n8n智能体开发:处理不同数据类型
下面将学习如何使用 n8n 核心节点 处理不同类型的数据。
HTML 和 XML 数据#
您可能对 HTML 和 XML 都很熟悉。
HTML 与 XML 的区别
HTML 是一种标记语言,用于描述网页的结构和语义。XML 看起来与 HTML 相似,但标签名称不同,因为它们描述的是所包含数据的类型。
如果需要在 n8n 工作流中处理 HTML 或 XML 数据,可以使用 HTML 节点 或 XML 节点。
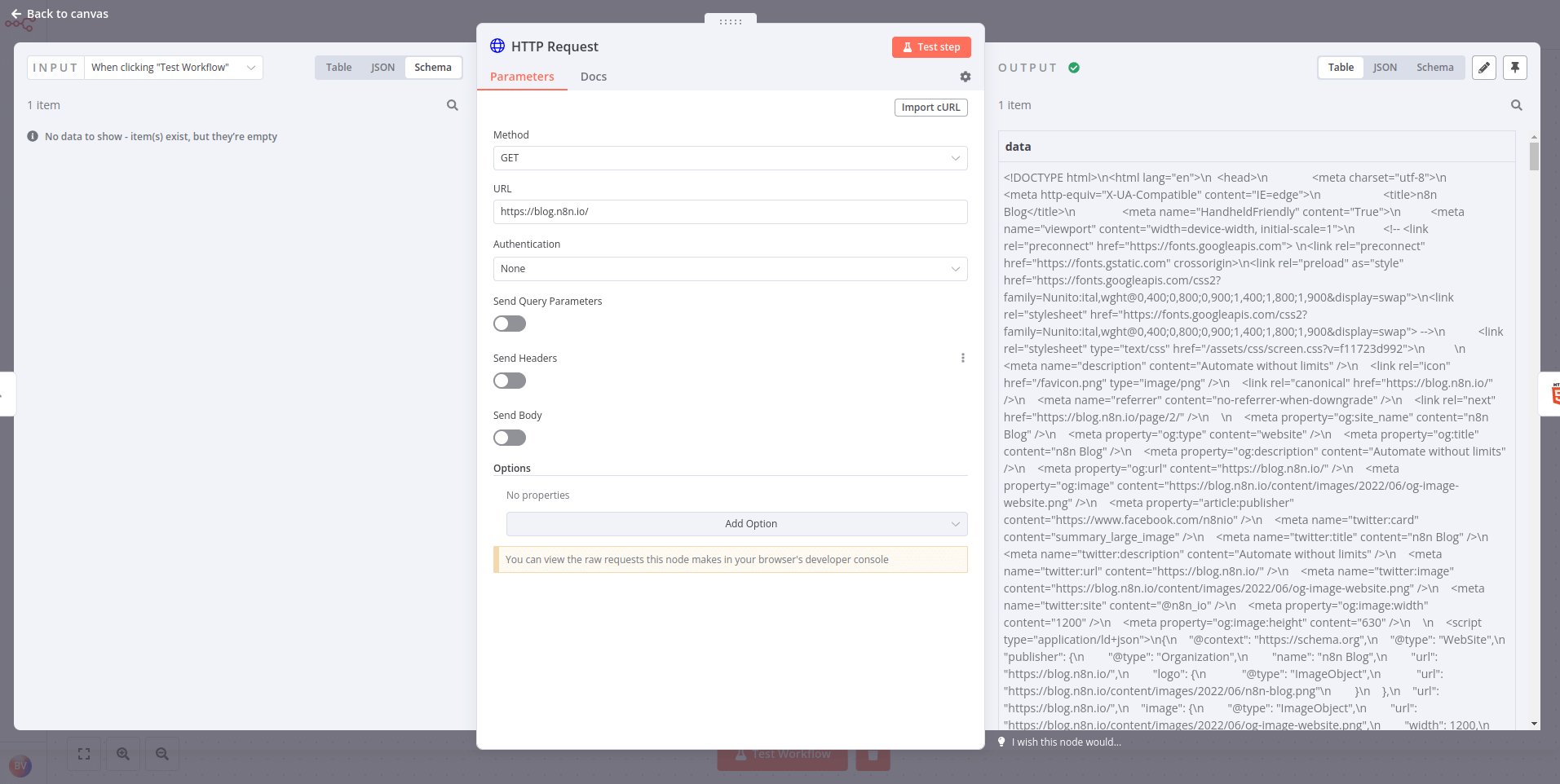
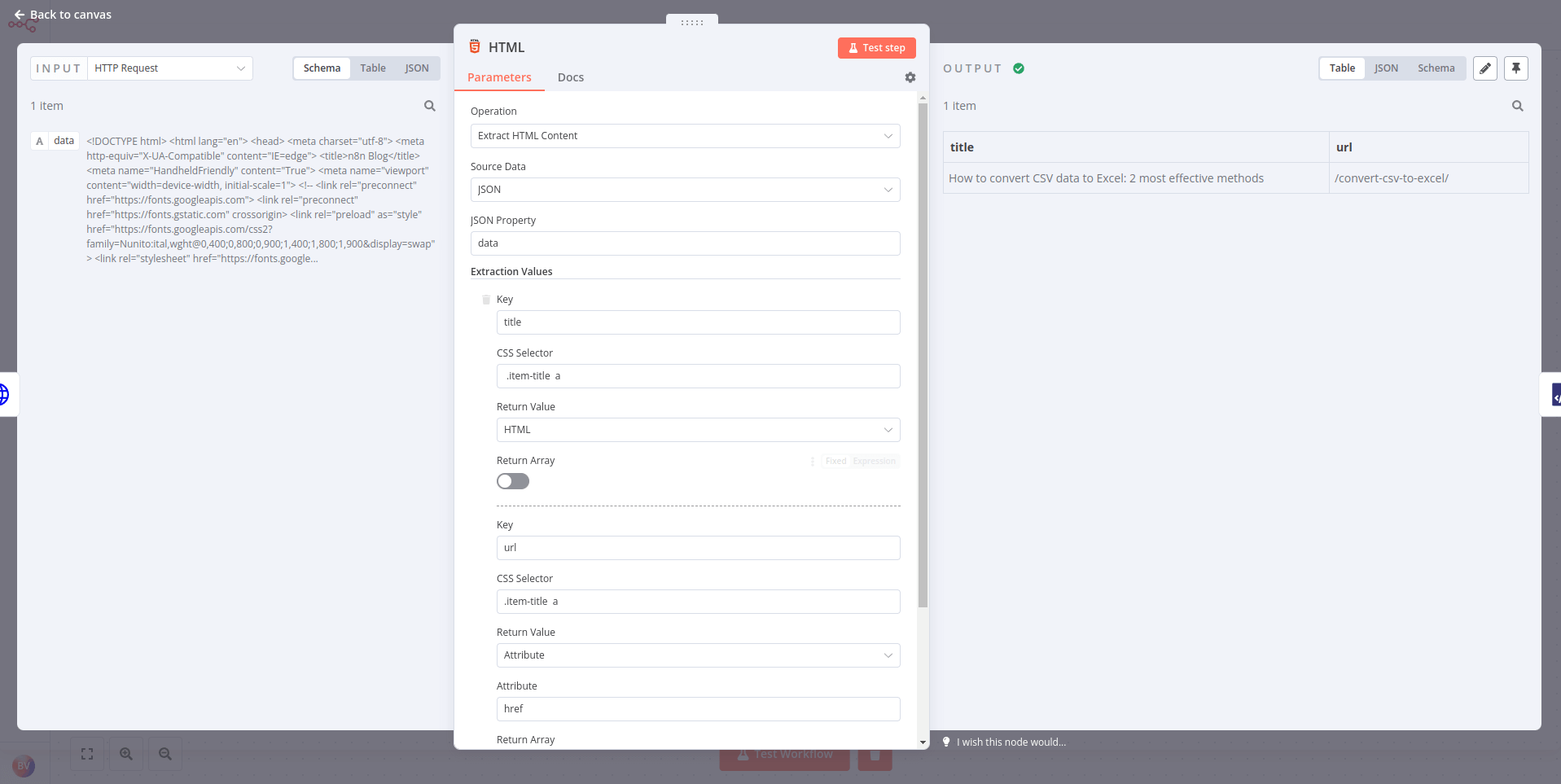
使用 HTML 节点 通过引用 CSS 选择器来提取网页的 HTML 内容。这在您想从网站收集结构化信息(网络爬取)时非常有用。
HTML 练习#
让我们获取最新的 n8n 博客文章标题:
- 使用 HTTP Request 节点 向 URL
https://blog.n8n.io/发送 GET 请求(此端点无需认证)。 - 连接一个 HTML 节点 并配置它以提取页面上第一篇博客文章的标题。
- 提示:如果您不熟悉 CSS 选择器或阅读 HTML,可以使用 CSS 选择器
.post .item-title a来定位!
- 提示:如果您不熟悉 CSS 选择器或阅读 HTML,可以使用 CSS 选择器
显示解决方案
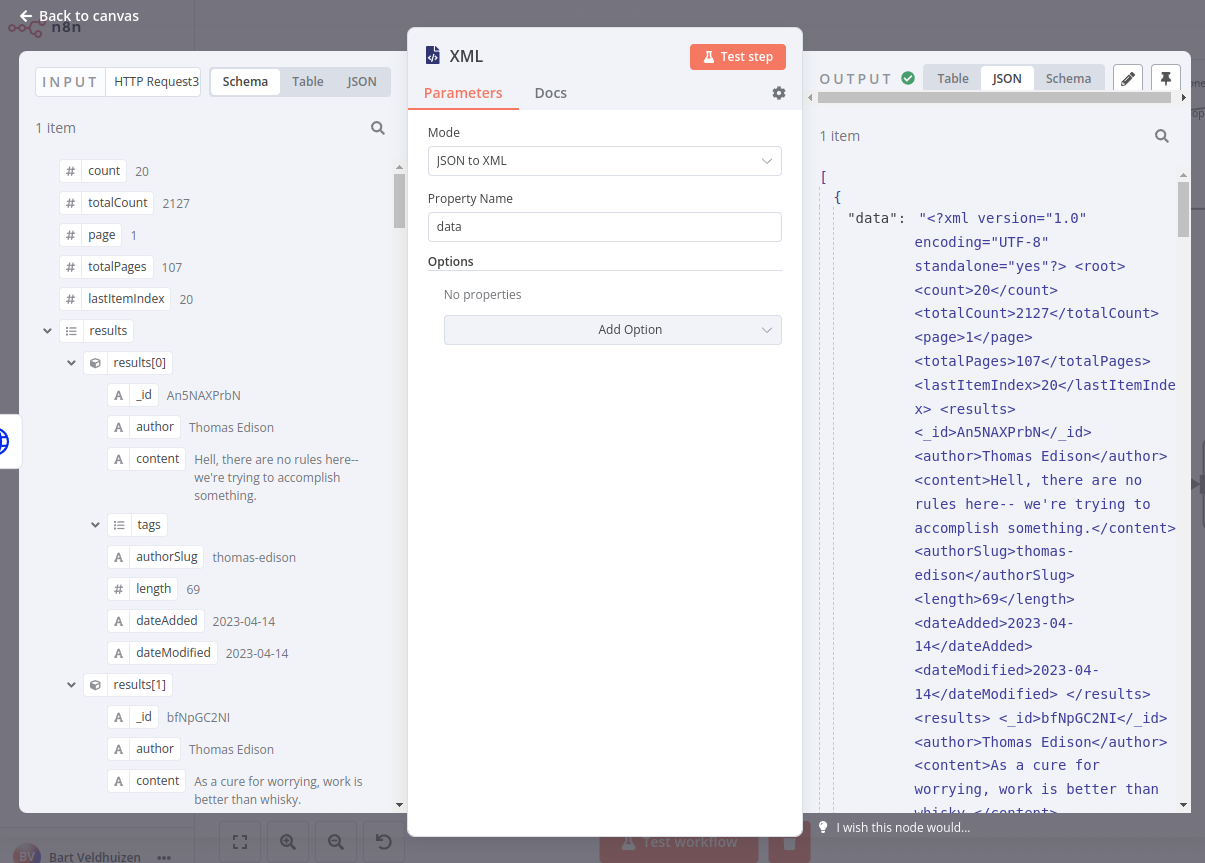
使用 XML 节点 在 XML 和 JSON 之间相互转换。当您需要与使用不同格式(XML 或 JSON)的 Web 服务交互并在它们之间获取和提交数据时,此操作非常有用。
XML 练习#
在第一章的最终练习中,您使用了 HTTP Request 节点 向 PokéAPI 发起请求。本练习中,我们将再次使用该 API,但会将输出转换为 XML 格式:
- 添加一个 HTTP Request 节点,向 PokéAPI 发起相同请求,地址为
https://pokeapi.co/api/v2/pokemon。 - 使用 XML 节点将 JSON 输出转换为 XML。
显示解决方案
日期、时间和间隔数据#
日期和时间数据类型包括 DATE、TIME、DATETIME、TIMESTAMP 和 YEAR。日期和时间可以以不同格式传递,例如:
DATE: 2022年3月29日, 29-03-2022, 2022/03/29TIME: 08:30:00, 8:30, 20:30DATETIME: 2022/03/29 08:30:00TIMESTAMP: 1616108400 (Unix时间戳), 1616108400000 (Unix毫秒时间戳)YEAR: 2022, 22
处理日期和时间有几种方法:
有时您可能需要暂停工作流执行。当您知道某个服务不会立即处理数据或返回所有结果较慢时,这很有必要。在这些情况下,您不希望n8n将不完整的数据传递给下一个节点。
如果遇到这种情况,请在需要延迟的节点后使用等待节点。等待节点会暂停工作流执行,并在以下情况下恢复执行:
- 在特定时间
- 经过指定时间间隔后
- 收到webhook调用时
日期练习#
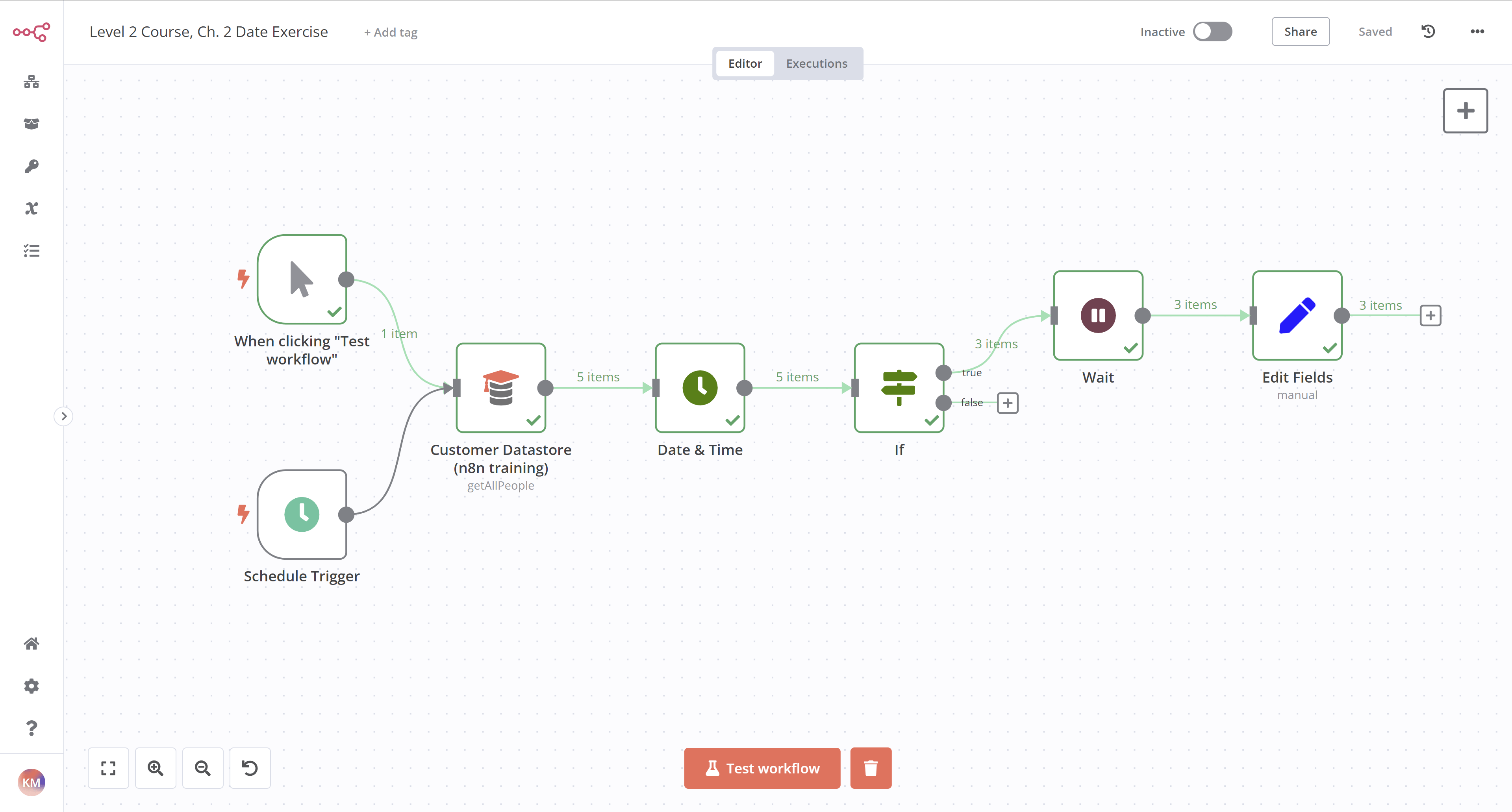
构建一个工作流,将之前使用的 Customer Datastore 节点中的输入日期增加五天。然后,如果计算后的日期晚于 1959 年,工作流会等待 1 分钟,再将计算后的日期设置为一个值。该工作流应每 30 分钟触发一次。
开始步骤:
- 添加 Customer Datastore (n8n training) 节点,选择 Get All People 操作。返回所有记录。
- 添加 Date & Time 节点,将数据存储中的创建日期向上舍入到月末。输出到 new-date 字段。包含所有输入字段。
- 添加 If 节点 检查新的舍入日期是否晚于
1960-01-01 00:00:00。 - 在该节点的 True 输出分支添加 Wait 节点,设置为等待一分钟。
- 添加 Edit Fields (Set) 节点,设置一个名为 outputValue 的新字段,其值为包含 new-date 的字符串。包含所有输入字段。
- 在工作流开头添加 Schedule Trigger 节点,设置为每 30 分钟触发一次。(可以保留手动触发节点用于测试!)
显示解决方案
二进制数据#
到目前为止,您主要处理的是文本数据。但如果您需要处理非文本数据(如图片或 PDF 文件)该怎么办?这类文件以二进制数字系统表示,因此被视为二进制数据。在这种形式下,二进制数据无法提供有用信息,您需要将其转换为可读格式。
在 n8n 中,您可以使用以下节点处理二进制数据:
- HTTP Request - 从网络资源和 API 请求/发送文件
- Read/Write Files from Disk - 从运行 n8n 的机器读写文件
- Convert to File - 将输入数据输出为文件
- Extract From File - 从二进制格式提取数据并转换为 JSON
文件读写功能仅限自托管版 n8n
n8n 云版本不支持磁盘文件读写操作。读写操作将在安装 n8n 的机器上执行。如果您在 Docker 中运行 n8n,命令将在 n8n 容器内执行而非 Docker 宿主机。Read/Write Files From Disk 节点会相对于 n8n 安装路径查找文件。n8n 建议使用绝对文件路径以避免错误。
要读写二进制文件,您需要在节点的 File(s) Selector 参数(读取操作)或 File Path and Name 参数(写入操作)中填写文件路径(位置)。
正确命名路径
文件路径的表示方式因 n8n 运行方式而异:
- npm 安装:
~/my_file.json - n8n 云/Docker 环境:
/tmp/my_file.json
二进制数据练习 1#
在我们的第一个二进制数据练习中,让我们将一个 PDF 文件转换为 JSON:
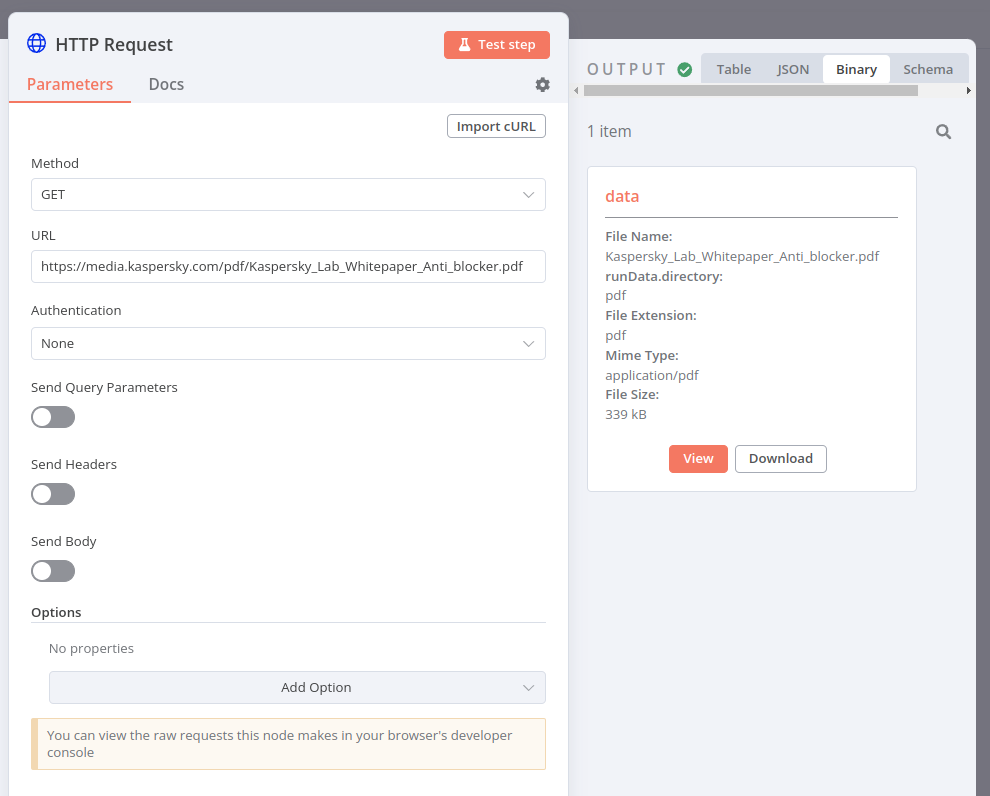
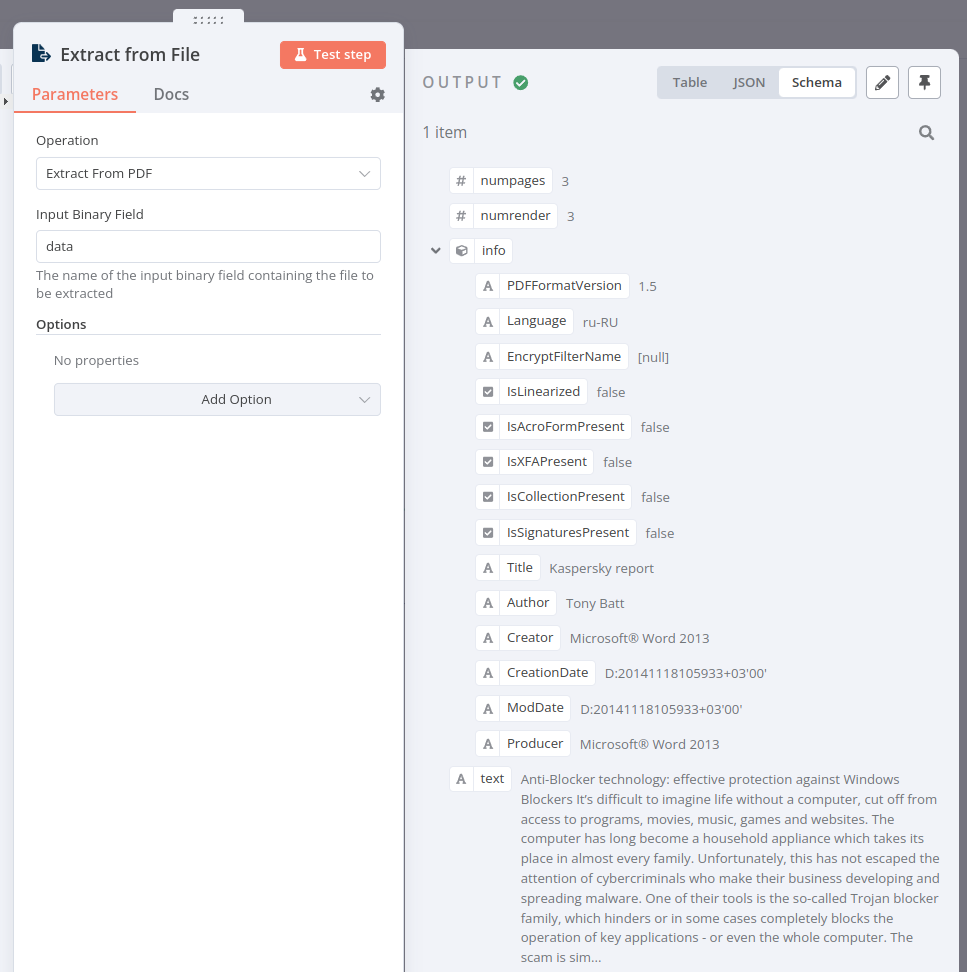
- 发起 HTTP 请求获取这个 PDF 文件:
https://media.kaspersky.com/pdf/Kaspersky_Lab_Whitepaper_Anti_blocker.pdf. - 使用 Extract From File 节点 将文件从二进制格式转换为 JSON。
显示解决方案
二进制数据练习 2#
在我们的第二个二进制数据练习中,让我们将一些 JSON 数据转换为二进制:
- 向 Poetry DB API
https://poetrydb.org/random/1发起 HTTP 请求 - 使用 Convert to File 节点 将返回的数据从 JSON 转换为二进制
- 使用 Read/Write Files From Disk 节点 将新的二进制文件数据写入运行 n8n 的机器
- 为了验证操作是否成功,使用 Read/Write Files From Disk 节点 读取生成的二进制文件
《动手学PyTorch建模与应用:从深度学习到大模型》是一本从零基础上手深度学习和大模型的PyTorch实战指南。全书共11章,前6章涵盖深度学习基础,包括张量运算、神经网络原理、数据预处理及卷积神经网络等;后5章进阶探讨图像、文本、音频建模技术,并结合Transformer架构解析大语言模型的开发实践。书中通过房价预测、图像分类等案例讲解模型构建方法,每章附有动手练习题,帮助读者巩固实战能力。内容兼顾数学原理与工程实现,适配PyTorch框架最新技术发展趋势。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)