5600亿参数的 AI 有多高效?美团 “闪电龙猫(LongCat-Flash)“ 的智能运转秘籍
LongCat-Flash是5600亿参数的MoE模型,采用Zero-computation Experts和Shortcut-connected MoE架构。采用了 Hyperparameter transfer和Model-growth Initialization等方法训练,在20万亿tokens上训练30天,达到100tokens/秒,成本$0.70/百万输出 tokens。
摘要:LongCat-Flash是5600亿参数的MoE模型,采用Zero-computation Experts和Shortcut-connected MoE架构。采用了 Hyperparameter transfer和Model-growth Initialization等方法训练,在20万亿tokens上训练30天,达到100tokens/秒,成本$0.70/百万输出 tokens。
-----
当你用手机APP查询附近的餐馆,或是向智能客服咨询订单问题时,是否想过背后的AI是如何快速响应的?传统的大语言模型常常像一台"油老虎"汽车,不管路途远近都全速运转,既浪费资源又反应迟缓。而美团团队研发的"闪电龙猫"(LongCat-Flash),这只拥有5600亿参数的AI模型,却像一辆混合动力车,既能高效完成复杂任务,又能精准控制能耗,堪称AI界的"节能高手"。
要理解"闪电龙猫"的过人之处,得先看看普通AI的短板。就像快递分拣中心如果对所有包裹都用同样的流程处理——不管是一封信还是一个大箱子都经过全套安检、称重、分类,效率肯定高不了。传统AI模型也是如此,处理简单的"你好"和复杂的数学公式时,动用的计算资源几乎一样,这种"平均用力"的方式造成了大量浪费。更麻烦的是,当模型规模扩大,不同模块之间传递信息就像单车道上的车流,很容易拥堵,严重拖慢整体速度。
"闪电龙猫"的突破,就在于它采用了两项巧妙设计,彻底解决了这些问题。
第一项核心技术是"零计算专家"(Zero-computation Experts)。想象一个高效的医院分诊系统:普通感冒患者直接到简易门诊快速处理,疑难杂症才送到专家诊室。"闪电龙猫"的计算团队里,除了负责复杂任务的"全能专家",还加入了一群"零计算专家"——它们不做复杂运算,遇到简单的词汇或句子时,就像简易门诊一样直接返回结果,不占用额外资源。比如处理"的、了、吗"这类虚词时,"零计算专家"快速响应;碰到数学公式或代码时,才调动"全能专家"深入计算。为了让工作量分配更合理,系统还配备了类似恒温器的智能调节机制,确保每个专家的负荷稳定,经过训练后,平均每次只需要激活2700亿参数,仅占总参数的4.8%,实现了真正的"按需分配"。
第二项关键设计是"快捷连接混合专家"(Shortcut-connected MoE)。传统的AI模型处理信息就像流水线作业,必须等上一个环节完成,下一个环节才能开始,哪怕前一步只剩最后一个步骤,后一步也得等着。而"闪电龙猫"通过一条"快捷通道",让前一层处理信息时就能把部分结果传给下一层,就像餐厅后厨里,切菜师傅刚切好一种食材,厨师就立刻开始烹饪这道菜,不用等所有菜都切完。这种设计大幅增加了计算和通信的重叠时间,在大规模训练时,能把设备空闲时间从25.3%降到8.4%,效率提升显著,而且完全不影响模型的性能。
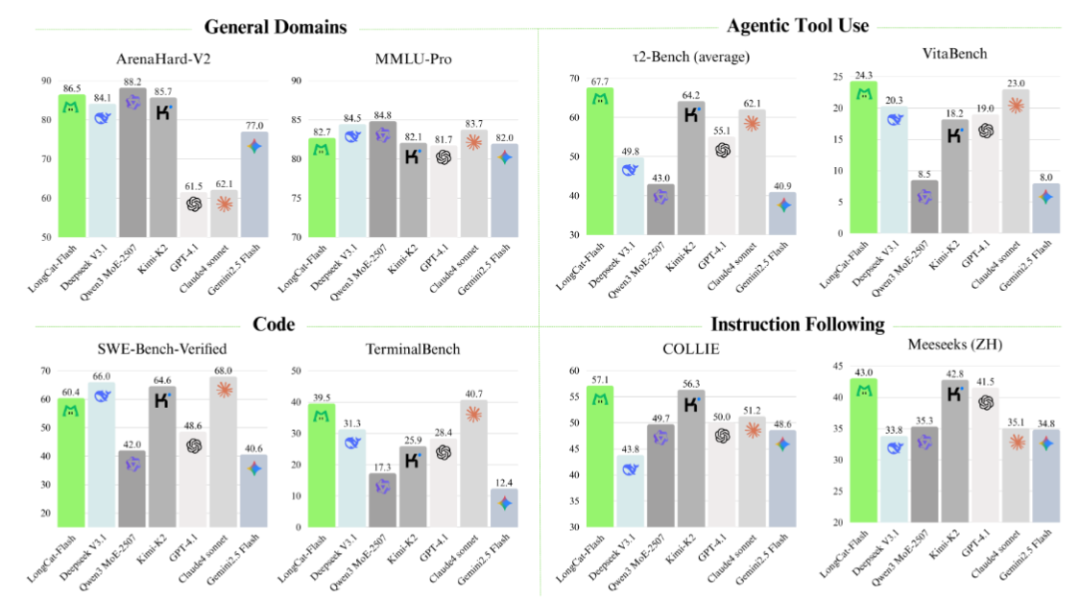
这两项技术的结合,让"闪电龙猫"展现出惊人的效率:它能在30天内完成20万亿个词汇的训练,推理速度超过每秒100个词汇,而成本仅为每百万个输出词汇0.7美元。从"不管任务难易都全力运转"到"智能调配资源精准发力","闪电龙猫"的进化不仅让AI更高效、更经济,也为它在手机、智能设备等资源有限的场景中应用铺平了道路。未来,当我们享受着AI带来的便捷服务时,或许正是这只聪明的"闪电龙猫"在背后高效运转,用最合理的"力气",做最多的事。
参考:
LongCat Chat: https://longcat.ai
Hugging Face: https://huggingface.co/meituan-longcat
Github: https://github.com/meituan-longcat
更多内容,请关注公众号“快乐王子AI说”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)