(论文速读)MVPortrait:文本驱动的多视角生动肖像动画技术
《MVPortrait:文本引导的多视图生动肖像动画》提出了一种创新性两阶段框架,通过FLAME 3D面部模型作为中间表示,实现文本驱动的多视角肖像动画生成。该系统采用解耦设计,分别训练运动和情感扩散模型,再通过多视图视频生成模型输出动画。实验表明,该方法在文本对齐、情感表达和多视角一致性上优于现有技术,且兼容文本、语音和视频多种驱动方式。该技术为虚拟主播、影视制作等领域提供了新的解决方案,代表了
论文题目:MVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation(文本引导运动和情感控制的多视图生动的肖像动画)
会议:CVPR2025
摘要:最近的肖像动画方法在产生逼真的嘴唇同步方面取得了重大进展。然而,他们往往缺乏对头部运动和面部表情的明确控制,并且无法从多个视点制作视频,导致动画的可控性和表现力较差。此外,文本引导的肖像动画仍未得到充分开发,尽管它具有用户友好的性质。我们提出了一种新的两阶段文本引导框架,MVPortrait(多视图生动肖像),以生成富有表现力的多视图肖像动画,忠实地捕捉所描述的动作和情感。MVPortrait是第一个引入FLAME作为中间表示的,有效地在其参数空间内嵌入面部运动、表情和视图转换。在第一阶段,我们分别训练基于文本输入的FLAME运动和情绪扩散模型。在第二阶段,我们训练了一个基于参考肖像图像和第一阶段的多视图flame渲染序列的多视图视频生成模型。实验结果表明,MVPortrait在运动和情绪控制以及视图一致性方面优于现有方法。此外,通过利用FLAME作为桥梁,MVPortrait成为第一个可控的肖像动画框架,兼容文本,语音和视频作为驱动信号。
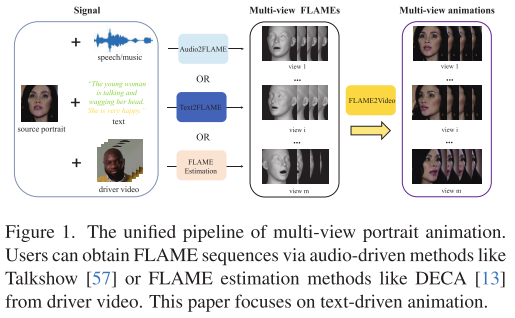
引言
在数字人动画领域,如何从一张静态照片生成生动、可控的动态肖像一直是研究热点。传统方法往往只能处理单一视角或缺乏精细控制,而最新发表在CVPR 2025的论文《MVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation》提出了一个突破性的解决方案。
现有技术的局限性
三大核心问题
当前肖像动画技术面临着三个主要挑战:
1. 控制能力不足 现有方法虽然在唇部同步方面取得了显著进展,但在头部运动和面部表情的精确控制方面仍有不足。大多数系统只能处理音频驱动的说话动画,缺乏对复杂情感表达的细粒度控制。
2. 视角局限性 传统方法通常只能生成单一视角的动画,无法提供多角度的观察体验。这限制了应用场景,特别是在需要沉浸式体验的VR/AR环境中。
3. 文本交互缺失 尽管文本是最直观、用户友好的交互方式,但文本驱动的肖像动画技术仍处于起步阶段,缺乏成熟的解决方案。
MVPortrait的技术创新
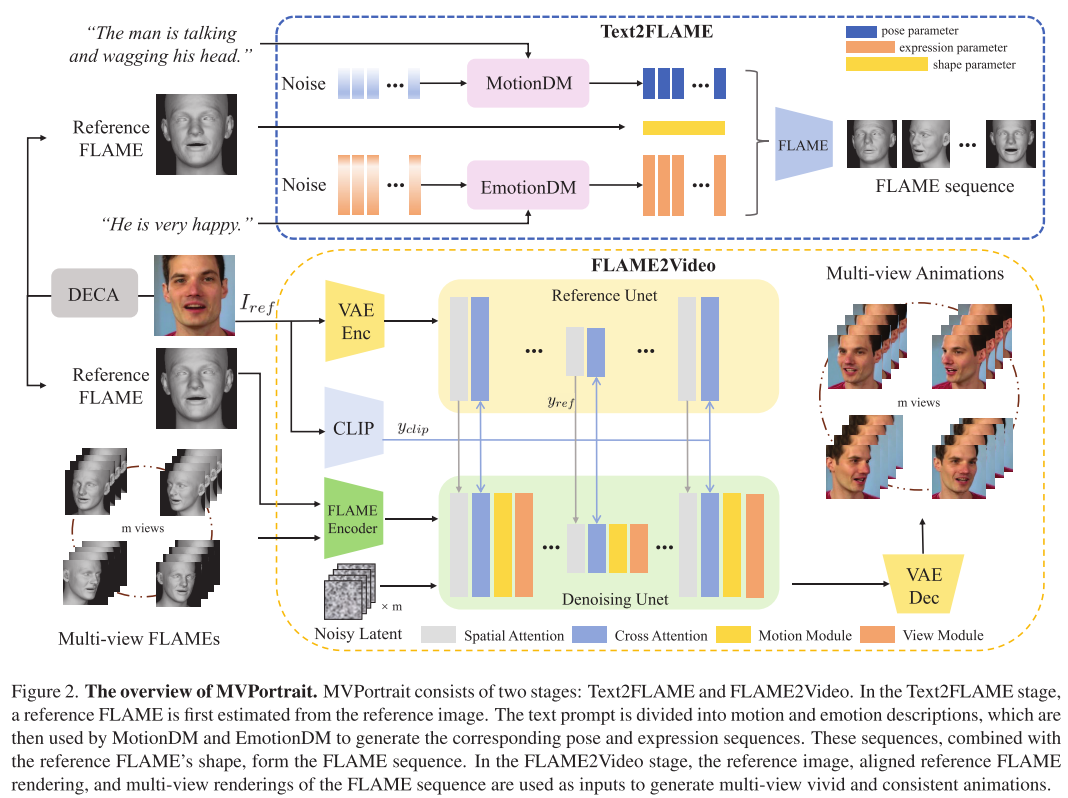
核心架构:FLAME驱动的两阶段框架
MVPortrait的最大创新在于引入了FLAME(Faces Learned with an Articulated Model and Expressions)3D面部模型作为中间表示。FLAME是一个参数化的3D头部模型,能够紧凑地表示面部形状、姿态和表情。
阶段一:Text2FLAME
这一阶段的目标是将文本描述转换为FLAME参数序列。系统采用了解耦设计:
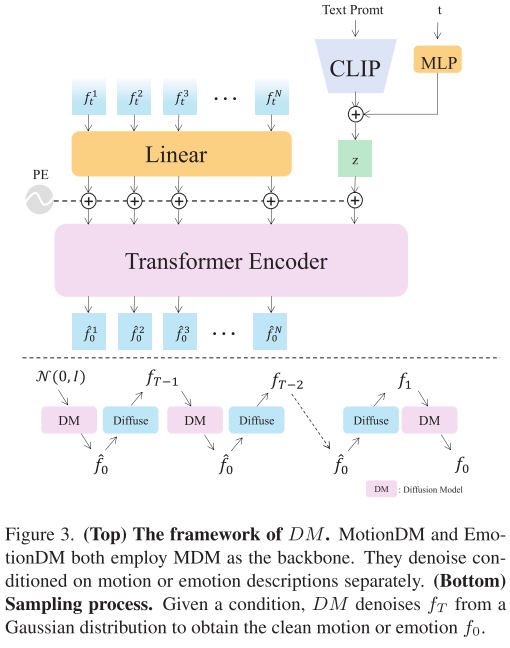
- MotionDM(运动扩散模型):专门处理文本中的运动描述,如"摇头"、"点头"等,输出头部姿态参数
- EmotionDM(情感扩散模型):专门处理情感描述,如"高兴"、"惊讶"等,输出面部表情参数
两个模型都基于Transformer架构的扩散模型实现,采用DDPM框架进行训练。为了减少生成结果的抖动,系统还引入了速度几何损失和滑动窗口平滑技术。
阶段二:FLAME2Video
在获得FLAME参数序列后,系统通过渲染生成多视角的FLAME图像,然后使用这些图像作为条件来生成最终的多视角动画视频。
关键组件包括:
- FLAME编码器:提取FLAME渲染图像中的姿态和表情信息
- 参考UNet:保持参考图像的外观特征
- 去噪UNet:结合多种条件生成最终视频
- 视角模块:确保多视角间的一致性
技术优势
1. 统一的多模态支持 通过FLAME作为中间表示,系统不仅支持文本驱动,还兼容音频和视频驱动,实现了真正的多模态统一框架。
2. 精细化控制 分离的运动和情感控制使得系统能够独立调节头部动作和面部表情,提供更精细的控制能力。
3. 多视角一致性 专门设计的视角注意机制确保生成的多视角动画在身份和动作上保持一致。
实验评估与结果
数据集
研究团队基于CelebV-Text数据集构建了CelebV-TF数据集,包含超过15k个文本-FLAME对。同时使用RenderMe-360数据集的子集进行多视角动画训练。
评估指标
系统采用了多维度的评估体系:
- 视频质量:FID、LIQE等指标评估生成视频的视觉质量
- 时间一致性:FVD评估视频的时间连贯性
- 文本对齐:CLIPSIM、VideoClip评估生成内容与文本描述的匹配度
- 主观评价:用户研究评估运动一致性(MC)、情感一致性(EC)和生动性(VS)
实验结果

MVPortrait在多个关键指标上显著优于现有方法:
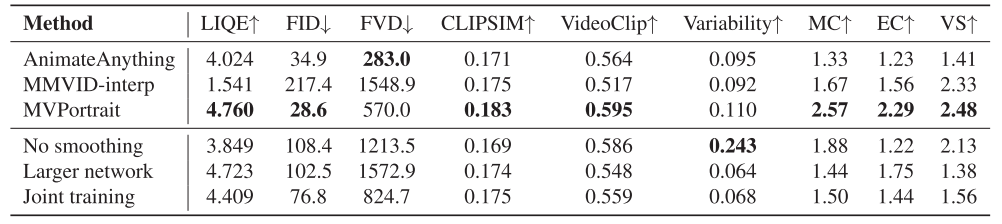
- 文本对齐能力:在CLIPSIM(0.183)和VideoClip(0.595)指标上均为最佳
- 动态表现:Variability指标(0.110)表明生成的动画更加动态和丰富
- 主观评价:在MC(2.57)、EC(2.29)、VS(2.48)三个维度都获得最高分
- 多视角一致性:SSIM(0.6224)和ID(0.8409)指标证明了优秀的多视角一致性
技术细节与实现
网络架构
扩散模型设计:采用单层Transformer编码器,潜在维度为64,使用余弦噪声调度和1000步扩散过程。
训练策略:采用三阶段训练:
- 训练FLAME编码器、参考UNet和去噪UNet的2D组件
- 独立训练运动模块
- 独立训练视角模块
性能优化
- 速度:Text2FLAME平均0.04s/帧,FLAME2Video平均0.45s/帧
- 显存需求:Text2FLAME需要2GB,FLAME2Video需要14GB显存
- 训练时间:两阶段分别需要约16小时和5天(8×A100 GPU)
局限性与未来发展
当前局限
- 数据依赖:系统性能受限于视频数据集中文本标注的准确性
- 表情分布:面部运动和情感在数据中的分布不均匀
- 微表情捕获:FLAME模型在捕获细微表情方面仍有局限
发展方向
未来研究将重点关注:
- 设计更细粒度的表情控制框架
- 提高系统的泛化能力
- 探索实时生成的可能性
- 集成更多模态的输入信号
应用前景
MVPortrait技术在多个领域具有广阔的应用前景:
- 虚拟主播:基于文本脚本生成多角度的主播动画
- 影视制作:快速生成角色的多视角表演动画
- 教育培训:创建交互式的虚拟教师系统
- 游戏开发:实时生成NPC的对话动画
- 社交媒体:个性化的头像动画生成
结论
MVPortrait代表了肖像动画技术的重要突破,通过创新的FLAME中间表示和两阶段生成框架,实现了文本驱动的多视角生动肖像动画。系统不仅在技术指标上表现优异,更重要的是为用户提供了直观、便捷的交互方式。
随着技术的不断发展和完善,我们有理由相信,MVPortrait将为数字人动画领域带来新的发展机遇,推动虚拟内容创作进入一个新的时代。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)