NPU边缘推理识物系统
本文介绍了一个基于NPU的边缘推理识物系统。系统采用NXP i.MX93处理器,搭载ARM Ethos-U65 NPU,在正点原子ATK-DLIMX93开发板上实现本地AI推理。软件部分包含底层NPU推理代码(使用TFLite框架)和应用层QT显示界面,实现了物体识别功能。系统优势在于本地化处理,推理速度快(约4ms)、功耗低(6TOPs算力),适用于实时性要求高的场景。项目成果展示了边缘推理的可
目录
NPU边缘推理识物系统
一、项目简介
物品分类是计算机视觉的重要技术,本项目的核心是:使用NPU(神经网络处理器或神经网络处理单元)进行本地推理计算识别。相比与传统的识别技术,NPU边缘推理识别不需要依赖网络和云端,它在本地SoC(System on Chip片上系统)上就可以高效、快速地处理AI任务。NPU在AI推理计算上比CPU更专业和高效,比GPU更省电。
二、硬件介绍
本项目使用的是NXP(恩智浦)推出的i.MX93,i.MX93处理器集成的NPU,搭载了 ARM 自研的 Ethos-U65。Ethos-U65 神经处理单元(NPU)是 ARM 为了在面积受限的嵌入式和物联网设备的情况下加速机器学习推理而设计。
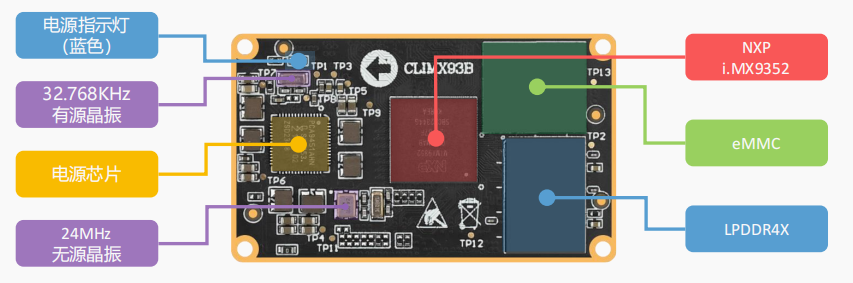
项目开发板使用的是正点原子推出的ATK-DLIMX93 开发板
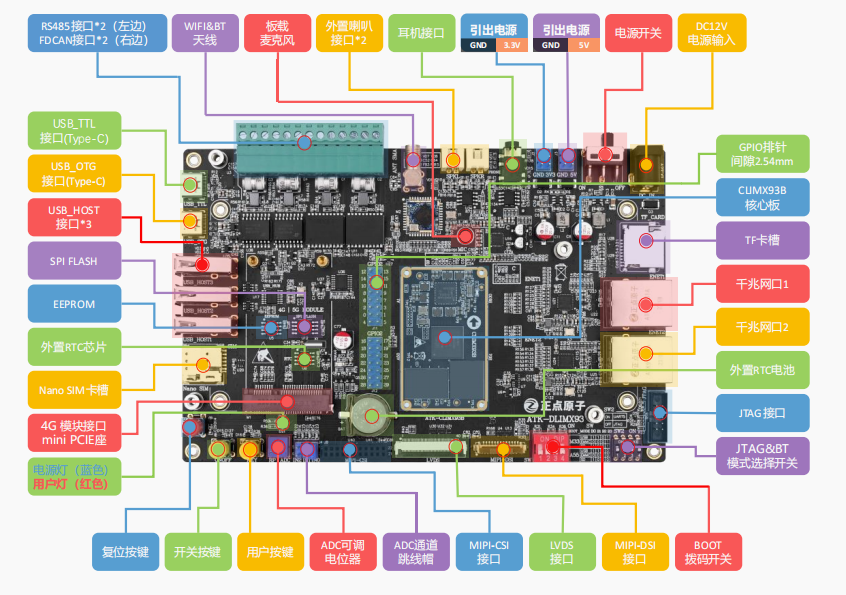
开发板实物展示


硬件层面虽然正点原子设计的接口很多,但是我们只使用了SoC中的NPU和屏幕进行效果展示。后期考虑接入摄像头设备。
注意:正点原子没有提供i.MX93的核心板原理图,如果想要自己设计出核心板需要借鉴NXP(恩智浦)官方提供的评估板原理图资料进行复刻。
三、软件设计
首先声明,我们项目的所有操作都是基于Linux操作系统来进行的,所以我们要对i.MX93上面烧录Linux操作系统之后再能进行后续软件开发。
1、底层NPU推理代码
底层NPU推理识别流程图
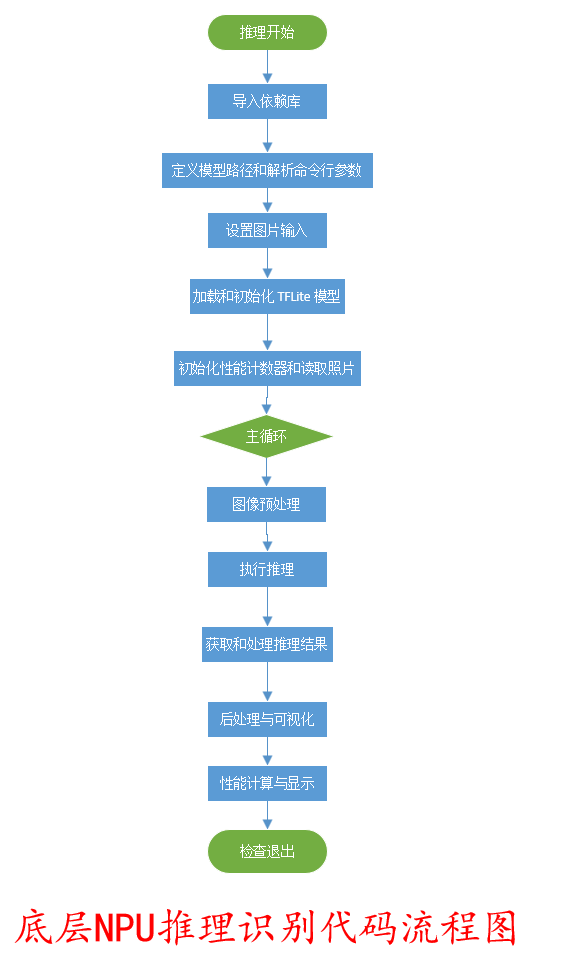
底层控制NPU推理识别Python代码
'''
项目所有文件名 : main4.py
作者 : SELSL
版本 : V1.0
描述 : 使用NPU推理得出图片类型
其他 : 无
论坛 : 无
日志 : 初版 V1.0 2025/8/8 SELSL创建
'''
#导入依赖库
#用于加载和运行 .tflite 格式的模型
import tflite_runtime.interpreter as tflite
#用于处理数组和数值计算
import numpy as np
#(OpenCV): 用于视频捕获、图像处理和保存图像
import cv2
#用于测量代码执行时间
import time
#用于解析命令行参数
import argparse
#将模型输出的类别索引映射为人类可读的类别名称
from labels import label2string
#定义模型路径和解析命令行参数
#指定了 .tflite 模型文件的路径
MODEL_PATH = "../vela_models/ssd_mobilenet_v1_quant_vela.tflite"
parser = argparse.ArgumentParser()
parser.add_argument(
'-i',
'--input',
default='/dev/video0',
help='input to be classified')
parser.add_argument(
'-d',
'--delegate',
default='',
help='delegate path')
args = parser.parse_args()
#设置图片输入
if args.input.isdigit():
cap_input = int(args.input)
else:
cap_input = args.input
vid = cv2.VideoCapture(cap_input)
#加载和初始化 TFLite 模型
if args.delegate:
ext_delegate = [tflite.load_delegate(args.delegate)]
interpreter = tflite.Interpreter(model_path=MODEL_PATH, experimental_delegates=ext_delegate)
else:
interpreter = tflite.Interpreter(model_path=MODEL_PATH)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
height = input_details[0]['shape'][1]
width = input_details[0]['shape'][2]
#初始化性能计数器和读取照片
total_fps = 0
total_time = 0
ret, frame = vid.read()
if frame is None:
print("Can't read frame from source file", args.input)
exit(0)
saved = False
#主循环
while ret:
total_fps += 1
loop_start = time.time()
#图像预处理
img = cv2.resize(frame, (width, height)).astype(np.uint8)
input_data = np.expand_dims(img, axis=0)
interpreter.set_tensor(input_details[0]['index'], input_data)
#执行推理
invoke_start = time.time()
interpreter.invoke()
invoke_end = time.time()
#获取和处理推理结果
boxes = interpreter.get_tensor(output_details[0]['index'])[0]
labels = interpreter.get_tensor(output_details[1]['index'])[0]
scores = interpreter.get_tensor(output_details[2]['index'])[0]
number = interpreter.get_tensor(output_details[3]['index'])[0]
#后处理与可视化
if int(number) > 0 and not saved:
for i in range(int(number)):
if scores[i] > 0.5:
box = [boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3]]
x0 = max(2, int(box[1] * frame.shape[1]))
y0 = max(2, int(box[0] * frame.shape[0]))
x1 = int(box[3] * frame.shape[1])
y1 = int(box[2] * frame.shape[0])
cv2.rectangle(frame, (x0, y0), (x1, y1), (255, 0, 0), 2)
cv2.putText(frame, label2string[labels[i]], (x0, y0 + 13),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
print(f"Detected object: ({x0},{y0})-({x1},{y1}) label:{label2string[labels[i]]} score:{scores[i]:.2f}")
cv2.imwrite('test.bmp', frame)
print("Detection result saved as test.bmp")
saved = True
#性能计算与显示
loop_end = time.time()
total_time += (loop_end - loop_start)
fps = int(total_fps / total_time)
invoke_time = int((invoke_end - invoke_start) * 1000)
print(f"Processing frame {total_fps}: FPS={fps}, Inference time={invoke_time}ms")
#检查退出
ret, frame = vid.read()
if cv2.waitKey(1) & 0xFF == ord('q'):
break
vid.release()2、应用层QT显示代码
QT应用层代码流程图
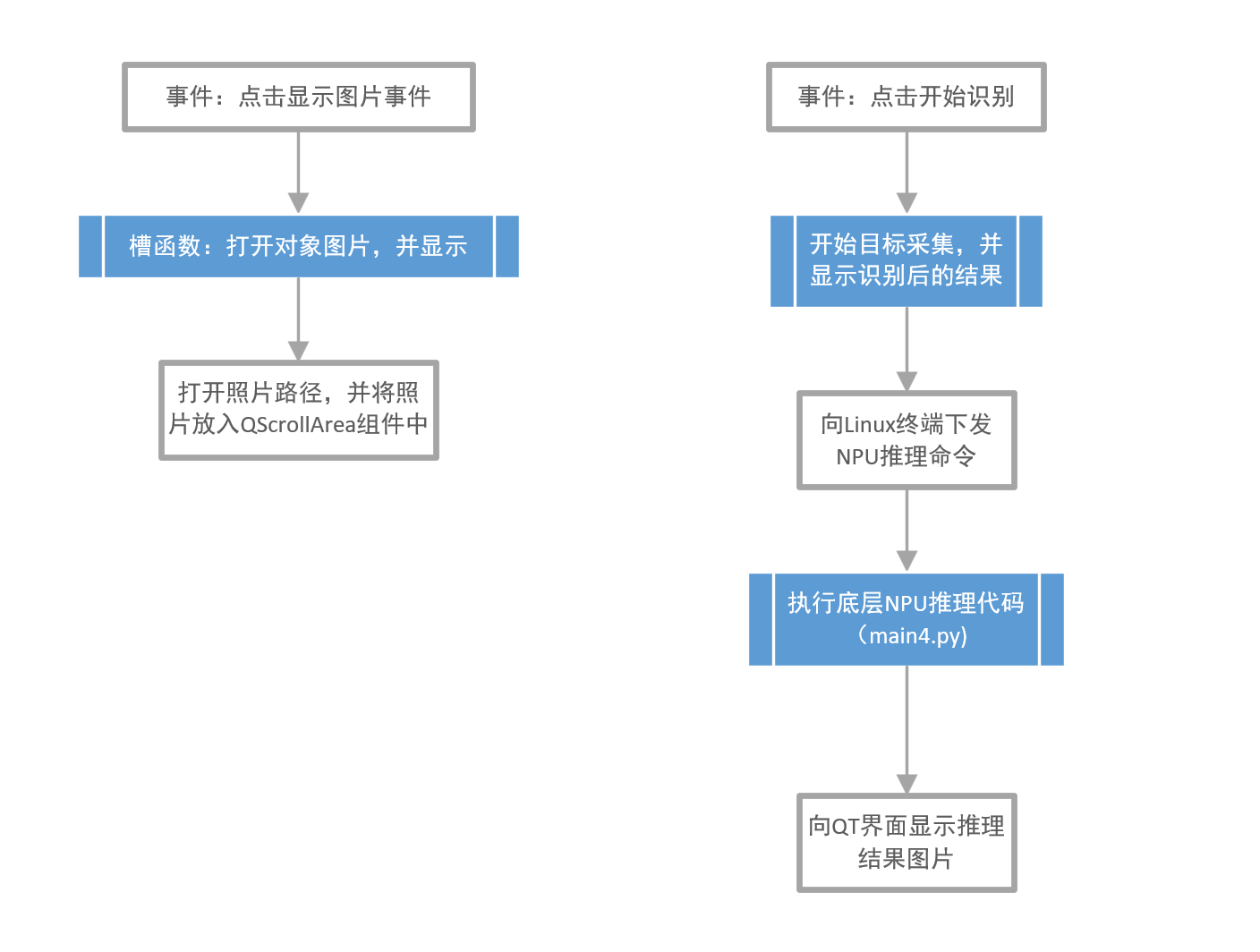
显示图像框架预览
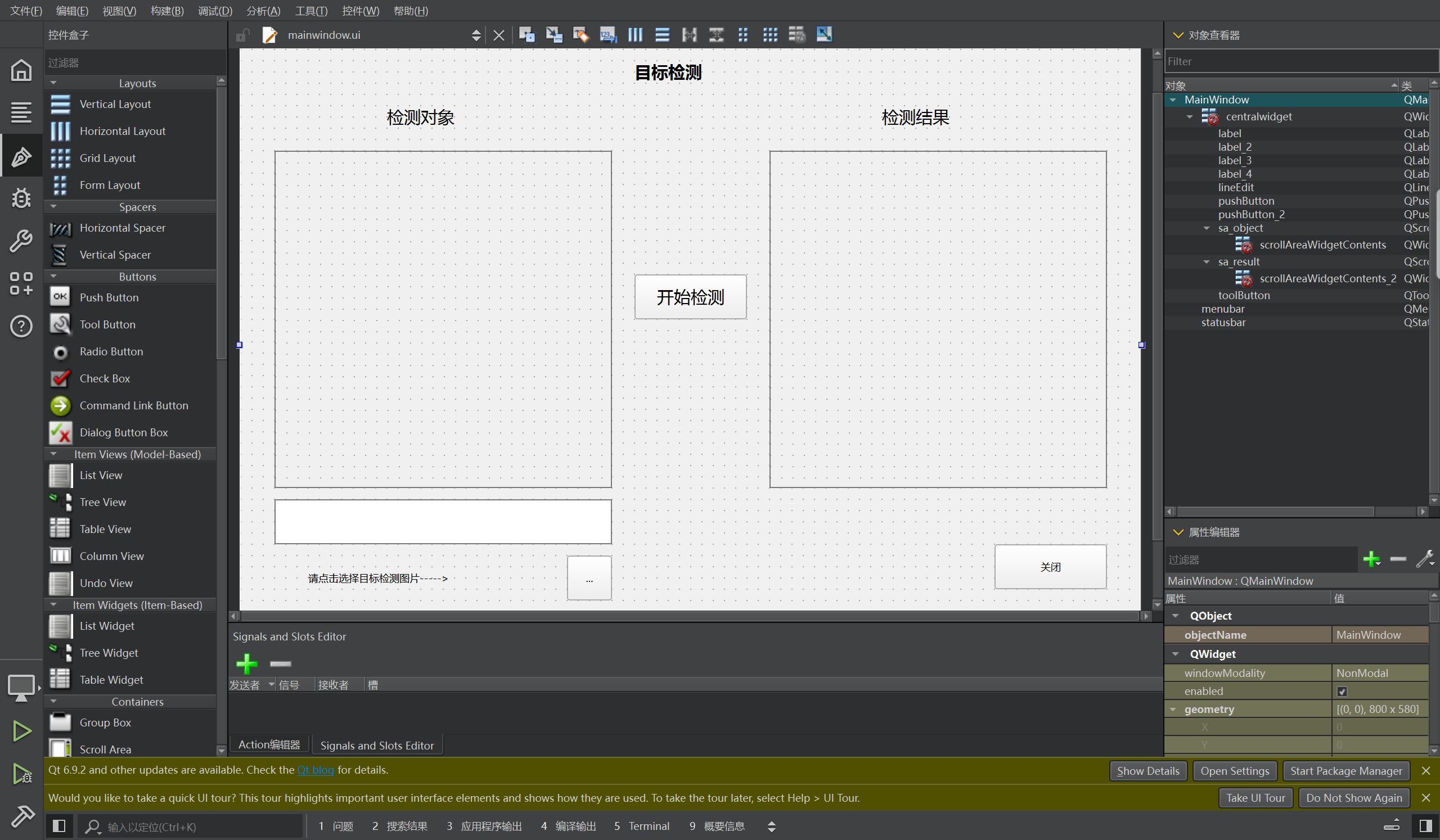
QT核心代码预览
/***************************************************************
项目所有文件名 : mainwindow.h main.c mainwindow.c mainwindow.ui
作者 : SELSL
版本 : V1.0
描述 : 使用NPU推理得出图片类型
其他 : 无
论坛 : 无
日志 : 初版 V1.0 2025/8/8 SELSL创建
***************************************************************/
#include "mainwindow.h"
#include "ui_mainwindow.h"
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
ui->setupUi(this);
//设置工作路径,方便后续操作图片处理命令
QDir::setCurrent("/usr/bin/eiq-examples-git/object_detection");
//创建QProcess对象,方便后期进行命令执行
process = new QProcess;
}
MainWindow::~MainWindow()
{
delete process;
delete imageLabel;
delete imageLabel2;
delete ui;
}
//关闭窗口
void MainWindow::on_pushButton_2_pressed()
{
close();
}
//打开对象图片,并显示
void MainWindow::on_toolButton_clicked()
{
//使用QFileDialog中的getOpenFileName获取要进行目标检测的图片地址
QString imageName = QFileDialog::getOpenFileName(this, tr("请选择图片"), "/usr/bin/eiq-examples-git/object_detection");
//输出图片地址是否正确
qDebug() << imageName;
//把图片地址放入QLineEdit组件中,方便用户查看
ui->lineEdit->setText(imageName);
//创建QLabel标签对象,为放置图片做准备
imageLabel = new QLabel;
//把图片放入QImage对象中
QImage image(imageName);
//把图片放入QPixmap处理,在放入QLabel中
imageLabel->setPixmap(QPixmap::fromImage(image));
//最终把图片展示在界面的QScrollArea组件中,显示出要识别的图片,方便用户直观的查看图片。
ui->sa_object->setWidget(imageLabel);
}
//开始目标采集,并显示
void MainWindow::on_pushButton_clicked()
{
//输出当前的工作目录
qDebug() << QDir::currentPath();
//使用 NPU 推理进行目标检测的终端命令
QString command1 = QString("python3 main4.py -i ");
QString command2 = QString(ui->lineEdit->text());
QString command3 = QString(" -d /usr/lib/libethosu_delegate.so");
QString command = command1 + command2 + command3;
//输出验证终端命令是否正确
qDebug() << command;
//开始使用NPU 推理进行目标检测
process->start("/bin/sh", QStringList() << "-c" << command);
//等待使用NPU推理进行目标检测完成
process->waitForFinished();
//输出NPU推理目标检测完成后的输出信息
QString output = process->readAllStandardOutput();
qDebug() << output;
//得到NPU推理得出的目标图片地址
QString imageName = QString("/usr/bin/eiq-examples-git/object_detection/test.bmp");
//输出图片地址是否正确
qDebug() << imageName;
//创建QLabel标签对象,为放置图片做准备
imageLabel2 = new QLabel;
//把图片放入QImage对象中
QImage image(imageName);
//把图片放入QPixmap处理,在放入QLabel中
imageLabel2->setPixmap(QPixmap::fromImage(image));
//向目标QScrollArea展示推理得出的目标图片
ui->sa_result->setWidget(imageLabel2);
}注意:QT应用层代码有mainwindow.h main.c mainwindow.c mainwindow.ui,这里只显示了最核心的部分mainwindow.c,其他代码请向项目成员SELSL获取。
四、项目成果展示
代码预览展示
调试阶段性结果展示
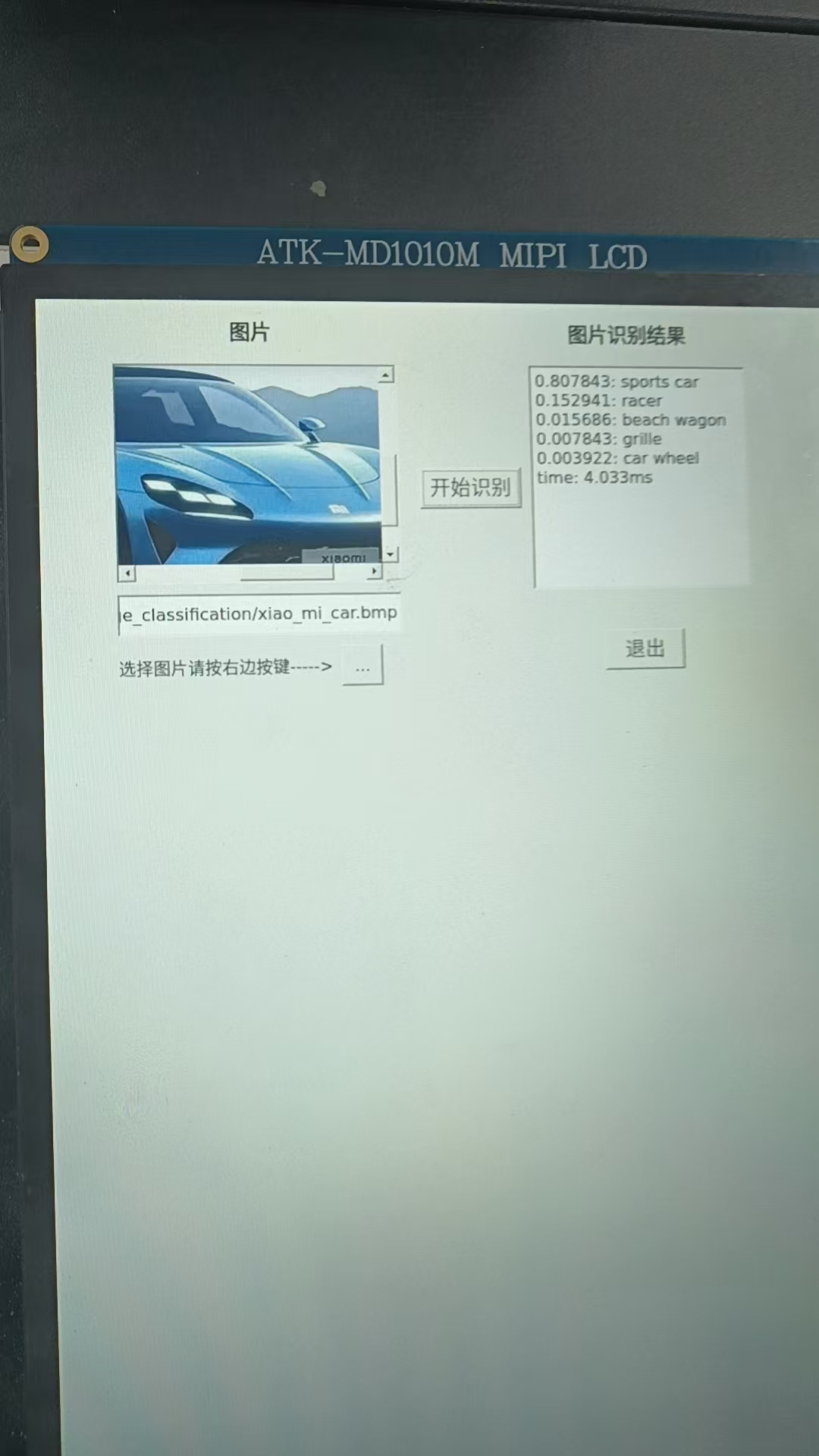
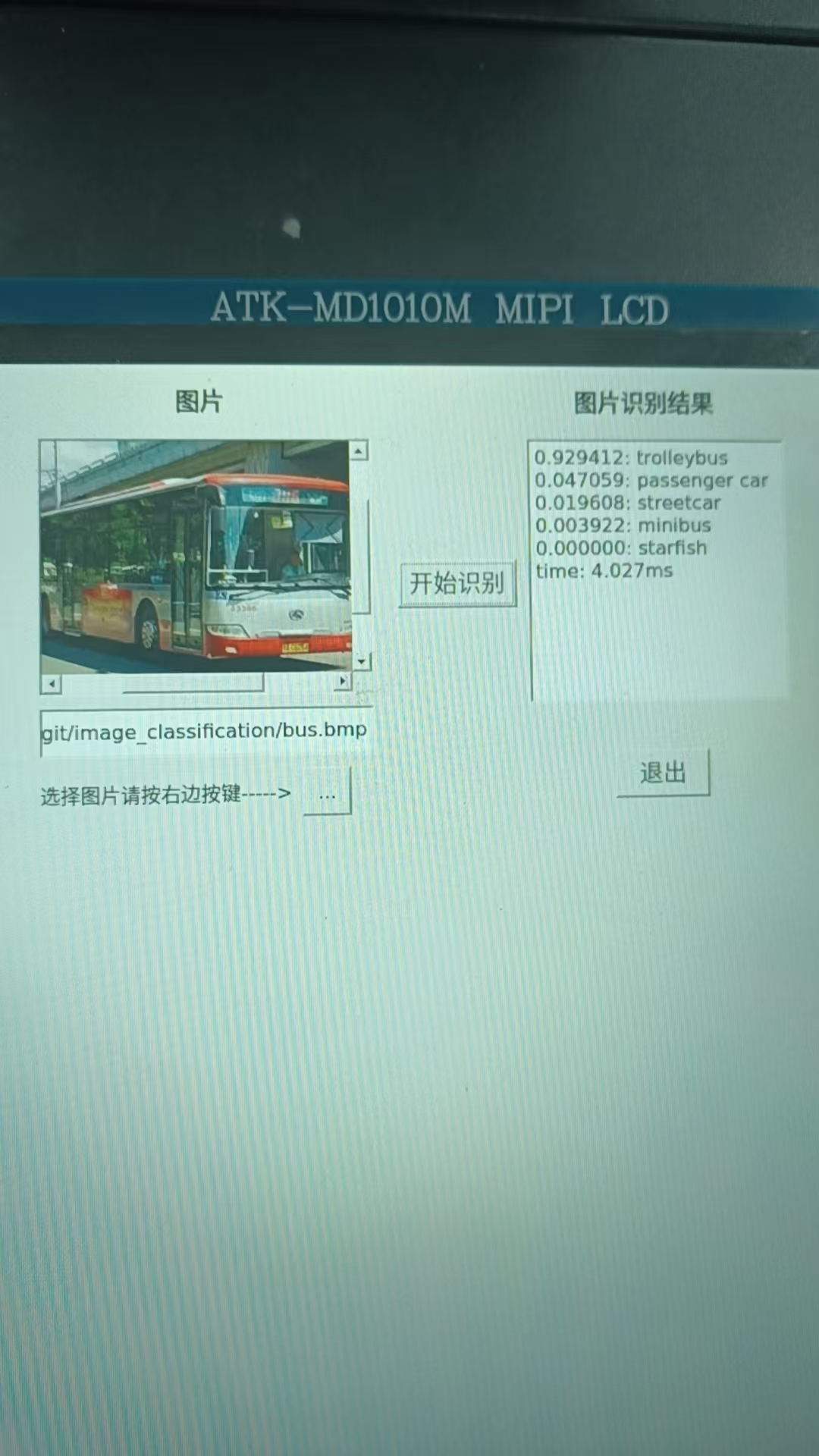
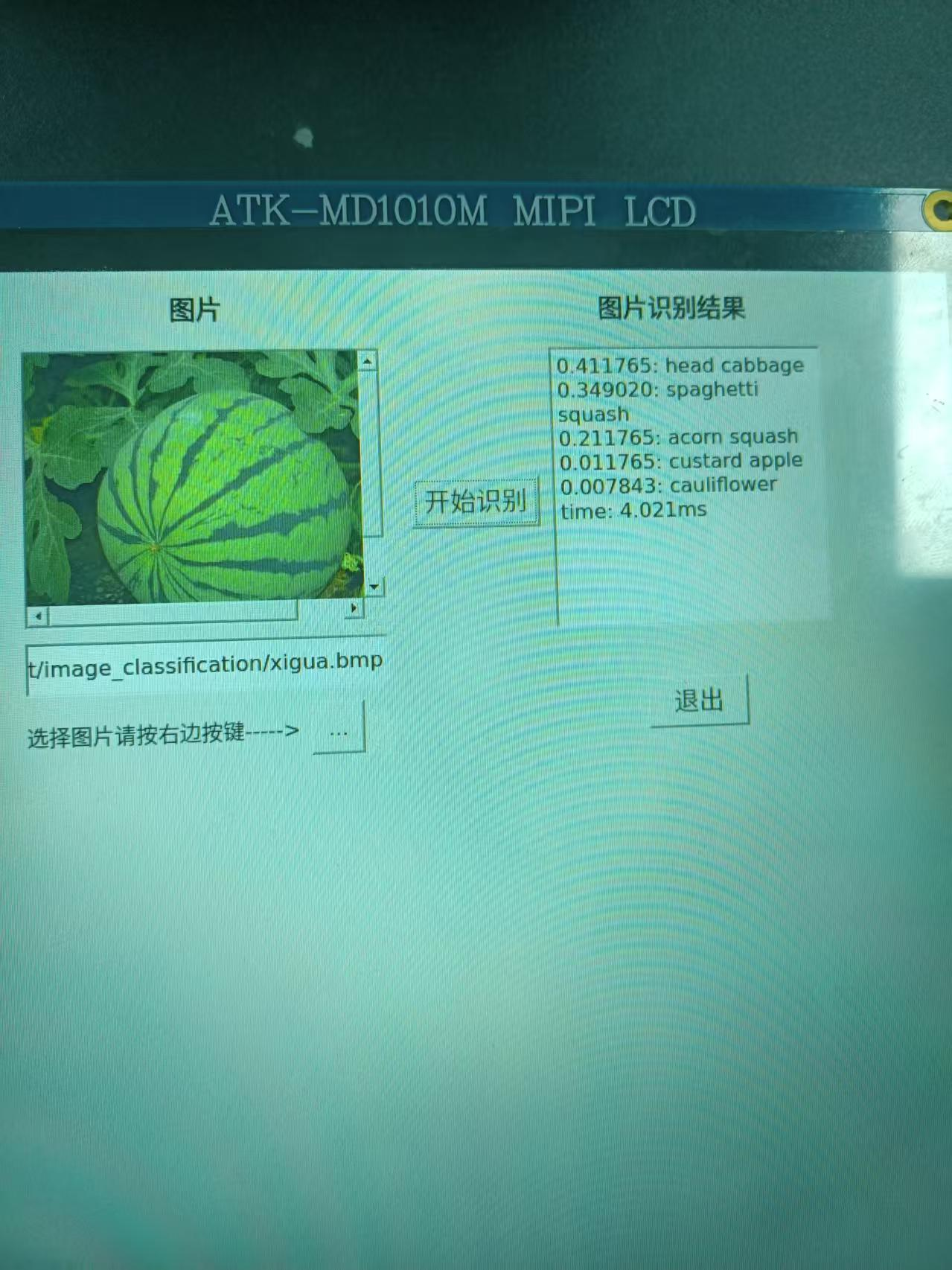
最终结果演示

注意:这个项目我们采用的是官方提供的免费开源模型,开源的,你懂的,就是能用,但是效果没有自己训练的模型或买的模型效果好,所以有一部分物体识别达不到先要的效果,包括本团队后期使用NPU进行的人脸识别推理,同一个人识别出不同的效果的现象。这不是代码的问题也NPU的问题,而是模型上的问题。
我们的NPU算力达到了6TOPs,在移动终端设备上是一个比较快的水准,当然向上与GPU几百的算力相比还是稍显逊色,但是相比于功耗来说,我们的NPU的功耗是远远低于GPU的功耗。这里通过上面的调试推理过程也可以看到推理时间大概在4ms左右,这也是一个很快的推理速度,相比与传统的把图片上传至云端耗时操作好点的,特别是在实时性要求比较高的场所,NPU边缘推理是一个很好的解决方案。
资料获取:https://download.csdn.net/download/2403_82436914/91888061

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)