Context-Aware Pseudo-Label Refinement for Source-Free Domain Adaptive Fundus Image Segmentation
该论文聚焦于无源域自适应(SF-UDA)在眼底图像分割中的应用,提出了一种基于上下文感知的伪标签优化(CPR)框架,有效解决了源数据不可用时模型在目标域上的性能下降问题,尤其针对视杯和视盘分割这一青光眼筛查关键任务。
该论文聚焦于无源域自适应(SF-UDA)在眼底图像分割中的应用,提出了一种基于上下文感知的伪标签优化(CPR)框架,有效解决了源数据不可用时模型在目标域上的性能下降问题,尤其针对视杯和视盘分割这一青光眼筛查关键任务。
一、论文核心背景与问题
1. 领域适配的核心挑战
- 眼底图像分割的临床意义:视杯与视盘的精准分割是计算杯盘比(用于青光眼筛查)的关键,但深度学习模型易受域偏移影响(如不同医院的扫描设备、成像参数差异)。
- 传统无监督域适配(UDA)的局限:需同时访问源域数据(带标签)和目标域数据(无标签),但源数据常因隐私保护(医疗数据)或知识产权问题无法提供,因此催生“无源源域适配(SF-UDA)”。
2. SF-UDA的现有方案与不足
现有SF-UDA方法主要分为四类,但均忽略了“上下文关系”这一关键信息:
| 方法类别 | 核心思路 | 代表工作 | 不足 |
|---|---|---|---|
| BN统计适配 | 对齐源/目标域的批归一化(BN)统计量 | [16,17,23] | 仅关注统计量,未利用图像局部语义关联 |
| 源图像近似 | 生成类源域图像辅助域对齐 | [9,26] | 生成过程复杂,依赖图像风格迁移,易引入噪声 |
| 熵最小化 | 降低模型在目标域预测的不确定性 | [2] | 仅优化预测置信度,未修正伪标签的上下文矛盾 |
| 伪标签法 | 筛选/修正目标域伪标签用于监督 | [3,25] | 未利用“同类特征聚类”特性,伪标签存在上下文不一致(如相邻相似区域标签不同) |
3. 论文的关键观察(创新起点)
- 上下文不一致问题:源模型在目标域生成的伪标签存在“局部矛盾”——视觉相似的相邻区域可能被标注为不同类别(如图1(a)中视盘伪标签的不规则凸起)。
- 同类特征聚类特性:即使存在域偏移,目标域中“同类像素的特征仍会形成聚类”(图1(b)的t-SNE可视化),说明可通过特征距离计算上下文相似度(图1©)。
二、核心方法:CPR框架
CPR框架分为两大阶段,核心是“学习上下文相似度→优化伪标签→用可靠伪标签训练目标模型”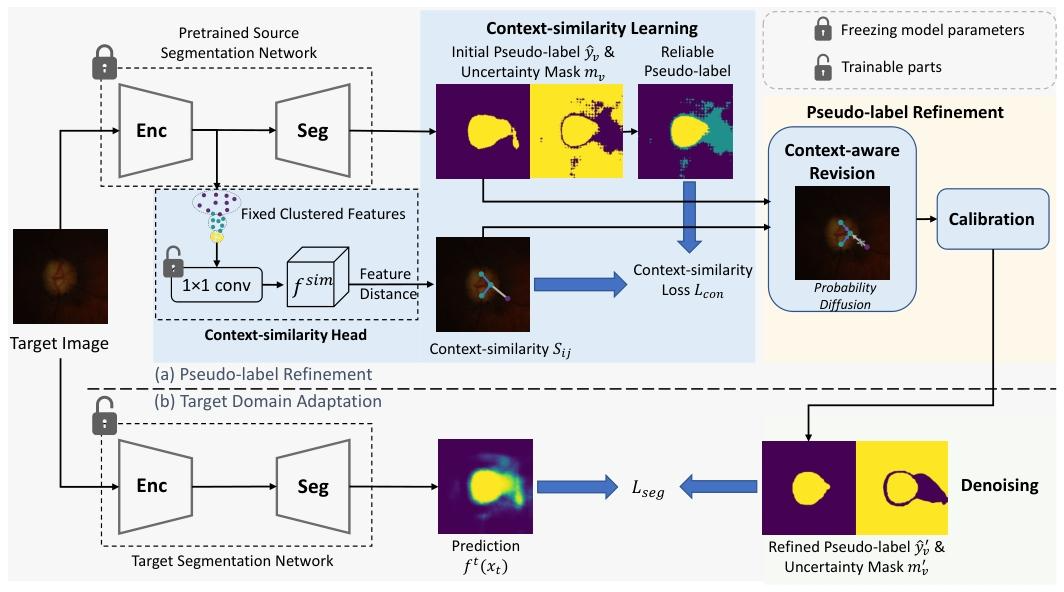
1. 阶段1:上下文相似度学习(Context-Similarity Learning)
(1)核心假设
冻结源模型的特征编码器(避免重新训练,减少计算成本),利用“同类特征聚类”特性,在编码器后添加一个上下文相似度头,学习像素间的语义关联。
(2)关键步骤
-
步骤1:生成初始可靠伪标签
基于源模型,通过蒙特卡洛 dropout(K次前向传播) 计算像素级伪标签和不确定性:- 对目标图像xtx_txt,源模型输出K个预测概率图,计算平均概率pvp_vpv和标准差uvu_vuv(uvu_vuv越大,不确定性越高);
- 伪标签y^v=1[pv≥γ]\hat{y}_v = \mathbb{1}[p_v \geq \gamma]y^v=1[pv≥γ](γ=0.75\gamma=0.75γ=0.75为阈值,1表示前景(视杯/视盘),0表示背景);
- 计算类原型(class prototype) zωz^\omegazω(ω\omegaω为前景/背景):对编码器输出的特征图,仅用“低不确定性(uv<ηu_v<\etauv<η)且标签一致”的像素特征求平均;
- 可靠性掩码mv=1[uv<η]⋅1[像素特征更接近同类原型]m_v = \mathbb{1}[u_v<\eta] \cdot \mathbb{1}[\text{像素特征更接近同类原型}]mv=1[uv<η]⋅1[像素特征更接近同类原型],mv=1m_v=1mv=1表示伪标签可靠。
-
步骤2:训练上下文相似度头
目标是让相似度头输出的“像素对相似度”与“可靠伪标签的一致性”匹配:- 定义相似度标签Sij∗S_{ij}^*Sij∗:若可靠伪标签y^i=y^j\hat{y}_i=\hat{y}_jy^i=y^j,则Sij∗=1S_{ij}^*=1Sij∗=1(同类),否则为0(异类);
- 相似度计算(L1距离的指数衰减,确保距离越小相似度越高):
Sij=exp{−∥fsim(xi,yi)−fsim(xj,yj)∥1}S_{ij} = exp\left\{-\left\| f^{sim}(x_i,y_i) - f^{sim}(x_j,y_j) \right\|_1\right\}Sij=exp{− fsim(xi,yi)−fsim(xj,yj) 1}
(fsimf^{sim}fsim是相似度头的1×1卷积输出,仅计算半径r=4r=4r=4范围内的像素对,降低计算量); - 损失函数(平衡三类相似度损失,避免类别不平衡):
Lcon=−14avg(logSij)y^i=y^j=1−14avg(logSij)y^i=y^j=0−12avg(log(1−Sij))y^i≠y^j\mathcal{L}_{con} = -\frac{1}{4}\text{avg}(logS_{ij})_{\hat{y}_i=\hat{y}_j=1} - \frac{1}{4}\text{avg}(logS_{ij})_{\hat{y}_i=\hat{y}_j=0} - \frac{1}{2}\text{avg}(log(1-S_{ij}))_{\hat{y}_i\neq\hat{y}_j}Lcon=−41avg(logSij)y^i=y^j=1−41avg(logSij)y^i=y^j=0−21avg(log(1−Sij))y^i=y^j
2. 阶段2:伪标签优化(Context-Aware Pseudo-Label Refinement)
(1)上下文感知修正(Context-Aware Revision)
利用学到的上下文相似度SijS_{ij}Sij,对初始伪标签的概率进行“局部加权更新”,解决上下文不一致:
- 对每个像素iii,在半径r=4r=4r=4的局部区域内,以SijβS_{ij}^\betaSijβ(β=2\beta=2β=2,放大高相似度权重)为权重,加权平均邻域像素的概率:
pire=∑d(i,j)≤rSijβ∑d(i,j)≤rSijβ⋅pjp_i^{re} = \sum_{d(i,j)\leq r} \frac{S_{ij}^\beta}{\sum_{d(i,j)\leq r} S_{ij}^\beta} \cdot p_jpire=d(i,j)≤r∑∑d(i,j)≤rSijβSijβ⋅pj
(d(i,j)d(i,j)d(i,j)为欧氏距离,迭代t=4t=4t=4次进一步优化)。
(2)概率校准(Calibration)
问题:若上下文相似度学习不准确(如视杯伪标签质量差),可能导致“前景概率被背景概率污染”(前景概率偏低)。
解决方案:用图像内的最大概率归一化,确保同类区域中心的概率接近1:
pi′=piremaxj(pjre)p_i' = \frac{p_i^{re}}{\text{max}_j(p_j^{re})}pi′=maxj(pjre)pire
3. 阶段3:模型适配(Model Adaptation with Denoised Pseudo-Labels)
(1)筛选可靠伪标签(像素级+类别级去噪)
即使经过优化,伪标签仍有噪声,需结合“概率置信度”和“特征分布”筛选:
- 像素级掩码mv,p′m_{v,p}'mv,p′:保留概率“极低(pv′<γlow=0.4p_v'<\gamma_{low}=0.4pv′<γlow=0.4,视为明确背景)”或“极高(pv′>γhigh=0.85p_v'>\gamma_{high}=0.85pv′>γhigh=0.85,视为明确前景)”的像素;
- 类别级掩码mv,c′m_{v,c}'mv,c′:保留“像素特征更接近同类原型”的像素(同阶段1的可靠性判断逻辑);
- 最终掩码mv′=mv,p′⋅mv,c′m_v' = m_{v,p}' \cdot m_{v,c}'mv′=mv,p′⋅mv,c′(仅mv′=1m_v'=1mv′=1的伪标签用于监督)。
(2)目标模型训练
用筛选后的伪标签y^v′=1[pv′≥γ]\hat{y}_v' = \mathbb{1}[p_v' \geq \gamma]y^v′=1[pv′≥γ],以交叉熵损失训练目标模型(仅更新分割头,编码器可微调):
Lseg=−∑vmv′⋅[y^v′⋅log(ft(xt)v)+(1−y^v′)⋅log(1−ft(xt)v)]\mathcal{L}_{seg} = -\sum_v m_v' \cdot \left[ \hat{y}_v' \cdot log(f^t(x_t)_v) + (1-\hat{y}_v') \cdot log(1-f^t(x_t)_v) \right]Lseg=−v∑mv′⋅[y^v′⋅log(ft(xt)v)+(1−y^v′)⋅log(1−ft(xt)v)]
三、实验验证
1. 实验设置
- 数据集:三个主流眼底图像数据集(均含视杯/视盘标签),按“源域→目标域”分为两组实验:
- 源域:Drishti-GS(50训练/51测试)→ 目标域:RIM-ONE-r3(99训练/60测试);
- 源域:REFUGE(320训练/80测试)→ 目标域:Drishti-GS(50训练/51测试)。
- 模型与指标:
- 基础模型:MobileNetV2+DeepLabv3+(分割网络);
- 评价指标:Dice系数(越高越好,衡量分割重叠度)、平均表面距离(ASD,越低越好,衡量分割边界精度)。
- 对比方法:无适配(直接用源模型测目标域)、上限(用目标域标签训练)、3种SOTA方法(DPL[3]、FSM[26]、U-D4R[25])。
2. 核心结果
(1)与SOTA方法的对比(表1)
两组实验中CPR均显著优于现有方法,以“Drishti-GS→RIM-ONE-r3”为例:
- Dice系数(平均):CPR(85.03%)> U-D4R(83.33%)> FSM(82.88%)> DPL(82.11%);
- ASD(平均):CPR(7.08像素)< U-D4R(8.16像素)< DPL(9.92像素)< FSM(12.41像素)。
- 定性结果(图3(a)):CPR的分割边界更平滑,无明显“上下文矛盾”区域(如视盘边缘无凸起)。
(2)消融实验(验证各模块有效性)
- 模块必要性验证(表2):
- 移除“伪标签优化”:视杯Dice从75.02%降至67.25%,证明优化的核心作用;
- 移除“校准”:视杯Dice降至58.34%(表3),说明校准能有效修正“前景概率被污染”问题;
- 移除“去噪”:平均Dice降至83.23%,说明筛选可靠伪标签可减少噪声监督。
- 伪标签质量提升(表3):优化后的伪标签质量显著提升,视杯Dice从67.66%→72.01%,视盘Dice从90.01%→93.51%(即使初始质量高的视盘标签仍有提升)。
四、结论与局限
1. 核心贡献
- 创新思路:首次将“上下文相似度”引入SF-UDA眼底分割,利用“同类特征聚类”特性修正伪标签的上下文矛盾;
- 实用框架:无需源数据,仅通过“相似度学习→伪标签优化→去噪监督”实现域适配,计算成本低(冻结源编码器);
- 性能验证:在两个跨域任务上超越SOTA,为医疗图像SF-UDA提供可落地方案。
2. 潜在局限
- 适用场景:仅验证了“视杯/视盘二分类分割”,需扩展到多类别眼底分割(如血管、黄斑);
- 参数敏感性:相似度计算的半径rrr、权重β\betaβ等参数需经验调优,缺乏自适应机制;
- 小样本鲁棒性:未验证目标域数据量极小时的性能(如仅10张目标图像)。
五、关键补充信息
- 数据集获取:Drishti-GS、RIM-ONE-r3、REFUGE均为公开眼底数据集,可通过医学图像平台获取;
- 核心公式速查:
- 相似度计算:Sij=exp(−∥fisim−fjsim∥1)S_{ij} = exp(-\left\| f^{sim}_i - f^{sim}_j \right\|_1)Sij=exp(− fisim−fjsim 1);
- 伪标签修正:pire=∑Sijβ∑Sijβ⋅pjp_i^{re} = \sum \frac{S_{ij}^\beta}{\sum S_{ij}^\beta} \cdot p_jpire=∑∑SijβSijβ⋅pj;
- 概率校准:pi′=piremax(pjre)p_i' = \frac{p_i^{re}}{\text{max}(p_j^{re})}pi′=max(pjre)pire。
Context-Aware Pseudo-Label Refinement for Source-Free Domain Adaptive Fundus Image Segmentation
https://github.com/xmed-lab/CPR

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)