AI试衣间实现360度全身自由!SpreeAI带来VirtualFittingRoom:让自拍秒变沉浸式换装秀
【摘要】VFR框架突破性地实现了从单张图片生成任意时长(720×1152分辨率,24FPS)的高质量虚拟试衣视频,解决了现有技术局限于静态图像或超短视频的痛点。该研究通过自回归分段生成策略,结合"锚视频"全局引导和"前缀条件"局部优化,在保持3D一致性的同时,创新性地实现了分钟级视频的平滑过渡与时间连贯性。实验表明,该方法在四个评估维度(服装/人体一致性、手

文章链接:https://arxiv.org/pdf/2509.04450
项目链接:https://immortalco.github.io/VirtualFittingRoom/
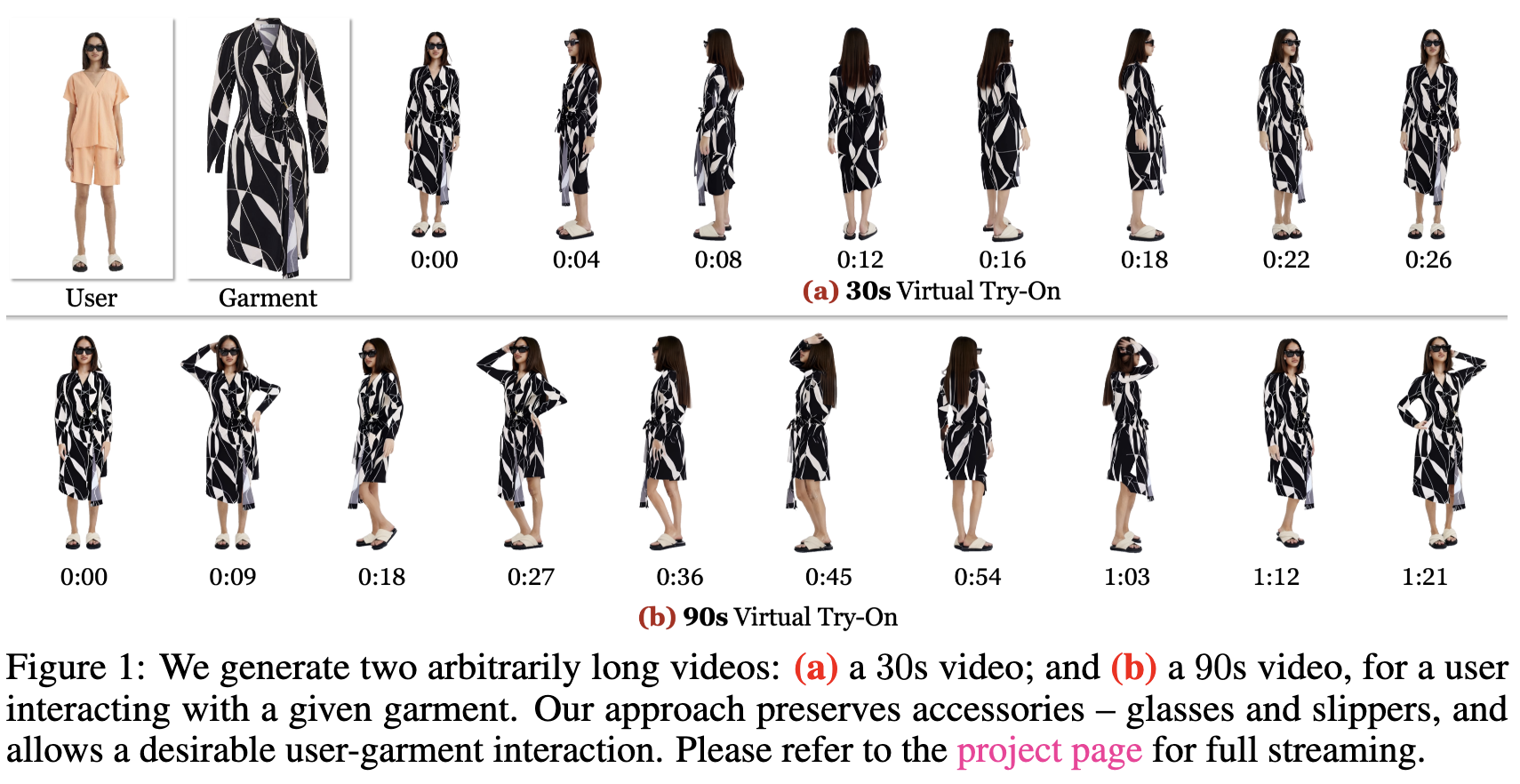
生成两段任意长度的视频片段
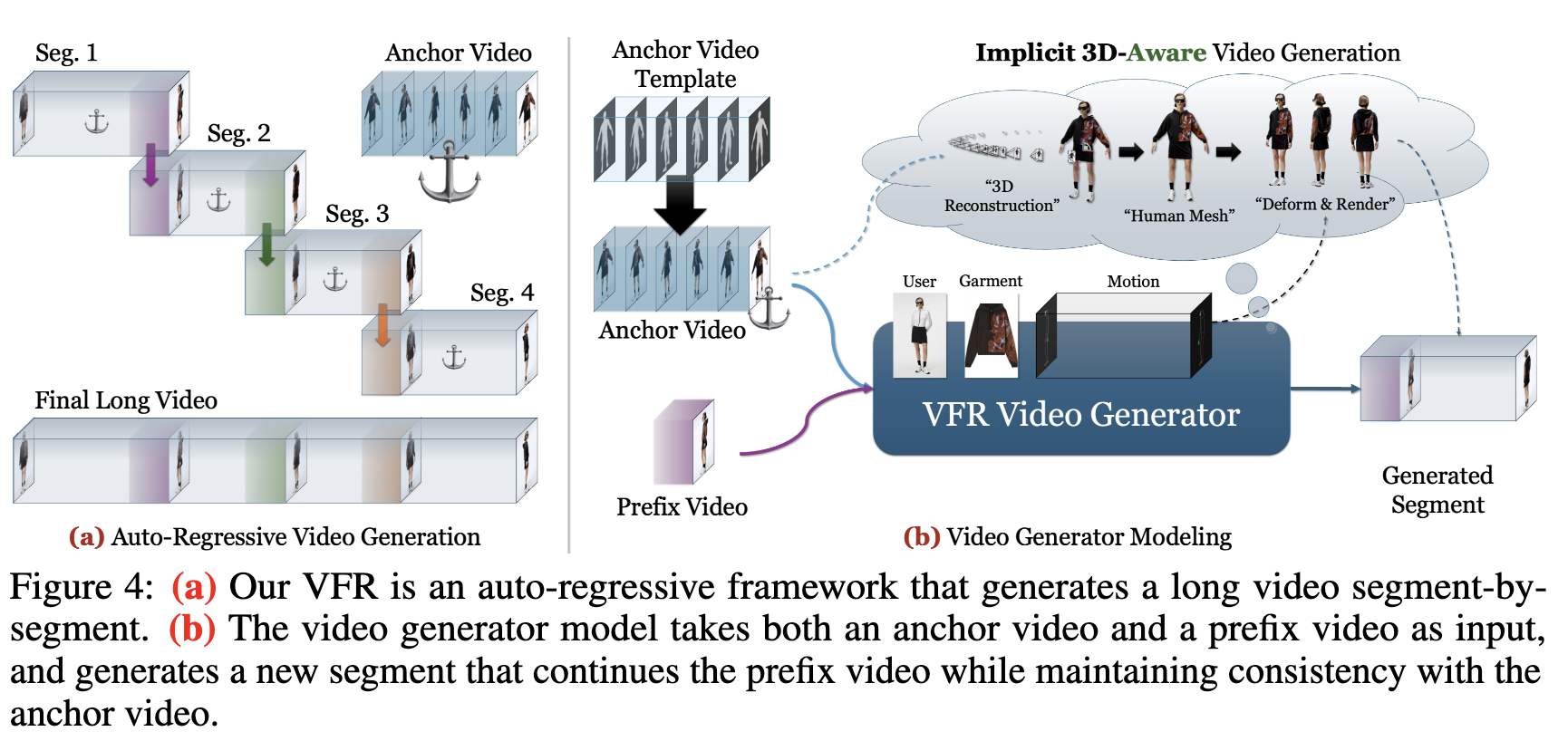
VFR框架
亮点直击
VFR,一种从单个图像生成长达任意长度、高分辨率(720 × 1152分辨率,24FPS)的虚拟试衣人物视频的方法。据我们所知,以前的工作没有展示过这些结果。
引入了一种评估协议,用于评估虚拟试衣方法的整体质量。
所提出的方法隐式地学习了3D一致性,能够进行自由视角渲染。
总结速览
解决的问题
-
现有虚拟试衣技术的局限性:
-
当前的虚拟试衣技术大多局限于静态图像或极短(5~10秒)的视频,这限制了用户对服装的全面体验。
-
生成长视频需要巨大的计算资源和大量的长时间视频数据。
-
-
长视频生成的挑战:
-
需要确保相邻片段之间的局部平滑性。
-
保持不同片段之间的全局时间一致性。
-
提出的方案
-
虚拟试衣间(Virtual Fitting Room, VFR):
-
提出了一种新的视频生成模型,通过自回归、逐段生成的方式,生成任意长度的虚拟试衣视频。
-
引入“前缀视频条件”和“锚视频”来确保局部平滑性和全局时间一致性。
-
-
两步法生成长视频:
-
首先创建一个“大纲”或“锚视频”来指导生成过程。
-
然后生成多个短片段视频,这些片段与锚视频保持一致,从而确保彼此的一致性。
-
-
新的评估协议:
- 设计了四个不同难度级别的评估标准,以全面评估生成的长视频质量:
-
360° 服装一致性
-
360° 人体+服装一致性
-
手部与身体的交互保真度
-
任意姿势的能力
-
- 设计了四个不同难度级别的评估标准,以全面评估生成的长视频质量:
应用的技术
-
自回归视频生成:
-
将长视频生成任务分解为多个短片段的自回归生成,每个片段与前一片段有轻微重叠,以确保局部平滑性。
-
-
锚视频和前缀条件:
-
使用一个360°的短视频作为锚视频,指导整个生成过程,确保全局时间一致性。
-
利用前缀视频条件,确保相邻片段之间的平滑过渡。
-
-
隐式3D建模:
-
通过强制时间一致性,模型隐式地实现了3D一致性,使得可以从任意视角渲染人体,并生成3D网格。
-
达到的效果
-
高质量的长视频生成:
-
能够生成分钟级的虚拟试衣视频(720 × 1152分辨率,8 FPS,可进一步细化到24 FPS),同时保持局部平滑性和全局时间一致性。
-
-
灵活性和可扩展性:
-
用户可以根据需要生成任意长度的视频,而无需额外的训练数据或计算资源。
-
-
全面的评估和改进:
-
新的评估协议涵盖了多个方面,使得可以系统地评估和改进生成视频的质量。
-
-
自由视角渲染:
-
生成的360°视频具有3D一致性,可以从任意视角渲染,并支持3D网格重建。
-
可以从单个图像重新着装和重新动作化任何人,并从任意视角查看结果。
-
VFR:方法概述
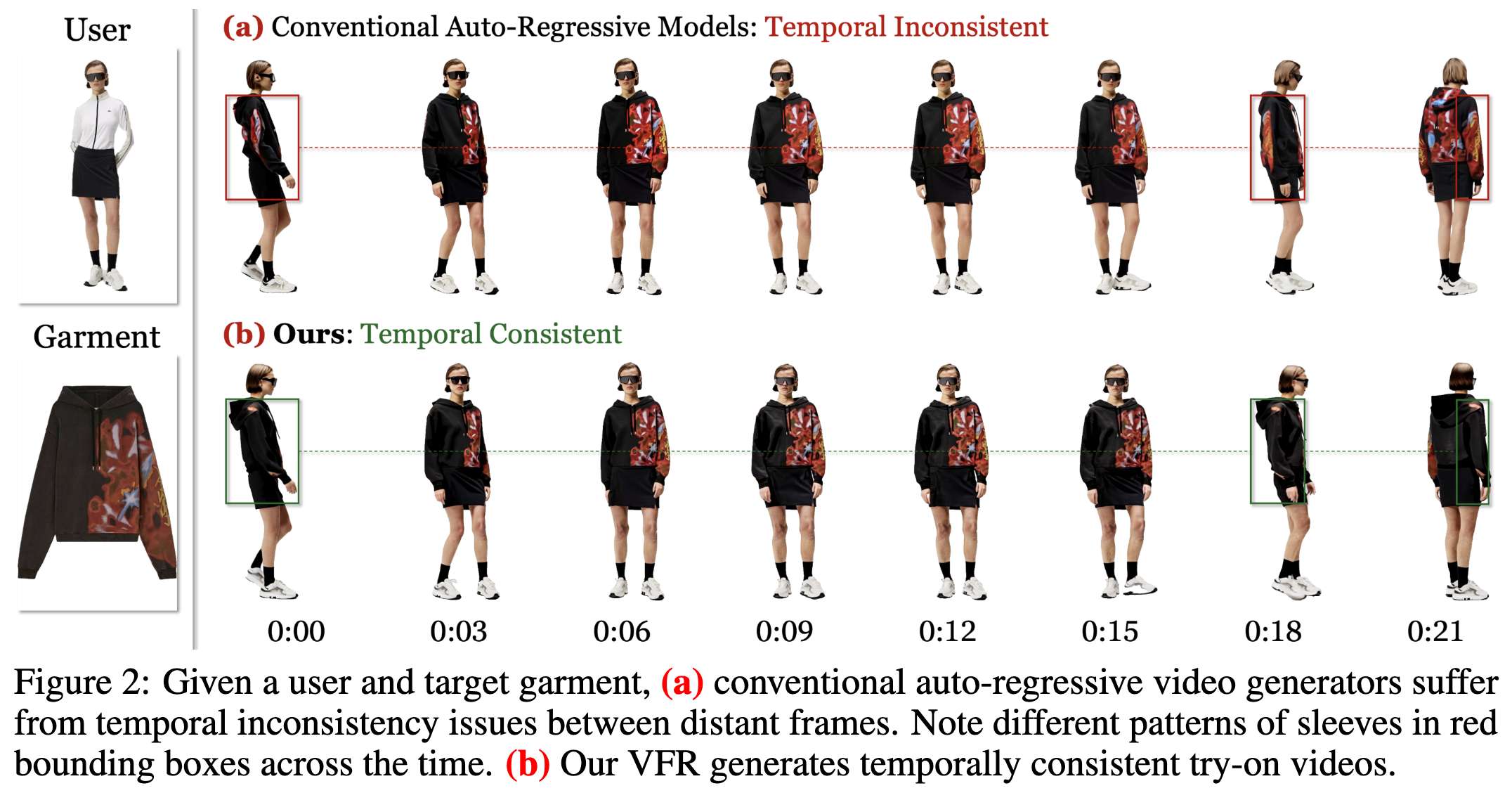
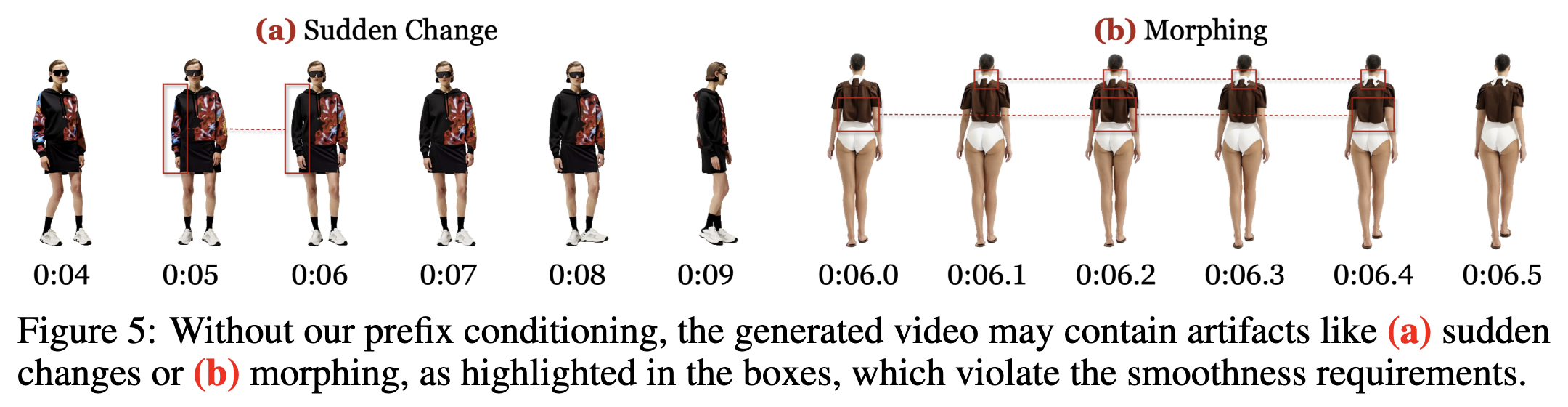
给定用户图像、参考服装图像、可选的文本提示和长动作参考视频,本文的VFR是一种以自回归、逐段的方式生成用户穿着所需服装并执行指定动作的长达分钟级的高质量试衣视频的方法。在自回归生成框架中,核心挑战是实现(1)局部平滑性,使视频过渡无缝且没有明显的突然变化或变形(下图5);以及(2)全局时间一致性,使得视频中所有出现时刻的用户和服装外观保持一致(下图2)。
为了解决这些关键挑战,本文核心见解是(1)提出“锚视频”生成,以确保整个视频中的一致外观,以及(2)引入视频前缀条件和即时优化器,通过强条件增强视频平滑度。结合这两个见解,本文的VFR实现了高质量的长试衣视频,同时确保平滑性和时间一致性。

人体主体以简单的“A”姿势进行的360°短视频作为合理的锚点
实验
实验设置
模型训练设置。VFR模型建立在Dress&Dance的基础上,增加了“前缀视频”和“锚视频”CondNets。我们在Dress&Dance的互联网和捕获数据集上训练VFR 10,000次迭代。即时优化器从基础VFR的第5,000次迭代检查点初始化,并再训练5,000次迭代。
评估任务。有四个不同部分:(1)360°服装一致性,生成5秒360°视角的“A”姿势视频,该视频也作为其他任务的锚视频;(2)360°人体+服装一致性,生成30秒360°随意移动视频;(3)360°手部与身体交互保真度,生成90秒固定动作视频;以及(4)任意姿势能力,生成30∼60秒任意动作视频。
Baseline。将VFR与FramePack基线进行比较,采用与Dress&Dance对齐的“图像虚拟试衣+图像到视频动画”(IVT+I2V)程序。以[14]中提到的“重复图像到视频”(RI2V)方式与Kling Video 2.0进行比较。我们无法与以下基线进行比较:StreamT2V,因为它仅支持16:9横向视频;CausVid,因为没有可用的图像到视频检查点发布;TTT,因为它仅支持汤姆和杰瑞视频;以及DiffusionForcing和HistoryGuidance,因为它们仅限于各自训练数据集的视频。至于图像试衣方法,本文主要使用两种最先进的方法,Dress&Dance图像试衣和Kling Try-On,来生成视频的第一帧。
消融研究。将完整的VFR与以下变体进行比较:(1)“无前缀”(NP),不使用前缀条件,而是直接利用DiffEdit来绘制带有前缀的视频;(2)“无锚”(NA),不生成和基于锚视频进行片段生成条件;(3)“Dress&Dance”(D&D),既不使用锚视频也不使用前缀条件,这使其等同于一种无需训练的方法,该方法采用Dress&Dance与DiffEdit进行长视频生成;(4)“无优化”(NR),不使用即时优化器来优化每个片段的输出。
指标。与Dress&Dance和FramePack一致,利用基于GPT的分数和VBench来评估本文的视频。GPT分数可以有效地从各个方面评估试衣质量,利用GPT的视觉能力;VBench引入了一套指标,从质量和语义角度全面评估视频。
实验结果与分析
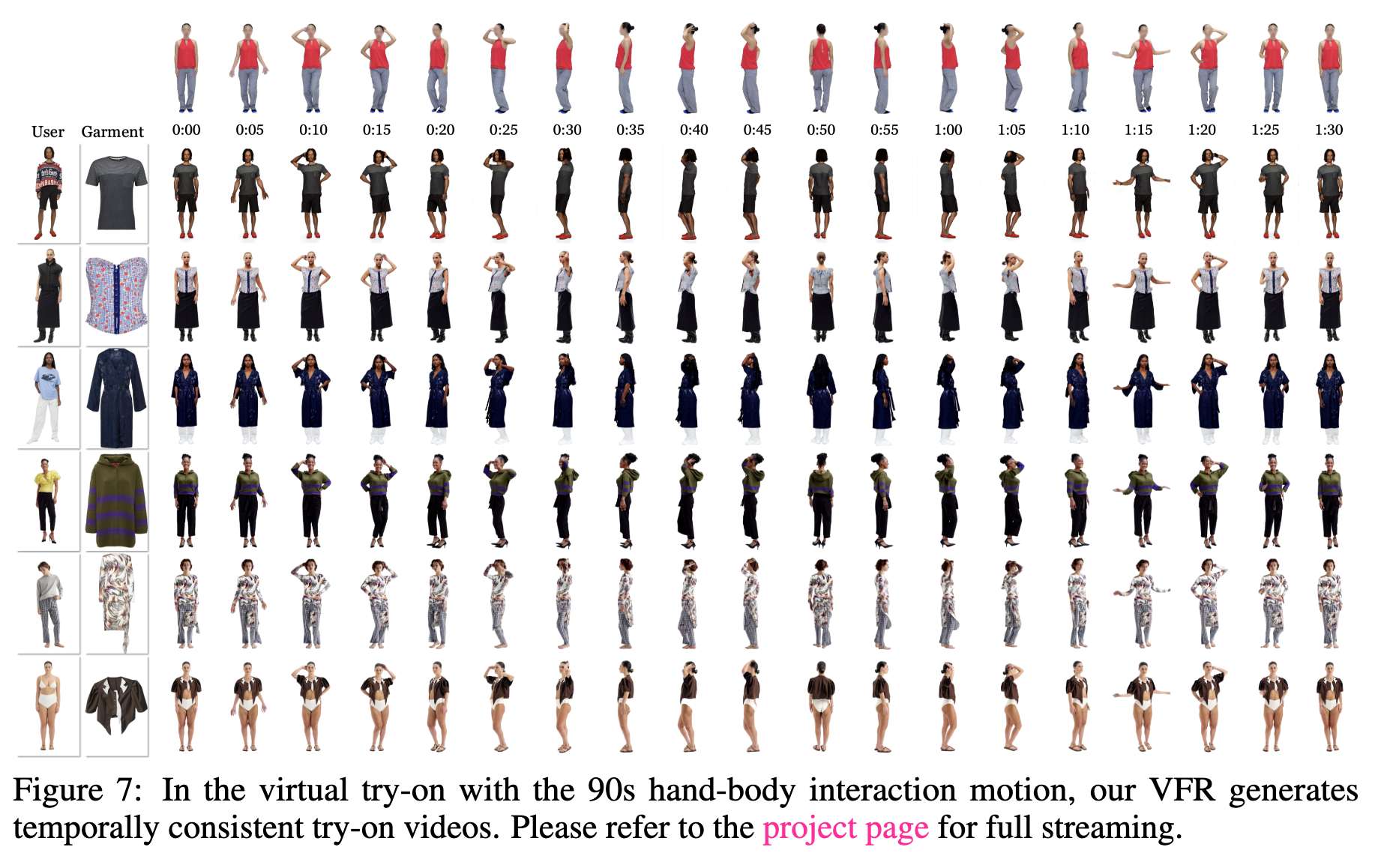
在下图6、7、8中以图像形式展示了定性结果,并在项目页面中以视频形式展示。在下表1中提供了定量结果。
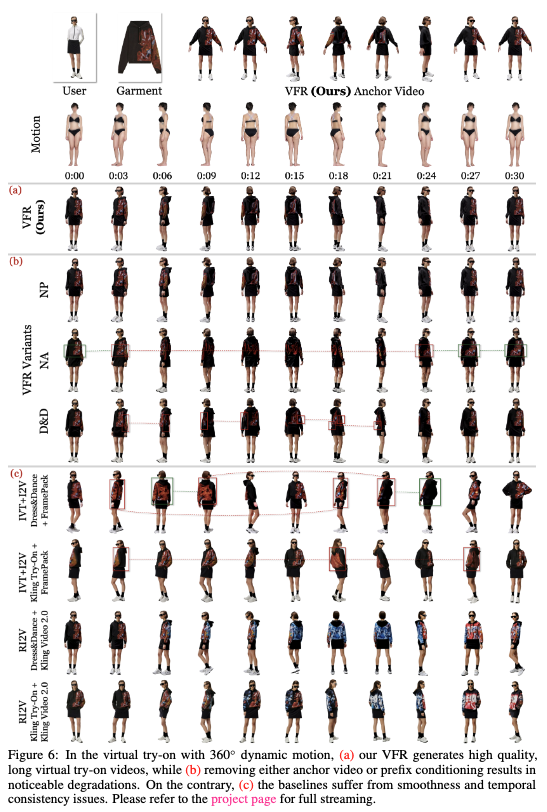

360°人体+服装一致性(30秒)。如上图6-(a)所示,VFR生成了高质量的长虚拟试衣视频。在图6-(b)中,本文的“无前缀”(NP)变体由于全局锚视频的存在,生成的结果与本文的完整VFR相当,但在项目页面中展示了一些突然变化。相比之下,本文的“无锚”(NA)变体的视频显示出长期时间不一致性,而“Dress&Dance无训练”(D&D)变体在短期和长期都表现出更大的时间不一致性。这突显了我们VFR中用于局部平滑性和全局时间一致性的两种设计都是有效且必要的。在图6-(c)中,基线FramePack产生了整体平滑的结果,但存在长期不一致性,而基于Kling Video 2.0的RI2V方法生成的结果中外观显著偏离。这表明虚拟试衣任务是非平凡且具有挑战性的,突显了我们在实现高质量结果方面的贡献。
手部与身体交互保真度(90秒)。见上图7,这些评估任务中的动作包括人体旋转和手臂运动。本文的VFR在不同虚拟试衣任务中忠实地执行相同的动作,展示了在各种服装(如裤子、裙子或连衣裙)中描绘相同动作的能力。即使对于如此长期的视频,本文的VFR仍保持高度的时间一致性,这可以通过比较第一帧和最后一帧观察到。
任意姿势能力(∼50秒)。见上图8,在这些极具挑战性的任务中,动作可以是任意的,包括各种手臂和腿部运动,这导致了服装和用户之间更广泛的展示和交互。本文的VFR有效地处理了这些动作,并生成了高质量的视觉效果来描绘它们。这表明VFR有能力推广到各种长视频虚拟试衣任务。
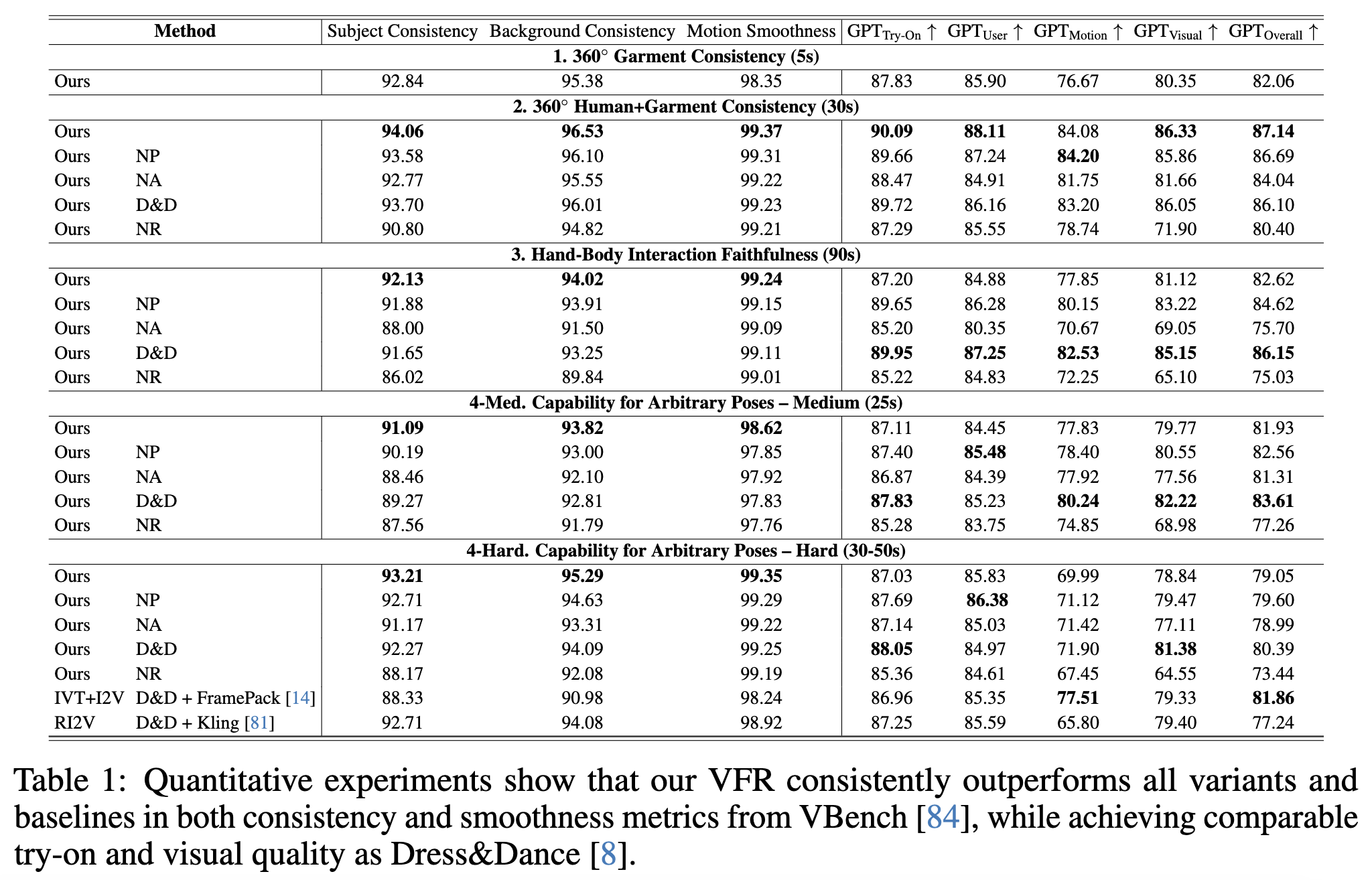
定量实验。定量评估比较在表1中提供。使用VBench中的“主体一致性”、“背景一致性”和“运动平滑性”来评估如何解决两个主要挑战——时间一致性和平滑性,以及使用[8]中的GPT指标来评估整体虚拟试衣质量。
如上表1所示,在每个评估协议的组成部分中,完整VFR始终优于所有基线和变体。此外,由于本文的VFR基于先前的工作Dress&Dance,所有这些变体都保持了其一部分虚拟试衣能力,实现了可比的GPT评估分数,其中D&D变体作为利用D&D的无训练长视频生成流程,保留了其大部分能力。
本文的NP变体的性能与本文的完整模型非常相似,反映了锚视频提供的强控制。然而,没有锚视频,NA和D&D变体在(人物)主体和背景一致性方面都显著下降,甚至在GPT评估指标中,NA变体的虚拟试衣质量也出现了退化。这表明锚视频不仅控制一致的外观,还控制试衣质量。
本文将最强大的基线FramePack和Kling与最先进的虚拟试衣方法Dress&Dance结合起来进行比较。FramePack的一致性指标显著较低,表明其考虑先前帧的条件方法不足以强制一致性。Kling的一致性指标仍略低于本文的VFR,但虚拟试衣的质量有所下降。
结论
VFR,一种从单个用户图像、服装和动作参考生成任意长、高分辨率视频的虚拟试衣方法。我们方法的关键是锚视频引导的框架,确保各片段间的时间一致性,并隐式捕捉3D结构,无需3D监督即可实现自由视角渲染。结合前缀条件,在长视频生成中实现了局部平滑性和全局时间一致性。进一步引入了一种新的评估协议,专门针对长视频虚拟试衣,涵盖服装保真度、用户外观和动作鲁棒性。实验表明,VFR产生的结果真实、平滑、时间一致且服装保真,显著超越了先前方法的能力。我们相信VFR为互动式、个性化的虚拟试衣体验开辟了新途径——无论是在电子商务、虚拟社交平台还是创意内容生成中。
讨论。本文在为虚拟试衣生成任意长、高分辨率视频方面取得了进展。本文的初步分析表明,额外的视频数据可以帮助我们进一步提高生成视频的质量。其次,尽管这项工作是第一项此类工作,但生成30秒视频需要1∼2小时,这不足以近乎实时地生成长视频——将这种加速作为有趣的未来工作。最后,相信本文的工作将为从长视频过渡到任意4D内容铺平道路,用户可以在其中更改相机视角和动作。
参考文献
[1] Virtual Fitting Room: Generating Arbitrarily Long Videos of Virtual Try-On from a Single Image Technical Preview

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)