秋招程序员上岸必备技术之高并发+大模型+大数据全套面试题及答案!
以上全套面试题覆盖了高并发、大模型和大数据的核心知识点。练习方法:针对每个主题,动手实现小项目(如用Redis构建锁、训练简单Transformer模型)。面试准备:结合实际问题(如“如何设计高并发电商系统?”),展示综合能力。资源推荐:参考《Designing Data-Intensive Applications》书籍或LeetCode算法题。如果您有具体问题或需要更多题目,请随时补充!祝秋招
以下是针对秋招程序员“上岸必备技术”的完整指南,覆盖高并发、大模型和大数据三大核心领域。将以结构清晰的方式逐步呈现,包括每个主题的简要概述、常见面试题及答案。
第一部分:高并发技术
高并发指系统在单位时间内处理大量请求的能力,常见于分布式系统、微服务架构。面试重点考察多线程、锁机制、分布式一致性等。
常见面试题及答案
-
面试题:如何实现分布式锁?
答案: 常用方法包括基于Redis的SETNX命令或ZooKeeper的临时节点。核心是保证原子性和互斥性。例如,Redis实现伪代码:def acquire_lock(redis_conn, lock_name, timeout=10): identifier = str(uuid.uuid4()) end = time.time() + timeout while time.time() < end: if redis_conn.setnx(lock_name, identifier): redis_conn.expire(lock_name, timeout) return identifier time.sleep(0.01) return None解释:使用
SETNX设置键值,确保只有一个客户端获取锁;超时机制防止死锁。 -
面试题:解释CAP定理,并说明在分布式系统中的应用。
答案: CAP定理指出分布式系统无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)。在设计中必须权衡:- CA系统(如单机数据库):放弃分区容忍性,适合低风险场景。
- AP系统(如Cassandra):优先可用性和分区容忍性,适合高并发读。
- CP系统(如ZooKeeper):优先一致性和分区容忍性,适合事务处理。
公式表示:$C + A + P \leq 2$,即在分区发生时,只能保证两个属性。
-
面试题:什么是线程池?如何优化其性能?
答案: 线程池管理多个线程复用,减少创建销毁开销。优化方法:- 调整核心线程数和最大线程数,基于任务类型(如I/O密集型或CPU密集型)。
- 使用队列(如LinkedBlockingQueue)避免任务堆积。
- 监控线程状态,防止资源泄漏。
独立公式:线程池大小估算公式为:
$$N_{threads} = N_{cpu} \times U_{cpu} \times (1 + \frac{W}{C})$$
其中$N_{cpu}$是CPU核心数,$U_{cpu}$是目标利用率(e.g., 0.8),$W$是等待时间,$C$是计算时间。
第二部分:大模型技术
大模型指大规模预训练语言模型(如GPT、BERT),用于自然语言处理、生成任务。面试重点考察模型架构、训练策略和优化。
常见面试题及答案
-
面试题:解释Transformer的自注意力机制,并用公式说明。
答案: 自注意力允许模型在不同位置关注相关词。核心是计算查询(Query)、键(Key)、值(Value)的权重。公式为:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
其中$d_k$是键的维度,用于缩放点积,防止梯度消失。举例:在句子“I love NLP”中,“love”会关注“I”和“NLP”。 -
面试题:如何训练一个大模型?涉及哪些优化技术?
答案: 训练流程:数据预处理→预训练→微调。优化技术包括:- 混合精度训练:使用FP16和FP32混合减少显存,公式:$ \text{loss}_{scaled} = \text{loss} \times \text{scale} $。
- 梯度裁剪:防止梯度爆炸,$ \text{if } | \nabla | > \text{threshold}, \text{ then } \nabla = \frac{\nabla \cdot \text{threshold}}{| \nabla |} $。
- 分布式训练:如数据并行,各GPU处理不同批次。
-
面试题:什么是模型量化?它的优缺点是什么?
答案: 量化将模型参数从高精度(如FP32)转换为低精度(如INT8),以减少模型大小和推理延迟。- 优点:加速推理,适合移动端;公式:$ \text{size}{new} = \frac{\text{size}{original}}{4} $(FP32到INT8)。
- 缺点:可能损失精度,需后训练校准补偿。
第三部分:大数据技术
大数据处理海量数据集,涉及存储、计算和分析。面试重点考察Hadoop、Spark、流处理框架。
常见面试题及答案
-
面试题:解释MapReduce的工作原理,并举例说明。
答案: MapReduce分两阶段:- Map阶段:将输入数据拆分,应用Map函数输出键值对。例如,词频统计:
Map("hello world") → [("hello", 1), ("world", 1)]。 - Reduce阶段:合并相同键的值。公式:$ \text{Reduce}(k, \text{list}(v)) \rightarrow \text{output} $。
整体流程:输入→分片→Map→Shuffle→Reduce→输出。
- Map阶段:将输入数据拆分,应用Map函数输出键值对。例如,词频统计:
-
面试题:Spark和Hadoop的区别是什么?Spark的优势在哪里?
答案:- 区别:Hadoop基于磁盘存储(HDFS),适合批处理;Spark基于内存计算,适合迭代任务。
- Spark优势:
- 速度更快:内存计算减少I/O,公式:$ \text{speedup} \approx 10\times $。
- 支持多种API:如Spark SQL、Streaming。
- 容错机制:通过RDD(弹性分布式数据集)保证数据恢复。
-
面试题:什么是流处理?如何用Flink或Kafka实现实时分析?
答案: 流处理实时处理连续数据流。实现方法:- Flink:使用时间窗口聚合,例如计算每分钟交易额:
公式:窗口函数$ \text{sum}(t) = \sum_{i=1}^{n} \text{amount}_i $。DataStream<Transaction> stream = ...; stream.keyBy(Transaction::getUserId) .window(TumblingProcessingTimeWindows.of(Time.minutes(1))) .sum("amount"); - Kafka:作为消息队列,配合Spark Streaming消费数据。
- Flink:使用时间窗口聚合,例如计算每分钟交易额:
总结与建议
以上全套面试题覆盖了高并发、大模型和大数据的核心知识点。建议您:
- 练习方法:针对每个主题,动手实现小项目(如用Redis构建锁、训练简单Transformer模型)。
- 面试准备:结合实际问题(如“如何设计高并发电商系统?”),展示综合能力。
- 资源推荐:参考《Designing Data-Intensive Applications》书籍或LeetCode算法题。
如果您有具体问题或需要更多题目,请随时补充!祝秋招顺利上岸!
学习目录

学习内容(59大专题)
Java企业架构体系相关

![]()
Al大模型相关

![]()
HR面试软技能

设计模式相关

并发编程相关

网络IO与Netty相关

互联网三高项目相关

亿级流量多级缓存相关

数据结构算法相关

分布式相关
分布式锁相关
分布式ID相关

核心源码相关

大厂线上故障分析相关

Docker相关
Dubbo相关
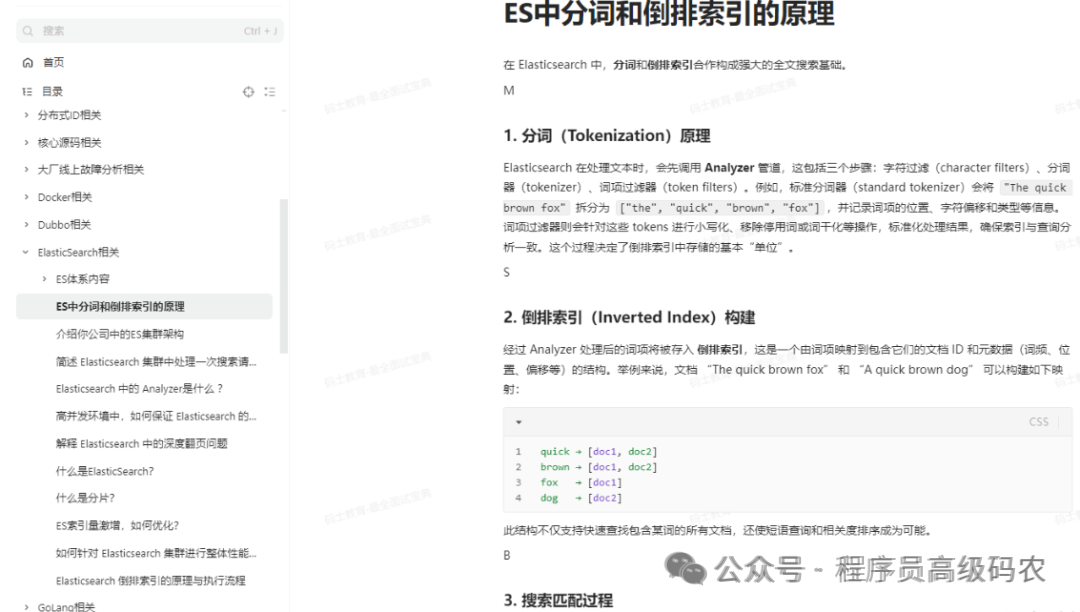
ElasticSearch相关
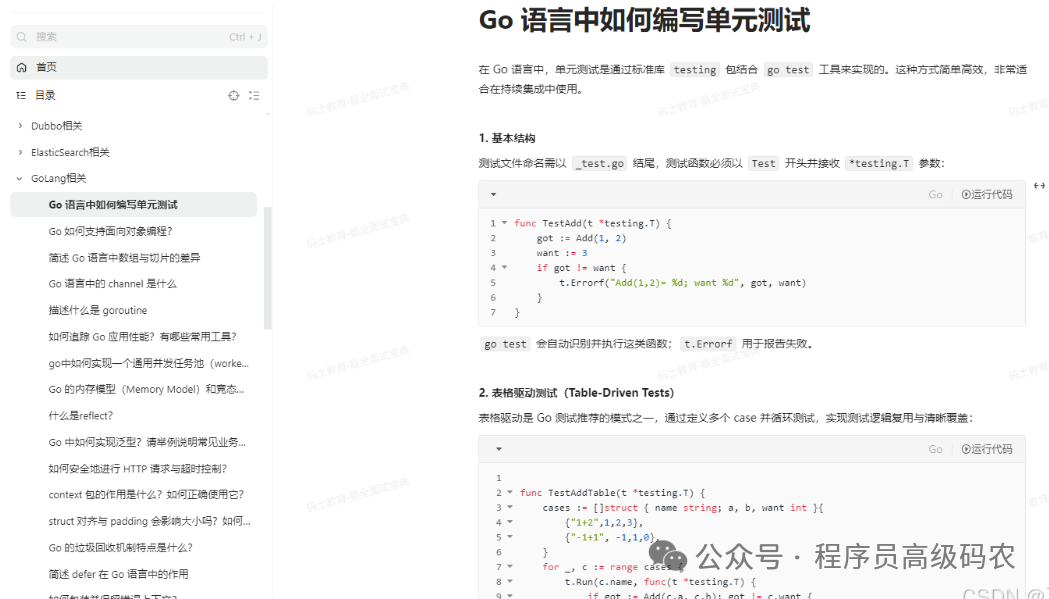
GoLang相关
Java基础核心

JVM核心相关

JVM调优底层相关

Kafka相关

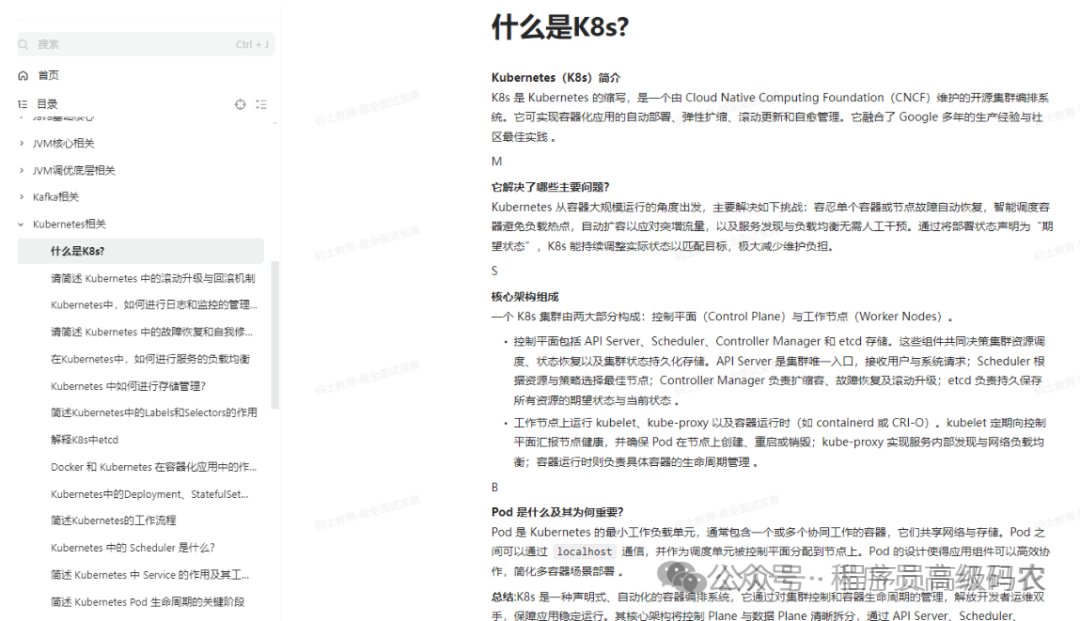
Kubernetes相关
Linux相关

MongoDB相关

MQ相关

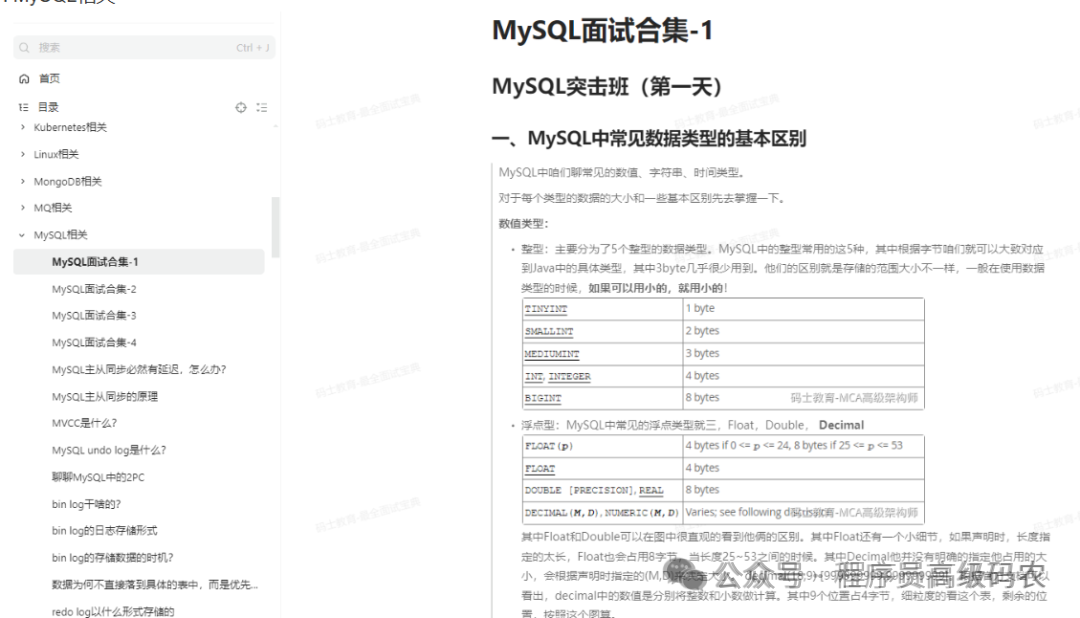
MySQL相关
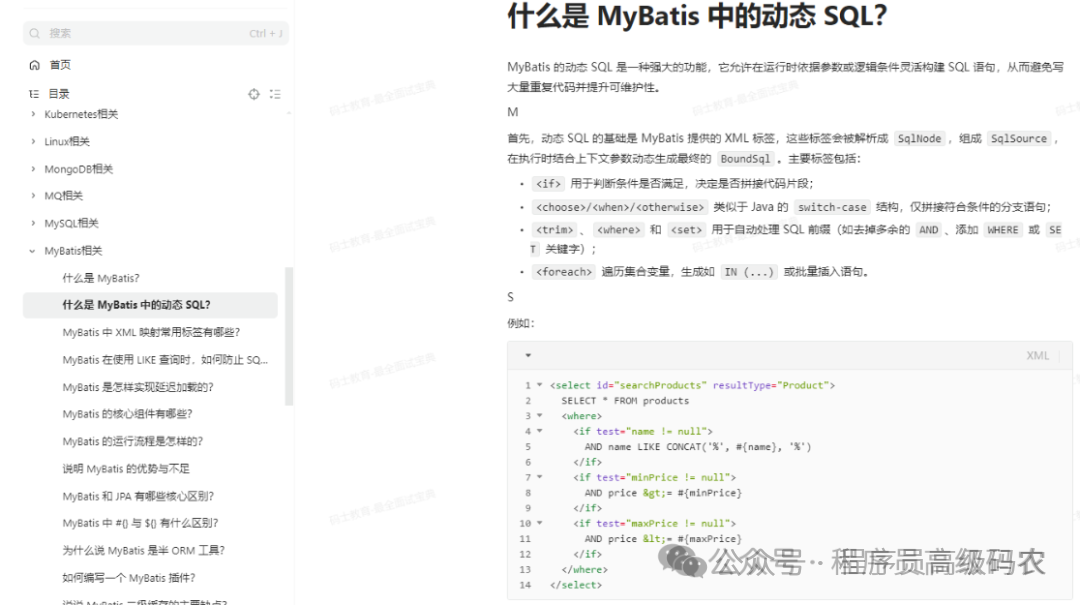
MyBatis相关
MyBatisPlus相关

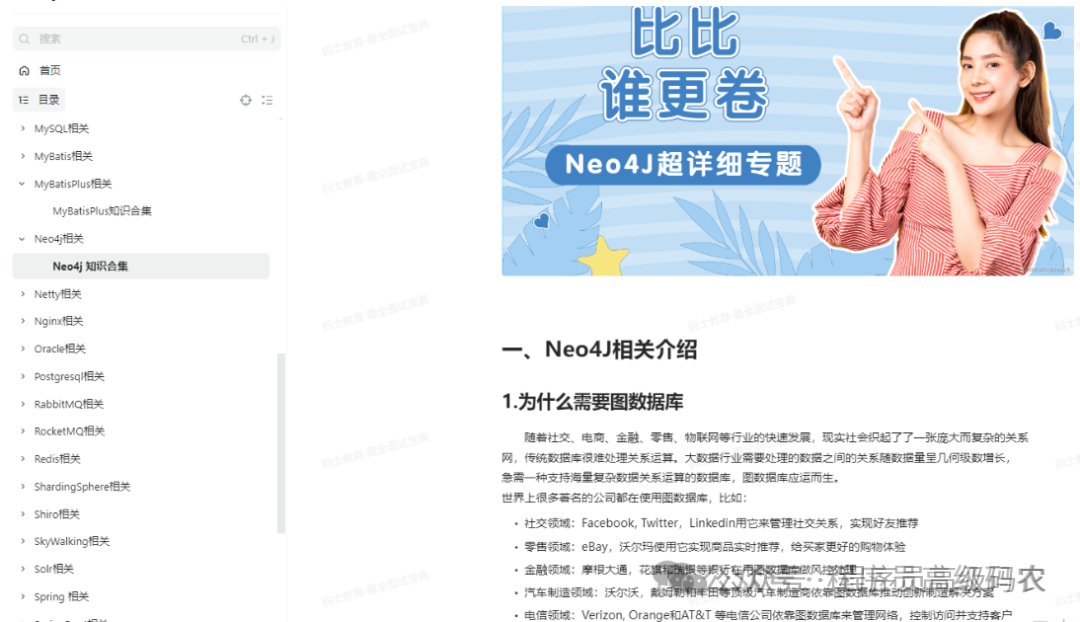
Neo4j相关
Netty相关

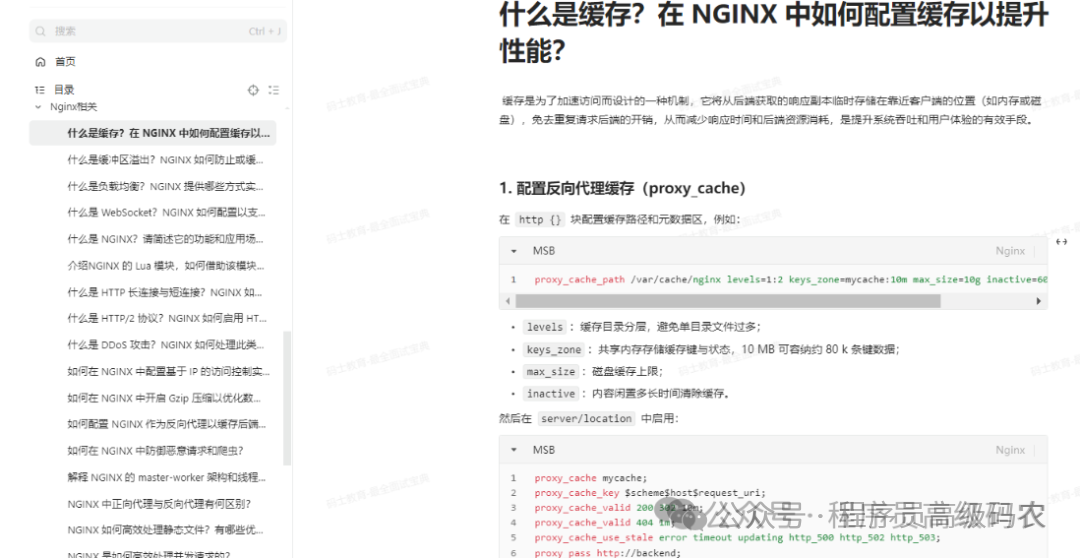
Nginx相关
Oracle相关

postgresql相关

RabbitMQ相关

RocketMQ相关

Redis相关

shardingSphere相关

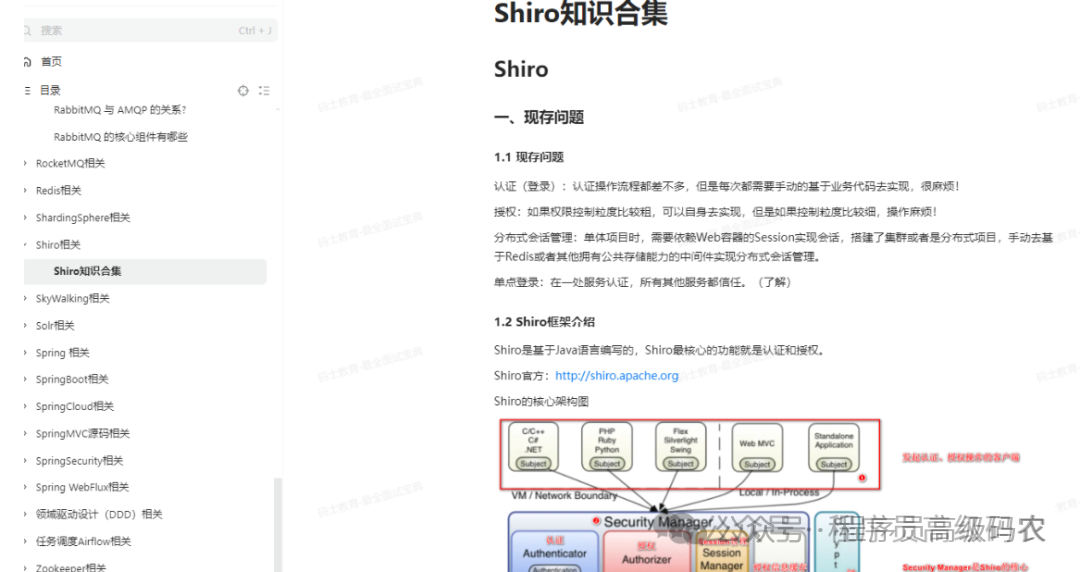
shiro相关
skywalking相关

Solr相关

Spring相关

SpringBoot相关

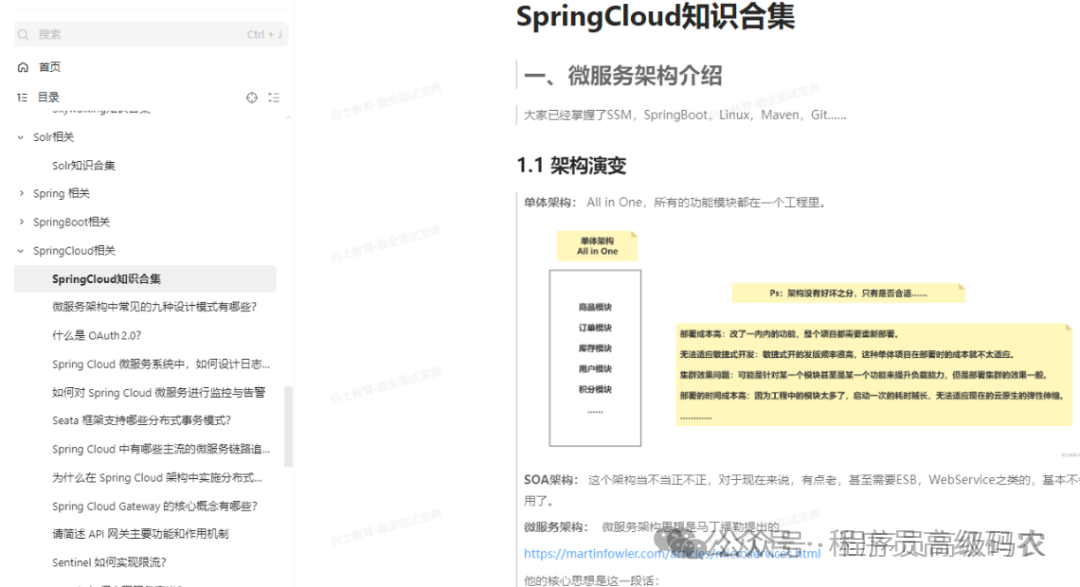
SpringCloud相关
SpringMVc源码相关

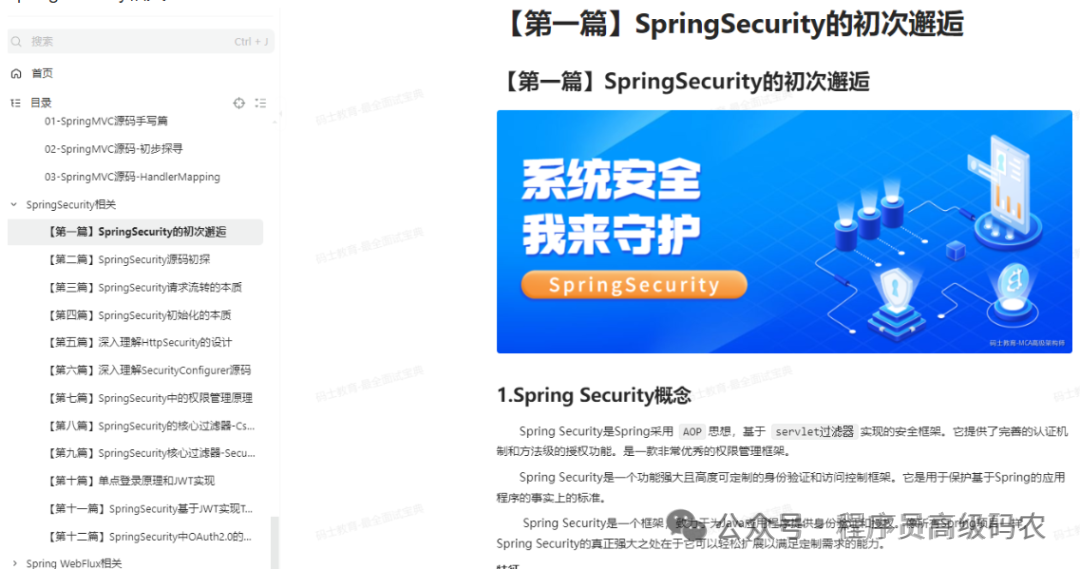
springSecurity相关
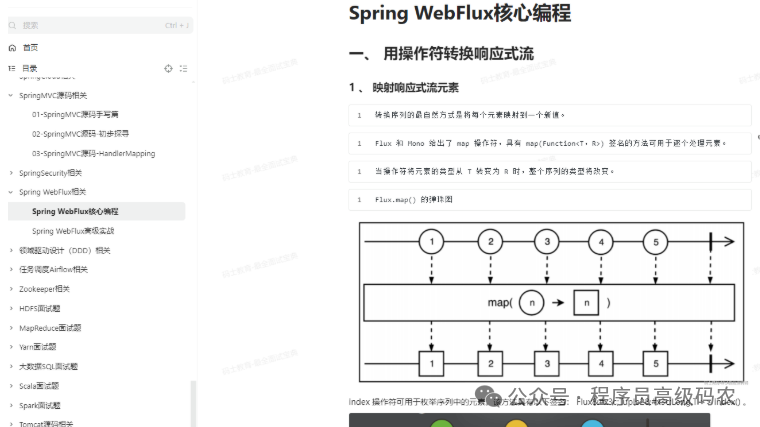
Spring WebFlux相关
领域驱动设计(DDD)相关

任务调度Airflow相关

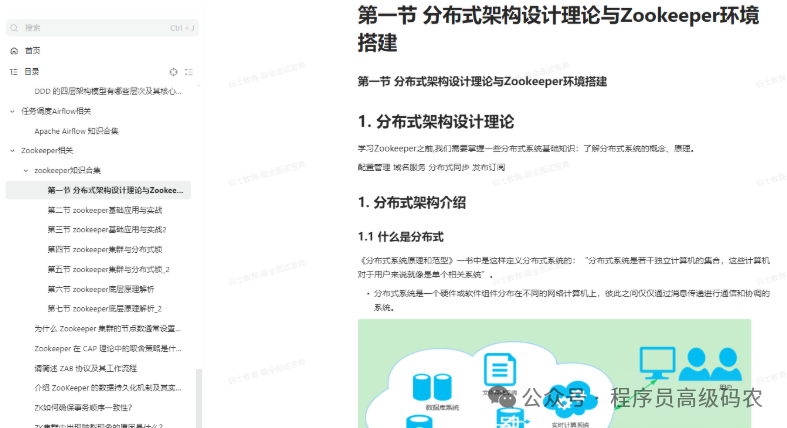
zookeeper相关
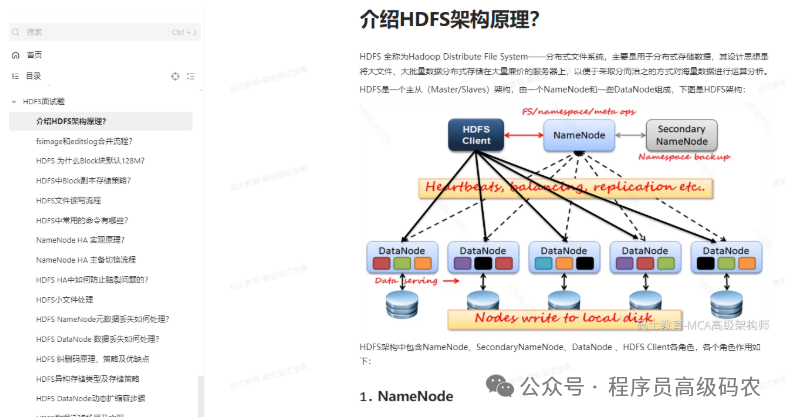
HDFS面试题
MapReduce面试题

Yarn面试题

大数据SQL面试题

Scala面试题

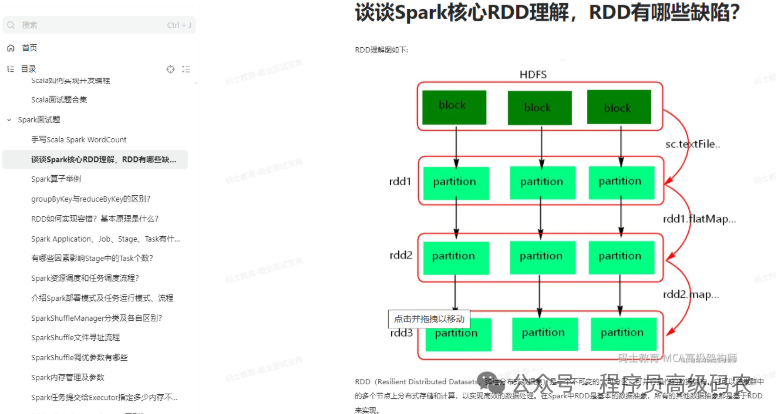
Spark面试题
Tomcat源码
相关网络安全相关

运维/云原生相关

结束语
已经整理成册,需要的同学查看下方名片拿走了!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)