医疗多智能体系统设计:大模型防幻觉终极方案:从 “生成式架构“ 向 ”验证式架构“ 转变
借助医疗知识网络连接各种医疗信息源,把所有医学知识建成一个域(一个中心+N个扩展),使得无损长上下文中稳定管理多维信息,同时解决语义检索捕获不了的长尾关系(不太常见但可能很重要的信息 — 因为长尾知识通常存在于细节和上下文中,而不是简单的实体关系中)。构建一个医疗多智能体问答系统:接收医生的复杂医疗问题,通过多个智能体协作,从知识图谱中检索、验证、整合信息,最终输出准确、可追溯的医疗建议。同时,用
医疗多智能体系统设计:大模型防幻觉终极方案:从 “生成式架构“ 向 ”验证式架构“ 转变
多智能体分工协作:医疗AI的"专家会诊"模式
通过逐步验证机制代替一步到位,减少了单个环节出错的影响。
同时,用专门智能体团队处理不同类型的医疗任务,每个智能体只负责自己最擅长的部分,提高了整体可靠性。
借助医疗知识网络连接各种医疗信息源,把所有医学知识建成一个域(一个中心+N个扩展),使得无损长上下文中稳定管理多维信息,同时解决语义检索捕获不了的长尾关系(不太常见但可能很重要的信息 — 因为长尾知识通常存在于细节和上下文中,而不是简单的实体关系中)。
再通过多层推理分析(多维 + 多跳),发现表面看不出的疾病关联和治疗线索。
五大核心智能体的分工
1. 问题拆解专员
职责:把医生提出的复杂问题"切片"成一个个具体任务
工作方式:就像项目经理拆解需求
- 原始问题:“这个患者有EGFR基因突变,该如何用药?”
- 拆解结果:
- 子任务1:查询EGFR基因突变的类型和特征
- 子任务2:分析该突变对药物代谢的影响
- 子任务3:匹配个体化治疗方案
2. 知识搜索专员
职责:在海量医学资料中精准"捞针"
工作范围:
- 医学知识图谱(疾病-症状-药物关系网)
- 权威医学文献库(中华医学会指南、国际顶级期刊)
- 临床试验数据库(真实世界证据)
特点:不是简单搜索,而是"精准定位"——知道去哪找、怎么找
3. 证据核查专员
职责:给每条信息"打分验真"
核查方法:
- 多源对比:同一个结论,在临床指南里怎么说?真实病例中怎么做?
- 一致性检验:不同来源的信息是否相互印证?
- 可信度评级:这个证据是金标准,还是仅供参考?
类比:就像论文查重系统,但查的是医学证据的可靠性
4. 争议仲裁专员
职责:当证据"打架"时做最终裁决
裁决原则(优先级从高到低):
- 国家级诊疗指南 > 国际共识
- 大规模随机对照试验 > 小样本研究
- 多中心研究 > 单中心报道
- 最新证据 > 历史文献
举例: - 证据A说"用药剂量100mg"(来自2020年指南)
- 证据B说"用药剂量150mg"(来自2023年大型临床试验)
- 裁决:采用150mg,因为证据更新、样本更大
5. 报告撰写专员
职责:把所有信息整合成一份"看得懂、用得上"的报告
报告要素:
- 核心结论:直接回答医生的问题(开门见山)
- 证据链条:每个结论都标注出处(句句有来源)
- 置信程度:明确告知哪些是确定的,哪些存在争议
- 决策建议:给出可操作的临床建议
- 参考文献:完整的引用列表(便于深入查证)
为什么这种分工如此重要?
对比单一模型的问题:
- 让一个模型"全能",就像让一个医生同时做检验、影像、手术、康复——不现实
- 单一模型容易在某个环节"掉链子",导致整体出错
多智能体的优势:
- 专业的事交给专业的"人":检索的只管检索,验证的只管验证
- 层层把关:一个环节出错,下一环节能发现并纠正
- 可解释性强:每个决策步骤都清晰可见,便于追责和改进
- 灵活升级:某个智能体表现不佳,单独优化即可,不影响整体
实际运行示例
场景:医生询问"乳腺癌HER2阳性患者的治疗方案"
流程追踪:
1. 问题拆解专员 → 识别出3个关键任务
2. 知识搜索专员 → 检索到8份相关指南、12篇核心文献
3. 证据核查专员 → 发现2份指南存在细节差异
4. 争议仲裁专员 → 根据证据等级,采用2024年NCCN指南
5. 报告撰写专员 → 生成结构化报告,明确推荐"曲妥珠单抗+帕妥珠单抗"方案
这种架构确保了:即使单个环节有瑕疵,通过多重验证和协作,最终输出依然可靠。这就是验证式架构的精髓——不是相信一次生成,而是通过分工协作和层层验证,确保每个结论都经得起推敲。
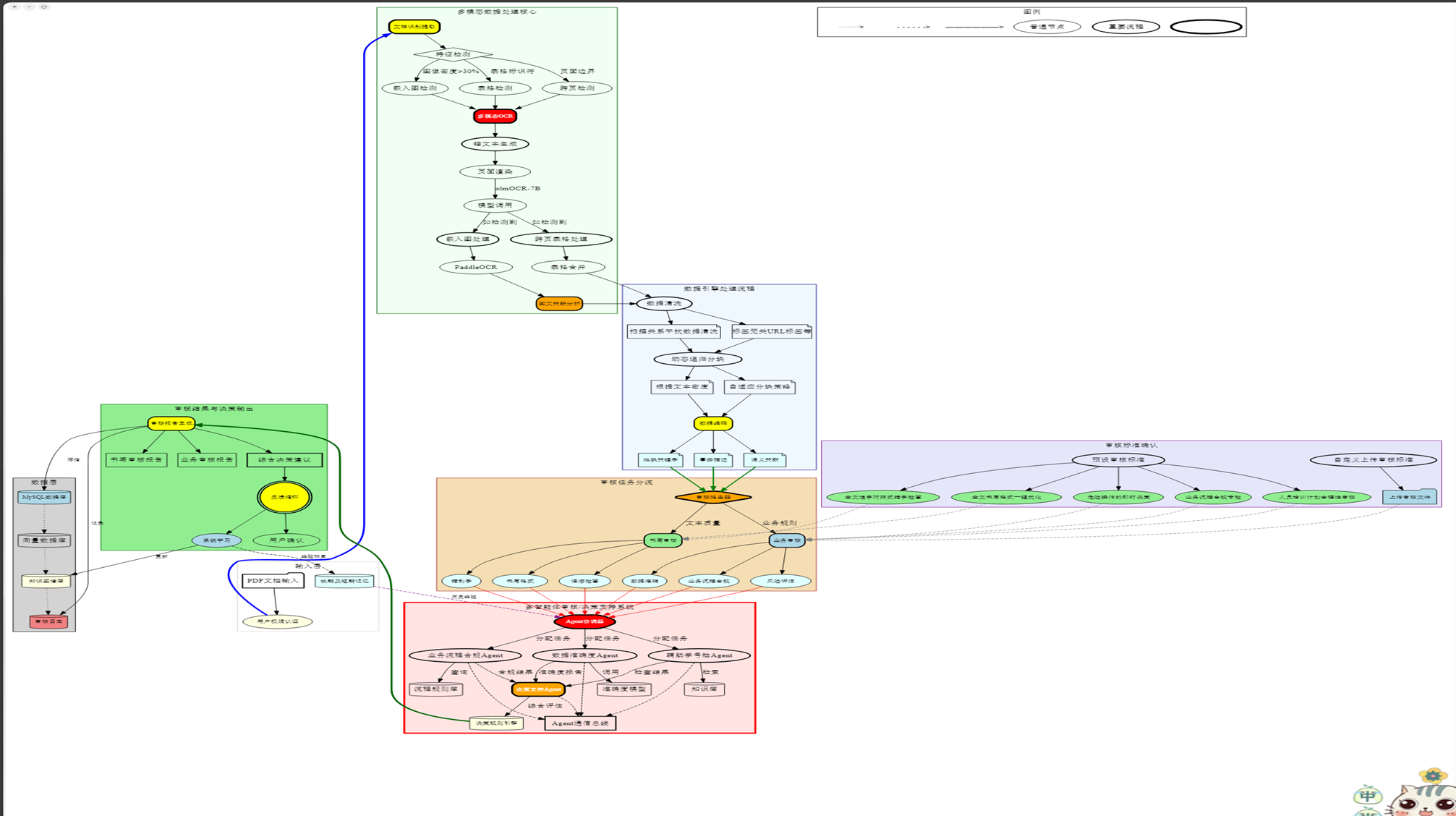
沉浸式角色扮演分析
构建一个医疗多智能体问答系统:接收医生的复杂医疗问题,通过多个智能体协作,从知识图谱中检索、验证、整合信息,最终输出准确、可追溯的医疗建议。
def medical_qa_system_main(user_question: str) -> dict:
"""
主函数:医疗问答系统的领导者
我只负责调度各个智能体,把握整体流程节奏
"""
# 1. 任务分派:把复杂问题拆解
subtasks = task_dispatcher_agent(user_question)
# 2. 知识检索:并行检索各个子任务
raw_knowledge = knowledge_retriever_agent(subtasks)
# 3. 交叉验证:验证检索结果的可靠性
validated_knowledge = cross_validator_agent(raw_knowledge)
# 4. 冲突解决:处理矛盾信息
resolved_knowledge = conflict_resolver_agent(validated_knowledge)
# 5. 报告生成:整合成专业报告
final_report = report_generator_agent(resolved_knowledge)
return final_report
如果我是任务分派智能体:
- 我吃什么:医生提出的复杂医疗问题(自然语言文本)
- 我如何消化:用NLP技术解析问题,识别医疗实体、意图和关键词
- 我产生什么:结构化的子任务列表,每个都有明确的检索目标
- 我不能做什么:不能直接给出医疗建议,只负责理解和拆解
- 我追求什么:问题拆解的准确性和完整性
【策略1:思路分解粒度控制】
粗粒度分解(概念层):
- 理解医生问题
- 拆分成子任务
- 安排执行顺序
中粒度分解(逻辑层):
- 接收问题文本
- 提取医疗实体
- 识别问题意图
- 创建任务列表
- 设置优先级
- 返回任务序列
细粒度分解(可实现层):
- 接收字符串参数
- 调用分词工具切分句子
- 用医疗词典匹配实体(疾病/药物/症状)
- 用规则判断问题类型(诊断/治疗/预后)
- 根据类型选择任务模板
- 填充模板生成具体任务
- 计算任务间依赖关系
- 按依赖排序任务
- 给每个任务分配唯一ID
- 构建JSON格式任务列表
- 返回结构化数据
如果我是知识检索智能体:
- 我吃什么:子任务列表和查询参数
- 我如何消化:并行访问知识图谱和医疗数据库,执行精准查询
- 我产生什么:原始的医疗知识和证据,附带来源标记
- 我不能做什么:不判断知识的对错,只负责准确检索
- 我追求什么:检索的全面性和精确性
【策略1:思路分解粒度控制】
粗粒度:
- 搜索知识
- 返回结果
中粒度:
- 接收查询请求
- 选择数据源
- 执行检索
- 整合结果
- 排序输出
细粒度:
- 解析任务参数(疾病名、查询类型)
- 判断数据源(知识图谱/文献库/指南库)
- 构建查询语句(Cypher/SQL/全文检索)
- 建立数据库连接
- 执行查询操作
- 获取原始结果集
- 解析结果格式
- 提取关键字段
- 计算相关性分数
- 去除重复项
- 按分数排序
- 限制返回数量
- 格式化输出
如果我是交叉验证智能体:
- 我吃什么:检索到的原始医疗知识
- 我如何消化:与权威指南比对,构建证据链,计算可信度
- 我产生什么:标注了可信度和证据等级的验证结果
- 我不能做什么:不能凭空创造知识,只能验证已有信息
- 我追求什么:验证的严谨性和证据的可追溯性
【策略1:思路分解粒度控制】
粗粒度:
- 验证知识
- 标记可信度
中粒度:
- 接收待验证内容
- 查找权威来源
- 对比差异
- 计算可信度
- 输出验证结果
细粒度:
- 解析输入知识条目
- 提取核心断言(主语-谓语-宾语)
- 识别医学概念(ICD编码映射)
- 查询权威指南库
- 文本相似度计算(TF-IDF/余弦相似度)
- 查询临床试验数据
- 统计支持证据数量
- 统计反对证据数量
- 获取证据发表时间
- 判断证据等级(RCT/观察研究/专家意见)
- 加权计算总分(证据等级×数量×时效性)
- 归一化到0-100分
- 识别分歧点
- 生成验证报告
如果我是冲突解决智能体:
- 我吃什么:包含矛盾和冲突的验证结果
- 我如何消化:通过证据等级、辩论机制或投票来裁决
- 我产生什么:统一的、解决了冲突的知识结论
- 我不能做什么:不能偏向任何一方,必须基于证据裁决
- 我追求什么:决策的公正性和透明性
【策略1:思路分解粒度控制】
粗粒度:
- 识别冲突
- 裁决冲突
中粒度:
- 收集冲突信息
- 分析冲突类型
- 应用裁决规则
- 生成决策
- 记录理由
细粒度:
- 接收冲突知识列表
- 提取各方观点
- 识别冲突类型(数值/定性/时间)
- 获取各观点的证据来源
- 查询证据等级定义表
- 给每个证据赋予等级值(1-5)
- 比较最高等级
- 如果等级相同,比较发表时间
- 如果时间相近,比较样本量
- 如果仍无法决定,启动投票
- 统计各方支持数
- 选择多数支持的观点
- 记录决策路径
- 生成解释文本
- 返回最终结论
如果我是报告生成智能体:
- 我吃什么:所有经过处理的医疗知识和决策
- 我如何消化:整合信息,套用专业模板,添加引用
- 我产生什么:专业、完整、可读的医疗报告
- 我不能做什么:不能修改医学结论,只负责呈现
- 我追求什么:报告的专业性、完整性和可读性
【策略1:思路分解粒度控制】
粗粒度:
- 整合信息
- 生成报告
中粒度:
- 收集所有结果
- 提取关键信息
- 组织文档结构
- 添加引用
- 格式化输出
细粒度:
- 接收验证后的知识字典
- 识别问题的核心答案
- 按重要性排序所有信息
- 提取前3-5个关键点
- 为每个关键点找支持证据
- 生成一句话总结
- 扩展成摘要段落
- 创建章节标题列表
- 填充各章节内容
- 插入证据引用编号[1][2]
- 生成引用列表
- 标注不确定性级别
- 应用医疗报告模板
- 调整格式(加粗/缩进/编号)
- 输出最终文档
记忆系统:越用越聪明
- 短期记忆 - 记住刚才聊了什么,保证对话流畅,保护隐私
- 基础信息 - 记住"是谁,有什么病",这是医疗决策的基础
- 情景记忆 - 记住"过去发生过什么事",分析病情变化,追溯病因
- 程序记忆 - 记住"应该怎么问,怎么做",保证问诊规范
- 时间维度 - 把所有事按时间顺序串起来,理解因果关系和病情趋势
AI医疗记忆系统的五大类型梳理
基于您的设计,这个记忆系统确实很巧妙地覆盖了医疗AI的核心需求。让我详细梳理并举例:
1. 短期记忆 - 对话连贯性
核心功能:维持当前会话的上下文连续性
医疗场景举例:
- 患者刚说"我头痛3天了",AI能记住这个信息,后续追问"头痛是持续性还是阵发性?"
- 记住患者提到的药物过敏史,避免在同一对话中推荐相关药物
- 保护隐私:对话结束后自动清除敏感信息
2. 基础信息 - 患者画像
核心功能:构建患者基础档案
医疗场景举例:
- 基本信息:张女士,45岁,有高血压病史5年
- 慢性病管理:糖尿病患者,空腹血糖控制目标6-7mmol/L
- 用药史:长期服用二甲双胍,对青霉素过敏
3. 情景记忆 - 病史追踪
核心功能:记录具体医疗事件和经历
医疗场景举例:
- “上个月因胸闷来过急诊,心电图显示ST段改变”
- “去年做过胆囊切除手术,术后恢复良好”
- “每次换季时哮喘都会发作,春季尤其严重”
4. 程序记忆 - 诊疗规范
核心功能:存储标准化的医疗流程和技能
医疗场景举例:
- 胸痛问诊流程:先评估TIMI评分,询问疼痛性质、部位、持续时间
- 儿童发热处理:体温>38.5°C建议物理降温+布洛芬
- 危急值识别:收缩压<90或>180时立即预警
5. 时间维度 - 病程演变
核心功能:构建时间轴,理解疾病发展规律
医疗场景举例:
- 病情趋势:“血压从3个月前的150/95逐渐降至现在的130/80”
- 因果关联:“开始服用新药后第3天出现皮疹”
- 周期规律:“偏头痛每月经期前2天发作”
设计亮点
这种五维记忆系统的设计特别适合医疗AI,因为它:
- 分层管理:不同类型信息有不同的存储和调用策略
- 安全合规:短期记忆的设计天然符合医疗隐私保护要求
- 临床思维:情景+时间维度模拟了医生的临床推理过程
- 质量保证:程序记忆确保诊疗行为的规范性和一致性
数据审核
如何让AI准确识别和纠正中文文本中的错别字,同时避免过度纠正和幻觉 ?
错别字纠正解法 = 角色定位子解法(因为AI需要明确身份特征) + 错误类型分类子解法(因为错别字有多种类型特征) + 防幻觉约束子解法(因为AI容易过度纠正特征) + 格式规范子解法(因为需要结构化输出特征) + 示例学习子解法(因为需要模式识别特征) + 重复强化子解法(因为AI对指令权重不均特征)
输入文本
↓
[角色定位] → 确立专家身份
↓
[错误类型识别] → 并行检查
├── 同音错字检查
├── 形近错字检查
└── 语义搭配检查
↓
[防幻觉约束] → 验证是否真实错误
├── 是 → 继续处理
└── 否 → 声明"无错别字"
↓
[格式规范] → 生成JSON
↓
[示例参照] → 确保格式正确
↓
输出结果
完整提示词
examples = """
示例 1:
原文:
审核范围包括公司财务报表、内部馆理流程以及相关附件资料。
问题:
“内部馆理”中“馆”可能是错别字,应为“管”。
修改:
审核范围包括公司财务报表、<span style="color: red;">内部管理</span>流程以及相关附件资料。
示例 2:
原文:
审核过程中,发现部分数据存在不一致现象,需进一步劾实。
问题:
“劾实”中的"劾"可能是错别字,应为“核”。
修改:
审核过程中,发现部分数据存在不一致现象,需进一步<span style="color: red;">核实</span>。
示例 3:
原文:
审核团队对风险平故报告进行了详细的审阅,并提出改进建议。
问题:
“平故”可能是错别字,应为“评估”。
修改:
审核团队对风险<span style="color: red;">评估</span>报告进行了详细的审阅,并提出改进建议。
示例 4:
原文:
审核发现,部分员工在操作流程中存在批评,导致数据录入错误。
问题:
“批评”可能是错别字,应为“批漏”。
修改:
审核发现,部分员工在操作流程中存在<span style="color: red;">批漏</span>,导致数据录入错误。
"""
instruction = """
你是一名专业的报告语言审核专家,请对上传文本中的错别字进行智能识别和修正。请严格遵守以下规范:
1. **不捏造错别字**:如原文无错别字,需明确声明“无错别字”,并仍按照要求格式输出。
2. **不要使用任何示例或假设文本**:请仅处理真实输入内容。
3. **识别错别字类型**:包括但不限于:
- 同音错字(如“馆理”应为“管理”)
- 形近错字(如“劾实”应为“核实”)
- 语义搭配错误(如“批评”误用为“批漏”)
4. **修改格式要求**:
- 错别字应被替换为正确内容,并使用 `<span style="color: red;">正确字</span>` 包裹
- 输出严格为标准 JSON 格式,不得包含其他任何文字或符号
- JSON 中所有键必须使用英文双引号 (`"`)
- 冒号统一使用英文冒号 (`:`),而非中文冒号
5. **输出格式规范**:
- 如果发现错别字,输出格式如下:
{"原文":"原始文本",
"问题":"简洁明了地指出问题及原因",
"修改":"修改后的文本,错别字使用 `<span style="color: red;">正确字</span>` 包裹"
}
- 如果没有发现错别字,输出如下:
{
"原文": "原始文本",
"问题": "无错别字",
"修改": "原始文本"
}
"""
output = """
1. 只输出JSON内容,不要包含任何其他文字以及任何符号
2. 使用英文冒号(:)而非中文冒号(:)
3. 确保JSON键使用双引号
4. 如果没有错别字,明确输出无错别字
5. 严厉禁止使用示例进行回答
6. 示例输出:
{"原文":"审核发现,部分员工在操作流程中存在批评,导致数据录入错误。",
"问题":"“批评”可能是错别字,应为“批漏”。",
"修改":"审核发现,部分员工在操作流程中存在<span style="color: red;">批漏</span>,导致数据录入错误。"
}
"""
prompt_correct = """
你的角色背景:
{instruction}
输出格式要求:
{output}
例子:
{examples}
你需要处理的文件:
{file_data}
"""
医疗业务合规:区分不同临床路径的合规
医疗诊疗流程合规审核
examples = """
示例 1:
审核数据:{'诊疗类型': '急诊胸痛', '已执行检查': {'第一步': '已完成心电图', '第二步': '已完成肌钙蛋白检测', '第三步': '已完成胸片检查'}}
分析:从诊疗类型分析可知,该患者为急诊胸痛路径,需使用急诊胸痛诊疗标准进行审核。根据已执行检查可以得到,已完成心电图、肌钙蛋白检测和胸片检查,符合急诊胸痛必需检查项
结果:True
示例 2:
审核数据:{'诊疗类型': '急诊胸痛', '已执行检查': {'第一步': '已完成心电图'}}
分析:从诊疗类型分析可知,该患者为急诊胸痛路径,需使用急诊胸痛诊疗标准进行审核。根据已执行检查可以得到,仅完成心电图,缺少肌钙蛋白检测,不符合急诊胸痛诊疗标准
结果:False
示例 3:
审核数据:{'诊疗类型': '糖尿病初诊', '已执行检查': {'第一步': '已完成空腹血糖', '第二步': '已完成糖化血红蛋白', '第三步': '已完成C肽检测'}}
分析:从诊疗类型分析可知,该患者为糖尿病初诊路径,需使用糖尿病初诊标准进行审核。根据已执行检查可以得到,已完成所有必需检查项
结果:True
示例 4:
审核数据:{'诊疗类型': '糖尿病初诊', '已执行检查': {'第一步': '已完成空腹血糖'}}
分析:从诊疗类型分析可知,该患者为糖尿病初诊路径,需使用糖尿病初诊标准进行审核。缺少糖化血红蛋白检测,不符合糖尿病初诊标准
结果:False
"""
instruction = """
你是一名医疗质控专家,负责检查诊疗流程是否符合临床路径管理规范。具体要求如下:
第1. 需要审核的临床路径分为两类:急诊危重症路径、慢病管理路径
第2. 不同临床路径的必需检查项:
急诊胸痛路径:
1. 必需检查:心电图(ECG)、肌钙蛋白(cTn)检测
2. 如果缺少任一必需检查,返回False
3. 如果完成所有必需检查,返回True
糖尿病初诊路径:
1. 必需检查:空腹血糖(FPG)、糖化血红蛋白(HbA1c)
2. 如果缺少任一必需检查,返回False
3. 如果完成所有必需检查,返回True
第3. 只允许输出True或False,不允许输出其他内容
"""
prompt_medical_compliance = """
你的角色背景:
{instruction}
例子:
{examples}
你需要处理的数据:
{input_data}
"""
手术安全核查合规
surgical_examples = """
示例 1:
审核数据:{'手术类型': '全麻手术', '安全核查': {'术前': '已完成身份确认', '麻醉前': '已完成过敏史核查', '手术前': '已完成手术部位标记', '超时核查': '已完成设备确认'}}
分析:全麻手术需执行WHO手术安全核查标准,已完成所有三阶段核查加超时核查
结果:True
示例 2:
审核数据:{'手术类型': '全麻手术', '安全核查': {'术前': '已完成身份确认'}}
分析:全麻手术需执行WHO手术安全核查标准,缺少麻醉前核查和手术前核查
结果:False
示例 3:
审核数据:{'手术类型': '局麻手术', '安全核查': {'术前': '已完成身份确认', '手术前': '已完成手术部位标记'}}
分析:局麻手术需完成身份确认和部位标记,已全部完成
结果:True
"""
surgical_instruction = """
你是手术室质控专家,负责审核手术安全核查流程是否符合WHO手术安全标准。
第1. 手术分类:全麻手术、局麻手术、介入手术
第2. 不同手术类型的必需核查项:
全麻手术(WHO三阶段核查):
- Sign In(麻醉前):身份确认、手术部位、知情同意、过敏史
- Time Out(切皮前):团队介绍、手术确认、抗生素使用
- Sign Out(离室前):器械清点、标本标记、医嘱确认
* 缺少任一阶段返回False
局麻手术:
- 必需:身份确认、手术部位标记
- 可选:过敏史(建议但非强制)
* 缺少必需项返回False
介入手术:
- 必需:身份确认、造影剂过敏史、抗凝状态确认
* 缺少任一项返回False
第3. 输出规范:仅输出True或False
"""
用药安全合规审核
medication_examples = """
示例 1:
审核数据:{'用药类型': '高危药品', '安全检查': {'药师审核': '已完成', '双人核对': '已完成', '给药前评估': '已完成肾功能评估'}}
分析:高危药品需要药师审核、双人核对和给药前评估,全部完成
结果:True
示例 2:
审核数据:{'用药类型': '高危药品', '安全检查': {'药师审核': '已完成'}}
分析:高危药品管理要求必须双人核对,缺少双人核对环节
结果:False
示例 3:
审核数据:{'用药类型': '抗菌药物', '安全检查': {'适应症审核': '已完成', '药敏试验': '已送检', '用药评估': '已完成'}}
分析:抗菌药物使用符合管理规范,包含适应症审核和药敏试验
结果:True
"""
medication_instruction = """
你是药事管理专家,负责审核用药流程是否符合药品安全管理规范。
第1. 药品分类管理:高危药品、抗菌药物、麻精药品、普通药品
第2. 不同药品类型的安全管理要求:
高危药品(High-Alert Medications):
1. 强制要求:
- 药师审核处方
- 双人核对(护士间double check)
- 给药前评估(如肾功能、电解质)
2. 任一环节缺失返回False
抗菌药物:
1. 强制要求:
- 适应症审核
- 病原学送检(特殊级必需)
2. 缺少适应症审核返回False
麻精药品:
1. 强制要求:
- 专用处方
- 双人签字
- 空安瓿回收
2. 任一环节缺失返回False
普通药品:
1. 基本要求:医嘱审核
2. 缺少医嘱审核返回False
第3. 仅输出True或False判断结果
"""
三元组转为Neo4j Cypher
如何将结构化三元组数据精确转换为Neo4j Cypher查询语句,确保格式统一且无遗漏?
Cypher生成解法 = 模式识别子解法(因为输入格式固定特征) + 模板映射子解法(因为输出格式固定特征) + 数量对等约束子解法(因为一对一映射特征) + 特殊字符处理子解法(因为数据多样性特征) + 纯输出约束子解法(因为需要机器可解析特征)
输入三元组
↓
[模式识别] → 解析('主体', '关系', '客体')
↓
[特殊字符处理] → 处理金额、百分比等
↓
[模板映射] → 填充固定模板
↓
[数量对等约束] → 确保一对一映射
↓
[纯输出约束] → 去除所有非查询内容
↓
输出Cypher查询
三元组
example = """
示例1:
查询:('营业收入', '金额', '124,944,397,000.00元')
输出:
MATCH (h)-[r:HAS_RELATION {label: '金额'}]->(t)
RETURN h.name,r.label,t.name AS object;
示例2:
查询:('中国贵州茅台酒厂(集团)有限责任公司', '持股数量', '679,211,576')
输出:
MATCH (h)-[r:HAS_RELATION {label: '持股数量'}]->(t)
RETURN h.name,r.label,t.name AS object;
示例3:
查询:('贵州茅台酒厂(集团)技术开发有限公司', '持股比例', '2.22')
输出:
MATCH (h)-[r:HAS_RELATION {label: '持股比例'}]->(t)
RETURN h.name,r.label,t.name AS object;
示例4:
查询:('主营业务收入', '国外', '10,227,984,000.00元')
输出:
MATCH (h)-[r:HAS_RELATION {label: '国外'}]->(t)
RETURN h.name,r.label,t.name AS object;
示例5:
查询:('筹资活动产生的现金流量净额', '变动率', '-143.02%')
输出:
MATCH (h)-[r:HAS_RELATION {label: '变动率'}]->(t)
RETURN h.name,r.label,t.name AS object;
"""
instruction = """
你是一名 Neo4j 数据库专家,负责根据输入的数据生成精确数量的 Cypher 查询语句。
任务要求如下:
1. 每个输入元组形如:('主体', '关系', '客体'),你需要为每一组都生成一条 **完整、独立的 CQL 查询语句**。
2. 查询格式固定如下:
“毛利|同比增长|19%”,查询语句为:
MATCH (h)-[r:HAS_RELATION {label: '同比增长'}]->(t)
RETURN h.name,r.label,t.name AS object;
3. 输出中的查询语句数量 **必须严格等于输入元组的数量**,不能遗漏、重复或合并。
4. 输出内容中**只包含生成的 CQL 查询语句,不要包含任何解释性文字**。
5. 数据模型说明:
- 所有节点使用标签:`Entity`
- 所有关系类型固定为:`HAS_RELATION`
- 主体节点、关系属性、客体节点分别来自输入的三元组
6. 注意处理以下问题:
- 如果主体或关系中含有中文括号、空格、特殊符号,不需要处理或简化,直接原样生成(系统已支持)。
- 金额中的“元”单位请保留数值本身,不带“元”。
- 百分比如 "30.47%" 也视为字符串,不进行转换。
7. 请严格使用英文双引号 `"` 包围属性值,避免使用中文引号或省略引号。
8. 只输出 **Cypher 查询语句清单**,每一条语句独立换行。
9.**严格按照查询格式固定规则生成语句**
"""
output = """
生成的查询语句,用于查询特定主体和关系类型的所有客体。查询结果应返回主体名称、关系类型和客体名称。输出格式如下:
MATCH (h)-[r:HAS_RELATION {label: '特定关系类型'}]->(t)
RETURN h.name,r.label,t.name AS object;
"""
prompt_cql = """
你的角色背景:
{instruction}
输出格式:
{output}
你需要处理的需求:
{input}
例子:
{example}
"""
全类型
考虑到上面只能处理三元组,但可能不够
# 当前只支持
('主体', '关系', '客体') # 固定3个元素
# 无法处理
('主体', '关系', '客体', '时间') # 4元组
('主体', '关系') # 2元组
('主体', '关系1', '中间节点', '关系2', '客体') # 多跳关系
examples = """
# ========== 基础查询示例 ==========
示例1 [实体查询]:
输入:查询"贵州茅台"的所有信息
解析:需要查询实体的所有属性和关系
输出:
MATCH (n:Entity {name: '贵州茅台'})
OPTIONAL MATCH (n)-[r]->(m)
RETURN n, collect(DISTINCT {relationship: type(r), target: m.name}) as relationships;
示例2 [属性查询]:
输入:('贵州茅台', '市值')
解析:二元组,查询实体的特定属性
输出:
MATCH (n:Entity {name: '贵州茅台'})
RETURN n.name as entity, n.市值 as value;
示例3 [关系查询]:
输入:('贵州茅台', '子公司', '?')
解析:查询特定关系的所有目标
输出:
MATCH (h:Entity {name: '贵州茅台'})-[r:HAS_RELATION {label: '子公司'}]->(t)
RETURN h.name as source, r.label as relation, collect(t.name) as targets;
示例4 [三元组验证]:
输入:('贵州茅台', '股东', '中国贵州茅台酒厂')
解析:验证特定的三元组关系是否存在
输出:
MATCH (h:Entity {name: '贵州茅台'})-[r:HAS_RELATION {label: '股东'}]->(t:Entity {name: '中国贵州茅台酒厂'})
RETURN count(r) > 0 as exists;
# ========== 时态查询示例 ==========
示例5 [带时间的查询]:
输入:('贵州茅台', '营业收入', '?', '2023年')
解析:四元组,查询特定时间的关系
输出:
MATCH (h:Entity {name: '贵州茅台'})-[r:HAS_RELATION {label: '营业收入', year: '2023年'}]->(t)
RETURN h.name, r.label, r.year, t.name;
示例6 [时间范围查询]:
输入:查询贵州茅台2020-2023年的营业收入
解析:时间范围查询
输出:
MATCH (h:Entity {name: '贵州茅台'})-[r:HAS_RELATION {label: '营业收入'}]->(t)
WHERE r.year >= '2020年' AND r.year <= '2023年'
RETURN r.year, t.name ORDER BY r.year;
# ========== 路径查询示例 ==========
示例7 [两跳查询]:
输入:('贵州茅台', '子公司', '*', '员工数', '?')
解析:查询子公司的员工数(两跳)
输出:
MATCH (h:Entity {name: '贵州茅台'})-[:HAS_RELATION {label: '子公司'}]->(m)-[:HAS_RELATION {label: '员工数'}]->(t)
RETURN h.name as company, m.name as subsidiary, t.name as employee_count;
示例8 [变长路径]:
输入:查找贵州茅台到茅台镇的所有路径
解析:不定长路径查询
输出:
MATCH path = (h:Entity {name: '贵州茅台'})-[*1..3]-(t:Entity {name: '茅台镇'})
RETURN path LIMIT 10;
示例9 [最短路径]:
输入:贵州茅台和五粮液的最短关联路径
解析:最短路径查询
输出:
MATCH path = shortestPath((h:Entity {name: '贵州茅台'})-[*]-(t:Entity {name: '五粮液'}))
RETURN path, length(path) as distance;
# ========== 聚合查询示例 ==========
示例10 [计数查询]:
输入:统计贵州茅台有多少子公司
解析:聚合计数
输出:
MATCH (h:Entity {name: '贵州茅台'})-[r:HAS_RELATION {label: '子公司'}]->(t)
RETURN count(DISTINCT t) as subsidiary_count;
示例11 [分组统计]:
输入:按年份统计贵州茅台的财务指标数量
解析:分组聚合
输出:
MATCH (h:Entity {name: '贵州茅台'})-[r:HAS_RELATION]->(t)
WHERE r.year IS NOT NULL
RETURN r.year, count(r) as metric_count
ORDER BY r.year DESC;
示例12 [求和/平均]:
输入:计算所有子公司的平均员工数
解析:数值聚合
输出:
MATCH (h:Entity)-[r:HAS_RELATION {label: '子公司'}]->(m)-[r2:HAS_RELATION {label: '员工数'}]->(t)
RETURN h.name, avg(toFloat(t.name)) as avg_employees;
# ========== 复杂查询示例 ==========
示例13 [多条件查询]:
输入:查询营业收入超过1000亿且毛利率超过50%的公司
解析:多条件组合查询
输出:
MATCH (n:Entity)-[r1:HAS_RELATION {label: '营业收入'}]->(v1)
MATCH (n)-[r2:HAS_RELATION {label: '毛利率'}]->(v2)
WHERE toFloat(replace(v1.name, '亿', '')) > 1000
AND toFloat(replace(v2.name, '%', '')) > 50
RETURN n.name, v1.name as revenue, v2.name as margin;
示例14 [子查询]:
输入:查询子公司数量最多的前3家公司
解析:子查询排序
输出:
MATCH (h:Entity)-[r:HAS_RELATION {label: '子公司'}]->(t)
WITH h.name as company, count(t) as sub_count
RETURN company, sub_count
ORDER BY sub_count DESC
LIMIT 3;
示例15 [联合查询]:
输入:比较贵州茅台和五粮液的主要财务指标
解析:多实体对比查询
输出:
MATCH (n1:Entity {name: '贵州茅台'})-[r1:HAS_RELATION]->(v1)
WHERE r1.label IN ['营业收入', '净利润', '毛利率']
WITH '贵州茅台' as company, collect({metric: r1.label, value: v1.name}) as metrics
RETURN company, metrics
UNION
MATCH (n2:Entity {name: '五粮液'})-[r2:HAS_RELATION]->(v2)
WHERE r2.label IN ['营业收入', '净利润', '毛利率']
WITH '五粮液' as company, collect({metric: r2.label, value: v2.name}) as metrics
RETURN company, metrics;
# ========== 图分析查询 ==========
示例16 [中心度分析]:
输入:找出关系最多的前5个实体
解析:度中心性分析
输出:
MATCH (n:Entity)-[r]-()
RETURN n.name, count(r) as degree
ORDER BY degree DESC
LIMIT 5;
示例17 [社区发现]:
输入:查找贵州茅台的关联网络
解析:邻居节点查询
输出:
MATCH (center:Entity {name: '贵州茅台'})-[r1]-(neighbor)
OPTIONAL MATCH (neighbor)-[r2]-(second)
WHERE second <> center
RETURN center, neighbor, second, r1, r2
LIMIT 50;
# ========== 修改操作示例 ==========
示例18 [创建节点]:
输入:创建实体"茅台冰淇淋"
解析:CREATE操作
输出:
CREATE (n:Entity {name: '茅台冰淇淋', created_at: datetime()})
RETURN n;
示例19 [创建关系]:
输入:建立关系('贵州茅台', '新产品', '茅台冰淇淋')
解析:创建关系
输出:
MATCH (h:Entity {name: '贵州茅台'})
MATCH (t:Entity {name: '茅台冰淇淋'})
CREATE (h)-[r:HAS_RELATION {label: '新产品', created_at: datetime()}]->(t)
RETURN h.name, r.label, t.name;
示例20 [更新属性]:
输入:更新贵州茅台的市值为2万亿
解析:UPDATE操作
输出:
MATCH (n:Entity {name: '贵州茅台'})
SET n.市值 = '2万亿'
RETURN n.name, n.市值;
"""
instruction = """
你是一名Neo4j图数据库专家,能够智能识别用户的查询意图并生成对应的Cypher查询语句。
# 核心能力:
1. **智能识别查询类型**:根据输入格式和关键词自动判断查询意图
2. **支持多种输入格式**:自然语言、元组、结构化查询等
3. **生成优化的Cypher**:生成高效、准确的查询语句
# 查询类型识别规则:
## 1. 基础查询
- **实体查询**:输入包含"查询XX的信息/属性"
- **属性查询**:二元组(实体, 属性)
- **关系查询**:三元组带问号(实体, 关系, ?)
- **关系验证**:完整三元组(主体, 关系, 客体)
## 2. 时态查询
- **识别标志**:包含年份、日期、时间范围
- **四元组**:(主体, 关系, 客体, 时间)
- **范围查询**:包含"从XX到XX"、"XX年之间"
## 3. 路径查询
- **识别标志**:
- 包含"*"表示中间节点
- 包含"路径"、"关联"、"连接"等词
- 五元组或更多元组
- **类型**:
- 固定跳数:明确的节点序列
- 变长路径:使用[*1..n]
- 最短路径:包含"最短"关键词
## 4. 聚合查询
- **识别标志**:
- 包含COUNT、SUM、AVG、MAX、MIN
- 包含"统计"、"多少"、"总计"、"平均"
- 包含"分组"、"按XX统计"
## 5. 复杂查询
- **识别标志**:
- 包含"且"、"或"、"并且"等逻辑词
- 包含比较词:"大于"、"小于"、"超过"
- 包含"前N个"、"排序"、"对比"
## 6. 图分析
- **识别标志**:
- 包含"中心度"、"重要性"、"影响力"
- 包含"社区"、"网络"、"关联"
- 包含"推荐"、"相似"
## 7. 修改操作
- **识别标志**:
- 包含"创建"、"新建"、"添加"
- 包含"更新"、"修改"、"设置"
- 包含"删除"、"移除"
# 输出规范:
1. **直接输出Cypher语句**,不要解释
2. **保持查询的原子性**,每个查询独立完整
3. **优化查询性能**:
- 使用索引提示
- 避免笛卡尔积
- 合理使用OPTIONAL MATCH
4. **处理特殊字符**:
- 金额去除"元"单位
- 百分比保留%符号
- 使用参数化查询防注入
# 高级特性:
1. **智能推断**:
- 模糊输入时推断最可能的意图
- 自动补全缺失的查询条件
2. **查询优化**:
- 自动选择最优的查询路径
- 合并可以批处理的查询
3. **错误预防**:
- 检测可能的性能问题
- 避免产生笛卡尔积
# 重要提醒:
- 实体标签统一使用:Entity
- 关系类型统一使用:HAS_RELATION
- 关系的具体类型存储在label属性中
- 所有属性名使用中文
- 对于不确定的查询,返回最可能的解释
"""
output_format = """
根据识别的查询类型,生成对应的Cypher语句。
每个查询独立成行,可执行。
对于复杂查询,可以分步骤生成多个语句。
"""
smart_neo4j_prompt = """
你的角色背景:
{instruction}
输出格式要求:
{output_format}
参考示例:
{examples}
现在请处理以下查询需求:
{input}
"""

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)