Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
1.发明了“翻译官”(TEKGEN): 能把整个庞大的 Wikidata 知识图谱(像结构化表格)精准地“翻译”成自然语言句子(人话)。2.建了个“人话”知识库(KELM): 用上面方法生成了 1800 万句包含丰富、准确知识的句子。3.证明“人话”知识好用: 把这些句子喂给语言模型(如 REALM),能让模型变得更“博学”、更“靠谱”,在回答问题和掌握常识上表现更好。
核心目标: 让电脑更懂“事实”!怎么做到呢?把庞大的知识图谱(KG)像“翻译”一样变成人话(自然语言文本),然后用这些“人话”去训练更聪明的语言模型。
如何将大规模知识图谱(KG)转换为自然语言文本,以生成合成语料库(KELM Corpus),用于增强语言模型的预训练。论文的核心是解决知识图谱与自然语言文本的集成问题,通过结构化知识图谱的“verbalization”(文本化),无缝融入现有语言模型。
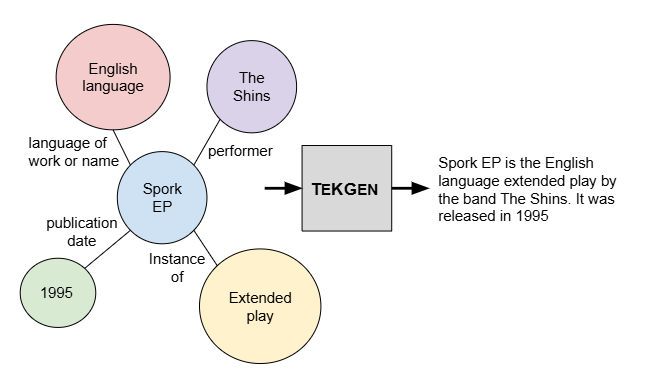
论文里的第一张图,左边是知识图谱,右边是转换为句子。
目标: 从 Neff Maiava 的维基百科页面中,自动找出匹配 Wikidata 三元组的句子。
1. Wikidata 中的三元组(结构化事实)
Wikidata 中存储了关于 Neff Maiava 的三个核心事实:1.(Neff Maiava, date of birth, 01 May 1924)
2.(Neff Maiava, date of death, 21 April 2018)
3.(Neff Maiava, occupation, professional wrestler)
2. 维基百科原文(自然语言文本)
在 Neff Maiava 的维基百科页面根章节(通常是简介段落)中找到以下句子:"Maiava (May 1, 1924 – April 21, 2018) was an American Samoan professional wrestler."
“根部分”指 Wikipedia页面的首段摘要(通常是第一段或导言部分)。
原因与特点:
- 信息集中性:根部分通常包含实体核心属性的总结(如出生/死亡日期、职业、国籍等),与KG的三元组高度对应。
- 结构稳定性:该部分为百科标准格式,避免正文中复杂的细节描述或分散的关系。
3. 远监督对齐匹配过程
论文的算法会这样匹配:1.锁定实体主语: 确定当前页面主体是 Neff Maiava(维基百科标题)。
2.扫描根章节句子: 只分析简介段落中的句子(减少噪音)。
3.匹配对象实体:日期匹配:
句子中的 May 1, 1924 和 April 21, 2018 通过正则表达式被识别为日期格式,与 Wikidata 中的 date of birth 和 date of death 的值(01 May 1924, 21 April 2018)完全一致。职业匹配:
句子中的关键词 professional wrestler 是 Wikidata 中 occupation 值(professional wrestler)的完整别名,直接匹配。4.生成对齐结果:
算法将上述句子与三个三元组关联起来,形成一条训练数据:
输入(三元组):
Neff Maiava date of birth 01 May 1924, date of death 21 April 2018, occupation professional wrestler
输出(自然语言):
"Maiava (May 1, 1924 – April 21, 2018) was an American Samoan professional wrestler."
为啥要把 KG 变“人话”?
语言模型的短板: 像 GPT 这类模型,主要吃“普通文章”长大。这些文章里的“事实”可能没说全、没说透,或者有偏见/错误。模型学到的知识就不完整、不精确。
如果把 KG 精准地“翻译”成人话,塞给语言模型“吃”,就能:
让模型更“懂行”: 掌握更多、更准确的世界知识。
让模型更“靠谱”: 减少胡说八道(幻觉)和偏见/有毒内容。
论文针对“数据到文本生成”(Data-to-Text Generation)任务,但不同于以往专注于特定领域(如WebNLG数据集),它首次尝试将整个英文Wikidata知识图谱(约600万个实体和1500种关系)转换为自然语言文本。
怎么“翻译”整个大 KG?(TEKGEN 模型)
这步最难!论文搞了个叫 TEKGEN 的“翻译官”。
挑战: Wikidata 太大(600万“东西”,1500种“关系”),不像小练习册(如 WebNLG)那么简单。最大的麻烦是:容易“瞎编”(比如输入“爱因斯坦 出生在 德国”,它可能瞎编出“爱因斯坦是德国科学家”,但没给“职业”信息它就乱猜)
TEKGEN(Text from KG Generator):一个序列到序列模型,用于生成自然语言文本。它基于T5-large模型,通过多步微调优化生成质量。
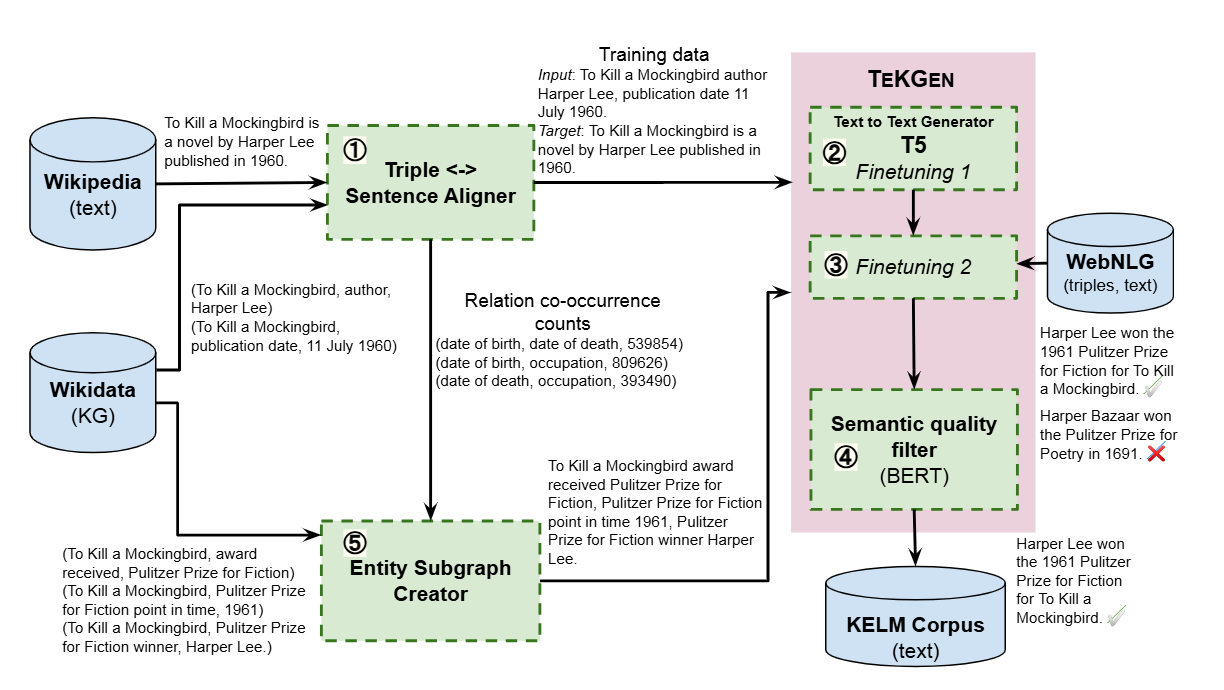
找“双语对照”材料: 从 Wikipedia 文章里,自动找出和 Wikidata 事实匹配的句子(比如文章里写了“爱因斯坦出生于德国”,就关联上 (爱因斯坦, 出生地, 德国) 这个事实)。这步叫“远监督对齐”,量大但有点“糙”。
分两阶段“教”:
第一阶段: 用上面那些“双语材料”训练,让“翻译官”学会覆盖各种“东西”和“关系”。
第二阶段: 再用一个干净但小的练习册(WebNLG)训练,专门治“瞎编”的毛病,让它学会“有啥说啥,别加戏”。
装个“质检员”: 训练另一个小模型(基于 BERT)给生成的句子打分,看它有没有准确表达 KG 的事实、有没有“加戏”。低分的淘汰掉!
生成“人话”知识库 (KELM Corpus)
用训练好的 TEKGEN “翻译官” 去处理整个 Wikidata:
打包“知识块”: 不能一个个“事实”单独翻(更容易“瞎编”)。论文发明了个办法:把围绕同一个“东西”的几条相关“事实”打包成一组(叫 Entity Subgraph),比如把关于“爱因斯坦”的出生地、职业、重要成就等几个事实放一起。
“翻译”并“质检”: 用 TEKGEN 把每组事实“翻译”成一句或几句话,再用“质检员”模型过滤掉质量差的句子。
成果: 生成了包含 1800 万句“人话” 的大知识库(KELM Corpus),覆盖了 Wikidata 的精华。
用“人话”知识库提升语言模型
论文做了个实验:把生成的 KELM “人话”知识库,喂给一个叫 REALM 的“爱查资料”的语言模型。
REALM 是啥? 这种模型在回答问题时,会先跑去一个庞大的“资料库”(通常是维基百科文本)里查相关资料,然后结合资料生成答案。
怎么用? 把 KELM 库也加进 REALM 的“资料库”里,让它查资料时既能查普通百科,也能查这些精准的“人话”知识。
效果如何?
知识掌握更牢: 在考模型“常识”的测试(LAMA)上,成绩显著提高(尤其是一些事实性问题)。加了 KELM 资料后,模型知道得更多、更准了。
问答更厉害: 在开放域问答(如回答“爱因斯坦什么时候出生的?”这种问题)任务上,答案的准确率也提升了。
关键发现: “翻译”成“人话”很重要! 实验对比发现,直接把原始 KG 三元组塞给模型效果不如“翻译”后的“人话”。说明自然语言才是模型最容易“消化”的形式。
总结一下这篇论文干了啥:
1.发明了“翻译官”(TEKGEN): 能把整个庞大的 Wikidata 知识图谱(像结构化表格)精准地“翻译”成自然语言句子(人话)。
2.建了个“人话”知识库(KELM): 用上面方法生成了 1800 万句包含丰富、准确知识的句子。
3.证明“人话”知识好用: 把这些句子喂给语言模型(如 REALM),能让模型变得更“博学”、更“靠谱”,在回答问题和掌握常识上表现更好。
把海量、精准的百科知识“说”成电脑能听懂、能学会的“人话”,让 AI 变得更聪明、更懂世界! 相当于给 AI 喂了一本用 Wikidata 精华写成的“事实宝典”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)