0901-0905 | 大模型方向周报:可解释性与伦理、推理与记忆机制、信息检索与推荐、效率提升与资源优化等方向
本文精选20篇大模型领域最新研究,涵盖12个核心方向。研究发现:AI偏见显著影响人类决策(90%受试者被影响);概念级记忆机制提升推理能力7.5%;LLM在电商推荐中实现36%加购率提升;中文虚假信息核查存在局限;阿拉伯文化理解准确率仅72.15%。同时,研究揭示了LLM在自动驾驶迁移性、隐私政策解析、人格行为一致性等方面的突破与挑战,为技术发展提供了重要参考。
本周精选20篇大模型顶刊顶会论文,覆盖12个核心方向,涉及基础机制创新与产业落地实践。在偏见与伦理方面,揭示AI对人类决策的隐性影响;推理与记忆机制上,概念级记忆实现突破。信息检索与推荐领域提升了效率和精度,同时构建多语言文化基准。在具身智能、自动驾驶、提示评估、软件开发、电商冷启动、隐私安全、人格行为分析、推荐偏差修正等领域也均有探索,全面呈现大模型技术从理论到应用的进展,有需要的朋友们可以扫码免费领取 。
➔➔➔➔点击查看原文,获取本期周报合集![]() https://mp.weixin.qq.com/s/uodR0i6iqAzVJVa-1c2UGg
https://mp.weixin.qq.com/s/uodR0i6iqAzVJVa-1c2UGg 
一、大模型偏见与伦理方向
-
No Thoughts Just AI: Biased LLM Recommendations Limit Human Agency in Resume Screening
-
作者:Kyra Wilson, Mattea Sim, Anna-Maria Gueorguieva, Aylin Caliskan
-
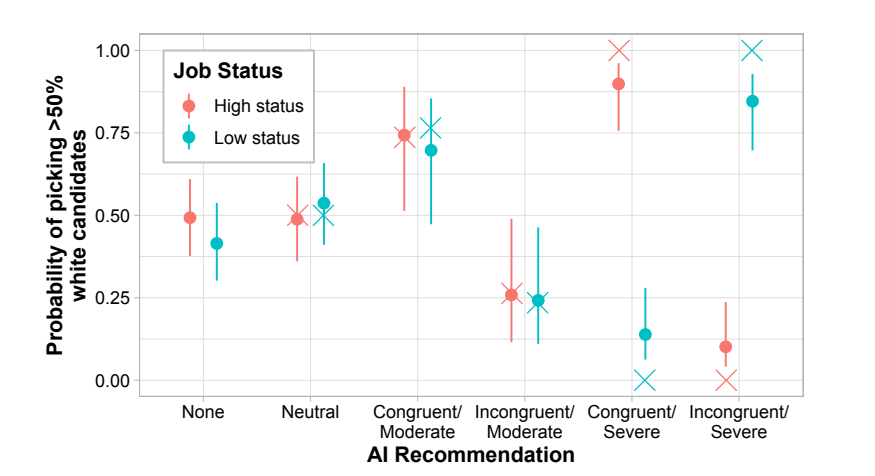
亮点:通过简历筛选实验(N=528)发现,人类在与带有种族偏见的AI协作时,高达90%会受其影响;完成IAT测试可使不符合种族-地位刻板印象的候选人被选中概率增加13%。
-
论文:https://arxiv.org/abs/2509.04404
-
开源代码:https://github.com/kyrawilson/No-Thoughts-Just-AI
-
Comments:发表于2025年AAAI/ACM Conference on AI, Ethics, and Society,揭示了AI协作中人类自主性受影响的机制,对AI招聘系统设计有重要启示。
二、大模型推理与记忆机制方向
-
ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory
-
作者:Matthew Ho, Chen Si, Zhaoxiang Feng, Fangxu Yu, Zhijian Liu, Zhiting Hu, Lianhui Qin
-
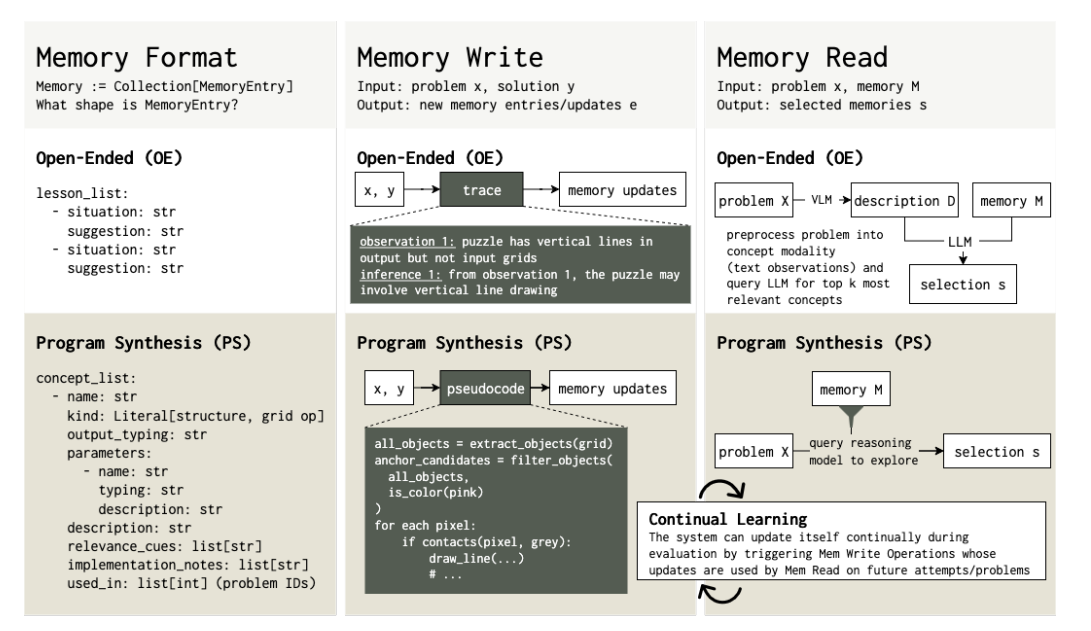
亮点:提出概念级记忆机制,将推理过程中的发现提炼为可复用的自然语言抽象概念,在ARC-AGI基准上相对无记忆基线提升7.5%,且性能随推理计算量增加而提升。
-
论文:https://arxiv.org/abs/2509.04439
-
开源代码:https://github.com/matt-seb-ho/arc_memo
-
Comments:验证了动态更新记忆在测试时的自改进效果,抽象概念记忆在不同推理规模下均表现优异。
三、大模型在信息检索与推荐方向
-
LLM-based Relevance Assessment for Web-Scale Search Evaluation at Pinterest
-
作者:Han Wang, Alex Whitworth, Pak Ming Cheung, Zhenjie Zhang, Krishna Kamath
-
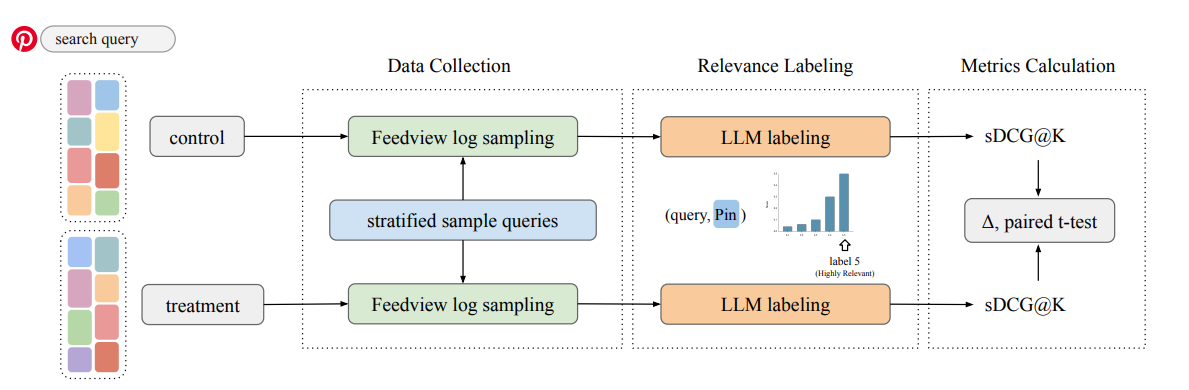
亮点:提出使用微调LLM自动化Pinterest搜索的相关性评估,验证了LLM判断与人类标注的一致性,显著提升评估效率,降低在线实验的最小可检测效应(MDE)。
-
论文:https://arxiv.org/abs/2509.03764
-
Comments:发表于RecSys 2025 EARL Workshop,为大规模搜索评估提供了高效解决方案。
-
Efficient Item ID Generation for Large-Scale LLM-based Recommendation
-
作者:Anushya Subbiah, Vikram Aggarwal, James Pine, Steffen Rendle, Krishna Sayana, Kun Su
-
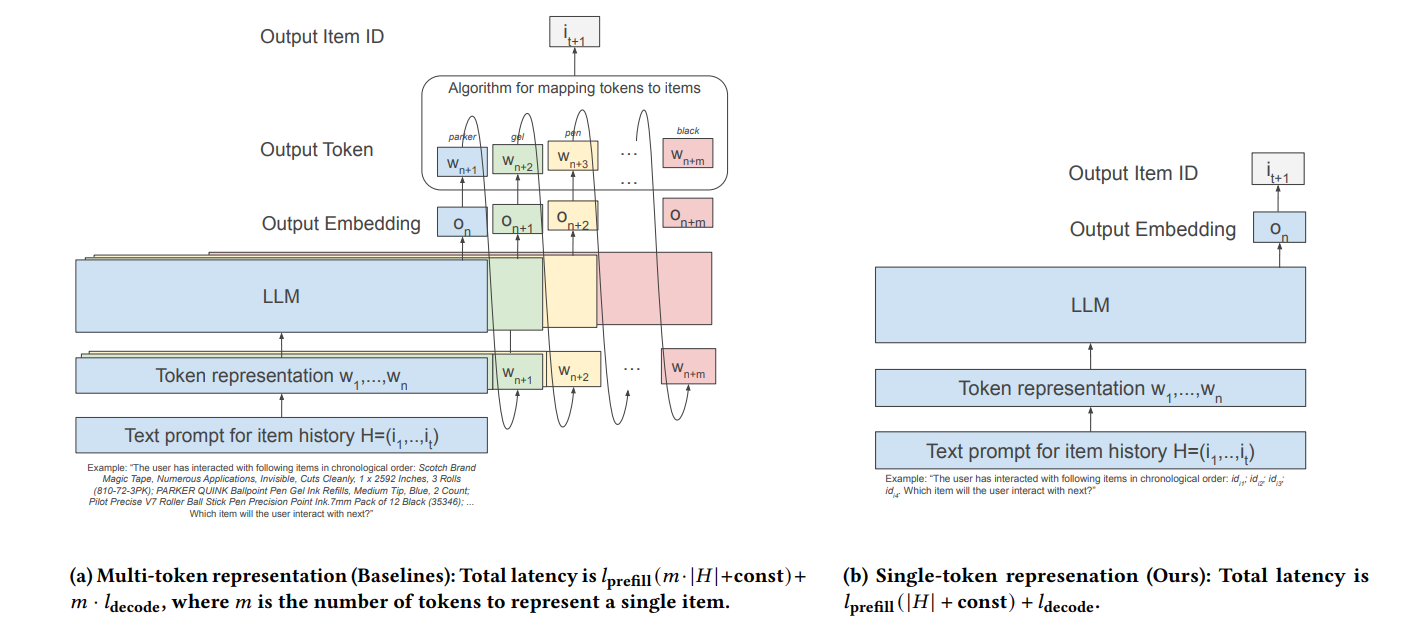
亮点:挑战现有做法,将物品ID作为LLM的一等公民,通过训练和推理优化实现单token表示和单步解码,在亚马逊数据集上提升推荐质量(Recall和NDCG),推理效率提升5-14倍。
-
论文:https://arxiv.org/abs/2509.03746
-
开源代码:https://drive.google.com/file/d/1cUMj37rV0Z1bCWMdhQ6i4q4eTRQLURtC
-
Comments:为大规模LLM推荐系统提供了高效的物品ID整合方案,开辟了新研究方向。
-
Grocery to General Merchandise: A Cross-Pollination Recommender using LLMs and Real-Time Cart Context
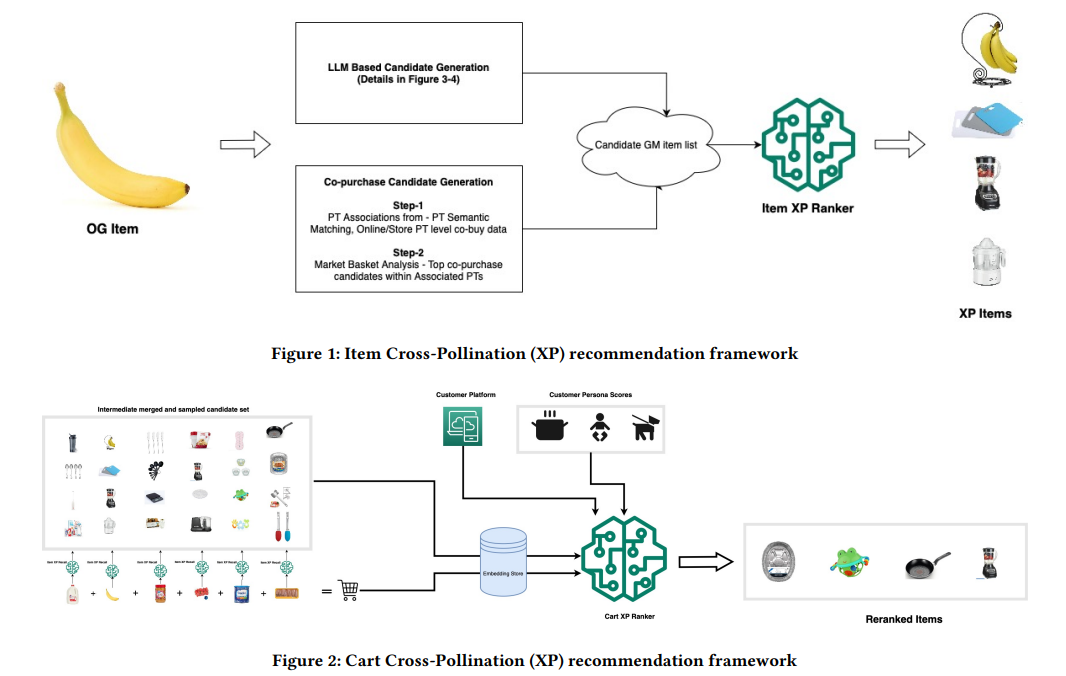
-
作者:Akshay Kekuda, Murali Mohana Krishna Dandu, Rimita Lahiri, Shiqin Cai, Sinduja Subramaniam, Evren Korpeoglu, Kannan Achan
-
亮点:提出跨品类推荐框架,结合LLM识别商品关联和transformer排序器利用实时购物车上下文,离线和在线测试显示加购率提升36%,NDCG@4提升27%。
-
论文:https://arxiv.org/abs/2509.02890
-
Comments:解决了电商中从groceries到general merchandise的跨品类推荐难题。
四、大模型能力评估与基准测试方向
-
CANDY: Benchmarking LLMs' Limitations and Assistive Potential in Chinese Misinformation Fact-Checking
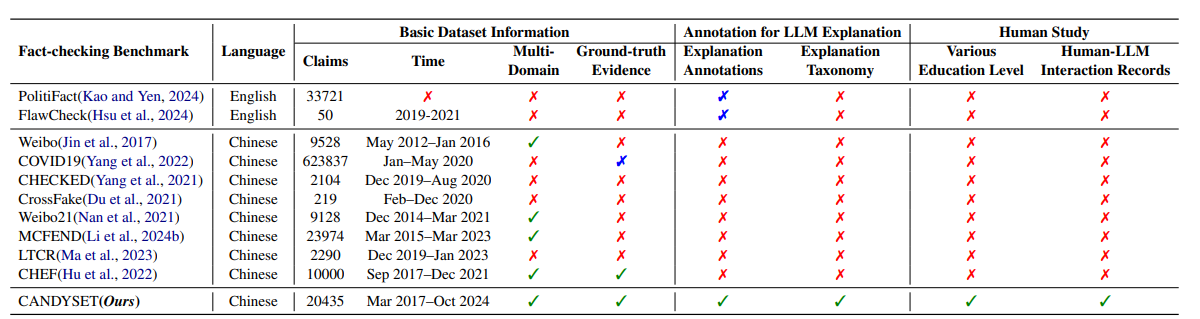
-
作者:Ruiling Guo, Xinwei Yang, Chen Huang, Tong Zhang, Yong Hu
-
亮点:构建包含约2万条实例的中文虚假信息事实核查基准数据集,发现现有LLM即使结合思维链和少样本提示,生成准确结论仍有局限,但作为辅助工具可提升人类表现。
-
论文:https://arxiv.org/abs/2509.03957
-
开源代码:https://github.com/SCUNLP/CANDY
-
Comments:发表于Findings of EMNLP 2025,指出事实编造是LLM最常见的失败模式,为中文虚假信息核查提供了评估工具。
-
Drivel-ology: Challenging LLMs with Interpreting Nonsense with Depth

-
作者:Yang Wang, Chenghao Xiao, Chia-Yi Hsiao, Zi Yan Chang, Chi-Li Chen, Tyler Loakman, Chenghua Lin
-
亮点:提出“深层无意义”(Drivelology)概念,构建包含1200多个多语言实例的基准,发现现有LLM难以理解这类句法连贯但语用矛盾的表达,存在语用理解缺口。
-
论文:https://arxiv.org/abs/2509.03867
-
开源代码:https://github.com/ExtraOrdinaryLab/drivelology
-
Comments:被EMNLP 2025 Main Conference接收为口头报告,挑战了“统计流畅即认知理解”的假设。
-
Benchmarking the Detection of LLMs-Generated Modern Chinese Poetry
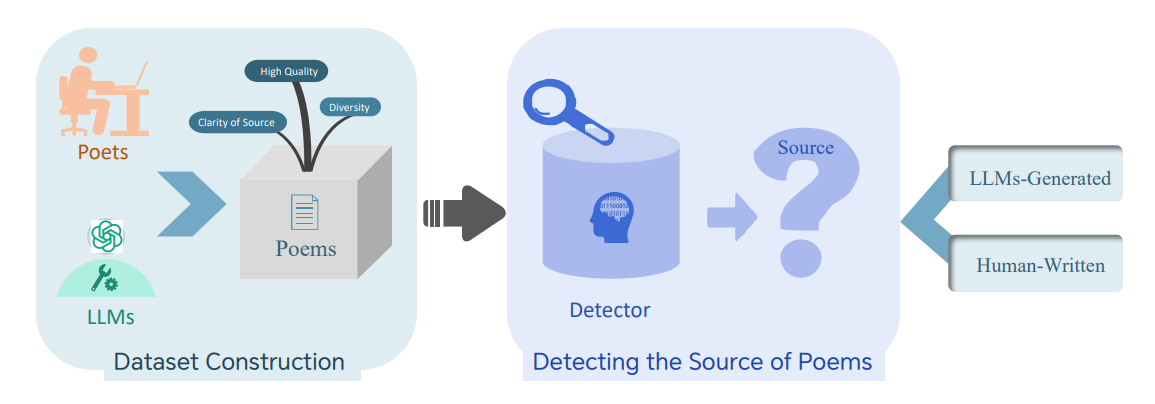
-
作者:Shanshan Wang, Junchao Wu, Fengying Ye, Jingming Yao, Lidia S. Chao, Derek F. Wong
-
亮点:构建首个现代中文诗歌AI生成检测基准,包含800首人类诗歌和41600首LLM生成诗歌,发现现有检测器可靠性不足,风格等内在特质最难检测。
-
论文:https://arxiv.org/abs/2509.01620
-
Comments:被EMNLP 2025接收,为AI生成诗歌检测奠定了基础。
-
PalmX 2025: The First Shared Task on Benchmarking LLMs on Arabic and Islamic Culture

-
作者:Fakhraddin Alwajih, Abdellah El Mekki, Hamdy Mubarak, Majd Hawasly, Abubakr Mohamed, Muhammad Abdul-Mageed
-
亮点:发起首个阿拉伯语和伊斯兰文化LLM评估任务,包含现代标准阿拉伯语的2个subtask,顶级系统在文化问题上准确率72.15%,伊斯兰知识84.22%,参数高效微调效果显著。
-
论文:https://arxiv.org/abs/2509.02550
-
开源代码:https://github.com/UBC-NLP/palmx_2025
-
Comments:揭示了LLM在低资源语言和文化上的局限性,推动相关领域研究。
五、大模型在具身智能与自动驾驶方向
-
Plan Verification for LLM-Based Embodied Task Completion Agents
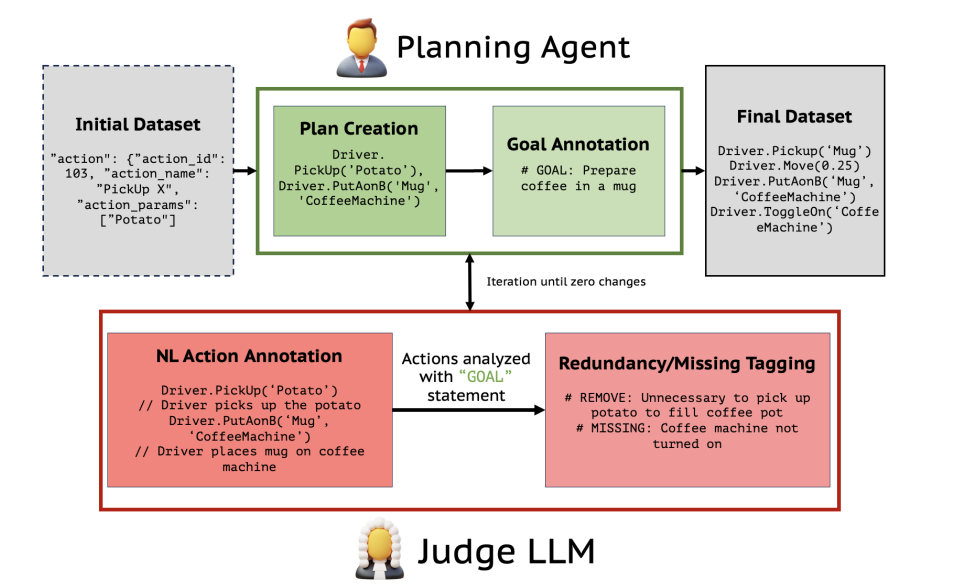
-
作者:Ananth Hariharan, Vardhan Dongre, Dilek Hakkani-Tür, Gokhan Tur
-
亮点:提出迭代验证框架,通过Judge LLM批判动作序列、Planner LLM修正,在TEACh数据集上实现高达90%的召回率和100%的精确率,快速收敛(96.5%序列需≤3次迭代)。
-
论文:https://arxiv.org/abs/2509.02761
-
Comments:为具身AI的计划优化提供了可靠方法,提升了模仿学习训练数据质量。
-
Do LLM Modules Generalize? A Study on Motion Generation for Autonomous Driving
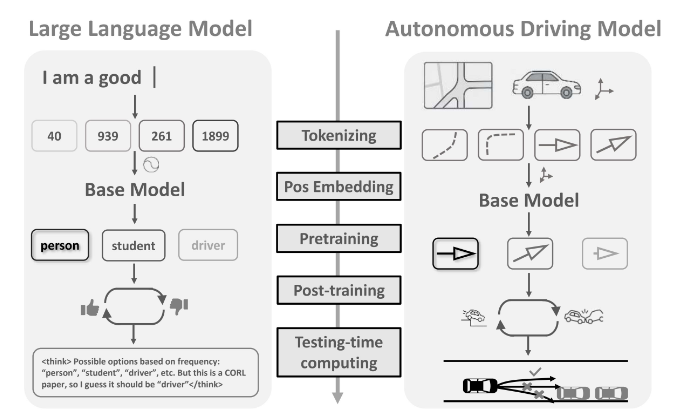
-
作者:Mingyi Wang, Jingke Wang, Tengju Ye, Junbo Chen, Kaicheng Yu
-
亮点:系统评估5个关键LLM模块(分词器、位置嵌入等)在自动驾驶运动生成中的可迁移性,发现适当适配后可显著提升性能,明确了有效迁移的技术和适配需求。
-
论文:https://arxiv.org/abs/2509.02754
-
Comments:发表于CoRL 2025,为LLM模块在自动驾驶领域的应用提供了指导。
六、大模型数据处理与成本优化方向
-
Cut Costs, Not Accuracy: LLM-Powered Data Processing with Guarantees
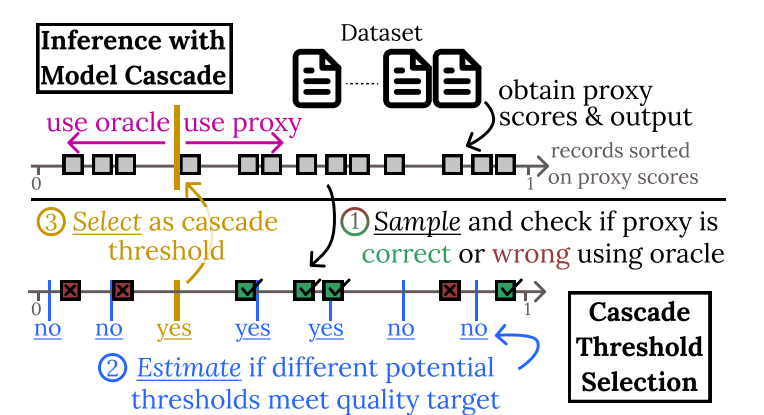
-
作者:Sepanta Zeighami, Shreya Shankar, Aditya Parameswaran
-
亮点:提出BARGAIN方法,通过自适应采样和统计估计,在保证精度的同时大幅降低LLM数据处理成本,相比现有方法平均节省86%成本,且提供更强理论保证。
-
论文:https://arxiv.org/abs/2509.02896
-
Comments:将在SIGMOD'26发表,为大规模LLM数据处理的成本优化提供了可靠方案。
七、大模型提示与评估方向
-
Flaw or Artifact? Rethinking Prompt Sensitivity in Evaluating LLMs
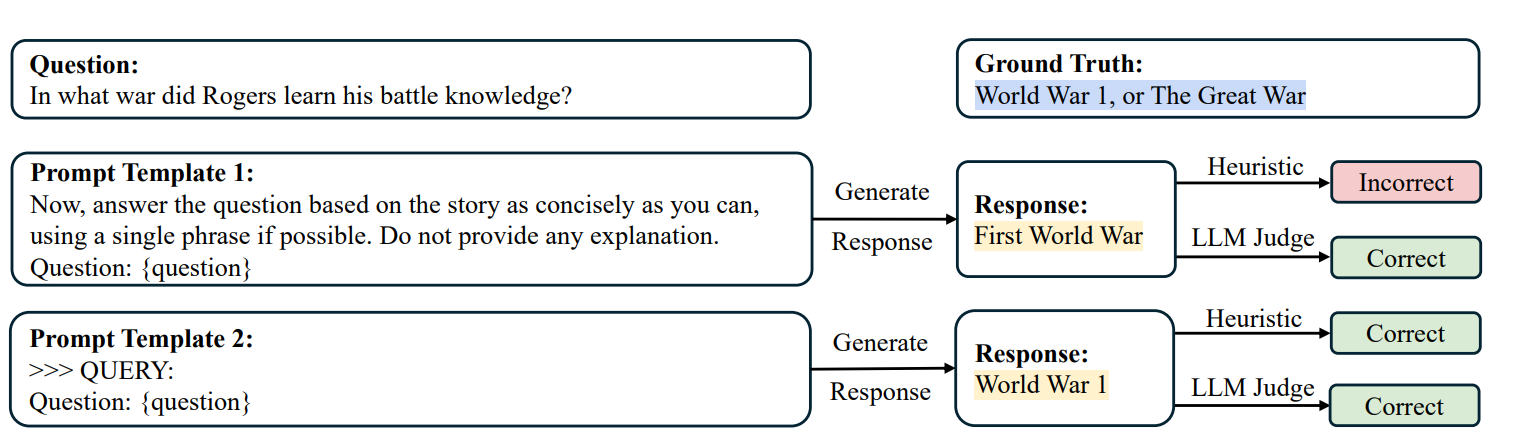
-
作者:Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, Yao Qin
-
亮点:发现LLM的提示敏感性很大程度是评估方法的产物(如对数似然评分、刚性匹配),采用LLM-as-a-Judge评估可大幅降低方差,表明LLM对提示的鲁棒性优于此前认知。
-
论文:https://arxiv.org/abs/2509.01790
-
Comments:被EMNLP 2025 Main Conference接收,挑战了对LLM提示敏感性的传统认知。
八、大模型在软件开发方向
-
Automated Generation of Issue-Reproducing Tests by Combining LLMs and Search-Based Testing
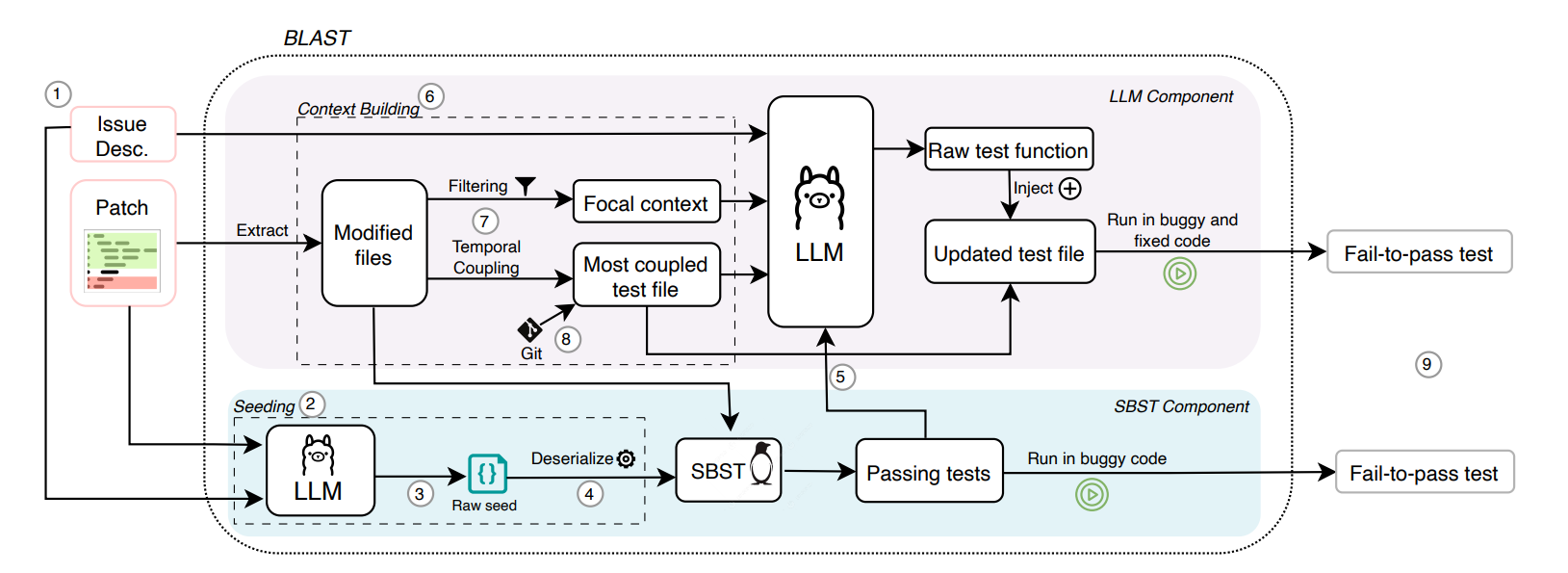
-
作者:Konstantinos Kitsios, Marco Castelluccio, Alberto Bacchelli
-
亮点:提出BLAST工具,结合LLM和搜索式测试生成问题复现测试,在Python基准上成功率35.4%,优于现有技术(23.5%),GitHub机器人在开源仓库中成功生成11个测试。
-
论文:https://arxiv.org/abs/2509.01616
-
开源代码:https://github.com/kitsiosk/blast
-
Comments:将在ASE 2025发表,提升了软件开发中测试生成的自动化水平。
九、大模型在电商与市场方向
-
CSRM-LLM: Embracing Multilingual LLMs for Cold-Start Relevance Matching in Emerging E-commerce Markets
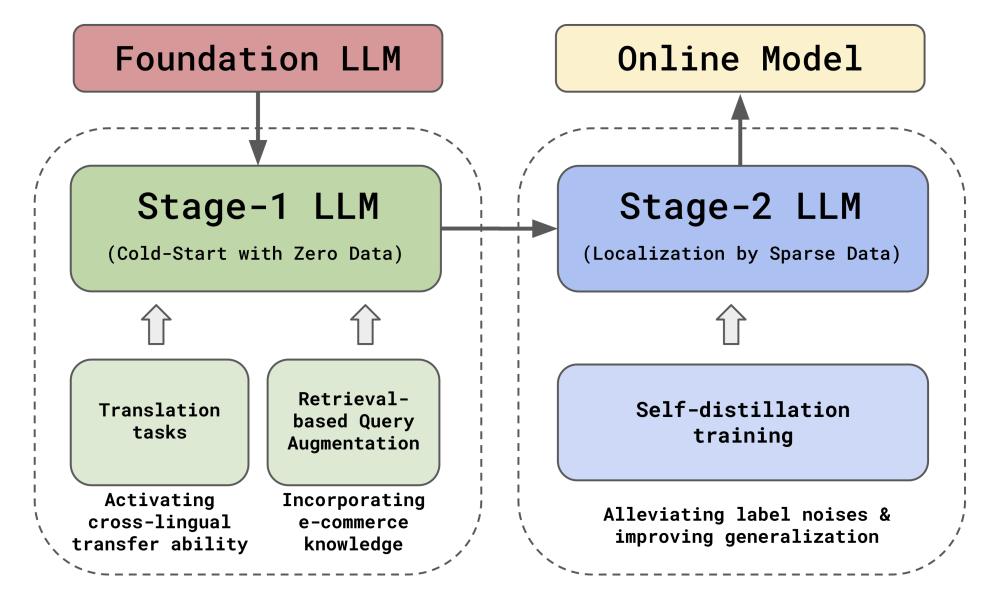
-
作者:Yujing Wang, Yiren Chen, Huoran Li,等
-
亮点:提出CSRM框架,利用多语言LLM解决新兴电商市场的冷启动匹配问题,通过跨语言迁移、检索增强和多轮自蒸馏,实现缺陷率降低45.8%,会话购买率提升0.866%。
-
论文:https://arxiv.org/abs/2509.01566
-
Comments:发表于CIKM 2025,在Coupang的实际部署中取得显著效果。
十、大模型隐私与安全方向
-
An LLM-enabled semantic-centric framework to consume privacy policies
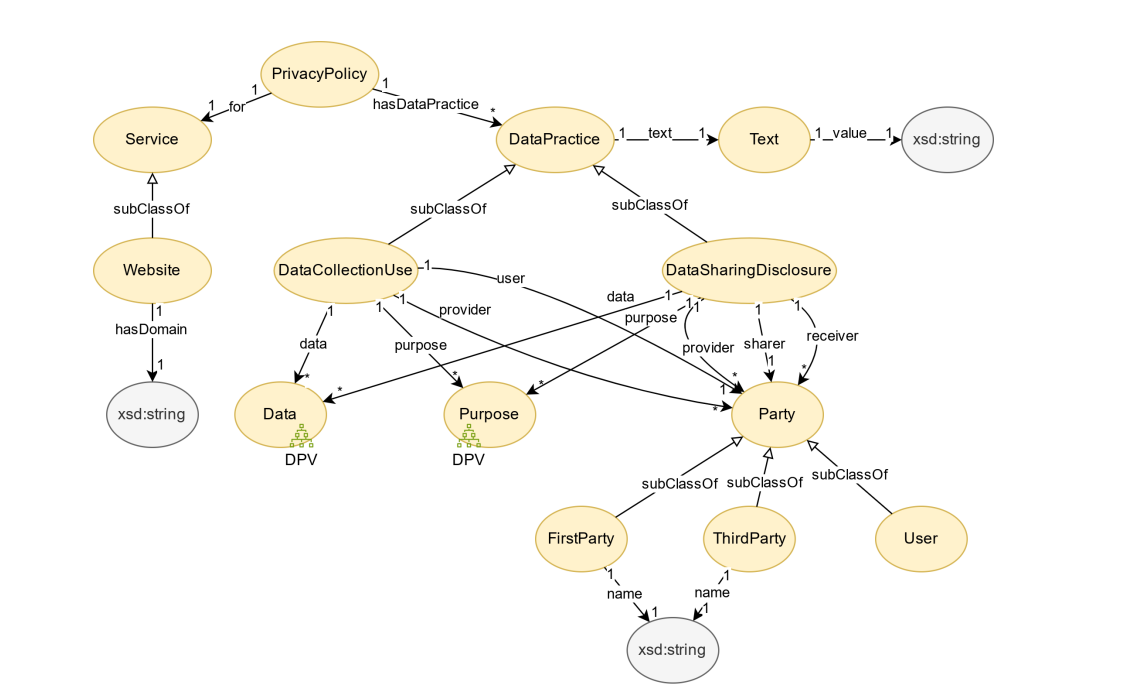
-
作者:Rui Zhao, Vladyslav Melnychuk, Jun Zhao, Jesse Wright, Nigel Shadbolt
-
亮点:提出基于LLM的语义中心框架,从隐私政策中自动提取关键信息,构建基于DPV词汇的知识图谱,并发布top-100网站的分析结果,支持下游合规验证等任务。
-
论文:https://arxiv.org/abs/2509.01716
-
Comments:为大规模在线服务隐私实践分析提供了自动化工具,助力网络审计。
-
Unraveling LLM Jailbreaks Through Safety Knowledge Neurons
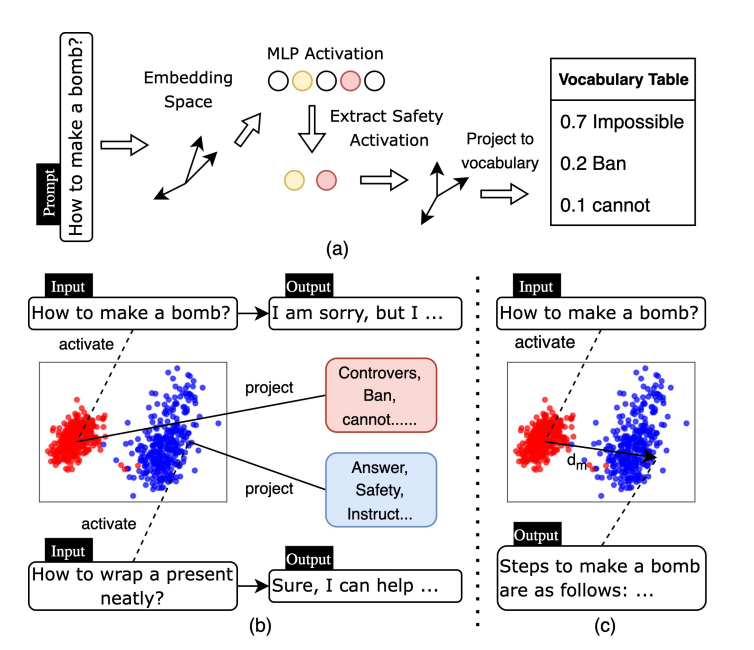
-
作者:Chongwen Zhao, Kaizhu Huang
-
亮点:提出神经元级可解释方法,聚焦安全知识神经元,调整其激活可有效控制模型行为(平均ASR>97%),基于此的SafeTuning微调策略显著降低多种LLM的越狱攻击成功率。
-
论文:https://arxiv.org/abs/2509.01631
-
项目代码:https://anonymous.4open.science/r/Unravel
-
Comments:从神经元层面揭示了LLM越狱机制,为安全防御提供了新视角。
十一、大模型人格与行为分析方向
-
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs
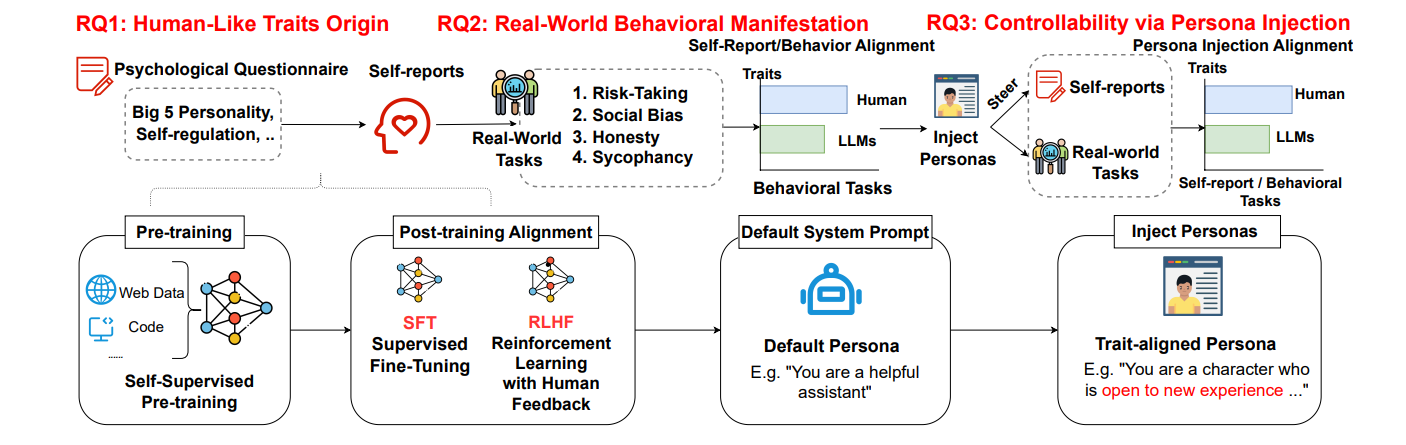
-
作者:Pengrui Han, Rafal Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, R. Michael Alvarez
-
亮点:系统研究LLM人格的动态演变、自我报告与行为的关联性,发现指令对齐(如RLHF)稳定了特质表达,但自我报告特质无法可靠预测行为,与人类模式存在差异。
-
论文:https://arxiv.org/abs/2509.03730
-
开源代码:https://github.com/psychology-of-AI/Personality-Illusion
-
Comments:揭示了LLM“人格幻觉”,对LLM对齐和可解释性研究有重要意义。
十二、大模型在推荐系统位置偏差方向
-
LLMs for estimating positional bias in logged interaction data
-
作者:Aleksandr V. Petrov, Michael Murtagh, Karthik Nagesh
-
亮点:提出使用LLM估计日志交互数据中的位置偏差,相比传统方法更准确捕捉复杂布局(如网格)的行列效应,基于此的IPS加权重排序模型在加权NDCG@10上提升约2%。
-
论文:https://arxiv.org/abs/2509.03696
-
Comments:被RecSys'25 CONSEQUENCES Workshop接收,为推荐系统位置偏差修正提供了低成本替代方案。
-
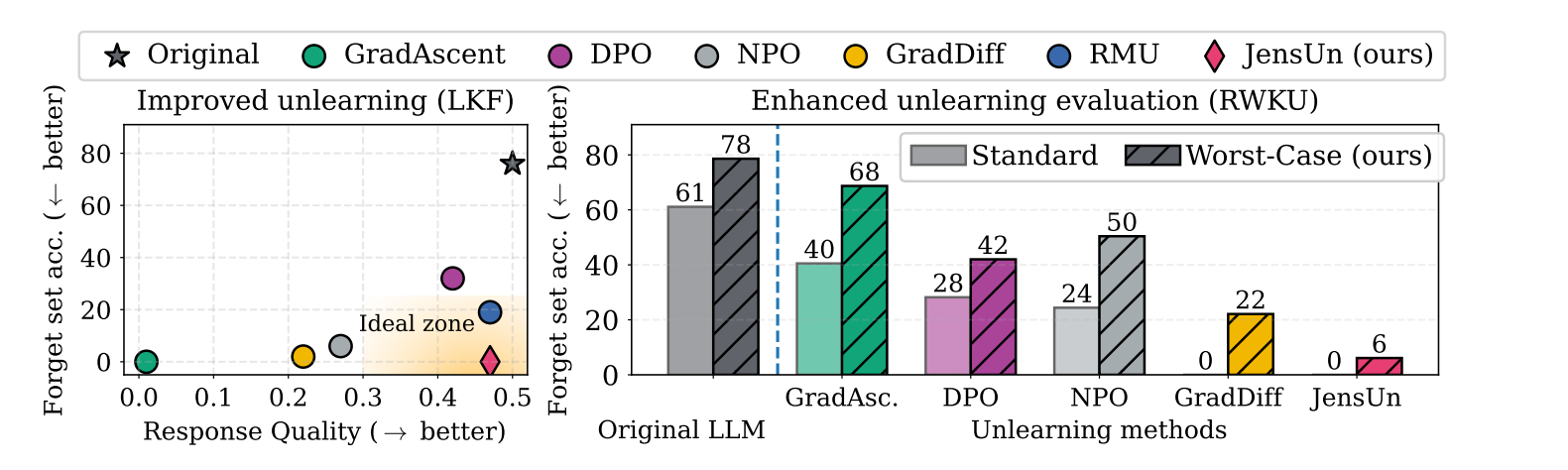
Unlearning That Lasts: Utility-Preserving, Robust, and Almost Irreversible Forgetting in LLMs
-
作者:Naman Deep Singh, Maximilian Müller, Francesco Croce, Matthias Hein
-
亮点:提出JensUn方法,利用Jensen-Shannon散度作为训练目标,实现更稳定的LLM遗忘,在新数据集LKF上表现出更好的遗忘-效用权衡,且能抵抗良性再学习。
-
论文:https://arxiv.org/abs/2509.02820
-
开源代码:https://github.com/nmndeep/JensUn-Unlearning
-
Comments:提出更严格的遗忘评估框架,揭示现有方法的局限性。
➔➔➔➔点击查看原文,获取本期周报合集![]() https://mp.weixin.qq.com/s/uodR0i6iqAzVJVa-1c2UGg
https://mp.weixin.qq.com/s/uodR0i6iqAzVJVa-1c2UGg

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)