DeepSeek实战--RAG
RAG(检索增强生成)是一种结合信息检索系统与大语言模型的技术框架,通过外部知识库检索相关上下文,提升模型回答的准确性和可靠性。其核心流程包括数据加载、文本分割、向量化、构建向量数据库,以及查询转换、语义检索、上下文构建和答案生成。文中还演示了如何使用Qdrant向量数据库和DeepSeek模型搭建RAG系统,并指出该技术可有效规避大模型幻觉问题,但不同模型在专业任务上表现各异。
1. 什么是RAG?
1.1 简介
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索(IR) 系统与大语言模型(LLM) 相结合的技术框架。它的核心思想是在LLM生成答案之前,先从外部知识库中检索出相关的信息片段,然后将这些片段作为上下文(Context)与用户问题(Query)一并提供给LLM,最终让LLM基于这些可靠的上下文生成更准确、更可靠的答案。
你可以把它想象成一个开了外挂的学霸:
- 传统LLM:一个只能凭记忆答题的“闭卷考生”,记错了或没记过就会答错。
- RAG:一个可以随时开卷查阅参考资料(从知识库检索)的考生,他综合查阅到的资料和自己的理解(LLM的生成能力),写出答案,其准确性和可靠性大大提升。
1.2 核心流程
-
阶段一:检索(Retrieval)
-
数据加载:收集并加载各种格式的文档(PDF、Word、HTML、数据库等)作为外部知识源。
-
文本分割(Chunking):将长文档切分成更小的、语义完整的文本片段(Chunks)。这是因为LLM有上下文长度限制,且小片段更利于精确检索。
-
向量化(Embedding):使用文本嵌入模型(Embedding Model)(如text-embedding-ada-002、BGE、M3E等)将每个文本块转换为一个高维向量(Vector)。这个向量可以理解为该文本片段的数学表示,语义相似的文本其向量在空间中的距离也更近。
-
构建向量数据库(Vector Database):将所有这些向量及其对应的原始文本存储到专门的向量数据库(如Chroma、Milvus、Pinecone、Weaviate等)中。
-
-
阶段二:检索(Retrieval)
-
查询转换:当用户提出一个问题(Query)时,系统使用同样的嵌入模型将这个问题也转换为一个查询向量。
-
语义检索:在向量数据库中执行相似性搜索(Similarity Search),寻找与查询向量最相似的K个文本片段向量(即最相关的内容)。
-
上下文构建:将这些检索到的Top K文本片段组合起来,与用户的原始问题一起,构建成一个精心设计的提示(Prompt)模板。
-
答案生成:将这个填充好的Prompt发送给LLM(如GPT-4、ChatGLM、Llama等)。LLM的指令通常是:“请仅根据提供的上下文内容来回答以下问题:…”。最终,LLM生成一个基于可靠上下文的、高质量的答案。
-
流程图如下:

-
2.实操
Step1:首先安装向量数据库
docker 命令,安装qdrant向量库:
docker run -d --name qdrant -p 6333:6333 -v /root/qdrant_data:/qdrant/storage docker.1ms.run/qdrant/qdrant:latest
下载、并运行成功: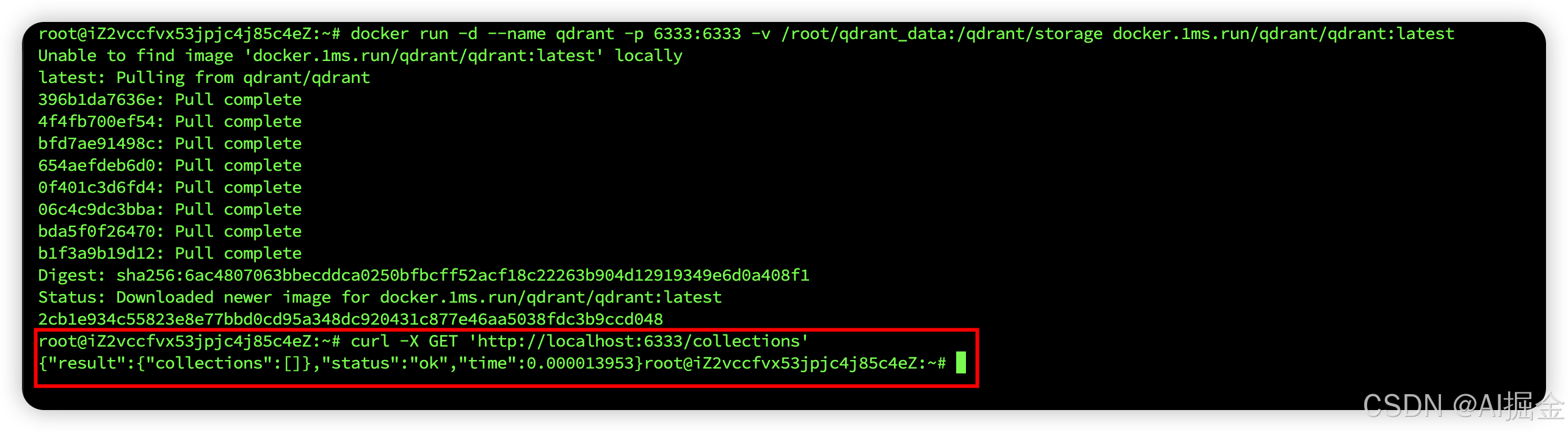
可以用你的公网地址访问控制台:
http://<你的公网 IP>:6333/dashboard
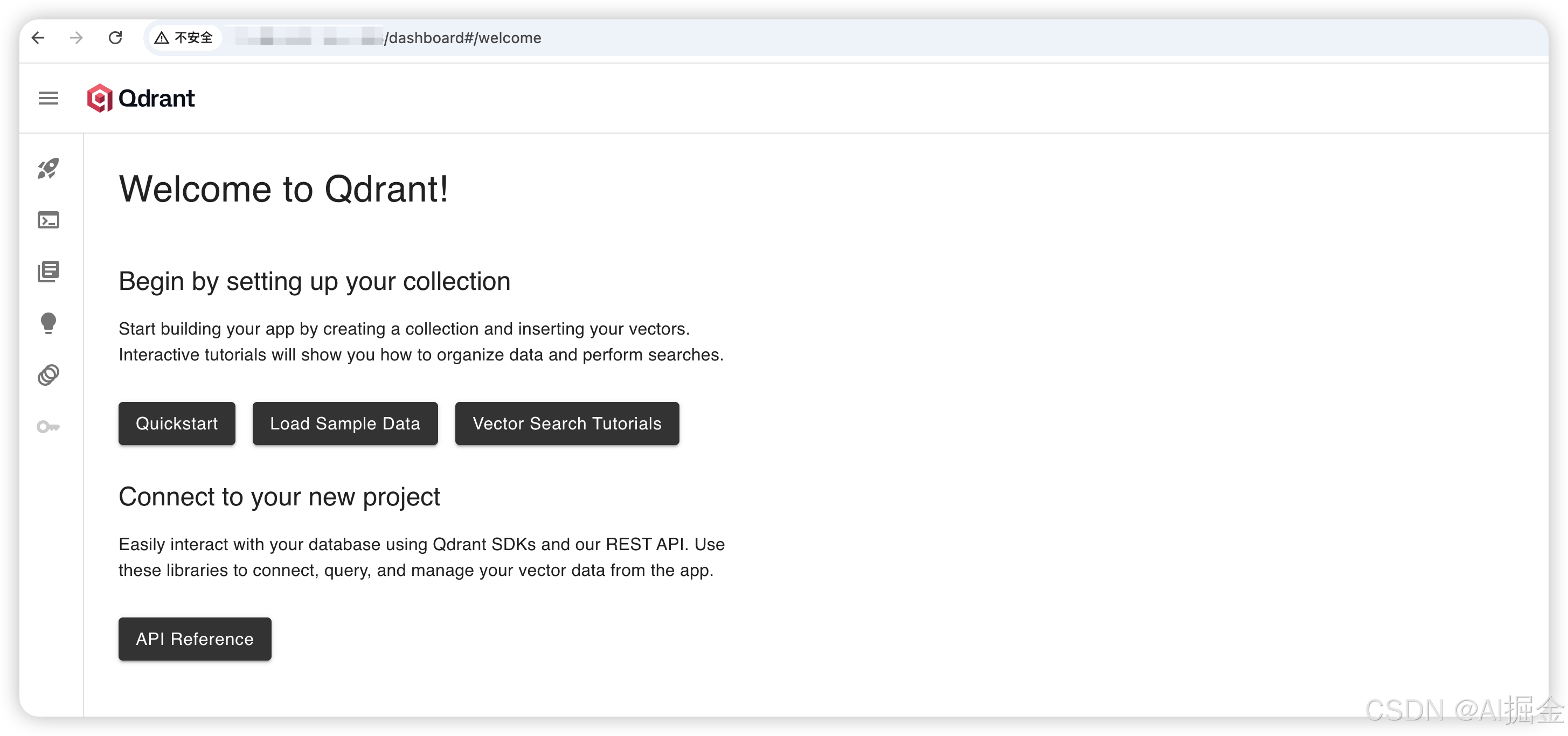
1)在向量数据库中有一个重要的概念叫 Collections,这个可以理解为是普通数据库中的数据表
2)记得,在你服务器防火墙中,将6333端口放开
Step2:设置Qdrant API key
# 停止并删除已存在的名为 qdrant 的容器(如果不再需要)
docker stop qdrant
docker rm qdrant
# 使用修正后的命令重新运行 Qdrant 容器
docker run -d --name qdrant -p 6333:6333 -e QDRANT_API_KEY=your_key -v /root/qdrant_data:/qdrant/storage docker.1ms.run/qdrant/qdrant:latest
Step3:验证Qdrant API key
curl -H "api-key: your_key” http://host:6333/collections
Step4: 在向量库创建collection并结合大模型读写数据
import os
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
import numpy as np
from dotenv import load_dotenv
# 1.加载环境变量
load_dotenv()
# 2.初始化Qdrant客户端
qdrant_client = QdrantClient(
url=os.getenv("QDRANT_HOST") , # 替换为您的Qdrant实例URL
api_key=os.getenv("QDRANT_API_KEY") # 替换为您的Qdrant API密钥
)
# 3.初始化DeepSeek客户端
deepseek_client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"), # 替换为您的DeepSeek API密钥
base_url="https://api.deepseek.com"
)
# 4.创建集合collection
collection_name = "location_collection"
try:
qdrant_client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=128, distance=Distance.COSINE)
)
except Exception as e:
print(f"集合可能已存在: {e}")
# 5.简单的文本转向量函数(模拟)
def text_to_vector(text):
# 在实际应用中,应使用真实的嵌入模型
# 这里使用随机向量作为演示
np.random.seed(hash(text) % (2 ** 32 - 1))
return np.random.rand(128).tolist()
# 6.插入数据
location_text = "中国.成都.北京区.yy湖"
vector = text_to_vector(location_text)
qdrant_client.upsert(
collection_name=collection_name,
points=[PointStruct(
id=1,
vector=vector,
payload={"text": location_text}
)]
)
# 查询函数
def query_rag(user_question):
# 将问题转换为向量
question_vector = text_to_vector(user_question)
# 在Qdrant中搜索相似向量
search_result = qdrant_client.search(
collection_name=collection_name,
query_vector=question_vector,
limit=1
)
# 获取最相关的上下文
context = ""
if search_result:
context = search_result[0].payload.get("text", "")
# 构造提示词
prompt = f"""
根据以下上下文回答问题:
上下文:{context}
问题:{user_question}
回答:
"""
# 使用DeepSeek生成回答
response = deepseek_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": prompt}
],
stream=False
)
return response.choices[0].message.content
# 示例使用
if __name__ == "__main__":
question = "yy湖属于哪个区?"
answer = query_rag(question)
print(f"问题:{question}")
print(f"回答:{answer}")
Step5:检阅结果
1)Qdrant 写入的collection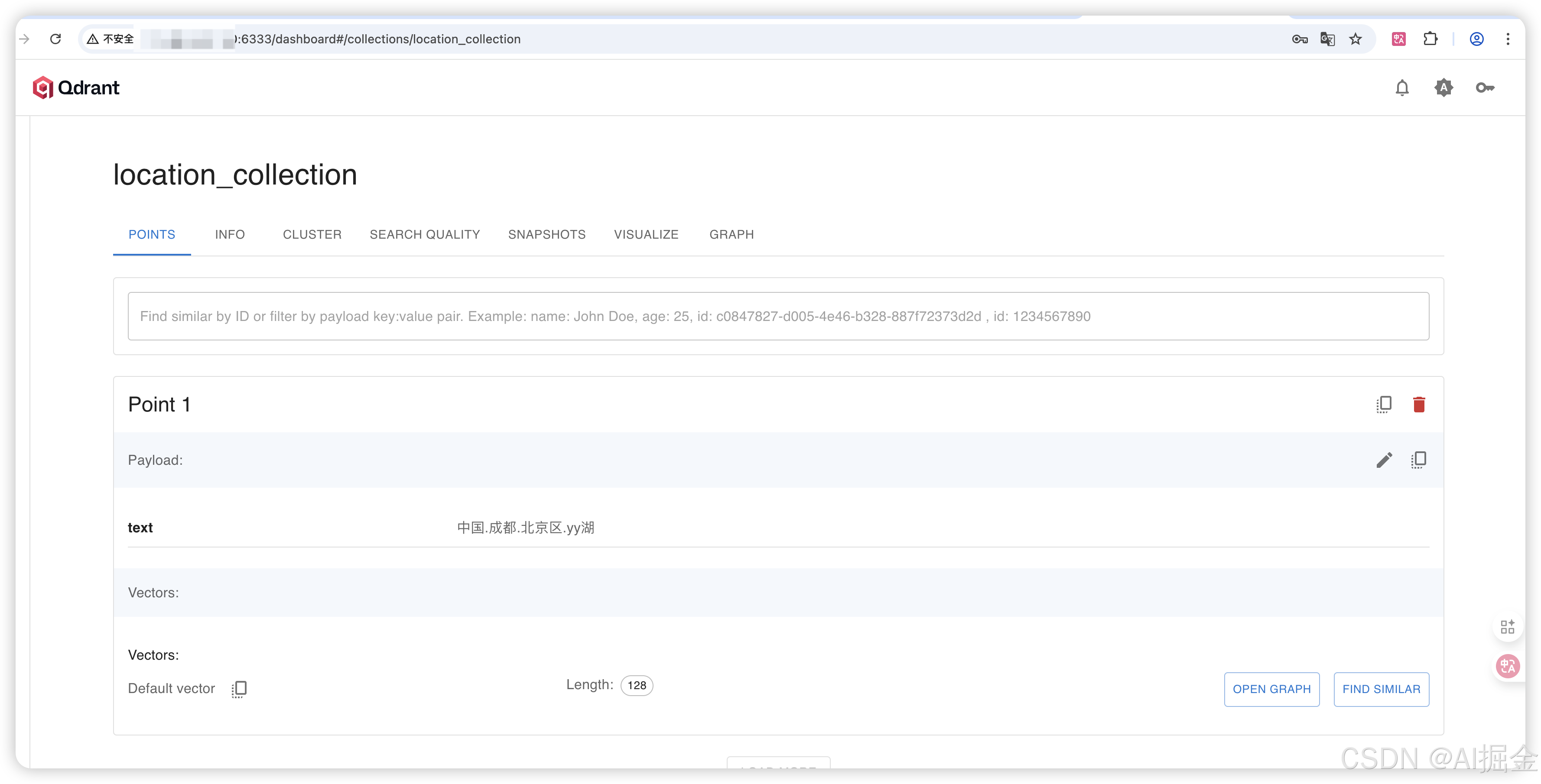
2)RAG执行结果
3.总结
1)演示中可以看到,DeepSeek是按Qdrank 召回的内容,作为context 回答的后续问题,即使Qdrank的内容是错的,大模型没有主动的纠正,这个特点正好规避了大模型幻觉问题。
2) 本次对比了DeepSeek 与 Lingma 生成demo代码的效果,DeepSeek 生成的代码,无法运行,最后还是得靠lingma生成的代码。充分说明,术业有专攻,大模型不是万能的,专业的事情,专业的模型做有更好的效果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)