自动驾驶大模型---SOLVE:视觉语言与端到端的协同
论文提出SOLVE模型,创新性地融合视觉语言大模型(VLM)与端到端自动驾驶系统,通过轨迹思维链(T-CoT)和时间解耦策略实现视觉感知与自然语言指令的协同。该系统采用视觉编码器、语言编码器和跨模态注意力融合模块,能理解"施工绕行"等复杂指令,并通过模仿学习优化控制决策。实验以L2距离为指标验证了方案有效性,为解决传统自动驾驶在长尾场景下的局限提供了新思路。
1 前言
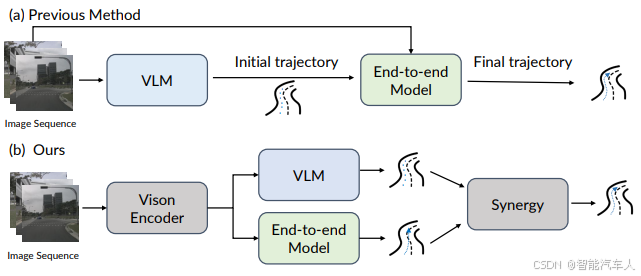
咋一听到这个标题,熟悉的读者朋友很容易联想到清华大学和理想汽车之前发表并量产的DriveVLM双系统,同样地采用了VLM视觉语言大模型和另一个E2E双模型结合的自动驾驶系统,理想汽车研发团队在量产后也提出,双系统的配合会是一个问题,因此开发了VLA架构。
那么,本次提到的论文成果核心就在于探索如何将自然语言指令与视觉感知相结合,并融入到端到端(end-to-end)的自动驾驶系统中,以提高系统的鲁棒性、可解释性以及在复杂、非常规场景下的决策能力。
2 SOLVE模型
本节主要通过介绍SOLVE(Synergy of Language-Vision and End-to-end,其中Synergy是协同的意思)的背景,核心思想及架构等多方面进行阐述。
现代自动驾驶系统在结构化和可预测的环境中取得了显著进展。然而,在面对非结构化、动态变化或包含模糊指令的复杂场景时,它们仍然面临巨大挑战。例如,当人类驾驶员需要处理“在下一个路口左转,但如果看到施工就提前变道”这样的复杂指令时,纯粹基于视觉感知的系统难以理解和执行。
- 端到端自动驾驶的优势与局限:
- 优势: 端到端系统直接将传感器输入映射到驾驶行为(如方向盘角度、油门、刹车),简化了传统模块化系统的复杂性,可能学习到更优的全局策略。
- 局限: 缺乏可解释性,难以调试;在面对训练数据中未出现过的“长尾”事件时,鲁棒性差;难以整合高层语义信息或人类指令。
- 语言在自动驾驶中的潜力: 自然语言是人类交流和理解复杂意图的强大工具。将语言引入自动驾驶系统,可以:
- 提供高层指令: 允许用户通过语音或文本给出复杂的驾驶指令(例如,“靠右行驶,准备超车”)。
- 增强场景理解: 语言可以为视觉信息提供额外的语义上下文,帮助系统理解场景中的关键元素(例如,“那辆停着的卡车”)。
- 提高可解释性: 系统可以根据语言指令来解释其行为,或生成语言描述来解释其感知到的内容。
- 处理非常规情况: 语言可以描述视觉上难以直接识别的抽象概念或意图。
2.1 核心思想
论文的核心思想是构建一个能够协同利用视觉信息和自然语言指令的端到端网络,从而实现更智能、更灵活的自动驾驶。它强调了“协同”(Synergy)这一概念,意味着语言和视觉不是简单地并行处理,而是深度融合,相互增强。
SOLVE旨在解决以下问题:
- 如何有效地将异构的视觉特征和语言特征进行融合?
- 如何让融合后的特征指导车辆的端到端控制决策?
- 如何确保系统在执行语言指令的同时,仍能安全地进行驾驶?
2.2 SOLVE网络架构
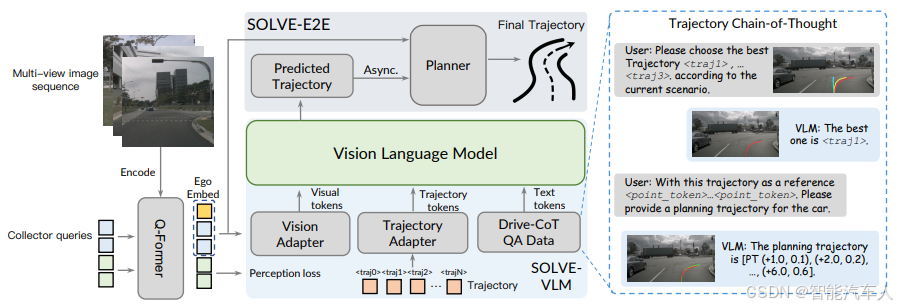
SOLVE架构包含以下几个关键模块:(1)Q-Former;(2)SOLVE-VLM;(3)SOLVE-E2E。
-
Q-Former
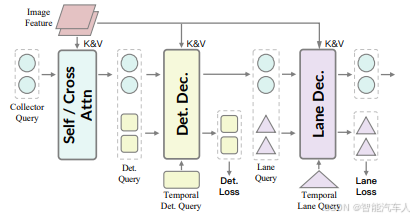
为了从观测中提取相关信息,将有用的视觉线索分为三类,如下图所示。第一类包括场景级的静态或整体环境细节,例如天气、时段和交通状况。第二类聚焦于道路上的动态参与者,如车辆和行人。第三类包含动态地图线索,例如车道。Sequential Q-Former,一种类 Q-Former 架构,它能将这些视觉线索组依次压缩为固定数量的精简视觉查询,实现感知与推理、规划的对齐。
收集器查询(Collector Query)被发送至视觉适配器(Vision Adapter),以匹配视觉 - 语言模型(VLM)的维度,同时附加一个自车标记用于轨迹预测。
接下来基本就是VLM视觉语言大模型的结构了,前面已经介绍过很多次了。
- 视觉语言大模型(SOLVE-VLM)
-
视觉编码器(Vision Encoder)
- 输入: 车辆的传感器数据,通常是多路摄像头图像(前视、侧视、后视)或激光雷达点云。
- 功能: 提取场景的视觉特征。这通常通过深度卷积神经网络(CNN)或Transformer-based的视觉骨干网络(如ResNet, EfficientNet, ViT等)实现,将原始图像转换为高维特征向量。
- 输出: 包含空间和语义信息的视觉特征图或特征向量。
-
大语言模型(LLM)
- 输入: 视觉以及文本的token。
- 功能: 将视觉以及文本的token转换为语义丰富的语言特征向量。
- 输出: 包含预测输出的一系列token。
-
-
端到端规划模块(SOLVE-E2E)
- 输入: 融合后的多模态特征和VLM输出的特征。
- 功能: 基于融合特征直接输出车辆的行驶轨迹。这可以是:
- 高级规划指令: 目标路径点序列。
- 行为预测: 预测其他交通参与者的行为,并据此调整自身策略。
- 网络结构: 多层感知机(MLP)。
2.3 训练策略
- 数据集: 需要包含视觉数据和对应的自然语言指令的自动驾驶数据集。
- 模仿学习(Imitation Learning): 最常见的方法是模仿学习,即通过监督学习,让网络学习专家驾驶员在给定视觉和语言指令下的驾驶行为。
- 损失函数: 通常包括控制损失(如L1/L2损失,用于预测的控制量与真值之间的误差)和可能的辅助损失(如语义分割损失、目标检测损失,以帮助视觉模块更好地理解场景)。
2.4 实验结果
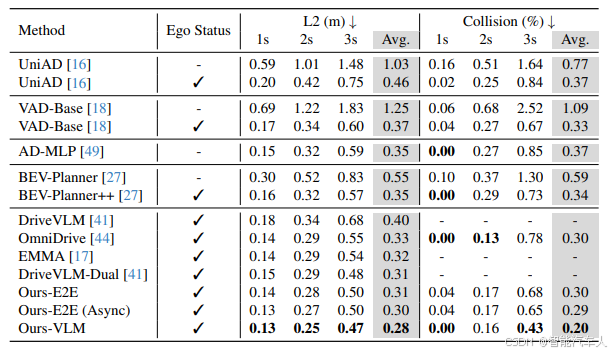
评价指标主要是不同时刻的L2范式距离和碰撞概率,对比结果如下。
3 总结
SOLVE 这一创新框架旨在促进视觉 - 语言模型(VLM)与端到端(E2E)模型之间的协同作用,重点强调知识与规划的融合。为解决视觉 - 语言模型在以自回归方式直接生成细粒度轨迹时面临的挑战,提出了轨迹思维链(T-CoT)方法,该方法利用预定义的轨迹库和链式推理逐步优化轨迹。此外,还提出了一种时间解耦策略,以促进视觉 - 语言模型与端到端模型之间的协作。
参考论文:《SOLVE: Synergy of Language-Vision and End-to-end Network for Autonomous Driving》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)