【深度学习】基于深度学习的图像卡通化与风格迁移算法研究
基于生成对抗网络(GAN)的图像卡通化与风格迁移研究,综合利用条件GAN、CycleGAN、AdaIN、自适应归一化、感知损失与对抗训练等技术,实现照片向卡通/艺术风格的高保真转换,同时强化边缘、保持语义一致并兼顾时间一致性与轻量化部署。通过定性视觉对比与定量指标(如 FID、LPIPS)评估效果,并探讨多风格控制与移动端实时化策略。适合专业:计算机科学与技术、人工智能、电子信息工程、软件工程、数
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯基于深度学习的图像卡通化与风格迁移算法研究
背景和意义
伴随着计算机视觉和人工智能技术的快速发展,图像风格化与卡通化已成为视觉计算领域的重要研究方向。图像风格化旨在将输入图像通过一系列算法变换为具有特定艺术风格或视觉效果的输出图像,这不仅具有显著的学术价值,而且在商业应用中也具有广泛前景:从影视后期处理、移动端滤镜、社交媒体内容创作,到广告设计、游戏美术资源生成乃至医学影像的视觉增强,均能借助风格化技术实现自动化与高效化。深度学习的兴起为风格迁移与图像卡通化带来了范式性的变化:通过学习大规模数据中的分布特征,神经网络能够生成风格多样、细节保真并可控性更强的风格化结果,从而推动了该领域从经验滤镜走向数据驱动和模型驱动的转型。

技术思路
图像卡通化与风格迁移涉及诸多基础和应用研究问题,涵盖图像表征、纹理合成、空间结构保护、语义感知与可控生成等多个方面。风格迁移促进了对“内容—风格”分离表示的理解,这不仅关系到生成模型的可解释性,也推动了视觉表征学习、对抗学习、生成模型以及Transformer架构在图像生成领域的交叉融合。常见的研究问题包括如何在保留图像语义结构的前提下迁移目标风格、如何设计稳定且高质量的生成对抗训练策略、以及如何评价生成结果的“艺术性”与“真实性”。卡通化与风格迁移的研究为移动端实时滤镜、视频风格化、一键美化和个性化内容创作提供了技术支持,具有显著的产业化潜力。
基于边缘的风格化方法
基于边缘的风格化方法核心意图是突出图像的结构要素(如轮廓、边界和主干线条),以实现类似手绘、素描或漫画的视觉效果。传统图像处理领域中,边缘检测是这一类方法的基础步骤,常见算子包括Sobel、Prewitt、Roberts和Laplacian等。以二维灰度图I(x,y)为例,Sobel算子通过水平与垂直核(Gx, Gy)对图像进行卷积,得到局部梯度分量,进而计算梯度幅值
Canny边缘检测在此基础上引入了高斯平滑、非极大值抑制与双阈值连接,使得边缘检测具有较好的抗噪与连通性。基于边缘的风格化通常先通过上述方法获取稀疏或稠密的边缘图,然后结合形态学处理(膨胀、腐蚀)、轮廓简化(多边形逼近)和线条着色等步骤,将边缘信息以粗细、强度可控的方式渲染到目标图像。例如,在卡通化处理中,往往将边缘图用作遮罩(mask),对原图的边缘区域进行高对比度描边处理,同时对非边缘区域进行颜色平滑(如双边滤波),从而产生“线条+平色块”的漫画感。
在深度学习兴起之后,基于边缘的风格化方法也逐步向学习驱动转变。卷积神经网络(CNN)可直接学习从原始图像到线稿(line drawing)或到卡通线条增强的映射,绕开传统算子在复杂场景下的脆弱性。比如训练一个网络F,使得F(I)接近人工标注的线稿L,可采用像素级损失(L2)、边缘感知损失(使用梯度算子)以及对抗损失(GAN判别器用于提升线稿的真实感)。边缘感知损失可写为:
将边缘与语义结合:先使用语义分割网络提取人物、背景等语义区域,再在这些区域内采用不同的边缘处理策略(如人物轮廓更细致、背景轮廓更模糊),以达到更符合艺术审美与语义一致性的效果。此外,Graph-based或基于变分模型(如各向异性扩散)也可用于提升边缘的连续性与风格化的稳定性。基于边缘的风格化在卡通化中的优势在于结构清晰、线条表达强烈,但也面临如何在强调结构的同时保留质感与颜色信息的挑战,因此往往与颜色处理、纹理合成等方法联合使用以取得最佳效果。

基于颜色的风格化方法
基于颜色的风格化最直观的起点是利用统计学或像素级映射将源图像的色彩分布变换为目标风格的分布。常见技术包括直方图匹配、颜色迁移(color transfer)和色彩空间变换等。直方图匹配通过累积分布函数(CDF)将源图像某通道的像素值映射到目标图像对应通道的分布,从而实现整体色调的移植;Reinhard 等提出的简单线性变换方法则通过对图像在某一颜色空间(如Lab)的均值与方差进行匹配,实现跨图像的基调迁移。更为精细的统计方法会把颜色分布建模为多元高斯混合模型(GMM)或利用最优传输(Optimal Transport)来求解源与目标颜色分布之间的最小代价映射,从而得到更全局一致且平滑的颜色映射函数。这类方法的优势在于计算相对简单、可解释性强、在全局色温与色调迁移方面常常效果显著;但固有的缺点也很明显:它们往往忽视图像的空间信息和语义结构,导致色彩跨语义区域的错误传播(例如天空色被应用到前景人物),以及局部细节处出现色块不连贯或边界伪影。为缓解此类问题,工程上常把全局统计映射与空间/语义先验结合,例如先基于分割或显著性检测将图像分区,再对每一区块独立进行统计匹配,或对映射结果进行后处理以保证局部连贯性。
边缘保留滤波器(如双边滤波、导向滤波、基于域变换的快速边缘保留法)能在保持显著轮廓的同时将非结构性细节平滑为大色块,形成类似油画或漫画的“色块化”效果;这类滤波器的核心是同时依赖空间距离与像素值相似度来加权卷积,从而避免跨越轮廓的颜色混合。为了表现笔触和材质,研究者结合多尺度方法:粗尺度上进行色彩简化与大片笔触方向场估计,细尺度上合成笔触纹理或噪声以增加画面质感;笔触方向常通过图像梯度或主方向场估计算法得到,纹理合成则可采用基于样本的非参数合成或预先训练的笔触字典拼接。另一个重要方向是基于调色板(palette-based)的颜色简化:先抽取目标艺术风格的调色板,再将源图像的每个像素映射到最近颜色簇,从而实现具有艺术风格的配色风格化。此外,patch-based 技术(例如基于图像库的纹理搬运)能够将真实艺术品中的纹理块迁移到目标图像相应语义区域,通过匹配局部结构和相似上下文保证纹理的自然拼接。上述局部方法在保结构与创造手工质感方面表现优良,但实现中常需精细参数调优以避免“笔触错位”、拼接接缝明显或重复纹理伪影。神经风格迁移最早通过在预训练卷积网络特征空间中匹配内容与风格统计量(如Gram矩阵)来合成图像,随后的工作发展出前馈式生成网络(用感知损失训练以实现实时风格化)、可迁移到任意风格的模块化机制(如AdaIN、WCT),以及基于对抗训练的风格生成器以提升纹理真实感。
基于颜色的风格化方法具有高度的表现力和灵活性,能够在色彩层面创造多样化的艺术效果,但同时也面临着如何保持图像语义一致性、避免色彩漂移与伪影、以及实现高分辨率与视频帧一致性的挑战。针对这些问题,研究者们提出了多层次损失设计(结合内容、风格、结构与感知一致性)、多尺度网络架构、以及时序一致性约束(用于视频风格化)。综合来看,边缘与颜色两类方法常常互为补充:边缘负责刻画结构与轮廓,颜色负责赋予画面情绪与艺术质感;将二者有机结合,并在深度学习框架下设计可控、稳定且高效的算法,是图像卡通化与风格迁移研究的核心任务之一。

随着深度学习技术的迅速发展,以神经网络为基础的图像风格化方法迅速成为研究与应用的热点,尤其是以风格迁移为代表的一系列技术,不仅在学术界引发大量关注,也在工业界得到广泛落地。深度模型通过多层卷积网络、残差结构、注意力机制等自动学习出从低级纹理到高级语义的多尺度特征表示,使得风格迁移能够超越传统基于规则或统计的方法,处理更加复杂、多样且语义相关的风格变换。典型方法包括基于感知损失的优化型风格迁移、基于前馈网络的实时风格化、基于特征统计变换(如AdaIN、WCT)的任意风格迁移、以及近年的生成对抗网络(GAN)和扩散模型(diffusion models)用于生成更高保真、纹理更丰富的风格化图像。训练策略上,研究者结合像素级损失、内容保持损失、风格统计损失、对抗损失和结构/边缘保持损失等多重目标,以在保留输入图像语义结构的同时迁移目标风格的色彩与纹理特征。

通过引入语义分割或注意力引导机制,模型可以按语义区域差异化地应用风格,从而避免将不合适的颜色或纹理迁移到人脸、天空等关键区域;通过风格向量或控制参数,模型还能实现风格强度的可控插值、多风格混合与局部风格编辑。深度方法在视频风格化、移动端实时滤镜、交互式艺术创作等应用场景表现出强大的适应性,但同时也带来了新的挑战:
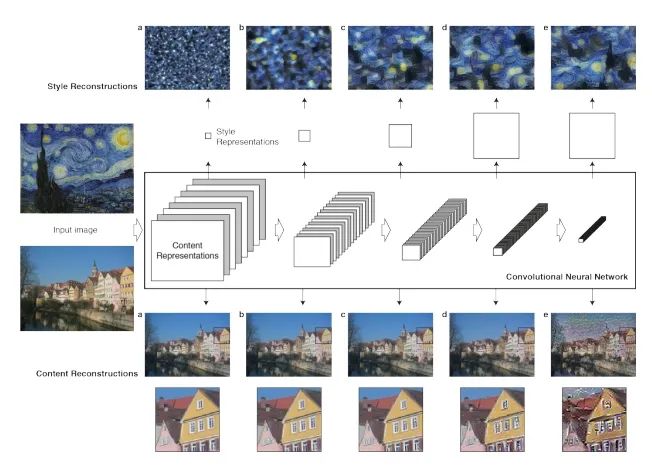
图像风格迁移的基本理念在于把一幅图像的语义内容与另一幅图像的艺术风格相结合,从而合成出既保持原始场景结构又呈现目标艺术特征的新图像。该思路受到对人类视觉信息处理方式的启发:人脑通过多层次的抽象来理解视觉信息,观察对象时会根据距离或注意焦点在不同层次上提取信息——靠近查看时侧重纹理与局部细节,远观则侧重整体轮廓与空间布局。卷积神经网络(CNN)天然契合这种分层处理机制,其各卷积层逐步从低级的边缘、纹理等特征抽象到高级的语义与结构信息。基于此,可以把图像的表征分为“内容层”和“风格层”两类:内容层主要承载图像的全局结构与语义信息,如物体类型与相对位置;而风格层则反映纹理模式、笔触特征、色彩分布等局部统计性质。正是这种内容与风格相对独立但可组合的表征,使得我们能够在保留源图像语义结构的前提下,通过操作或匹配不同层级的特征统计来迁移目标风格,从而实现既语义一致又具有艺术质感的图像生成。
在数学上,风格的表达通常涉及到格拉姆矩阵(Gram Matrix),该矩阵通过计算特征图之间的内积来捕捉图像的风格特征。格拉姆矩阵可以看作是特征之间的协方差矩阵,能够反映不同特征之间的关系。因此,通过比较两幅图像的格拉姆矩阵,我们可以度量它们风格的差异。具体而言,给定一幅内容图像 ccc 和一幅风格图像 sss,我们希望生成一幅图像 xxx,其目标是最小化一个综合的损失函数,该函数通常包括内容损失和风格损失,从而实现内容与风格的有效融合。
风格迁移问题可以被表述为在图像空间中寻找一幅生成图像 ,使其在“内容”特征上接近原始内容图像 ,在“风格”统计量上接近风格图。常用的实现框架是基于预训练的卷积网络(如 VGG)在若干层上提取特征,并在这些特征上定义内容损失与风格损失。内容损失典型形式为某层特征的均方误差:
风格通常通过层级特征之间的二阶统计来刻画,最经典的是格拉姆矩阵(Gram matrix):
基于格拉姆矩阵的风格损失可写为多层加权和:
最终的优化目标通常是这些损失的线性组合并加上正则项(如全变差 TV 损失以去除噪点):
基于上述公式的早期方法采取逐像素迭代优化,这类方法在视觉效果上往往较为忠实但计算代价高且不适合实时应用。为了提高效率,后来提出前馈式的图像转换网络(Image Transform Net),将一次训练过程用于学习从任意内容图像到目标风格图像的直接映射,训练时用上述感知损失约束网络输出与期望风格之间的差距,从而将耗时的迭代优化转化为一次性模型训练,推理阶段仅需一次前向传播。
单模型单风格的框架(如 Johnson 等人的工作)通常由两部分组成:一个用于图像生成的前馈网络(编码器-残差块-解码器架构常见),以及一个用来计算感知损失的固定判别网络(通常取 VGG 的若干层并计算内容与风格损失)。此类方法训练效率高,推理速度快,适合实时滤镜与移动端应用,但其主要局限在于每个训练好的模型只能表示一种风格。为克服这一限制,Style Bank 等多风格方案提出共享自编码器并在其“瓶颈”处插入多个风格滤波器组(style filters)。具体流程为:内容图像经编码器得到特征表示,随后该表示在不同的并行滤波器组中被卷积变换以产生对应风格的特征,最后通过解码器重建为风格化图像。训练时采用两条并行的训练路径——一条保证内容重建(自编码器直通),使用逐像素 MSE 保证内容一致;另一条通过风格滤波器组学习风格化变换,同时结合风格损失、内容损失与平滑正则等以约束输出质量。Style Bank 的优势在于风格模块化:新增风格只需训练对应滤波器组而不必重训练自编码器,从而实现增量学习和参数共享。但这种方法也有挑战:风格滤波器如何设计以兼顾多样性与参数效率、滤波器组之间是否会相互干扰、以及如何在保持高质量的同时压缩模型体积以便部署,都是工程上需要权衡的问题。
为了解决单模型只能表示单一风格的局限,Style Bank 提出了将“风格表示模块化”的思路——通过一组独立的风格滤波器(style filters)来显式编码多个风格,从而使得多个风格可以共享同一套编码器-解码器结构。具体流程为:输入图像先由编码器映射为中间特征图(feature map);随后该特征图分别与多个并行的风格滤波器组相互作用(通常以卷积操作实现),每一组滤波器对同一特征图施加不同的滤波变换以生成对应风格的特征;最后通过共享的解码器将风格化后的特征重建为图像输出。这样的设计把“内容表征”(由自编码器负责)与“风格变换”(由各个滤波器组负责)解耦,使得风格成为可插拔、可增量的模块。
在训练策略上,Style Bank 采用了两条并行但互补的训练路径以保证内容保持与风格表达的质量:一条是自编码器重建分支,其目标是使重建输出在像素级上与输入内容一致,通常以逐像素均方误差(MSE)作为损失,从而确保编码器-解码器对内容信息的保留与复原能力;另一条是风格化分支,该分支在保持内容大体结构的同时,需学习将目标风格的纹理与色彩特征注入到特征图中,因此训练时会结合内容损失、基于特征统计的风格损失以及平滑或全变差等正则项来约束输出质量。训练过程通常以交替或分阶段的方式进行:先确保自编码器能良好重建内容,再训练或微调风格滤波器组以学习多样的风格映射;由于风格模块与自编码器相对独立,新风格只需新增或单独训练对应的滤波器组即可实现增量学习,而无需重训练整个自编码器。
Style Bank 的工程优势在于参数与计算的共享性以及风格扩展的灵活性:共享的自编码器大大降低了模型体积与训练成本,而模块化的滤波器组则便于增添或替换风格;此外,这种显式滤波器的形式相对直观,便于分析不同滤波器对视觉效果的具体贡献。但该方法也有需要权衡的方面——滤波器组的容量与设计会影响风格表达的丰富性与互相干扰;若滤波器设计或训练不当,可能出现风格迁移不充分、内容泄露不足或不同风格间风格泄露(交叉影响)等问题。为提升灵活性与泛化性,后续研究提出了另一些思路,例如通过实例归一化(Instance Normalization)与可学习的缩放、偏移系数来控制风格表现,或用自适应实例归一化(AdaIN)直接以风格特征的通道均值与方差调制内容特征,从而实现无需为每种风格训练独立滤波器组的任意风格注入能力。
# -------------------------
# VGG 使用的 imagenet mean/std
vgg_mean = torch.tensor([0.485, 0.456, 0.406]).view(1,3,1,1)
vgg_std = torch.tensor([0.229, 0.224, 0.225]).view(1,3,1,1)
def preprocess_image(pil_img, device, target_size=None):
if target_size is not None:
pil_img = pil_img.resize((target_size, target_size), Image.LANCZOS)
tf = transforms.Compose([
transforms.ToTensor(), # [0,1]
])
x = tf(pil_img).unsqueeze(0).to(device) # (1,3,H,W)
# 归一化到 VGG 要求
x = (x - vgg_mean.to(device)) / vgg_std.to(device)
return x
def postprocess(tensor):
# tensor: (B,3,H,W) in VGG-normalized space
device = tensor.device
x = tensor * vgg_std.to(device) + vgg_mean.to(device)
x = x.clamp(0, 1)
x = x.cpu().squeeze(0)
img = transforms.ToPILImage()(x)
return img
# -------------------------
# 风格迁移前向(推理)
# content: tensor (1,3,H,W) already normalized for VGG
# style: tensor (1,3,H,W) already normalized
# alpha: 0..1,控制风格强度
# -------------------------
def stylize(encoder, decoder, content, style, alpha=1.0):
"""
1) 提取 content, style 在 relu4_1 的特征
2) 对 content 特征做 AdaIN,使其均值/方差匹配 style 特征
3) 对 AdaIN 后特征做线性插值(alpha)回 content 特征空间(可选)
4) decoder 解码得到图像
"""
# encode
content_feats = encoder(content)
style_feats = encoder(style)
cf = content_feats['relu4_1']
sf = style_feats['relu4_1']
# AdaIN
t = adain(cf, sf)
# 可插值控制风格强度
t = alpha * t + (1 - alpha) * cf
# decode
generated = decoder(t)
return generated
# content_loss = || encoder(generated)['relu4_1'] - t ||^2
# style_loss = sum_l || mean(gen_feat_l) - mean(style_feat_l) ||^2 + || std(...) - std(...)||^2
# -------------------------
def train_adain(decoder, encoder, dataloader, style_loader, device,
epochs=10, lr=1e-4, content_weight=1.0, style_weight=10.0):
decoder.to(device)
encoder.to(device)
optimizer = torch.optim.Adam(decoder.parameters(), lr=lr)
mse = nn.MSELoss()
# style_loader yields style images; 可以在每次迭代随机取一个 style
style_iter = iter(style_loader)
for epoch in range(epochs):
for i, content in enumerate(dataloader):
# content: (B,3,H,W) 需预处理到 VGG 格式
content = content.to(device)
try:
style = next(style_iter)
except StopIteration:
style_iter = iter(style_loader)
style = next(style_iter)
style = style.to(device)
# Encode
cf_map = encoder(content)['relu4_1']
sf_map = encoder(style)['relu4_1']
# AdaIN target
t = adain(cf_map, sf_map).detach() # detach t (原文中将 t 视为目标)
# Decode to image
generated = decoder(t)
# re-encode generated
gen_feats = encoder(generated)
# content loss: between gen relu4_1 and t
gen_relu4_1 = gen_feats['relu4_1']
content_loss = mse(gen_relu4_1, t)
# style loss: 对多层的均值/方差进行匹配
style_loss = 0.0
for layer in ['relu1_1', 'relu2_1', 'relu3_1', 'relu4_1']:
gf = gen_feats[layer]
sf = encoder(style)[layer] # 再次提取(可预缓存以加速)
gm_mean, gm_std = calc_mean_std(gf)
sm_mean, sm_std = calc_mean_std(sf)
style_loss += mse(gm_mean, sm_mean) + mse(gm_std, sm_std)
loss = content_weight * content_loss + style_weight * style_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 200 == 0:
print(f"Epoch {epoch} Iter {i}: loss={loss.item():.4f} content={content_loss.item():.4f} style={style_loss.item():.4f}")
# optionally save checkpoint
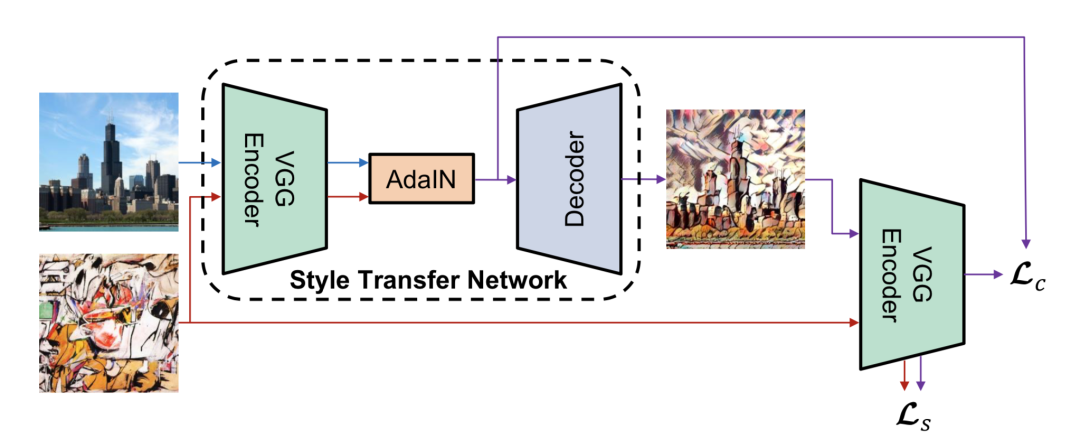
torch.save(decoder.state_dict(), f"adain_decoder_epoch{epoch}.pth")单模型任意风格框架突破了单模型多风格方法的局限性,能够在不重新训练模型的情况下实现多种风格的转换。该方法通过学习实例归一化的仿射变换系数来控制风格的表现,研究表明这些仿射参数可以用风格图本身的统计信息来替代,即通过风格图像的均值和方差来生成任意风格的图像。这一过程通过AdaIN层实现,具体做法是利用内容图的均值和方差进行归一化处理,然后将风格图的均值和方差作为偏移量和缩放系数,从而有效地融合内容与风格。这一创新使得模型能够灵活地适应多样化的风格要求,同时避免了反复训练的计算成本,极大地提升了风格迁移的效率和实用性。
class Discriminator(nn.Module):
def __init__(self, in_channels=6, ndf=64):
super().__init__()
# 输入为 concat(photo, comic) -> 判断是否真实
self.layer1 = conv_block(in_channels, ndf, norm=False) # 128
self.layer2 = conv_block(ndf, ndf*2) # 64
self.layer3 = conv_block(ndf*2, ndf*4) # 32
self.layer4 = conv_block(ndf*4, ndf*8, stride=1) # 31
self.last = nn.Conv2d(ndf*8, 1, kernel_size=4, stride=1, padding=1) # 输出 patch 判别图
def forward(self, x):
h1 = self.layer1(x)
h2 = self.layer2(h1)
h3 = self.layer3(h2)
h4 = self.layer4(h3)
out = self.last(h4)
return out
# ---------------------------
# 感知(VGG)损失(用 relu2_2, relu3_3 等)
# ---------------------------
class VGGPerceptual(nn.Module):
def __init__(self):
super().__init__()
vgg = models.vgg19(pretrained=True).features
# 用到的层索引(按 torchvision.vgg19.features 编号)
self.slice1 = nn.Sequential(*[vgg[x] for x in range(0, 4)]) # relu1_1..relu1_2
self.slice2 = nn.Sequential(*[vgg[x] for x in range(4, 9)]) # relu2_2
self.slice3 = nn.Sequential(*[vgg[x] for x in range(9, 16)]) # relu3_3
for p in self.parameters():
p.requires_grad = False
def forward(self, x):
# expects x in range [0,1] and normalized by imagenet mean/std before calling
h = self.slice1(x)
h = self.slice2(h)
h = self.slice3(h)
return h
# ---------------------------
# 权重初始化
# ---------------------------
def init_weights(m):
classname = m.__class__.__name__
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
if getattr(m, "bias", None) is not None:
nn.init.constant_(m.bias.data, 0)
elif isinstance(m, nn.InstanceNorm2d):
if m.weight is not None:
nn.init.constant_(m.weight.data, 1.0)
nn.init.constant_(m.bias.data, 0.0)
# ---------------------------
# 创建模型、优化器、损失
# ---------------------------
G = GeneratorUNet().to(device)
D = Discriminator().to(device)
G.apply(init_weights)
D.apply(init_weights)
optimizer_G = torch.optim.Adam(G.parameters(), lr=LR, betas=(0.5, 0.999))
optimizer_D = torch.optim.Adam(D.parameters(), lr=LR, betas=(0.5, 0.999))
mse_loss = nn.MSELoss()
l1_loss = nn.L1Loss()
vgg_loss_net = VGGPerceptual().to(device)
# VGG 期望输入为 ImageNet 归一化:先从 [-1,1] -> [0,1] -> normalize
imagenet_norm = transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225])
def to_vgg_input(x): # x in [-1,1]
x = (x + 1.0) / 2.0
return imagenet_norm(x)
# ---------------------------
# 训练主循环(简化)
# ---------------------------
def train(train_loader):
G.train(); D.train()
for epoch in range(EPOCHS):
for i, (photo, comic) in enumerate(train_loader):
photo = photo.to(device)
comic = comic.to(device)
# --------------------
# 更新 D: 判别真/假
# --------------------
fake = G(photo)
# concat along channel
real_pair = torch.cat([photo, comic], dim=1)
fake_pair = torch.cat([photo, fake.detach()], dim=1)
pred_real = D(real_pair)
pred_fake = D(fake_pair)
# LSGAN: 真标签为 1,假为 0
valid = torch.ones_like(pred_real, device=device)
fake_lbl = torch.zeros_like(pred_fake, device=device)
loss_D_real = mse_loss(pred_real, valid)
loss_D_fake = mse_loss(pred_fake, fake_lbl)
loss_D = 0.5 * (loss_D_real + loss_D_fake)
optimizer_D.zero_grad()
loss_D.backward()
optimizer_D.step()
# --------------------
# 更新 G
# --------------------
fake_pair = torch.cat([photo, fake], dim=1)
pred_fake_for_G = D(fake_pair)
# GAN loss (LSGAN)
loss_G_gan = mse_loss(pred_fake_for_G, valid)
# L1 loss (像素)
loss_G_l1 = l1_loss(fake, comic) * LAMBDA_L1
# 感知损失
# 将生成与真实转到 VGG 输入格式
vgg_fake = to_vgg_input(fake)
vgg_real = to_vgg_input(comic)
feat_fake = vgg_loss_net(vgg_fake)
feat_real = vgg_loss_net(vgg_real)
loss_perc = l1_loss(feat_fake, feat_real) * LAMBDA_PERC
loss_G = loss_G_gan + loss_G_l1 + loss_perc
optimizer_G.zero_grad()
loss_G.backward()
optimizer_G.step()
if i % 100 == 0:
print(f"Epoch [{epoch}/{EPOCHS}] Iter {i} Loss_D: {loss_D.item():.4f} Loss_G: {loss_G.item():.4f} (gan:{loss_G_gan.item():.4f}, l1:{loss_G_l1.item():.4f}, perc:{loss_perc.item():.4f})")
# 保存模型与可视化样本
os.makedirs(SAVE_DIR, exist_ok=True)
torch.save(G.state_dict(), os.path.join(SAVE_DIR, f"G_epoch{epoch}.pth"))
torch.save(D.state_dict(), os.path.join(SAVE_DIR, f"D_epoch{epoch}.pth"))
# 保存第一批样本的可视化
G.eval()
with torch.no_grad():
sample_photo, sample_comic = next(iter(train_loader))
sample_photo = sample_photo.to(device)[:4]
fake_sample = G(sample_photo)
# 反归一化到 [0,1] 并保存网格
def denorm(x): return (x + 1) / 2
grid = utils.make_grid(torch.cat([denorm(sample_photo), denorm(fake_sample)], dim=0), nrow=4)
utils.save_image(grid, os.path.join(SAVE_DIR, f"sample_epoch{epoch}.png"))
G.train()
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献191条内容
已为社区贡献191条内容

所有评论(0)