大模型基础 | 第四章Transformer性能优化之SparseAttention
本文系统介绍了Transformer模型中的稀疏注意力机制及其优化方法。针对标准自注意力机制在处理长序列时存在的O(n²)计算复杂度问题,提出了三种优化方案:膨胀自注意力通过周期性采样保持全局感知,局部自注意力聚焦固定窗口实现线性复杂度,混合稀疏注意力结合二者优势形成"局部紧密+远程稀疏"模式。这些方法通过打破全局关联假设,在计算效率与表达能力间取得平衡,有效解决了长序列处理中
Transformer性能优化之SparseAttention
标注注意力机制
自注意力机制的计算复杂度与序列长度之间存在着一种紧密的平方关系,这意味着随着序列变得越来越长,所需的计算资源也会以更快的速度增长。这种现象在处理诸如长篇文档这样的大数据集时尤为明显,给计算资源带来了显著的压力。
经典的自注意力机制公式为:
Attention(Q,K,V)=softmax(QKTdmodel)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{\text{model}}}}\right)V Attention(Q,K,V)=softmax(dmodelQKT)V
其中QQQ、KKK、VVV分别代表序列中的三个输入向量。
自注意力机制呈现O(n2)O(n^2)O(n2)的时间复杂度,主要原因在于其核心计算步骤——计算查询(Query)与键(Key)之间的所有成对相似度。
具体来说,假设输入序列的长度为nnn,每个向量的维度为dkd_kdk:
计算注意力分数(Attention Scores)中,我们需要计算序列中每一个位置的查询向量QiQ_iQi与所有位置的键向量KjK_jKj(包括自身)的点积。这会产生一个n×nn \times nn×n的注意力分数矩阵,其中每个元素(i,j)(i,j)(i,j)表示第iii个位置的输出对第jjj个位置输入的关注程度。计算这个n×nn \times nn×n矩阵需要进行n×n=n2n \times n = n^2n×n=n2次点积运算。 因此,仅这一步的计算量就与n2n^2n2成正比。
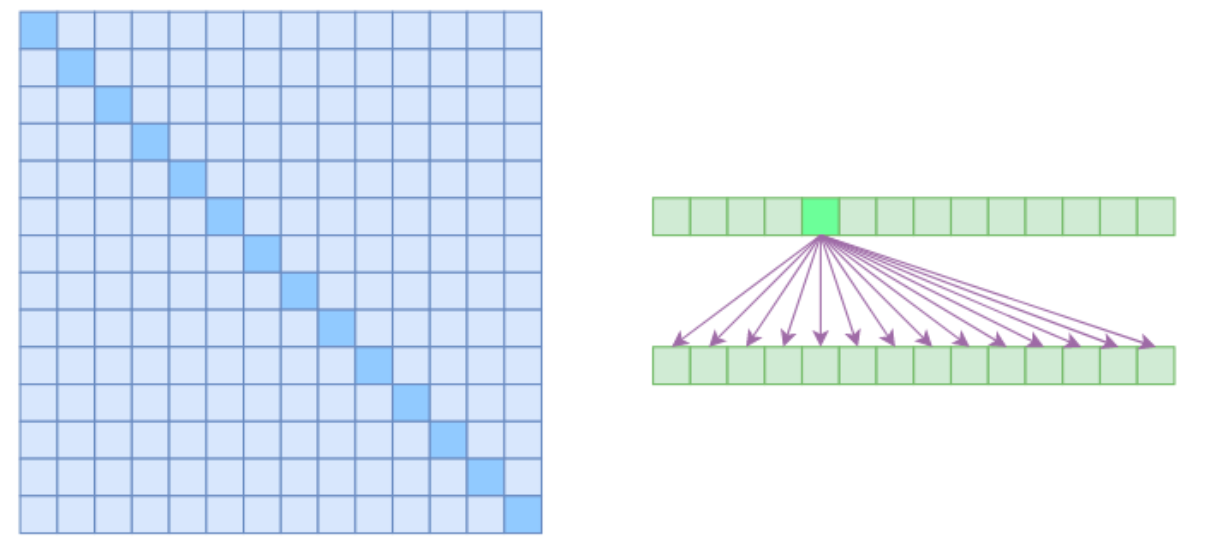
标准的Attention关联示意图如图上所示,左图表示矩阵中一个元素与其他元素的相关得分的矩阵,标准的Attention是每个元素与其他元素都存在关联关系那么矩阵都无白色区域的格子,右图展示了一个元素与其他元素的关联关系,箭头就表示为存在关联关系。
Sparse Attention(稀疏注意力)
它的核心假设是序列中每个元素只跟一部分元素相关联,而不是与所有元素相关联,这样就能减少矩阵的计算量
膨胀自注意力
膨胀自注意力(Atrous Self-Attention),也可称为“空洞自注意力”或“带孔自注意力”。
膨胀自注意力的设计灵感来源于计算机视觉中的“膨胀卷积(Atrous Convolution)”。其核心思想是对注意力关联模式施加约束,强制每个元素仅与相对位置为k,2k,3k,…k, 2k, 3k, \ldotsk,2k,3k,…的其他元素发生交互,其中k>1k > 1k>1是一个预先设定的超参数。这种约束反映在注意力矩阵上(如右下图所示)可以看到存在箭头表示有关联,即要求相对距离不为kkk的整数倍的注意力权重被强制置为零(图中白色区域表示零值):
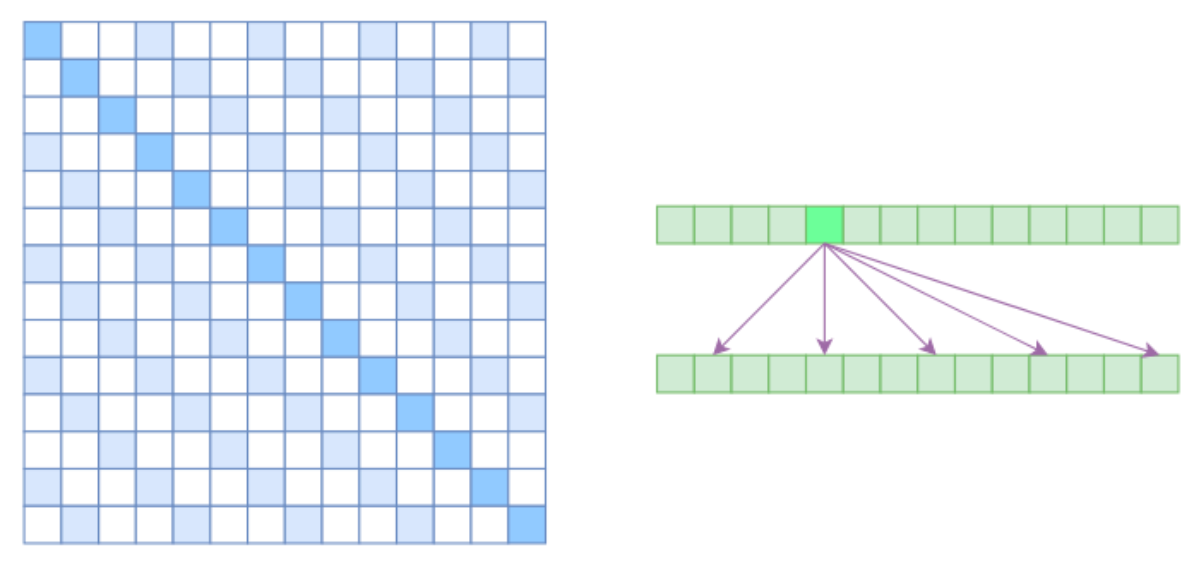
换一个角度来理解,这种机制可被视为对注意力模式施加了一种周期性的稀疏化策略,仅在固定间隔的位置上建立关联,从而在保持全局感知能力的同时显著降低计算复杂度。
局部自注意力
局部自注意力则放弃全局关联,重新引入局部先验,约束每个元素仅与其前后各 k个元素(共2k+1个元素)以及自身发生关联。
从注意力矩阵的角度来看,这一机制将相对距离超过k的位置的注意力权重强制设为 0,从而实现对注意力范围的显式限制。
从注意力矩阵的角度来看,这一机制将任意两个位置i和j之间相对距离超过k的注意力权重强制设为 0,即:
Attention(i,j)=0for all ∣i−j∣>k \text{Attention}(i, j) = 0 \quad \text{for all } |i - j| > k Attention(i,j)=0for all ∣i−j∣>k
从而使得注意力矩阵呈现出带状的稀疏结构。
局部自注意力机制与常规卷积操作具有一定的相似性:两者都定义了一个固定大小为 (2k+1) 的局部窗口,并在该窗口内进行特征聚合。不同之处在于,卷积通过将窗口内的特征展平后经过全连接层完成变换,而局部自注意力则是在窗口内通过查询-键值匹配进行加权平均,权重由注意力函数动态计算得到。
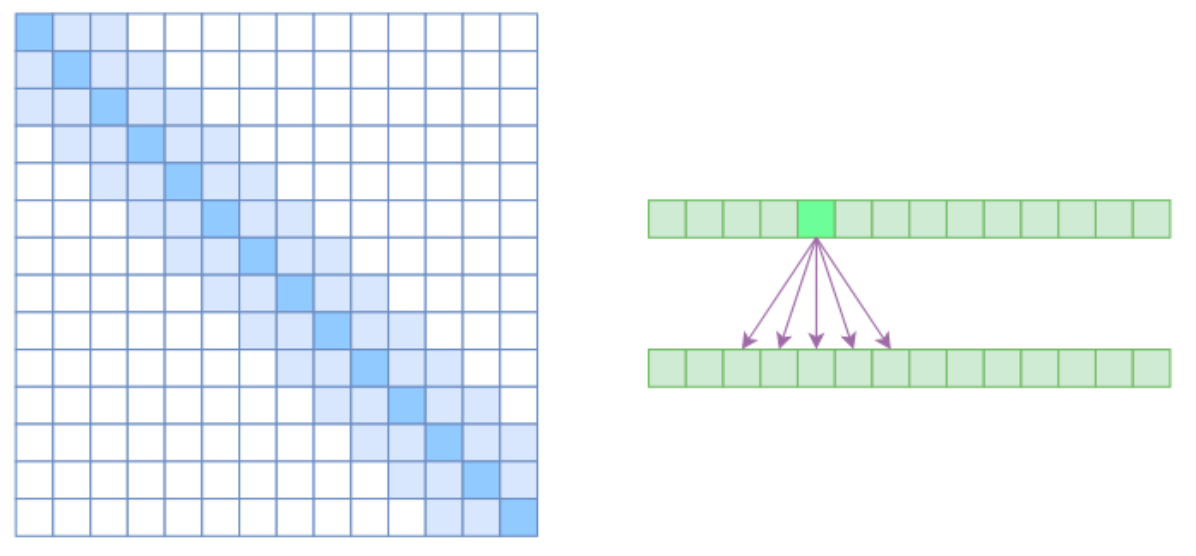
左图中注意力权重被强制置为零(图中白色区域表示零值)
这种设计带来一个显著优势:计算复杂度和显存占用从全局自注意力的O(n2)\mathscr{O}(n^2)O(n2)下降至O((2k+1)n)∼O(kn)\mathscr{O}((2k+1)n) \sim \mathscr{O}(kn)O((2k+1)n)∼O(kn),即与序列长度 n 呈线性关系:O(kn)\mathscr{O}(kn)O(kn)
这使得模型在处理长序列时更具可扩展性。然而,这一效率的提升是以牺牲长程依赖建模能力为代价的,模型不再能够直接捕捉远距离元素之间的关系。
混合稀疏自注意力机制
为了解决局部自注意力不再能够直接捕捉远距离元素之间的关系,混合稀疏自注意力机制是一种将膨胀自注意力与局部自注意力相结合的创新方法。局部自注意力机制假设相关性主要集中在固定窗口范围内,虽然能强化局部特征提取,却难以捕获全局语义依赖。而结合了膨胀自注意力基于“相关性均匀分布”的假设,采用等间隔采样策略,从而能够有效捕捉全局语义信息。将两种机制融合成为一种更优的解决方案,能够在全局感知与局部聚焦之间实现更好的平衡。
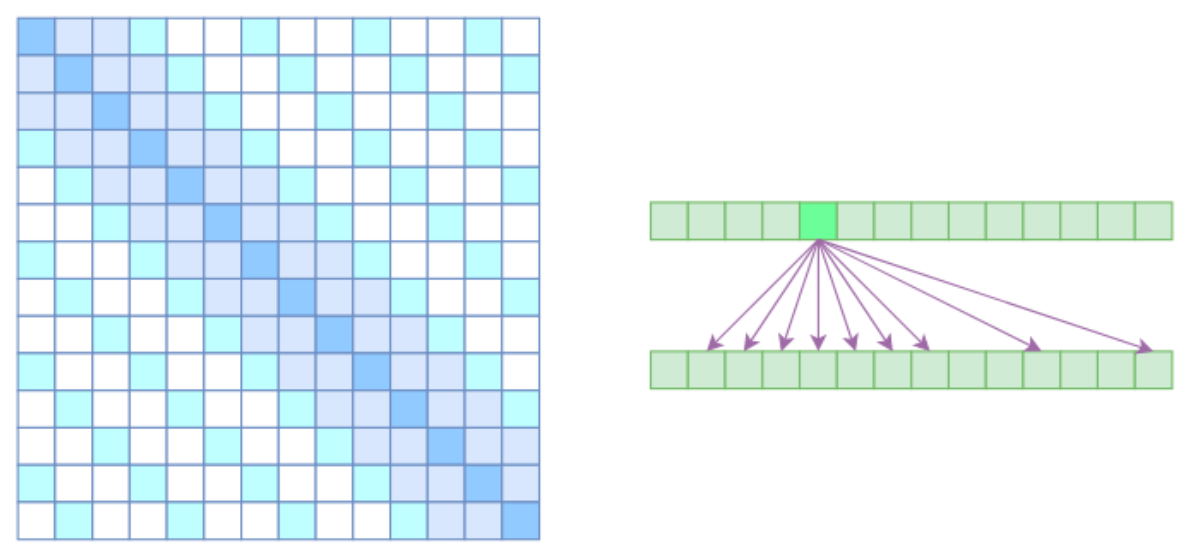
从注意力矩阵上看就很容易理解了,就是只有相对距离不超过kkk的、相对距离为k,2k,3k,…k,2k,3k,\dotsk,2k,3k,…的注意力都不为0,其他部分都设为 0(空白区域),这样一来 Attention 就具有“局部紧密相关和远程稀疏相关”的特性,这对很多任务来说可能是一个不错的先验,因为真正需要密集的长程关联的任务事实上是很少的。
总结
本章系统性地介绍了稀疏注意力(Sparse Attention) 机制及其变体,旨在解决标准自注意力机制在处理长序列时存在的计算和存储瓶颈问题。
核心问题
标准自注意力机制的计算复杂度为O(n2)O(n^2)O(n2),使其难以高效处理长序列(如长文档、高分辨率图像等),限制了其在资源受限环境下的应用。
解决方案
稀疏注意力的核心思想是打破全局关联假设,认为序列中每个元素仅需与一部分元素交互,从而显著降低计算量。本章重点介绍了三种代表性方法:
-
膨胀自注意力:
- 灵感来源于计算机视觉中的膨胀卷积。
- 强制每个元素仅与相对位置为k,2k,3k,…k, 2k, 3k, \ldotsk,2k,3k,…的元素交互,形成周期性稀疏模式。
- 在保持一定全局感知能力的同时,降低了计算复杂度。
-
局部自注意力:
- 引入局部性先验,约束每个元素仅与其附近固定窗口(如前后kkk个元素)内的元素交互。
- 计算复杂度降至O(k⋅n)O(k \cdot n)O(k⋅n),与序列长度呈线性关系,极大提升了效率。
- 缺点是无法直接建模长程依赖,更侧重于局部特征提取。
-
混合稀疏自注意力:
- 结合了膨胀注意力的全局采样能力与局部注意力的细节捕捉能力。
- 形成“局部紧密相关 + 远程稀疏相关”的注意力模式,在全局感知与局部聚焦之间取得平衡。
- 是一种更通用、更灵活的稀疏注意力设计范式。
意义
稀疏注意力不仅大幅提升了长序列处理的效率,还为注意力机制的设计提供了新的思路:通过引入结构化先验或学习到的稀疏模式,在计算效率与表达能力之间寻求最优解。这类方法已被广泛应用于长文本处理、图像生成、语音识别等任务中,成为Transformer模型扩展至长序列场景的关键技术之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)