AI Python基础(面向对象之前)
一、计算机的原理
1、计算机组成
中央处理器 CPU
存储器分内存储器和外存储器,内存储器叫内存,外存储器有硬盘U盘等,CPU负责处理内存里的东西,因为在内存处理效率高,如果要处理硬盘或外存的东西,先调用到内存。
2、Python介绍
过
二、Python基础语法
1、注释
单行注释
# 注释内容多行注释,单引号双引号都可以
"""
注释内容
注释内容
"""2、变量
变量的作用
变量是存储数据时,当前数据所在的内存地址的名字
定义变量
由数字、字母、下划线组成,不能以数字开头,不能使用内置关键字,严格区分大小写。
使用变量
stu_name = 'tom'
print(stu_name)
print('大家好')3、认识bug和使用debug工具
4、数据类型
数值:整型int 浮点型float
bool:ture/false
字符串:str
列表list:[1,2,3] 元组tuple:(1,2,3) 列表可以进行增删改,元组不可以
集合set:{1,2,3}
字典dict:{'name':'xjj','age':18} 这种一个名称+冒号+内容的组合叫键值对
检测数据类型
stu_name = 'tom'
stu_number = 14.4
print(stu_name)
print(stu_number)
print(type(stu_number))
print(type(stu_name))5、输出
格式化输出
作用:程序输出内容给用户
格式化符号:字符串%s,有符号十进制%d,浮点数%f
%s比较强大,可以同样表示十进制和浮点数
%.2f 保留两位小数
%06d 表示输出的整数显示位数,不足的以0补全,超出当前位数则原样输出
print('我的名字是%s,明年%d岁了' % (name, age + 1))print(f'我的名字是{name},我今年{age}岁')
print(f'我的名字是{name},明年{age+1}岁了')转义字符
\n 空一行,\t 制表符空一个tab距离(4个空格)
结束符
print(' hello ' , end="\n") 默认是\n,其它的也可以
6、输入
input( "提示信息" ),程序执行到input,等待执行,接收用户输入后,一般存储到变量,会把接收到的任意用户输入数据都当作字符串处理
number = input('请输入red有几个人:')
print(f'red有{number}个人')
print(type(number))7、转换数据类型
承接上面,已知input会把接收到的数据当作字符串处理,这时候我们需要转换数据类型
eval( ),计算字符串在python中本来的类型并返回一个对象比如
str1 = '(1,2,3)'
print(type(eval(str1)))8、运算符
算数运算符
注意优先级,()大于**大于*/大于+-
赋值运算符
多变量赋值
num1,str1,float1 = 1,'hello',1.2复合赋值运算符
a = 10
a *= 3
print(a)注意:先算复合赋值运算符右边的内容,再算复合赋值运算
比较运算符
== != > < >= <= 这些返回值是True or False
逻辑运算符
and都真才真 or有真就真 not取反
三、判断语句
1、if语句
if True:
print('hello world')a = int(input('请输入你的年龄:'))
if a>=18:
print(f'你的年龄是{a},可以上网')这边注意input默认是str数据类型,要转换一下
if-else语句
a = int(input('请输入你的年龄:'))
if a>=18:
print(f'你的年龄是{a},可以上网')
else:
print(f'未满18岁,不能上网')a = int(input('请输入你的年龄:'))
if a<18:
print(f'你的年龄是{a},属于童工')
elif (a>=18) and (a<=60):
print(f'你的年龄是{a},合法劳动工')
else:
print(f'你的年龄是{a},可以退休了')if嵌套语句
a = int(input('你身上带了多少钱:'))
if a>=1:
print('上车')
b = int(input('车上有几个座位:'))
if b>=1:
print('找空位入座')
else:
print('没座位了,站一会')
else:
print('余额不足')案例:猜拳游戏 (随机数)
import 模块名
random.randint(开始,结束)import random
player = int(input('玩家请出拳 0--石头 1--剪刀 2--布:'))
computer = random.randint(0, 2)
print(f'你出了{player},电脑出了{computer}')
if ((player == 0)and(computer == 1))or((player == 1)and(computer == 2))or((player == 2)and(computer == 0)):
print('玩家获胜')
elif player == computer:
print('平局')
else:
print('电脑获胜')三目运算符
化简简单if-else语句
条件成立执行的表达式 if 条件 else 条件不成立的表达式a = 4
b = 7
c = a if a<b else b
print(c)四、循环语句
1、while循环
while 条件:
条件成立重复执行的代码1i = 0
while i<5:
print('ok',end ="\n")
i+=12、break和continue语句
break语句
i = 0
while i < 5:
if i == 3:
break
print(i)
i += 1continue语句
continue语句之前要写 i += 1,不然会陷入死循环
i = 0
while i < 5:
if i == 3:
print(f'{i}不输出')
i += 1
continue
print(i)
i += 13、while循环嵌套的作用和语法
这里注意 i = 0要卸载外层循环里内层循环外,做到一个重置内存循环的作用
j = 0
while j < 3:
i = 0
while i < 3:
print('我错了')
i += 1
print('刷碗')
j += 1while循环嵌套示例
打印正方形星号
j = 0
while j < 5:
i = 0
while i < 5:
print('*', end = "")
i += 1
print(end = "\n")
j += 1打印三角形星号,注意改成 i <= j,由行号控制个数
j = 0
while j < 5:
i = 0
while i <= j:
print('*', end = '')
i += 1
print(end = "\n")
j += 1九九乘法表
j = 1
while j <= 9:
i = 1
while i <= j:
print(f'{i}×{j}={i*j}', end = ' ')
i += 1
print(end = "\n")
j += 14、for循环
语法
for 临时变量 in 序列:str1 = 'helloworld'
for i in str1:
print(i)用break or continue退出for循环(类似while)
str1 = 'helloworld'
for i in str1:
if i == 'w':
break
print(i)5、循环else语句的使用
要循环正常结束之后才执行else,注意是正常结束,如果break提前结束则不执行else,如果是continue则执行else,while与for同理
五、字符串
1、认识字符串
字符串可以用单引号双引号,也可以用三个单/双引号,三引号可以正常输出换行,单双不行
a = ('asd'
'bs')
print(a)
b = '''hello
world'''
print(b)2、字符串的输入输出
输出可以直接输出和格式化输出
# 输入
n = input('请输入密码:')
print(f'密码是{n}')
print(type(n))3、切片
字符串下标
i = 0
str = 'sadgvxce'
while i < 8:
if str[i] == 'g':
i += 1
continue
print(str[i])
i += 1切片
切片是指对操作的对象截取其中一部分的操作 序列【开始位置下标:结束位置下标:步长】
注意:不包含结束位置下标对应数据,正负整数均可;步长是选取间隔,默认为1,正负数皆可
str = '012345678'
print(str[0:5:2])
print(str[0:5:1])不写开始,默认0开始;不写结束,表示选取到最后;不写步长,默认为1;不写开始和结束(但是要写冒号),选取所有。
步长为-1,倒序(从右往左数);起止位置上的负数,-1是最后一个数据
!!如果选取方向和步长冲突,则无法选取
4、字符串的常用操作方法
查找find(),index(),count()
find()用法:序列.find( '子串' , 开始下标,结束下标 ) 存在返回开始下标,不存在返回-1
rfind()从右侧开始查找
index()用法:序列.index( '字串',开始下标,结束下标 )存在返回开始下标,不存在报错
rindex()从右侧开始查找
count()用法:序列.count( '字串' ,开始下标,结束下标 )返回区间字串个数,不存在返回0
a = 'hello world and welcome and go to'
print(a.find('and' ,15,30))修改replace(),split(),join()
replace():序列.replace(旧字串,新字串,替换次数),替换次数不写表示全部替换
replace并不会修改字符串本来的数据,只是会返回修改后的数据,说明字符串是不可变数据类型
a = 'hello world and welcome and go to'
b = a.replace('and','he')
print(b)split():序列.split(分割字符,num) num表示分割字符出现的次数,即将来返回数据个数为num+1
a = 'hello world and welcome and go and to'
b = a.split('and',2)
print(b)join():字符或字串.join(多字符串组成的序列)
意思就是比如我有一个'R','E','D'三个字母组成一个序列,我用 . 把他们连接起来,这时候可以join
a = ['r','e','d']
b = '.'.join(a)
print(b)转换capitalize(),title(),lower(),upper()
capitalize():将字符串第一个字符转换成大写,!!只有首字母大写,后面的大写会转成小写
title():将字符串每个单词首字母大写
lower():将字符串中大写转小写
upper():将字符串中小写转大写
删除首位空白字符lstrip(),rstrip(),strip()
a = ' hello world and go and to and she '
print(a.rstrip())对齐ljust(),rjust(),center()
序列.ljust(长度,填充字符)
str = 'hello'
str
'hello'
str.ljust(10)
'hello '
str.ljust(10,'a')
'helloaaaaa'判断1.0startswith(),endswith()
startswith():序列.startswith(字串,开始下标,结束下标) 作用是检查是否以某个字串开头是返回True,否返回False
a = 'hello world and go and to and she'
print(a.startswith(' ',5,30))!!注意:空格也算字符,字符串首个数据是从0开始算的
endswith():同理
判断2.0isalpha(),isdigit(),isalnum(),isspace()
isalpha():至少有一个字符并且所有字符都是字母时True
isdigit():只包含数字返回True
isalnum():都是字母或数字或数字字母True
isspace():都是空白True
六、列表
1、列表的遍历
for循环
a = ['doas','mdoo','owmd']
for i in a:
print(i)while循环
a = ['doas','mdoo','owmd']
i = 0
while i < len(a):
print(a[i])
i += 12、列表的常用操作
查找 下标查找or函数查找index(),count(),len()
同字符串查找
判断是否存在in,not in
a = ['doas','mdoo','owmd']
print('doas' in a )in,not in体验案例
a = ['ivy','qiana','lulu']
b = input('请输入名字:')
if b in a:
print(f'你输入的名字为{b},用户名已存在')
else:
print(f'输入成功')列表增加数据append(),extend(),insert()
append():序列.append( 数据 ) 追加数据到结尾,如果追加序列则是一整个序列都追加到结尾,append只能追加一个元素
extend():如果追加的是一个序列,那么会把里面的数据拆开逐一追加到列表结尾
insert():序列.insert( 下标,数据 )
a = ['ivy','qiana','lulu']
a.insert(1,'jinny')
print(a)列表删除数据del(),pop(),remove(),clear()
del():del 目标,也可以 del a[ 0 ]删除单个数据
a = ['ivy','qiana','lulu']
del a[2]
print(a)pop():删除指定下标的数据,如果不指定默认删除最后一个数据,无论删哪个,pop函数都会返回这个被删除的数据 序列.pop( 数据 )
a = ['ivy','qiana','lulu']
b = a.pop()
print(a,b)remove():序列.remove( 数据 )
clear():清空列表
修改reverse(),sort()
修改指定下标数据可以直接修改
reverse():逆序排列 序列.reverse( )
sort():排序 序列.sort( ) 默认是False升序 序列.sort( reverse = True )降序
复制
a = ['ivy','qiana','lulu']
b = a.copy()
print(b)3、列表嵌套
一个列表里面包含其他子列表
a = [['ivy','qiana','lulu'],['alyce','betty'],['xiu','jinny']]
print(a[0][1])4、综合应用--老师随机分配办公室
需求:有三个办公室,8位老师,8位老师随机分配到三个办公室
import random
teachers = ['jinny','xiu','alyce','betty','ivy','qiana','lulu','num8']
office = [[],[],[]]
for name in teachers:
i = random.randint(0,len(office)-1)
office[i].append(name)
j = 0
while j < len(office):
print(office[j],len(office[j]))
j += 1七、元组
1、定义元组
如果定义的元组只有一个数据,那么这个数据后面也好添加逗号,否则数据类型为唯一数据的数据类型
a = (2,3,4)
b = ('a',)
print(type(b))2、元组的常见操作
查找
按下标,index,count,len !!注意在元组中count不能这样(‘字串’,起,止),这是错的,要么就是一个数据,要么就是先切片,如下图
a = ('2','3','4','5')
print(a[1:2].count('2'))
修改
在元组中,如果元组里有嵌套的列表,则可以修改列表里的数据
八、字典
1、创建字典的语法
字典里面的数据是以键值对( key:value )的形式出现,和数据顺序无关即字典不支持下标
dict1 = {'name':'ivy','age':19,'birthday':828}
dict2 = {}
dict3 = dict()2、字典的常见操作
增:字典序列[ key ] = 值
dict1 = {'name':'ivy','age':19,'birthday':828}
dict1['num'] = 5
print(dict1)删:del(),clear()
dict1 = {'name':'ivy','age':19,'birthday':828}
del dict1['birthday']
print(dict1)修改:字典序列[ key ] = 值
dict1 = {'name':'ivy','age':19,'birthday':828}
dict1['age'] = 20
print(dict1)查找:key值查找,get(),keys(),values(),items()
key值查找:如果当前查找的key值存在,则返回对应的值,否则报错
get():序列.get( 'key' ,默认值) 有key则返回,key不存在则返回默认值或者none
dict = {'name':'ivy','age':19,'birthday':828}
a = dict.get('id')
b = dict.get('id','没有id')
c = dict.get('name')
print(a,b,c)keys():序列.keys() 查找字典中所有的key,返回可迭代对象,结果为:
!!可迭代对象:通常按顺序访问,不能按下标访问
values():同keys,查找字典中所有value
dict_keys(['name', 'age', 'birthday'])items():查找字典中所有的键值对,返回可迭代对象,里面的数据是元组
dict_items([('name', 'ivy'), ('age', 19), ('birthday', 828)])
3、字典的循环遍历
遍历
keys,values,items同理
dict = {'name':'ivy','age':19,'birthday':828}
for i in dict.keys():
print(i)拆包
items()返回可迭代对象,内部是元组,元组数据1是key,元组数据2是value
dict = {'name':'ivy','age':19,'birthday':828}
for key,value in dict.items():
print(f'{key} = {value}')九、集合
1、创建集合
可以用{}或set(),但是如果要创建空集合只能用set(),因为{}用来创建空字典
集合用于存储不允许重复的数据(有去重功能)
set1 = {1,2,4,6,3}
print(set1)
set2 = set()
print(set2)2、集合常见操作方法
增:add(),update()
add()追加单一数据:集合数据是没有顺序的,所以add可能追加到任意位置,集合有去重功能,如果增加数据是已有数据,则什么事情都不做
set1 = {1,2,4,6,3}
set1.add(5)
print(set1)update()追加序列:如果update() 括号内是[] 追加列表中的数据,{}追加键key
set1 = {1,2,4,6,3}
set1.update([4,2,5,7])
print(set1)删:remove(),discard(),pop()
remove删除指定数据,不存在的数据会报错
discard删除指定数据,不存在的数据不会报错
pop删除随机数据,并返回这个数据
查找:in,not in
set1 = {1,2,4,6,3}
a = 10 in set1
print(a)十、公共操作
1、运算符
+,*,in,not in
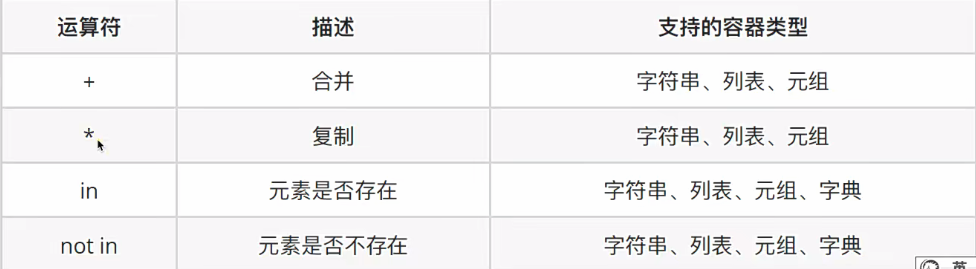
!!注意:in 和 not in 在字典中会默认检查键而不是值
len()计算容器中元素个数
在字典中是返回键值对的个数
del 目标 或 del( 目标 )
str1 = 'asdafasd'
list = [2,3,4,5]
tuple = (2,3,4,5)
set1 = {2,3,4,5}
dict = {'name':'ivy','age':25}
del dict['age']
print(dict)max,min
!!注意:因为max还有len,del这种是公共函数,这些是写在括号里,之前的replace,append这些是某个数据类型独有的操作方式,称之为方法,要用 . 调用
list = [2,3,4,5]
print(max(list))range(start,end,step)
和切片类似,结束不包含,如果range只输入一个数字默认为stop,并且从0开始步长为1
for i in range(10):
print(i)
enumerate(可遍历对象,start = 0)
start用来设置遍历数据下标的起始值,默认为0,enumerate返回结果是元组
list = ['a','b','c','d','e','f']
for i in enumerate(list):
print(i)(0, 'a')
(1, 'b')
(2, 'c')
(3, 'd')
(4, 'e')
(5, 'f')如果start = 1,就是从1开始
2、容器类型转换tuple(),list(),set()
可以互相转换,注意转换成集合set的时候会去掉重复的数据
3、while,for循环创建有规律的列表
list = []
i = 0
while i < 10:
list.append(i)
i += 1
print(list)list = []
for i in range(10):
list.append(i)
print(list)4、推导式
4.1、列表推导式
list = [i for i in range(10)]
print(list)带if的列表推导式range()步长实现,if实现
list1 = [i for i in range(0,10,2)]
list2 = [i for i in range(10) if i % 2 == 0]
print(list1)
print(list2)多个for循环实现列表推导式
list = [(i,j) for i in range(0,2) for j in range(3)]
print(list)4.2 字典推导式
作用:快速合并列表为字典或提取字典目标数据
dict = {i:i**2 for i in range(1,5)}
print(dict)将两个列表合并为一个字典;!!注意创建的时候是两个列表[ ]合并为一个字典{ }
如果两个列表数据个数相同,len任何一个列表都可以,个数不同的话,只能len少的
dict1 = ['name','age','gender']
dict2 = ['tom',25,'man']
dict3 = {dict1[i]:dict2[i] for i in range(len(dict1))}
print(dict3)提取字典目标数据
dict1 = ['name','age','gender']
dict2 = ['tom',25,'man']
dict3 = {dict1[i]:dict2[i] for i in range(len(dict1))}
count = {key:value for key,value in dict3.items() if value == 25}
print(count)4.3、集合推导式
list = [1,1,4]
set = {i ** 2 for i in list}
print(set)十一、函数
1、定义函数->调用函数
def sel_fun():
print('显示余额')
print('存款')
print('取款')
print('恭喜您调用成功')
sel_fun()
print('您的余额是10000000000')
sel_fun()
print('取款成功10000')
sel_fun()2、函数参数的作用
def add_fun(a,b):
return a+b
c = add_fun(1,2)
print(c)return作用:负责函数返回值,退出当前函数(导致return下方的函数体内部的代码不执行)
3、函数的说明文档
help( ):查看函数的说明文档 说明文档是定义函数完了首行缩进三引号
def add_fun(a,b):
"""求和函数"""
return a+b
c = add_fun(1,2)
print(c)
help(add_fun)4、函数嵌套调用
案例1:打印多条横线
def print_line():
print('-'*10)
def print_lines():
for i in range(5):
print_line()
print_lines()案例2:求三个数平均值
def add_num(a,b,c):
return a+b+c
def average_fun(a,b,c):
return add_num(a,b,c)/3
print(average_fun(1,2,3))5、变量作用域
局部变量
定义在函数体内部的变量,只在函数体内部生效
全局变量
全局生效,定义在外部,如果要修改全局变量,不能在函数里修改,想要修改要global声明全局
a = 100
def fun1():
global a
a = 200
print(a)
fun1()函数返回值
返回多个值时会返回元组,也可以返回列表,元组,字典,集合
def fun():
return 1,2
a = fun()
print(a)(1, 2)6、函数的参数
位置参数
根据函数定义的参数位置传递参数,顺序和个数必须一致
def fun(name,age,gender):
print(f'名字是{name},年龄{age},性别{gender}')
fun('tom',18,'男')关键字参数
没有顺序需求,位置参数必须在关键字参数的前面
def fun(name,age,gender,day):
print(f'名字是{name},年龄{age},性别{gender},第几天{day}')
fun('tom',20,day = 7,gender = 'man')缺省参数
也叫默认函数,用于定义函数,为参数提供默认值,不传数据使用默认值,传数据则修改默认值
def fun(name,age,gender = 'man'):
print(f'名字是{name},年龄{age},性别{gender}')
fun('tom',20)不定长参数
包裹位置传递 def fun(*args) 是元组类型
def fun(*args):
print(args)
fun(1,2)包裹关键字传递 def fun(**kwargs) kw是key word 是字典类型
def fun(**kwargs):
print(kwargs)
fun(name = 'tom', age = 20)7、拆包和交换变量值
拆包
# 元组拆包
def fun1():
return 1,2
num1,num2 = fun1()
print(num1)
print(num2)
# 字典拆包 先准备字典然后拆包
dict1 = {'name':'tom','age':18}
a,b = dict1
print(a,dict1[a])
print(b,dict1[b])
交换变量的值 两种方法
# 方法一 利用中间变量
c = 0
c = a
a = b
b = c
# 方法二
a,b = 1,2
a,b = b,a8、引用
可变与不可变类型
我们可以用id( )来判断两个变量是否为同一个值的引用
这个是int不可变类型的案例 在a修改之后b已经不是和a一个地址了
a = 1
b = a
print(id(a))
print(id(b))
a = 1418
print(id(a))
print(id(b))列表list是可变类型,案例如下
aa = [1,2]
bb = aa
print(id(aa))
print(id(bb))
aa.append(3)
print(id(aa))
print(id(bb))
引用当作实参
可以当作实参传入 int:计算前后id不同 list:计算前后id相同
十二、函数高级
1、综合案例--学员管理系统
def info_print():
print('请选择功能-------------------')
print('1、添加学员')
print('2、删除学员')
print('3、修改学员信息')
print('4、查询学员信息')
print('5、显示所有学员信息')
print('6、退出系统')
print('-'* 30)
def info_add():
global info
name_add = input('请输入学生姓名:')
id_add = int(input('请输入学生学号:'))
tel_add = int(input('请输入学生手机号:'))
for i in info:
if i['name'] == name_add:
print('请勿重复输入学生')
return
info_dict = {}
info_dict['name'] = name_add
info_dict['id'] = id_add
info_dict['tel'] = tel_add
info.append(info_dict)
print(info)
def info_del():
global info
del_name = input('请输入要删除的学生姓名:')
for i in info:
if i['name'] == del_name:
info.remove(i)
break
else:
print('学生不存在')
print(info)
def info_modify():
global info
modify_name = input('请输入要修改信息的学生姓名:')
for i in info:
if i['name'] == modify_name:
modify_num = int(input('请输入要修改的信息内容:1--学号 2--手机号'))
if modify_num == 1:
new_id = int(input('请输入新的学号:'))
i['id'] = new_id
break
elif modify_num == 2:
new_tel = int(input('请输入新的手机号:'))
i['tel'] = new_tel
break
break
else:
print('学生不存在')
print(info)
def info_index():
global info
index_name = input('请输入你要查询信息的学生姓名')
for i in info:
if i['name'] == index_name:
print(i)
break
else:
print('学生不存在')
def info_show():
global info
print(info)
info_print()
info = []
while True:
fun_num = int(input('请输入功能序号:'))
if fun_num == 1:
info_add()
elif fun_num == 2:
info_del()
elif fun_num == 3:
info_modify()
elif fun_num == 4:
info_index()
elif fun_num == 5:
info_show()
elif fun_num == 6:
exit_flag = input("确认退出输入‘yes',不退出输入'no'")
if exit_flag == 'yes':
break
else:
print('不符合要求,请输入序号1~6')
2、递归函数
特点+案例求3以内累加和
1、函数内部自己调用自己;2、必须有出口
def sum1(num):
if num == 1:
return 1
return num + sum1(num-1)
print(sum1(3))3、匿名函数
应用场景
如果一个函数有一个返回值,并且只有一句代码,可以使用lambda简化
语法
lambda 参数列表:表达式
lambda表达式的参数可有可无,lambda表达式能接收任何数量的参数但只能返回一个表达式的值
fn2 = lambda:100
print(fn2)
print(fn2())fn2返回lambda内存地址 fn2()是调用函数返回100
fn2 = lambda a,b:a+b
print(fn2(1,2))lambda的参数形式
# 无参
fn1 = lambda : 100
print(fn1())
# 一个参数
fn2 = lambda a : a
print(fn2('ivy'))
# 默认参数
fn3 = lambda a,b,c = 100 : a + b + c
print(fn3(50,30))
# 可变参数 *argus 返回元组
fn4 = lambda *argus : argus
print(fn4(1,2,3))
# 可变参数 **kwargus
fn5 = lambda **kwargus : kwargus
print(fn5(name = 'ivy',age = 19))lambda的应用
fn1 = lambda a,b : a if a > b else b
print(fn1(1, 2))4、高阶函数
列表内字典数据排序
!!注意:lambda就和len类似,len对于字符串来说,是一个一个len(‘字符串’)把他们对应的长度都取出来,然后sort执行排序,lambda就是把字典里对应关键字的value一个一个取出来而已
students = [
{"name": "Tom", "age": 20},
{"name": "Jerry", "age": 18},
{"name": "Alice", "age": 22},
]
students.sort(key = lambda x : x['name']) # 交给 sort,让它自己调用
print(students)
abs( )和round( )
abs():完成求绝对值计算 round():完成对数字的四舍五入计算
def add(a,b,f):
return f(a)+f(b)
print(add(1,-2,abs))map( )
map():map(func,list),将传入变量func作用到list变量的每个元素中,并将结果迭代器返回
def func(a):
return a**2
list1 = [1,2,3,4]
result = map(func,list1)
print(result)
print(list(result))
reduce( ):要导入模块functools
reduce():reduce(func,list),其中func必须有两个参数。每次func计算的结果继续和序列下一个元素做累积计算,!!注意:reduce的第一步会取两个元素,然后每一轮是用上一步的运行结果和下一个数据进行计算
import functools
list1 = [1,2,3,4,5]
def func(a,b):
return a+b
result = functools.reduce(func,list1)
print(result)filter( )
filter():用于过滤序列,过滤掉不符合条件的元素,返回一个filter对象,如果要转换成列表可以用list( )
list1 = ['jinny','xiu','alyce','betty','ivy','qiana','lulu']
def func(x):
return len(x) == 5
result = filter(func,list1)
print(list(result))十三、文件操作
文件操作的作用就是把一些内容(数据)存储存放起来,可以让程序下一次执行的时候直接使用,而不必重新制作一份,省时省力
1、文件操作步骤
打开
open():open( name,mode ),如下此时f是open函数的文件对象
f = open('test.txt'.'w')name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、读写、追加等,如果访问模式省略表示访问模式为r只读
主访问模式 r,w,a
r只读:如果文件不存在,报错,不支持写入操作,表示只读
w只写:如果文件不存在,新建文件,如果执行写入,会覆盖原有内容
a追加:如果文件不存在,新建文件,如果执行写入,在原有内容基础上追加新内容
写write()
读read(),readlines(),readline()
文件对象.read( ),括号里可以有参数,代表多少个字节,文件如果换行会有\n字节占位情况
f = open("test.txt","r")
print(f.read(10))
readlines是一行一行读取的,返回由多个行组成的列表,每一行数据为一个元素返回结果如下
['hello world\n', 'aaa\n', 'bbb\n', 'ccccc\n']readline一次读一行,返回一行数据
访问模式拓展 r,rb,r+,rb+,w,wb,w+,wb+,a,ab,a+,ab+
b是以二进制格式打开的意思, +是可读可写的意思
r开头为拓展的,要和r只读一样,如果文件不存在要报错
w+模式下读取时,因为什么都没有输入,覆盖了之前文件里的内容,所以读出来是空的,一下这个代码运行结果是空的
f = open("test.txt","w+")
result = f.read()
print(result)
f.close()
a+模式下读取时,因为文件指针在结尾,无法读取数据
seek()函数
用来移动文件指针的位置, 文件对象.seek(偏移量,起始位置) 起始位置:0开头1当前2结尾
f = open("test.txt","r+")
f.seek(2,0)
result = f.read()
print(result)
f.close()
2、文件备份
规划文件名
用户当前目录下任意文件名,如果想要给他备份的话,类似这样 test[备份].txt
步骤:接收用户输入的文件名;规划备份文件名;备份文件写入数据(和原文件一样)
!!注意:在给文件备份的时候,我们要找到文件后缀与文件名之间的那个点,然后用原名字+[备份]+后缀结合为备份,我们找点的时候用rfind从右侧开始找,原名字其实就是整个文件名的一个字串,这里我们用切片,切片的语法是字符串['开始下标':‘结束下标’:步长]
old_name = input('请输入想要备份的文件名:')
index = old_name.rfind('.')
print(old_name[:index])
print(old_name[index:])
new_name = old_name[:index]+'[备份]'+old_name[index:]
print(new_name)文件备份写入数据
如果不确定目标文件大小,我们循环读取写入,如果读取出来的数据没有了(len==0),退出循环
old_name = input('请输入想要备份的文件名:')
index = old_name.rfind('.')
new_name = old_name[:index]+'[备份]'+old_name[index:]
print(new_name)
old_f = open(old_name,'rb')
new_f = open(new_name,'wb')
while True:
con = old_f.read(1024)
if len(con) == 0:
break
new_f.write(con)
old_f.close()
new_f.close()!!思考:如果输入的文件是这种 .txt 这种无效的文件名,需要弹一个报错来限制一下,这个时候需要判断是否index > 0,下面是改进后的代码
old_name = input('请输入想要备份的文件名:')
index = old_name.rfind('.')
if index > 0:
postfix = old_name[index:]
# new_name = old_name[:index]+'[备份]'+old_name[index:]
new_name = old_name[:index]+'[备份]'+ postfix
print(new_name)
old_f = open(old_name,'rb')
new_f = open(new_name,'wb')
while True:
con = old_f.read(1024)
if len(con) == 0:
break
new_f.write(con)
old_f.close()
new_f.close()3、文件和文件夹的操作
文件操作rename(),remove()
注意rename既可以完成文件重命名也可以完成文件夹重命名
在python中文件和文件夹的操作要借助os模块里的相关功能,所以要导入os模块
remove的时候如果文件不存在会报错
import os
os.rename('77.test','77.txt')import os
os.remove('test[备份].txt')
文件夹操作创建和删除mkdir(),rmdir()
mkdir(文件名):make directory创建文件夹,如果文件夹已经存在会报错
import os
os.mkdir('dictory')
rmdir(文件名):remove directory删除文件夹,如果文件夹不存在会报错
import os
os.rmdir('dictory')
路径相关函数getcwd(),chdir(),listdir()
getcwd():get current working directory获取当前工作目录所在路径
import os
print(os.getcwd())
# 结果E:\Py_project\project1chdir():切换当前的文件目录,如要在别的文件目录下创建文件或文件夹,要先切换当前文件目录
import os
os.chdir('test') # 把当前文件目录切换到test
os.mkdir('dir_in_test') # 在test文件夹下面创建文件夹
listdir():获取目录列表,也可以写参数,比如listdir(‘test’),这样就会返回我上面刚刚创建好的dir_in_test这个文件夹
import os
print(os.listdir())
#运行结果
['.idea', '.venv', '77.txt', 'info_stu.py', 'main.py', 'sound.txt.mp3', 'test', 'test.py']4、应用案例--批量重命名
以下代码在当前列表所有的文件夹前面加上了Python_,属于添加指定字符串
删除Python_重命名
import os
files = os.listdir()
for i in files:
new_name = 'Python_' + i
os.rename(i,new_name)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)