的提示词(Prompt)让 LLM 生成多个与原始查询相关的变体。
# rag_ollama_advanced.py
#...
def _generate_expanded_queries(self, query: str) -> List[str]:
"""使用LLM生成相关查询以进行查询扩展"""
prompt = f"""
你是一个AI助手,擅长根据用户查询生成相关的、多样化的查询。
请根据以下用户查询,生成3个与它高度相关的、不同视角的查询。
用户查询: {query}
请直接以JSON数组格式返回,不要包含其他任何文本。
示例: ["查询1", "查询2", "查询3"]
"""
response = self.ollama_client.generate(
model=self.config.ollama_model,
prompt=prompt
)
# ...
3.3 重排序(Reranking)
重排序是 RAG 流程中的关键优化环节,旨在提升检索结果的精确性和相关性。它在初步检索(如混合检索)得到一个候选文档集后,使用一个更强大的模型对这些文档与原始查询的相关性进行重新打分和排序,从而将最相关的文档排在前面。
理论:
- 双塔模型局限:传统的向量检索采用双塔模型(Dual-Encoder),即查询和文档分别独立编码,计算相似度。这种方式计算高效,但在捕捉深层次语义交互方面存在不足。
- 交叉编码器优势:重排序模型通常使用交叉编码器(Cross-Encoder),它将查询和文档拼接后,作为整体输入到模型中,让模型可以更细致地理解二者之间的交互关系,从而进行更精准的相关性判断。
- 流程:初次检索(如向量或BM25)负责召回(Recall),即尽可能多地找出潜在相关的文档;重排序则负责排序(Ranking),即从召回的文档中找出最相关的Top-K个。
代码实践:
本项目架构中预留了重排序功能 (README_OLLAMA.md 中 use_reranking=True),但在 rag_ollama_advanced.py 中并未直接实现一个完整的重排序模型。通常,重排序会作为 query 方法中 hybrid 或 vector 检索之后的一个可选步骤。其逻辑流程如下:
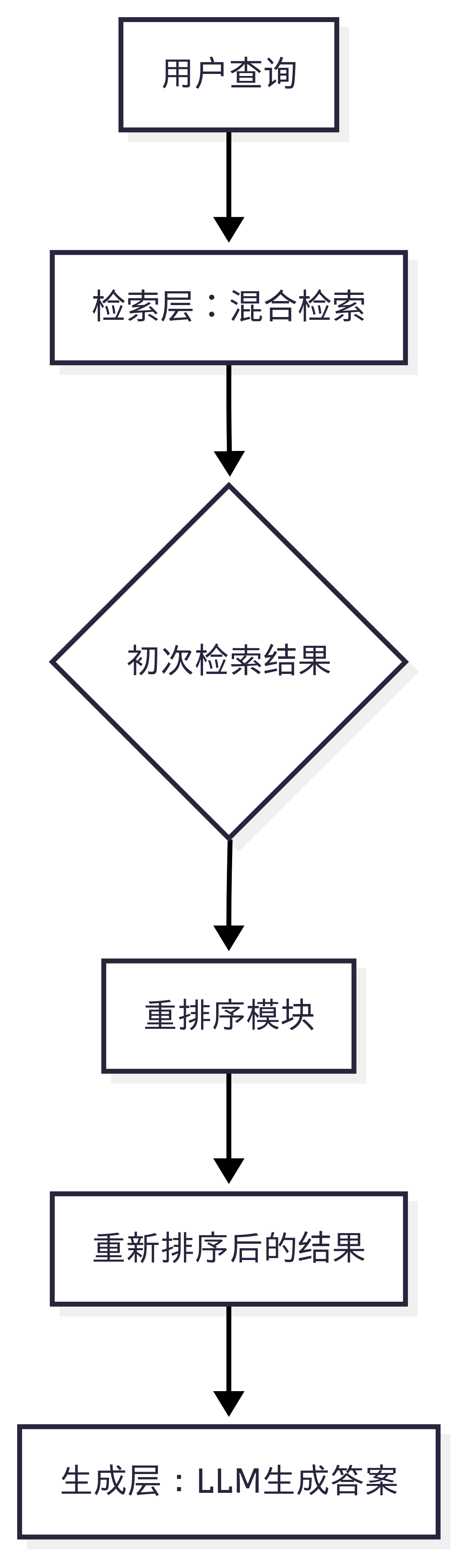
在实际项目中,你可以将一个 Reranker 模型集成到系统中,例如使用 Sentence-Transformers 库中的交叉编码器模型,在得到 hybrid_results 后,调用该模型对结果进行二次排序。
3.4 知识图谱(Knowledge Graph)
知识图谱是一种将知识以实体-关系-实体(Entity-Relation-Entity)三元组形式结构化存储的表示方法。当面对需要基于事实、关系或推理的复杂查询时,知识图谱能够提供比非结构化文本更精准、更可控的检索能力。
理论:
- 结构化知识:知识图谱将非结构化文本中的信息,如“苹果公司”和“史蒂夫·乔布斯”之间的“创始人”关系,显式地表示出来。
- 多跳推理:可以利用图算法进行多跳推理,例如查询“苹果公司创始人的第一份工作是什么?”时,可以从“苹果公司”跳到“史蒂夫·乔布斯”,再跳到他的第一份工作。
- RAG 增强:知识图谱可以作为一种独特的检索来源,与向量检索、BM25检索互补,特别适合回答事实性、定义性或需要关系推理的问题。
代码实践:
在 rag_ollama_advanced.py 中,知识图谱模块通过以下步骤实现:
- 初始化:在系统启动时,调用 _initialize_knowledge_graph 方法,遍历所有文档,提取其中的实体和关系,构建一个 networkx 图对象。
# rag_ollama_advanced.py
def _initialize_knowledge_graph(self):
"""从所有文档中提取实体和关系并构建知识图谱"""
#...
for doc in self.all_documents:
entities_and_relations = self._extract_entities_and_relations(doc.page_content)
for triple in entities_and_relations:
# 添加实体(节点)
self.knowledge_graph.add_node(triple['head'], type='entity', text=triple['head'])
self.knowledge_graph.add_node(triple['tail'], type='entity', text=triple['tail'])
# 添加关系(边)
self.knowledge_graph.add_edge(triple['head'], triple['tail'], relation=triple['relation'])
- 实体和关系提取:_extract_entities_and_relations 方法使用 LLM 来从文本中识别并提取三元组。这个过程是基于 LLM 的生成能力,让它以结构化的 JSON 格式返回结果。
# rag_ollama_advanced.py
def _extract_entities_and_relations(self, text: str) -> List[Dict[str, str]]:
"""使用LLM从文本中提取实体和关系三元组"""
prompt = f"""
你是一个AI助手,擅长从文本中提取知识图谱三元组(实体1, 关系, 实体2)。
请从以下文本中提取所有可用的三元组,并以JSON数组格式返回,每个元素是一个字典。
...
"""
response = self.ollama_client.generate(
model=self.config.ollama_model,
prompt=prompt
)
# ...
- 知识图谱检索:在 query 方法中,当 search_type 为 “kg” 时,系统会使用图算法在知识图谱中进行检索和推理,而不是传统的文本检索。
4. 动手实践:系统部署与演示
为了更好地理解上述技术,你可以运行项目中的演示脚本。
- 环境准备:
- 首先,运行 setup_ollama.py 脚本,它将检查你的系统是否安装了 Ollama 服务。
- 如果未安装,脚本会引导你进行安装;如果已安装,它会检查服务是否正在运行,并提示你下载推荐的 LLM 模型(如 qwen3:8b)和嵌入模型(如 bge-m3)。
- 数据加载与演示:
- 运行 rag_ollama_advanced.py,它会自动加载 ./data 目录下的文档,进行分块、嵌入并建立索引,同时构建 BM25 和知识图谱索引。
- 运行 demo_scenarios.py,该脚本包含了 7 个不同的演示场景,包括基础 RAG、混合检索对比和查询扩展效果等。你将直观地看到不同技术如何影响检索结果和最终答案。
- 演示脚本还提供了性能可视化功能,可以生成图表,对比不同检索策略的查询时间、检索结果数和相关性分数。
- API 服务:
- 项目还提供了基于 FastAPI 的 API 服务 api_server.py,允许你将高级 RAG 功能封装为 RESTful API,方便集成到其他应用程序中。
通过以上实践,你将不仅能理解高级 RAG 的理论,更能掌握其在实际项目中的实现细节,为你的技术面试和项目开发打下坚实基础。
5. 加餐:面试常见问题
1. 基础概念
Q: 什么是RAG?为什么需要RAG?
A: RAG(Retrieval-Augmented Generation)是检索增强生成技术,结合信息检索和文本生成。需要RAG的原因:
- 解决大模型知识更新滞后问题
- 减少幻觉现象
- 提供可追溯的信息来源
- 支持私有知识库
Q: RAG与微调的区别?
A:
- RAG:外挂知识库,实时更新,成本低,可解释性强
- 微调:内化知识,训练成本高,更新困难,黑盒化
2. 技术实现
Q: 如何实现混合检索?
A:
- 向量检索:使用嵌入模型进行语义搜索
- BM25检索:基于词频的关键词搜索
- 结果融合:加权合并或排序融合
- 重排序:使用交叉编码器优化结果
Q: 如何处理长文档?
A:
- 层级分块:不同粒度的文本分块
- 滑动窗口:保持上下文连贯性
- 摘要提取:关键信息压缩
- 递归总结:分层摘要构建
3. 优化策略
Q: 如何提高RAG系统准确性?
A:
- 查询优化:扩展、重写、澄清
- 检索优化:混合检索、重排序、过滤
- 上下文优化:精准分块、噪声过滤
- 生成优化:提示工程、约束生成
Q: 如何评估RAG系统效果?
A:
- 检索评估:召回率、准确率、MRR
- 生成评估:BLEU、ROUGE、人工评估
- 端到端评估:答案准确性、相关性
- 业务指标:用户满意度、任务完成率
4. 实际应用
Q: RAG在企业中的典型应用场景?
A:
- 智能客服:基于知识库的问答
- 文档分析:合同、报告解读
- 辅助决策:数据分析和建议
- 培训教育:个性化学习助手
Q: 实施RAG系统的挑战?
A:
- 数据质量:文档清洗、结构化
- 性能优化:实时响应、成本控制
- 安全合规:数据隐私、访问控制
- 持续优化:反馈循环、模型更新
准备好开始你的高级RAG之旅了吗? 🎯
立即运行 python setup_ollama.py 开始体验!
这个项目将帮助你:
✅ 深入理解现代RAG技术
✅ 掌握实际开发技能
✅ 准备技术面试
✅ 构建生产级应用
祝你学习愉快!🎉
请访问我的微信公众号“大模型RAG和Agent技术实践”,获取完整系统项目源代码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 41
41 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)