论文阅读:ACL 2022 Beyond Goldfish Memory∗: Long-Term Open-Domain Conversation
打破“金鱼记忆”:长期开放域对话研究。
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2107.07567
dataset:https://parl.ai/projects/msc/
打破“金鱼记忆”:长期开放域对话研究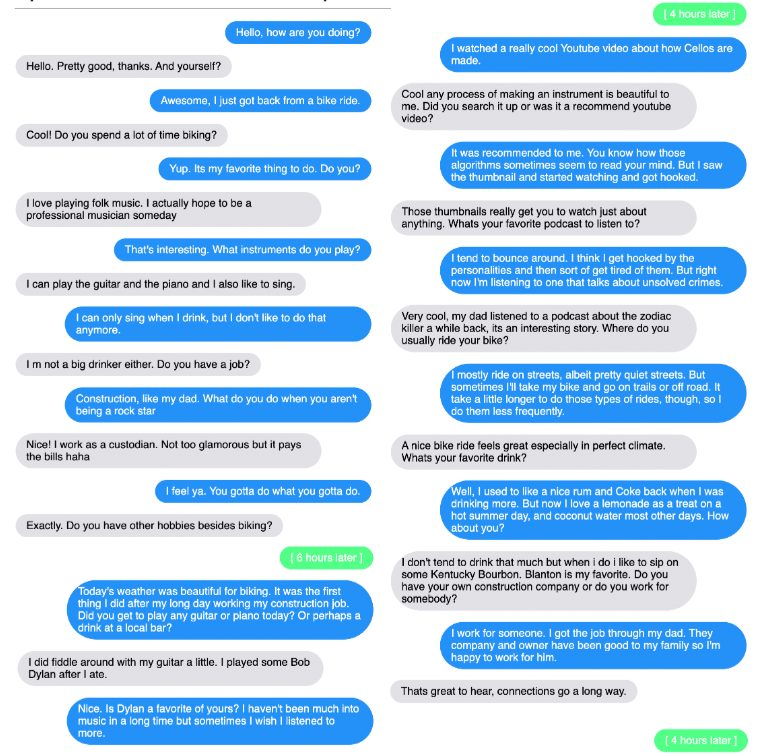
速览
该论文《Beyond Goldfish Memory: Long-Term Open-Domain Conversation》发表于 ACL 2022,由 Facebook AI Research 的 Jing Xu、Arthur Szlam 和 Jason Weston 共同撰写。论文聚焦于长期开放域对话这一较少被研究的领域,旨在解决现有对话模型在处理长对话时的不足。
目前,尽管开放域对话模型取得了显著进展,但大多数模型的训练和评估都集中在短对话上,缺乏对长期对话情境的考量。该论文通过收集和发布一个多会话的人类对话数据集——Multi-Session Chat(MSC),来填补这一空白。MSC 数据集包含多个聊天会话,对话者在这些会话中逐渐了解彼此的兴趣,并在后续会话中继续讨论之前的话题。
研究发现,现有的标准编码器 - 解码器架构在长期对话设置中表现不佳,无论是自动评估还是人类评估都显示出较差的效果。为此,论文探索了两种能够处理长上下文的对话架构:一是检索增强型生成模型,二是基于读写记忆的模型,后者能够实时总结和存储对话内容。实验结果表明,这两种方法都优于传统的 Transformer 架构,且在自动指标和人类评估中都表现出色。
此外,论文还对不同模型架构进行了广泛的实验和消融研究,以揭示这些改进背后的原因,并发布了模型、数据和代码,以便其他研究人员进一步评估这一重要问题的进展。该研究不仅为长期开放域对话提供了新的数据资源,还为未来对话系统的发展提供了新的方向,特别是在如何更好地利用长期上下文和对话历史方面。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)