Mysql索引
MySQL 的存储引擎选择对性能至关重要,而 InnoDB 是 MySQL 5.5 及之后版本的默认存储引擎(包括当前主流版本 MySQL 8.0)。– 假设存在idx_name。关键口诀:索引列不做计算,最左前缀要满足,覆盖索引是利器,EXPLAIN诊断不可少。1.主键索引(PRIMARY KEY)。1.B+树(Mysql默认结构)。四、索引工作流程(以B+树为例)。辅
Mysql索引
MySQL索引是提升数据库查询性能的核心机制,其本质是通过特定的数据结构(如B+树)存储表中特定列的值和对应记录位置(行指针),从而显著减少查询时全表扫描的数据量。
以下是关于MySQL索引的解析:
一、索引的本质与作用
1.快速定位: 类似书籍目录,避免逐行扫描。
2.优化排序与分组: 对ORDER BY、GROUP BY效率提升显著。
3.减少I/O: 直接读取索引数据,无需加载整行(尤其覆盖索引时)。
4.强制唯一性: 唯一索引保证列值不重复。
二、索引的数据结构
1.B+树(Mysql默认结构)
- 平衡多路搜索树: 所有叶子节点深度相同。
- 叶子节点存储数据:
- 主键索引(聚簇索引):叶子节点存储完整行数据。
- 二级索引(辅助索引):叶子节点存储主键值 + 索引列值。
- 范围查询高效: 叶子节点通过指针双向连接。
- 示例:
CREATE INDEX idx_name ON users(name); – 创建B+树索引
2.哈希索引 - 仅Memory引擎支持: InnoDB支持自适应哈希(后台自动生成)。
- 精确匹配极快: 时间复杂度≈O(1)。
- 局限: 不支持范围查询、排序,易哈希冲突。
3.全文索引(FULLTEXT) - 针对文本搜索: 适用于MATCH() AGAINST()操作。
- 倒排索引结构: 记录关键词与文档的映射。
4.空间索引(R-Tree) - 地理数据处理: 用于GIS数据类型(如POINT、GEOMETRY)。
三、索引类型详解
1.主键索引(PRIMARY KEY)
- 唯一标识每行,表只能有一个,叶子节点存储行数据。
- 创建:
CREATE TABLE users (id INT PRIMARY KEY, name VARCHAR(50));
2.普通索引(单列/组合索引) - 无唯一性限制,加速查询。
- 组合索引:
CREATE INDEX idx_name_age ON users(name, age); – 最左前缀生效
3.唯一索引(UNIQUE) - 列值必须唯一,允许NULL值(可重复)。
CREATE UNIQUE INDEX uq_email ON users(email);
4.前缀索引 - 对文本前N个字符索引,节省空间。
CREATE INDEX idx_city_prefix ON users(city(10)); – 仅索引前10字符
5.覆盖索引 - 高效场景: 查询列均在索引中,无需回表。
- 示例:
– idx_name_age索引包含name和age
SELECT name, age FROM users WHERE name = ‘Alice’; – 覆盖索引生效
四、索引工作流程(以B+树为例)
1.二级索引查询:
SELECT * FROM users WHERE name = ‘Bob’; – 假设存在idx_name
- 步骤:
i.在idx_name中快速定位Bob的叶子节点。
ii.获取对应主键值(如id=5)。
iii.回表查询: 用主键值到聚簇索引中查找完整行数据。
2.覆盖索引优化:
SELECT id, name FROM users WHERE name = ‘Bob’; – 若id是主键 - 仅访问idx_name即可返回结果(id已在索引中),避免回表。
五、索引失效的常见陷阱
1.对索引列计算或函数操作:
SELECT * FROM users WHERE YEAR(create_time) = 2023; – 失效
– 改为:
SELECT * FROM users WHERE create_time BETWEEN ‘2023-01-01’ AND ‘2023-12-31’;
2.隐式类型转换:
SELECT * FROM users WHERE phone = 13800138000; – phone是varchar
– 改为字符串查询:
SELECT * FROM users WHERE phone = ‘13800138000’;
3.OR连接非索引列:
SELECT * FROM users WHERE name = ‘Alice’ OR age = 30; – age无索引则全表扫描
4.违反最左前缀原则(组合索引):
CREATE INDEX idx_scores ON users(math, english, history);
– 有效查询:
SELECT * FROM users WHERE math > 90;
SELECT * FROM users WHERE math = 85 AND english > 80;
– 失效查询:
SELECT * FROM users WHERE english = 90; – 缺失math条件
5.使用!=、NOT IN、NOT LIKE:
SELECT * FROM users WHERE status != 1; – 可能全表扫描
六、最佳实践与优化建议
1.选择高区分度列: 如用户ID而非性别(低区分度)。
2.控制索引数量: 每增删改一行需更新所有相关索引,影响写入性能。
3.优先组合索引: 替代多个单列索引,注意字段顺序(高频查询条件放左侧)。
4.使用EXPLAIN分析: 查看执行计划中的索引使用情况。
EXPLAIN SELECT * FROM users WHERE name = ‘Charlie’;
5.定期维护:
ANALYZE TABLE users; – 更新索引统计信息
OPTIMIZE TABLE users; – 重建表,整理索引碎片(谨慎使用)
七、索引的代价
- 空间占用: 索引需额外存储空间(尤其组合索引)。
- 维护成本: 增删改操作需同步更新索引,降低写入速度。
- 优化器选择: 错误选择索引可能导致性能下降(可用FORCE INDEX强制指定)。
总结
MySQL索引是高性能查询的基石,但也需要权衡读写性能。深入理解B+树结构、最左前缀原则、覆盖索引机制及失效场景,结合EXPLAIN工具分析,才能精准设计有效索引。避免过度索引,重点关注慢查询的优化,才能真正发挥索引的威力。
关键口诀:索引列不做计算,最左前缀要满足,覆盖索引是利器,EXPLAIN诊断不可少。
EXPLAIN
使用EXPLAIN分析SQL执行计划时,以下字段是诊断性能问题的关键。重点关注前6个核心字段,其余辅助分析:
核心字段(必看)
1.type(访问类型)性能从优到差排序:
system > const > eq_ref > ref > range > index > ALL
- 目标:至少达到 range(范围扫描),避免 ALL(全表扫描)。
- 常见值说明:
- const:通过主键或唯一索引直接定位单行(SELECT * FROM users WHERE id = 1)。
- eq_ref:多表JOIN时,主键或唯一索引匹配(… ON users.id = orders.user_id)。
- ref:非唯一索引的等值查询(WHERE name = ‘Alice’)。
- range:索引范围扫描(WHERE age > 20)。
2.key(实际使用的索引) - 是否命中预期索引,若为NULL表示全表扫描。
- 对比possible_keys(可能可用的索引),检查优化器是否选错索引。
3.rows(扫描行数) - 关键指标:估算扫描的行数,值越大性能越差。
- 结合WHERE条件判断是否可减少扫描量(如增加索引或调整条件)。
4.Extra(附加信息)高频重要值: - Using where:需在存储引擎层后过滤数据(索引未完全覆盖条件)。
- Using index:覆盖索引,无需回表(最优情况之一)。
- Using filesort:文件排序(需优化ORDER BY,尝试用索引排序)。
- Using temporary:创建临时表(常见于GROUP BY未用索引)。
5.possible_keys(可能用到的索引) - 优化器可选择的索引列表,若为空则无合适索引。
6.key_len(索引使用字节数) - 计算实际使用的索引长度,判断是否充分利用组合索引。
- 示例:
EXPLAIN SELECT * FROM users WHERE name = ‘Alice’ AND age = 30;
– key_len = 4 (age INT) + 3 * 10 (name VARCHAR(10) UTF8) + 1(变长字段标识)= 35
– 若未使用完整索引,key_len会小于此值
辅助字段(按需关注)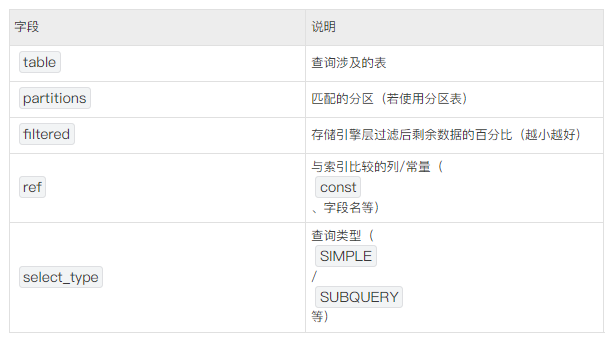
诊断案例
EXPLAIN SELECT * FROM orders
WHERE user_id = 100 AND status = ‘paid’
ORDER BY create_time DESC;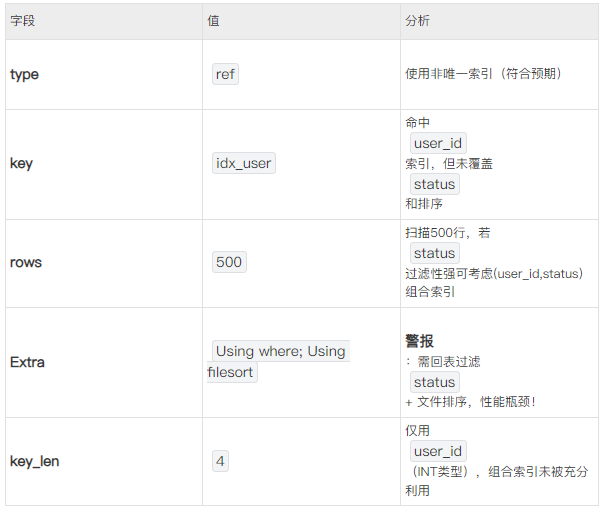
优化方向
1.增加覆盖索引:
CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time);
- 使WHERE和ORDER BY均被索引覆盖,消除Using filesort和回表。
2.检查rows与filtered: - 若filtered值高(如>30%),考虑优化查询条件或索引。
口诀:
type看扫描方式,key查索引命中,rows评数据量,Extra挖潜在问题,key_len验索引利用。结合业务场景反复调优,最终目标:type ≥ range, key不为空, rows趋近1, Extra出现Using index。
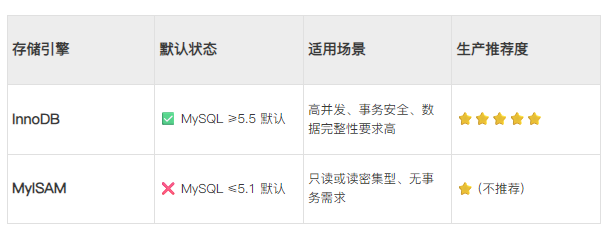
MySQL 的存储引擎
MySQL 的存储引擎选择对性能至关重要,而 InnoDB 是 MySQL 5.5 及之后版本的默认存储引擎(包括当前主流版本 MySQL 8.0)。以下是核心对比:
一、关键结论
二、InnoDB vs MyISAM 核心机制对比
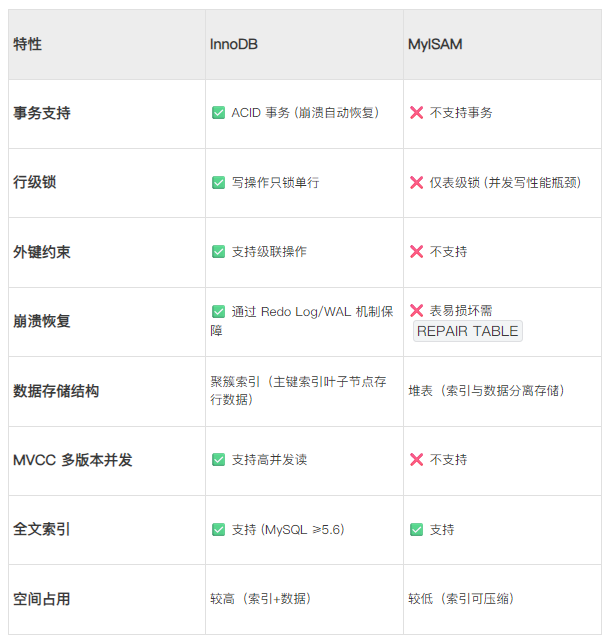
💡 关键区别解释:
- 行锁 vs 表锁:InnoDB 的并发写入能力远超 MyISAM(100个写并发时,InnoDB 吞吐量可达 MyISAM 的10倍以上)。
- 数据安全:MyISAM 在崩溃或断电时可能永久丢失数据,而 InnoDB 通过日志保证数据可恢复。
三、如何确认表使用的引擎?
SHOW TABLE STATUS LIKE ‘表名’;
– 查看 Engine 字段
输出示例:
NameEngineVersionRow_formatRows…usersInnoDB10Dynamic1000…
四、生产环境强烈推荐 InnoDB 的原因
1.事务保障:银行转账、订单支付等场景必须使用事务(BEGIN; COMMIT; ROLLBACK;)。
2.高并发优化:行级锁 + MVCC 避免读写阻塞。
3.数据安全:崩溃后自动恢复至最近一致性状态(依赖 Redo Log 和 Undo Log)。
4.热备份:支持在线备份工具(如 mysqldump --single-transaction)。
5.外键约束:维护关联表数据完整性(需注意性能影响)。
五、MyISAM 的残留使用场景(谨慎选择)
1.只读数据仓库:批量导入历史数据后仅查询(如日志分析表)。
2.空间占用敏感:MyISAM 支持 COMPRESSED 压缩表。
3.全文索引旧版:MySQL 5.5 前使用 MyISAM 实现(现已不推荐)。
⚠️ 严重缺陷警告:
MyISAM 在写操作时锁定整个表,执行 UPDATE large_table SET … 时全表阻塞,导致业务瘫痪!
六、迁移 MyISAM 表到 InnoDB
ALTER TABLE my_table ENGINE = InnoDB;
注意事项:
- 检查外键和索引兼容性
- 预留足够磁盘空间(InnoDB 空间放大系数约1.5倍)
- 业务低峰期执行(大表锁表时间长)
总结
- 现代 MySQL 默认且唯一推荐的生产引擎是 InnoDB,MyISAM 仅用于特定遗留场景。
- 选择 InnoDB = 事务安全 + 高并发 + 数据可靠,是任何严肃业务的必备基础。
- 使用 MyISAM 等同于主动放弃数据库的核心可靠性功能(除非明确知道风险且无替代方案)。
📌 建议:对所有新表强制使用 InnoDB,并迁移现存 MyISAM 表(监控锁表现象)。
事务的本质与 ACID
事务(Transaction)是一组原子性的数据库操作集合,满足四大特性:
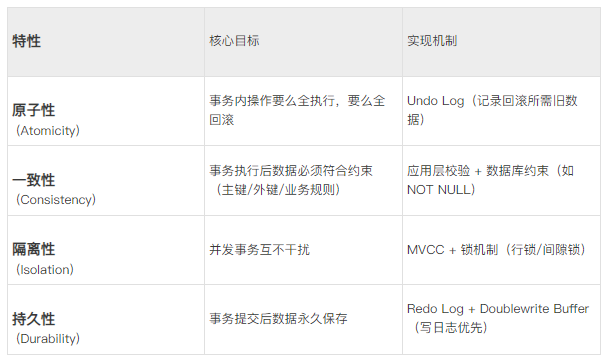
并发事务的隔离问题与解决方案
事务隔离级别详解:并发控制的四种策略
事务隔离级别是数据库控制并发访问的核心机制,决定了多个事务之间的可见性与相互影响程度:
- •读未提交:最低隔离等级,允许读取未提交数据
- •读已提交:仅允许读取已提交数据(多数数据库默认级别)
- •可重复读:确保同事务内多次查询结果一致(MySQL默认级别)
- •可串行化:最高隔离等级,强制事务顺序执行
典型并发问题在不同级别的表现:
复制┌──────────────┬─────────────┬───────────────┬───────────┐
│ 隔离级别 │ 脏读可能性 │ 不可重复读可能性 │ 幻读可能性 │
├──────────────┼─────────────┼───────────────┼───────────┤
│ 读未提交 │ ✓ │ ✓ │ ✓ │
│ 读已提交 │ ✗ │ ✓ │ ✓ │
│ 可重复读 │ ✗ │ ✗ │ ✓* │
│ 可串行化 │ ✗ │ ✗ │ ✗ │
└──────────────┴─────────────┴───────────────┴───────────┘
(*注:MySQL通过MVCC机制在可重复读级别实际规避了幻读)
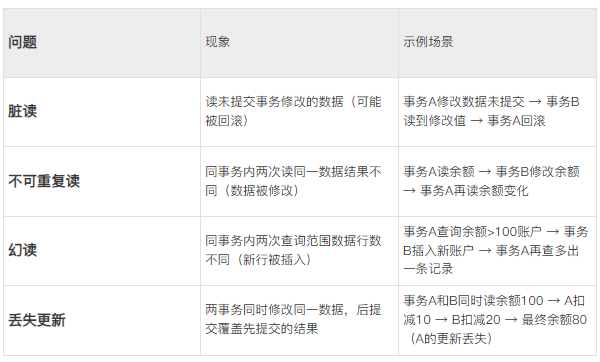
四大并发问题
分布式事务拓展
CAP 权衡
- 一致性 (Consistency):所有节点数据实时相同
- 可用性 (Availability):每次请求都有响应
- 分区容忍 (Partition Tolerance):容忍网络分区故障
📌 现实选择:放弃强一致性(CP或AP模型),如: - 金融系统:CP(如 ZooKeeper)
- 互联网应用:AP(如 Cassandra)
总结 - 事务是数据库的防火墙:ACID 特性为数据操作提供原子弹级别的安全保障。
- 隔离级别是性能与一致性的调节阀:默认 REPEATABLE READ 适合多数场景,金融系统可升级 SERIALIZABLE。
- MVCC + 锁 = InnoDB 高并发灵魂:理解快照读与当前读的区别是避免幻读的关键。
- 死锁如交通拥堵:预防胜于治疗(统一资源顺序 + 短事务)。
MVCC 解决的问题
核心痛点:传统锁机制在读写并发场景下的性能瓶颈
- 读写冲突:读操作被写操作阻塞(如 SELECT 等待 UPDATE 完成)
- 写写冲突:必须通过行锁/间隙锁处理(MVCC 不解决写写冲突)
MVCC 的精髓:
读操作访问历史快照数据,写操作创建新数据版本,读写互不阻塞!
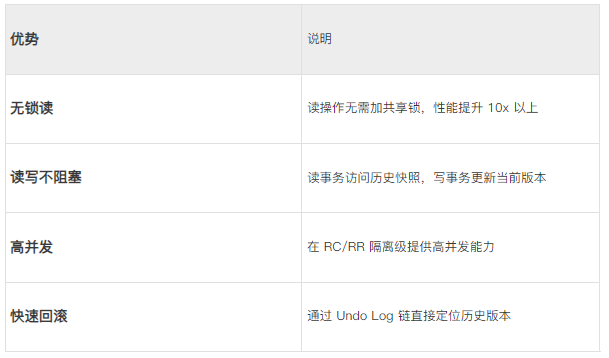
MVCC 的四大核心优势
总结与思考
- MVCC 是 InnoDB 的灵魂:通过(DB_TRX_ID + DB_ROLL_PTR + Undo Log + ReadView)实现多版本控制。
- 隔离级别选择:
- 需要绝对一致性 → RR + 显式加锁
- 追求高并发 → RC(每次读最新提交)
- 长事务是头号敌人:innodb_undo_log_truncate 需依赖无长事务运行。
⚠️ 终极警告:切勿在事务内执行远程 HTTP 调用或人为等待操作!这会导致 ReadView 长期不释放,引发数据库雪崩。
MVCC 解决的是读写并发问题,但写写冲突仍需锁控制。真正的数据库高手,既能享受 MVCC 的并发红利,又懂得何时用锁约束写操作。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)