TiDB优化从入门到精通:全方位指南与实战技巧
TiDB性能优化指南:从架构认知到实战调优 本文系统性地介绍了TiDB分布式数据库的性能优化方法。首先剖析了TiDB的核心架构组件和SQL执行流程,强调理解物理执行计划的重要性。进阶部分提出层级化优化体系:通过EXPLAIN分析执行计划、优化数据库Schema设计、改进SQL写法、维护准确的统计信息。精通篇深入讲解执行计划绑定、系统参数调优、监控诊断和热点处理等高级技术。最后通过典型案例演示优化全
引言
TiDB 作为一款领先的分布式 NewSQL 数据库,因其出色的水平扩展性、强一致性和高可用性,被广泛应用于各种对数据规模和数据一致性有高要求的企业级场景。然而,与传统单机数据库不同,分布式数据库的优化是一个更复杂、更立体的系统工程。本文将带你从入门到精通,系统地掌握 TiDB 的性能优化之道。
第一部分:入门篇 - 理解 TiDB 架构与核心概念
“工欲善其事,必先利其器”。优化 TiDB 的第一步是深入理解其核心架构,知道查询是如何执行的。
1.1 TiDB 核心组件回顾
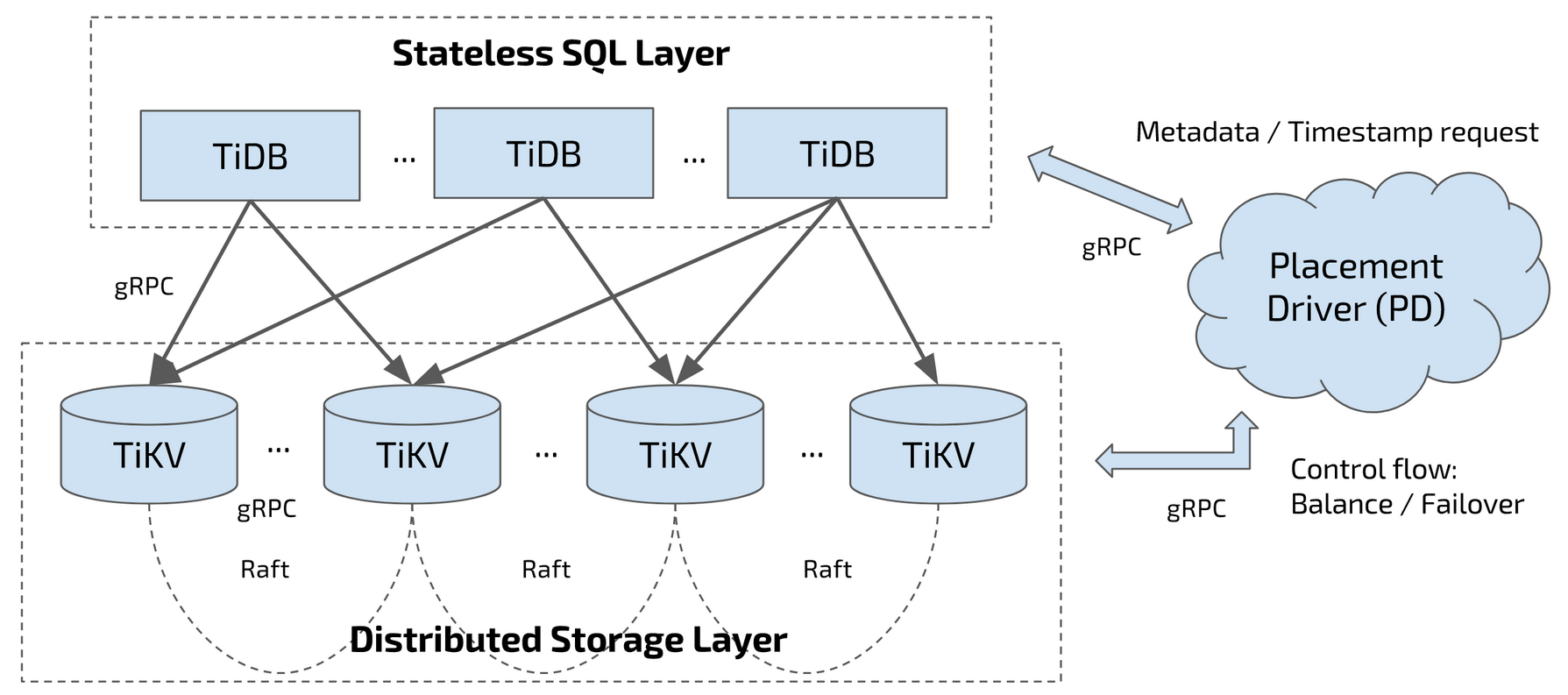
TiDB Server:无状态的计算层,负责接收 SQL 请求,处理 SQL 逻辑,生成分布式执行计划。它是应用程序直接对接的端点。
PD (Placement Driver) Server:整个集群的“大脑”,负责元数据存储、调度 TiKV 数据分布、分配全局唯一且递增的事务 ID。
TiKV Server:分布式、支持事务的 Key-Value 存储引擎,是数据的持久化层。数据以 Region 为单位进行复制和分散。
TiFlash:列式存储引擎,通过 Raft 协议从 TiKV 异步复制数据,专门用于处理分析型(AP)查询,提供强大的实时分析能力。
1.2 一条 SQL 语句的旅程
当你执行一条 SELECT * FROM users WHERE id = 1; 时,发生了什么?
1) 解析与验证:TiDB Server 解析 SQL,进行语法和语义检查。
2) 制定逻辑计划:将 SQL 转换为一个逻辑执行计划(比如,先过滤 where,再投影 select)。
3)制定物理计划:这是优化的核心!TiDB 会根据数据的统计信息(Statistics),将逻辑计划转化为一个具体的、可在 TiKV 上执行的分布式物理计划。
点查 (Point Get):如果 id 是主键或唯一索引,TiDB 会直接计算出数据所在的 Key 和 Region,直接访问对应的 TiKV。
索引读 (Index Lookup):如果 id 是普通索引,可能会先读索引拿到主键,再回表查数据。
全表扫 (Table Full Scan):如果没有索引,则会发起一个全表扫描(应尽量避免!)。
执行与聚合:TiDB 将计算任务下推(Coprocessor)到各个 TiKV 节点并行执行,最后在 TiDB Server 层进行汇总(Aggregation)并返回给客户端。
入门小结:优化的本质,就是让这个“旅程”尽可能高效,减少不必要的数据传输和计算,其关键在于制定一个好的物理执行计划。
第二部分:进阶篇 - 系统化的优化方法
TiDB 优化遵循一个清晰的层次结构,我们应自上而下地进行。
2.1 优化第一法则:使用 TiDB 执行计划分析 (EXPLAIN)
EXPLAIN 是你最强大的工具,它展示了 TiDB 是如何执行某条 SQL 语句的。
EXPLAIN:仅展示物理执行计划的逻辑步骤,不真正执行。
EXPLAIN ANALYZE:真正执行 SQL,并输出各步骤的实际执行时间和开销。这是性能分析的黄金标准。
如何解读 EXPLAIN?关注以下关键算子:
TableFullScan:全表扫描。红色警报!通常意味着缺失索引。
IndexLookUp:索引回表查询。先通过索引读到一个批量的主键,再根据主键去查数据。如果回表数据量很大,效率会降低。
IndexFullScan:全索引扫描。如果只查询索引列,可能不需要回表。
Point_Get / Batch_Point_Get:基于主键或唯一索引的点查,性能最佳。
Selection:过滤条件。理想情况是 Selection 被下推到 TiKV 端执行,而不是在 TiDB 端过滤。
Aggregation:聚合。注意是 HashAgg 还是 StreamAgg,以及聚合是否被下推。
tidb_decode_row:表示网络传输了大量原始行数据,可能存在优化空间。
示例:
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 100;
如果输出中出现 TableFullScan,你就需要为 user_id 列创建索引。
2.2 数据库模式 (Schema) 优化
1) 选择合适的主键:使用单调递增的整型(BIGINT)作为主键,有利于顺序写入,避免 TiKV Region 热点。避免使用随机字符串(如 UUID)作为主键。
2)二级索引优化:
覆盖索引 (Covering Index):索引包含了查询所需的所有列,可以避免回表操作,极大提升性能。
SELECT age FROM users WHERE name = ‘张三’;
创建索引 idx_name_age (name, age) 就是覆盖索引。
前缀索引 (Prefix Index):对字符串列创建索引时,可以只索引前几个字符,节省空间。
CREATE INDEX idx_email ON users(email(10));
3) 控制表的大小:使用 AUTO_RANDOM 代替 AUTO_INCREMENT 来分配主键,可以有效避免写热点。对大字段使用 TEXT/BLOB 并与其他常用列分离到不同表中。
2.3 SQL 语句优化
1)避免全表扫描:确保 WHERE 和 ORDER BY 子句中的列上有索引。
2)使用批量化操作:
不好:INSERT INTO t VALUES (1), (2); (逐行插入)
好:INSERT INTO t VALUES (1), (2); (批量插入)
对于大批量数据导入,使用 Lightning (TiDB Lightning) 工具。
3)避免使用 SELECT *:只取出需要的列,减少网络传输和内存消耗。
4)合理使用事务:保持事务短小精悍,避免大事务(操作太多数据、执行时间太长),因为大事务会增加冲突和锁的压力。
5)运算符优化:谨慎使用 !=, NOT IN, LIKE '%prefix' 等无法有效利用索引的运算符。
2.4 统计信息 (Statistics) - 优化器的“眼睛”
优化器依靠统计信息来估算数据分布和计算成本,从而选择最佳执行计划。统计信息不准会导致优化器“瞎猜”,产生糟糕的计划。
手动收集:ANALYZE TABLE table_name;
自动收集:TiDB 默认开启自动收集,但在大量数据变更后,建议手动触发一次。
统计信息类型:
Full Scan:全表扫描收集,最准确但资源消耗大。
Fast Scan:采样扫描(默认),速度快,但可能不如全扫描准确。
动态采样:TiDB v6.0+ 引入,对于没有统计信息的列,会在查询时自动采样,缓解因统计信息缺失导致的计划问题。
第三部分:精通篇 - 高级调优与集群管理
3.1 执行计划管理 (SPM)
有时,即使统计信息准确,优化器也可能选错计划。SPM 允许你“锁定”一个好的执行计划。
SQL Binding:强制 TiDB 使用一个 Hint 或一个特定的执行计划。
-- 创建一个绑定,强制使用索引
CREATE GLOBAL BINDING FOR
SELECT * FROM t WHERE a > 1
USING
SELECT * FROM t USE INDEX(idx_a) WHERE a > 1;
3.2 系统参数调优
TiDB 参数:
tidb_mem_quota_query:限制单条查询的内存使用,防止不良查询拖垮整个节点。
TiKV 参数(通常通过 PD 动态修改):
region-schedule-limit:控制 Region 调度的并发数,影响平衡速度。
raftstore.apply-pool-size 和 raftstore.store-pool-size:调整 Raft 处理线程数,影响写入吞吐量。
PD 参数:
schedule.leader-schedule-limit:调度 Leader 的速率。
注意:修改集群参数需谨慎,建议在 PingCAP 专家指导下进行。
3.3 监控与诊断:Grafana + Dashboard
TiDB 内置了极其丰富的监控指标。高手一定要学会看 Grafana 面板。
Overview 面板:快速查看 QPS、延迟、连接数等核心指标。
TiDB -> Server:
Query Summary:查看各种语句的耗时、执行时间。
Slow Queries:分析慢查询。
TiKV -> Details:
Cluster:查看 CPU、IO 负载。
Errors:关注 server is busy 和 channel full 错误,通常意味着系统已达瓶颈。
Coprocessor Overview:查看下推任务的执行情况,DAG 线程的 CPU 使用率是关键指标。
PD:查看 Region 健康状态、调度操作等。
诊断流程:QPS/Latency 异常 -> 查看对应组件的 CPU/IO -> 分析慢查询日志 -> 使用 EXPLAIN ANALYZE 定位问题算子。
3.4 热点问题处理
TiDB 通过 PD 自动调度 Region 以分散热点。但你也可以从应用层避免:
写热点:单调递增的主键会导致写请求集中在最后一个 Region。解决方案:使用 AUTO_RANDOM 或 SHARD_ROW_ID_BITS。
读热点:频繁访问少量数据(如热门商品、配置项)。解决方案:使用 TiDB 内置或应用层缓存(如 Redis),减少对数据库的直接访问。
第四部分:实战案例
场景:SELECT * FROM orders WHERE create_time > '2023-01-01’ ORDER BY price DESC LIMIT 10; 执行很慢。
排查步骤:
1) EXPLAIN ANALYZE:发现计划中有 TableFullScan 和 Sort。
2)分析:create_time 和 price 上没有联合索引,导致全表扫描和巨大的排序开销。
3)优化:创建复合索引 idx_time_price (create_time, price DESC)。
该索引可以高效过滤 create_time,并且数据已经按 price 降序排好,只需要取前10条即可。
4)再次 EXPLAIN:确认计划变为 IndexRangeScan,避免了 Sort 算子,性能大幅提升。
总结与思维导图
TiDB 优化是一个系统工程,其核心思想可以总结为以下路径: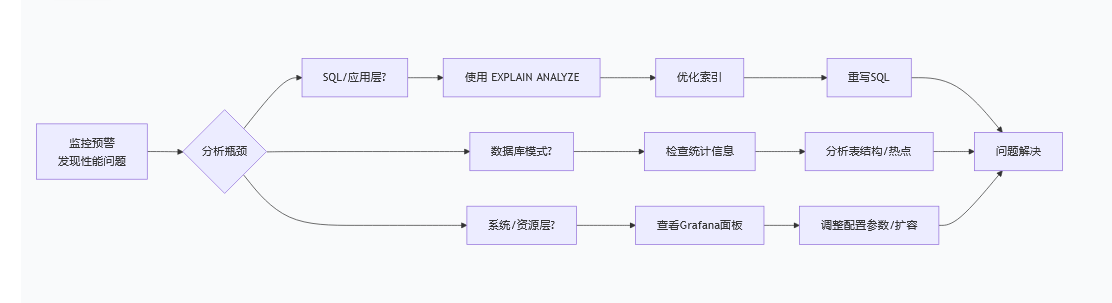
成为高手的关键:
1 习惯看 EXPLAIN ANALYZE:这是你的显微镜。
2 习惯看监控:这是你的仪表盘。
3 理解下推计算:让计算离存储越近越好。
4 怀疑统计信息:计划不好时,先想想统计信息是否准确。
5 从应用设计入手:最好的优化是在设计阶段选择正确的模式、主键和访问模式。
希望这篇详尽的指南能帮助你在 TiDB 性能优化的道路上披荆斩棘,从入门走向精通!
声明:本文部分内容参考了 PingCAP 官方文档和实践经验。随着 TiDB 版本迭代,部分细节可能发生变化,请始终以官方最新文档为准。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)