看不见的伪造痕迹:AI时代的鉴伪攻防战
从技术生态和模型演进的角度来看,为了应对不断出现的新型伪造方法,现有检测系统通常会部署持续的增量学习机制(Incremental Learning),不断吸纳新样本进行在线训练与模型更新。这种动态调整的机制使得模型能更快速地适应攻击方法的变种,避免因技术滞后造成的安全漏洞。上述这些技术方法的组合形成了一套完整的视频鉴伪管道,具备较高的泛化能力和实时检测能力,能够有效应对实际业务场景中大规模深度伪造
- 高层时序异常特征的捕捉与分析 视频与静态图像的本质区别在于时序信息。真实的人脸视频中,面部动作与表情演变存在内在的连续性与一致性。而深度伪造的视频往往通过逐帧生成或修正,从而在连续帧之间出现潜在的动态不一致,如眼球运动、面部微表情或嘴唇动作的不自然性。 技术层面上,检测模型通常通过 3D CNN 或 Transformer 等结构,对视频序列中的时序特征进行编码和建模,进而捕获连续帧之间的异常变化。这种方法能够补充单帧视觉分析的不足,显著提升对高质量伪造视频的识别能力。同时,为满足实际业务中毫秒级实时检测的需求,还会采用模型蒸馏、量化压缩或轻量级网络设计等策略,以减少检测延迟并提高性能表现。

从技术生态和模型演进的角度来看,为了应对不断出现的新型伪造方法,现有检测系统通常会部署持续的增量学习机制(Incremental Learning),不断吸纳新样本进行在线训练与模型更新。这种动态调整的机制使得模型能更快速地适应攻击方法的变种,避免因技术滞后造成的安全漏洞。
上述这些技术方法的组合形成了一套完整的视频鉴伪管道,具备较高的泛化能力和实时检测能力,能够有效应对实际业务场景中大规模深度伪造视频的威胁。
二、AIGC 图像鉴别:假画无处遁形
日常文档(如身份证、发票、合同)的篡改虽然技术门槛不高,但因涉及个人隐私、财务安全,技术难度反而较大。为解决这一问题,TextIn平台基于深度神经网络和模块化的系统架构,实现了针对文档篡改的高效准确检测。
多模态语义分析
大语言模型的快速发展使得视觉语义推理技术变得更加成熟。技术人员可以通过构建一系列提示指令(prompt),来指导模型对生成图像的逻辑合理性进行分析。例如,模型通过分析图像中的透视关系、光影的一致性,以及场景语义的逻辑性,评估画面的真实性。这种方式弥补了传统图像检测中语义分析缺乏的问题,使得模型能从语义层面检测伪造痕迹。
频域高低频特征融合
除语义分析外,频域分析也在图像鉴别技术中发挥了重要作用。生成图像往往在高频域会留下不自然的伪造痕迹,如重复的细节、特定的伪影和噪声。合合信息技术团队通过傅里叶变换等频域方法,将图像转换到频谱空间,重点分析高低频谱的幅值谱和相位谱,并结合空间域的视觉特征进行多维融合判断。这种方法在图像被压缩、裁剪或上传至网络平台后仍能有效检测出伪造痕迹,增强了模型的鲁棒性。
三、TextIn 通用篡改检测平台:技术架构与应用逻辑
日常文档(如身份证、发票、合同)的篡改虽然技术门槛不高,但因涉及个人隐私、财务安全,技术难度反而较大。为解决这一问题,TextIn平台基于深度神经网络和模块化的系统架构,实现了针对文档篡改的高效准确检测。

模块化检测架构
TextIn平台采用模块化技术架构,将整个检测过程分为快速粗检和精细像素级检测两个阶段。粗检阶段使用轻量化网络快速筛选出存在篡改嫌疑的文档;精细检测阶段则对疑似文档区域进行像素级分析,准确定位具体的篡改区域。
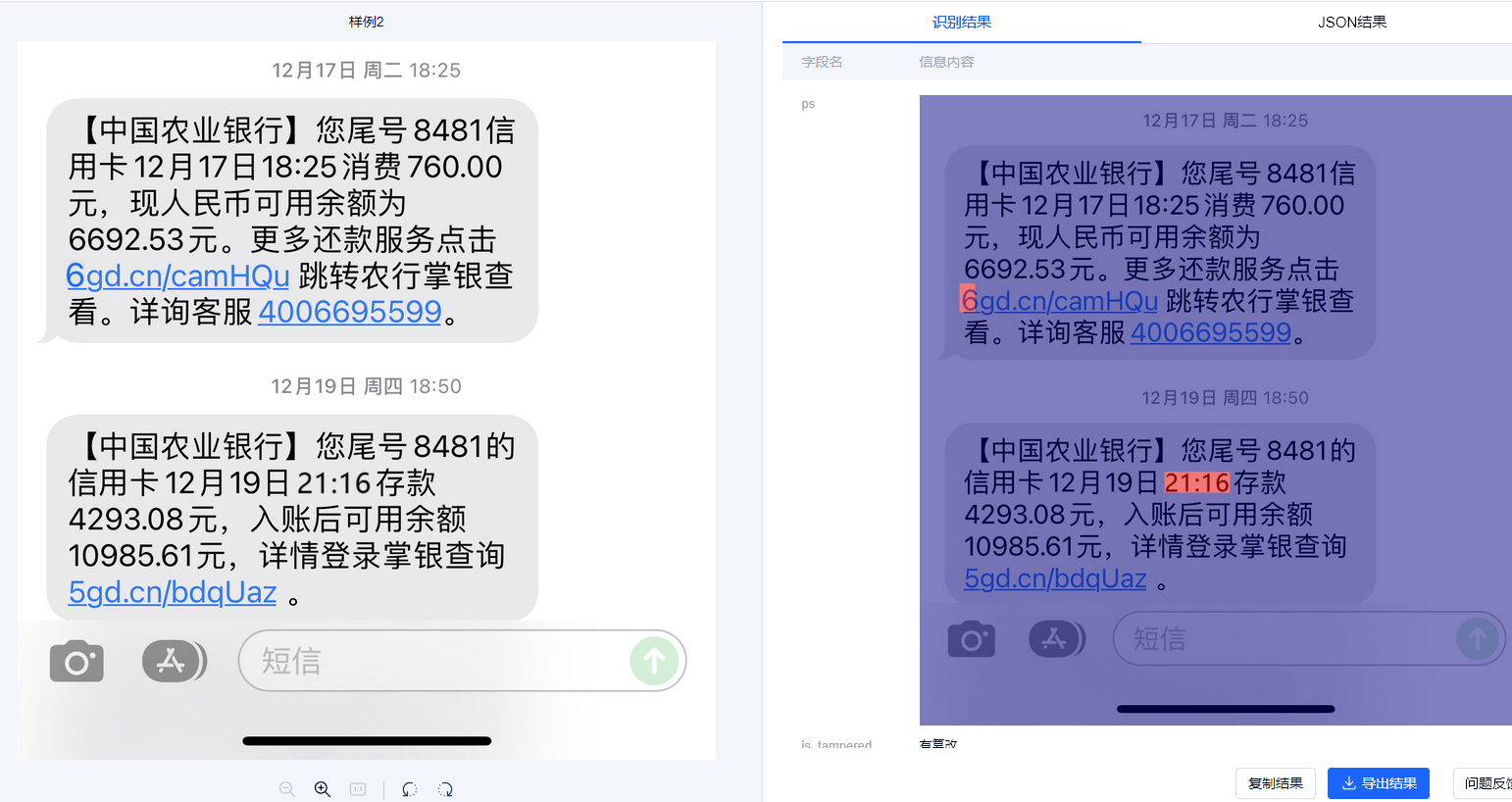
动态阈值调节技术
考虑到实际业务场景对误检率和召回率的不同需求,技术团队引入了动态阈值调整机制。开发人员可以根据不同业务需求灵活调整检测灵敏度,从而精确控制检测结果在敏感度与准确性之间的平衡,显著降低了误检率,满足多种业务场景的实际需求。

多模态交叉验证
单纯视觉信息往往难以独立支撑高度可靠的篡改鉴定。因此,技术团队通过结合OCR字符识别技术与业务规则校验实现跨模态的交叉验证。以发票检测为例,通过OCR识别出关键信息如发票号码,再与官方税务平台或第三方数据源进行交叉核验,这种融合视觉与语义的多模态鉴别技术进一步提高了鉴伪结果的可靠性。
上述这些技术实现手段,共同构成了一个完整的、适用于多种应用场景的通用文档篡改检测平台。
更值得一提的是,这个平台并不只是一个“演示工具”,而是经受住了实际业务的考验。比如某大型银行在贷款审核系统中接入了该模型,成功识别出伪造票据并帮助客户减少了 80% 的潜在风险。在银行票据审核、保险理赔材料验证、证券资质文件校验等场景中,文档量大、版式复杂,TextIn 依靠百万级数据训练可以在毫秒内完成一次鉴定,误检率低至千分之一。正因为实战表现出色,它已经在金融、零售、互联网等多行业落地,成为企业提升内容真实性的基础设施。
四、技术实力与行业标准

技术的发展离不开持续的实践和行业共识。在过去几年,图像篡改检测领域涌现了众多技术挑战赛,这些竞赛为各个供了公平而严格的环境,以验证和提升自身算法的有效性。合合信息在多次技术比赛中表现优异,通过参与这些赛事,不仅检验了团队的技术能力,也积累了丰富的实践经验。技术团队提
例如,在 2022 年的真实场景篡改图像检测挑战赛中,合合信息团队依靠稳健的模型设计和深度学习技术,成功处理了复杂的真实场景数据;2023 年,在 ICDAR DTT 竞赛中,他们以较低的误检率和较高的召回率取得佳绩;同年,在 AFAC 金融数据验真赛上,通过严谨的模型结构设计和训练策略有效地处理了金融场景中的文档篡改问题;2024 年,团队在全球 AI 攻防挑战赛中展现了出色的泛化能力和抗攻击性。
除赛事之外,合合信息也在推动技术规范化方面做出了贡献。2024 年 9 月,他们联合中国信通院以及多家高校、研究机构共同起草了《文本图像篡改检测系统技术要求》,明确了行业的技术标准和规范。标准中包含了检测数据集的构建原则、模型训练的技术细节、结果评估方法等具体内容。这一标准的建立为后续行业内技术交流、模型比对和成果验证提供了清晰统一的依据。
五、前景与挑战:AI安全赛道上的长跑者
回顾此次 WAIC 的展示,我们看到合合信息从单点检测走向全场景的视觉安全体系:人脸视频检测应对深度伪造袭击,AIGC 图像鉴别解决生成式图像泛滥,TextIn 通用篡改检测平台守护日常文档安全。它们既是产品,也是多模态大模型时代的安全底座。
然而挑战并未结束。随着生成式 AI 大模型不断进化,伪造内容的复杂度和多样性会持续提升,算法必须保持持续迭代才能应对新的攻击。尤其是在实时视频、长音频和全息场景中,如何在保证准确率的同时做到超低延迟,依然考验着技术实力。另外,视觉内容安全不仅是技术问题,还涉及隐私保护和伦理规范,未来如何在保护安全的同时尊重用户隐私,需要产业界和监管层共同探索。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)