构建AI智能体:二十六、语言模型的“解码策略”:一文读懂AI文本生成的采样方法
本文探讨了AI文本生成中的采样方法,这些方法决定了AI如何选择候选词来生成文本。文章介绍了两种主要方法:确定性方法(贪心算法和束搜索)和随机采样方法(基础随机采样、温度采样、Top-k采样和Top-p采样)。贪心算法每次选择概率最高的词,生成结果可靠但缺乏创意;束搜索保留多条候选路径,适合需要准确性的任务。随机采样方法则通过引入随机性增加多样性,其中温度采样通过调整温度参数控制创意的随机程度,To
一、开篇导语
不知道大家有没有刷到过一个趣味玩法,在输入法的文本框以一个什么字开头,一直按下一个下一个,可以生成一句看似完整且有趣的话,这是最早期的通过键盘记忆形成的词组文本。再看看近期豆包和deepseek大火,大家有没有尝试过给他们输入一个简短的文本或情节,让他们进行续写,生成一段内容,经历过这些,不知道你是否曾好奇,这些功能强大的AI工具,是如何从“今天天气真好”这样简单的开头,生成出或严谨、或风趣、或充满创意的长长段落的?它每次生成的答案为何时而稳定,时而多变?这背后的奥秘,就是基于语言模型的采样方法在做决策。采样方法决定了AI在每一步思考时,是做一个严谨的学霸,只认唯一答案;还是成为一个奔放的诗人,在词海中自由徜徉。
今天,我们就来探讨一下采样方法的神秘面纱,了解这些了我们将不再是AI输出的被动接受者,而将成为它的导演,学会如何通过调整温度、Top-p等这些旋钮,精确地控制AI的性格和输出风格。无论你是想让AI基于知识库做精准可靠的问答,还是让它创作动人的故事,这篇文章都将带你由浅入深,通过通俗的讲解和丰富的代码示例(结合Faiss检索和Qwen大模型),彻底掌握这门与AI对话的艺术。

二、AI是怎么说话的
想象一下,让一个语言模型完成这句话:“今天的天气真好啊,我们一起去...”。模型可能会计算出无数个后续词的概率,比如“公园”(概率30%)、“散步”(概率25%)、“爬山”(概率15%)、“睡觉”(概率0.1%)等等。
如果我们每次都只选择概率最高的“公园”,那么模型生成的文本就会非常机械和可预测,缺乏惊喜和创造力。采样或者说解码策略,就是我们从这些概率分布中选择下一个词的一系列规则和方法。它的目的是在生成文本的准确性、多样性、流畅性和创造性之间取得平衡。
采样,也叫解码策略,就是我们教AI如何从这份“候选词清单”里挑词的方法。不同的挑法,会让AI变成不同的角色,是严谨的科学家,还是天马行空的诗人?全看我们怎么掌舵这个方向。
为了更直观地理解如何选择这些方法,我们可以参考下面的决策流程图:
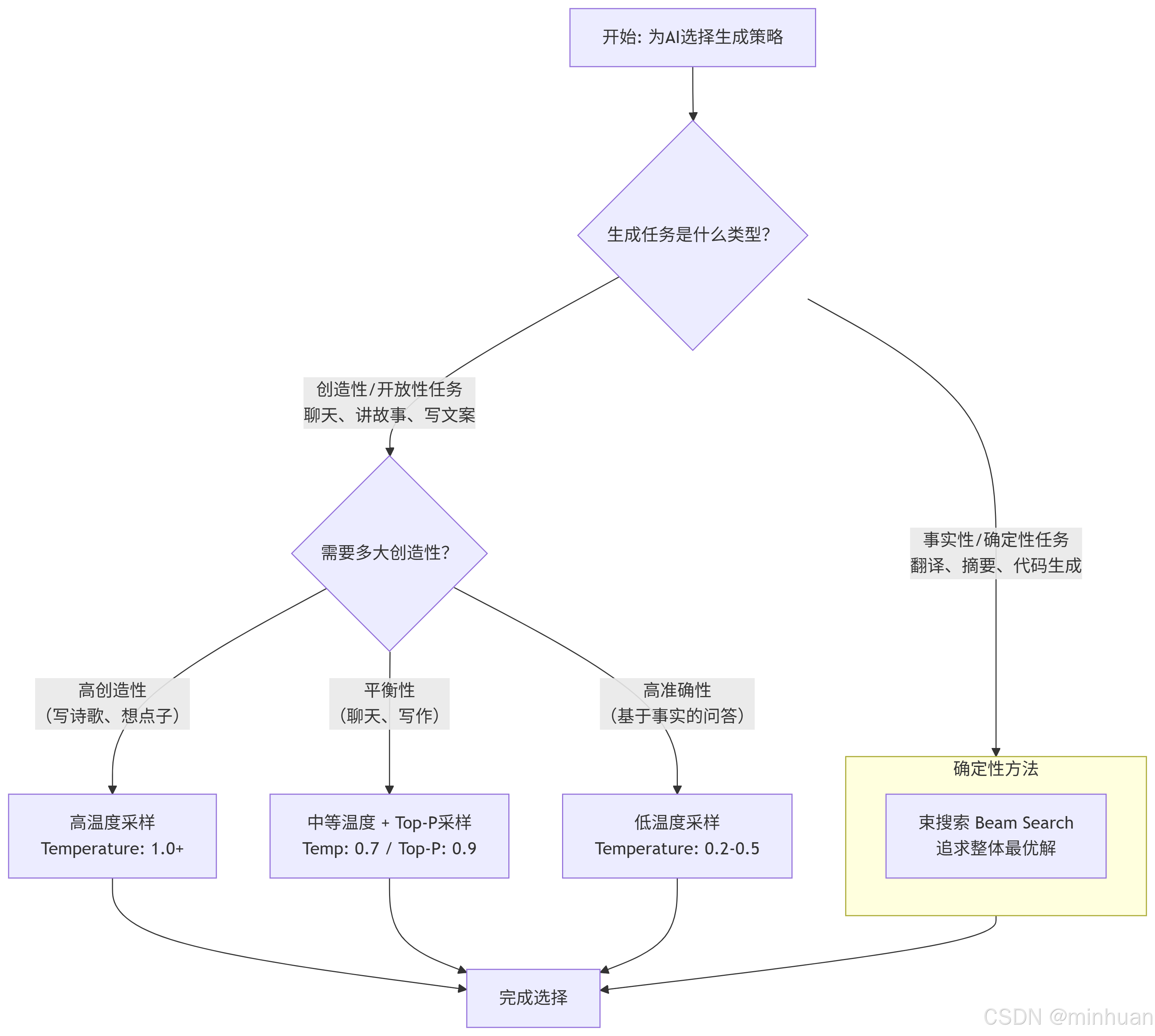
三、采样方法
1. 确定性方法——“严谨的学霸”
这类方法的核心是每次都以某种确定性规则选择概率最高的词,就像是一个严谨的学霸,每次只认“最优解”,所以同样的题目,每次给出的答案都一模一样。
1.1 贪心算法
原理:每一步都毫不犹豫地选择当前概率最高的词。
通俗理解:永远只选当前第一步最好的,不管后面。就像下棋,只吃对方眼前的一个兵,而不考虑接下来十步会不会输。
示例一:提示词:"夏天的午后,最适合吃一块冰镇的"
- "夏天的午后,最适合吃一块冰镇的",看到"西瓜"概率最高(25%),立马选择"西瓜"。
- 接着,"夏天的午后,最适合吃一块冰镇的西瓜",后面概率最高的可能是"。"(句号) ,生成结束。
- 最终输出:"夏天的午后,最适合吃一块冰镇的西瓜。" (正确但平淡)
示例二:提示词:"夏夜的星空,"
- 模型计算 "夏夜的星空," 之后的所有词,发现 "格外" 概率最高,选择 "格外";
- 现在句子是 "夏夜的星空,格外",模型计算下一个词,发现 "明亮" 概率最高,选择 "明亮";
- 句子变为 "夏夜的星空,格外明亮",模型计算下一个词,"。"(句号)概率最高,选择 "。",生成结束。
- 最终输出:"夏夜的星空,格外明亮。"
优点: 计算高效,速度快。
缺点:容易生成重复、无聊的文本,并且可能错过全局更优的序列。因为它可能为了第一步的“西瓜”,错过了“冰镇的芒果蛋糕真是太美味了”这样更长更精彩的句子。
特点:正确但非常平淡、可预测,没有任何惊喜。多次生成只会得到一模一样的结果。
使用场景: 主要用于需要确定性输出和快速生成的简单任务,如实时翻译或语音识别,但现在已较少用于开放式文本生成。
1.2 束搜索 - 贪心搜索的升级版
原理:贪心搜索的升级版,它不再是“孤注一掷”,而是有一个“容错空间”。它会在每一步保留概率最大的k个候选序列,保留多条路径,最终选择整体概率最高的序列。
通俗理解:不是只选1条路,而是同时探索多条(k条)最有潜力的路,最后看哪条路整体最好。
假设 k=2(束宽为2),就像派2个人并行探险。
示例一:提示词:"夏天的午后,最适合吃一块冰镇的"
- 第一步:第一个人选概率最高的"西瓜"(25%),第二个人选第二高的"蛋糕"(20%)。
- 第二步:基于"西瓜"计算后面所有词的概率(如"西瓜很", "西瓜。");基于"蛋糕"也计算一遍(如"蛋糕和", "蛋糕。")。然后从所有这些组合中("西瓜很", "西瓜。", "蛋糕和", "蛋糕。")再选出总体概率最高的2个序列。
- 第三步:如此反复,直到所有人都走到句号为止。
示例二:提示词: "夏夜的星空,"
- 第一步:选择概率最高的两个词:"格外" (1st) 和 "非常" (2nd)。
- 第二步:对于路径1 "格外":计算后续词,比如 "明亮"、"的"...
- 对于路径2 "非常":计算后续词,比如 "明亮"、"美丽"...
- 现在比较所有组合:"格外明亮" vs "格外璀璨" vs "非常明亮" vs "非常美丽"... 假设 "非常美丽" 和 "格外明亮" 是整体概率最高的两条路径。
- 第三步:继续基于这两条路径扩展,直到完成。
- 最终输出:"夏夜的星空,非常美丽。" 或 "夏夜的星空,格外明亮。"
优点:比贪心搜索视野更广,找到全局更优序列的可能性大得多,生成的文本通常整体更通顺、更合理,如“非常美丽”整体上可能比“格外明亮”更优
缺点:生成的内容仍然比较保守、缺乏惊喜和多样性,可能很平淡甚至乏味。而且k值越大,计算量也越大。
使用场景:非常适合有标准答案、事实性强、目标明确的任务,如机器翻译、文本摘要、代码生成,这些任务通常有一个“最佳”答案。
2. 随机采样方法——“富有创意的艺术家”
这类方法通过“掷骰子”的方式引入随机性,从概率分布中随机抽取下一个词,从而让生成内容更具创造性和多样性。让AI变得更有创意。同样的提示,每次生成的结果都可能不同。
2.1 基础随机采样
原理:纯粹地按照模型输出的概率分布进行随机抽样,概率为0.4的词被抽中的机会就是40%,通俗的理解就是按照概率分布“掷骰子”。
实例过程:
- 第一步:"夏夜的星空," 之后的概率分布可能是 {"格外": 0.5, "非常": 0.3, "特别": 0.1, "有如": 0.05, ...}。它完全随机地抽到了一个词,比如 "特别"。
- 第二步:"夏夜的星空,特别" 之后的概率分布,它又随机抽到了 "的"。
- 第三步:"夏夜的星空,特别的",它可能抽到一个低概率词,比如 "深邃"。
- 最终输出:"夏夜的星空,特别的深邃。" (可能通顺)
- 也可能输出:"夏夜的星空,特别西瓜。" (不通顺,甚至荒谬,因为它有可能抽到任何低概率词)。
优点:最大化多样性。
缺点:过于随机,容易产生不合逻辑或不连贯的内容,甚至可能抽到一些奇怪的低概率词。
特点:极度不可控,可能产生有趣的结果,但更可能生成无意义的内容。
使用场景: 在需要高度创造性的场景中偶尔使用,但通常需要与其他技术结合。
2.2 温度采样 - 控制创意的油门
原理:通过温度参数调整概率分布的平滑度后再采样。
通俗理解:这是控制随机性最常用、最有效的手段。它通过一个温度参数来调整概率分布的形状,然后再进行采样。温度就是个“创意油门”。温度值(T)就像控制概率分布是“尖峰”还是“平原”。
示例一:提示词:"夏天的午后,最适合吃一块冰镇的"
低温度 (T < 1, 比如 0.2): “谨慎模式”。猛踩油门,猛踩油门,放大高概率词的差距,让分布更“尖锐”,让高概率的词(如“西瓜”)概率更高,低概率的词(如“拖鞋”)概率更低。AI输出更集中、更可靠、更保守。
- T=0.2时,概率分布可能变为:"西瓜"(0.7) | "蛋糕"(0.2) | ... | "拖鞋"(0.0000001%)。AI几乎肯定会选择“西瓜”。
高温度 (T > 1, 比如 1.5): “疯狂模式”。放松油门,平滑概率分布,缩小高概率和低概率词之间的差距,让所有词都有更接近的机会。AI输出更随机、更创意、也更可能出错。
- T=1.5时,概率分布可能变为:"西瓜"(0.2) | "蛋糕"(0.19) | "冰块"(0.18) | "芒果"(0.17) | ...。AI可能会选择“芒果”这样更有创意的词。
示例二:提示词: "夏夜的星空,"
- 高温度 (T=1.5) 会拉平原始概率分布。原本 "格外"(0.5) 和 "非常"(0.3) 差距很大,现在可能变成 "格外"(0.3), "非常"(0.25), "特别"(0.2), "有如"(0.15)... 差距变小了。
- 模型在这个被平滑后的分布里随机采样,它选中 "有如" 的概率就大大增加了。
- 后续步骤也遵循同样规则。
- 最终输出:"夏夜的星空,有如一幅闪烁的画卷。" (更具文学性和创意)
特点:有效控制输出的随机性程度。低温度(T=0.5)会输出更像贪心搜索的结果("格外明亮"),而高温度能鼓励模型选择更不寻常的词,增加创造性。
使用场景:
低温度:聊天对话、事实问答、文本分析,追求准确和可靠。
高温度:写诗歌、讲故事、生成创意文案,追求新颖和出乎意料。
2.3 Top-k 采样
通俗理解:为了解决基础随机采样可能抽到奇怪低概率词的问题,Top-k采样只从概率最高的k个词中进行采样,并将这k个词的概率重新归一化,使它们的概率之和为1,然后只在这个k个词的候选名单名单里“掷骰子”。
原理:只从概率最高的k个词里采样。
示例一:提示词:"夏天的午后,最适合吃一块冰镇的",假设k=3
- 模型只考虑概率最高的3个词:"西瓜"、"蛋糕"、"冰块"。它会无视后面的所有词(包括“拖鞋”),然后在前三名里随机选择。
- 最终输出:"夏天的午后,最适合吃一块冰镇的西瓜(蛋糕和冰块都有可能)“
示例二:提示词: "夏夜的星空,",假设k=40
- 模型计算出 "夏夜的星空," 之后概率最高的40个词。这个名单里可能包含 "格外", "非常", "特别", "无比", "仿佛", "像"... 等合理的词。
- 它绝对排除了排名第41及以后的所有词,比如一些完全不相关的名词或动词(如“西瓜”、“跑步”),避免了基础随机采样的无意义的内容问题。
- 它在这个“Top-40精英名单”里随机抽样,抽中了 "仿佛"。
- 最终输出:"夏夜的星空,仿佛在低声诉说着什么。"
优点: 有效避免了低概率奇怪词的干扰。
缺点:不够灵活。有时候概率分布可能很平,很多词概率差不多,k值固定可能过滤掉很多合理的候选;有时候分布很尖,只有一个词概率极高,k值固定又可能引入不合适的候选。通俗的讲就是有时候前3个词都很合适,有时第4名其实也是个好词,但被无情淘汰了。
特点:在保证质量的基础上引入多样性,避免了奇怪词,但不够灵活,因为k是固定值。
2.4 Top-p 采样 (核采样) - 创意候选名单
Top-k的升级版,解决了其不够灵活的问题。它不固定候选词的数量k,而是固定一个概率阈值p(通常0.7~0.95)。它从概率最高的词开始累加,直到累积概率刚好超过p,然后只从这个小集合里采样。
原理:从累积概率超过p的最小词集合中采样。
通俗理解:不固定名单数量k,而是固定一个概率总和p。AI从高到低累加词的概率,直到总和超过p,然后在这个动态的名单里“掷骰子”。
示例一: 提示词:"夏天的午后,最适合吃一块冰镇的",p=0.9。
- 模型对"夏天的午后,最适合吃一块冰镇的"之后的词按概率从高到低排序并累加:
- 概率列表:"西瓜"(0.5) -> "蛋糕"(0.2) -> "冰块"(0.15) -> "芒果"(0.1) -> ...
- 累加:0.5 + 0.2 = 0.7 < 0.9;0.7 + 0.15 = 0.85 < 0.9;0.85 + 0.1 = 0.95 > 0.9(停了!)。
- 于是,AI只在 {"西瓜", "蛋糕", "冰块", "芒果"} 这个集合里随机选择。
- 最终输出:"夏天的午后,最适合吃一块冰镇的西瓜(蛋糕、冰块、芒果都有可能)“
示例二:提示词: "夏夜的星空,",p=0.9。
- 模型对 "夏夜的星空," 之后的词按概率从高到低排序并累加:
- 概率列表:"格外" (0.5) -> "非常" (0.3) -> "特别" (0.1)
- 累加:0.5 + 0.3 = 0.8 < 0.9; 0.8 + 0.1 = 0.9 (刚好达到/超过0.9,停止!)
- 此时,动态的候选集合是 {"格外", "非常", "特别"}。模型只从这个集合里随机采样,它抽中了 "特别"。
- 注意:像 "仿佛"(概率0.05)这次没有被包含进来,因为累积概率在 "特别" 这里已经达到阈值了。但如果某次提示的概率分布更平缓,"仿佛" 就可能被包含进来。候选集大小是动态变化的。
- 最终输出:"夏夜的星空,特别让人心旷神怡。"
优点:超级智能!名单大小能根据当前概率分布动态调整。是目前开放式创作的首选方法。
特点:智能且灵活,能自适应不同的概率分布,是创造性任务的首选。它结合了Top-k的优点,同时又克服了其缺点。
使用场景: 几乎所有的创造性文本生成任务,如与ChatGPT等聊天机器人的对话。
3. 示例的特性对比
| 方法 | 实例输入 | 可能输出实例 | 特点 |
| 贪心搜索 | 夏夜的星空, | 格外明亮。 | 单调、可预测、无惊喜 |
| 束搜索 | 夏夜的星空, | 非常美丽。 | 更通顺,但依然保守 |
| 基础随机 | 夏夜的星空, | 特别西瓜。 或 特别的深邃。 | 极度随机,可能荒谬 |
| 温度 (高)采样 | 夏夜的星空, | 有如一幅闪烁的画卷。 | 创造性高,文学性强 |
| Top-k采样 | 夏夜的星空, | 仿佛在低声诉说。 | 质量有保障,多样性好 |
| Top-p采样 | 夏夜的星空, | 特别让人心旷神怡。 | 智能、灵活、首选 |
4. 方法总结
| 方法 | 核心思想 | 优点 | 缺点 | 适用场景 |
| 贪心搜索 | 每一步选最概率最高的 | 速度快 | 容易重复,缺乏多样性 | 简单任务,已少用 |
| 束搜索 | 每一步保留Top-k候选 | 生成更流畅准确 | 缺乏多样性,计算量大 | 翻译、摘要、代码生成 |
| 温度采样 | 用温度参数调整分布形状 | 有效控制随机性 | 需手动调参 | 几乎所有场景的微调 |
| Top-k采样 | 从Top-k词中随机选 | 避免奇怪词 | k值不灵活 | 创造性生成(较旧) |
| Top-p采样 | 从累积概率超p的词中选 | 动态灵活,智能 | 需手动调参 | 创造性生成(首选) |
场景对应的组合选择:
- 任务目标明确,有标准答案:束搜索 或 极低温度+Top-p。
- 开放式聊天、创意写作:中等温度(0.7~1.0) + Top-p(0.9~0.95),这是当前最主流的组合。
- 需要高度随机性和惊喜:高温度(>1.0) + Top-p。
四、方法示例
不同采样方法在 RAG 系统中的代码示例, 下面将为每种采样方法提供结合 Faiss 检索和 Qwen API 调用的具体代码示例:
1. 公共部分的代码
import dashscope
from dashscope import Generation
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
import os
# 设置API密钥 - 请替换为您的实际API信息
dashscope.api_key = os.environ.get("DASHSCOPE_API_KEY")
# 1. 准备知识库 - 中国古典诗词知识
knowledge_base = [
"《静夜思》是唐代诗人李白的诗作,表达了对故乡的思念之情。床前明月光,疑是地上霜。举头望明月,低头思故乡。",
"《水调歌头·明月几时有》是宋代苏轼的代表作,是一首咏月怀人的词。明月几时有?把酒问青天。",
"《春晓》是唐代诗人孟浩然的诗作,描绘了春天早晨的景色。春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。",
"杜甫是唐代伟大的现实主义诗人,被尊为诗圣,与李白合称李杜。他的诗反映了唐代由盛转衰的历史过程。",
"《将进酒》是李白的一首豪放诗篇,表达了人生得意须尽欢的豪情。君不见黄河之水天上来,奔流到海不复回。",
"王维是唐代著名诗人、画家,被誉为诗佛,他的诗多以山水田园为题材,充满禅意。",
"《相思》是王维的诗作,借红豆表达相思之情。红豆生南国,春来发几枝。愿君多采撷,此物最相思。",
]
# 2. 将知识库转换成向量并构建Faiss索引
encoder = SentenceTransformer('D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2')
kb_embeddings = encoder.encode(knowledge_base)
dimension = kb_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(kb_embeddings)
# 3. 用户查询和检索
user_query = "请介绍李白的《静夜思》这首诗"
query_embedding = encoder.encode([user_query])
k = 3 # 从知识库中检索最相关的3条信息
distances, indices = index.search(query_embedding, k)
# 构建检索到的上下文
retrieved_context = ""
for i, idx in enumerate(indices[0]):
retrieved_context += knowledge_base[idx] + "\n"
print(f"用户问: {user_query}")
print("---Faiss检索到的最相关知识---")
print(retrieved_context)
# 4. 构建通用Prompt模板
def build_prompt(context, query):
return f"""
你是一个博学的中国古典文学专家。请根据以下【相关知识】,准确并专业地回答用户的问题。
如果相关知识中没有答案,请如实告知你不知道。
【相关知识】
{context}
【用户问题】
{query}
【专家回答】
"""
# 5. Qwen API调用函数
def call_qwen_api(prompt, **kwargs):
"""
调用Qwen API生成文本
:param prompt: 输入的提示文本
:param kwargs: 生成参数
:return: 生成的文本
"""
try:
response = Generation.call(
model="qwen-max", # 可根据需要选择不同模型,如qwen-plus、qwen-max等
prompt=prompt,
**kwargs
)
return response.output.text
except Exception as e:
print(f"API调用出错: {e}")
return None输出结果:
用户问: 请介绍李白的《静夜思》这首诗
---Faiss检索到的最相关知识---
《静夜思》是唐代诗人李白的诗作,表达了对故乡的思念之情。床前明月光,疑是地上霜。举头望明月,低头思故乡。
《将进酒》是李白的一首豪放诗篇,表达了人生得意须尽欢的豪情。君不见黄河之水天上来,奔流到海不复回。
杜甫是唐代伟大的现实主义诗人,被尊为诗圣,与李白合称李杜。他的诗反映了唐代由盛转衰的历史过程。2. 贪心搜索示例
# 贪心搜索示例 - 通过设置temperature=0实现
print("\n=== 贪心搜索 ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用贪心搜索 - 设置temperature=0
response = call_qwen_api(
prompt,
temperature=0, # 温度为0相当于贪心搜索
max_tokens=200,
)
if response:
print(response)
else:
print("API调用失败")
print("\n" + "="*50 + "\n")输出结果:
=== 贪心搜索 ===
《静夜思》是唐代著名诗人李白创作的一首五言绝句,这首诗以其简洁明快的语言和深刻的情感表达而广为人知。全诗如下:
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
在这首诗中,李白通过描绘夜晚明亮的月光照进房间的情景,营造出一种宁静而又略带孤寂的氛围。“疑是地上霜”一句巧妙地将月光
比作地上的白霜,既形象又富有诗意。接着,“举头望明月”表达了诗人抬头仰望天空中的月亮的动作;最后一句“低头思故乡”,则直
接点出了整首诗的主题——对远方家乡的深深思念之情。这种由外在景象引发内心情感变化的手法,在李白的作品中十分常见,也使得
《静夜思》成为了流传千古、触动无数游子心弦的经典之作。
==================================================3. 束搜索示例
# 束搜索示例 - 注意:Qwen API通常不支持束搜索参数
print("=== 束搜索 ===")
print("注意: Qwen API通常不支持束搜索参数,使用低温度替代")
prompt = build_prompt(retrieved_context, user_query)
# 使用低温度模拟束搜索的效果
response = call_qwen_api(
prompt,
temperature=0.1, # 低温度模拟束搜索的确定性
max_tokens=200,
)
if response:
print(response)
else:
print("API调用失败")
print("\n" + "="*50 + "\n")输出结果:
=== 束搜索 ===
注意: Qwen API通常不支持束搜索参数,使用低温度替代
《静夜思》是唐代著名诗人李白创作的一首五言绝句,这首诗以其简洁明快的语言和深刻的情感表达而广为人知。全诗如下:
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
在这首诗中,李白通过描绘夜晚独自一人时所见的明亮月光,巧妙地将自然景象与个人情感相结合。首句“床前明月光”直接点出了诗
人所在环境以及引起他注意的事物——那洒落在床前如同白霜般的皎洁月光。“疑是地上霜”进一步强化了这种视觉上的错觉,同时也暗
示着一种清冷孤寂之感。接下来,“举头望明月”,诗人抬头仰望着天空中的满月,这一动作不仅表达了他对美好事物的向往,也隐含
着对远方亲人或家乡的思念之情。“低头思故乡”则是整首诗情感的核心所在
==================================================4. 温度采样示例
# 温度采样示例 - 低温度
print("=== 温度采样 - 低温度 (T=0.3) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用温度采样 - 低温度
response = call_qwen_api(
prompt,
temperature=0.3, # 低温度,输出更确定
max_tokens=200,
)
if response:
print(response)
else:
print("API调用失败")
print("\n" + "="*50 + "\n")
# 温度采样示例 - 高温度
print("=== 温度采样 - 高温度 (T=1.5) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用温度采样 - 高温度
response = call_qwen_api(
prompt,
temperature=1.5, # 高温度,输出更随机
max_tokens=200,
)
if response:
print(response)
else:
print("API调用失败")
print("\n" + "="*50 + "\n")输出结果:
=== 温度采样 - 低温度 (T=0.3) ===
《静夜思》是唐代著名诗人李白创作的一首五言绝句,这首诗以其简洁而深刻的语言表达了作者在寂静夜晚对远方家乡的深切思念之
情。全诗如下:
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
在这首诗中,“床前明月光”描绘了一个宁静夜晚里明亮皎洁的月光照进了屋内;“疑是地上霜”则通过将月光比作地上的白霜来进一步
强调了月色之明亮以及环境之清冷。“举头望明月”,当诗人抬头仰望着那轮高挂天空中的圆月时,不禁勾起了他对远方家人的无限怀
念与向往;最后一句“低头思故乡”,则是直接点出了整首诗的主题——对故乡深深的思念之情。整首作品语言朴素自然,情感真挚动人
,充分展现了李白诗歌中既有豪放不羁也有细腻柔
==================================================
=== 温度采样 - 高温度 (T=1.5) ===
《静夜思》是唐代诗人李白所作的一首短诗,全诗只有四句二十字,但意境深邃、感人至深。它以简洁明快的语言描绘了作者在寂静
夜晚的深切思绪。“床前明月光”,开篇就设置了一个宁静而美丽的场景:明亮的月光照进屋内,“疑是地上霜”则是将月色比作寒冷季
节地面覆盖的白霜,营造出一种清冷孤寂的氛围。接着,“举头望明月”,诗人抬头仰望天空中悬挂着的月亮,这里的“望”字不仅描述
了动作,也表达了内心对远方(可能是故乡或亲人)深切的挂念。“低头思故乡”最后一句,则直接点出了诗人此时此刻最真实的感情
状态——思念家乡。整首诗歌通过对月光景色细腻入微地描写,巧妙地寓情于景,表达了远离故土之人对家乡的深深怀念之情。
==================================================5. Top-k 采样示例
# Top-k 采样示例
print("=== Top-k 采样 (k=30) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用Top-k采样
response = call_qwen_api(
prompt,
temperature=0.7, # 配合适中的温度
top_k=30, # 只从概率最高的30个词中采样
max_tokens=200,
)
if response:
print(response)
else:
print("API调用失败")
print("\n" + "="*50 + "\n")输出结果:
=== Top-k 采样 (k=30) ===
《静夜思》是唐代著名诗人李白创作的一首脍炙人口的五言绝句,通过简洁而富有画面感的语言,表达了诗人在寂静夜晚对远方家乡
深切的怀念之情。全诗如下:
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
这首诗以“床前”的视角展开,首先映入眼帘的是明亮皎洁的月光,诗人初时误以为是地上的白霜(这反映了夜间月色之明亮)。随后
,他抬头仰望着那轮高悬于空中的明月,在这样的美景面前不禁想起了遥远的家乡。最后,“低头思故乡”一句,则直接点出了整首诗
歌的主题——即在外漂泊者对于故土难以割舍的情感寄托。整首诗语言朴素自然、情感真挚动人,成为中国古典文学中表达乡愁的经典
之作之一。
==================================================6. Top-p 采样 (核采样) 示例
# Top-p 采样示例
print("=== Top-p 采样 (p=0.9) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用Top-p采样(核采样)
response = call_qwen_api(
prompt,
temperature=0.7, # 配合适中的温度
top_p=0.9, # 从累积概率达到0.9的词中采样
max_tokens=200,
)
if response:
print(response)
else:
print("API调用失败")
print("\n" + "="*50 + "\n")输出结果:
=== Top-p 采样 (p=0.9) ===
《静夜思》是唐代著名诗人李白创作的一首脍炙人口的五言绝句,这首诗以其简洁明快的语言风格和深刻的情感表达深受后世读者的
喜爱。全诗如下:
```
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
```
在这首诗中,李白通过对夜晚月色下景象的独特描绘,表达了他对远方家乡深深的思念之情。“床前明月光”,描述了作者夜晚醒来时
看到明亮皎洁的月光照进房间;“疑是地上霜”则通过将月光比喻成地面上覆盖着一层薄霜来形象化这份清冷之美感,同时也暗示了季
节可能是在秋季或者是冬季初期。“举头望明月”表明诗人被这美丽的景色所吸引而抬头凝视天空中的月亮;最后,“低头思故乡”直接
点出了整首诗的主题——无论身处何方,在这样宁静美好的夜晚里
==================================================7. 组合使用示例 (Temperature + Top-p)
# 组合使用示例 - 创造性回答
print("=== 组合采样 (Temperature=0.8 + Top-p=0.9) ===")
creative_query = "请用富有诗意的语言介绍《静夜思》"
prompt = build_prompt(retrieved_context, creative_query)
# 使用组合采样 - 适合创造性任务
response = call_qwen_api(
prompt,
temperature=0.8, # 中等温度
top_p=0.9, # Top-p采样
max_tokens=250,
)
if response:
print(response)
else:
print("API调用失败")
print("\n" + "="*50 + "\n")输出结果:
=== 组合采样 (Temperature=0.8 + Top-p=0.9) ===
在那宁静而又深邃的夜晚,一轮明月悄悄地爬上了天际,将它那温柔而明亮的光芒洒向了大地。唐代诗人李白,在这样一个万籁俱寂
、唯有月色相伴的时刻,心中涌动着对远方家乡无尽的思念。他静静地坐在床边,眼前仿佛覆盖了一层薄霜般的月光让这位才华横溢
的诗人不禁生出错觉,以为是秋天的寒霜降临。然而抬头望向天空中那轮皎洁圆满的月亮时,所有关于时间与空间的距离都瞬间被拉
近了——那不仅是天上的明珠,更是连接着游子与故乡之间最柔软也最坚强的情感纽带。
通过这首《静夜思》,李白用极其简练却又充满画面感的语言,描绘了一个远离家乡的人在寂静之夜对亲人和故土深深眷恋之情。短
短四句诗,却蕴含着跨越千年仍旧能够触动人心弦的力量。每当有人身处异乡仰望星空之时,《静夜思》便如同一缕清风,穿越时空
界限,轻轻拂过每个漂泊者的心田,唤起那份埋藏心底对于“家”的永恒向往。
==================================================8. 示例总结
通过上述示例,可以清楚地看到不同采样方法的特点:
- 贪心搜索:输出稳定、准确,但可能缺乏变化和创造性。
- 束搜索:比贪心搜索找到的句子通常更通顺、完整,但依然较为保守。
- 基础随机:极度不可控,可能产生有趣的结果,但更可能生成无意义的内容。
- 温度采样(低温度):输出更加确定和可靠,适合事实性问答。
- 温度采样(高温度):输出更加随机和富有创造性,适合文学性任务。
- Top-k 采样:在保证质量的前提下引入多样性,避免低概率奇怪词。
- Top-p 采样:智能动态地选择候选词,是目前创造性任务的首选方法。
- 组合采样:通过调整温度和Top-p参数,可以精细控制生成文本的风格。
在实际应用中,你可以根据任务需求选择合适的采样方法:
- 事实性问答:低温度 + Top-p
- 创意写作:中高温度 + Top-p
- 翻译/摘要:束搜索 或 低温度采样
- 开放式对话:中温度 + Top-p + 重复惩罚
这些示例展示了如何将Faiss检索与Qwen大模型的不同采样策略结合使用,构建一个灵活且强大的RAG系统。
五、组合示例
我们建一个“美食推荐机器人”。用户问:“天气好热,推荐点吃的吧?”。
- 用Faiss检索:从美食知识库中快速找到“清热”、“解暑”、“夏季”相关的菜品描述。
- 用Qwen-max生成:把检索到的信息喂给Qwen-max,让它生成友好推荐。
代码示例
import dashscope
from dashscope import Generation
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
import os
# 设置API密钥 - 请替换为您的实际API密钥
dashscope.api_key = os.environ.get("DASHSCOPE_API_KEY")
# 1. 准备一个模拟的"美食知识库"
knowledge_base = [
"冰糖葫芦是一种传统的北方小吃,由山楂和糖制成,酸甜开胃,但适合冬天吃。",
"火锅是四川特色,以麻辣鲜香著称,但吃多了容易上火。",
"绿豆汤是由绿豆熬制而成的甜品,清热解毒,是夏季消暑的佳品。",
"冰淇淋是一种冷冻奶制品,口感冰凉香甜,夏天食用能有效降温。",
"红烧肉是一道著名的大众菜肴,使用肥瘦相间的五花肉做成,油腻温热,不适合夏天。",
"凉皮是陕西的特色小吃,口感滑嫩,凉爽可口,非常适合在炎热的夏季食用。",
"姜撞奶是一种广东甜品,由姜汁和牛奶制成,口感滑嫩,但姜性温热。",
]
# 将知识库转换成向量并构建Faiss索引
encoder = SentenceTransformer('D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2')
kb_embeddings = encoder.encode(knowledge_base)
dimension = kb_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(kb_embeddings)
# 2. 用户查询和检索
user_query = "天气好热,推荐点吃的吧?"
query_embedding = encoder.encode([user_query])
k = 3 # 从知识库中检索最相关的3条信息
distances, indices = index.search(query_embedding, k)
# 打印检索到的内容
print(f"\n用户问: {user_query}")
print("---Faiss检索到的最相关知识---")
retrieved_context = ""
for i, idx in enumerate(indices[0]):
print(f"{i+1}. {knowledge_base[idx]}")
retrieved_context += knowledge_base[idx] + "\n"
# 3. 构建Prompt,将检索到的知识作为上下文
prompt = f"""
你是一个友好的美食推荐助手。请根据以下【相关知识】,回答用户的问题。
回答要简短、亲切、有吸引力。
【相关知识】
{retrieved_context}
【用户问题】
{user_query}
【助手推荐】
"""
print("\n---生成的Prompt---")
print(prompt)
# 4. 定义Qwen API调用函数
def call_qwen_api(prompt, **kwargs):
"""
调用Qwen API生成文本
:param prompt: 输入的提示文本
:param kwargs: 生成参数
:return: 生成的文本
"""
try:
response = Generation.call(
model="qwen-max", # 可根据需要选择不同模型,如qwen-plus、qwen-max等
prompt=prompt,
**kwargs
)
return response.output.text
except Exception as e:
print(f"API调用出错: {e}")
return None
# 5. 关键步骤:选择不同的采样方法生成回复
# 场景一:追求准确可靠(基于事实推荐)
print("\n---生成模式一: 准确模式(低温度+Top-p)---")
response = call_qwen_api(
prompt,
temperature=0.3, # 低温度,创造性低
top_p=0.9, # Top-p采样
max_tokens=150, # 最多生成150个token
)
if response:
print(response)
else:
print("API调用失败")
# 场景二:追求创意有趣(写美食文案)
print("\n---生成模式二: 创意模式(中温度+Top-p)---")
response = call_qwen_api(
prompt,
temperature=0.8, # 中温度,创造性更高
top_p=0.92, # Top-p采样
max_tokens=150, # 最多生成150个token
)
if response:
print(response)
else:
print("API调用失败")输出结果
用户问: 天气好热,推荐点吃的吧?
---Faiss检索到的最相关知识---
1. 冰糖葫芦是一种传统的北方小吃,由山楂和糖制成,酸甜开胃,但适合冬天吃。
2. 绿豆汤是由绿豆熬制而成的甜品,清热解毒,是夏季消暑的佳品。
3. 红烧肉是一道著名的大众菜肴,使用肥瘦相间的五花肉做成,油腻温热,不适合夏天。
---生成的Prompt---
你是一个友好的美食推荐助手。请根据以下【相关知识】,回答用户的问题。
回答要简短、亲切、有吸引力。
【相关知识】
冰糖葫芦是一种传统的北方小吃,由山楂和糖制成,酸甜开胃,但适合冬天吃。
绿豆汤是由绿豆熬制而成的甜品,清热解毒,是夏季消暑的佳品。
红烧肉是一道著名的大众菜肴,使用肥瘦相间的五花肉做成,油腻温热,不适合夏天。
【用户问题】
天气好热,推荐点吃的吧?
【助手推荐】
---生成模式一: 准确模式(低温度+Top-p)---
这么热的天,来碗清凉解暑的绿豆汤最合适不过了,既能消暑又能清热解毒,给你带来一丝凉爽!
---生成模式二: 创意模式(中温度+Top-p)---
这么热的天,来一碗清凉的绿豆汤最合适不过啦!既能解暑又能清热解毒,让你从内到外都感到清爽。试试看吧!六、总结
综合示例,通过调整“方向盘”上的参数,我们可以让同一个AI模型表现出完全不同的性格:
- 做学问、搞翻译:用束搜索或低温度+Top-p,让它严谨可靠。
- 日常聊天、写文案:用中温度+Top-p(如T=0.8, top_p=0.9),让它既有创意又不失控。
- 写诗、搞艺术创作:用高温度+Top-p(如T=1.2, top_p=0.9),让它尽情发挥想象力。
通过这些实例,你可以直观地感受到,通过调整这些“旋钮”,我们能有效地控制AI模型的“性格”和输出风格。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)