让机器人先“脑补”再动手!CoT-VLA 用“视觉思维链”刷新操作纪录
·
📌 引言
- 论文标题:CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
- arXiv 链接:arXiv:2503.22020
- 项目主页:https://cot-vla.github.io
🧐 研究背景/动机
“看得懂”≠“做得对”
近年来,视觉-语言-动作模型(VLA)让机器人“听懂人话、看懂世界”,但大多数方法都是“一步到底”:把当前画面和指令直接映射成动作,中间没有任何“思考过程”。
缺陷显而易见:
- 复杂任务被当成黑箱,缺乏可解释性;
- 遇到稍长的步骤(如“先把毛巾移到盘子旁,再盖在碗上”)容易顺序错乱;
- 训练极度依赖带动作标签的机器人数据,昂贵且稀缺。
能否让机器人像人类一样“先想象,再行动”?
🛠️ 研究方法
CoT-VLA 把“语言模型里的思维链”搬到视觉世界,核心只有两步:
1️⃣ 视觉“脑补”
给定一句人话 + 当前照片,模型先自回归地生成一张未来子目标图像(例如“5 秒后毛巾应该在盘子上方”)。
(示意图:输入图→生成子目标图,用箭头标注“想象”)
2️⃣ 动作“落地”
把“原始图 + 子目标图”一起喂给模型,一次性输出 10 步连续动作,让机械臂闭眼执行,再开环观察,循环往复。
与传统VLA 方法的直观对比: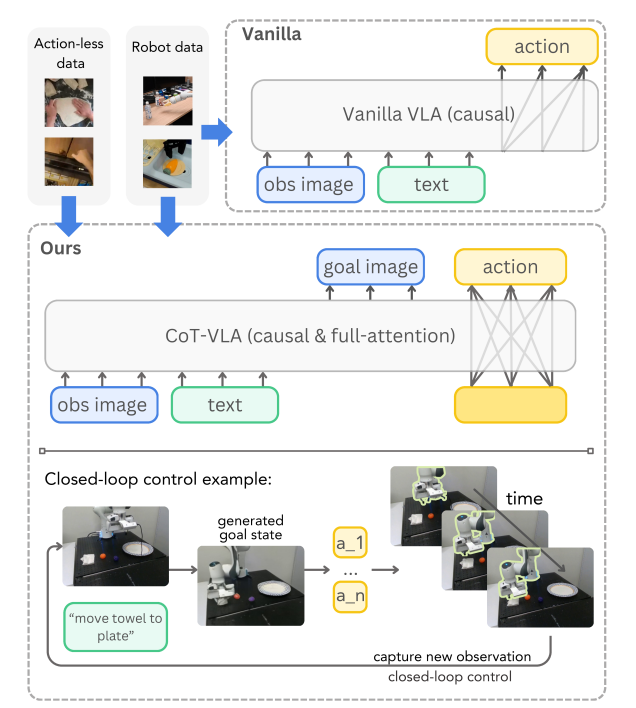
三大创新点
- 子目标图作为思维链:无需额外标注,视频里任意两帧就能当“想象”标签。
- 混合注意力:生成图像/文字时用“因果掩码”,预测动作时用“全注意力”,让 7 维动作彼此协调。
- 动作块(chunking):一次预测 10 步,降低累积误差,平均提速 7 倍。
数据配方
- 机器人演示:Open X-Embodiment 精选子集
- 无动作视频:EPIC-KITCHENS、Something-Something V2
比例≈ 7 : 3,让模型先“看会世界”,再“学会动手”。
📈 实验结果
① LIBERO 仿真基准(4 大场景)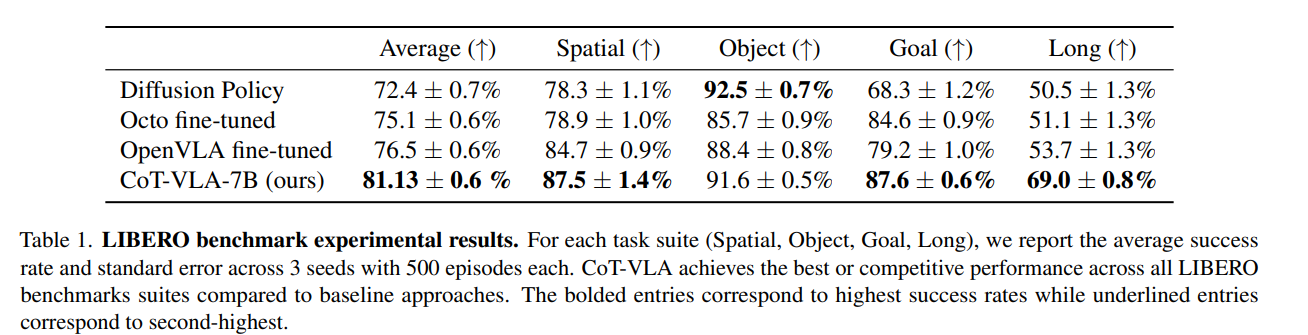
② Bridge-V2 真机 45k 数据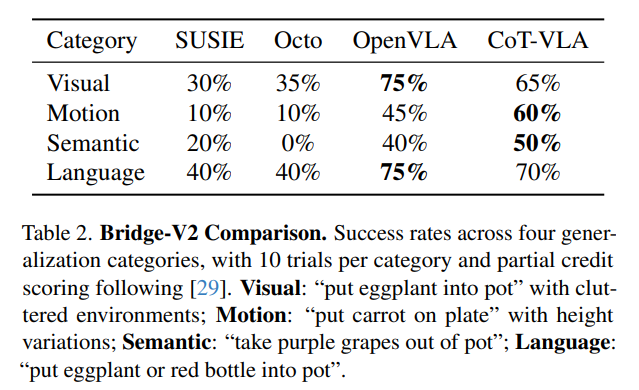
③ Franka-Tabletop 小样本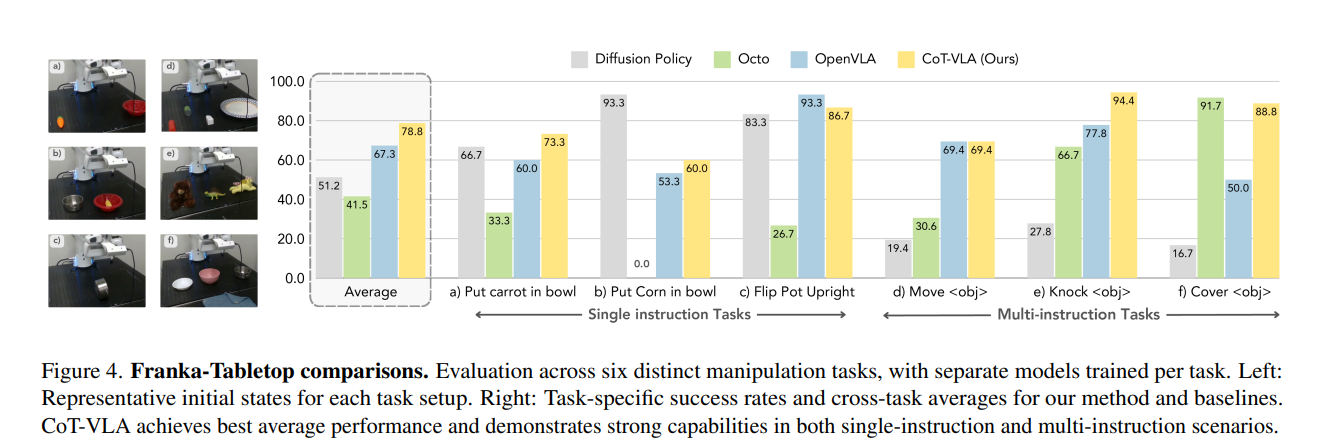
④ 消融实验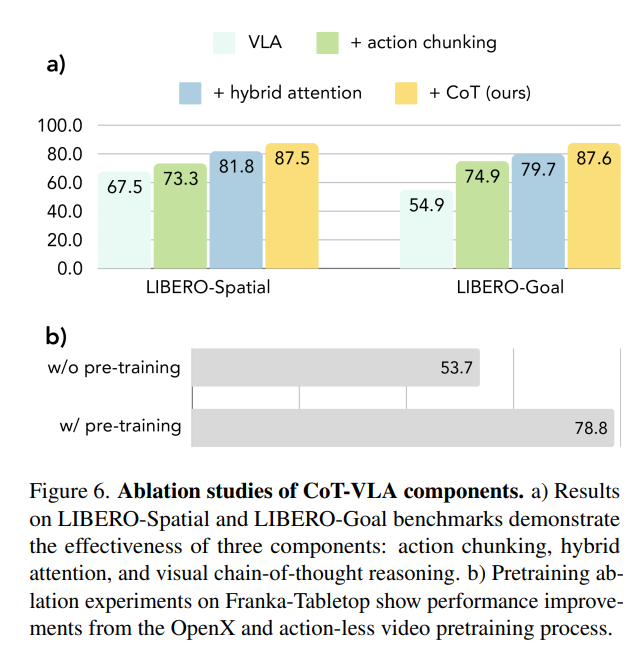
✍️ 结语
CoT-VLA 用一张“想象中的未来照片”把大语言模型的“逐步思考”搬进机器人世界,让动作不再黑箱,让数据不再昂贵。
留给我们的启发:
- 当 AI“会说会画”之后,“会想象”可能是通往通用机器人的下一站;
- 若手机里的短视频都能变成机器人“脑内小剧场”,低成本大规模训练不再是梦。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)