开始 ComfyUI 的 AI 绘图之旅-文生图(一)
文章标题
一、什么是ComfyUI?
ComfyUI 是一个基于节点的生成式 AI 界面和推理引擎,用户可以通过节点组合各种 AI 模型和操作,实现高度可定制和可控的内容生成
,ComfyUI 完全开源,可以在本地设备上运行。
来源:https://docs.comfy.org/zh-CN
The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface.
最强大的开源节点式生成式 AI 应用程序
来源:https://github.com/comfyanonymous/ComfyUI/
二、安装 ComfyUI
1.系统要求
-
Python 版本
推荐 Python 3.12
支持 Python 3.13(部分自定义节点可能不兼容)
-
支持的硬件
NVIDIA 显卡
AMD 显卡
Intel 显卡(包括 Arc 系列,支持 IPEX)
Apple Silicon(M1/M2)
Ascend NPU
Cambricon MLU
CPU(可用 —cpu 参数,速度较慢) -
依赖
需安装 PyTorch(不同硬件需不同版本,详见下方)
需安装 ComfyUI 的 requirements.txt 中所有依赖
来源:https://docs.comfy.org/zh-CN/installation/system_requirements
2.Windows和Mac安装
直接下载安装即可:https://www.comfy.org/zh-cn/download
3.Linux安装
# 安装稳定的PyTorch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu129
# 安装PyTorch nightly可能会提高性能
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu129
pip install -r requirements.txt
python main.py
来源:https://github.com/comfyanonymous/ComfyUI?tab=readme-ov-file#nvidia
4.添加外部模型路径
如果你在计算机上的 ComfyUI 安装目录之外的其他位置存储了模型,可以通过配置 extra_model_paths.yaml 文件将它们添加到 ComfyUI 中。对于 ComfyUI 桌面版,对应文件路径为:
- Windows:
C:\Users\<你的用户名>\AppData\Roaming\ComfyUI\extra_model_paths.yaml - macOS:
~/Library/Application Support/ComfyUI/extra_model_paths.yaml - Linux:
~/.config/ComfyUI/extra_model_paths.yaml
来源:https://docs.comfy.org/zh-CN/installation/manual_install#%E6%B7%BB%E5%8A%A0%E5%A4%96%E9%83%A8%E6%A8%A1%E5%9E%8B%E8%B7%AF%E5%BE%84
三、开始AI 绘图之旅
来源:https://docs.comfy.org/zh-CN/get_started/first_generation
本部分教程将会带你完成首次 ComfyUI 的图片生成,了解并熟悉 ComfyUI 中的一些界面基础操作,如工作流加载、模型安装、图片生成等。
本篇的主要目的是带你初步了解 ComfyUI 熟悉 ComfyUI 的一些基础操作,并引导你首次的图片生成
1. 加载示例工作流
- 从 ComfyUI 加载Workflows template中的Text to Image工作流
- 使用带有metadata 的图片中加载工作流
2. 指导你完成模型
- 自动安装模型
- 手动安装模型
- 使用 ComfyUI Manager 的模型管理功能安装模型
3. 进行一次文本到图片的生成
1.关于文生图的说明
文生图(Text to Image),是 AI 绘图的基础,通过输入文本描述来生成对应的图片,是 AI 绘图最常用的功能之一,你可以理解成你把你的绘图要求(正向提示词、负向提示词)告诉一个画家(绘图模型),画家会根据你的要求,画出你想要的内容,由于本篇教程主要是为了引导你开始 ComfyUI 的使用,对于文生图的详细说明,我们将在文生图章节进行详细讲解
2.ComfyUI 文生图工作流教程讲解
2.1 启动 ComfyUI
请确定你已经按照安装部分的指南完成了 ComfyUI 的启动,并可以成功打开 ComfyUI 的页面
2.2 加载默认文生图工作流
正常情况下,打开 ComfyUI 后是会自动加载默认的文生图工作流的, 不过你仍旧可以尝试以下不同方式加载工作流来熟悉 ComfyUI 的一些基础操作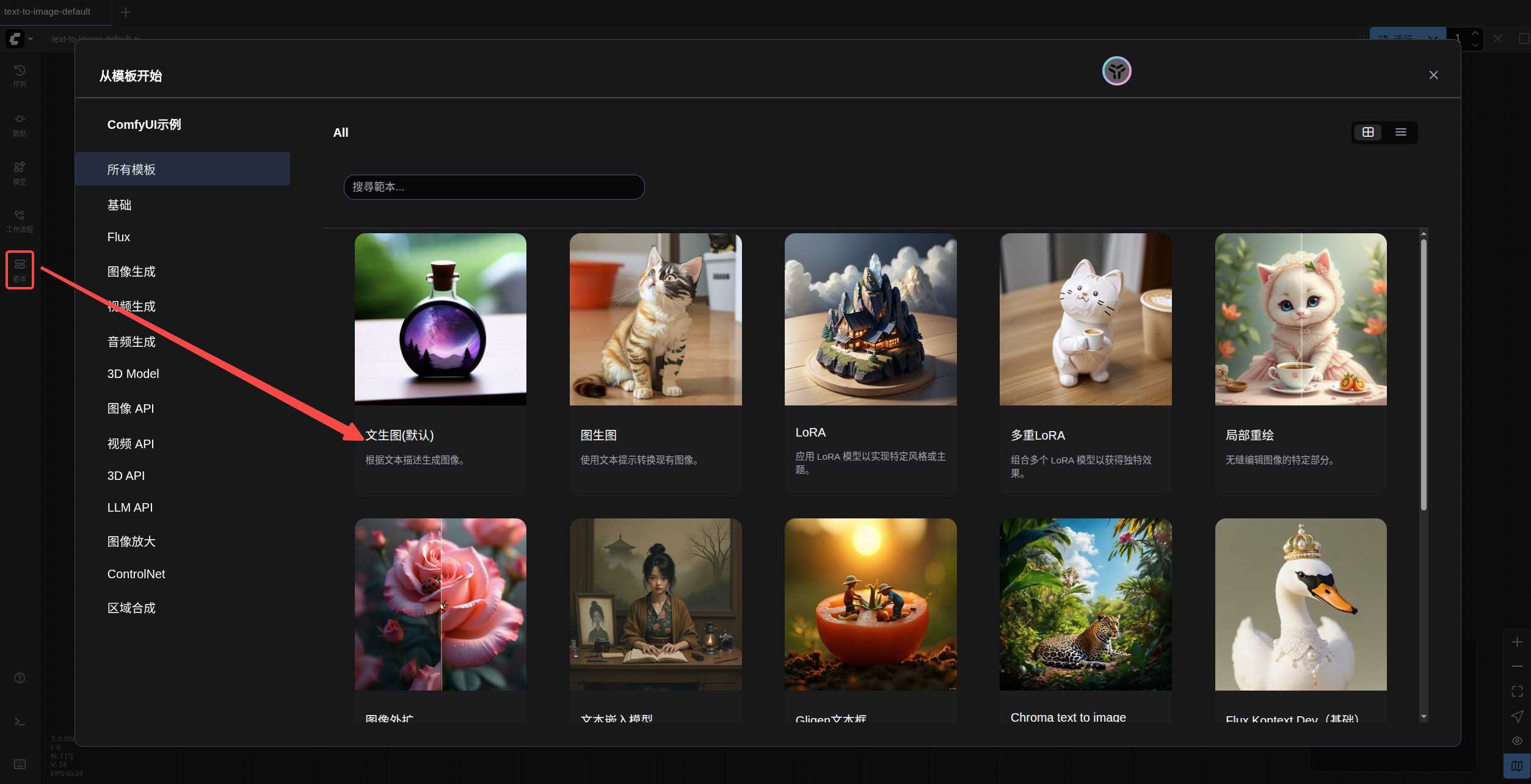
2.3 安装绘图模型(心得,使用aria2)
通常在 ComfyUI 的初始安装中,并不会包含任何的绘图模型,但是模型是我们运行图片生成必不可少的部分。
在你完成第二步,工作流的加载后,如果你的电脑上没有安装v1-5-pruned-emaonly-fp16.safetensors 这个模型文件时,一般会出现下图的提示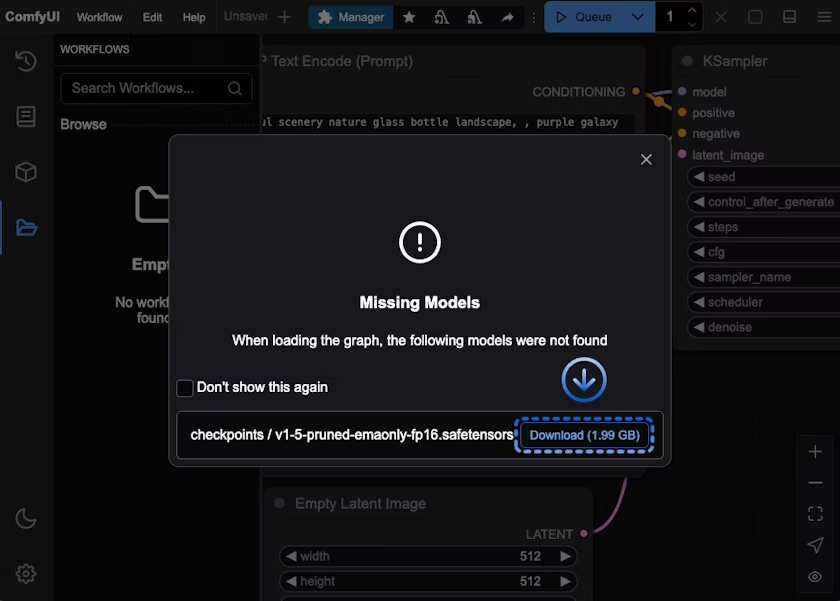
你可以直接选择点击 Download 按钮,让 ComfyUI 自动完成对应的模型的下载,但由于在有些地区不能够顺利访问对应模型的下载源,所以在这个步骤中,我将说明几种不同的模型安装方法。
无论使用哪种方法,模型都会被保存到 <你的 ComfyUI 安装位置>/ComfyUI/models/ 文件夹下,你可以在你的电脑上尝试找到这个文件夹位置,你可以看到许多文件夹比如 checkpoints、embeddings、vae、lora、upscale_model 等,这些都是不同的模型保存的文件夹,通常以文件夹名称区分,ComfyUI 在启动时会检测这些文件夹下的模型文件,以及extra_model_paths.yaml 文件中配置的文件路径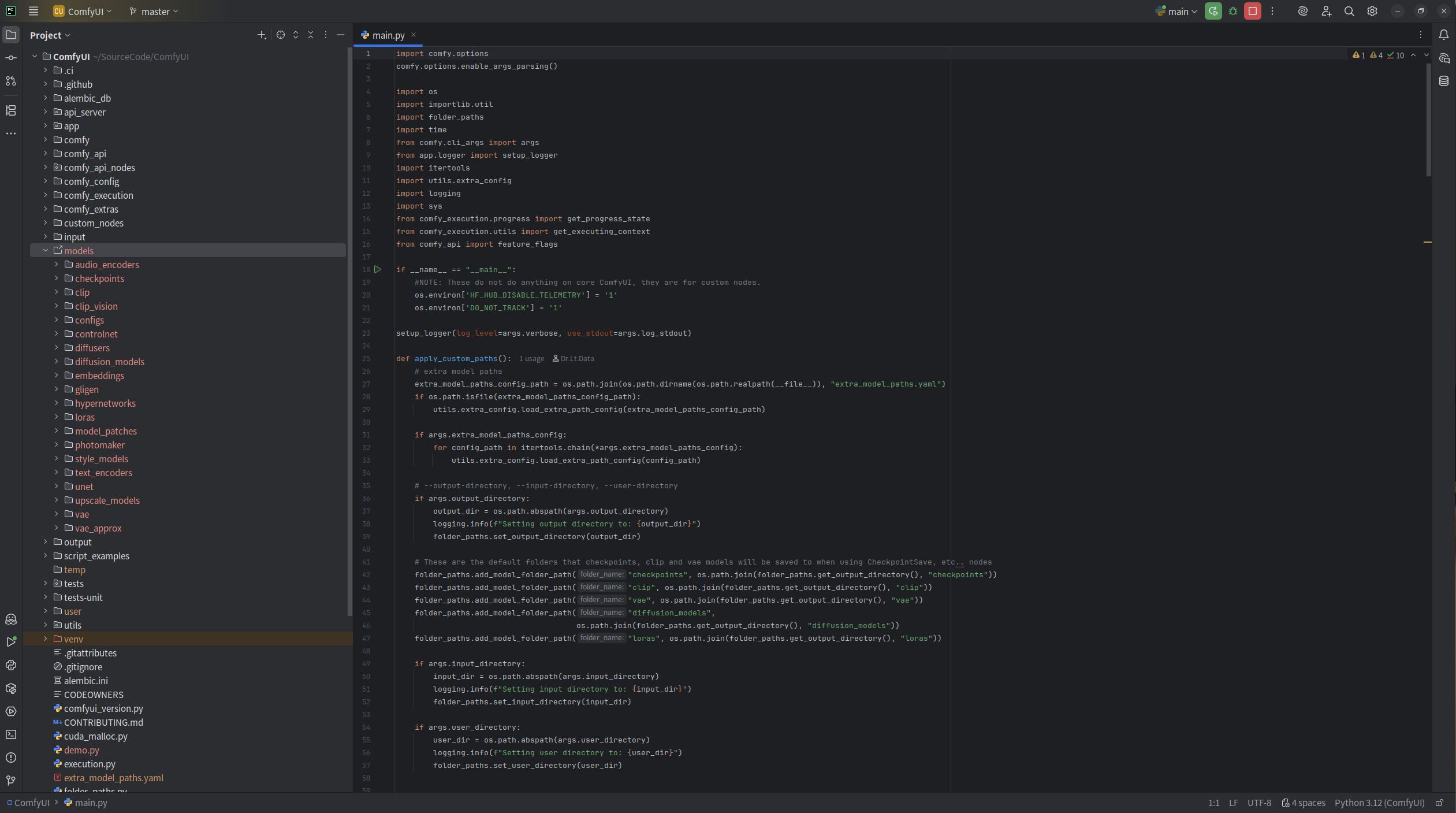
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
aria2c https://huggingface.co/Comfy-Org/stable-diffusion-v1-5-archive/blob/main/v1-5-pruned-emaonly-fp16.safetensors -o SourceCode/ComfyUI/models/checkpoints/v1-5-pruned-emaonly-fp16.safetensors auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不开https://huggingface.co,可以将其换成为https://hf-mirror.com/试一试
2.4 加载模型,并进行第一次图片生成
在完成了对应的绘图模型安装后,请参考下图步骤加载对应的模型,并进行第一次图片的生成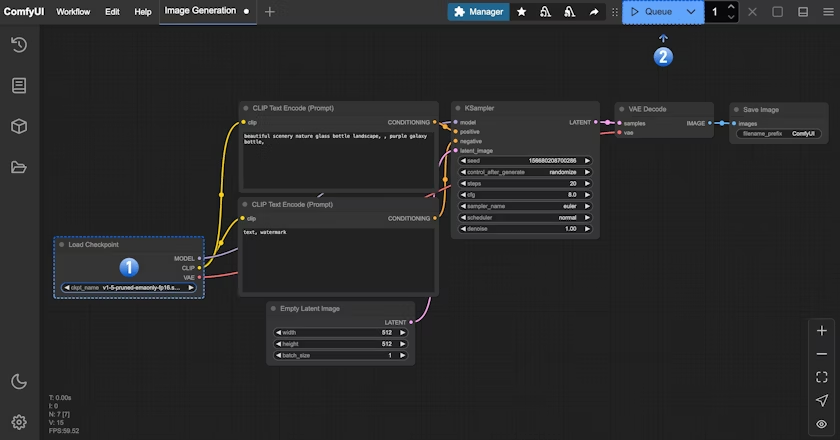
请对应图片序号,完成下面操作:
- 请在 Load Checkpoint 节点使用箭头或者点击文本区域确保 v1-5-pruned-emaonly-fp16.safetensors 被选中,且左右切换箭头不会出现 null 的文本
- 点击 Queue 按钮,或者使用快捷键 Ctrl + enter(回车) 来执行图片生成
等待对应流程执行完成后,你应该可以在界面的 保存图像(Save Image) 节点中看到对应的图片结果,可以在上面右键保存到本地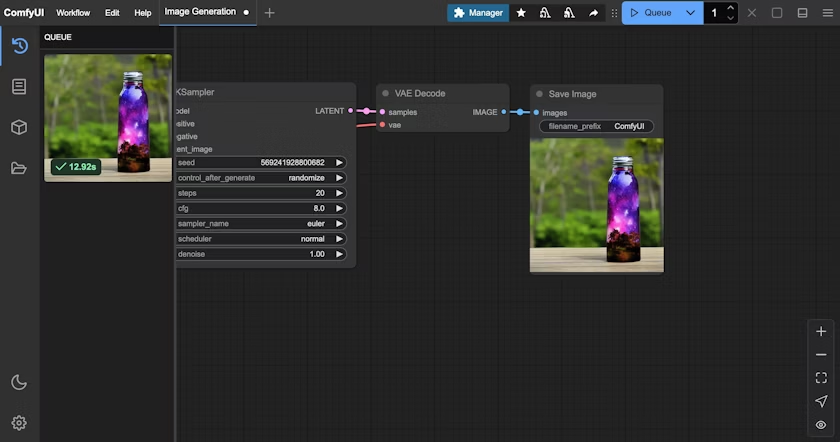
3. ComfyUI 文生图工作流节点讲解
来源:https://docs.comfy.org/zh-CN/tutorials/basic/text-to-image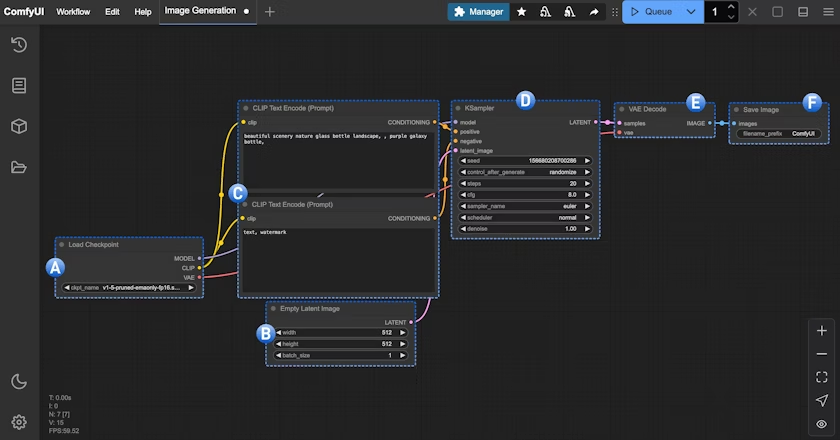
3.1 加载模型(Load Checkpoint)节点
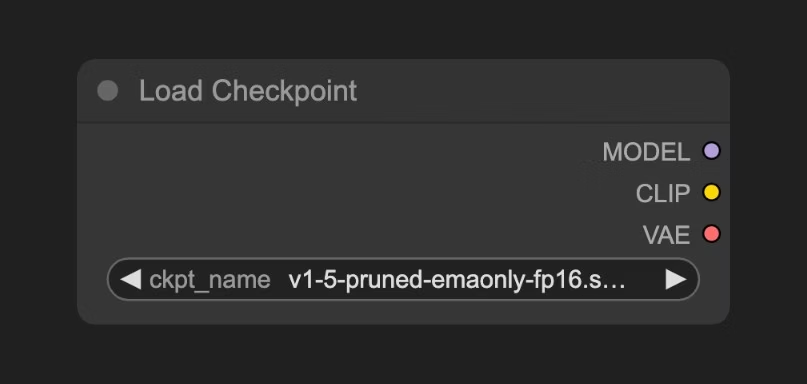
这个节点通常用于加载绘图模型, 通常 checkpoint 中会包含 MODEL(UNet)、CLIP 和 VAE 三个组件MODEL(UNet):为对应模型的 UNet 模型, 负责扩散过程中的噪声预测和图像生成,驱动扩散过程CLIP:这个是文本编码器,因为模型并不能直接理解我们的文本提示词(prompt),所以需要将我们的文本提示词(prompt)编码为向量,转换为模型可以理解的语义向量VAE:这个是变分自编码器,我们的扩散模型处理的是潜在空间,而我们的图片是像素空间,所以需要将图片转换为潜在空间,然后进行扩散,最后将潜在空间转换为图片
3.2 空Latent图像(Empty Latent Image)节点
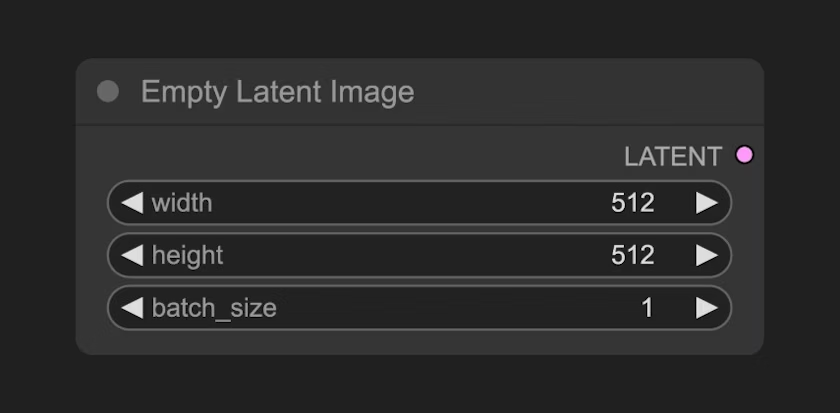
定义一个潜在空间(Latent Space),它输出到 KSampler 节点,空Latent图像节点构建的是一个 纯噪声的潜在空间
它的具体的作用你可以理解为定义画布尺寸的大小,也就是我们最终生成图片的尺寸
3.3 CLIP文本编码器(CLIP Text Encoder)节点
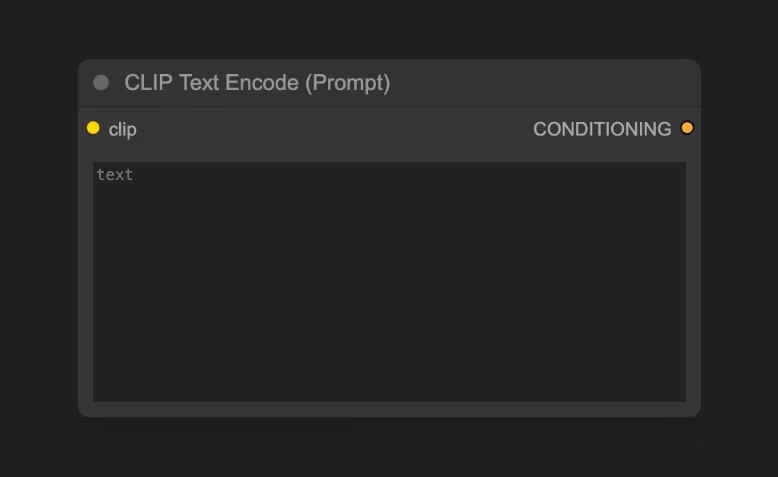
用于编码提示词,也就是输入你对画面的要求
连接到 KSampler 节点的 Positive 条件输入的为正向提示词(希望在画面中出现的元素)
连接到 KSampler 节点的 Negative 条件输入的为负向提示词(不希望在画面中出现的元素)
对应的提示词被来自 Load Checkpoint 节点的 CLIP 组件编码为语义向量,然后作为条件输出到 KSampler 节点
3.4 K 采样器(KSampler)节点
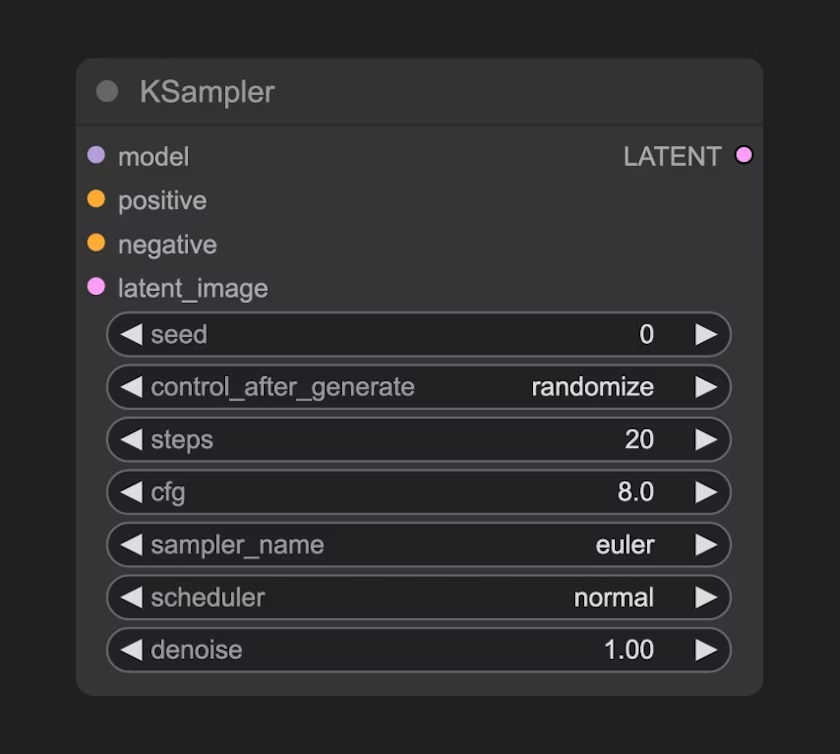
K 采样器 是整个工作流的核心,整个噪声降噪的过程都在这个节点中完成,并最后输出一个潜空间图像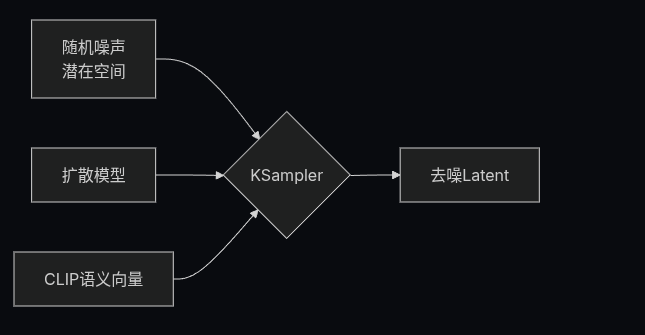
3.5 VAE 解码(VAE Decode)节点
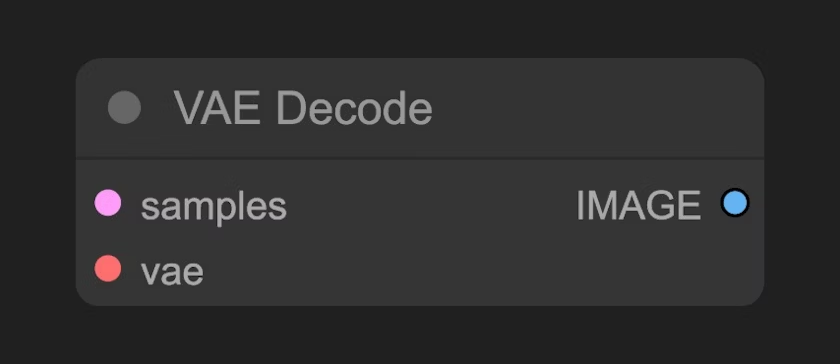
将 K 采样器(KSampler) 输出的潜在空间图像转换为像素空间图像
3.6 保存图像(Save Image)节点
预览并保存从潜空间解码的图像,并保存到本地ComfyUI/output文件夹下
4. SD1.5 模型简介
SD1.5(Stable Diffusion 1.5) 是一个由Stability AI开发的AI绘图模型,Stable Diffusion系列的基础版本,基于 512×512 分辨率图片训练,所以其对 512×512 分辨率图片生成支持较好,体积约为4GB,可以在**消费级显卡(如6GB显存)**上流畅运行。目前 SD1.5 的相关周边生态非常丰富,它支持广泛的插件(如ControlNet、LoRA)和优化工具。 作为AI绘画领域的里程碑模型,SD1.5凭借其开源特性、轻量架构和丰富生态,至今仍是最佳入门选择。尽管后续推出了SDXL/SD3等升级版本,但其在消费级硬件上的性价比仍无可替代。
基础信息
- 发布时间:2022年10月
- 核心架构:基于Latent Diffusion Model (LDM)
- 训练数据:LAION-Aesthetics v2.5数据集(约5.9亿步训练)
- 开源特性:完全开源模型/代码/训练数据
优缺点
模型优势:
- 轻量化:体积小,仅 4GB 左右,在消费级显卡上流畅运行
- 使用门槛低:支持广泛的插件和优化工具
- 生态成熟:支持广泛的插件和优化工具
- 生成速度快:在消费级显卡上流畅运行
模型局限:
- 细节处理:手部/复杂光影易畸变
- 分辨率限制:直接生成1024x1024质量下降
- 提示词依赖:需精确英文描述控制效果
四、API调用(心得,摸索)
1. 导出API
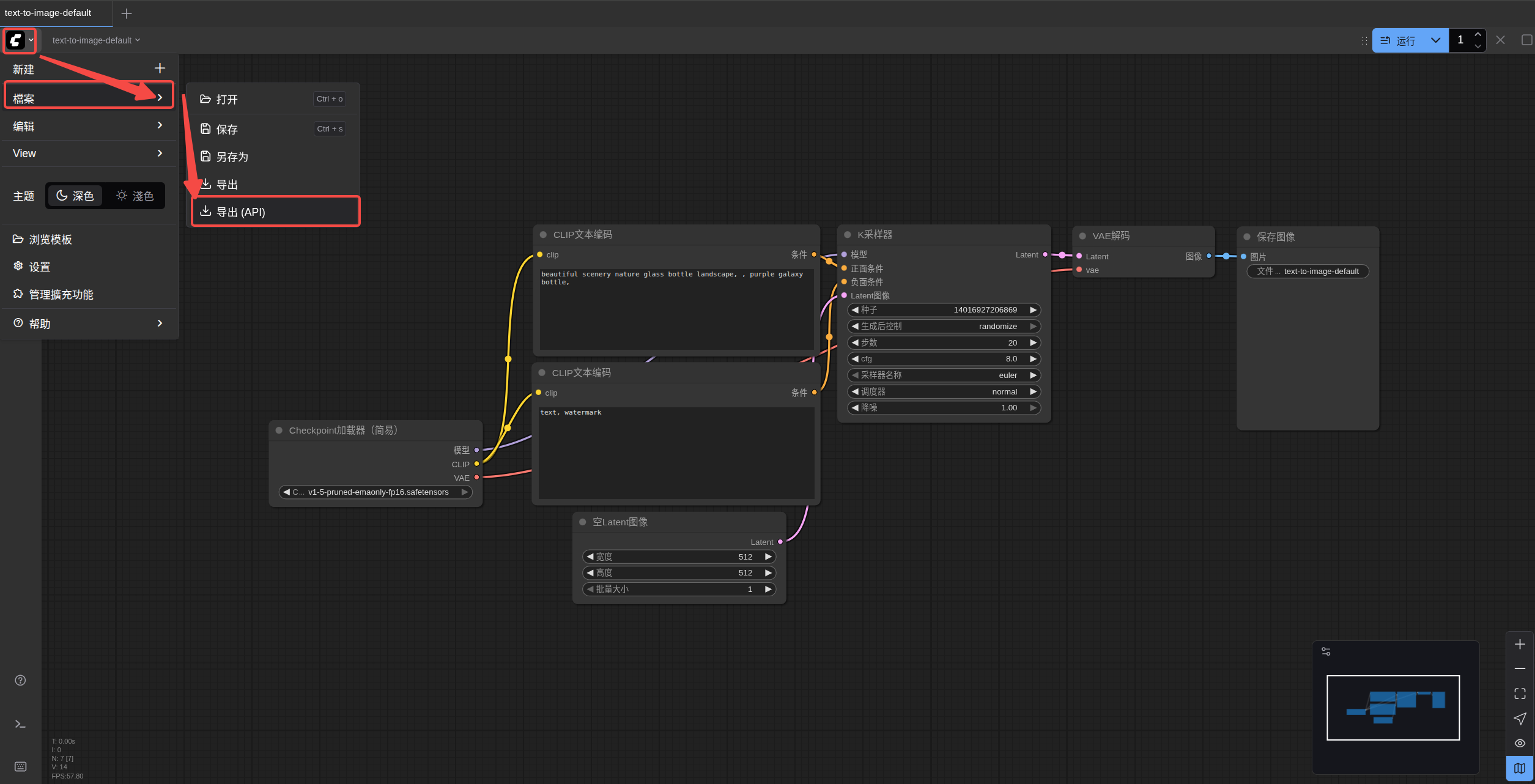
将导出的文件内容放到中:
workflow_with_api_nodes = """
"""
2. 运行效果
"""在无头模式或使用替代前端运行 ComfyUI 时使用 API 节点
你可以通过在 prompt 中包含 API key 来执行包含 API 节点的 ComfyUI 工作流。
API key 需要添加到 payload 的 `extra_data` 字段中。
下面我们展示一个如何实现的示例。
更多信息请参考:
- API 节点概述: https://docs.comfy.org/zh-CN/tutorials/api-nodes/overview
- 要生成 API key,请登录这里: https://platform.comfy.org/login
"""
import json
from urllib import request
SERVER_URL = "http://127.0.0.1:8188"
# 我们有一个包含 API 节点的 prompt/job(API 格式的工作流)。
workflow_with_api_nodes = """
{
"3": {
"inputs": {
"seed": 156680208700286,
"steps": 20,
"cfg": 8,
"sampler_name": "euler",
"scheduler": "normal",
"denoise": 1,
"model": [
"4",
0
],
"positive": [
"6",
0
],
"negative": [
"7",
0
],
"latent_image": [
"5",
0
]
},
"class_type": "KSampler",
"_meta": {
"title": "K采样器"
}
},
"4": {
"inputs": {
"ckpt_name": "v1-5-pruned-emaonly-fp16.safetensors"
},
"class_type": "CheckpointLoaderSimple",
"_meta": {
"title": "Checkpoint加载器(简易)"
}
},
"5": {
"inputs": {
"width": 512,
"height": 512,
"batch_size": 1
},
"class_type": "EmptyLatentImage",
"_meta": {
"title": "空Latent图像"
}
},
"6": {
"inputs": {
"text": "beautiful scenery nature glass bottle landscape, , purple galaxy bottle,",
"clip": [
"4",
1
]
},
"class_type": "CLIPTextEncode",
"_meta": {
"title": "CLIP文本编码"
}
},
"7": {
"inputs": {
"text": "text, watermark",
"clip": [
"4",
1
]
},
"class_type": "CLIPTextEncode",
"_meta": {
"title": "CLIP文本编码"
}
},
"8": {
"inputs": {
"samples": [
"3",
0
],
"vae": [
"4",
2
]
},
"class_type": "VAEDecode",
"_meta": {
"title": "VAE解码"
}
},
"9": {
"inputs": {
"filename_prefix": "aaa",
"images": [
"8",
0
]
},
"class_type": "SaveImage",
"_meta": {
"title": "保存图像"
}
}
}
"""
prompt = json.loads(workflow_with_api_nodes)
payload = {
"prompt": prompt,
# 将 `api_key_comfy_org` 添加到 payload 中。
# 如果你需要处理多个客户端,可以先从关联的用户获取 key。
"extra_data": {
"api_key_comfy_org": "comfyui-87d01e28d*******************************************************" # 替换为实际的 key
},
}
data = json.dumps(payload).encode("utf-8")
req = request.Request(f"{SERVER_URL}/prompt", data=data)
# 发送请求
resp = request.urlopen(req)
print(resp)
其中beautiful scenery nature glass bottle landscape, , purple galaxy bottle,属于正向提示词,text, watermark属于负向提示词
最终图片效果:
3. 修改提示词,代码高复用效果
流程确定了,我们可以通过代码修改里面的正反向提示词,达到高复用的目的,而不用每次都修改UI,太费劲了。
下面是几组不同的 prompt 示例,你可以尝试使用这些 prompt 来查看生成的效果,或者使用你自己的 prompt 来尝试生成
- 二次元动漫风格
正向提示词:
anime style, 1girl with long pink hair, cherry blossom background, studio ghibli aesthetic, soft lighting, intricate details
masterpiece, best quality, 4k
负向提示词:
low quality, blurry, deformed hands, extra fingers
最终图片效果:
- 写实风格
正向提示词:
(ultra realistic portrait:1.3), (elegant woman in crimson silk dress:1.2),
full body, soft cinematic lighting, (golden hour:1.2),
(fujifilm XT4:1.1), shallow depth of field,
(skin texture details:1.3), (film grain:1.1),
gentle wind flow, warm color grading, (perfect facial symmetry:1.3)
负向提示词:
(deformed, cartoon, anime, doll, plastic skin, overexposed, blurry, extra fingers)
最终图片效果:
- 特定艺术家风格
正向提示词:
fantasy elf, detailed character, glowing magic, vibrant colors, long flowing hair, elegant armor, ethereal beauty, mystical forest, magical aura, high detail, soft lighting, fantasy portrait, Artgerm style
负向提示词:
blurry, low detail, cartoonish, unrealistic anatomy, out of focus, cluttered, flat lighting
最终图片效果:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)