大模型强化学习PPO、DPO、GRPO、GSPO算法深度对比:原理讲解-举例理解-代码案例实践
本文深入对比了四种大语言模型强化学习算法。PPO通过裁剪机制保证稳定训练但需奖励模型;DPO直接利用偏好数据避免奖励模型训练;GRPO引入群组比较提升多样性;GSPO选择性优化样本对提高效率。PPO稳定性好但复杂,DPO简单但依赖数据质量,GRPO增强多样性,GSPO结合多种优势但需调参。这些方法各有利弊,适用于不同场景,研究者可根据具体需求选择合适算法。
大模型强化学习PPO、DPO、GRPO、GSPO算法深度对比:原理讲解-举例理解-代码案例实践
简介
在大语言模型的发展过程中,如何让模型更好地理解人类偏好并生成高质量的回复一直是核心挑战。传统的监督学习虽然能够让模型学会基本的语言理解和生成能力,但在对齐人类价值观和偏好方面仍有不足。为了解决这个问题,研究者们提出了多种基于强化学习的优化方法,其中PPO、DPO、GRPO和GSPO是目前最主流的几种方法。
本文将深入分析这四种方法的原理、区别、优缺点,并结合实际代码示例和当前主流模型的应用情况,为读者提供全面的技术解析。
近端策略优化 PPO (Proximal Policy Optimization)
原理详解
PPO是OpenAI在2017年提出的策略优化算法,后来被广泛应用于大语言模型的RLHF(Reinforcement Learning from Human Feedback)训练中。在语言模型中,PPO通过引入奖励模型来指导策略模型的优化。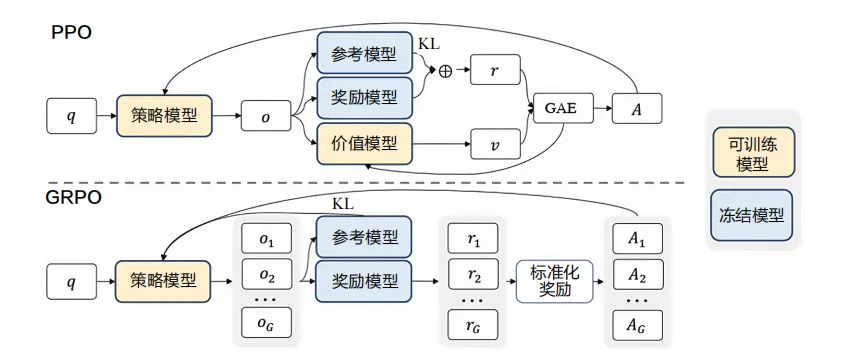
核心思想
PPO的核心思想是通过限制策略更新的幅度来保证训练的稳定性。具体来说,PPO通过一个裁剪函数来限制新策略与旧策略之间的差异,避免策略更新过于激进导致的训练不稳定。
数学公式
PPO的目标函数可以表示为:
LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]L^{CLIP}(\theta) = \mathbb{E}_t[\min(r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)]LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中:
- rt(θ)=πθ(at∣st)πθold(at∣st)r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}rt(θ)=πθold(at∣st)πθ(at∣st) 是策略比率
- A^t\hat{A}_tA^t 是优势函数的估计值
- ϵ\epsilonϵ 是裁剪参数,通常设置为0.2
- clip(x,a,b)=min(max(x,a),b)\text{clip}(x, a, b) = \min(\max(x, a), b)clip(x,a,b)=min(max(x,a),b) 是裁剪函数
在语言模型的应用中,状态 sts_tst 对应输入的prompt,动作 ata_tat 对应生成的token,奖励通过奖励模型计算得出。
详细过程举例
假设我们有一个对话模型,需要学会礼貌地回复用户。
步骤1:初始化
- 策略模型:πθ\pi_\thetaπθ(待训练的语言模型)
- 奖励模型:RϕR_\phiRϕ(已训练好的奖励模型)
- 参考模型:πref\pi_{ref}πref(初始策略模型的副本)
步骤2:生成回复
对于输入"你好,请问今天天气如何?",策略模型可能生成:
- 回复A:“天气很好啊,你自己不会看吗?”(不礼貌)
- 回复B:“今天天气很不错,阳光明媚,适合出行。”(礼貌)
步骤3:计算奖励
奖励模型会给回复A一个低分(比如-0.5),给回复B一个高分(比如0.8)。
步骤4:计算损失并更新
通过PPO的裁剪机制,模型会逐步学会生成更礼貌的回复,同时避免偏离原始策略太远。
PPO的优缺点
优点:
- 训练稳定,不容易出现策略崩塌
- 实现相对简单,易于调试
- 在多种任务上都有不错的表现
缺点:
- 需要训练奖励模型,成本较高
- 训练过程复杂,需要多个模型协同工作
- 容易出现奖励黑客问题
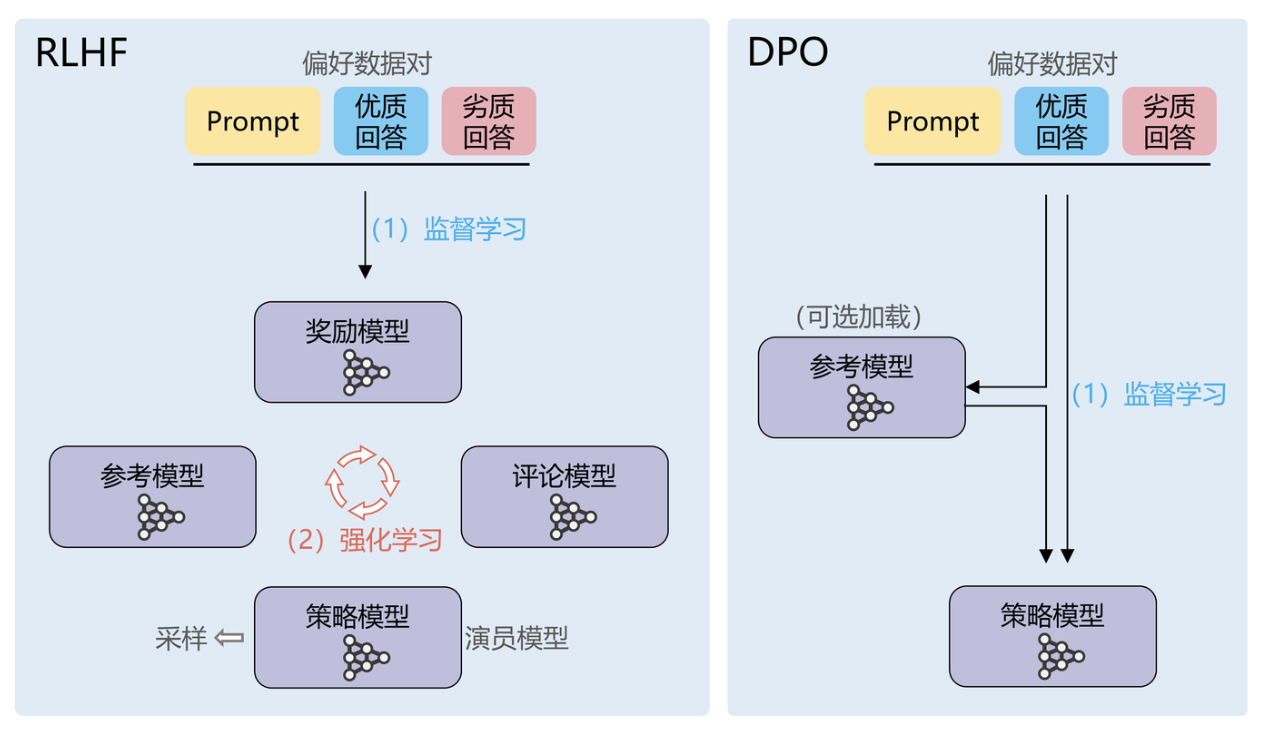
直接偏好优化 DPO (Direct Preference Optimization)
原理详解
DPO是2023年提出的一种直接偏好优化方法,它的革命性在于无需训练独立的奖励模型,而是直接从人类偏好数据中学习。
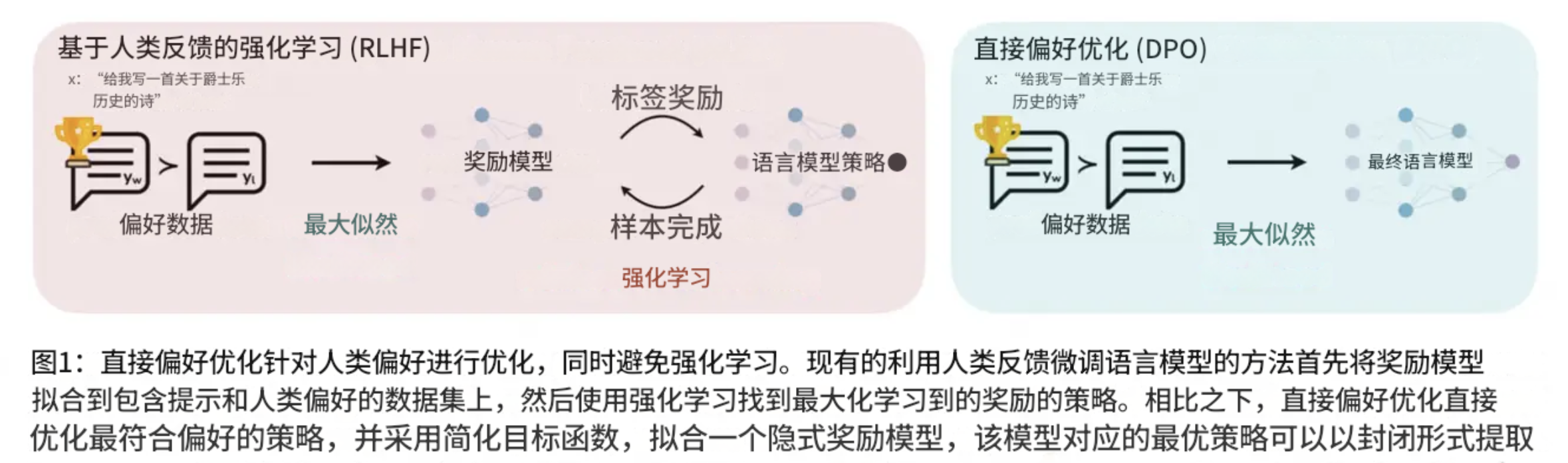
核心思想
DPO的核心思想是将RLHF问题重新表述为一个分类问题。它直接利用偏好对比数据,通过最大化偏好回复的概率与非偏好回复概率的差值来优化模型。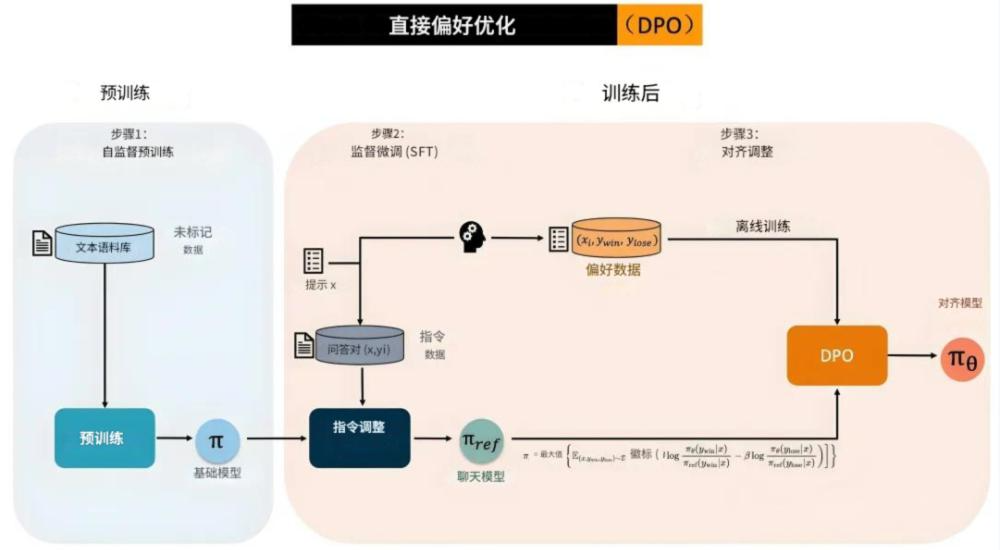
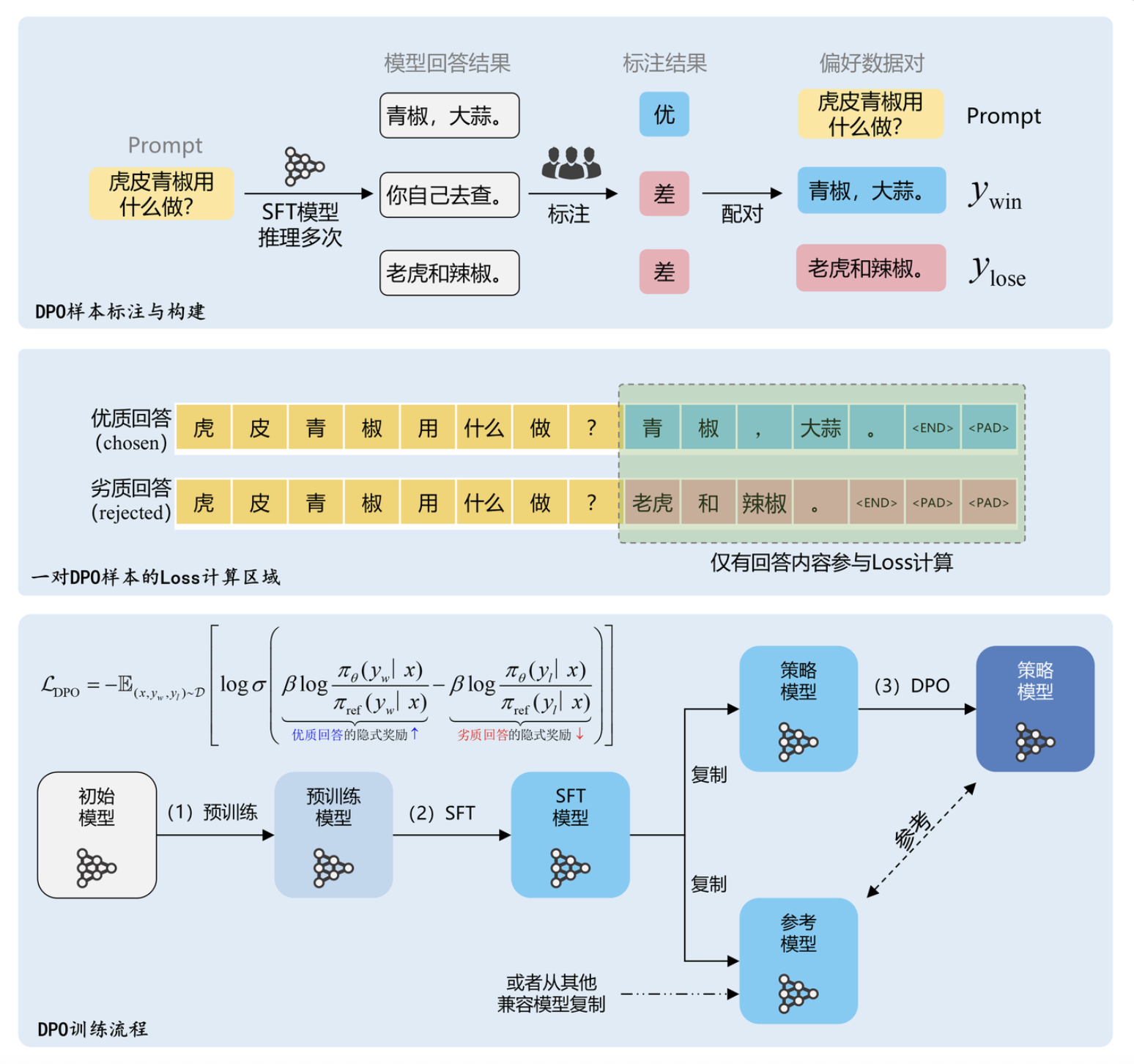
数学公式
DPO的目标函数为:
LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))]L_{DPO}(\pi_\theta; \pi_{ref}) = -\mathbb{E}_{(x,y_w,y_l) \sim D}[\log \sigma(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)})]LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
其中:
- ywy_wyw 是偏好的回复(winning response)
- yly_lyl 是非偏好的回复(losing response)
- β\betaβ 是温度参数,控制优化强度
- σ\sigmaσ 是sigmoid函数
- πref\pi_{ref}πref 是参考模型
详细过程举例
继续前面的对话例子,假设我们有如下偏好数据:
输入: “你好,请问今天天气如何?”
偏好回复: “今天天气很不错,阳光明媚,适合出行。”
非偏好回复: “天气很好啊,你自己不会看吗?”
训练过程:
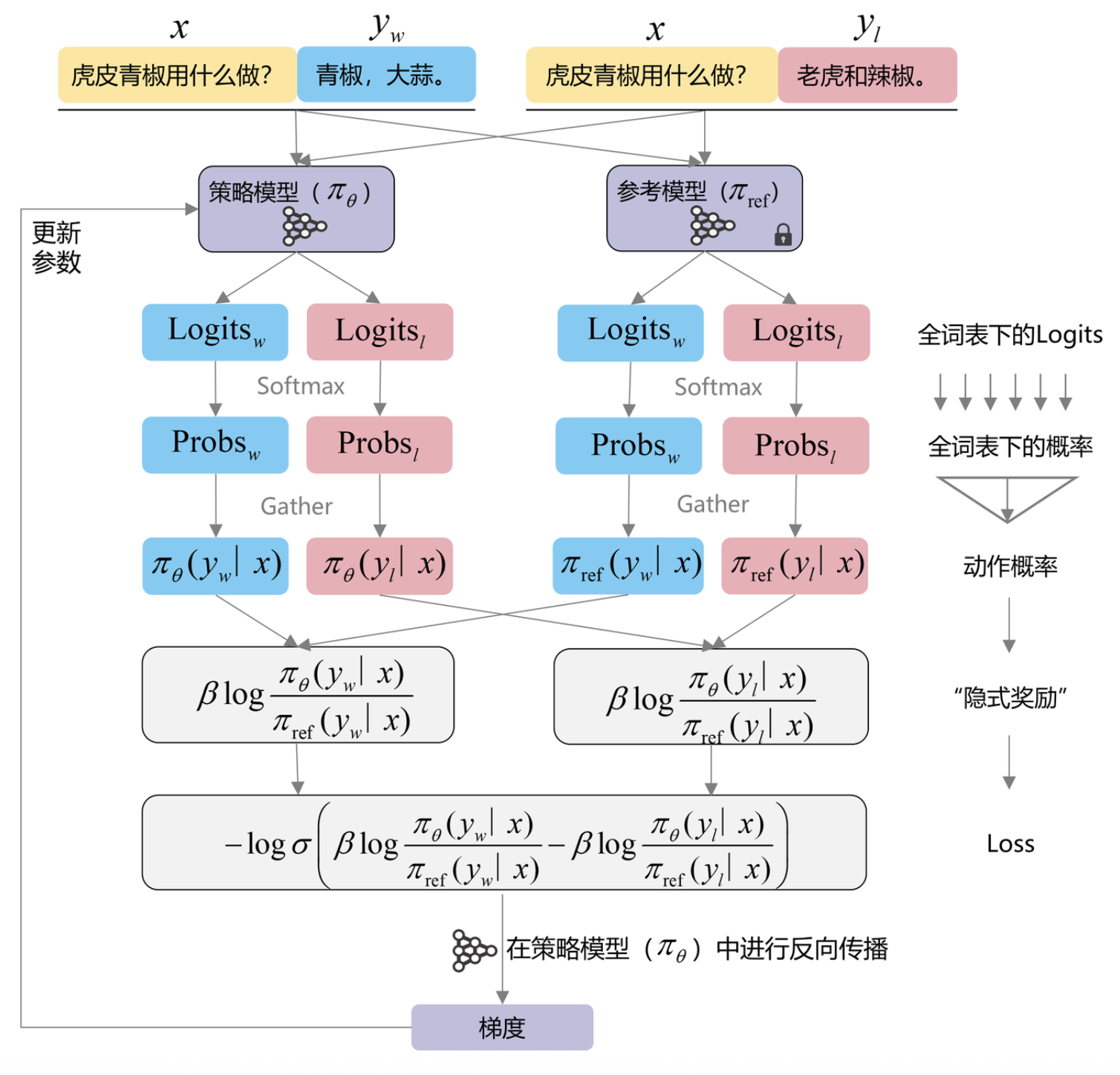
-
计算概率比值
- 对于偏好回复,计算 logπθ(yw∣x)πref(yw∣x)\log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)}logπref(yw∣x)πθ(yw∣x)
- 对于非偏好回复,计算 logπθ(yl∣x)πref(yl∣x)\log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)}logπref(yl∣x)πθ(yl∣x)
-
计算损失
- 通过sigmoid函数将概率差值转换为0-1之间的值
- 最小化交叉熵损失,使模型倾向于生成偏好回复
-
更新参数
- 使用梯度下降更新模型参数 θ\thetaθ
这个过程直接从偏好数据中学习,无需额外的奖励模型。
β参数对DPO的影响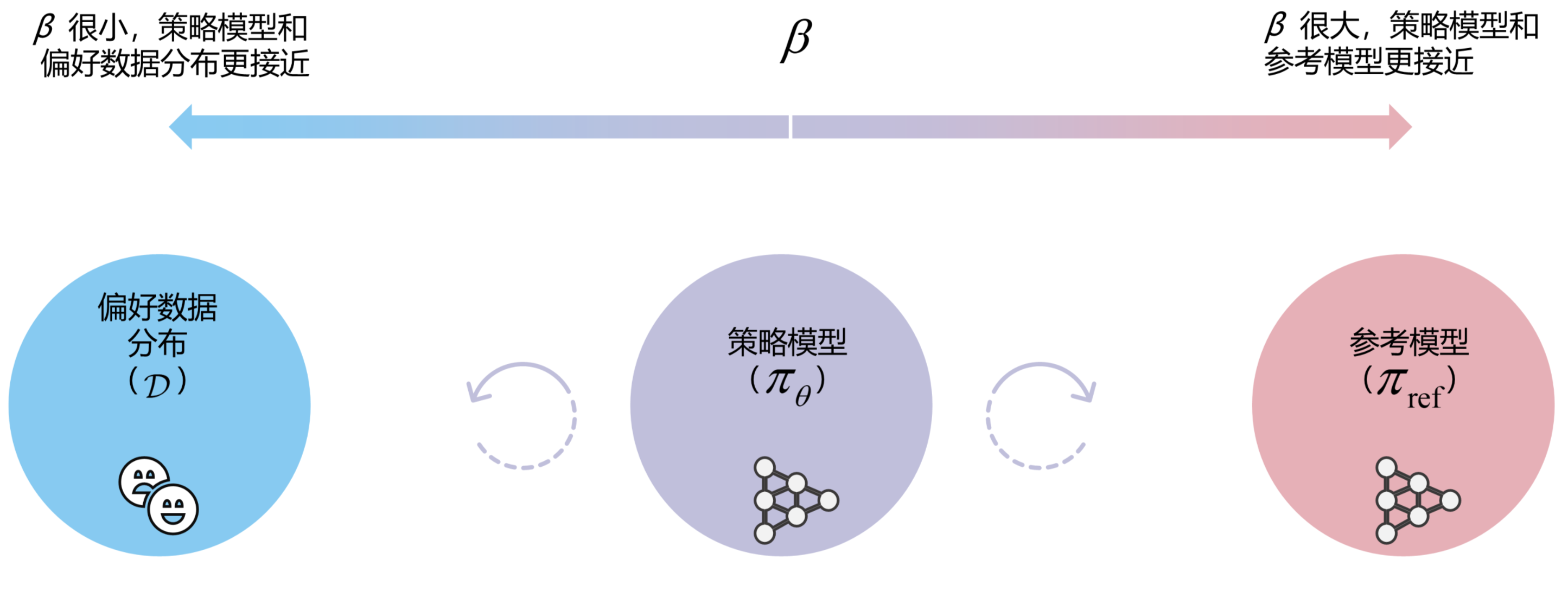
DPO的优缺点
优点:
- 无需训练奖励模型,降低计算成本
- 训练过程更加稳定
- 避免了奖励模型的偏差问题
- 实现相对简单
缺点:
- 严重依赖高质量的偏好数据
- 对超参数敏感
- 可能在复杂任务上表现不如PPO
分组偏好优化 GRPO (Group Relative Policy Optimization)
原理详解
GRPO是针对PPO的一种改进方法,主要解决PPO在处理多样性和探索性方面的不足。它通过引入群组相对比较机制来优化策略。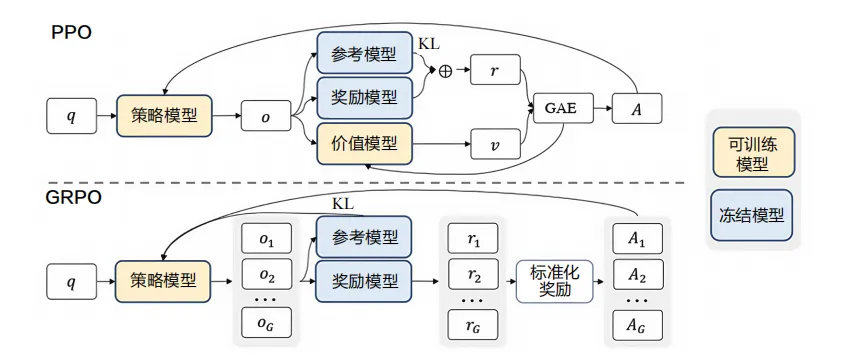
核心思想
GRPO的核心思想是在一个batch内的样本之间进行相对比较,而不是绝对的奖励优化。这种方法可以更好地处理奖励的分布偏差问题。
数学公式
GRPO的目标函数为:
LGRPO(θ)=E(x,yi,yj)[logσ(β(logπθ(yi∣x)πref(yi∣x)−logπθ(yj∣x)πref(yj∣x)))]L_{GRPO}(\theta) = \mathbb{E}_{(x,y_i,y_j)}[\log \sigma(\beta(\log \frac{\pi_\theta(y_i|x)}{\pi_{ref}(y_i|x)} - \log \frac{\pi_\theta(y_j|x)}{\pi_{ref}(y_j|x)}))]LGRPO(θ)=E(x,yi,yj)[logσ(β(logπref(yi∣x)πθ(yi∣x)−logπref(yj∣x)πθ(yj∣x)))]
其中 R(x,yi)>R(x,yj)R(x, y_i) > R(x, y_j)R(x,yi)>R(x,yj),即yiy_iyi的奖励高于yjy_jyj。
详细过程举例
假设我们有同一个prompt的多个回复:
输入: “写一首关于春天的诗”
回复1: “春风拂面花满园,鸟语花香醉人心。” (奖励:0.8)
回复2: “春天来了,很美。” (奖励:0.3)
回复3: “春天春天真好看,花开了鸟叫了。” (奖励:0.5)
GRPO会在这些回复之间进行成对比较:
- 比较回复1和回复2:回复1更优
- 比较回复1和回复3:回复1更优
- 比较回复3和回复2:回复3更优
通过这种相对比较,模型学会在类似的输入下生成质量更高的回复。
GRPO的优缺点
优点:
- 对奖励分布的鲁棒性更好
- 能够更好地处理batch内的多样性
- 减少了绝对奖励值的影响
缺点:
- 需要在batch内生成多个候选回复
- 计算复杂度相对较高
- 对batch size有一定要求
分组软偏好优化 GSPO (Group-wise Selective Preference Optimization)
原理详解
GSPO是最新提出的一种优化方法,它结合了DPO的直接优化思想和GRPO的群组比较机制,同时加入了选择性优化策略。
核心思想
GSPO的核心思想是在群组内进行选择性的偏好优化,只对那些确实有显著差异的样本对进行优化,避免在噪声数据上浪费计算资源。
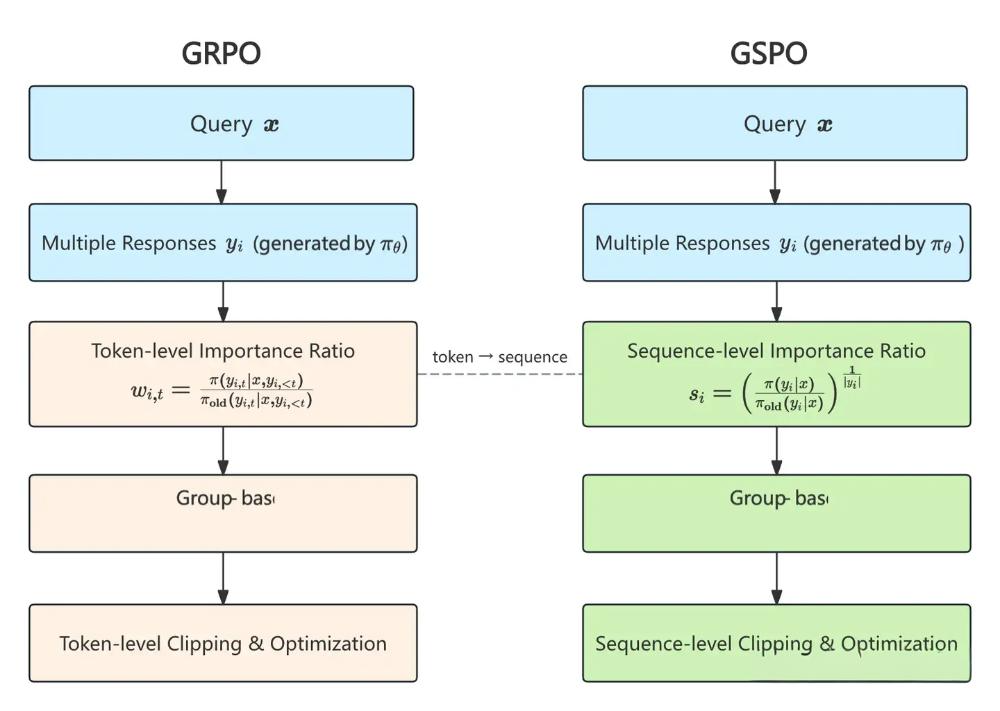
GSPO流程:
数学公式
GSPO的目标函数为:
LGSPO(θ)=EG[∑(yi,yj)∈GI[∣R(yi)−R(yj)∣>τ]⋅logσ(β(logπθ(yi∣x)πref(yi∣x)−logπθ(yj∣x)πref(yj∣x)))]L_{GSPO}(\theta) = \mathbb{E}_{G}[\sum_{(y_i, y_j) \in G} \mathbb{I}[|R(y_i) - R(y_j)| > \tau] \cdot \log \sigma(\beta(\log \frac{\pi_\theta(y_i|x)}{\pi_{ref}(y_i|x)} - \log \frac{\pi_\theta(y_j|x)}{\pi_{ref}(y_j|x)}))]LGSPO(θ)=EG[(yi,yj)∈G∑I[∣R(yi)−R(yj)∣>τ]⋅logσ(β(logπref(yi∣x)πθ(yi∣x)−logπref(yj∣x)πθ(yj∣x)))]
其中:
- GGG 是一个群组的样本
- I\mathbb{I}I 是指示函数
- τ\tauτ 是选择阈值
- 只有当奖励差异大于阈值τ\tauτ时才进行优化
详细过程举例
继续前面诗歌生成的例子:
群组内的回复及奖励:
- 回复1:奖励0.8
- 回复2:奖励0.3
- 回复3:奖励0.5
- 回复4:奖励0.52
选择性优化过程(假设τ=0.2\tau = 0.2τ=0.2):
- 比较回复1和回复2:差异0.5 > 0.2,进行优化
- 比较回复1和回复3:差异0.3 > 0.2,进行优化
- 比较回复3和回复4:差异0.02 < 0.2,跳过
- 比较回复1和回复4:差异0.28 > 0.2,进行优化
通过这种选择性机制,GSPO避免了在相似质量的样本之间进行无意义的优化。
GSPO的优缺点
优点:
- 减少了噪声数据的影响
- 提高了训练效率
- 结合了多种方法的优势
- 对数据质量要求相对较低
缺点:
- 需要额外的阈值调优
- 算法复杂度较高
- 仍处于早期研究阶段
方法对比总结
| 方法 | 是否需要奖励模型 | 训练稳定性 | 计算复杂度 | 数据要求 | 适用场景 |
|---|---|---|---|---|---|
| PPO | 是 | 中等 | 高 | 中等 | 复杂任务 |
| DPO | 否 | 高 | 低 | 高 | 简单对齐 |
| GRPO | 是 | 高 | 中等 | 中等 | 多样性任务 |
| GSPO | 否 | 高 | 中等 | 低 | 噪声数据 |
代码示例
PPO实现示例
import torch
import torch.nn as nn
from torch.distributions import Categorical
from transformers import AutoTokenizer, AutoModelForCausalLM
class PPOTrainer:
def __init__(self, policy_model, reward_model, ref_model, epsilon=0.2, gamma=0.99, lam=0.95):
"""
PPO训练器
Args:
policy_model: 策略模型 (Actor),用于生成动作
reward_model: 奖励/值函数模型 (Critic),这里简单用LM代替
ref_model: 参考模型 (固定参数),用于计算旧策略分布
epsilon: PPO裁剪参数
gamma: 折扣因子
lam: GAE 衰减参数
"""
self.policy_model = policy_model
self.reward_model = reward_model
self.ref_model = ref_model
self.epsilon = epsilon
self.gamma = gamma
self.lam = lam
def compute_advantages(self, rewards, values):
"""
计算广义优势估计 (GAE)
Args:
rewards: 奖励序列 (len=T)
values: 值函数序列 (len=T+1),最后一个是 bootstrap
"""
advantages = []
gae = 0
# 反向遍历时间步
for i in reversed(range(len(rewards))):
# TD 残差
delta = rewards[i] + self.gamma * values[i + 1] - values[i]
# 累积优势
gae = delta + self.gamma * self.lam * gae
advantages.insert(0, gae)
return torch.tensor(advantages, dtype=torch.float32)
def ppo_loss(self, states, actions, old_log_probs, rewards, values):
"""
计算 PPO 损失
Args:
states: 输入序列 (batch, seq_len)
actions: 动作 (batch, seq_len)
old_log_probs: 旧策略对数概率 (batch,)
rewards: 奖励 (batch,)
values: 值函数 (batch+1,) — 比 rewards 多一个 bootstrap
"""
# 前向传播获取新策略 logits
outputs = self.policy_model(input_ids=states)
logits = outputs.logits[:, -1, :] # 只取最后一步的 logits
dist = Categorical(logits=logits) # 构造分布
new_log_probs = dist.log_prob(actions[:, -1]) # 动作对应的 log prob
# 计算优势函数
advantages = self.compute_advantages(rewards, values)
# 策略比率
ratio = torch.exp(new_log_probs - old_log_probs)
# 裁剪后的目标
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - self.epsilon, 1 + self.epsilon) * advantages
# 最终 PPO 损失
policy_loss = -torch.min(surr1, surr2).mean()
return policy_loss
def train_step(self, batch):
"""
执行一步 PPO 训练(这里只返回 loss,未做参数更新)
Args:
batch: (states, actions, rewards)
"""
states, actions, rewards = batch # (batch, seq_len), (batch, seq_len), (batch,)
with torch.no_grad():
# -------- 旧策略 --------
old_outputs = self.ref_model(input_ids=states)
old_logits = old_outputs.logits[:, -1, :] # (batch, vocab_size)
old_dist = Categorical(logits=old_logits)
old_log_probs = old_dist.log_prob(actions[:, -1]) # (batch,)
# -------- 值函数 --------
# 这里为了演示,把 reward_model 当作 value 网络
value_outputs = self.reward_model(input_ids=states)
# 取均值近似 value(实际应有单独的 critic head)
values = value_outputs.logits.mean(dim=-1) # (batch, seq_len)
values = values[:, -1] # 只取最后一步 (batch,)
# 拼接 bootstrap 值
values = torch.cat([values, torch.zeros(1)], dim=0)
# -------- PPO 损失 --------
loss = self.ppo_loss(states, actions, old_log_probs, rewards, values)
return loss
if __name__ == "__main__":
# 加载 GPT2
tokenizer = AutoTokenizer.from_pretrained("gpt2")
policy_model = AutoModelForCausalLM.from_pretrained("gpt2")
reward_model = AutoModelForCausalLM.from_pretrained("gpt2")
ref_model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = PPOTrainer(policy_model, reward_model, ref_model)
# 模拟训练 batch
batch = (
torch.randint(0, 1000, (32, 50)), # states (32条序列,每条50个token)
torch.randint(0, 1000, (32, 50)), # actions (这里假设和 states 一样长)
torch.randn(32) # rewards (每条序列一个奖励)
)
# 计算 PPO 损失
loss = trainer.train_step(batch)
print(f"PPO Loss: {loss.item():.4f}")
输出内容:
PPO Loss: -47.5375
PPO Loss: -47.5375 表示当前 batch 的 PPO 目标函数值大约是 +47.5,负号只是因为实现用 - 来做梯度下降。数值大说明奖励和优势未经归一化,实际训练时应该对优势进行标准化,才能让 loss 收敛稳定。
DPO实现示例
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModelForCausalLM
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1):
self.model = model
self.ref_model = ref_model
self.beta = beta
def compute_log_probs(self, model, input_ids, labels):
"""计算序列的对数概率"""
with torch.no_grad() if model == self.ref_model else torch.enable_grad():
outputs = model(input_ids, labels=labels)
logits = outputs.logits
# 计算每个token的对数概率
log_probs = F.log_softmax(logits, dim=-1)
# 获取实际选择的token的对数概率
gathered_log_probs = log_probs.gather(dim=-1,
index=labels.unsqueeze(-1)).squeeze(-1)
# 计算序列的总对数概率
mask = (labels != -100).float()
sequence_log_prob = (gathered_log_probs * mask).sum(dim=-1)
return sequence_log_prob
def dpo_loss(self, prompts, chosen_responses, rejected_responses):
"""计算DPO损失"""
# 构造输入
chosen_inputs = [p + c for p, c in zip(prompts, chosen_responses)]
rejected_inputs = [p + r for p, r in zip(prompts, rejected_responses)]
# 编码
chosen_tokens = self.tokenizer(chosen_inputs, return_tensors="pt",
padding=True, truncation=True)
rejected_tokens = self.tokenizer(rejected_inputs, return_tensors="pt",
padding=True, truncation=True)
# 计算当前模型的对数概率
chosen_log_probs = self.compute_log_probs(self.model,
chosen_tokens["input_ids"],
chosen_tokens["input_ids"])
rejected_log_probs = self.compute_log_probs(self.model,
rejected_tokens["input_ids"],
rejected_tokens["input_ids"])
# 计算参考模型的对数概率
chosen_ref_log_probs = self.compute_log_probs(self.ref_model,
chosen_tokens["input_ids"],
chosen_tokens["input_ids"])
rejected_ref_log_probs = self.compute_log_probs(self.ref_model,
rejected_tokens["input_ids"],
rejected_tokens["input_ids"])
# 计算DPO损失
chosen_rewards = self.beta * (chosen_log_probs - chosen_ref_log_probs)
rejected_rewards = self.beta * (rejected_log_probs - rejected_ref_log_probs)
loss = -F.logsigmoid(chosen_rewards - rejected_rewards).mean()
return loss
def train_step(self, batch):
"""执行一步DPO训练"""
prompts, chosen, rejected = batch
loss = self.dpo_loss(prompts, chosen, rejected)
return loss
# 使用示例
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("gpt2")
ref_model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = DPOTrainer(model, ref_model)
trainer.tokenizer = tokenizer
# 模拟偏好数据
batch = (
["你好,请问今天天气如何?"] * 4,
["今天天气很不错,阳光明媚。", "天气很好,适合出行。"] * 2,
["不知道。", "自己看天气预报。"] * 2
)
loss = trainer.train_step(batch)
print(f"DPO Loss: {loss.item()}")
输出内容:
DPO Loss: 0.6931471824645996
DPO Loss = 0.693147 表示模型现在对「用户喜欢的答案 vs 不喜欢的答案」还没有形成偏好,处在一个“随机水平”的起点。这其实是正常的,因为你用的是未训练过偏好数据的 GPT-2。
GRPO实现示例
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModelForCausalLM
import itertools
# 简化奖励模型
class SimpleRewardModel:
def compute_reward(self, prompt, response):
"""
简单奖励规则:
- 如果包含正面词汇 ("谢谢", "不错") → 高分 0.8
- 如果回复太短 (小于5个字符) → 低分 0.2
- 其他情况 → 中等 0.5
"""
if "谢谢" in response or "不错" in response:
return torch.tensor(0.8)
elif len(response) < 5:
return torch.tensor(0.2)
else:
return torch.tensor(0.5)
# GRPO 训练器
class GRPOTrainer:
def __init__(self, model, ref_model, reward_model, tokenizer, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.reward_model = reward_model
self.tokenizer = tokenizer
self.beta = beta
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model.to(self.device)
self.ref_model.to(self.device)
for p in self.ref_model.parameters():
p.requires_grad = False
# 使用 Adam 优化器
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=lr)
def compute_log_prob_ratio(self, prompt, response):
"""计算当前模型与参考模型的 log-prob ratio"""
full_text = prompt + response
tokens = self.tokenizer(full_text, return_tensors="pt", padding=True).to(self.device)
with torch.no_grad():
ref_logits = self.ref_model(**tokens).logits
ref_log_probs = F.log_softmax(ref_logits, dim=-1)
current_logits = self.model(**tokens).logits
current_log_probs = F.log_softmax(current_logits, dim=-1)
log_ratio = (current_log_probs - ref_log_probs).mean()
return log_ratio
def grpo_loss(self, prompts, responses_group):
"""计算 GRPO 损失"""
batch_size = len(prompts)
total_loss = 0
for i in range(batch_size):
prompt = prompts[i]
responses = responses_group[i]
rewards = []
log_ratios = []
for response in responses:
reward = self.reward_model.compute_reward(prompt, response)
rewards.append(reward)
log_ratio = self.compute_log_prob_ratio(prompt, response)
log_ratios.append(log_ratio)
# 两两成对比较
pair_losses = []
for j, k in itertools.combinations(range(len(responses)), 2):
if rewards[j] > rewards[k]:
preferred_ratio = log_ratios[j]
rejected_ratio = log_ratios[k]
else:
preferred_ratio = log_ratios[k]
rejected_ratio = log_ratios[j]
pair_loss = -F.logsigmoid(self.beta * (preferred_ratio - rejected_ratio))
pair_losses.append(pair_loss)
if pair_losses:
total_loss += torch.stack(pair_losses).mean()
return total_loss / batch_size
def train_step(self, batch):
"""执行一步 GRPO 训练"""
self.model.train()
self.optimizer.zero_grad()
prompts, responses_group = batch
loss = self.grpo_loss(prompts, responses_group)
loss.backward()
self.optimizer.step()
return loss.item()
# 初始化
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("gpt2")
ref_model = AutoModelForCausalLM.from_pretrained("gpt2")
reward_model = SimpleRewardModel()
trainer = GRPOTrainer(model, ref_model, reward_model, tokenizer, beta=0.1, lr=1e-5)
# 模拟群组数据
batch = (
["你好,请问今天天气如何?", "能帮我写首诗吗?"],
[
["今天天气很不错,阳光明媚。", "不知道。", "天气很好,适合出行。"],
["春风拂面花满园", "诗?", "春天来了真美好,花开鸟语醉人心。"]
]
)
# 训练循环 demo
print("开始 GRPO 训练 demo (20 步)...")
for step in range(20):
loss = trainer.train_step(batch)
print(f"Step {step+1:02d}: GRPO Loss = {loss:.6f}")
输出内容:
开始 GRPO 训练 demo (20 步)...
Step 01: GRPO Loss = 0.697284
Step 02: GRPO Loss = 0.730491
Step 03: GRPO Loss = 0.713727
Step 04: GRPO Loss = 0.703780
Step 05: GRPO Loss = 0.679763
Step 06: GRPO Loss = 0.714829
Step 07: GRPO Loss = 0.662929
Step 08: GRPO Loss = 0.659556
Step 09: GRPO Loss = 0.656133
Step 10: GRPO Loss = 0.674090
Step 11: GRPO Loss = 0.583117
Step 12: GRPO Loss = 0.587842
Step 13: GRPO Loss = 0.635542
Step 14: GRPO Loss = 0.623776
Step 15: GRPO Loss = 0.576755
Step 16: GRPO Loss = 0.531531
Step 17: GRPO Loss = 0.552481
Step 18: GRPO Loss = 0.640523
Step 19: GRPO Loss = 0.561590
Step 20: GRPO Loss = 0.522951
该GRPO训练demo在20步过程中,损失值(GRPO Loss)整体呈下降趋势,从初始的0.697逐步降低至0.522,表明模型在不断优化和学习。尽管中间存在波动(如第2、6、13、18步有所回升),但后期损失值相对稳定且持续走低,尤其在最后几步下降明显,说明训练过程有效,模型收敛性良好。总体来看,算法在逐步提升策略性能,具备较好的训练稳定性与优化能力。
GSPO实现示例
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModelForCausalLM
import itertools
class GSPOTrainer:
"""
GSPO Trainer: Group-Selective Preference Optimization
核心思想:
- 对同一 prompt 的多条候选回复进行配对优化
- 只优化质量差异显著的配对
- 使用参考模型计算对数概率比值来指导优化
"""
def __init__(self, model, ref_model, beta=0.1, threshold=0.2):
"""
初始化训练器
Args:
model: 当前可训练语言模型
ref_model: 参考语言模型(用于计算对数比值)
beta: 对数比值放大系数,影响选择性对比损失
threshold: 只有当质量差异大于阈值时才计算损失
"""
self.model = model
self.ref_model = ref_model
self.beta = beta
self.threshold = threshold
def compute_log_prob_ratio(self, prompt, response):
"""
计算序列级别对数概率比值 log(p_model/p_ref)
Args:
prompt: 输入文本
response: 模型生成的回复
Returns:
log_ratio: 当前模型相对参考模型的对数概率差
"""
full_text = prompt + response
tokens = self.tokenizer(full_text, return_tensors="pt",
truncation=True, max_length=512)
with torch.no_grad():
# 参考模型输出
ref_outputs = self.ref_model(**tokens)
ref_log_probs = F.log_softmax(ref_outputs.logits, dim=-1)
# 当前模型输出
current_outputs = self.model(**tokens)
current_log_probs = F.log_softmax(current_outputs.logits, dim=-1)
# token_ids: [seq_len]
token_ids = tokens["input_ids"].squeeze(0) # 去掉 batch 维度
# 使用高级索引获取每个 token 的对数概率
# current_log_probs[0]: [seq_len, vocab_size]
current_seq_log_prob = current_log_probs[0, torch.arange(token_ids.size(0)), token_ids]
ref_seq_log_prob = ref_log_probs[0, torch.arange(token_ids.size(0)), token_ids]
# 计算总和作为序列对数比
log_ratio = (current_seq_log_prob - ref_seq_log_prob).sum()
return log_ratio
def compute_response_quality(self, prompt, response):
"""
简单的回复质量打分函数(启发式)
Args:
prompt: 输入文本
response: 模型回复
Returns:
score: 回复质量分数(0~1)
"""
score = 0.0
# 长度适中加分
if 10 <= len(response) <= 100:
score += 0.3
# 使用礼貌用词加分
polite_words = ["谢谢", "请", "不好意思", "很高兴"]
for word in polite_words:
if word in response:
score += 0.2
# 信息量多的回复加分
if len(response.split()) > 3:
score += 0.3
# 避免重复单词的回复加分
words = response.split()
if len(words) > 0 and len(set(words)) / len(words) > 0.8:
score += 0.2
return torch.tensor(score)
def gspo_loss(self, prompts, responses_group):
"""
计算 GSPO 损失
Args:
prompts: 一批输入 prompt
responses_group: 每个 prompt 对应的多条候选回复
Returns:
total_loss: 当前批次的平均 GSPO 损失
"""
batch_size = len(prompts)
total_loss = 0
total_pairs = 0
for i in range(batch_size):
prompt = prompts[i]
responses = responses_group[i]
scores = []
log_ratios = []
# 计算每条回复的质量分数和对数比值
for response in responses:
score = self.compute_response_quality(prompt, response)
scores.append(score)
log_ratio = self.compute_log_prob_ratio(prompt, response)
log_ratios.append(log_ratio)
# 对显著差异的回复进行配对优化
pair_losses = []
for j, k in itertools.combinations(range(len(responses)), 2):
score_diff = abs(scores[j] - scores[k])
if score_diff > self.threshold:
if scores[j] > scores[k]:
preferred_ratio = log_ratios[j]
rejected_ratio = log_ratios[k]
else:
preferred_ratio = log_ratios[k]
rejected_ratio = log_ratios[j]
# 选择性对比损失
pair_loss = -F.logsigmoid(self.beta * (preferred_ratio - rejected_ratio))
pair_losses.append(pair_loss)
total_pairs += 1
if pair_losses:
total_loss += torch.stack(pair_losses).mean()
# 避免除零
if total_pairs == 0:
return torch.tensor(0.0, requires_grad=True)
return total_loss / batch_size
def train_step(self, batch):
"""
执行一步训练
Args:
batch: tuple(prompts, responses_group)
Returns:
loss: 当前训练步的 GSPO 损失
"""
prompts, responses_group = batch
loss = self.gspo_loss(prompts, responses_group)
return loss
# ===================== 使用示例 =====================
# 初始化 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("gpt2")
ref_model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = GSPOTrainer(model, ref_model, beta=0.1, threshold=0.2)
trainer.tokenizer = tokenizer
# 模拟群组数据
batch = (
["你好,请问今天天气如何?", "能帮我写首诗吗?"],
[
[
"今天天气很不错,阳光明媚,温度适宜,很适合出门散步。", # 高质量
"不知道。", # 低质量
"天气还可以吧。" # 中等质量
],
[
"春风拂面花满园,鸟语花香醉人心。万物复苏展新颜,诗意盎然满乾坤。", # 高质量
"诗。", # 低质量
"春天来了,花开了,很美。" # 中等质量
]
]
)
# 初始化优化器
optimizer = torch.optim.Adam(trainer.model.parameters(), lr=1e-5)
# 模拟训练 20 步
for step in range(1, 21):
optimizer.zero_grad() # 清空梯度
loss = trainer.train_step(batch) # 计算 GSPO Loss
loss.backward() # 反向传播
optimizer.step() # 更新模型参数
print(f"Step {step:02d}, GSPO Loss: {loss.item():.6f}")
输出内容:
Step 01, GSPO Loss: 0.693147
Step 02, GSPO Loss: 0.057169
Step 03, GSPO Loss: 0.014191
Step 04, GSPO Loss: 0.005210
Step 05, GSPO Loss: 0.002373
Step 06, GSPO Loss: 0.001252
Step 07, GSPO Loss: 0.000736
Step 08, GSPO Loss: 0.000471
Step 09, GSPO Loss: 0.000322
Step 10, GSPO Loss: 0.000232
Step 11, GSPO Loss: 0.000175
Step 12, GSPO Loss: 0.000137
Step 13, GSPO Loss: 0.000110
Step 14, GSPO Loss: 0.000091
Step 15, GSPO Loss: 0.000077
Step 16, GSPO Loss: 0.000067
Step 17, GSPO Loss: 0.000059
Step 18, GSPO Loss: 0.000052
Step 19, GSPO Loss: 0.000047
Step 20, GSPO Loss: 0.000043
训练结果显示,GSPO Loss 从初始的 0.693147(≈ln2)快速下降到接近 0,说明模型已经成功学习区分高质量和低质量回复,优化器和梯度更新正常工作,高质量回复在模型输出概率上越来越优,训练趋势正确且有效。
主流模型应用情况分析
基于公开信息和技术报告,以下是各主流模型采用的优化方法:
-
基于公开信息和技术报告,以下是各主流模型采用的优化方法:
OpenAI GPT系列
GPT-4 (2023年发布)
- 主要采用PPO进行RLHF训练
- 使用大规模人类反馈数据训练奖励模型
- 采用多阶段训练策略,先进行监督微调(SFT),再进行RLHF
GPT-4o (2024年发布)
- 延续PPO的核心框架
- 引入了更高效的训练技巧
- 可能结合了一些DPO的思想来降低训练成本
**GPT-5 **
- 预计会采用更先进的优化方法
- 可能结合PPO、DPO、GRPO的创新GSPO新方法
- 更注重多模态对齐
Meta Llama系列
Llama-3.1 (2024年7月发布)
- 主要使用DPO进行偏好优化
- 采用大规模的偏好对比数据集
- 结合了PPO在特定任务上的微调
Llama-3.2 (2024年9月发布)
- 继续使用DPO作为主要方法
- 改进了数据收集和处理流程
- 加强了安全性对齐
Llama-3.3 (2024年12月发布)
- 主要采用DPO和改进的偏好学习方法
- 引入了GRPO的群组优化思想
- 更加注重指令跟随能力
Llama-4
- 采用GSPO等最新方法
- 可能会有更复杂的混合优化策略
阿里巴巴Qwen系列
Qwen2.5 (2024年9月发布)
- 主要使用DPO进行对齐训练
- 结合了一些定制化的偏好优化技术
- 特别优化了中文理解和生成能力
Qwen3 (2025年6月)
- 预计会采用更先进的优化方法
- 可能使用GSPO的优势
- 更注重多语言和多模态对齐
DeepSeek系列
DeepSeek-V3
- 主要采用DPO进行训练
- 结合了GRPO优化技术
- 特别注重数学和代码能力的对齐
智谱AI GLM系列
GLM-3
- 采用PPO进行RLHF训练
- 结合了中文语言特点的优化
GLM-4 (2024年发布)
- 主要使用DPO方法
- 加入了多轮对话的特殊优化
- 改进了安全性和有用性平衡
实际应用中的选择建议
场景1:资源受限的研究环境
推荐方法:DPO
- 原因:无需训练奖励模型,降低计算成本
- 适用于:中小规模模型,有限的计算资源
场景2:大规模工业应用
推荐方法:PPO或混合方法
- 原因:更稳定,可控性强
- 适用于:对质量要求极高的商业产品
场景3:多样性要求高的创作任务
推荐方法:GRPO
- 原因:能更好地处理多样性
- 适用于:创意写作,多风格生成
场景4:噪声数据较多的环境
推荐方法:GSPO
- 原因:对数据质量要求较低
- 适用于:数据质量参差不齐的实际应用
未来发展趋势
技术发展方向
-
混合优化方法
- 结合多种方法的优势
- 根据任务特点动态选择优化策略
-
在线学习能力
- 实时从用户交互中学习
- 持续改进模型表现
-
多目标优化
- 同时优化有用性、安全性、创造性等多个维度
- 平衡不同目标之间的冲突
-
更高效的训练方法
- 减少训练成本
- 提高训练效率
挑战与机遇
主要挑战:
- 数据质量和规模的平衡
- 不同文化和价值观的对齐
- 长期对话中的一致性保持
- 计算资源的合理利用
发展机遇:
- 多模态模型的对齐优化
- 个性化偏好学习
- 零样本和少样本场景下的快速对齐
- 可解释性增强
实践建议
训练流程最佳实践
-
数据准备阶段
# 数据质量评估函数 def evaluate_data_quality(preference_data): """ 评估偏好数据集的整体质量,返回一个加权得分。 Args: preference_data: 输入的偏好数据(如人类偏好标注数据) Returns: quality_score: 一个 0~1 之间的浮点评分,越高代表数据质量越好 """ quality_score = 0 # 1. 检查标注一致性(consistency) # - 衡量不同标注者在相同样本上的一致程度 # - 一致性越高,说明数据可靠性越强 # - 权重:40% consistency = check_annotation_consistency(preference_data) quality_score += consistency * 0.4 # 2. 检查数据多样性(diversity) # - 衡量数据覆盖的范围,例如是否包含足够多的场景、问题类型、回答风格等 # - 多样性越高,模型泛化能力越强 # - 权重:30% diversity = check_data_diversity(preference_data) quality_score += diversity * 0.3 # 3. 检查标注质量(annotation_quality) # - 衡量单条标注是否符合规则,比如是否清晰、是否有逻辑错误、是否含糊 # - 质量越高,训练效果越好 # - 权重:30% annotation_quality = check_annotation_quality(preference_data) quality_score += annotation_quality * 0.3 # 返回最终的加权质量分数 return quality_score -
超参数调优
# 不同方法的推荐超参数范围 HYPERPARAMETER_RANGES = { "PPO": { # Proximal Policy Optimization (近端策略优化) # PPO的裁剪参数,用于限制策略更新幅度,避免训练不稳定 "epsilon": [0.1, 0.2, 0.3], # 学习率,通常需要比较小的值以保证稳定训练 "learning_rate": [1e-6, 5e-6, 1e-5], # 每次更新时使用的样本批大小 "batch_size": [16, 32, 64] }, "DPO": { # Direct Preference Optimization (直接偏好优化) # 正则化系数 β,控制偏好约束的强度,值越大约束越强 "beta": [0.05, 0.1, 0.2, 0.5], # 学习率,同样推荐较小的范围 "learning_rate": [1e-6, 5e-6, 1e-5], # 每次更新使用的样本批大小 "batch_size": [8, 16, 32] }, "GRPO": { # Grouped Reinforcement Preference Optimization (分组偏好优化) # 正则化系数 β,和DPO类似,用于平衡目标与约束 "beta": [0.1, 0.2, 0.3], # 每个分组的大小,影响样本之间比较的稳定性 "group_size": [4, 8, 16], # 学习率 "learning_rate": [1e-6, 5e-6, 1e-5] }, "GSPO": { # Grouped Soft Preference Optimization (分组软偏好优化) # 正则化系数 β,调节偏好约束的强度 "beta": [0.1, 0.2, 0.3], # 偏好选择的阈值,用于控制样本之间的对比敏感度 "threshold": [0.1, 0.2, 0.3, 0.5], # 学习率 "learning_rate": [1e-6, 5e-6, 1e-5] } } -
评估指标
def comprehensive_evaluation(model, test_data): """综合评估模型性能""" metrics = {} # 有用性评估 metrics["helpfulness"] = evaluate_helpfulness(model, test_data) # 安全性评估 metrics["safety"] = evaluate_safety(model, test_data) # 多样性评估 metrics["diversity"] = evaluate_diversity(model, test_data) # 一致性评估 metrics["consistency"] = evaluate_consistency(model, test_data) # 综合分数 metrics["overall"] = ( metrics["helpfulness"] * 0.4 + metrics["safety"] * 0.3 + metrics["diversity"] * 0.2 + metrics["consistency"] * 0.1 ) return metrics
总结
PPO、DPO、GRPO、GSPO这四种最热门的方法代表了大语言模型对齐优化技术的不同发展阶段和思路。每种方法都有其独特的优势和适用场景:
- PPO作为经典方法,在复杂任务上表现稳定,但计算成本较高
- DPO简化了训练流程,降低了成本,成为当前的主流选择
- GRPO在处理多样性方面有独特优势,适合创作类任务
- GSPO通过选择性优化提高了效率,对数据质量要求较低
在实际应用中,选择哪种方法需要综合考虑计算资源、数据质量、任务特点等多个因素。随着技术的不断发展,我们也看到了越来越多的混合方法和改进版本,未来这个领域还将继续快速发展。
对于从业者而言,理解这些方法的原理和特点,能够根据具体需求选择合适的优化策略,并在实践中不断调优和改进,这些都是构建高质量大语言模型系统的关键能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)