基于langchain的 youtube多功能 Tool Calling Agent
安装库导入库本地执行可以先设置全局key。
安装库
%%capture
%pip install pytube
%pip install youtube-transcript-api==1.1.0
%pip install langchain-community==0.3.16
%pip install langchain==0.3.23
%pip install langchain-openai==0.3.14
%pip install yt-dlp
导入库
import re
from pytube import YouTube
from langchain_core.tools import tool
from IPython.display import display, JSON
import yt_dlp
from typing import List, Dict
from langchain_core.messages import HumanMessage
from langchain_core.messages import ToolMessage
import json
# Suppress warnings
import warnings
warnings.filterwarnings("ignore")
# Suppress pytube errors
import logging
pytube_logger = logging.getLogger('pytube')
pytube_logger.setLevel(logging.ERROR)
# Suppress yt-dlp warnings
yt_dpl_logger = logging.getLogger('yt_dlp')
yt_dpl_logger.setLevel(logging.ERROR)
本地执行可以先设置全局key
os.environ["API_KEY"] = "your API key here"
创建tools
定义一个函数extract_video_id,该工具将从给定的URL中提取视频ID。许多YouTube API操作,包括文本提取,需要视频ID而不是完整的URL。该函数使用正则表达式处理不同的YouTube URL格式(标准、缩短和嵌入),并提取11个字符的视频ID。
tools = []
@tool
def extract_video_id(url: str) -> str:
"""
Extracts the 11-character YouTube video ID from a URL.
Args:
url (str): A YouTube URL containing a video ID.
Returns:
str: Extracted video ID or error message if parsing fails.
"""
# Regex pattern to match video IDs
pattern = r'(?:v=|be/|embed/)([a-zA-Z0-9_-]{11})'
match = re.search(pattern, url)
return match.group(1) if match else "Error: Invalid YouTube URL"
tools.append(extract_video_id)
#测试(可选)
print(extract_video_id.name)
print("----------------------------")
print(extract_video_id.description)
print("----------------------------")
print(extract_video_id.func)
extract_video_id.run("https://www.youtube.com/watch?v=hfIUstzHs9A")
现在 从YouTube视频中获取字幕。这个工具使用YouTubeTranscriptApi库从视频中检索标题或字幕。输入视频ID(可以使用之前的工具提取)和可选的语言参数。该函数将获取记录并将所有文本段连接到一个连续的字符串中,如果无法检索到记录,则返回一条错误消息。
from youtube_transcript_api import YouTubeTranscriptApi
@tool
def fetch_transcript(video_id: str, language: str = "en") -> str:
"""
Fetches the transcript of a YouTube video.
Args:
video_id (str): The YouTube video ID (e.g., "dQw4w9WgXcQ").
language (str): Language code for the transcript (e.g., "en", "es").
Returns:
str: The transcript text or an error message.
"""
try:
ytt_api = YouTubeTranscriptApi()
transcript = ytt_api.fetch(video_id, languages=[language])
return " ".join([snippet.text for snippet in transcript.snippets])
except Exception as e:
return f"Error: {str(e)}"
#加入工具列表
tools.append(fetch_transcript)
#测试
fetch_transcript.run(" hfIUstzHs9A")#前面extract_video_id获取
tools.append(fetch_transcript)
下面创建一个搜索工具,允许根据查询字符串查找YouTube上的视频。这个工具使用PyTube库中的Search类在YouTube上执行搜索。当给定一个搜索词时,它返回一个匹配视频的列表,其中每个视频表示为包含标题、视频ID和缩短的URL的字典。这个工具将有助于发现相关的视频,当你还没有一个特定的URL在脑海中。
from pytube import Search
from langchain.tools import tool
from typing import List, Dict
@tool
def search_youtube(query: str) -> List[Dict[str, str]]:
"""
Search YouTube for videos matching the query.
Args:
query (str): The search term to look for on YouTube
Returns:
List of dictionaries containing video titles and IDs in format:
[{'title': 'Video Title', 'video_id': 'abc123'}, ...]
Returns error message if search fails
"""
try:
s = Search(query)
return [
{
"title": yt.title,
"video_id": yt.video_id,
"url": f"https://youtu.be/{yt.video_id}"
}
for yt in s.results
]
except Exception as e:
return f"Error: {str(e)}"
#加入工具列表
tools.append(search_youtube)
#测试
search_out=search_youtube.run("Generative AI")
display(JSON(search_out))
output:
继续创建一个工具,使用yt-dlp库从YouTube视频中提取详细的元数据。该工具采用YouTube URL并返回有关视频的全面信息,包括其标题,观看次数,持续时间,频道名称,喜欢数量,评论数量和任何章节标记。
@tool
def get_full_metadata(url: str) -> dict:
"""Extract metadata given a YouTube URL, including title, views, duration, channel, likes, comments, and chapters."""
with yt_dlp.YoutubeDL({'quiet': True, 'logger': yt_dpl_logger}) as ydl:
info = ydl.extract_info(url, download=False)
return {
'title': info.get('title'),
'views': info.get('view_count'),
'duration': info.get('duration'),
'channel': info.get('uploader'),
'likes': info.get('like_count'),
'comments': info.get('comment_count'),
'chapters': info.get('chapters', [])
}
#加入列表
tools.append(get_full_metadata)
#测试
meta_data=get_full_metadata.run("https://youtu.be/qWHaMrR5WHQ")
display(JSON(meta_data))
output:
创建建一个工具来提取YouTube视频的所有可用缩略图图像。该工具使用yt-dlp检索有关YouTube为不同分辨率的视频生成的各种缩略图图像的信息。对于每个缩略图,收集其URL、宽度、高度和格式化的分辨率。
@tool
def get_thumbnails(url: str) -> List[Dict]:
"""
Get available thumbnails for a YouTube video using its URL.
Args:
url (str): YouTube video URL (any format)
Returns:
List of dictionaries with thumbnail URLs and resolutions in YouTube's native order
"""
try:
with yt_dlp.YoutubeDL({'quiet': True, 'logger': yt_dpl_logger}) as ydl:
info = ydl.extract_info(url, download=False)
thumbnails = []
for t in info.get('thumbnails', []):
if 'url' in t:
thumbnails.append({
"url": t['url'],
"width": t.get('width'),
"height": t.get('height'),
"resolution": f"{t.get('width', '')}x{t.get('height', '')}".strip('x')
})
return thumbnails
except Exception as e:
return [{"error": f"Failed to get thumbnails: {str(e)}"}]
tools.append(get_thumbnails)
output:
Binding tools
llm_with_tools = llm.bind_tools(tools)
bind_tools将每个工具的属性(名称、描述、参数模式)转换为语言模型能够理解的标准化格式,
以便根据用#户请求确定何时以及如何调用特定工具。类似于以下代码,其中每个工具的模式都被存储起来:
for tool in tools:
schema = {
"name": tool.name,
"description": tool.description,
"parameters": tool.args_schema.schema() if tool.args_schema else {},
"return": tool.return_type if hasattr(tool, "return_type") else None}
display(JSON(schema))
llm调用tools以及三种message作用
#humanmessage
query = "I want to summarize youtube video: https://www.youtube.com/watch?v=T-D1OfcDW1M in english"
messages = [HumanMessage(content = query)]
#aimessage
response_1 = llm_with_tools.invoke(messages)
messages.append(response_1)
在收到LLM的响应后,需要提取结构化工具调用信息。tool_calls_1 = response_1.tool_calls 获取工具调用对象,其中包含LLM决定使用的工具以及要传递给它的参数。此信息将用于执行具有正确输入的适当工具。现创建一个字典,将工具名称映射到相应的函数对象。以便后面调用工具。当您只有作为字符串的工具名称时,它允许您轻松查找和执行工具函数,这在处理来自语言模型的工具调用时非常重要。
tool_mapping = {
"get_thumbnails" : get_thumbnails,
"get_trending_videos": get_trending_videos,
"extract_video_id": extract_video_id,
"fetch_transcript": fetch_transcript,
"search_youtube": search_youtube,
"get_full_metadata": get_full_metadata
}
从语言模型的响应中提取工具调用。当LLM确定它需要使用您的哪一个工具时,它会在响应中包含结构化的“tool_calls”。在tool_calls里可以查看模型决定使用哪些工具来完成关于总结YouTube视频的请求。
tool_calls_1 = response_1.tool_calls
display(JSON(tool_calls_1))
output: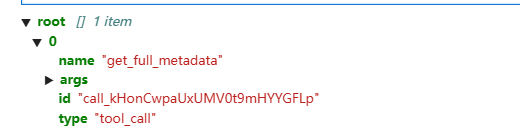
在这里,你看到的是大语言模型(LLM)决定进行的工具调用的结构。该工具调用被格式化为一个字典,包含以下关键组成部分:
1. name: 这标识了大语言模型(LLM)首先想要使用的工具;
2. args:包含要传递给工具的参数 —— 在这种情况下,是来自你的查询的 YouTube 网址;
3. id:这个特定工具调用的唯一标识符,有助于跟踪请求 / 响应对;
4. type:表明这是工具调用,而非其他类型的人工智能响应。
# 需要的工具传入需要的参数,这些都由llm决定了
my_tool=tool_mapping[tool_calls_1[0]['name']]
tool_output= my_tool.invoke(tool_calls_1[0]['args'])
将工具的输出添加到你的对话历史中。你需要创建一条toolmessage,其中包含:
1. 执行工具的结果
2. 原始的工具调用 ID,以将此响应与特定请求关联起来。
通过将这条消息添加到对话历史中,你是在告知大语言模型工具执行的结果,它可以在下次响应时使用这些结果。
#toolmessage
messages.append(ToolMessage(content =tooloutput , tool_call_id = tool_calls_1[0]['id']))
response_2 = llm_with_tools.invoke(messages)
response_2#这里又变成aimessage
messages.append(response_2)
将更新后的对话储存并再次发送给大语言模型(LLM)。模型会查看原始查询和先前的结果,从而确定该 YouTube 视频所需的下一步操作,也就是确定下一步还需要什么工具从而能够完成任务。
后面的过程和第一轮一样,获取工具及参数,得到的结果用toolmessage包装,再交给llm继续判断总结
自动化tool calling过程
上面手动演示了整个tool calling过程,会比较繁琐,现在创建一个函数来自动化工具调用。输入是工具调用对象,从中提取名称,并使用 tool_mapping 字典找到要调用的正确函数。你会将工具调用中的参数传递给这个函数,然后将输出作为包含 tool_call_id 的 ToolMessage 返回。tool_call_id 是这个过程中必不可少的部分,因为它将每个工具响应与语言模型发出的特定工具请求关联起来。当多个工具被依次或同时调用时,这个 ID 确保大语言模型能够将响应与其请求相匹配,这一点至关重要。如果没有这个 ID,大语言模型将无法知道哪个响应对应哪个请求,从而使多步骤推理变得不可能。
def execute_tool(tool_call):
"""Execute single tool call and return ToolMessage"""
try:
result = tool_mapping[tool_call["name"]].invoke(tool_call["args"])
return ToolMessage(
content=str(result),
tool_call_id=tool_call["id"]
)
except Exception as e:
return ToolMessage(
content=f"Error: {str(e)}",
tool_call_id=tool_call["id"]
)
现在要将所有的函数或工具串联起来,但在此之前,需要正确格式化数据。这里不仅要存储每个工具的输出,还需要存储诸如工具 ID 之类的状态信息。为了有效地做到这一点,必须确保每个工具的输出能够恰当地传递到流程中的下一步。RunnablePassthrough 组件允许在整个链中维持状态,同时在每个步骤添加或转换数据,这使其非常适合将各种工具连接成一个连贯的工作流。位于链末端的 RunnableLambda 则有不同的用途 —— 它只提取你想要呈现给用户的最终结果。在所有工具调用和消息处理完成后,会得到一个包含许多字段的丰富状态对象,但用户通常只需要最终答案。RunnableLambda 会将这个完整的状态转换为你想要返回的信息。
summarization_chain = (
# Start with initial query
RunnablePassthrough.assign(
messages=lambda x: [HumanMessage(content=x["query"])]
)
# First LLM call (extract video ID)
| RunnablePassthrough.assign(
ai_response=lambda x: llm_with_tools.invoke(x["messages"])
)
# 处理first tool call
| RunnablePassthrough.assign(
tool_messages=lambda x: [
execute_tool(tc) for tc in x["ai_response"].tool_calls
]
)
# 更新 message history
| RunnablePassthrough.assign(
messages=lambda x: x["messages"] + [x["ai_response"]] + x["tool_messages"]
)
# Second LLM call (fetch transcript)
| RunnablePassthrough.assign(
ai_response2=lambda x: llm_with_tools.invoke(x["messages"])
)
# 处理 second tool call
| RunnablePassthrough.assign(
tool_messages2=lambda x: [
execute_tool(tc) for tc in x["ai_response2"].tool_calls
]
)
# Final message update
| RunnablePassthrough.assign(
messages=lambda x: x["messages"] + [x["ai_response2"]] + x["tool_messages2"]
)
# 生成final summary
| RunnablePassthrough.assign(
summary=lambda x: llm_with_tools.invoke(x["messages"]).content
)
# 只返回 summary text
| RunnableLambda(lambda x: x["summary"])
)
#测试
result = summarization_chain.invoke({
"query": "Summarize this YouTube video: https://www.youtube.com/watch?v=t97ipSIDEfU"
})
print("Video Summary:\n", result)
模块化的chain写法
#定义第一个call
first_llm_call = RunnablePassthrough.assign(
ai_response=lambda x: llm_with_tools.invoke(x["messages"])
)
#处理first tool call
first_tool_processing = RunnablePassthrough.assign(
tool_messages=lambda x: [
execute_tool(tc) for tc in x["ai_response"].tool_calls
]
).assign(
messages=lambda x: x["messages"] + [x["ai_response"]] + x["tool_messages"]
)
#
second_llm_call = RunnablePassthrough.assign(
ai_response2=lambda x: llm_with_tools.invoke(x["messages"])
)
#第二个tool call
second_tool_processing = RunnablePassthrough.assign(
tool_messages2=lambda x: [
execute_tool(tc) for tc in x["ai_response2"].tool_calls
]
).assign(
messages=lambda x: x["messages"] + [x["ai_response2"]] + x["tool_messages2"]
)
#处理第二个
final_summary = RunnablePassthrough.assign(
summary=lambda x: llm_with_tools.invoke(x["messages"]).content
) | RunnableLambda(lambda x: x["summary"])
chain = (
initial_setup
| first_llm_call
| first_tool_processing
| second_llm_call
| second_tool_processing
| final_summary
)
Recursive chain flow
上面已经创建了一个适用于特定两步工具调用流程的chain,现在可以考虑更复杂的场景。你当前的chain仅限于固定顺序的恰好两次工具调用。在实际应用中,根据用户的查询,你可能需要不定数量的工具调用 —— 例如,获取热门视频,然后为每个视频获取元数据,或者搜索某个主题的视频,然后获取多个结果的文字记录。为了处理这些更复杂的场景,需要构建一个递归链条,它能够动态决定需要多少次工具调用,并持续处理直到收集到所有必要的信息。首先构建通用的工具执行方法
from langchain_core.runnables import RunnableBranch, RunnableLambda
from langchain_core.messages import HumanMessage, ToolMessage
import json
def execute_tool(tool_call):
"""Execute single tool call and return ToolMessage"""
try:
result = tool_mapping[tool_call["name"]].invoke(tool_call["args"])
content = json.dumps(result) if isinstance(result, (dict, list)) else str(result)
except Exception as e:
content = f"Error: {str(e)}"
return ToolMessage(
content=content,
tool_call_id=tool_call["id"]
)
接下来的函数是处理递归链的核心。它接收当前的对话历史,并执行以下操作:
1. 识别对话中最新的消息;
2. 从该消息中提取所有工具调用,并使用 execute_tool 辅助函数并行执行它们;
3. 通过添加工具响应消息来更新消息历史;
4. 基于更新后的对话从语言模型获取下一个响应;
5. 返回包含工具响应和新的大语言模型响应的完整更新后的消息历史。
def process_tool_calls(messages):
"""Recursive tool call processor"""
last_message = messages[-1]
# Execute all tool calls in parallel
tool_messages = [
execute_tool(tc)
for tc in getattr(last_message, 'tool_calls', [])
]
# Add tool responses to message history
updated_messages = messages + tool_messages
# Get next LLM response
next_ai_response = llm_with_tools.invoke(updated_messages)
return updated_messages + [next_ai_response]
创建递归停止判断函数,此函数用于判断递归过程应继续还是终止。它的作用如下:
1. 获取当前的消息历史并查看最后一条消息;
2. 使用 getattr 函数检查该消息是否包含任何工具调用(该函数可安全处理属性可能不存在的情况);
3. 返回一个布尔值 —— 如果有更多工具调用需要处理,则返回 True;当达到大语言模型已提供最终答案且未请求额外工具的状态时,则返回 False。
def should_continue(messages):
"""Check if you need another iteration"""
last_message = messages[-1]
return bool(getattr(last_message, 'tool_calls', None))
recursive_chain函数:
1. 它首先使用 should_continue 函数检查终止条件,以确定是否需要调用更多工具;
2. 如果需要更多工具调用,它会使用 process_tool_calls 函数处理这些调用,然后使用更新后的消息递归调用自身;
3. 如果不需要更多工具调用,它会返回最终的消息历史,其中包含完整的对话,包括大语言模型的最终响应。
4. 定义此递归函数后,将把它包装在 RunnableLambda 中,使其与 LangChain 的链架构兼容。
def _recursive_chain(messages):
"""Recursively process tool calls until completion"""
if should_continue(messages):
new_messages = process_tool_calls(messages)
return _recursive_chain(new_messages)
return messages
recursive_chain = RunnableLambda(_recursive_chain)
最后构建完整的通用chain,它能够处理任何需要调用任意数量工具的查询。这个链条包含三个主要步骤:
1.将用户的查询转换为格式正确的 HumanMessage 对象
2.将这条初始消息发送给配备了工具的大语言模型(LLM),并将大语言模型的首次响应添加到消息历史中
3.将对话传递给你的递归链条,该链条会处理所有后续的工具调用,直到大语言模型给出最终答案
这个通用链条比你之前的固定步骤链条灵活得多,因为它能够动态适应那些需要不同数量和类型工具调用的查询。
universal_chain = (
RunnableLambda(lambda x: [HumanMessage(content=x["query"])])
| RunnableLambda(lambda messages: messages + [llm_with_tools.invoke(messages)])
| recursive_chain
)
#测试
print(universal_chain.invoke({
"query": "Show top 3 US trending videos with metadata and thumbnails"
})[-1])

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)