U-Net 全解析:从网络架构、核心原理到 PyTorch 代码实现
U-Net 是一个非常经典且极其重要的卷积神经网络(CNN)架构。它最初是为了生物医学图像分割而设计的,但由于其特别的设计,如今已经成为各种图像分割任务乃至 AI 图像生成模型(如 Stable Diffusion)的核心组件。
U-Net 是一个非常经典且极其重要的卷积神经网络(CNN)架构。它最初是为了生物医学图像分割而设计的,但由于其特别的设计,如今已经成为各种图像分割任务乃至 AI 图像生成模型(如 Stable Diffusion)的核心组件。
它的名字来源于其独特的、对称的 U 形结构。
第一部分:UNET 是什么?为什么需要它?
一句话概括:
UNET是一个专门为图像分割(Image Segmentation)任务设计的卷积神经网络架构。它的核心思想是能够用很少的训练数据就学到精确的分割结果。
什么是图像分割?
现在一张街景照片,里面有汽车、行人、树木、天空。
图像分类:回答“这张图片里有什么?” -> “这是一张街景图。”
目标检测:回答“东西在哪?” -> “这里有一辆汽车(用框圈出来),那里有一个行人(用另一个框圈出来)。”
图像分割:回答“每一个像素属于什么?” -> 为图片中的每一个像素点都打上标签,生成一张“分割图”,其中汽车区域是所有标为“汽车”的像素,行人区域是所有标为“行人”的像素。
在 U-Net 诞生之前,深度学习做图像分割(即将图像中的每个像素分配到一个类别)面临一个挑战:既需要通过深度网络来理解图像的全局内容(“是什么”),又需要保留像素级的精确定位信息(“在哪里”)。
传统的分类CNN(如VGG, ResNet)通过不断的池化(Pooling)和卷积来提取特征,但这个过程会丢失图像的空间信息(位置、细节)。最后得到一个“这张图是猫”的结论,但我们无法知道猫的精确轮廓。我们需要一个能输出和输入图片一样大小的精细结果的网络。
UNET的诞生:
UNET最初(2015年)是为医学图像分割(比如从CT扫描图中分割出肿瘤)而设计的。医学数据通常很难获取(训练数据少),并且需要非常精确的分割轮廓(细节要求高)。UNET完美地解决了这两个痛点。
第二部分:UNET的核心结构——“U型”编码与解码
UNET的结构得名于它的形状,像一个英文字母“U”。它可以清晰地分为两个部分:左侧的编码器(收缩路径) 和 右侧的解码器(扩张路径)。
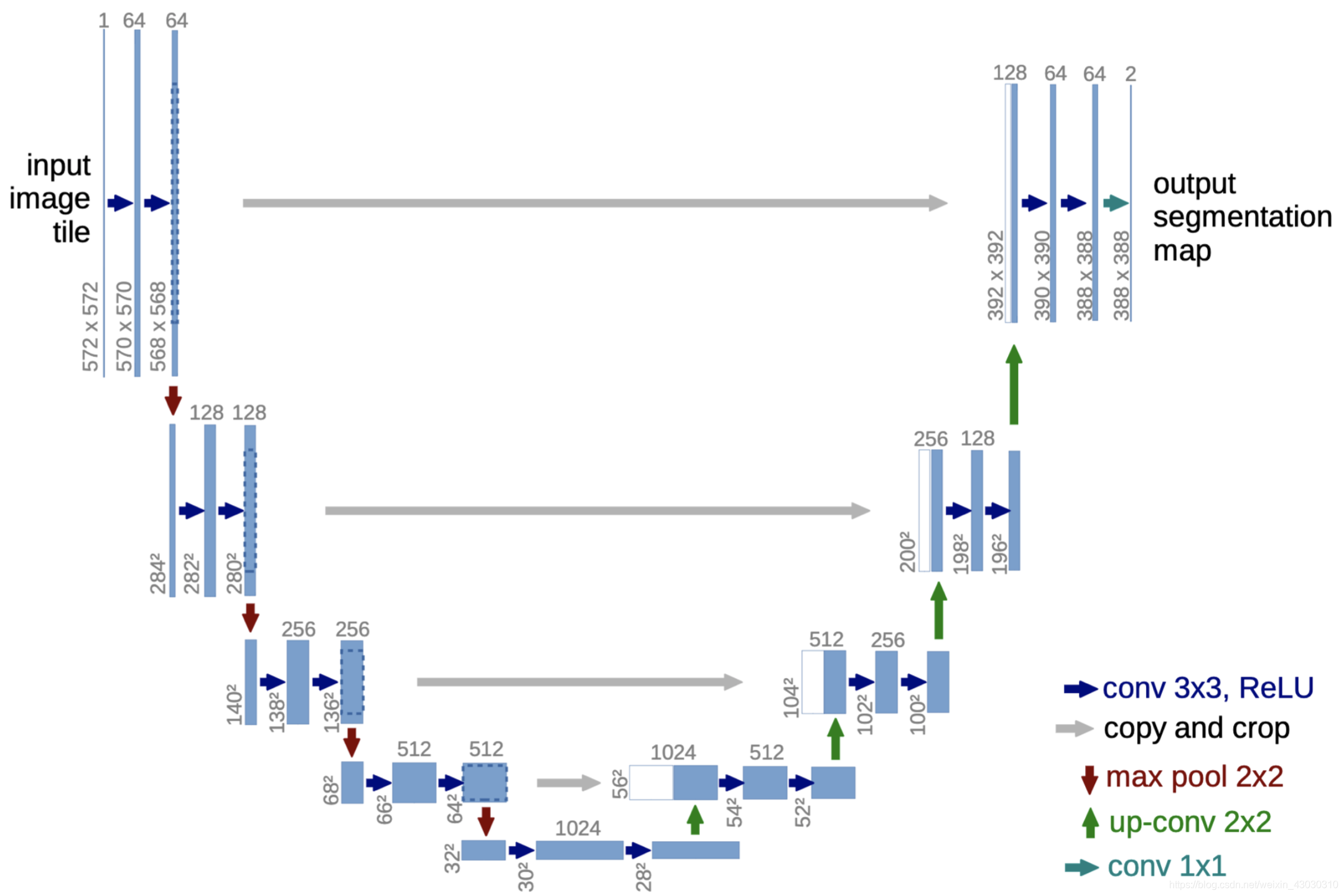
U-Net 的三大核心组成部分
U-Net 的 U 形结构可以清晰地分为三个部分:
-
收缩路径( Encoder): U 形的左半部分。
-
扩展路径( Decoder): U 形的右半部分。
-
跳跃连接(Skip Connections): 连接左右两部分的“桥梁”。
1. 收缩路径 (Encoder) - 捕捉上下文信息
这部分的作用和普通的图像分类网络非常相似,其目标是提取图像的特征并理解图像内容。
操作流程: 它由一系列重复的模块组成,每个模块包含:
-
两个 3x3 的卷积层(通常后面跟着 ReLU 激活函数)。
-
一个 2x2 的最大池化(Max Pooling)层,步长为 2。
效果:
卷积层负责从图像中学习特征(如边缘、纹理、形状等)。
最大池化层进行下采样,将特征图的尺寸(宽和高)减半,同时将特征通道的数量翻倍。
目的: 随着网络层数的加深(U 形的下降),特征图的空间尺寸越来越小,但特征的“语义”级别越来越高。网络从关注像素级的细节,逐渐转变为理解“这里可能是一个细胞”、“那是一块背景”等高层概念。简而言之,它解决了“是什么”的问题。
代码:
import torch
import torch.nn as nn
self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu1_1 = nn.ReLU(inplace=True)
# 572*572*1变成570*570*64
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0)
self.relu1_2 = nn.ReLU(inplace=True)
# 由570*570*64变成了568*568*64
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64
数据维度变化:1x572x572->64x570x570->64x568x568
重复此操作,完成左边编码器操作,提取最终特征图:
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128
self.relu2_2 = nn.ReLU(inplace=True)
#64x284x284->128x282x282->128x280x280
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 采用最大池化进行下采样 280*280*128->140*140*128
经过一系列重复操作后我们得到:28*28*1024 的特征图
在最大池化(下采样)之前,我们需要有个新变量保存输出的内容,因为我们观察UNET的网络结构,是类似于残差连接的方式,所以我们需要一个格式还没有被裁剪的原图,方便后续进行复制和裁剪。
def forward(self, x):
x1 = self.conv1_1(x)
x1 = self.relu1_1(x1)
x2 = self.conv1_2(x1)
c1 = self.relu1_2(x2) # 这个后续需要使用
down1 = self.maxpool_1(x2)
x3 = self.conv2_1(down1)
x3 = self.relu2_1(x3)
x4 = self.conv2_2(x3)
c2 = self.relu2_2(x4) # 这个后续需要使用
down2 = self.maxpool_2(x4)
x5 = self.conv3_1(down2)
x5 = self.relu3_1(x5)
x6 = self.conv3_2(x5)
c3 = self.relu3_2(x6) # 这个后续需要使用
down3 = self.maxpool_3(x6)
x7 = self.conv4_1(down3)
x7 = self.relu4_1(x7)
x8 = self.conv4_2(x7)
c4 = self.relu4_2(x8) # 这个后续需要使用
down4 = self.maxpool_4(x8)
x9 = self.conv5_1(down4)
x9 = self.relu5_1(x9)
x10 = self.conv5_2(x9)
c5 = self.relu5_2(x10)
以上,c1,c2,c3,c4就是我们后面需要用到的,c5作为底层,不需要拼接,主要是作为解码器的起始特征图。
2. 扩展路径 (Decoder) - 实现精确定位
这部分的目标是将编码器提取的高级但粗糙的特征图恢复到原始图像的尺寸,并在此过程中实现像素级的精确定位。
-
操作流程: 它同样由一系列重复的模块组成,每个模块包含:
-
一个 2x2 的上采样卷积(Up-convolution),也叫转置卷积(Transposed Convolution)。这个操作将特征图的尺寸翻倍,通道数减半。
-
接下来会与来自“跳跃连接”的特征图进行拼接(Concatenate)。
-
两个 3x3 的卷积层(同样跟着 ReLU)。
-
-
目的: 上采样操作逐步恢复了空间分辨率,但仅靠这些低分辨率的高级特征,恢复出来的细节会非常模糊。它解决了“在哪里”的问题,但不够精确。不过后续的跳跃连接解决了这个问题,我们暂且按下不表,先完成右边部分代码
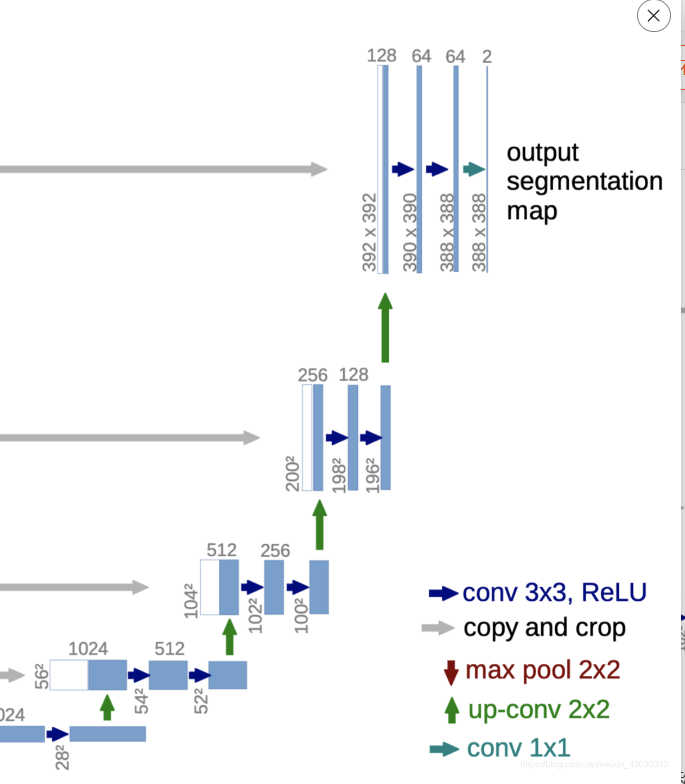
我们来一层一层完成这个解码器
self.up_conv_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2, padding=0)
# 上采样中的up-conv2*2 28*28*1024->56*56*512
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0)
# 56*56*1024->54*54*512
self.relu6_1 = nn.ReLU(inplace=True)
self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0)
# 54*54*512->52*52*512
self.relu6_2 = nn.ReLU(inplace=True)
self.up_conv_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0)
# 52*52*512->104*104*256
self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0)
# 104*104*512->102*102*256
self.relu7_1 = nn.ReLU(inplace=True)
self.conv7_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0)
# 102*102*256->100*100*256
self.relu7_2 = nn.ReLU(inplace=True)
self.up_conv_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0)
# 100*100*256->200*200*128
self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0)
# 200*200*256->198*198*128
self.relu8_1 = nn.ReLU(inplace=True)
self.conv8_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0)
# 198*198*128->196*196*128
self.relu8_2 = nn.ReLU(inplace=True)
self.up_conv_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0)
# 196*196*128->392*392*64
self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0)
# 392*392*128->390*390*64
self.relu9_1 = nn.ReLU(inplace=True)
self.conv9_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0)
# 390*390*64->388*388*64
self.relu9_2 = nn.ReLU(inplace=True)
最终
28x28x1024的特征图成为了388x388x64
这个时候还没完,最后接上1x1d的卷积核进行降维:它的作用是将最终的特征图通道数映射到所需的类别数。
例如,对于一个二分类任务(如肿瘤 vs 非肿瘤),输出通道数就是1,然后用Sigmoid激活函数输出每个像素是肿瘤的概率。
self.conv_10 = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1, stride=1, padding=0)
# 1x1卷积
3. 跳跃连接 (Skip Connections) - U-Net 的精髓
这是 U-Net 最具创新性和影响力的设计,也是它成功的关键
是什么: 跳跃连接将收缩路径(Encoder)中、下采样之前的特征图,直接“跳跃”到扩展路径(Decoder)中,与对应层级上采样之后的特征图进行拼接。
为什么需要它:
-
收缩路径(Encoder)在下采样的过程中,不可避免地会丢失很多精细的空间细节信息。
-
扩展路径(Decoder)虽然能恢复尺寸,但无法凭空创造这些丢失的细节。
它如何工作:
-
来自 Encoder 的特征图具有高分辨率和丰富的细节信息(因为它经过的池化层少)。
-
来自 Decoder 上一层的特征图具有高级的语义信息(因为它经过了整个 Encoder 的提炼)。
-
跳跃连接将这两者拼接在一起,使得 Decoder 在进行上采样和卷积时,既能利用高级语义信息(知道“这是一个细胞的边界”),又能利用高分辨率的细节信息(知道“这个边界的具体像素位置在这里”)。
U-Net 跳跃连接的实现方式不是将两个特征图进行数学上的加法(像 ResNet 那样),而是拼接。
拼接 是指将两个或多个张量(Tensor)沿着一个指定的维度“堆叠”起来。在图像处理中,通常是沿着通道维度进行拼接。
举个例子,假设:
-
解码器(Decoder)中,经过上采样得到的特征图
A的尺寸是[Batch_size, 256, 64, 64]。(代表有 256 个通道,高和宽都是 64) -
编码器(Encoder)中,对应层级的特征图
B的尺寸也是[Batch_size, 256, 64, 64]。
将 A 和 B 沿着通道维度(dim=1)进行拼接后,得到的新特征图 C 的尺寸会是:
-
[Batch_size, 256 + 256, 64, 64],即[Batch_size, 512, 64, 64]。
这个拼接后的、更“厚”的特征图 C,就同时包含了来自解码器路径的高级语义信息和来自编码器路径的低级细节信息。然后,它会被送入解码器后续的卷积层进行进一步的学习和融合。
让我们跟着数据在 U-Net 中走一遍,看看跳跃连接是如何发生的:
1. 在编码器(收缩路径)中:
网络在进行下采样时,我们需要把下采样之前的特征图保存下来。
-
输入 -> 卷积块1 -> 输出
c1-
c1是一个高分辨率、低语义的特征图。 -
【关键步骤】我们将
c1暂存起来,比如放进一个列表或字典里。 -
然后
c1经过最大池化(Max Pooling)得到p1,送入下一层。
-
-
p1-> 卷积块2 -> 输出c2-
【关键步骤】我们将
c2也暂存起来。 -
然后
c2经过池化得到p2...
-
这个过程会一直持续到 U-Net 的最底部(Bottleneck)。
2. 在解码器(扩展路径)中:
网络开始进行上采样,这时就需要使用我们之前保存的特征图了。
... 从最底部 b 开始 -> 上采样卷积1 -> 输出up_conv_1
up_conv_1 的尺寸被设计成与我们之前保存的 c4的尺寸完全相同。
执行拼接操作:merged_1 = concatenate([u1, c4])
将 merged_1 送入解码器的卷积块进行处理。
这个过程在解码器的每一层都会重复,直到输出最终的分割图。
在 U-Net 的跳跃连接中,需要将编码器(左侧)的特征图与解码器(右侧)上采样后的特征图进行拼接。
然而,在原始的 U-Net 论文中,卷积操作使用了 'valid' 模式,即没有填充(Padding)。这会导致每次卷积后,特征图的尺寸都会略微缩小。
这就造成了一个问题:当解码器将特征图上采样后,其尺寸可能会比编码器中对应层级的特征图要小一些。例如,解码器的图是 88x88,而编码器的图是 92x92。
为了能让它们成功拼接,就必须将尺寸较大的编码器特征图进行裁剪,使其与解码器的特征图尺寸一致。
# 中心裁剪,
def crop_tensor(self, tensor, target_tensor):
target_size = target_tensor.size()[2]
tensor_size = tensor.size()[2]
delta = tensor_size - target_size
delta = delta // 2
# 如果原始张量的尺寸为10,而delta为2,那么"delta:tensor_size - delta"将截取从索引2到索引8的部分,长度为6,以使得截取后的张量尺寸变为6。
return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]
代码分步解析:
我们假设输入的张量格式为 [批次数, 通道数, 高度, 宽度]
target_size = target_tensor.size()[2]
获取 target_tensor 的第三个维度的大小,也就是目标高度。
tensor_size = tensor.size()[2]
获取待裁剪 tensor 的第三个维度的大小,也就是原始高度。
delta = tensor_size - target_size
计算原始张量和目标张量在高度(或宽度)上的总尺寸差异。例如,如果原始尺寸是 92x92,目标尺寸是 88x88,那么 delta 就是 4。
delta = delta // 2
将总差异除以2(整数除法)。这计算出了在单边需要裁剪掉的像素数量。在上面的例子中,delta 会变成 2。这意味着我们需要从上、下、左、右四个方向各裁剪掉 2 个像素。
return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]
[:, :, ...]:前两个 :表示保留所有的批次(Batch)维度和通道(Channel)维度。
delta:tensor_size - delta:这是对高度维度的切片。它从索引 delta开始,到索引 tensor_size - delta结束(不包括结束索引本身)。这意味着它去掉了原始特征图顶部和底部各 delta个像素。
delta:tensor_size - delta:这是对宽度维度的切片。同理,它去掉了原始特征图左侧和右侧各 delta个像素。
在我们的例子中,就是从索引 2 切到 92 - 2 = 90,即 [2:90]。这会选取索引为 2, 3, ..., 89 的部分,总长度为 88,正好等于 target_size。
效果:最终输出的特征图尺寸变为 target_size x target_size(高度和宽度都与 target_tensor相同),通道数保持不变。
函数计算 delta后,从原始特征图的四个边(上、下、左、右)各均匀地裁剪掉 delta个像素。
这相当于保留了原始特征图最中心的 target_size x target_size区域。
这种裁剪方式基于一个假设:图像或特征图的重要信息通常集中在中心区域,边缘信息相对次要或可以通过上下文推断。
好的,准备工作做好了,现在正式进入代码讲解实操
首先,我们对第一层进行上采样,然后对需要拼接的C4进行裁剪,匹配大小,然后拼接,最后进行RELU操作,得到Y2
# 第一次上采样
up1 = self.up_conv_1(c5)
# 得到56*56*512
# 需要对c4进行裁剪,从中心往外裁剪
crop1 = self.crop_tensor(x8, up1)
# 拼接操作
up_1 = torch.cat([crop1, up1], dim=1)
y1 = self.conv6_1(up_1)
y1 = self.relu6_1(y1)
y2 = self.conv6_2(y1)
y2 = self.relu6_2(y2)# 第二次上采样
up2 = self.up_conv_2(y2)
# 需要对c3进行裁剪,从中心往外裁剪
crop2 = self.crop_tensor(c3, up2)
# 拼接
up_2 = torch.cat([crop2, up2], dim=1)
y3 = self.conv7_1(up_2)
y3 = self.relu7_1(y3)
y4 = self.conv7_2(y3)
y4 = self.relu7_2(y4) # 第三次上采样
up3 = self.up_conv_3(y4)
# 需要对c2进行裁剪,从中心往外裁剪
crop3 = self.crop_tensor(c2, up3)
up_3 = torch.cat([crop3, up3], dim=1)
y5 = self.conv8_1(up_3)
y5 = self.relu8_1(y5)
y6 = self.conv8_2(y5)
y6 = self.relu8_2(y6)
# 第四次上采样
up4 = self.up_conv_4(y6)
# 需要对c1进行裁剪,从中心往外裁剪
crop4 = self.crop_tensor(c1, up4)
up_4 = torch.cat([crop4, up4], dim=1)
y7 = self.conv9_1(up_4)
y7 = self.relu9_1(y7)
y8 = self.conv9_2(y7)
y8 = self.relu9_2(y8)
# 最后的conv1*1
out = self.conv_10(y8)
return out
U-Net 的现代应用:扩散模型的核心
虽然 U-Net 最初于图像分割,但它“输入一张图,输出一张同样尺寸的图”的特性使其非常适合去噪任务。
在 Stable Diffusion、Midjourney 等现代 AI 绘画模型中,其核心的噪声预测器就是一个经过现代化改造的 U-Net。
-
在扩散模型的反向过程中,每一步都需要从一张带噪图片 x_t 中预测出所添加的噪声
。
-
这个任务完美契合 U-Net 的结构:输入是一张带噪图片,输出是预测的噪声图(尺寸完全相同)。
-
文本提示(Prompt)等条件信息,则通过交叉注意力(Cross-Attention)机制被巧妙地注入到 U-Net 的各个模块中,引导 U-Net 预测出符合描述的噪声,从而生成想要的图像。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 35
35 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)