transformers 的 metric_for_best_model 设置 eval_f1 作为评估标准
基于HuggingFace Transformers库的模型训练实现,讨论了最佳模型的选择问题。作者展示了一个通用训练流程代码,使用Trainer类进行模型训练,并支持从检查点恢复训练。针对评估指标选择问题,作者发现默认使用eval_loss选择最佳模型可能不理想,应改用eval_f1等任务相关指标。通过修改trainer_state.json文件中的best_global_step,可以手动指定
文章目录
Trainer 的代码实现
下述是我写的模型训练的代码,算是比较通用的使用 transformers.Trainer 训练模型的代码实现流程。
import logging
import os
from transformers import AutoTokenizer
from transformers import HfArgumentParser, TrainingArguments, Trainer
from transformers.trainer_utils import get_last_checkpoint
from ..abc.arguments import AbsDataArguments, AbsModelArguments
from .data import IndustryDataset, IndustryDataCollator
from .model import IndustryRulerModel, compute_metrics
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def main():
parser = HfArgumentParser((AbsDataArguments, AbsModelArguments, TrainingArguments))
data_args, model_args, training_args = parser.parse_args_into_dataclasses()
model_args: AbsModelArguments
data_args: AbsDataArguments
training_args: TrainingArguments
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path)
train_dataset = IndustryDataset(args=data_args, is_train=True)
eval_dataset = IndustryDataset(args=data_args, is_train=False)
print(train_dataset[0])
print(f"train on {len(train_dataset)} samples, eval on {len(eval_dataset)} samples")
model = IndustryRulerModel(
model_args=model_args,
)
if "qwen" in model_args.model_name_or_path.lower():
model.model.config.pad_token_id = tokenizer.pad_token_id
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=IndustryDataCollator(data_args=data_args, tokenizer=tokenizer),
compute_metrics=compute_metrics,
)
# 检查输出文件夹中是否有 checkpoint,若有继续训练
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is not None:
logging.info(f"⚡ Found checkpoint at {last_checkpoint}. Resuming training.")
else:
logging.warning("❌ No checkpoint found. Starting fresh training.")
else:
logging.info("➡️ No previous output_dir or overwrite_output_dir=True, starting from scratch.")
trainer.train(resume_from_checkpoint=last_checkpoint if last_checkpoint else None)
save_model_dir = os.path.join(training_args.output_dir, "best_model")
tokenizer.save_pretrained(save_model_dir)
model.model.save_pretrained(save_model_dir)
if __name__ == "__main__":
main()
加载最佳模型
bert_pure \
--dataset_dir ../data/bert_dataset \
--model_name_or_path $model_name_or_path \
--fp16 \
--num_labels 1009 \
--output_dir $output_dir \
--num_train_epochs $epoch \
--save_strategy steps \
--save_steps $steps_nums \
--eval_strategy steps \
--eval_steps $steps_nums \
--eval_on_start \
--save_total_limit 3 \
--learning_rate 2e-5 \
--weight_decay 0.1 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--logging_steps 10 \
--logging_first_step \
--logging_dir $output_dir/logs \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--warmup_ratio 0.08 \
--save_safetensors \
--overwrite_output_dir False \
--dataloader_num_workers 0 \
--remove_unused_columns False \
--load_best_model_at_end True \
--report_to tensorboard
我使用了 load_best_model_at_end 参数,默认保留最小的测试集评估结果eval_loss最小的那个checkpoint作为best_model。
我发现,loss最小的checkpoint并不总是最好的。我当前训练的这个模型是文本分类模型,评估标准应该设置为eval_f1。评估的这些指标在compute_metrics里面进行定义。
我删除了best_model模型,重新启动训练,这样模型就会生成新的best_model模型。
--metric_for_best_model eval_f1 \
--greater_is_better True \
在训练的脚本中,我设置了上述参数,要求选择eval_f1最大的checkpoint模型作为最佳模型。
checkpoint没有删除,不会从头开始训练模型,我的想法就是重新训练后,会自动生成一个新的best_model。但是事与愿违,即便我设置了--metric_for_best_model eval_f1 ,生成的best_model还是以前的,eval_f1的设置没有生效。
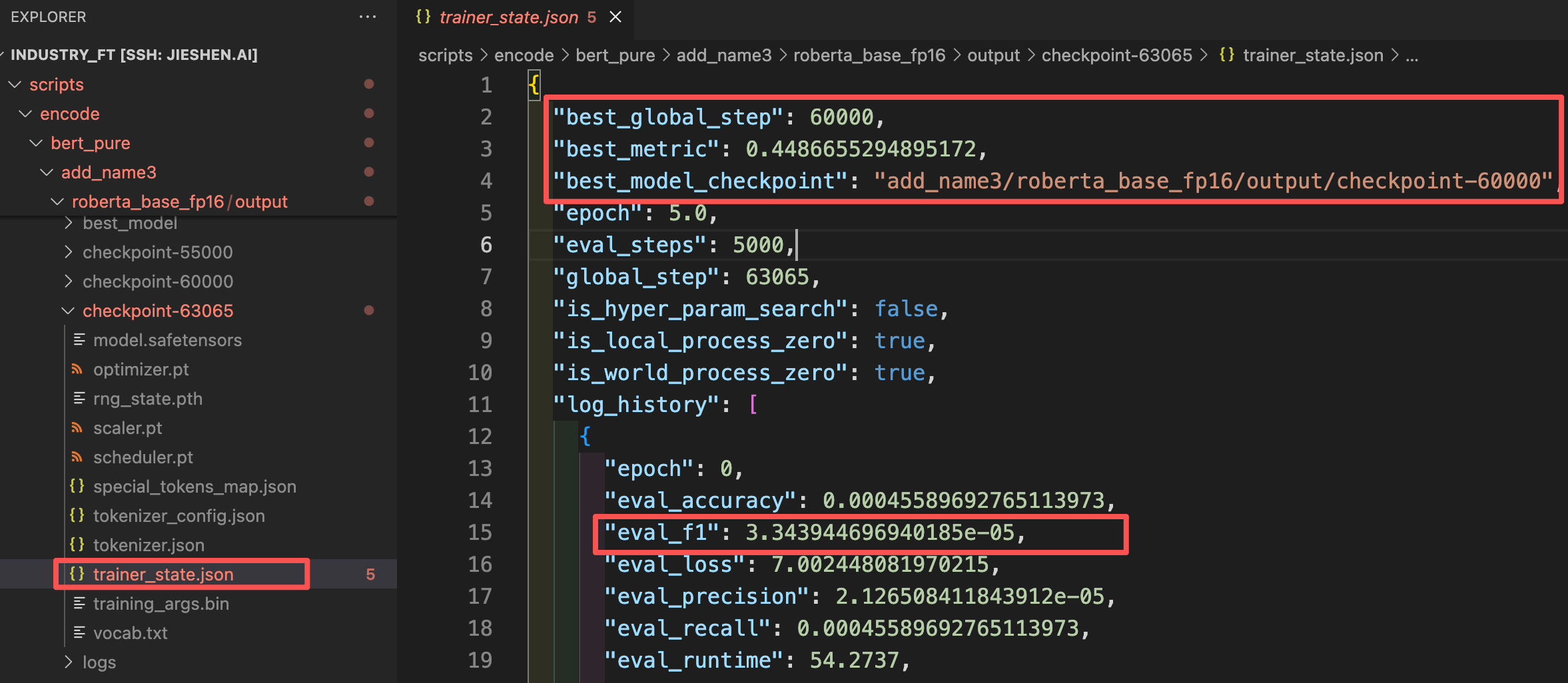
在checkpoint文件夹里面有一个 trainer_state.json 文件,其中best_gobal_step就是当前表现最佳的step数,我们可以找log_history列表里面找到eval_f1最大的那个checkpoint,并修改best_model_checkpoint。
这样在更改了metric_for_best_model最佳模型的评估指标后,也无需重复训练模型。
补充说明
我使用的是fp16混合精度训练的模型,checkpoint文件夹中保存的模型无法直接使用。发现只有best_model模型可以使用。所以很自然地就需要把checkpoint模型转成为best_model模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)