具身导航“所想即所见”!VISTA:基于生成式视觉想象的视觉语言导航
论文提出了VISTA框架,通过整合视觉想象、感知对齐和结构化推理,显著提升了视觉语言导航任务的性能,尤其在长时域和视觉模糊场景中表现出色,为智能体导航提供了更鲁棒、可解释的解决方案!
·
- 作者:Yanjia Huang, Mingyang Wu, Renjie Li, Zhengzhong Tu
- 单位:德克萨斯农工大学计算机科学与工程系
- 论文标题:VISTA: Generative Visual Imagination for Vision-and-Language Navigation
- 论文链接:https://arxiv.org/pdf/2505.07868
主要贡献
- 提出统一的闭环视觉语言导航框架VISTA,将主动想象、视觉-语义对齐和结构化思维链推理相结合,实现了鲁棒且可解释的导航行为。
- 引入自适应想象调度器和感知对齐滤波器两个关键模块,自适应想象调度器基于轨迹不确定性和视觉-语义对齐动态选择指令驱动和观察驱动的想象模式;感知对齐滤波器将视觉想象与实时观测明确对齐,增强可解释性和导航精度。
- 在Room-to-Room(R2R)和RoboTHOR基准测试中展示了显著的性能提升,特别是在成功率、导航效率等方面。
研究背景
- 视觉语言导航(VLN)任务:要求智能体在未见过的环境中,根据自然语言指令和视觉线索找到特定目标物体。现有方法多遵循“观察-推理”模式,即基于当前视觉观测决定下一步行动,但在长时域场景下,由于即时观测的局限性和视觉-语言模态之间的差距,这些方法面临挑战。
- 人类导航方式的启发:人类在导航时,会通过想象目标场景、预期布局并模拟可能路径来辅助决策。这种将想象、感知和推理相结合的认知循环,使人类能够有预见性地行动、适应模糊性并从不确定性中恢复。因此,论文认为在VLN中引入显式的目想象对于智能体的导航至关重要。
方法
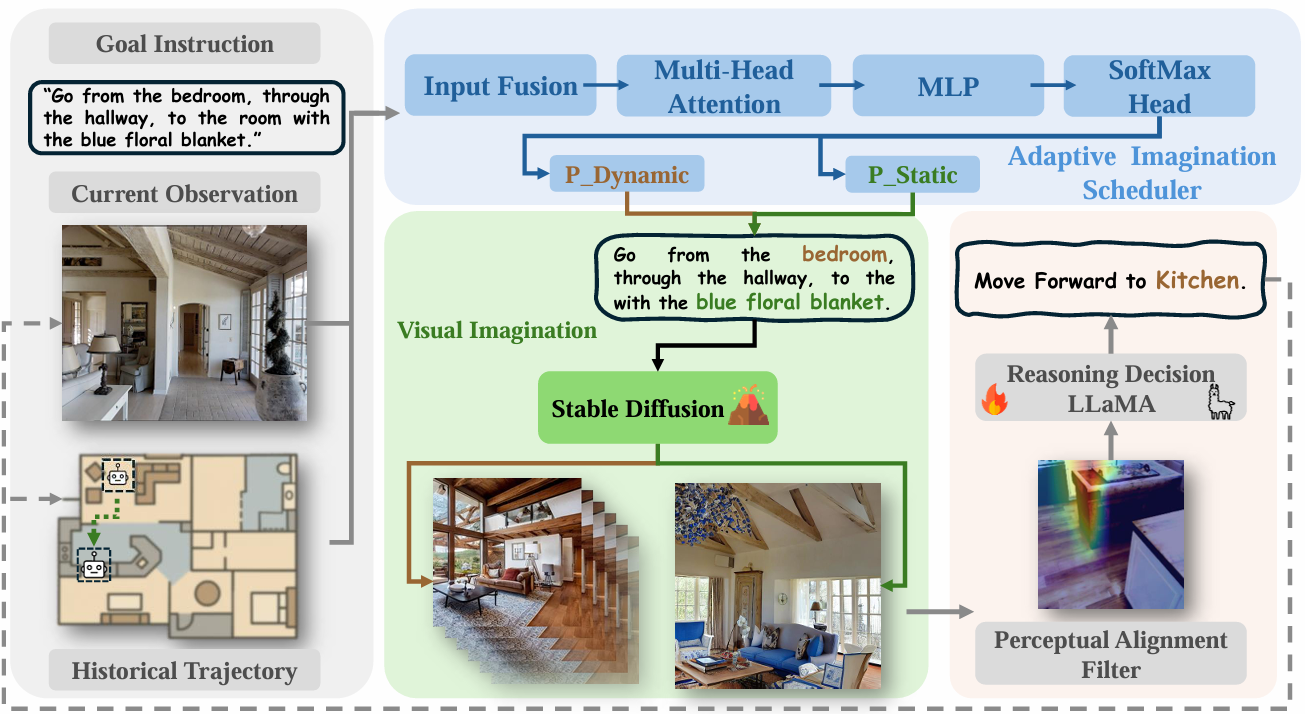
VISTA框架是一个受认知启发的导航框架,它在闭环推理循环中运行,智能体在每个导航步骤中主动想象未来目标,将这些预测与实时视觉输入对齐,并进行推理以决定下一步行动。
自适应想象调度器
解决智能体在导航过程中何时依赖高级指令、何时根据即时视觉观测进行适应的关键问题。它动态地在静态(指令驱动)和动态(观测驱动)目标预测模式之间切换。
- 静态模式:从指令中提取语义实体(如“厨房”、“楼梯”、“沙发”等)。
- 动态模式:利用最近的轨迹历史和当前视觉观测来提出即时目标。
- 模式选择依据:通过评估两个指标来决定模式。一是轨迹不确定性utu_tut,通过动作熵和路径偏差衡量;二是视觉语义相似性得分sts_tst,计算想象图像和观测图像嵌入之间的余弦相似度。如果ut<τuu_t < \tau_uut<τu且st>τss_t > \tau_sst>τs(τu\tau_uτu和τs\tau_sτs是预定义的阈值),则选择静态模式,否则选择动态模式。
视觉想象模块
帮助智能体在视觉上预测未来的导航目标。
- 两阶段视觉-语言流程:
- 首先,使用Qwen2-VL模型从候选场景(来自训练数据或之前想象的场景)生成描述性标题(如“A spacious living room with a blue sofa, wooden floors, and large windows.”)。
- 然后,将标题输入LoRA微调的Stable Diffusion模型,合成对应的视觉场景。
- 增强上下文相关性:通过在当前观测的掩蔽区域填充由相同标题引导的想象内容,创建一个修复版本的图像IinpainttI_{\text{inpaint}}^tIinpaintt,以增强上下文相关性。
感知对齐滤波器
将智能体想象的目标场景与当前自身中心观测进行比较,产生一个注意力图,突出显示可能的目标区域,使智能体能够验证其预测是否与现实相符,并确定目标位置。
- 输入:当前观测OtO_tOt、想象场景ISDtISD_tISDt和修复图像IinpainttI_{\text{inpaint}}^tIinpaintt。
- 处理过程:每个图像通过共享的ResNet-18主干网络进行编码,其特征通过多头注意力机制融合,解码成空间注意力图At∈[0,1]H×WA_t \in [0,1]^{H \times W}At∈[0,1]H×W,为OtO_tOt中的每个像素分配软相关性分数。
- 监督方法:使用从定位模型中派生的伪真值掩码AGTtA_{\text{GT}}^tAGTt来监督注意力图。通过从Qwen生成的标题中提取实体级关键词,并使用Grounded-SAM在OtO_tOt中定位它们,生成这些掩码。
- 训练:
- 构建了一个包含30000个四元组(Ot,ISDt,Iinpaintt,AGTtO_t, ISD_t, I_{\text{inpaint}}^t, A_{\text{GT}}^tOt,ISDt,Iinpaintt,AGTt)的数据集,覆盖了各种场景类型和目标类别。
- 使用二进制交叉熵和软Dice损失进行训练,使用Adam优化器,学习率为1×10−41 \times 10^{-4}1×10−4。所有图像被调整为256×256像素,模型训练50个周期,并采用早停机制。
导航思维链决策

在将想象目标与当前观测对齐后,智能体需要确定下一步导航动作。
- CoT推理:采用结构化的、基于语言的思维链(CoT)推理方法,将决策过程分解为可解释的逐步推理过程,整合多模态信息(包括任务指令、观测标题、视觉注意力图和导航历史)。
- 推理阶段:
- 目标定位:根据全局指令推断智能体当前正在寻找的目标(如“带蓝色沙发的房间”)。
- 感知验证:解释观测和注意力图,确定目标是否出现在当前场景中。
- 决策理由:基于对齐结果,选择最佳的下一步行动并说明理由。
- 模型训练:
- 使用LoRA适配器微调的LLaMA2-7B模型输出中间推理步骤和最终动作。通过从注意力图中提取简洁的文本摘要(如“掩码突出显示走廊的左侧”)来表示视觉上下文。
- 与之前主要作为事后解释的CoT方法不同,VISTA将CoT推理直接嵌入导航控制循环中,将抽象指令与具体的视觉感知联系起来。这种明确的、逐步的推理过程增强了可解释性,提高了导航的鲁棒性,并支持更透明的决策过程。
实验
实验设置
- 数据集:在Room-to-Room(R2R)数据集上进行评估,该数据集基于Matterport3D模拟器构建,包含90个真实世界室内场景,10567个全景视点以及7189条轨迹,每条轨迹都配有三条自然语言指令和一条真实路径。数据集分为训练集(4675条轨迹)、验证集(340条轨迹)、验证未见集(783条轨迹)和测试集(1391条轨迹)。
- 辅助数据集:为了支持想象引导的导航,作者创建了一个大规模辅助数据集R2R-Imagine,包含超过250000张图像,覆盖所有R2R分割的想象目标场景。这些图像通过两阶段视觉-语言流程生成,使用Qwen2-VL生成标题,再通过LoRA微调的Stable Diffusion模型生成图像。
- 评估指标:
- 成功率(SR):智能体在3米范围内停止的百分比。
- 路径长度加权成功率(SPL):通过比较智能体的路径与最短可能路径来惩罚较长的轨迹。
- 导航误差(NE):智能体最终位置与目标位置之间的最短路径距离。
- 轨迹长度(TL):智能体在一集内行进的总距离。
- 硬件环境:在NVIDIA A100 GPU上运行,包括视觉想象和思维链推理,平均速度为8FPS。
主要结果
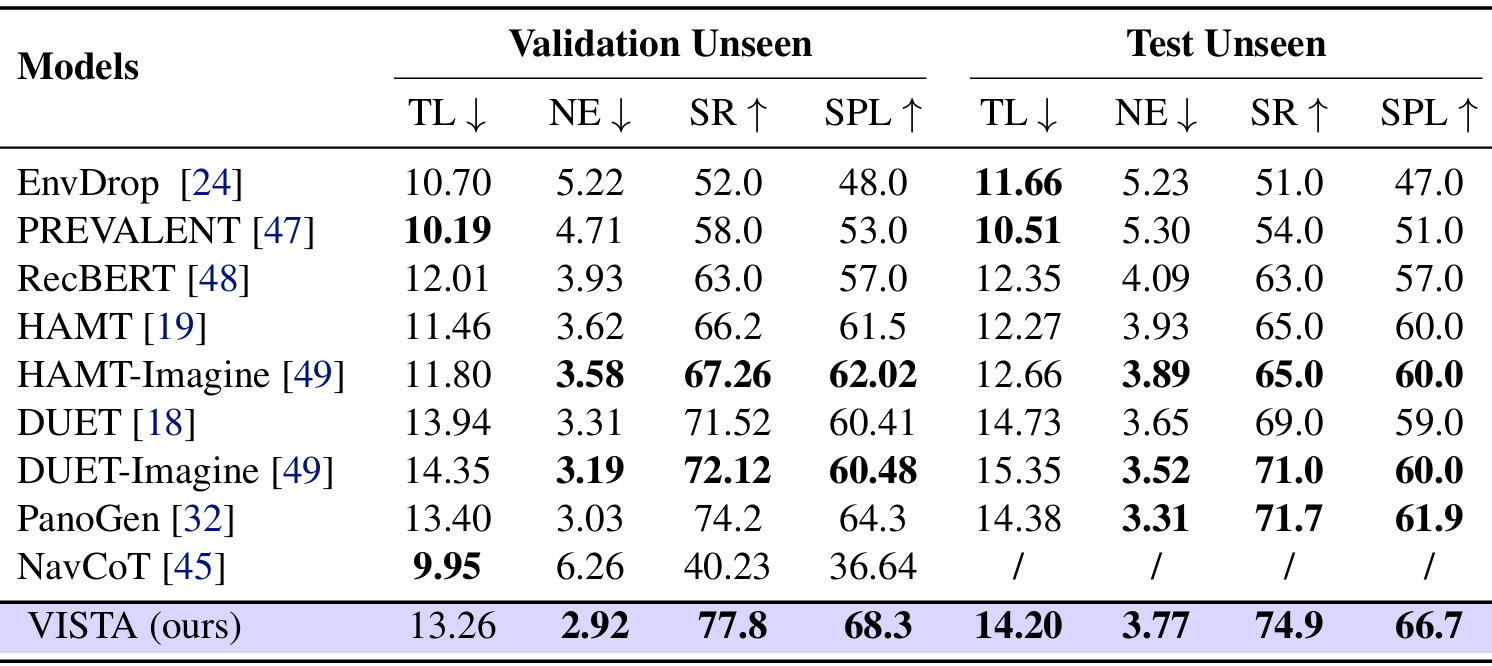
- R2R基准测试结果:
- VISTA在R2R基准测试的验证未见集和测试未见集上均取得了最先进的性能。
- 在验证未见集上,VISTA达到了77.8%的SR和68.3的SPL,超过了之前的最佳模型DUET-Imagine的+3.2% SR和+7.5 SPL。
- 在测试未见集上,VISTA保持了74.9%的SR,表明其改进能够稳健地推广到保留的环境中。
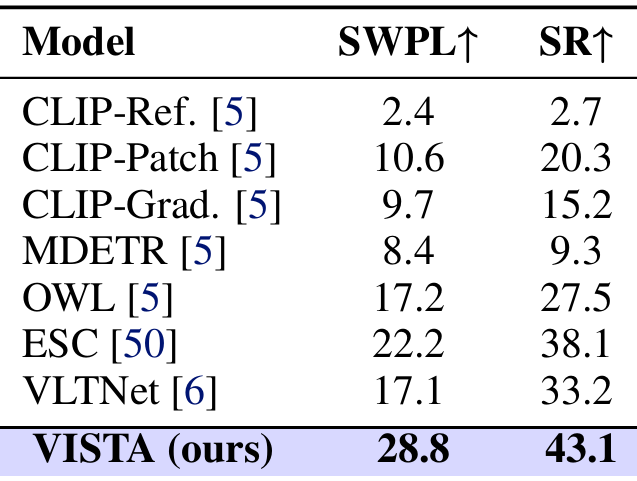
- RoboTHOR基准测试结果:
- VISTA在RoboTHOR基准测试中也取得了显著的性能提升,达到了28.8%的SWPL和43.1%的SR。
- 与竞争基线如VLTNet和ESC相比,VISTA在成功率和路径效率方面都有显著提升。
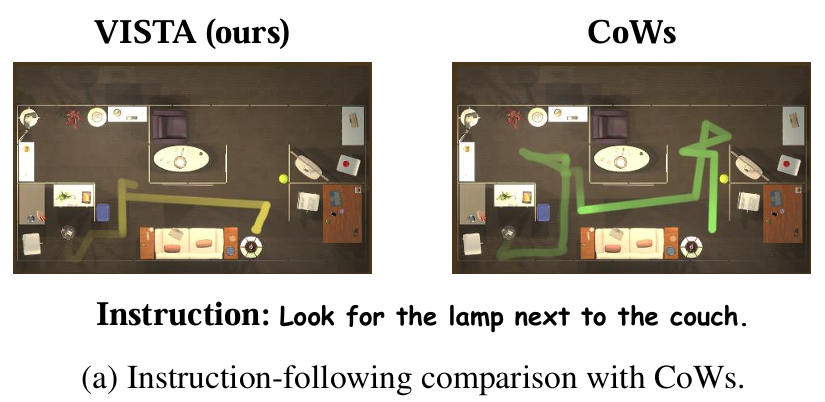
- 定性比较:
- 下图展示了VISTA与其他方法的定性比较,表明VISTA能够有效地将指令与视觉观测相结合,突出其可解释性和鲁棒性。
消融研究
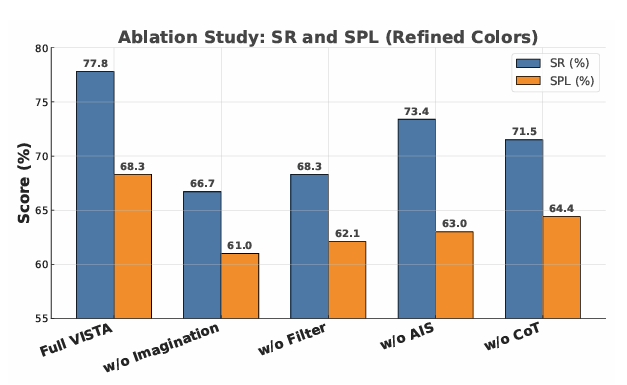
- 移除关键模块的影响:
- 移除视觉想象模块:导致性能大幅下降,SR从77.8%降至66.7%,SPL从68.3降至61.0。这表明视觉想象模块在使智能体能够进行前瞻性行为中的重要性。
- 移除感知对齐滤波器:SR从77.8%降至68.3%,SPL从68.3降至62.1。这表明感知对齐滤波器在空间聚焦和目标定位中的关键作用。
- 移除自适应想象调度器:SR从77.8%降至73.4%,SPL从68.3降至63.0。这表明自适应想象调度器在动态选择想象模式中的有效性。
- 移除思维链推理:SR从77.8%降至71.5%,SPL从68.3降至64.4。这表明思维链推理在提高路径效率中的重要性。
- 模块贡献分析:
- 在RoboTHOR环境中,视觉想象模块在长路径(>15米)上显著提高了成功率(+11.1%),确认了其在长时域导航中的必要性。
- 感知对齐滤波器和思维链推理模块在提高导航效率和路径稳定性方面发挥了重要作用。
失败案例分析
- 不准确的视觉想象:当视觉想象模块生成的场景与实际环境显著偏离时,后续的感知对齐会误导行动选择,导致导航错误。
- 注意力错位:感知对齐滤波器有时会产生过于宽泛或错位的注意力掩码,特别是在视觉复杂或模糊的场景中,降低定位精度,导致效率低下的导航路径。
- 过度依赖指令驱动模式:偶尔,自适应想象调度器会过早选择静态想象模式,忽略实时视觉线索,导致次优路径或导航失败。
结论与未来工作
- 结论:
- VISTA通过将视觉想象、感知对齐和结构化推理相结合,为视觉语言导航任务提供了一种新的解决方案。实验结果表明,VISTA在长时域和视觉模糊场景中表现出色,能够实现鲁棒、可解释的导航行为。
- 未来工作:
- 尽管VISTA在长时域导航任务中表现出色,但仍存在一些局限性。
- 首先,想象目标场景的保真度取决于扩散模型的生成质量,这在复杂环境中可能导致对齐错误。
- 其次,想象和推理流程增加了计算负担,可能限制实时部署。
- 此外,自适应想象调度器依赖手动调整的阈值,可能需要根据不同环境进行调整。
- 最后,所有评估都在模拟环境中进行,现实世界部署可能面临传感器噪声和领域偏移等额外挑战。
- 未来的研究可以探索更轻量级的生成模块、学习调度策略和迁移方法,以提高泛化能力和部署效率。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)