每天10分钟轻松掌握MCP 40天学习计划的第 6 天 :JSON-RPC通信协议在MCP中的应用机制(二)
每天10分钟轻松掌握MCP 40天学习计划的第 6 天 :JSON-RPC通信协议在MCP中的应用机制(二):如果文章对你有帮助,还请给个三连好评,感谢感谢!
·
每天10分钟轻松掌握MCP 40天学习计划的第6天
JSON-RPC通信协议在MCP中的应用机制(二)
🚀 第二部分:高级特性与实践应用
上一部分我们搞定了JSON-RPC的基础知识,就像学会了说"你好"和"谢谢"。现在我们要学习如何"能说会道",处理复杂的并发场景、流式数据,甚至让不同语言的程序都能愉快地交流!
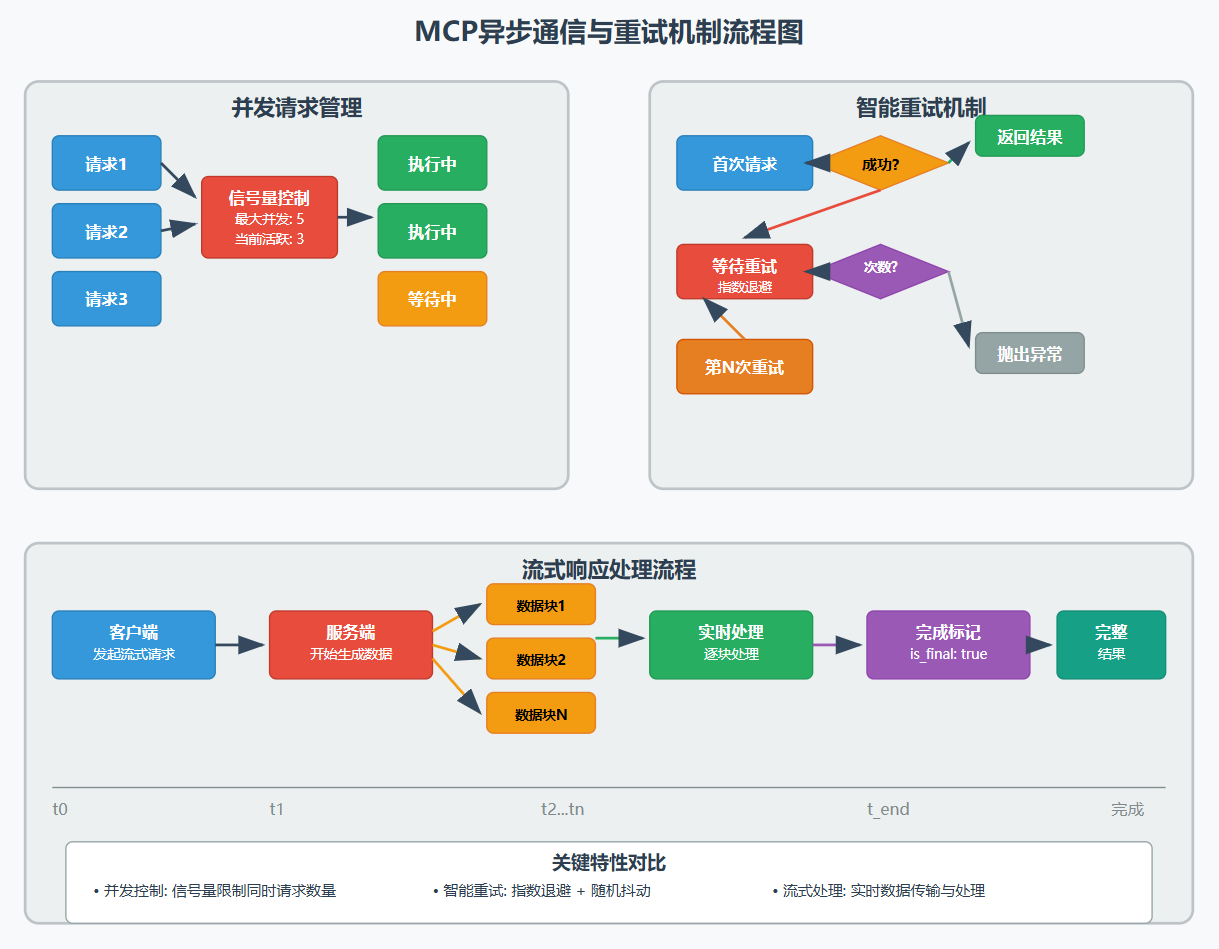
1. 异步通信处理机制
1.1 并发请求管理策略
在现实场景中,客户端可能需要同时发送多个请求,就像你在餐厅同时点了汤、主菜和甜品一样。
| 管理策略 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 队列模式 | 顺序执行 | 简单,不会冲突 | 效率低,串行等待 |
| 并发模式 | 独立任务 | 效率高,并行处理 | 复杂度高,需要同步 |
| 混合模式 | 复杂业务 | 灵活可控 | 实现复杂 |
1.2 并发请求管理实现
import asyncio
import time
from typing import Dict, Any, Optional, Callable
from dataclasses import dataclass
from enum import Enum
class RequestStatus(Enum):
PENDING = "pending"
COMPLETED = "completed"
FAILED = "failed"
TIMEOUT = "timeout"
@dataclass
class RequestInfo:
"""请求信息跟踪"""
id: str
method: str
created_at: float
timeout: float
future: asyncio.Future
retry_count: int = 0
status: RequestStatus = RequestStatus.PENDING
class AsyncMCPClient:
"""支持异步并发的MCP客户端"""
def __init__(self, max_concurrent_requests: int = 10, default_timeout: float = 30.0):
self.max_concurrent_requests = max_concurrent_requests
self.default_timeout = default_timeout
self.pending_requests: Dict[str, RequestInfo] = {}
self.request_semaphore = asyncio.Semaphore(max_concurrent_requests)
self.is_running = False
async def send_request(self, method: str, params: Optional[Dict[str, Any]] = None,
timeout: Optional[float] = None) -> Any:
"""发送异步请求"""
request_id = self._generate_request_id()
timeout = timeout or self.default_timeout
# 创建请求信息
future = asyncio.Future()
request_info = RequestInfo(
id=request_id,
method=method,
created_at=time.time(),
timeout=timeout,
future=future
)
self.pending_requests[request_id] = request_info
# 限制并发数量
async with self.request_semaphore:
try:
# 构造JSON-RPC请求
rpc_request = {
"jsonrpc": "2.0",
"id": request_id,
"method": method
}
if params:
rpc_request["params"] = params
# 发送请求(这里模拟网络发送)
await self._send_to_server(rpc_request)
# 等待响应或超时
result = await asyncio.wait_for(future, timeout=timeout)
request_info.status = RequestStatus.COMPLETED
return result
except asyncio.TimeoutError:
request_info.status = RequestStatus.TIMEOUT
raise TimeoutError(f"Request {request_id} timed out after {timeout}s")
except Exception as e:
request_info.status = RequestStatus.FAILED
raise e
finally:
# 清理请求信息
self.pending_requests.pop(request_id, None)
async def _send_to_server(self, request: Dict[str, Any]) -> None:
"""模拟向服务器发送请求"""
# 这里只是模拟,实际实现会通过WebSocket、HTTP等发送
print(f"发送请求: {request['method']} (ID: {request['id']})")
await asyncio.sleep(0.1) # 模拟网络延迟
def _generate_request_id(self) -> str:
"""生成请求ID"""
import uuid
return str(uuid.uuid4())
def handle_response(self, response: Dict[str, Any]) -> None:
"""处理服务器响应"""
request_id = response.get("id")
if not request_id or request_id not in self.pending_requests:
return
request_info = self.pending_requests[request_id]
if "error" in response:
error = response["error"]
request_info.future.set_exception(
Exception(f"RPC Error {error['code']}: {error['message']}")
)
else:
request_info.future.set_result(response.get("result"))
async def get_status_summary(self) -> Dict[str, Any]:
"""获取请求状态摘要"""
total = len(self.pending_requests)
status_counts = {}
for req in self.pending_requests.values():
status = req.status.value
status_counts[status] = status_counts.get(status, 0) + 1
return {
"total_pending": total,
"status_breakdown": status_counts,
"semaphore_available": self.request_semaphore._value
}
# 使用示例:并发调用多个工具
async def demo_concurrent_requests():
"""演示并发请求处理"""
client = AsyncMCPClient(max_concurrent_requests=5)
# 准备多个并发任务
tasks = []
# 任务1: 计算器工具
tasks.append(client.send_request(
method="tools/call",
params={"name": "calculator", "arguments": {"operation": "add", "a": 10, "b": 5}}
))
# 任务2: 文件读取工具
tasks.append(client.send_request(
method="tools/call",
params={"name": "file_reader", "arguments": {"path": "/tmp/data.txt"}}
))
# 任务3: 天气查询工具
tasks.append(client.send_request(
method="tools/call",
params={"name": "weather", "arguments": {"city": "北京"}}
))
# 并发执行所有任务
start_time = time.time()
results = await asyncio.gather(*tasks, return_exceptions=True)
end_time = time.time()
print(f"并发执行完成,耗时: {end_time - start_time:.2f}秒")
for i, result in enumerate(results):
if isinstance(result, Exception):
print(f"任务{i+1}失败: {result}")
else:
print(f"任务{i+1}成功: {result}")
# 运行演示
if __name__ == "__main__":
asyncio.run(demo_concurrent_requests())
2. 超时控制与重试策略
2.1 超时策略对比
| 策略类型 | 超时时间 | 适用场景 | 重试次数 |
|---|---|---|---|
| 快速响应 | 5-10秒 | 简单计算、缓存查询 | 2-3次 |
| 标准处理 | 30-60秒 | 文件操作、数据库查询 | 3-5次 |
| 长时间任务 | 300秒+ | 大数据处理、AI推理 | 1-2次 |
2.2 智能重试机制实现
import random
from typing import Callable, Any
class RetryStrategy:
"""重试策略配置"""
def __init__(self, max_retries: int = 3, base_delay: float = 1.0,
max_delay: float = 60.0, backoff_factor: float = 2.0):
self.max_retries = max_retries
self.base_delay = base_delay
self.max_delay = max_delay
self.backoff_factor = backoff_factor
def get_delay(self, attempt: int) -> float:
"""计算重试延迟时间(指数退避 + 随机抖动)"""
# 指数退避
delay = self.base_delay * (self.backoff_factor ** attempt)
delay = min(delay, self.max_delay)
# 添加随机抖动(防止雷群效应)
jitter = random.uniform(0.8, 1.2)
return delay * jitter
class ResilientMCPClient(AsyncMCPClient):
"""具备重试能力的MCP客户端"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.default_retry_strategy = RetryStrategy()
async def send_request_with_retry(self, method: str, params: Optional[Dict[str, Any]] = None,
timeout: Optional[float] = None,
retry_strategy: Optional[RetryStrategy] = None) -> Any:
"""支持重试的请求发送"""
retry_strategy = retry_strategy or self.default_retry_strategy
last_exception = None
for attempt in range(retry_strategy.max_retries + 1):
try:
print(f"尝试发送请求 {method},第 {attempt + 1} 次")
result = await self.send_request(method, params, timeout)
if attempt > 0:
print(f"重试成功!第 {attempt + 1} 次尝试")
return result
except (TimeoutError, ConnectionError, Exception) as e:
last_exception = e
print(f"第 {attempt + 1} 次尝试失败: {e}")
# 如果还有重试机会
if attempt < retry_strategy.max_retries:
delay = retry_strategy.get_delay(attempt)
print(f"等待 {delay:.2f} 秒后重试...")
await asyncio.sleep(delay)
else:
print(f"达到最大重试次数 ({retry_strategy.max_retries}),放弃重试")
# 所有重试都失败
raise last_exception
# 使用示例
async def demo_retry_mechanism():
"""演示重试机制"""
client = ResilientMCPClient()
# 自定义重试策略:快速重试
fast_retry = RetryStrategy(max_retries=2, base_delay=0.5, backoff_factor=1.5)
try:
result = await client.send_request_with_retry(
method="tools/call",
params={"name": "unreliable_service", "arguments": {}},
retry_strategy=fast_retry
)
print(f"最终结果: {result}")
except Exception as e:
print(f"最终失败: {e}")
if __name__ == "__main__":
asyncio.run(demo_retry_mechanism())
3. MCP协议扩展特性
3.1 流式响应处理
流式响应就像看直播一样,数据一边生成一边传输,不用等到全部完成才能看到结果。
import json
from typing import AsyncIterator, Dict, Any
class StreamingMCPClient:
"""支持流式响应的MCP客户端"""
async def send_streaming_request(self, method: str, params: Optional[Dict[str, Any]] = None) -> AsyncIterator[Dict[str, Any]]:
"""发送流式请求"""
request_id = self._generate_request_id()
# 构造流式请求
request = {
"jsonrpc": "2.0",
"id": request_id,
"method": method,
"params": {
**(params or {}),
"stream": True # 标记为流式请求
}
}
print(f"发送流式请求: {json.dumps(request, ensure_ascii=False)}")
# 模拟流式响应
await self._simulate_streaming_response(request_id)
async def _simulate_streaming_response(self, request_id: str) -> AsyncIterator[Dict[str, Any]]:
"""模拟流式响应数据"""
# 模拟AI生成文本的流式响应
text_chunks = [
"人工智能", "是计算机科学", "的一个分支", ",它致力于", "创建能够",
"模拟人类智能", "的系统。", "通过机器学习", "和深度学习", "技术..."
]
for i, chunk in enumerate(text_chunks):
await asyncio.sleep(0.3) # 模拟生成延迟
response = {
"jsonrpc": "2.0",
"id": request_id,
"result": {
"type": "stream_chunk",
"chunk_id": i,
"content": chunk,
"is_final": i == len(text_chunks) - 1
}
}
print(f"流式数据块 {i}: {chunk}")
yield response
def _generate_request_id(self) -> str:
import uuid
return str(uuid.uuid4())
# 使用示例
async def demo_streaming():
"""演示流式响应处理"""
client = StreamingMCPClient()
print("开始流式AI文本生成...")
full_text = ""
async for chunk_response in client.send_streaming_request(
method="ai/generate_text",
params={"prompt": "介绍人工智能", "max_tokens": 100}
):
result = chunk_response["result"]
content = result["content"]
full_text += content
# 实时显示进度
print(f"实时文本: {full_text}")
if result["is_final"]:
print(f"生成完成!最终文本: {full_text}")
break
if __name__ == "__main__":
asyncio.run(demo_streaming())
3.2 批量操作支持
批量操作就像批发购物,一次性处理多个相关任务,效率更高。
class BatchMCPClient:
"""支持批量操作的MCP客户端"""
async def send_batch_request(self, requests: list[Dict[str, Any]]) -> list[Dict[str, Any]]:
"""发送批量请求"""
# 为每个请求添加ID
for i, req in enumerate(requests):
if "id" not in req:
req["id"] = f"batch_{i}_{int(time.time())}"
req["jsonrpc"] = "2.0"
print(f"发送批量请求,包含 {len(requests)} 个子请求")
# 模拟批量处理
responses = []
for req in requests:
# 模拟处理单个请求
if req["method"] == "tools/call":
response = {
"jsonrpc": "2.0",
"id": req["id"],
"result": {
"tool": req["params"]["name"],
"status": "success",
"output": f"工具 {req['params']['name']} 执行完成"
}
}
else:
response = {
"jsonrpc": "2.0",
"id": req["id"],
"result": {"status": "processed"}
}
responses.append(response)
await asyncio.sleep(0.1) # 模拟处理时间
return responses
# 使用示例
async def demo_batch_operations():
"""演示批量操作"""
client = BatchMCPClient()
# 准备批量请求
batch_requests = [
{
"method": "tools/call",
"params": {"name": "calculator", "arguments": {"op": "add", "a": 1, "b": 2}}
},
{
"method": "tools/call",
"params": {"name": "translator", "arguments": {"text": "hello", "target": "zh"}}
},
{
"method": "resources/read",
"params": {"uri": "file:///data/config.json"}
}
]
print("开始批量处理...")
start_time = time.time()
responses = await client.send_batch_request(batch_requests)
end_time = time.time()
print(f"批量处理完成,耗时: {end_time - start_time:.2f}秒")
# 处理批量响应
for i, response in enumerate(responses):
print(f"请求 {i+1} 结果: {response['result']}")
if __name__ == "__main__":
asyncio.run(demo_batch_operations())
4. 跨语言兼容性实践
4.1 跨语言兼容性对比
| 语言 | JSON解析 | 异步支持 | 生态成熟度 | MCP集成难度 |
|---|---|---|---|---|
| Python | 原生支持 | asyncio | 很高 | 简单 |
| JavaScript | 原生支持 | Promise/async | 很高 | 简单 |
| Java | Jackson等库 | CompletableFuture | 高 | 中等 |
| Go | encoding/json | goroutine | 中等 | 中等 |
| Rust | serde_json | tokio | 中等 | 中等 |
4.2 跨语言数据类型映射
class CrossLanguageDataMapper:
"""跨语言数据类型映射工具"""
# 类型映射表
TYPE_MAPPING = {
"python": {
"string": str,
"number": (int, float),
"boolean": bool,
"array": list,
"object": dict,
"null": type(None)
},
"javascript": {
"string": "string",
"number": "number",
"boolean": "boolean",
"array": "Array",
"object": "Object",
"null": "null"
},
"java": {
"string": "String",
"number": "Number",
"boolean": "Boolean",
"array": "List",
"object": "Map",
"null": "null"
}
}
@staticmethod
def validate_json_rpc_params(params: Dict[str, Any]) -> Dict[str, str]:
"""验证JSON-RPC参数的跨语言兼容性"""
compatibility_report = {}
for key, value in params.items():
value_type = type(value).__name__
if isinstance(value, str):
compatibility_report[key] = "✅ 字符串 - 全语言兼容"
elif isinstance(value, (int, float)):
if isinstance(value, int) and -2**53 < value < 2**53:
compatibility_report[key] = "✅ 安全整数 - 全语言兼容"
elif isinstance(value, float):
compatibility_report[key] = "⚠️ 浮点数 - 精度可能不同"
else:
compatibility_report[key] = "❌ 大整数 - JavaScript不安全"
elif isinstance(value, bool):
compatibility_report[key] = "✅ 布尔值 - 全语言兼容"
elif isinstance(value, list):
compatibility_report[key] = "✅ 数组 - 全语言兼容"
elif isinstance(value, dict):
compatibility_report[key] = "✅ 对象 - 全语言兼容"
elif value is None:
compatibility_report[key] = "✅ null - 全语言兼容"
else:
compatibility_report[key] = f"❌ {value_type} - 非标准JSON类型"
return compatibility_report
# 使用示例
def demo_cross_language_compatibility():
"""演示跨语言兼容性检查"""
mapper = CrossLanguageDataMapper()
# 测试参数
test_params = {
"user_name": "张三",
"age": 25,
"height": 175.5,
"is_active": True,
"skills": ["Python", "JavaScript", "Go"],
"profile": {"city": "北京", "experience": 3},
"avatar": None,
"big_number": 9007199254740992, # 超过JavaScript安全整数范围
}
print("跨语言兼容性检查报告:")
print("=" * 50)
report = mapper.validate_json_rpc_params(test_params)
for param, status in report.items():
print(f"{param:12}: {status}")
print("\n建议:")
print("• 避免使用超过 2^53 的大整数")
print("• 浮点数运算结果可能在不同语言间略有差异")
print("• 使用标准JSON数据类型确保最佳兼容性")
if __name__ == "__main__":
demo_cross_language_compatibility()
🎯 第二部分核心要点
1. 异步通信处理机制
- 并发请求管理:使用信号量控制最大并发数,避免系统过载
- 请求状态跟踪:实时监控每个请求的状态(待处理、完成、失败、超时)
- 智能超时控制:根据不同场景设置合适的超时时间
2. 重试策略设计
- 指数退避算法:重试间隔逐渐增加,避免系统雪崩
- 随机抖动:防止大量客户端同时重试造成"雷群效应"
- 分层重试策略:快速任务短重试,复杂任务长重试
3. MCP协议扩展特性
- 流式响应:像看直播一样实时处理数据,提升用户体验
- 批量操作:一次性处理多个相关请求,提高效率
- 自定义方法:扩展标准JSON-RPC,支持业务特定需求
4. 跨语言兼容性
- 数据类型映射:确保不同语言间的数据类型正确转换
- 兼容性检查:自动验证参数的跨语言兼容性
- 最佳实践:避免使用特定语言的特殊数据类型
💡 实用技巧总结
| 场景 | 推荐策略 | 关键参数 |
|---|---|---|
| 高并发场景 | 信号量 + 异步 | max_concurrent=10 |
| 网络不稳定 | 指数退避重试 | max_retries=3, base_delay=1s |
| 大数据传输 | 流式响应 | stream=true, chunk_size=1KB |
| 批量处理 | 批量请求 | batch_size=50 |
欢迎大家关注同名公众号《凡人的工具箱》:关注就送学习大礼包


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)