大模型部署-3-vllm部署deepseek
vllm简介
如果说Ollama的优势在于其简洁性,那么Vllm则是一个另辟蹊径、优先考虑性能和可扩展性的大模型部署框架,其核心的优化点在高效内存管理、持续批处理功能和张量并行性,从而在生产环境中的高吞吐量场景中表现极佳,同时这也是为什么Vllm框架是目前最适用于企业真实生产环境部署的根本原因。
首先需要重点说明的是:Vllm框架仅支持Linux操作系统,官方并没有提供Windows的兼容版本。同时除了有操作的限制,对运行的`Python`版本也要求在Python 3.8 ~ Python 3.12之间。这两个条件限制为部署Vllm的先决条件,即必须满足才可以顺利使用Vllm启动大模型并提供推理服务。
vllm部署大模型
虚拟环境配置
#创建虚拟环境
conda create --name vllm python=3.12
#激活虚拟环境
conda activate vllm安装vllm
pip install vllm模型下载
进入魔塔社区:https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B,点击下载模型
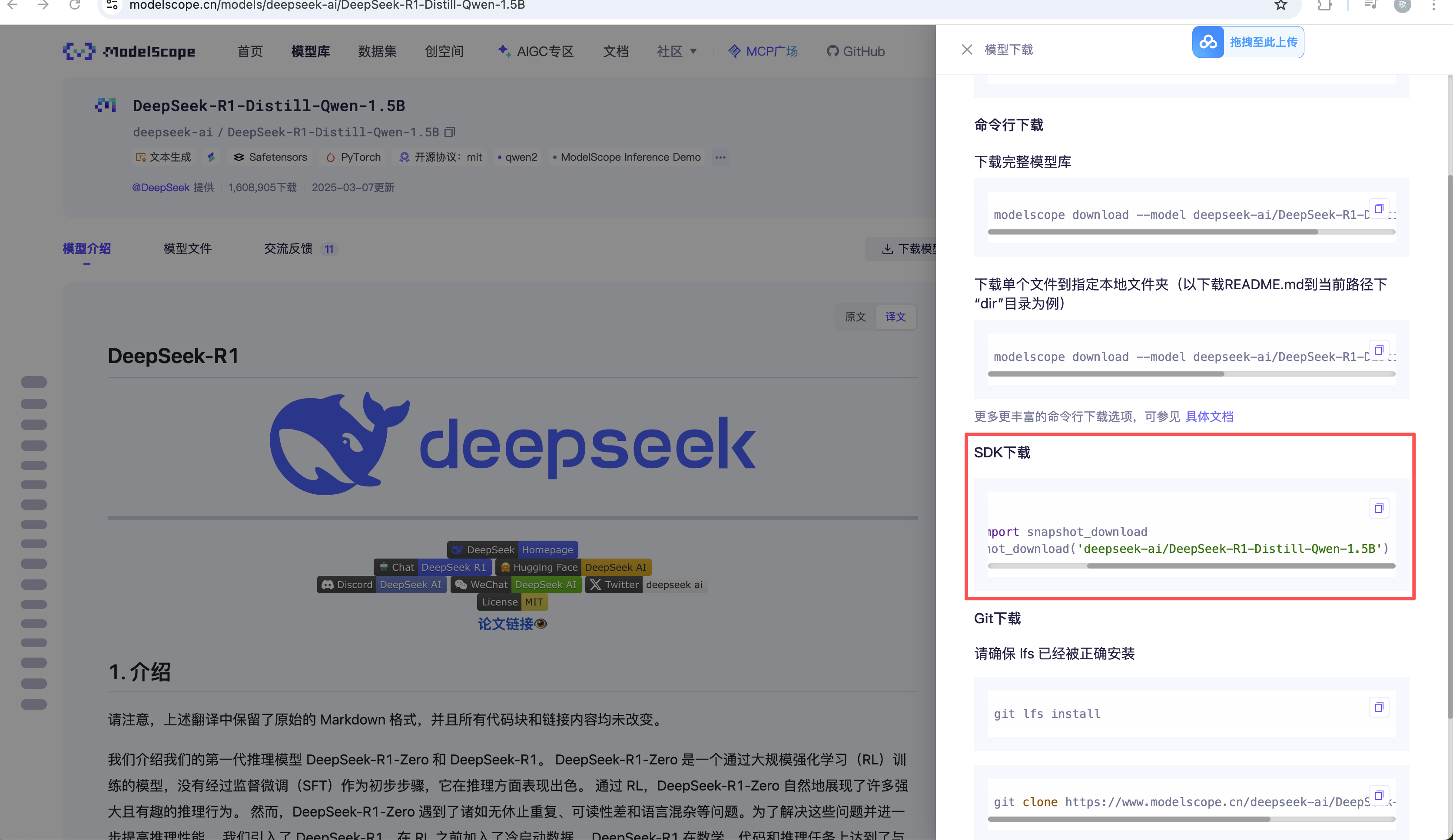
我这里使用sdk下载,先安装modelscope
pip install modelscope
下载脚本model_download.py:
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B', cache_dir='/home/models', revision='master')注意,这里cache_dir参数指定的路径是模型权重存储的路径,这里我们指定为/home/models 目录,即模型权重会存储到该目录下。执行脚本下载模型:
python model_download.py模型推理
离线推理
推理类模型的在Vllm离线推理API中的使用:
from vllm import LLM
llm = LLM(model="/home/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B", trust_remote_code=True, max_model_len=4096)
print(llm.generate("什么是大模型?"))在线推理
简单来说,所谓的vLLM在线推理,就是vLLM框架提供了一个可以设置为遵循OpenAI API协议的http服务器,实现了OpenAI的Completions API、Chat API等接口规范,只有通过这些接口规范,才能够允许我们使用通用的接口协议接入其他的客户端进行集成使用。比如热门开源项目Kotaemon、Open webui等,其接入的规范都是遵循OpenAI API协议的。
对于在线推理服务,需要先启动vLLM模型服务,然后才能通过http协议来访问模型服务。启动Http服务器vLLM提供的是vllm serve命令,可以通过vllm serve --help命令查看详细、可以在启动时指定模型服务启动的参数。
vLLM 在线推理服务启动参数:

我们在终端执行如下命令启动:
vllm serve DeepSeek-R1-Distill-Qwen-1___5B --served-model-name deepseek-r1-1.5b --host 0.0.0.0 --port 9000 --trust-remote-code --tensor-parallel-size 1 --api-key root --gpu-memory-utilization 0.95当能看到Application startup complete,则表示vLLM的在线推理服务启动成功。
这里的核心参数定义规则是:vllm serve <模型名称> --served-model-name <模型别名> --api_key <API密钥> --host <服务器地址> --port <端口号> --trust_remote_code --tensor_parallel_size <张量并行组数量> 。其中 vllm serve后不使用任何参数,直接指定本地模型的存储路径,而--served-model-name参数则用于指定模型服务启动后,在代码环境下通过http协议访问时需要指定的模型名称。
测试验证:
from openai import OpenAI
client = OpenAI(
base_url="http://192.168.110.131:9000/v1", # 这里是 --host + --port 的组合
api_key="root", # 这里是 --api_key 的参数
)
completion = client.chat.completions.create(
model="deepseek-r1-1.5b", # 这里是 --served-model-name 的参数
messages=[
{"role": "user", "content": "你好,请你介绍一下你自己"},
]
)
print(completion.choices[0].message.content)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)