golang教程笔记
第一个go程序package mainimport "fmt"func main() { // notice { 不能在单独的行上fmt.Println("Hello," + " World!")//当语句不在一行时 不需要行分隔符;go语言连接符为+}运行和编译方法1:编译二进制文件执行$ go build hello.go //命令行$ ./hello//命令行Hello, World! //
性能与优点、不足介绍

- go的性能很好!原生语法支持并发(实现起来很简单)
- 而且项目能编译成一个可执行文件,部署起来方便!
缺点
- 包管理 大部分包在github上。这种方式稳定性不好 毕竟github可能是私有仓库 某天突然删了
- 所有的Exception都用error来处理,比较有争议。
java 的error是jvm级别 会直接导致jvm停止运行 所以go和java是两个极端 go只有error java都是exception
第一个go程序
package main //package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。
import "fmt" //基本函数包
func main() { // notice { 不能在单独的行上
fmt.Println("Hello," + " World!")
//1 当两句代码不在一行时 不需要行分隔符“;”
//2 go语言连接符为+
//3 go的调用方式也类似java类的写法 点号
}
运行和编译
方法1:编译二进制文件执行
$ go build hello.go //命令行 或者直接go build
$ ./hello //命令行
Hello, World! //结果
方法2:
$ go run hello.go
第一行代码 package main 定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。
下一行的 import “fmt” 告诉 Go 编译器这个程序需要使用 fmt 包(的函数,或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。
再下一行 func main() 是程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)。
封装: 当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 protected )。
输入与输出
输出
fmt.Println("gA=",gA,",gB=",gB) //还能这样
fmt.Printin("gc=",gc)
%T是类型输出
Printf、Sprintf和Fprintf的区别
Printf、Sprintf和Fprintf是Go语言中用于格式化输出的三个函数,它们的主要区别在于输出目标和使用场景不同。
Printf:
功能:将格式化后的字符串输出到标准输出(通常是控制台)。
使用场景:适用于需要在控制台输出格式化文本的场景。
示例代码:
package main
import "fmt"
func main() {
name := "张三"
age := 25
fmt.Printf("我的名字是%s,今年%d岁。\n", name, age)
}
Sprintf:
功能:将格式化后的字符串返回为一个字符串,而不是输出到控制台。
使用场景:适用于需要构建字符串而不是直接输出的场景,可以将格式化后的字符串赋值给一个变量,以便后续处理。
示例代码:
package main
import "fmt"
func main() {
name := "李四"
age := 30
message := fmt.Sprintf("我的名字是%s,今年%d岁。", name, age)
fmt.Println(message)
}
Fprintf:
功能:将格式化后的字符串输出到指定的io.Writer接口实现对象中,最常见的用法是将内容写入文件。
使用场景:适用于需要将格式化输出写入文件或其他io.Writer接口实现的场景。
示例代码:
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Create("output.txt")
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
fmt.Fprintf(file, "这是一条测试信息。\n")
}
打印结构体
简单结构体的打印
在Golang中有原生的 fmt 格式化工具去打印结构体,可以通过占位符%v、%+v、%#v去实现,这3种的区别如下所示:
package main
import (
"fmt"
)
type User struct {
Name string
Age int
}
func main() {
user := User{
Name: "张三",
Age: 95,
}
//or user := User{"Alice", 30}
fmt.Println(user) //打印结果 {张三 95}
////Println等同于这个%v的
fmt.Printf("%v\n", user) //打印结果 {张三 95}
fmt.Printf("%+v\n", user) //打印结果 {Name:张三 Age:95}
fmt.Printf("%#v\n", user) //打印结果 main.User{Name:"张三", Age:95}
}
其中的区别:
%v占位符是不会打印结构体字段名称的,字段之间以空格隔开;%+v占位符会打印字段名称,字段之间也是以空格隔开;%+v 会递归打印所有嵌套结构体的字段名和值。%#v占位符则会打印结构体类型和字段名称,字段之间以逗号分隔
复杂结构体的打印
当结构体中的字段是指针类型时,用占位符直接打印出来的是怎样的呢?
package main
import "fmt"
type Cat struct {
Name string
Age int
}
type Dog struct {
Name string
Age int
}
type Man struct {
Age int
sex string
}
type User struct {
Name string
Man
Cat Cat
Dog *Dog
}
func main() {
dog := Dog{
Name: "旺财",
Age: 2,
}
cat := Cat{"二猫", 2}
man := Man{18, "男"}
user := User{
Name: "张三",
Man: man,
Cat: cat,
Dog: &dog,
}
fmt.Println(user)
//{张三 {18 男} {二猫 2} 0xc0001a0000}
fmt.Printf("%v\n", user)
//{张三 {18 男} {二猫 2} 0xc0001a0000}
fmt.Printf("%+v\n", user)
//{Name:张三 Man:{Age:18 sex:男} Cat:{Name:二猫 Age:2} Dog:0xc0001a0000}
fmt.Printf("%#v\n", user)
//main.User{Name:"张三", Man:main.Man{Age:18, sex:"男"}, Cat:main.Cat{Name:"二猫", Age:2}, Dog:(*main.Dog)(0xc0001a0000)}
}
这时还能把所有值打印出来吗?
这时可以看到指针字段打印的不是Dog结构体内部的值,而是一个地址值。很显然,这个不是我们需要在日志中看到的,我们需要看的是结构体具体的值,那这个值又怎么打印呢?
方案一 转化为json格式 推荐
转换成 json 格式
package main
import (
"encoding/json"
"fmt"
)
type Cat struct {
Name string
Age int
}
type Dog struct {
Name string
Age int
}
type Man struct {
Age int
sex string
}
type User struct {
Name string
Man
Cat Cat
Dog *Dog
}
func main() {
dog := Dog{
Name: "旺财",
Age: 2,
}
cat := Cat{"二猫", 2}
man := Man{18, "男"}
user := User{
Name: "张三",
Man: man,
Cat: cat,
Dog: &dog,
}
byteUser, _ := json.Marshal(&user)
fmt.Println(string(byteUser))
}
打印结果如下所示,如果使用 json 库的话,是可以直接把结构体指针类型的具体值都打印出来的,比较方便:
{"Name":"张三","Age":18,"Cat":{"Name":"二猫","Age":2},"Dog":{"Name":"旺财","Age":2}}
发现不论是普通类型 还是指针都能打印出来
方案二 不推荐
为了简单 我们简化如下
type Dog struct {
Name string
Age int
}
type User struct {
Name string
Age int
Dog *Dog
}
func main() {
dog := Dog{
Name: "旺财",
Age: 2,
}
user := User{
Name: "张三",
Age: 95,
Dog: &dog,
}
fmt.Println(user)
fmt.Printf("%v\n", user)
fmt.Printf("%+v\n", user)
fmt.Printf("%#v\n", user)
}
实现 String() 或GoString() 方法
Golang 中的 fmt 包中有一个 Stringer 接口,接口中只有一个 String() 方法
// Stringer is implemented by any value that has a String method,
// which defines the ``native'' format for that value.
// The String method is used to print values passed as an operand
// to any format that accepts a string or to an unformatted printer
// such as Print.
type Stringer interface {
String() string
}
我们可以让 User 和 Dog 结构体分别实现 String() 方法,这种方法类似于 Java 中的 toString() 方法。基于前面的代码,我们增加如下 String() 方法实现:
func (d *Dog) String() string {
return "{\"name" + "\": \"" + d.Name + "\"," + "\"" + "age\": \"" + strconv.Itoa(d.Age) + "\"}"
}
func (u *User) String() string {
return "{\"name" + "\": \"" + u.Name + "\", \"" + "age\": \"" + strconv.Itoa(u.Age) + "\", \"dog\": " + u.Dog.String() + "}"
}
运行后,打印的结果如下所示:
{张三 95 {"name": "旺财","age": "2"}}
{Name:张三 Age:95 Dog:{"name": "旺财","age": "2"}}
main.User{Name:"张三", Age:95, Dog:(*main.Dog)(0xc000004078)}
发现,实现 String() 方法只对 %v 和 %+v 占位符有效,对于%#v 占位符,其打印的结构体指针类型还是一个地址值。
其实在 fmt 包中,Stringer 接口 下面,我们还可以看到另外一个 GoStringer 接口:
// GoStringer is implemented by any value that has a GoString method,
// which defines the Go syntax for that value.
// The GoString method is used to print values passed as an operand
// to a %#v format.
type GoStringer interface {
GoString() string
}
The GoString method is used to print values passed as an operand to a %#v format. (GoString 方法用于打印作为操作数传递给 %#v 格式的值)
找到了,我们再实现 GoString() 方法,就可以用 %#v 占位符打印结构体指针类型中的值了。
基于之前代码增加如下代码:
func (d *Dog) GoString() string {
return "{\"name" + "\": \"" + d.Name + "\"," + "\"" + "age\": \"" + strconv.Itoa(d.Age) + "\"}"
}
func (u *User) GoString() string {
return "{\"name" + "\": \"" + u.Name + "\", \"" + "age\": \"" + strconv.Itoa(u.Age) + "\", \"dog\": " + u.Dog.String() + "}"
}
运行后,打印结果如下所示,这下子就都可以打印了:
{张三 95 {"name": "旺财","age": "2"}}
{Name:张三 Age:95 Dog:{"name": "旺财","age": "2"}}
main.User{Name:"张三", Age:95, Dog:{"name": "旺财","age": "2"}}
到这里,我感觉这种方案有点麻烦呢,还有没有其他不用维护 String() 或 GoString() 的方法呢?
方法3 go-spew库 强烈推荐
直接安装一个专门用于深度打印结构体的库(适合调试场景):
安装库:
go get github.com/davecgh/go-spew/spew
import "github.com/davecgh/go-spew/spew"
func main() {
// ...(结构体定义和初始化同上)
spew.Dump(user) // 一行代码直接输出所有内容(包括指针解引用)
}
(main.User) {
Name: (string) "张三",
Man: (main.Man) {
Age: (int) 18,
Gender: (string) "男"
},
Cat: (main.Cat) {
Name: (string) "二猫",
Age: (int) 2
},
Dog: (*main.Dog)(0xc00000c080)({
Name: (string) "旺财",
Age: (int) 2
})
}
方法4 原生方案:强制转换为 interface{} + %#v
如果不想用第三方库,可以用 fmt 包 + 类型断言:
func main() {
// ...(结构体定义和初始化同上)
fmt.Printf("User完整内容:\n%#v\n", user)
if user.Dog != nil {
fmt.Printf("Dog内容:\n%#v\n", *user.Dog)
}
}
输出:
User完整内容:
main.User{Name:"张三", Man:main.Man{Age:18, Gender:"男"}, Cat:main.Cat{Name:"二猫", Age:2}, Dog:(*main.Dog)(0xc00000c080)}
Dog内容:
main.Dog{Name:"旺财", Age:2}
缺点:
需要手动处理指针解引用
嵌套结构体的指针不会自动展开
变量类型和申明
var identifier type 如:var a int
var b, c int = 1, 2 //bc都是int
也可自动判断类型 var v_name = value
var d = true //这种方式只能用于函数体内 即不能用于全局变量!
还可以使用:=
i := 1
多变量申明
如:vname1, vname2, vname3 := v1, v2, v3//可套用上面其他两种方法,用,分开即可
默认值
- 数值类型(包括complex64/128)为 0
- 布尔类型为 false
- 字符串为 “”(空字符串)
以下几种类型为 nil:
var a *int
var a []int
var a map[string] int
var a chan int
var a func(string) int
var a error // error 是接口
简单来说 就是除了基本类型,即 数字 字符串 布尔 , 其他都为nil
值类型和引用类型
所有像 int、float、bool 和 string 这些基本类型都属于值类型,使用这些类型的变量直接指向存在内存中的值:
数值类型的=是拷贝,引用类型的=是地址被复制
你可以通过 &i 来获取变量 i 的内存地址
string
关于字符串连接,下面语法正确的是
A. str := 'abc' + '123'
B. str := "abc" + "123"
C. str := '123' + "abc"
D. fmt.Sprintf("abc%d", 123)
答案:BD
作者:大叔说码
链接:https://juejin.cn/post/6923477800041054221
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
类型转换
普通类型转化
var a int8 = 6
var b int16 = 12
var c = int16(a) + b
fmt.Printf("整形间的数值运算,值:%v --- 类型%T \n", c, c)
var sum int = 17
var count int = 5
var mean float32
mean = float32(sum)/float32(count)
这里其实有点点奇怪 因为go是类型写后面的
所以应该是xxx.(string) 而非(string)xxx ?
而且断言那里就是后置
所以此处应该将int()看成一个函数吧
而断言是不知道原本的类型,推测出一个
然后比如string转int啥的 就比较特殊了 需要用其他包
断言(*interface的转化)
interface的转化比较特殊
将其他类型转化为interface
x := interface{}("test")//这种语法后面会讲
interface转其他类型
用到的断言 具体看后面 比如
x:= a.(int)
另一篇会更详细的讲断言
局部变量一旦申明必须被使用
如果你声明了一个局部变量却没有在相同的代码块中使用它,同样会得到编译错误,例如下面这个例子当中的变量 a:
func main() {
var a string = "abc"
fmt.Println("hello, world")
}
但是可以在全局变量中使用它
交换变量与_
如果你想要交换两个变量的值,则可以简单地使用 a, b = b, a,两个变量的类型必须是相同。
空白标识符 _ 也被用于抛弃值,如值 5 在:_, b = 5, 7 中被抛弃。
真实含义是代表你不关心它,比如range循环 你可能不关心value是多少
tips 所以一些暂时的中间变量 可以用_开头表示它是临时变量 而不用自己想其他名字 比如sql1 sql2 , 比如_xiaoming=funname(xxx);xiaoming = func2(_xiaoming)
常量申明
显式类型定义: const b string = "abc"
隐式类型定义: const b = "abc"
iota—只能和const一起使用
应用场景 比如写错误码 或者用const写枚举类型,iota就很方便了
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;
package main
import "fmt"
func main() {
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
)
fmt.Println(a,b,c,d,e,f,g,h,i)
}
条件判断与循环
Go 没有三目运算符,所以不支持 ?: 形式的条件判断。
对于强类型语言 这个好像也不是这么重要?
if
if语句,如
a:=10
if a < 20 {
xxx
}
注意:
即使只有一个语句 也必须加中括号
也可在if中赋值
if a:=10,a < 20 { //这个的真正作用是a:=xxxfun(m) a的值是不确定的 常用于err和下面的map
xxx
}
注意 go中不能像其他语言那样 if(a)(a是int类型)的判断
//注意是map struct没有这种ok的操作
val, ok := map[key] //如果key在map里 val 被赋值map[key] ,ok 是true 否则val得到相应类型的零值;ok是false
//常用写法
if val, ok := map[key]; ok {
//do something here
}
else if 和else
如果有else 要紧接着写
else if 而非 elseif
if a < 20 {
xxx
}else if a>30{
yyy
}else{
zzz
}
for
和 C 语言的 for 一样:
for init; condition; post { } //初值;循环控制条件;赋值增量或减量
和 C 的 while 一样:
for condition { }
和 C 的 for(;;) 一样:
for { }
init: 一般为赋值表达式,给控制变量赋初值;
condition: 关系表达式或逻辑表达式,循环控制条件;
post: 一般为赋值表达式,给控制变量增量或减量。
for-range
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。格式如下:
for key, value := range oldMap { //依然要写for
newMap[key] = value
}
这个没php的foreach简洁==
实际用了多返回值语法
for range的坑
首先 这些坑大多数是go1.22之前(<1.22)的版本,如果你的go是1.22以及之后就不太会遇到了
主要是涉及指针的时候
arr := [2]int{1, 2}
res := []*int{}
for _, v := range arr {
res = append(res, &v)
}
//expect: 1 2 //but output: 2 2
fmt.Println(*res[0],*res[1])
这个是由于v是一个只声明了一次的局部变量,所以它每次的地址都是相同的,只是每次修改了它的值
修改方案两种:
1、通过arr[k]获取值,而不是v。
2、使用一个局部变量,每次重新定义与初始化(go可以):tmp :=v,之后对tmp处理。
比如
func main() {
arr := [2]int{1, 2}
res := []*int{}
for _, v := range arr {
v :=v //也可写成 tmp:=v
res = append(res, &v)
}
fmt.Println(*res[0],*res[1])
}
这是 Go 面试里经常出现的题目,结合 goroutine 更风骚,毕竟还会存在乱序执行等问题。
var prints []func()
for _, v := range []int{1, 2, 3} {
prints = append(prints, func() { fmt.Println(v) })
}
for _, print := range prints {
print()
}
这段程序的输出结果是什么?没有 & 取地址符,是输出 1,2,3 吗?
结果程序一运行,输出结果是 3,3,3。这又是为什么?
问题的重点之一:关注到闭包函数,实际上所有闭包都打印的是相同的 v,也就是输出 3,原因是在 for 循环结束后,最后 v 的值被设置为了 3,仅此而已。
如果想要达到预期的效果,依然是使用万能的再赋值。改写后的代码如下:
for _, v := range []int{1, 2, 3} {
v := v
prints = append(prints, func() { fmt.Println(v) })
}
增加 v := v 语句,程序输出结果为 1,2,3。仔细翻翻你写过的 Go 工程,是不是都很熟悉?就这改造方法,赢了。
还有类似
func fr1() {
arr := []int{1, 2, 3}
for _, val := range arr {
go func() {
time.Sleep(time.Millisecond * 100)
fmt.Println(val)
}()
time.Sleep(time.Second)
}
}
// 输出结果:3 3 3
func fr1() {
values := []int{1, 2, 3, 4, 5}
for _, val := range values {
// 在这加入临时变量
val := val
go func() {
time.Sleep(time.Millisecond * 100)
fmt.Println(val)
}()
time.Sleep(time.Second)
}
}
// 输出结果:2 3 1 4 5 或 5 3 4 1 2 等无序结果 因为协程执行无序
尤其是配合上 Goroutine 的写法,很多同学会更容易在此翻车。
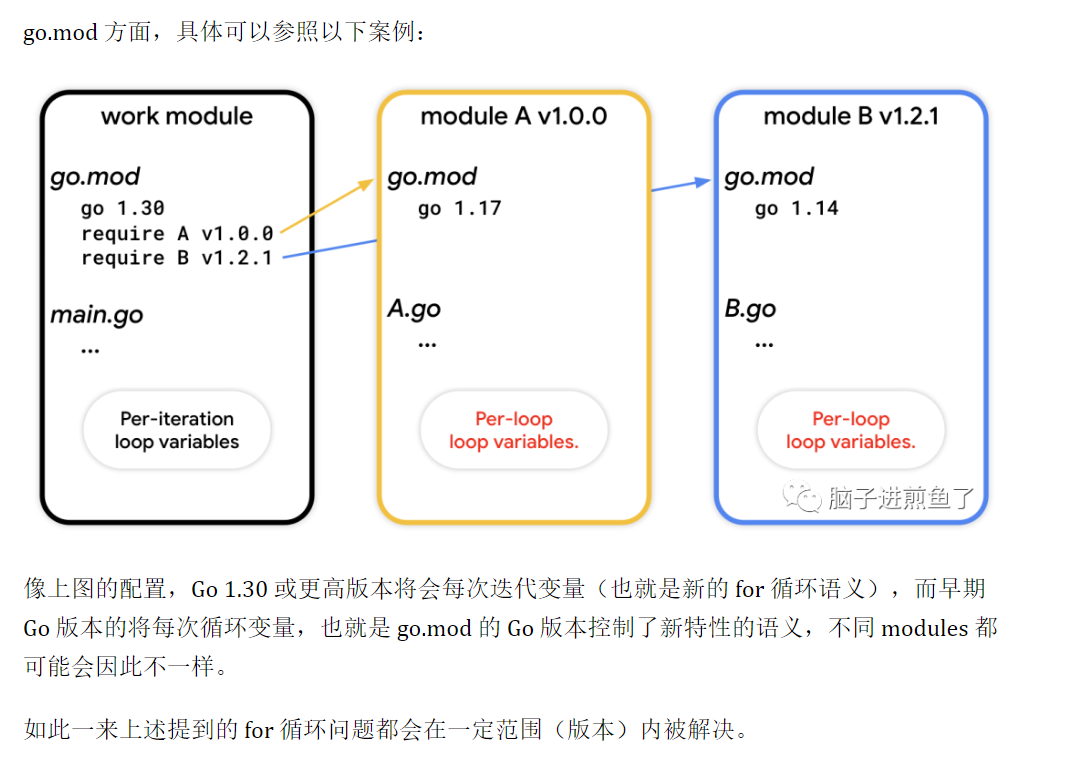
而go在1.22以及之后的版本。 每次都是重新定义 也就是类似上面会自动v := v
go1.21的比较特殊,我们可以开启 GOEXPERIMENT=loopvar 来构建 Go 程序,来体验上面提到的 for 循环变量的问题。比如GOEXPERIMENT=loopvar go build my/program
go 1.22之后的版本实际上是自动加上了这个选项
switch- case
func main(){
x:=2
switch x{
case 1:
fmt.println("x 等于 1");
case 2:
fmt.println("x 等于 2");
case 3:
fmt.println("x 等于 3");
}
}
func main(){
day:="Tuesday"
switch day{
case "Mondey","Tuesday","Wednesday":
fmt.Println("这是工作日")
case "Saturday","Sunday":
fmt.Println("这是周末")
default:
fmt.Println("无效的天数")
}
}
- 不指定表达式的 switch
Go中的switch可以省略表达式,直接用作条件分支判断,这类似于多层if-else。
package main
import "fmt"
func main(){
x:=1
switch{
case x > 0:
fmt.Println("正数")
case x < 0:
fmt.Println("负数")
default:
fmt.Println("0")
}
}
select-case语法
更多看并发原语 chan那篇单独的文章
select 语句只用于通道
会监听所有指定的通道上的操作
- 一旦其中一个通道准备好(发送值或者接受值成功)就会执行相应的代码块。
- 如果多个通道都准备好,那么 select 语句会随机选择一个通道执行。
- 如果所有通道都没有准备好,那么执行 default 块中的代码。
- 如果没有default快,且通道都没准备好,那么整个select会阻塞
和switch-case的区别在于
- select是用于通道的
- switch是顺序判断
- select可能会阻塞
函数
ps 函数可以有返回值 但是你不接受它 比如fmt.Printlnt
基本格式
go语言至少需要一个main函数
和类型定义不一样 这里func写在前面 标记是函数 返回值类型写后面
func function_name( [parameter list] ) [return_types] {
函数体
}
//如
func max(num1, num2 int) int {
}
func main() {
var a int = 100
var b int = 200
var ret int
/* 调用函数并返回最大值 */
ret = max(a, b)
fmt.Printf( "最大值是 : %d\n", ret )
}
参数默认值
在 Go 语言中,函数参数默认值的概念与某些其他编程语言(如 Python)略有不同。Go 语言本身不支持在函数定义中直接为参数设置默认值,这与 Python 或 Java 等语言不同。不过,你可以通过一些方式模拟出来
详细看另一篇专门的博客
函数返回多个值
类似php的list方法 其实很好实现
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("Google", "Runoob") //这里也能自动推断
fmt.Println(a, b)
}
//返回多个返回值,有形参名称的
func foo3(a string,b int)(rl int, r2 int){
fmt.Println("---- foo3")
fmt.Println("a=,a)
fmt.Println("b =",b)
r1 = 1000
r2=2000
return
}
这里的返回 只是简便写法 函数外部依然看不到r1 r2
返回值定义的时候命名
func main() {
fmt.Println(demo())
}
func demo() (a int) {
return 1
}
打印出1
func main() {
fmt.Println(demo())
}
func demo() (a int) {
return
}
打印出0
可变参数
在 Go 语言中,可变参数(Variadic Parameters) 允许函数接受不固定数量的参数。通过使用 … 语法,可以将参数声明为可变长度。以下是实现可变参数的详细方法:
1. 基本语法
在函数定义时,在参数类型前添加 … 前缀,表示该参数是可变参数:
func functionName(param ...Type) {
// param 是一个切片(slice),包含所有传入的参数
}
示例:
func sum(nums ...int) int {
total := 0
for _, num := range nums { //可以用range语法
total += num
}
return total
}
// 调用
result := sum(1, 2, 3) // 输出 6
2. 可变参数的本质
可变参数在函数内部会被转换为切片(slice)。因此,可以像操作普通切片一样处理可变参数:
func printStrings(strs ...string) {
for i, s := range strs {
fmt.Printf("第%d个参数: %s\n", i, s)
}
}
// 调用
printStrings("Hello", "World", "Go")
3. 传递切片给可变参数
如果已经有一个切片,可以使用 slice… 语法将其展开为可变参数:
nums := []int{1, 2, 3}
result := sum(nums...) // 等同于 sum(1, 2, 3) 注意 要加三个点
4. 混合普通参数与可变参数
可变参数必须放在参数列表的最后,且一个函数只能有一个可变参数:
func join(sep string, strs ...string) string {
return strings.Join(strs, sep)
}
// 调用
s := join("-", "a", "b", "c") // 输出 "a-b-c"
5. 处理不同类型的参数
如果希望接受任意类型的参数,可以使用 interface{} 类型,但需要手动处理类型断言:
func printAll(args ...interface{}) {
for _, arg := range args {
switch v := arg.(type) {
case int:
fmt.Println("整数:", v)
case string:
fmt.Println("字符串:", v)
default:
fmt.Println("未知类型:", v)
}
}
}
// 调用
printAll(42, "Go", 3.14)
匿名函数与闭包
在看这里之前 先看另一篇专门讲匿名函数与闭包的文章
下面更多是语法角度
简单的匿名函数调用
package main
import "fmt"
func main() {
// 定义并立即调用匿名函数
func(x int) {
fmt.Println("Hello", x)
}(10) // 传递参数10给匿名函数
}
将匿名函数赋值给变量
package main
import "fmt"
func main() {
// 将匿名函数赋值给变量
greeting := func(name string) {
fmt.Println("Hello", name)
}
greeting("World") // 调用变量greeting作为函数
}
为什么要这样呢?举个例子
var bytePool = sync.Pool{
// 为 sync.Pool 的 New 字段赋值一个函数
New: func() interface{} { //一个无参数、返回 interface{} 的函数
return make([]byte, 1024)
},
}
1、如果我们还要再给匿名函数赋个名字,那就有new和函数名两个了,但是后者显然没必要
2、new字段是有必要的 首先它是一个标识符,其次 我们需要一个字段承接这个函数,否则怎么传参呢?所以这就是函数变量化的意义
为什么要这么写 还有一个原因 看php匿名函数为什么要有名字那里
使用匿名函数作为高阶函数的参数
package main
import "fmt"
func process(f func(int, int) int, a, b int) int {
return f(a, b)
}
func main() {
// 使用匿名函数作为process函数的参数
result := process(func(x, y int) int {
return x + y // 返回x和y的和
}, 5, 3)
fmt.Println("Result:", result) // 输出:Result: 8
}
package main
import (
"fmt"
"math"
)
func main(){
/* 声明函数变量 */
getSquareRoot := func(x float64) float64 {
return math.Sqrt(x)
}
/* 使用函数 */
fmt.Println(getSquareRoot(9))//或者直接在里面写函数定义 不用新取一个名字
}
闭包
看另一篇专门的文章
go的方法(类似面向对象的成员函数)
后面面向对象会进一步讲到
数据结构
进阶的数据结构 比如map的底层 看另一篇go数据结构的文章
数组(静态 指定长度)
其实记住这2种就够了
var balance [10] float32 //仅仅申明 后续可以用 balance[1]=1 来赋值
//三个点也可换成数字 手动指定长度
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
注意 这里是 var arr [10]int 而不要理解为 var arr[10] int
申明数组,如
var balance [10] float32
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果数组长度不确定,可以使用 … 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
或
balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 0 和 2 的元素初始化
balance := [5]float32{0:2.0,2:7.0}
切片与数组的语法区别在于长度的指定!数组长度不可变
切片虽然长度可变 但是还是要申明初始长度 要通过这种语法 arr := make([]int, 3, 4) //创建一个长度为3,容量为4的切片 其中 容量可以不写 但是初始长度是一定要写的
除非这样 var slice []int // 创建一个nil切片的零值
func maxSubArray(nums []int) int {//这里没问题
nums_len := len(nums)
var dp [nums_len]int //这里有问题
}
这样是不行的 因为
var dp [nums_len]int 试图用变量nums_len声明数组长度,这不符合Go语言数组的定义规则8
Go的数组是值类型,长度是类型的一部分,必须在编译时确定8
正确做法:
如果需要在运行时确定长度,应该使用切片(slice)而不是数组:
dp := make([]int, nums_len)
但是java可以这样
Slice语言切片(动态数组)
号称Java中的List怎么用,切片就怎么用
实际就是动态数组 长度不固定的数组)
深入理解看另一篇数据结构的文章
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用(比如函数传参等),Go 中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
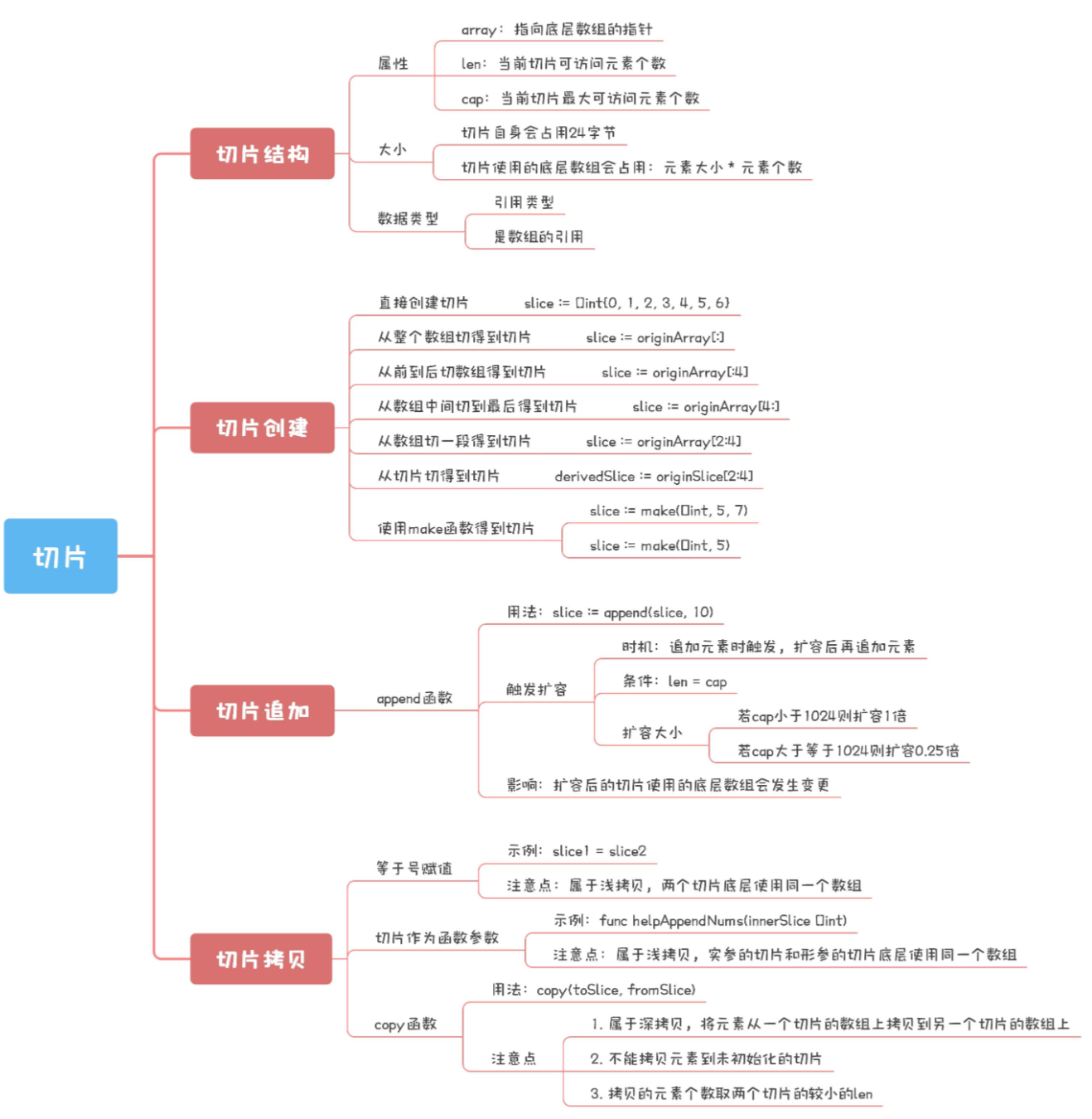
方法 :len、cap等
make的意思是“开辟内存空间” go中 可以不指定初始值 而先开辟一个内存空间给它“占位”
//声明slice1是一个切片,并且初始化,默认值是1,2,3。长度len是3
//slice1 :=[lint{1,2,3}
//声明slice1是一个切片,但是并没有给slice分配空间
//var slice1 []int
//slice1= make([]int,3)//开辟3个空间 ,默认值是0
//声明slice1是一个切片,同时给slice分配空间,3个空间,初始化值是0
var slicel []lint=make([]int,3)
[]int 解释
- []代表是一个数组
- int代表里面的元素是int
- 因为make不光可以创建切片 还可以map等 所以不能简化为 make(int,3)
//你可以声明一个未指定大小的数组来定义切片:
var identifier []type //!这里和普通数组那里的区别是,这里方括号李既没数字也没三个点!
//也可指定切片的length和容量
var slice1 []type = make([]T, length, capacity) //length 必须写 初始切片的长度 capacity可选 如果超过了capacity go会自动扩充一倍
// 如
var numbers = make([]int,3,5) //定义
追加元素
//向numbers切片追加一个元素2,numbers len=5,[0,0,0,1,2],cap=5
numbers =append(numbers,2)
fmt.Printf("len =%d,cap =%d, slice = &v\n",len(numbers),cap(numbers), numbers)
//向一个容量cap已经满的slice 追加元素,
numbers=append(numbers,3)
好像不能直接类似php那样 比如初始化是[0,1,2,3] 你直接访问未定义的比如test[5]会panic
遍历元素
len和cap函数
func main() {
var numbers = make([]int,3,5)
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
切片截取 用到的时候看https://www.w3cschool.cn/go/go-slice.html
一个实例:
/**
* Definition for a binary tree node.
* type TreeNode struct {//注意这里没有*
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func levelOrder(root *TreeNode) [][]int {
ret := [][]int{} //没有长度 没有三个点 这是一个切片 且为[]([]int{}) 外面是数组 里面是[]int{}
if root==nil{
return ret
}
//由于go有动态数组 所以不需要使用java的queue、list
queue := []*TreeNode{root}//定义一个切片 里面放的是*TreeNode指针类型 并用root初始化
for i := 0; len(queue) > 0; i++ {//和java不同 没有isEmpty方法 所以用普通循环的形式
this_level :=[]int{}
last_queue_size := len(queue)
for j:=0;j<last_queue_size;j++{
node := queue[j]
this_level = append(this_level, node.Val)//append
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
queue = queue[last_queue_size:]//使用这个模拟java的pop
ret = append(ret, this_level)
}
return ret;
}
Map集合
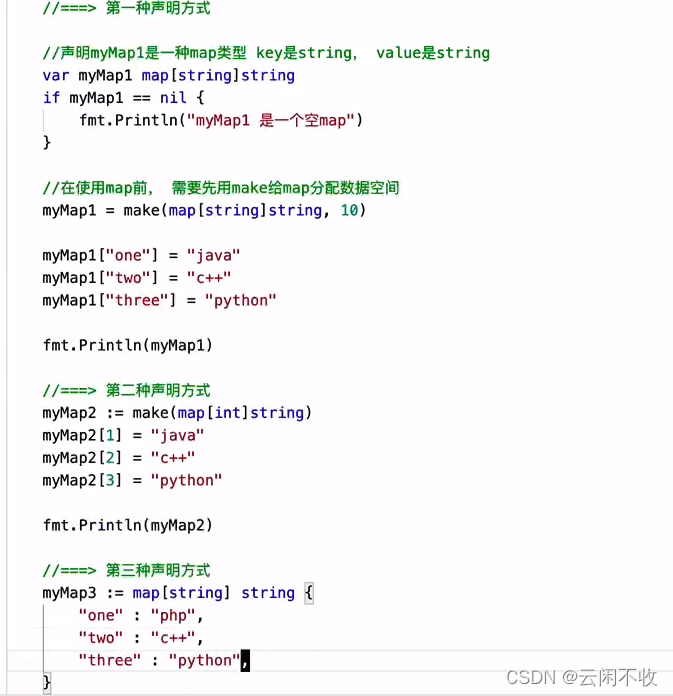
法一 用切片的形式
var countryCapitalMap map[string]string /*创建集合 */
countryCapitalMap = make(map[string]string) //正常是比如 []bool 这里中括号里的string规定的是 key
/* map插入key - value对,各个国家对应的首都 */
countryCapitalMap [ "France" ] = "巴黎"
countryCapitalMap [ "Italy" ] = "罗马"
countryCapitalMap [ "Japan" ] = "东京"
countryCapitalMap [ "India " ] = "新德里"
/*使用键输出地图值 */
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap [country])
}
法二
//{}代表“实例化 或者赋值”
countryCapitalMap := map[string]string{"France": "Paris", "Italy": "Rome", "Japan": "Tokyo", "India": "New delhi"}
使用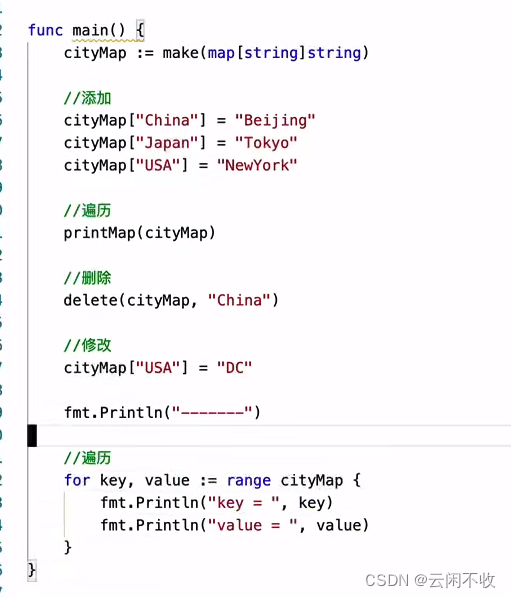
val, ok := map[key] //如果key在map里 val 被赋值map[key] ok 是true 否则val得到相应类型的零值;ok是false
//常用写法
if val, ok := map[key]; ok {
//do something here
}
注意这种写法 和python不同 python会强报错
注意和结构体的区别
- 定义的时候,结构体的实例化key不用双引号
- 使用的时候 map是 variablename[“keyname”]的形式 结构体是 variable.field的形式
指针
避免大型结构体的复制,提高效率:当结构体较大时,按值传递会导致整个结构体在每次方法调用时被复制,这可能会消耗较多的内存和时间。使用指针传递只需要复制指针的值(通常是一个较小的内存地址),而不是结构体本身,从而提高性能。特别是在需要频繁调用方法或结构体较大的情况下,使用指针可以显著减少性能开销1。

- 定义的时候
*是指针类型 理解为 p (*int) ,p是存放整性的内存地址; make(map[string]*User)这种也是定义int &a(c++)意思是定义一个引用//引用相当于指针再取值 他和被引用的变量都是表示同一块内存 而int a的意思是定义一个变量a
- 使用的时候,
&是对变量取地址,*是对指针取值
刚好相反
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
fmt.Printf("*ip 变量的值: %d\n", *ip )/* 在指针类型前面加上 * 号(前缀)来获取指针所指向的内容。 */
PS c++中不用&的方式
int swap1 (int &a,int &b){
int c;
c=a;
a=b;
b=c;
}
当一个指针被定义后没有分配到任何变量时,它的值为 nil。nil 指针也称为空指针。
一个指针变量通常缩写为 ptr。
var ptr *int
fmt.Printf("ptr 的值为 : %x\n", ptr )//这里输出的是0!
指向指针的指针
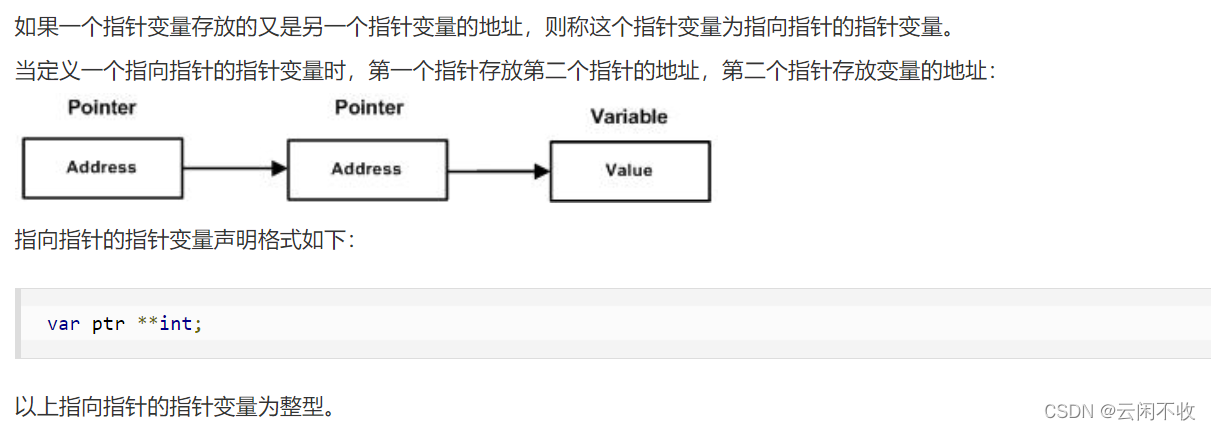
package main
import "fmt"
func main() {
var a int
var ptr *int
var pptr **int
a = 3000
/* 指针 ptr 地址 */
ptr = &a
/* 指向指针 ptr 地址 */
pptr = &ptr
/* 获取 pptr 的值 */
fmt.Printf("变量 a = %d\n", a )
fmt.Printf("指针变量 *ptr = %d\n", *ptr )
fmt.Printf("指向指针的指针变量 **pptr = %d\n", **pptr)
}
函数参数指针
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int= 200
swap(&a, &b);
}
func swap(x *int, y *int) {
var temp int
temp = *x /* 保存 x 地址的值 */
*x = *y /* 将 y 赋值给 x */
*y = temp /* 将 temp 赋值给 y */
}
ps 这种形式并不会造成都修改的都是一个"user" 因为首先 是对单次对话而言的 ,其次 user := &User 这个是个定义符 所以是新建 而非修改旧有的 而且User是一个结构体 需要实例化后才能用 而非对象
type User struct {
Name string
Addr string
C chan string
conn net.Conn
}
//创建一个用户的API
func NewUser(conn net.Conn) *User {
userAddr := conn.RemoteAddr().String()
user := &User{
Name: userAddr,
Addr: userAddr,
C: make(chan string),
conn: conn,
}
//启动监听当前user channel消息的goroutine
go user.ListenMessage()//可以直接用指针.field 的形式调用
return user
}
结合srtuct 用指针和不用指针的区别 这一节看看
面向对象
结构体—对象
结构体可以看成是一种复杂的数据结构(由基本数据组成)
package main
import "fmt"
//这里的type是定义基础类型的意思 是为了后面用var Book1 Books 这种语法
type Books struct { //其实和变量的声明一样 type类似func var 后面是名字 在后面是类型
title string
author string
subject string
book_id int
}
func main() {
// 创建一个新的结构体 使用{}实例化
fmt.Println(Books{"Go 语言", "www.runoob.com", "Go 语言教程", 6495407})
// 也可以使用 key => value 格式
//注意这里和map的区别在于 map的key要用引号括起来
fmt.Println(Books{title: "Go 语言", author: "www.runoob.com", subject: "Go 语言教程", book_id: 6495407})
// 忽略的字段为响应对应的零值
fmt.Println(Books{title: "Go 语言", author: "www.runoob.com"})
}
{Go 语言 www.runoob.com Go 语言教程 6495407}
{Go 语言 www.runoob.com Go 语言教程 6495407}
{Go 语言 www.runoob.com 0}
也可用点的形式
func main() {
var Book1 Books //这里是var了!
var Book2 Books
/* book 1 描述 */
Book1.title = "Go 语言"
ps 结构体变量和结构体变量的指针都能访问变量
通过指针变量 p 访问其成员变量 name,有哪几种方式?
A. p.name
B. (&p).name
C. (*p).name
D. p->name
答案 A C
成员方法
Go 没有面向对象,而我们知道常见的 Java C++ 等语言中,实现类的方法做法都是编译器隐式的给函数加一个 this 指针,而在 Go 里,这个 this 指针需要明确的申明出来,其实和其它 OOP 语言并没有很大的区别。
package main
import (
"fmt"
)
/* 定义结构体 */
type Circle struct {
radius float64
}
func main() {
var c1 Circle
c1.radius = 10.00
fmt.Println("圆的面积 = ", c1.getArea())
}
//该 method 属于 Circle 类型对象中的方法
func (c Circle) getArea() float64 {
//c.radius 即为 Circle 类型对象中的属性
return 3.14 * c.radius * c.radius
}
所以 “结构体也就可以近似的看成类与对象”
struct可以比较么?
https://juejin.cn/post/6881912621616857102 看这里 大叔说码
TAG
类似java的注解
斜引号括起来 空格间隔 key不带双引号 value带引号

通过反射得到Tag信息,这个需要先看另一篇博客的反射是什么
由于go大写是public 所以对一些可能异常 要用tag规定导出格式,而且在这里 还能够实现类似数据表直接重命名,很方便
不加tag的时候,默认就是变量名
ps 成员变量名首字母必须大写才能使用json
package main
import (
"encoding/json"
"fmt"
)
func main() {
type Man struct {
name string
Age int
CarId int
}
man := Man{"小明", 30, 1}
byte, _ := json.Marshal(&man)
fmt.Println(string(byte)) //{"Age":30,"CarId":1}
}
发现Name没出来 因为外部不可见
类
golang的类就是结构体+绑定的方法
和普通函数的区别在于 func后面多了个括号。而且set方法是不管用的,因为go对待结构体是值复制传递。所以set方法要用指针
这里不写this 好像随便写啥都是可以的 只是一个名字
但是 golang官方好像不推荐 用me this 或者self 作为方法接收者
srtuct 用指针和不用指针的区别
类方法是否带指针
package main
import (
"fmt"
)
type Employee struct {
id string
name string
}
func (e Employee) SetName(name string) { // removed * in this line
e.name = name
}
func main() {
emp1 := Employee{
id: "E1",
name: "Shashank",
}
emp1.SetName("Vivek")
fmt.Println(emp1.name) //output:Shashank 发现没有改变
emp1.name = "Vivek"
fmt.Println(emp1.name) //output:Vivek 这倒是可以改变
}
因为值传递 所以发现并没有改变 那我我们将Employee改为指针呢
package main
import (
"fmt"
)
type Employee struct {
id string
name string
}
func (e Employee) SetName(name string) { // removed * in this line
e.name = name
}
func main() {
emp1 := &Employee{ //这里emp1是一个地址
id: "E1",
name: "Shashank",
}
emp1.SetName("Vivek")
fmt.Println(emp1.name) //output:Shashank 而且我们发现,地址.name也能够打印出来
emp1.name = "Vivek"
fmt.Println(emp1.name) //output:Vivek
}
无论对象是指针还是实变量 对象.属性都能够访问到值
可以看到 实例化的时候 改为指针 但是 依然和之前一样无法改变
package main
import (
"fmt"
)
type Employee struct {
id string
name string
}
//参数改为了指针
func (e *Employee) SetName(name string) {
e.name = name
}
func main() {
emp1 := &Employee{
id: "E1",
name: "Shashank",
}
emp1.SetName("Vivek")
fmt.Println(emp1.name)//ouput Vivek
}
改为指针后 就可以了 我们也可以在结构体中就改为指针
使用指针传递结构体可以避免大型结构体的复制,提高效率:当结构体较大时,按值传递会导致整个结构体在每次方法调用时被复制,这可能会消耗较多的内存和时间。使用指针传递只需要复制指针的值(通常是一个较小的内存地址),而不是结构体本身,从而提高性能。特别是在需要频繁调用方法或结构体较大的情况下,使用指针可以显著减少性能开销1。
新问题 那为什么有的struct 内部的属性 要定义为struct呢 因为nil
如果是值传递结构体 那么就是结构体内部的属性为初值(可能有零的出现)而指针的话 没定义就是整个内部结构体为nil 避免一些没定义的属性出现?(因为初始化的0不是我们想要的),还有上面提到的内部结构体(内部结构体也是指针)用指针 在进行一些运算的时候 用指针传递也可以节省资源?
结构体内部结构体带指针区别
package main
import (
"encoding/json"
"fmt"
)
type Man struct {
Name string
Age int
}
type Company struct {
Name string
Employees Man
}
func main() {
employee := Man{
Name: "修改前",
Age: 30,
}
company := Company{
Name: "ACME Inc.",
Employees: employee,
}
employee.Name = "修改后"
employee.Age = 35
bytecompany, _ := json.Marshal(&company)
byteemployee, _ := json.Marshal(&employee)
fmt.Println(string(bytecompany))
fmt.Println(string(byteemployee))
/*
OUTPUT:
{"Name":"ACME Inc.","Employees":{"Name":"修改前","Age":30}}
{"Name":"修改后","Age":35}
*/
}
可以看到没修改成功
package main
import (
"encoding/json"
"fmt"
)
type Man struct {
Name string
Age int
}
type Company struct {
Name string
Employees Man
}
func main() {
employee := Man{
Name: "修改前",
Age: 30,
}
company := Company{
Name: "ACME Inc.",
Employees: employee,
}
company.Employees.Name = "修改后"
company.Employees.Age = 35
bytecompany, _ := json.Marshal(&company)
byteemployee, _ := json.Marshal(&employee)
fmt.Println(string(bytecompany))
fmt.Println(string(byteemployee))
/*
OUTPUT:
{"Name":"ACME Inc.","Employees":{"Name":"修改后","Age":35}}
{"Name":"修改前","Age":30}
*/
}
可以看到 虽然成功了 但是employ没改 但是 如果我们有时候想要保持一致呢?
package main
import (
"encoding/json"
"fmt"
)
type Man struct {
Name string
Age int
}
type Company struct {
Name string
Employees *Man
}
func main() {
employee := Man{
Name: "修改前",
Age: 30,
}
company := Company{
Name: "ACME Inc.",
Employees: &employee,
}
//这种方式也是一样的
//company.Employees.Name = "修改后"
//company.Employees.Age = 35
employee.Name = "修改后"
employee.Age = 35
bytecompany, _ := json.Marshal(&company)
byteemployee, _ := json.Marshal(&employee)
fmt.Println(string(bytecompany))
fmt.Println(string(byteemployee))
/*
OUTPUT:
{"Name":"ACME Inc.","Employees":{"Name":"修改后","Age":35}}
{"Name":"修改后","Age":35}
*/
}
可以看到区别了
继承
注意这个语法区别,和level区别 Human是只有类型 没有变量名的

接口
接口的实质是指针
接口和之前继承不一样,只要你实现了接口定义的所有方法 就相当于你实现了这个接口
type Phone interface {
call()
}
type NokiaPhone struct {
}
//func max(num1, num2 int) int 之前的函数定义是这样 这里是在前面括号李又多了
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func main() {
var phone Phone
phone = new(NokiaPhone)
phone.call()
phone = new(IPhone)
phone.call()
}

PS 结构体使用指针的原因是 这里没有用return 而上面的例子用了return 如果你想直接改变xx的值 那么就要用指针
接口可用作万能数据类型。以及断言判断类型。断言相当于java的instance of
另一篇具体讲到断言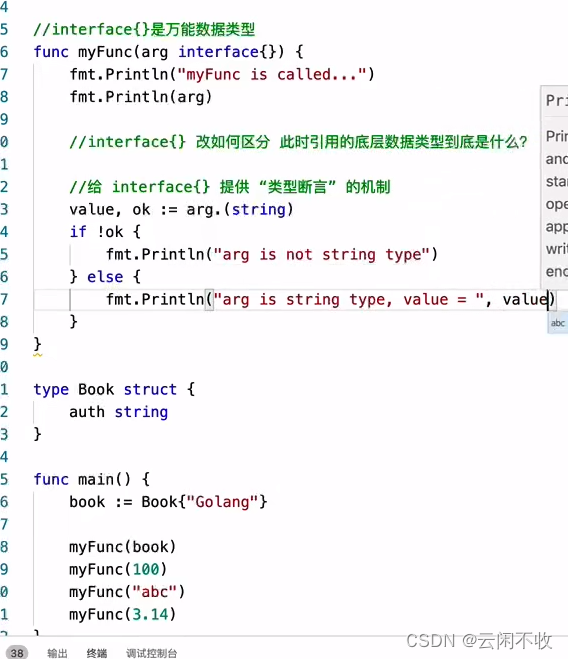
多态
go通过接口实现多态,例子同上
一个实例
var bytePool = sync.Pool{
// 为 sync.Pool 的 New 字段赋值一个函数
New: func() interface{} { //一个无参数、返回 interface{} 的函数
return make([]byte, 1024)
},
}
核心语法拆解
- New: 的含义
New 是 sync.Pool 结构体的一个字段,类型为 func() interface{}(一个无参数、返回 interface{} 的函数) - : 表示给这个字段赋值,类似键值对的语法
- func() interface{} { … } 的含义
- 定义一个匿名函数(没有函数名的函数)
- 这个函数的签名必须与 sync.Pool.New 字段要求的类型一致:
- 无参数 (())
- 返回 interface{}(空接口,可以表示任何类型)
- return make([]byte, 1024) 的含义
当这个函数被调用时,会创建一个新的 []byte 切片,长度为 1024 - 由于返回值是 interface{},Go 会自动将具体类型 []byte 转换为空接口类型
错误处理与异常 defer recover panic
defer recover panic 更详细的看 https://zhuanlan.zhihu.com/p/1021876002
error
Go 语言通过内置的错误接口提供了非常简单的错误处理机制。
(卫述语句)
_,err := errorDemo()
if err!=nil{
fmt.Println(err)
return
}
error类型是一个接口类型,这是它的定义:
type error interface {
Error() string
}
我们可以在编码中通过实现 error 接口类型来生成错误信息。
函数通常在最后的返回值中返回错误信息。使用errors.New 可返回一个错误信息:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// 实现
}
后面写代码的时候就可以
if a,err:=sqrt(1.1),err!=nil{
if err.Error() == "math: square root of negative number" {
//dosth
}
if err.Error() == "other define err" {
//dosth
}
}
panic
在 Go 中,error 表示一个错误,错误通常会返给调用方,交由调用方来决定如何处理。而 panic 则表示一个无法挽回的异常,panic 会直接终止当前执行的控制流。
panic 是一个内置函数,它会停止程序的正常控制流并输出 panic 相关信息。
有两种方式可以触发 panic
- 一种是非法操作导致运行时错误,比如访问数组索引越界,此时会触发运行时 panic。
- 另一种是主动调用 panic 函数。
当在函数 F 中调用了 panic 后,程序执行流程如下:
-
函数 F 调用 panic 时,F 的执行会被停止,接下来会执行 F 中调用 panic 之前的所有 defer 函数,然后 F 返回给调用者。
-
接着,对于 F 的调用方 G 的行为也类似于对 panic 的调用。
-
该过程继续向上返回,直到当前 goroutine 中的所有函数都返回,此时程序崩溃。
最后,你将在执行 Go 程序的控制台看到程序执行异常的堆栈信息。
panic 使用示例如下:
func f() {
defer fmt.Println("defer 1")
fmt.Println(1)
panic("woah")
defer fmt.Println("defer 2")
fmt.Println(2)
}
func main() {
f()
}
执行示例代码,得到输出如下:
$ go run main.go
1
defer 1
panic: woah
goroutine 1 [running]:
main.f()
/go/blog-go-example/error/defer-panic-recover/panic/main.go:10 +0xa0
main.main()
/go/blog-go-example/error/defer-panic-recover/panic/main.go:29 +0x1c
exit status 2
可以发现,panic 会输出异常堆栈信息。
并且 1 和 defer 1 都被输出了,而 2 和 defer 2 没有输出,说明 panic 调用之后的代码不会执行,但它不影响 panic 之前 defer 函数的执行。
此外,如果你足够细心,还可以发现 panic 后程序的退出码为 2。
子 Goroutine 中 panic
如果在子 goroutine 中发生 panic,也会导致主 goroutine 立即退出:
func g() {
fmt.Println("calling g")
// 子 goroutine 中发生 panic,主 goroutine 也会退出
go f(0)
fmt.Println("called g")
}
func f(i int) {
fmt.Println("panicking!")
panic(fmt.Sprintf("i=%v", i))
fmt.Println("printing in f", i) // 不会被执行
}
func main() {
g()
time.Sleep(10 * time.Second)
}
执行示例代码,程序并不会等待 10s 后才退出,而是立即 panic 并退出,得到输出如下:
$ go run main.go
calling g
called g
panicking!
panic: i=0
goroutine 3 [running]:
main.f(0x0)
/go/blog-go-example/error/defer-panic-recover/panic/main.go:25 +0xa0
created by main.g in goroutine 1
/go/blog-go-example/error/defer-panic-recover/panic/main.go:19 +0x5c
exit status 2
panic 和 os.Exit
虽然 panic 和 os.Exit 都能使程序终止并退出,但它们有着显著的区别,尤其在触发时的行为和对程序流程的影响上。
panic 用于在程序中出现异常情况时引发一个运行时错误,通常会导致程序崩溃(除非被 recover 恢复)。当触发 panic 时,defer 语句仍然会执行。panic 还会打印详细的堆栈信息,显示引发错误的调用链。panic 退出状态码固定为 2。
os.Exit 会立即终止程序,并返回指定的状态码给操作系统。当执行 os.Exit 时,defer 语句不会执行。os.Exit 直接通知操作系统退出程序,它不会返回给调用者,也不会引发运行时堆栈追踪,所以也就不会打印堆栈信息。os.Exit 可以设置程序退出状态码。
因为 panic 比较暴力,所以一般只建议在 main 函数中使用,比如应用的数据库初始化失败后直接 panic,因为程序无法连接数据库,程序继续执行意义不大。而普通函数中推荐尽量返回 error 而不是直接 panic。
不过 panic 也不是没有挽救的余地,recover 就是来恢复 panic 的。
recover
recover 也是一个函数,用来从 panic 所导致的程序崩溃中恢复执行。
在下面的讲述之前,我们要先提一下defer,defer是最后执行的意思,它会在函数return执行或者panic之前执行。如果有多个defer 会按照后进先出的顺序执行
详细看下一节
defer 在 panic 发生时仍然会执行,这意味着它可以用来拦截异常,防止程序直接崩溃。
但是这个执行顺序是 看到panic了 先将panic和参数压到栈中 然后再执行defer 等到defer执行完了 再真正panic 所以defer中panic能捕获
也就是先压栈
defer3
defer2
defer1
panic
然后再调用
使用
recover 使用示例如下:
func test() {
defer func() {
recover()
fmt.Println("被recover捕获了")
}()
fmt.Println(1)
panic("oh")
defer fmt.Println("defer 2")
fmt.Println(2)
}
func main() {
test()
}
执行示例代码,得到输出如下:
1
被recover捕获了
recover() 的调用捕获了 panic 触发的异常,并且程序正常退出。
注意,只在 defer 语句的函数体中再调用revover函数才有效,直接调用的话,只会返回 nil。
如下两种方式都是错误的用法:
recover()
defer recover()
可见,recover 必须与 defer 一同使用,来从 panic 中恢复程序。不过 panic 之后的代码依旧不会执行,recover() 调用后只会执行 defer 语句中的剩余代码。
下面这个例子将会捕获到 panic,并且输出 panic 信息:
func f() {
defer func() {
if r := recover(); r != nil {
fmt.Println("recover:", r)
}
}()
panic("woah")
}
执行示例代码,得到输出如下:
recover: woah
可以发现,recover 函数的返回值,正是 panic 函数的参数。
一般不要在 defer 中出现 panic
为了避免不必要的麻烦,defer 函数中最好不要有能够引起 panic 的代码。
正常来说,defer 用来释放资源,不会出现大量代码。如果 defer 函数中逻辑过多,则需要斟酌下有没有更优解。
如下示例将输出什么?
func f() {
defer func() {
if r := recover(); r != nil {
fmt.Println("recover:", r)
}
}()
defer func() {
panic("woah 1")
}()
panic("woah 2")
}
执行示例代码,得到输出如下:
recover: woah 1
看来,defer 中的 panic(“woah 1”) 覆盖了程序正常控制流中的 panic(“woah 2”)。
如果我们将代码顺序稍作修改:
func f() {
defer func() {
panic("woah 1")
}()
defer func() {
if r := recover(); r != nil {
fmt.Println("recover:", r)
}
}()
panic("woah 2")
}
执行示例代码,得到输出如下:
recover: woah 2
//下面是 panic("woah 1")的输出内容
panic: woah 1
goroutine 1 [running]:
main.f.func1()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:68 +0x2c
main.f()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:77 +0x68
main.main()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:142 +0x1c
exit status 2
看来,调用 recover 的 defer 应该放在函数的入口处,成为第一个 defer。
recover 只能捕获当前 Goroutine 中的 panic
需要额外注意的一点是,recover 只会捕获当前 goroutine 所触发的 panic。
在Go语言中,协程是相互独立的执行单元。当一个子协程发生panic时,它会在自己的执行栈中进行异常处理流程。通常情况下,外层协程无法直接捕获子协程的panic。
从执行流程角度看,每个协程就像是一个独立的小世界,当子协程出现panic,它会在自己的世界里按照panic的处理规则(如逆序执行defer函数)进行处理,这个过程不会自动和外层协程交互,使得外层协程不能简单地捕获子协程的panic。
示例如下:
func f() {
defer func() {
if r := recover(); r != nil {
fmt.Println("recover:", r)
}
}()
go func() {
panic("woah")
}()
time.Sleep(1 * time.Second)
}
执行示例代码,得到输出如下:
panic: woah
goroutine 18 [running]:
main.f.func2()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:91 +0x2c
created by main.f in goroutine 1
/go/blog-go-example/error/defer-panic-recover/recover/main.go:90 +0x40
exit status 2
子 goroutine 中触发的 panic 并没有被 recover 捕获。
所以,如果你认为代码中需要捕获 panic 时,就需要在每个 goroutine 中都执行 recover。
将 panic 转换成 error 返回
有时候,我们可能需要将 panic 转换成 error 并返回,防止当前函数调用他人提供的不可控代码时出现意外的 panic。
通过 defer + recover 捕获 panic,将其转换为 error 类型返回。
基础实现模板
func SafeFunc() (err error) {
defer func() {
if r := recover(); r != nil {
// 将 panic 转换为 error
err = convertPanicToError(r)
}
}()
// 可能触发 panic 的逻辑
riskyOperation()
return nil
}
func convertPanicToError(r interface{}) error {
if e, ok := r.(error); ok {
return e // 已经是 error 类型直接返回
}
return fmt.Errorf("panic recovered: %v", r) // 其他类型包裹为 error
}
完整案例演示
package main
import (
"errors"
"fmt"
)
func main() {
if result, err := SafeDivision(10, 0); err != nil {
fmt.Println("Error:", err) // Error: division by zero
} else {
fmt.Println("Result:", result)
}
if result, err := SafeDivision(10, 2); err != nil {
fmt.Println("Error:", err)
} else {
fmt.Println("Result:", result) // Result: 5
}
}
// 安全除法函数(将 panic 转为 error)
func SafeDivision(a, b int) (result int, err error) {
defer func() {
if r := recover(); r != nil {
err = WrapPanic(r)
}
}()
result = Divide(a, b) // 可能触发 panic 的调用
return
}
// 高风险函数(可能 panic)
func Divide(a, b int) int {
if b == 0 {
panic(errors.New("division by zero"))
}
return a / b
}
// 统一 panic 转换逻辑
func WrapPanic(r interface{}) error {
switch t := r.(type) {
case error:
return t
case string:
return errors.New(t)
default:
return fmt.Errorf("unexpected panic: %v", r)
}
}
实际案例
net/http 使用 recover 优雅处理 panic
我们在开发 HTTP Server 程序时,即使某个请求遇到了 panic 也不应该使整个程序退出。所以,就需要使用 recover 来处理 panic。
来看一个使用 net/http 创建的 HTTP Server 程序示例:
package main
import (
"fmt"
"log"
"net/http"
"os"
)
func handler(w http.ResponseWriter, r *http.Request) {
if r.URL.Path == "/panic" {
panic("url is error")
}
// 打印请求的路径
fmt.Fprintf(w, "Hello, you've requested: %s\n", r.URL.Path)
}
func main() {
// 创建一个日志实例,写到标准输出
logger := log.New(os.Stdout, "http: ", log.LstdFlags)
// 自定义 HTTP Server
server := &http.Server{
Addr: ":8080",
ErrorLog: logger, // 设置日志记录器
}
// 注册处理函数
http.HandleFunc("/", handler)
// 启动服务器
fmt.Println("Starting server on :8080")
if err := server.ListenAndServe(); err != nil {
logger.Println("Server failed to start:", err)
}
}
启动示例,程序会阻塞在这里等待请求进来:
$ go run main.go
Starting server on :8080
使用 curl 命令分别对 HTTP Server 发送三次请求:
$ curl localhost:8080
Hello, you've requested: /
$ curl localhost:8080/panic
curl: (52) Empty reply from server
$ curl localhost:8080/hello
Hello, you've requested: /hello
可以发现,在请求 /panic 路由时,HTTP Server 触发了 panic 并返回了空内容,然后第三个请求依然能够得到正确的响应。
可见 HTTP Server 并没有退出。
现在回去看一下执行 HTTP Server 的控制台日志:
Starting server on :8080
http: 2024/10/13 23:08:28 http: panic serving [::1]:50547: url is error
goroutine 34 [running]:
net/http.(*conn).serve.func1()
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/net/http/server.go:1947 +0xb0
panic({0x10114c000?, 0x1011a4ba8?})
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/runtime/panic.go:785 +0x124
main.handler({0x1011a8178?, 0x140001440e0?}, 0x1400010bb28?)
/workspace/projects/go/blog-go-example/error/defer-panic-recover/recover/http/main.go:12 +0x130
net/http.HandlerFunc.ServeHTTP(0x101348320?, {0x1011a8178?, 0x140001440e0?}, 0x1010999e4?)
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/net/http/server.go:2220 +0x38
net/http.(*ServeMux).ServeHTTP(0x0?, {0x1011a8178, 0x140001440e0}, 0x14000154140)
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/net/http/server.go:2747 +0x1b4
net/http.serverHandler.ServeHTTP({0x1400011ade0?}, {0x1011a8178?, 0x140001440e0?}, 0x6?)
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/net/http/server.go:3210 +0xbc
net/http.(*conn).serve(0x140000a4120, {0x1011a8678, 0x1400011acf0})
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/net/http/server.go:2092 +0x4fc
created by net/http.(*Server).Serve in goroutine 1
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/net/http/server.go:3360 +0x3dc
panic 信息 url is error 被输出了,并且打印了堆栈信息。
不过这 HTTP Server 依然在运行,并能提供服务。
这其实就是在 net/http 中使用了 recover 来处理 panic。
我们可以看下 http.Server.Serve 的源码:
func (srv *Server) Serve(l net.Listener) error {
...
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, err := l.Accept()
if err != nil {
...
return err
}
connCtx := ctx
if cc := srv.ConnContext; cc != nil {
connCtx = cc(connCtx, rw)
if connCtx == nil {
panic("ConnContext returned nil")
}
}
tempDelay = 0
c := srv.newConn(rw)
c.setState(c.rwc, StateNew, runHooks) // before Serve can return
go c.serve(connCtx)
}
}
可以发现,在 for 循环中,每接收到一个请求都会交给 go c.serve(connCtx) 开启一个新的 goroutine 来处理。
那么在 serve 方法中就一定会有 recover 语句:
// Serve a new connection.
func (c *conn) serve(ctx context.Context) {
if ra := c.rwc.RemoteAddr(); ra != nil {
c.remoteAddr = ra.String()
}
ctx = context.WithValue(ctx, LocalAddrContextKey, c.rwc.LocalAddr())
var inFlightResponse *response
defer func() {
if err := recover(); err != nil && err != ErrAbortHandler {
const size = 64 << 10
buf := make([]byte, size)
buf = buf[:runtime.Stack(buf, false)]
c.server.logf("http: panic serving %v: %v\n%s", c.remoteAddr, err, buf)
}
if inFlightResponse != nil {
inFlightResponse.cancelCtx()
inFlightResponse.disableWriteContinue()
}
if !c.hijacked() {
if inFlightResponse != nil {
inFlightResponse.conn.r.abortPendingRead()
inFlightResponse.reqBody.Close()
}
c.close()
c.setState(c.rwc, StateClosed, runHooks)
}
}()
...
}
果然,在 serve 方法源码中发现了 defer + recover 的组合。
并且这行代码:
c.server.logf("http: panic serving %v: %v\n%s", c.remoteAddr, err, buf)
可以在执行 HTTP Server 的控制台日志中得到印证:
http: 2024/10/13 23:08:28 http: panic serving [::1]:50547: url is error
数据库事务
使用 defer + recover 来处理数据库事务,也是比较常用的做法。
这里有一个来自 GORM 官方文档中的 示例程序:
type Animal struct {
Name string
}
func CreateAnimals(db *gorm.DB) error {
tx := db.Begin()
defer func() {
if r := recover(); r != nil {
tx.Rollback()
}
}()
if err := tx.Error; err != nil {
return err
}
if err := tx.Create(&Animal{Name: "Giraffe"}).Error; err != nil {
tx.Rollback()
return err
}
if err := tx.Create(&Animal{Name: "Lion"}).Error; err != nil {
tx.Rollback()
return err
}
return tx.Commit().Error
}
在函数最开始开启了一个事务,接着使用 defer + recover 来确保程序执行中间过程遇到 panic 时能够回滚事务。
程序执行过程中使用 tx.Create 创建了两条 Animal 数据,并且如果输出,都将回滚事务。
如果没有错误,最终调用 tx.Commit() 提交事务,并将其错误结果返回。
这个函数实现逻辑非常严谨,没什么问题。
但是这个示例代码写的过于啰嗦,还有优化的空间,可以写成这样:
func CreateAnimals(db *gorm.DB) error {
tx := db.Begin()
defer tx.Rollback()
if err := tx.Error; err != nil {
return err
}
if err := tx.Create(&Animal{Name: "Giraffe"}).Error; err != nil {
return err
}
if err := tx.Create(&Animal{Name: "Lion"}).Error; err != nil {
return err
}
return tx.Commit().Error
}
这里在 defer 中直接去掉了 recover 的判断,所以无论如何程序最终都会执行 tx.Rollback()。
之所以可以这样写,是因为调用 tx.Commit() 时事务已经被提交成功,之后执行 tx.Rollback() 并不会影响已经提交事务。
这段代码看上去要简洁不少,不必在每次出现 error 时都想着调用 tx.Rollback() 回滚事务。
你可能认为这样写有损代码性能,但其实绝大多数场景下我们不需要担心。我更愿意用一点点可以忽略不计的性能损失,换来一段清晰的代码,毕竟可读性很重要。
panic 并不是都可以被 recover 捕获——比如并发读写 map、slice
最后,咱们再来看一个并发写 map 的场景,如果触发 panic 结果将会怎样?
示例如下:
func f() {
m := map[int]struct{}{}
go func() {
defer func() {
if err := recover(); err != nil {
fmt.Println("goroutine 1", err)
}
}()
for {
m[1] = struct{}{}
}
}()
go func() {
defer func() {
if err := recover(); err != nil {
fmt.Println("goroutine 2", err)
}
}()
for {
m[1] = struct{}{}
}
}()
select {}
}
这里启动两个 goroutine 来并发的对 map 进行写操作,并且每个 goroutine 中都使用 defer + recover 来保证能够正常处理 panic 发生。
最后使用 select {} 阻塞主 goroutine 防止程序退出。
执行示例代码,得到输出如下:
$ go run main.go
fatal error: concurrent map writes
goroutine 3 [running]:
main.f.func1()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:156 +0x4c
created by main.f in goroutine 1
/go/blog-go-example/error/defer-panic-recover/recover/main.go:149 +0x50
goroutine 1 [select (no cases)]:
main.f()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:171 +0x84
main.main()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:204 +0x1c
goroutine 4 [runnable]:
main.f.func2()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:167 +0x4c
created by main.f in goroutine 1
/go/blog-go-example/error/defer-panic-recover/recover/main.go:160 +0x80
exit status 2
然而程序还是输出 panic 信息 fatal error: concurrent map writes 并退出了。
但是根据输出信息,我们无法知道具体原因。
在 Go 1.19 Release Notes 中有提到,从 Go 1.19 版本开始程序遇到不可恢复的致命错误(例如并发写入 map,或解锁未锁定的互斥锁)只会打印一个简化的堆栈信息,不包含运行时元数据。不过这可以通过将环境变量 GOTRACEBACK 被设置为 system 或 crash 来解决。
所以我们可以使用如下两种方式来输出更详细的堆栈信息:
$ GOTRACEBACK=system go run main.go
$ GOTRACEBACK=crash go run main.go
再次执行示例代码,得到输出如下:
$ GOTRACEBACK=system go run main.go
fatal error: concurrent map writes
goroutine 4 gp=0x14000003180 m=3 mp=0x14000057008 [running]:
runtime.fatal({0x104904795?, 0x0?})
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/runtime/panic.go:1088 +0x38 fp=0x14000051750 sp=0x14000051720 pc=0x104898a28
runtime.mapassign_fast64(0x104938ee0, 0x1400007a0c0, 0x1)
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/runtime/map_fast64.go:122 +0x40 fp=0x14000051790 sp=0x14000051750 pc=0x1048cb5d0
main.f.func1()
/go/blog-go-example/error/defer-panic-recover/recover/main.go:156 +0x4c fp=0x140000517d0 sp=0x14000051790 pc=0x1049017bc
runtime.goexit({})
/go/pkg/mod/golang.org/toolchain@v0.0.1-go1.23.1.darwin-arm64/src/runtime/asm_arm64.s:1223 +0x4 fp=0x140000517d0 sp=0x140000517d0 pc=0x1048d4694
created by main.f in goroutine 1
/go/blog-go-example/error/defer-panic-recover/recover/main.go:149 +0x50
...
exit status 2
这里省略了大部分堆栈输出,只保留了重要部分。根据堆栈信息可以发现在 runtime/map_fast64.go:122 处发生了 panic。
相关源码内容如下:
func mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(unsafe.Pointer(h), callerpc, abi.FuncPCABIInternal(mapassign_fast64))
}
if h.flags&hashWriting != 0 {
fatal("concurrent map writes") // 第 122 行
}
...
return elem
}
显然是第 122 行代码 fatal(“concurrent map writes”) 触发了 panic,并且其参数内容 concurrent map writes 也正是输出结果。
fatal 函数源码如下:
// fatal triggers a fatal error that dumps a stack trace and exits.
//
// fatal is equivalent to throw, but is used when user code is expected to be
// at fault for the failure, such as racing map writes.
//
// fatal does not include runtime frames, system goroutines, or frame metadata
// (fp, sp, pc) in the stack trace unless GOTRACEBACK=system or higher.
//
//go:nosplit
func fatal(s string) {
// Everything fatal does should be recursively nosplit so it
// can be called even when it's unsafe to grow the stack.
systemstack(func() {
print("fatal error: ")
printindented(s) // logically printpanicval(s), but avoids convTstring write barrier
print("\n")
})
fatalthrow(throwTypeUser)
}
fatal 内部调用了 fatalthrow 来触发 panic。看来由 fatalthrow 所触发的 panic 无法被 recover 捕获。
我们开发时要切记:并发读写 map 触发 panic,无法被 recover 捕获。
并发操作 map 一定要小心,这是一个比较危险的行为,在 Web 开发中,如果在某个接口 handler 方法中触发了 panic,整个 http Server 会直接挂掉。
涉及并发操作 map,我们应该使用 sync.Map 来代替:
func f() {
m := sync.Map{}
go func() {
defer func() {
if err := recover(); err != nil {
fmt.Println("goroutine 1", err)
}
}()
for {
m.Store(1, struct{}{})
}
}()
go func() {
defer func() {
if err := recover(); err != nil {
fmt.Println("goroutine 2", err)
}
}()
for {
m.Store(1, struct{}{})
}
}()
select {}
}
这个示例就不会 panic 了。
错误和异常是不一样的 go还有panic等等
看另一篇文章把 对比各个语言错误异常机制的
defer
用法
最基础用法
func main() {
defer fmt.Println("Hello")
fmt.Println("World")
}
运行后输出:
World
Hello
有点像析构函数,当执行完的时候调用。更准确的说像java中的finally。
defer后面要跟一个函数的执行,不能是其他 比如 defer a=1 就会报错expression in defer must be function call
多个defer执行顺序 后进先出(栈)
func main() {
defer fmt.Println("1")
defer fmt.Println("2")
defer fmt.Println("3")
}
输出:
3
2
1
defer与return的执行顺序
情况 1:普通返回值(匿名返回值)不会被 defer 修改
func test() int {
x := 10
defer func() {
x = 20
}()
return x
}
func main() {
fmt.Println(test()) // 输出10(因为 return x 先执行,defer 修改 x 但不会影响返回值)
}
情况 2:命名返回值可以被 defer 修改
func test() (x int) {
x = 10
defer func() {
x = 20
}()
return x
}
func main() {
fmt.Println(test()) // 输出20 发现被修改了
}
之所以出现这么奇怪的现象是因为
defer的定义,就是在函数返回之前执行。这一点毋庸置疑,肯定是在retumn之前执行。
需要注意的是,return 是非原子性的,需要两步:
- 执行前首先要得到返回值(也就是对返回值赋值)
- return 将返回值返回调用处。
defer 和 return 的执行顺序是:
- 先为return的返回值赋值
- 然后执行 defer
- 然后真正调用return 到函数调用处
所以 对于例子1而言:
- return x 会先将 x 的值(即 10)复制到返回值的内存空间;
- 随后执行 defer 函数,此时修改的是函数内的局部变量 x,但不影响已存储的返回值23;
- 最终返回值为 10。
对于例子2
- 具名返回值 x 在函数声明时已作为作用域内的变量存在,return x 仅将当前值(10)赋给 x,但未触发
值拷贝可以理解是指针拷贝; - defer 函数直接修改了作用域内的 x(从 10 改为 20)37;
- 最终返回的是修改后的 x,即 20。
defer 声明时就会对参数进行求值,而不是等到真正执行时才计算
defer 语句在声明时就会对参数进行求值,而不是等到真正执行时才计算。
func main() {
x := 10
defer fmt.Println("defer x:", x)
x = 20
fmt.Println("main x:", x)
}
输出:
main x: 20
defer x: 10
defer 在声明时就“捕获”了 x 的值(10),即使后续 x 变成了 20,defer 执行时仍然使用 10。
执行逻辑:
- defer fmt.Println(x) 中的 x 在 defer 语句执行时(即声明时)就被求值为 10,并作为参数传递给 fmt.Println;
- 后续 x = 20 的修改不影响 defer 已捕获的参数值;
- 最终输出 defer x: 10。
如果 defer 需要使用“最终的值”,可以传入 指针 或 闭包。
func main() {
x := 10
defer func() { fmt.Println("defer x:", x) }()
x = 20
fmt.Println("main x:", x)
}
输出:
main x: 20
defer x: 20
由于 defer 绑定的是 闭包,所以 x 的最终值是 20。
执行逻辑:
- defer 后的匿名函数没有显式参数,其内部通过闭包直接引用变量 x,此时闭包捕获的是变量 x 的地址而非当前值;
- x = 20 修改了变量 x 的值,闭包在最终执行时读取的是 x 的最终值(20);
- 最终输出 defer x: 20。
所以,如果我们修改下:
func main() {
x := 10
defer test(10)
x = 20
fmt.Println("main x:", x)
}
func test(x int) { fmt.Println("defer x:", x) }
则输出为:
main x: 20
defer x: 10
指针的例子如下
type User struct {
name string
}
func (u *User) Print() {
fmt.Println("User:", u.name)
}
func main() {
u := &User{name: "Alice"}
defer u.Print()
u.name = "Bob"
}
输出:Bob(因为 defer 绑定的是 u.Print(),而 u.name 在 defer 执行前已被修改)
defer func(name string) {
fmt.Println("User:", name)
}(u.name) // 传入当前 name 值
如果这样 则是alice
还有slice和map也类似 如果扩容就和值传递引用传递那类似
package defer_knowledge
import "fmt"
func DeferParams2(){
var arr = make([]int,5,5)
//引用类型直接传递即可,将追踪到引用改变为止
defer func(a []int){
fmt.Printf("defer内的参数为%#v\n",a)
}(arr)
arr[2] = 10
fmt.Printf("arr已经变成了%#v\n",arr)
}
arr已经变成了[]int{0, 0, 10, 0, 0}
defer内的参数为[]int{0, 0, 10, 0, 0}
defer与闭包
上一节讲了
闭包通过引用直接访问外部变量,实际执行时才会读取变量的最新值,这绕过了 defer 参数声明时的值拷贝机制
defer 关闭 channel 需要谨慎
错误示范
func main() {
ch := make(chan int)
defer close(ch) // ⚠️ 可能 panic
ch <- 1
}
正确方式:让 唯一的发送方 负责关闭 channel
func sender(ch chan int) {
defer close(ch)
ch <- 1
}
func main() {
ch := make(chan int)
go sender(ch)
fmt.Println(<-ch)
}
defer与panic
看上一节
defer 与 exit
os.Exit(0) 会跳过所有 defer
错误示范
func main() {
defer fmt.Println("这条语句不会执行")
os.Exit(0) // 直接终止程序
}
func main() {
defer fmt.Println("程序即将退出")
return // 让函数正常返回
}
总结——defer不执行的情况
- 函数中发生了panic,且没有被当前函数内的recover捕获。
- 函数还没执行到defer,就遇到提前返回或者panic等中断函数执行的情况。
- 其他不正常的退出路径,如通过调用os.Exit强制退出程序。
defer 的应用场景
2.1 资源释放
在处理文件、数据库连接等资源时,defer 让代码更简洁,避免忘记释放资源。
func readFile(filename string) {
file, err := os.Open(filename)
if err != nil {
fmt.Println("打开文件失败:", err)
return
}
defer file.Close() // 确保文件在函数退出时关闭
fmt.Println("读取文件...")
}
2.2 互斥锁解锁
var mu sync.Mutex
func criticalSection() {
mu.Lock()
defer mu.Unlock()
fmt.Println("执行关键代码区域")
}
这样,无论函数中途如何返回,互斥锁都会被正确释放,避免死锁。
2.3 计算执行时间(简单性能分析)
func trackTime() func() {
start := time.Now()
return func() {
fmt.Println("执行时间:", time.Since(start))
}
}
func main() {
defer trackTime()()
time.Sleep(2 * time.Second)
}
2.4 defer 与 panic/recover 的配合
defer 在 panic 发生时仍然会执行,因此常用于 异常捕获,避免程序崩溃。
func protect() {
if r := recover(); r != nil {
fmt.Println("捕获 panic:", r)
}
}
func mayPanic() {
defer protect() // 保护代码块
panic("发生严重错误!") // 触发 panic
}
func main() {
mayPanic()
fmt.Println("程序继续运行")
}
recover() 只有在 defer 作用域内才能捕获 panic,否则 panic 仍然会导致程序崩溃。
多个 defer 仍然遵循 LIFO 规则,可以在多个 defer 里做不同的善后处理。
总结使用场景
| 场景 | 示例 |
|---|---|
| 释放锁 | defer mu.Unlock() |
| 关闭文件 | defer file.Close() |
| 关闭网络连接 | defer conn.Close() |
| 关闭数据库连接 | defer db.Close() |
| 捕获 panic | defer recover() |
| 计算执行时间 | defer time.Since(start) |
| 多个 defer 逆序执行 | defer fmt.Println() |
| 删除临时文件 | defer os.Remove() |
总结——defer、panic和recover
- defer执行顺序 是个栈 后进先出
- return是先计算值 然后defer 然后再真正return 但是也分引用的情况 比如命名返回值
- defer也是 申明的时候就先计算好值了,如果要使用最终值 请使用“最终的值”,可以传入 指针 或 闭包。
- defer关闭chan要谨慎
- defer会再return和panic之前执行 但是exit会退出
- defer需要在panic或者return之前申明 不然会失效
- 利用上面这个特性 defer可以捕获错误panic ,看到panic了 先将panic和参数压到栈中 然后再执行defer 等到defer执行完了 再真正panic 所以defer中panic能被recover捕获 也就是panic在栈底
- recover必须再defer的匿名函数中使用
- 外层的协程一般不能捕获子协程的panic,一般只能捕获当前协程的panic
- 通过处理 可以将panic转化为error 避免程序退出
- 特别小心map和slice 并发写会panic 且不能被捕获
- 为了避免不必要的麻烦,defer 函数中最好不要有能够引起 panic 的代码。
- defer的应用场景
- 资源释放
- 异常捕获,避免程序崩溃。
- 互斥锁解锁
- 计算执行时间(简单性能分析)
并发
groutine
channel
select
定时器
sync包
等
详见另一篇文章
框架
好像gin beego go Frame比较多?按照顺序学吧==
封装
包
- 包名可以不和文件夹的名字一样,包名不能包含 - 符号。
- 包名为main的包为应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不包含main包的源代码则不会得到可执行文件。
基本操作
此处为了简单 先用最简单的go get path模式 后面会讲更推荐使用的go mod模式
下载包用get,类似py的pip,官方的包管理工具
go get -u github.com/gin-gonic/gin
导入包,官方、第三方的包用全路劲,自己的项目的包用相对路径,多个的话 用括号括起来
import (
"net/http"
"github.com/gin-gonic/gin"
)
如果你的包引入了三种类型的包,标准库包,程序内部包,第三方包,建议采用如下方式进行组织你的包:
import (
"encoding/json"
"strings"
"myproject/models"
"myproject/controller"
"myproject/utils"
"github.com/astaxie/beego"
"github.com/go-sql-driver/mysql"
)
init函数与继承
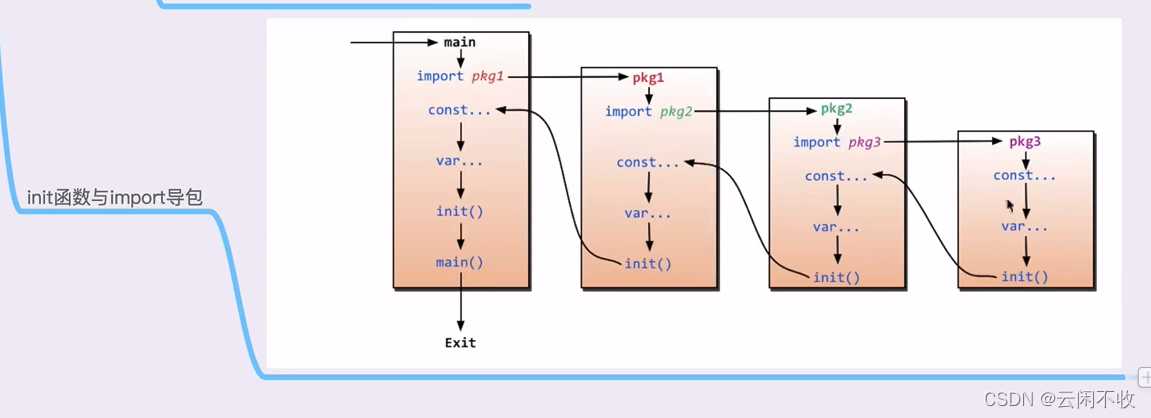
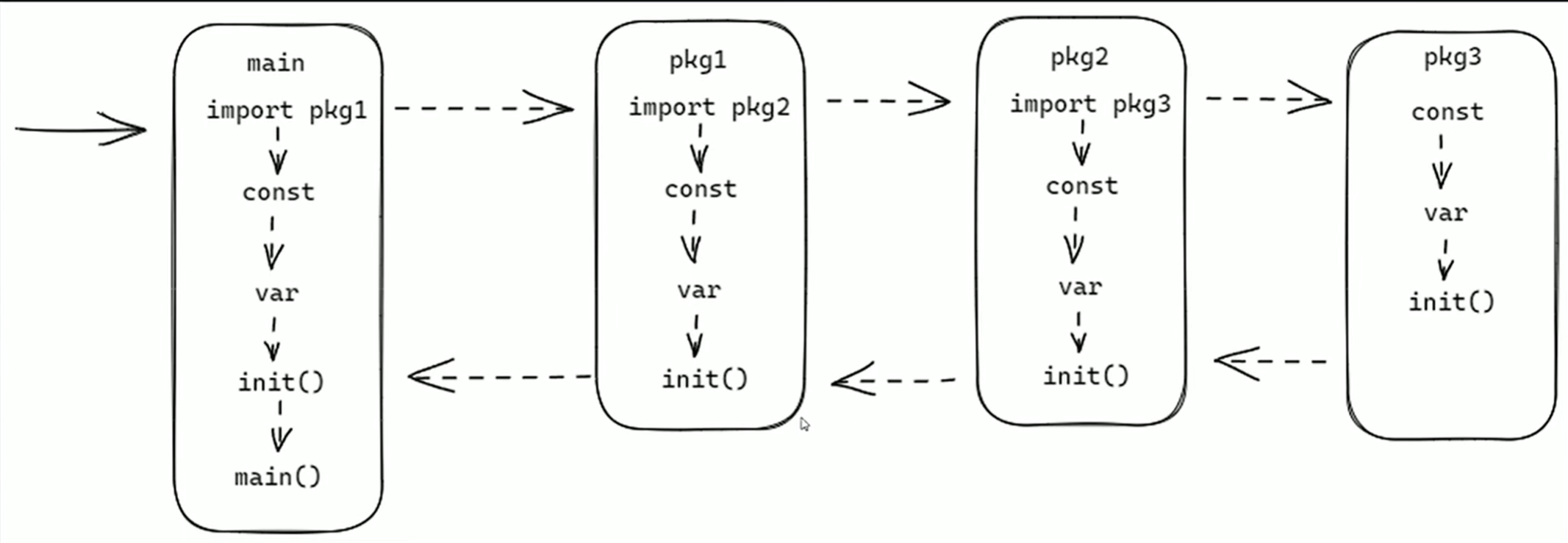
注意 init是小写,和大写的Init不一样 ,而且不能带参数
一个包可以有多个init函数而不会报错
package main
func init() {
println("init a")
}
func init() {
println("init b")
}
func init() {
println("init c")
}
func main() {
println("main")
}
init函数如何实现类似带参数的效果
在Go语言中,init 函数是特殊的函数,它用于在包初始化时自动执行某些代码。init 函数不允许有参数,也不可以有返回值。这是Go语言的设计,意味着你不能直接给init函数添加参数。
但是,如果你需要在init函数中使用参数,你可以通过以下几种方式来间接实现:
环境变量:读取环境变量作为参数。
package mypackage
import (
"fmt"
"os"
)
func init() {
param := os.Getenv("MY_PARAM")
fmt.Println("Init function with parameter from environment:", param)
}
在程序启动前设置环境变量:
export MY_PARAM="Hello, World!"
- 命令行参数:如果你的程序是可执行的,你可以通过命令行参数来传递参数,并在init函数中读取。
go
package mypackage
import (
"fmt"
"os"
)
func init() {
param := os.Args[1] // 假设命令行参数是第二个参数
fmt.Println("Init function with parameter from command line:", param)
}
运行程序时传递参数:
go run myprogram.go "Hello, World!"
请注意,init函数的执行顺序是不确定的,除了在同一个包内的init函数会按照它们在代码中出现的顺序执行外,不同包的init函数之间的执行顺序是无法保证的。因此,尽量避免在init函数中使用复杂的逻辑或依赖于特定执行顺序的操作。
三种特殊的导入
import (
v2 "github.com/YFJie96/wx-mall/controller/api/v2"
_ "github.com/YFJie96/wx-mall/docs"
. "fmt"
"github.com/gin-gonic/gin"
)
-
别名
v2:
相当于是导入包的一个别名,后续可以直接使用v2.xxx调用import包内接口或方法。 -
匿名导入 下划线
_:
在导入路径前加入下划线表示只执行该库的 init 函数而不对其它导出对象进行真正地导入。因为 Go 语言的数据库驱动都会在 init 函数中注册自己,所以我们只需要进行上述操作即可;否则的话,Go 语言的编译器会提示导入了包却没有使用的错误。
所以 如果你导入了包不使用 会报错 这时可以用匿名导入,在前面加一个下划线 -
点
.:
点相当于把导入包的函数,同级导入到当前包,可以直接使用包内函数名进行调用
import实际上是文件的路径 和增加了一个环境path
和java有一定区别
import实际上相当于 增加了一个环境path 告诉go 要去这个目录下找包
首先 go会自动在当前目录去引入文件 但是不会引入子目录 比如我们有这个目录结构
├── Controllers
│ └── baseController
│ └── response.go //package controller,并定义了responseSuccess方法
├ ── loginController.go //代码第一行 package controller
└── main.go
此时,虽然loginController.go 和response.go 都用package声明了属于controller包,但是在loginController中 使用responseSuccess方法 你会发现编译器提示没有这个方法!
但是 我们在loginController.go中 ,增加一个import
import ."Controllers/baseController" //这里是文件路径 不是包名!
responseSuccess() //就不会报错了
或者
import hhh"Controllers/baseController" //这里是文件路径 不是包名!
hhh.responseSuccess() //就不会报错了
注意 这样之后 是hhh.responseSuccess() 而非hhh.controller.responseSuccess
由此 我们得出结论 import的重命名操作 会将该目录下的所有代码文件(一级)都重命名为hhh,而不管代码里实际package定义的是什么
或者
import "Controllers/baseController" //这里是文件夹的路径 不是包名!
baseController.controller.responseSuccess() //就不会报错了
注意这里是baseController.controller要写文件夹+package声明的包名才行
体会和上面的区别
go 包管理模式 path模式与mod模式
简单来说就是
当目录下没有go.mod文件 以及你从来没执行过go mod init命令的时候,默认是go path模式
反之则是go module模式
path模式下 你需要go get 或者编译go run xxx的时候自动导入包(但是一般得手动导入 不然写代码就是一堆红色报错 看着很烦)
而mod模式下 你只需要第一次运行下 go mod init命令,之后用go mod tidy命令自动导入包即可(也可直接go run)
当然你在mod模式下也可以用go get命令 但是此时的get命令会被mod模式接管
还有一个区别是导入你自己写的代码的
如果是path模式 直接 import controller即可 如果是mod模式 需要import xxx/controller
go path模式 已经不推荐使用了
go在1.11版本之前使用的管理模式
- GOROOT:golang 的安装路径
- GOPATH:存放sdk以外的第三方类库;自己收藏的可复用的代码
此外,Goland里还分了 Project GPPATH 和 Global GOPATH
- Global GOPATH是所有项目都可以使用的
- Project GOPATH是只有这个项目可以使用的
使用下面命令能够看到gopath的目录
$ go env
GOPATH=C:\Users\xiaoming\go
gopath下包含三个文件夹
- bin是可执行二进制文件 你的go命令就是这里
- pkg是加快你的编译速度的一些文件和依赖。使用 go module后 会把下载的包放这个位置
- src就是你导入的包,比如导入github后 里面有个github的文件夹
使用第三方库的方法
package main
import (
"github.com/gin-gonic/gin"
)
func main() {
router := gin.Default()
router.Run()
}
import了一个github.com/gin-gonic/gin套件,这个是别人开发的Web Framework套件,是不存在于官方程式库的,而是放在GitHub上的第三方套件。
当执行Golang程式码,当需要存取套件时:
- 会先去GOROOT路径下的src资料夹找-有没有gin这个资料夹-
- 如果在GOROOT路径下没有找到,则会往GOPATH路径下找
所以只要GOROOT跟GOPATH路径下都没有找到该套件的话,就无法执行该程式码。
如果我们没找到的话 这时候我们就要用go get 命令下载 对应包
GOPATH的缺点
Go所依赖的所有的第三方库都放在GOPATH这个目录下面,下载的依赖包也没有版本概念,这就导致了同一个库只能保存一个版本的代码。如果不同的项目,无法依赖同一个第三方的库的不同版本。第三方套件只要不是官方程式库,都需要放置在GOPATH/src的路径下才可以使用
再来,如果你开发的专案采用第三方套件是不同版本或者某些情况需要修改第三方包怎么办?以往的解决方法是要设定多组不同的GOPATH。
所以 goPath模式(go get )的弊端:无法指定版本号!这样可能会导致 你把自己写的包给别人用的时候,无法保证版本一致。引入的包如果涉及依赖(引入的包也需要引入其他库),也无法保证引入的包能正常运行
go modules ——推荐使用
Go.mod是Golang1.11 版本新引入的官方包管理工具,用于解决之前没有地方记录依赖包具体版本的问题
Modules是相关Go包的集合,是源代码交换和版本控制的单元。go命令直接支持使用Modules,包括记录和解析对其他模块的依赖性。Modules替换旧的基于GOPATH的方法,来指定使用哪些源文件。
Modules和传统的GOPATH不同,不需要包含例如src,bin这样的子目录,一个源代码目录甚至是空目录都可以作为Modules,只要其中包含有go.mod文件。
go mod的要求:
go的版本必须升级到 1.11 以上
设置GO111MODULE的值:
GO111MODULE = auto
默认值,go命令行将会根据当前目录来决定是否启用module功能。
情况下可以分为两种情形:
① 当前目录在GOPATH/src之外且该目录包含go.mod文件
② 当前文件在包含go.mod文件的目录下面。
当modules功能启用时,依赖包的存放位置变更为$GOPATH/pkg
GO111MODULE = off
go命令行将不会支持module功能,寻找依赖包的方式将会沿用旧版本那种通过vendor目录或者GOPATH模式来查找。
GO111MODULE = on
go命令行会使用modules,而一点也不会去GOPATH目录下查找。
go mod关键字
go.mod 文件内提供了module、 require、replace、exclude四个关键字。
go.mod文件 关键字
- module语句指定包的名字(路径)
- require语句指定的依赖项模块
- replace语句可以替换依赖项模块
- exclude语句可以忽略依赖项模块
go mod常用命令
go mod download //下载依赖包
go mode edit edit go.mod from tools or scripts 编辑go.mod
go mod graph //打印模块依赖图
go mod init initialize new module in current directory 在当前目录初始化mod
go mod tidy //拉取缺少的模块,移除不用的模块。
go mod vendor //将依赖复制到vendor下
go mod verify verify dependencies have expected content 验证依赖是否正确
go mod why //解释为什么需要依赖
在使用go mod init 模块名称 命令后,会在当前目录下生成一个go.mod文件,之后的包的管理都是通过这个文件管理。
go.mod文件一旦创建后,它的内容将会被go toolchain全面掌控。go toolchain会在各类命令执行时,比如go get、go build、go mod等修改和维护go.mod文件。
会除了go.mod之外,go命令还维护一个名为go.sum的文件,其中包含特定模块版本内容的预期加密哈希 ,go命令使用go.sum文件确保这些模块的未来下载检索与第一次下载相同的位,以确保项目所依赖的模块不会出现意外更改,无论是出于恶意、意外还是其他原因
采用Go Modules,下载下来的第三方套件都在,GOPATH/pkg/mod资料夹里面
notice 导入自己写的代码包的问题
你创建了一个文件的名字为list001如果你初始化项目名字为list
go mod init list
那么你导本身就是代码内的文件包的时候就得也用list
import (
"lisi/controller"
"lisi/models"
)
总结:一切以mod的为主,不要用创建文件的名字list001,要用list

gosum文件是保证下的包是完整的

你可能想要升级版本 或者不小心手动get 然后升级了版本,发现不好用。但是go的mod文件似乎会自动变成你新拉的。这时候你可能像变回去,两种方法
1,直接修改require
2,上面的replace语法,但是repalce其实用处是,比如你下载国外的包 很慢下不下来 可以用国内的镜像下载下来的去替代
包的执行顺序
权限
当命名(包括常量、变量、类型、函数名、结构字段等等,不包括包 因为包肯定是要导出的啊 不然你封装这个包干什么)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);
命名如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 private )
问题
我有个问题
比如引入的包要求go是旧版 特别多个包 引入 每个都不一样
那这之后咋执行 谁为准 会出问题么?
常用工具 代码格式化、检查、自动引入包等
gofmt 大部分的格式问题可以通过gofmt解决, gofmt 自动格式化代码,保证所有的 go 代码与官方推荐的格式保持一致,于是所有格式有关问题,都以 gofmt 的结果为准。
goimport 我们强烈建议使用 goimport ,该工具在 gofmt 的基础上增加了自动删除和引入包.
go get golang.org/x/tools/cmd/goimports
go vet vet工具可以帮我们静态分析我们的源码存在的各种问题,例如多余的代码,提前return的逻辑,struct的tag是否符合标准等。
go get golang.org/x/tools/cmd/vet
使用如下:
go vet
编译
详细可看
http://c.biancheng.net/view/120.html
go build -o myexec main.go lib.go
同时编译两个go文件 并且命名为mywxec
ps:1、windows使用.\可执行文件 2、名字要改成exe Linux不需要后缀名
Suggestion [3,General]: 找不到命令 server,但它确实存在于当前位置。默认情况下,Windows PowerShell 不会从当前位置加载命令。如果信任此命令,请改为键入“.\server”。有关
详细信息,请参阅 “get-help about_Command_Precedence”。
条件编译
Go语言支持条件编译,通过编译标签(//+build)和文件后缀实现不同环境下的代码选择性编译。
一、编译标签
格式:以注释形式添加在文件顶部,格式为//+build ,下一行必须为空行。
逻辑关系:
- 空格分隔表示OR关系
- 逗号分隔表示AND关系
- !前缀表示NOT关系
适用场景:可指定操作系统(如linux、darwin)、架构(如amd64)、编译器(如gc)等条件。
二、文件后缀
格式:文件名以_GOOS.go或_GOARCH.go结尾(如_linux.go、_amd64.go),用于区分不同平台或架构。
组合使用:可同时使用标签和后缀,例如//+build linux,amd64配合_linux_amd64.go文件。
这个方法通过改变文件名的后缀来提供条件编译,这种方案比编译标签要简单,go/build可以在不读取源文件的情况下就可以决定哪些文件不需要参与编译。
文件命名约定可以在go/build 包里找到详细的说明,简单来说如果你的源文件包含后缀:_GOOS.go,那么这个源文件只会在这个平台下编译,_GOARCH.go也是如此。这两个后缀可以结合在一起使用,但是要注意顺序:_GOOS_GOARCH.go, 不能反过来用:_GOARCH_GOOS.go. 例子如下:
mypkg_freebsd_arm.go // only builds on freebsd/arm systems
mypkg_plan9.go // only builds on plan9
实际应用
- 跨平台开发:通过条件编译隐藏不同平台的API差异,例如Linux与Windows的文件操作实现分离。
- 环境区分:调试代码与生产代码分离,通过标签控制是否编译特定功能模块。
示例
// +build linux,amd64
// Linux amd64平台下编译该文件
// +build darwin,cgo
// 仅当darwin且开启cgo时编译该文件
三、如何实现交叉编译?
我们知道golang一份代码可以编译出在不同系统和cpu架构运行的二进制文件。go也提供了很多环境变量,我们可以设置环境变量的值,来编译不同目标平台。
GOOS: 目标平台; GOARCH: 目标架构。
# 编译目标平台linux 64位
GOOS=linux GOARCH=amd64 go build main.go
# 编译目标平台windows 64位
GOOS=windows GOARCH=amd64 go build main.go
others
https://zhuanlan.zhihu.com/p/360306642
这个讲的很好
推荐
《go语言圣经》http://shouce.jb51.net/gopl-zh/index.html 讲的还行
其他以后在想分类的

any
type any = interface{}
any,这实际上是 interface{} 的别名
之所以引入 any 关键字,主要是让泛型修饰时短一点,少一些括号。any 比 interface{} 会更清爽~
日志
看另一篇文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)