老码农和你一起学AI系列:系统化特征工程-理论基础
特征工程是决定机器学习系统性能的关键因素,它如同烹饪中的备菜过程,直接影响最终"菜品"质量。特征质量决定了模型认知能力的上限,优质特征比复杂算法更能提升模型表现。完整的特征工程包括数据理解、清洗、转换、构造和选择等环节,需要结合领域知识进行创造性处理。尽管AutoML等工具正在发展,但特征工程仍离不开人类对业务的理解和判断。掌握特征工程这一核心技能,才能从数据中真正挖掘出有价值
在人工智能席卷各行各业的今天,当我们谈论机器学习的成功时,目光往往聚焦于复杂的神经网络架构、精妙的优化算法或惊人的算力突破。然而,真正决定一个 AI 系统成败的关键因素,却常常隐藏在这些光鲜技术的背后 —— 特征工程。无论是 AI 领域的从业者,还是对机器学习感兴趣的普通读者,理解特征工程的核心价值,都将为我们打开一扇洞察机器学习本质的窗户。
什么是特征?
特征(Feature) 是对原始数据中具有预测价值或区分能力的属性的提炼,是机器学习模型理解世界的 "语言"。如果把模型比作一个决策者,那么特征就是它赖以做出判断的证据。
在不同场景中,特征的表现形式千差万别:
- 在人脸识别中,特征可能是眼角的角度、鼻梁的高度等关键面部特征点的相对位置
- 在自然语言处理中,特征可能是词语的词性、情感倾向或上下文关联
- 在金融风控中,特征可能是用户的还款记录、债务收入比、信用历史长度等
特征的质量直接决定了模型的 "认知能力"。就像人类决策者需要高质量的信息才能做出明智判断一样,模型也需要优质特征才能产出可靠结果。
特征决定上限:被低估的真理
机器学习领域有句颠扑不破的名言:"数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限"。这句话看似简单,却揭示了一个被许多人忽视的本质:无论使用多么先进的模型,如果输入的特征质量低下,最终结果必然不尽人意。
让我们通过三个场景理解这个道理:
-
医疗诊断场景:如果我们试图通过 "病人身高、体重" 来预测是否患有糖尿病,即使使用最先进的深度学习模型,准确率也难以突破 60%;但如果加入 "血糖值、胰岛素水平" 等关键特征,即使是简单的决策树模型,准确率也能轻松达到 90% 以上。
-
推荐系统场景:仅通过 "用户 ID、商品 ID" 预测点击行为,效果远不如加入 "用户历史浏览记录、商品类别、价格区间" 等特征的简单模型。
-
图像识别场景:早期的图像识别模型性能有限,并非因为算法不够先进,而是因为未能有效提取图像中的边缘、纹理等关键特征。直到卷积神经网络(CNN)出现,通过内置的特征提取机制自动学习有效特征,才带来了突破性进展。
这些案例共同证明:特征质量是机器学习系统的 "天花板"。模型和算法的作用,只是让我们更接近这个天花板,却无法突破它。
特征工程:机器学习的 "烹饪艺术"
要理解特征工程的价值,我们可以用烹饪过程做一个生动类比:
- 原始数据 = 新鲜食材(蔬菜、肉类、调料等)
- 特征工程 = 备菜过程(清洗、切割、腌制、搭配等)
- 模型训练 = 烹饪过程(煎、炒、烹、炸等技法)
- 模型输出 = 最终菜品
这个类比揭示了几个重要事实:
-
菜决定基础:再顶级的厨师,面对未清洗的蔬菜、未处理的生肉,也难以做出美味。同样,再先进的模型,遇到未经处理的原始数据,也难以发挥作用。
-
技巧决定风味:同样的食材,不同的备菜方式会产生截然不同的效果。比如同样是鸡肉,切块爆炒适合宫保鸡丁,切丝腌制适合鸡丝凉面。特征工程也是如此,同样的数据,不同的特征处理方式会带来迥异的模型性能。
-
经验决定品质:优秀的厨师能根据食材特性创造出新菜式,资深的数据科学家能从看似普通的数据中挖掘出高价值特征。这种对 "食材" 和 "数据" 本质的理解,是长期经验积累的结果。
在 Kaggle 等顶级数据科学竞赛中,这个规律表现得尤为明显。许多冠军团队的制胜关键,并非使用了多么复杂的模型,而是通过深入的特征工程挖掘出了数据中隐藏的模式。有竞赛获奖者曾透露,他们 80% 的时间都花在特征工程上,而模型调优仅占 20%。
实例:特征处理如何改变模型命运
让我们通过一个具体案例,直观感受特征工程的影响力。假设我们要构建一个预测 "学生考试是否及格" 的模型,原始数据包含三个特征:
| study_hours(学习时长) | sleep_hours(睡眠时长) | test_anxiety(考试焦虑度) | pass(是否及格) |
|---|---|---|---|
| 4 | 7 | 高 | 否 |
| 10 | 6 | 中 | 是 |
| 6 | 5 | 高 | 否 |
| 8 | 8 | 低 | 是 |
第一轮:原始特征直接建模
使用原始数据训练逻辑回归模型,得到的准确率仅为 75%。问题出在哪里?
study_hours和sleep_hours数值范围相近(4-10),但test_anxiety是文本类型(高 / 中 / 低),模型无法直接处理- 特征之间的重要性被数值规模不当影响,模型难以学习到真实模式
第二轮:基础特征处理
我们进行两项简单处理:
- 对
test_anxiety进行数值编码(高 = 3,中 = 2,低 = 1) - 对所有特征进行标准化(使均值为 0,标准差为 1)
处理后的数据:
| study_hours(标准化) | sleep_hours(标准化) | test_anxiety(编码后) | pass |
|---|---|---|---|
| -1.13 | 0.37 | 3 | 否 |
| 1.36 | -0.12 | 2 | 是 |
| -0.38 | -0.62 | 3 | 否 |
| 0.15 | 0.37 | 1 | 是 |
同一逻辑回归模型的准确率提升至 85%。简单的特征处理就让模型性能有了显著提升。
第三轮:特征构造
我们进一步构造新特征:
study_efficiency= study_hours /sleep_hours(学习效率)rest_study_ratio= sleep_hours /study_hours(休息学习比)
加入新特征后,模型准确率达到 95% 以上。这个简单案例清晰展示了:特征工程不是可有可无的点缀,而是决定模型性能的核心环节。
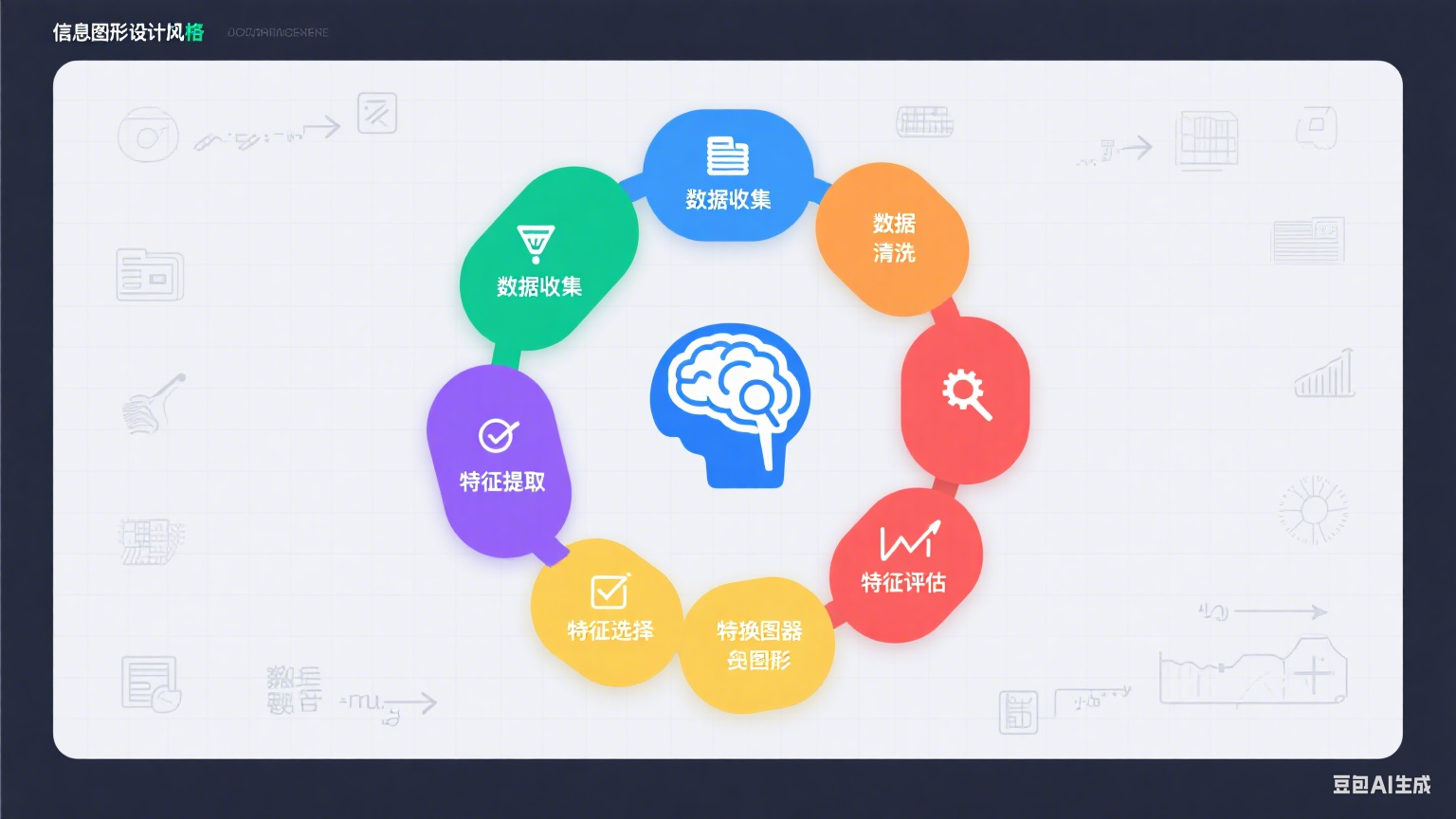
特征工程的完整工作流
特征工程是一个系统性过程,需要遵循科学的工作流程。一个完整的特征工程流程通常包含以下阶段:
1. 数据理解:知其然,更知其所以然
特征工程的第一步不是急于处理数据,而是深入理解数据。这包括:
- 业务理解:特征必须与业务目标相关。预测房价时,"房屋朝向" 在北方可能是重要特征,在热带地区则意义不大
- 统计分析:通过描述性统计(均值、方差、分位数)了解特征分布
- 可视化探索:使用直方图、箱线图、散点图等工具发现数据中的模式和异常
数据理解阶段就像医生的 "问诊",只有充分了解情况,才能制定有效的治疗方案。
2. 数据清洗:去伪存真
现实世界的数据往往存在各种问题,需要先进行 "清洗":
- 缺失值处理:根据缺失原因选择删除、均值填充、中位数填充或使用模型预测填充
- 异常值处理:识别并处理数据中的错误或极端值,避免影响模型学习
- 重复值处理:去除重复记录,避免数据权重失衡
数据清洗就像洗菜去沙,是后续工作的基础。
3. 特征转换:量体裁衣
原始特征往往不能直接被模型使用,需要进行转换:
- 数值特征转换:标准化、归一化、对数转换等,使特征满足模型假设
- 类别特征编码:独热编码、标签编码、目标编码等,将文本转换为数值
- 时间特征处理:从时间戳中提取年月日、星期、季节等周期性特征
特征转换就像为不同身材的人量体裁衣,让特征更适合模型 "穿着"。
4. 特征构造:点石成金
特征构造是特征工程的创造性环节,通过组合现有特征生成新特征:
- 数学运算:加减乘除(如 "人均收入 = 总收入 / 家庭人数")
- 聚合统计:分组均值、最大值、频率(如 "用户平均订单金额")
- 交叉特征:类别与数值交叉(如 "不同年龄段的平均消费")
- 领域特征:结合专业知识构造特征(如金融领域的 "流动比率")
优秀的特征构造能从平凡数据中挖掘出金子般的信息。
5. 特征选择:去粗取精
并非特征越多越好,冗余或噪声特征会导致模型过拟合:
- 过滤法:通过统计指标(如相关性、信息增益)筛选特征
- 包裹法:通过模型性能评估选择最优特征子集
- 嵌入法:利用模型自身的特征重要性评估(如决策树的 Gini 系数)
特征选择就像雕刻艺术品,去掉多余部分才能凸显精华。
6. 迭代优化:持续精进
特征工程不是一次性工作,而是一个循环迭代的过程:
- 根据模型反馈调整特征策略
- 尝试新的特征构造方法
- 随着新数据加入不断更新特征
这个过程就像厨师不断改进菜谱,通过持续优化提升最终品质。
特征工程的挑战与趋势
尽管特征工程至关重要,但它也面临着诸多挑战:
- 耗时费力:据统计,数据科学家约 60-70% 的时间都花在特征工程上
- 领域依赖:有效的特征往往需要深厚的领域知识
- 主观性强:特征选择和构造在很大程度上依赖个人经验
近年来,随着自动化机器学习(AutoML)的发展,出现了一些自动特征工程工具(如 Featuretools、TSFresh),它们能自动生成大量候选特征并筛选最优子集。但这并不意味着特征工程会被取代 —— 自动化工具可以提高效率,但无法替代人类对业务的理解和创造性思维。
未来,特征工程将向 "人机协作" 方向发展:机器负责处理重复性工作,人类则专注于理解业务、设计核心特征和评估特征质量。
最后小结
特征工程之所以重要,是因为它触及了机器学习的本质 —— 从数据中提取有价值的信息。在这个数据爆炸的时代,我们不缺数据,缺的是从数据中挖掘洞察的能力。
对于 AI 专业人士,掌握特征工程是提升模型性能的核心竞争力;对于普通读者,理解特征工程能帮助我们更理性地看待 AI 系统的能力边界 —— 当一个 AI 系统表现不佳时,问题可能不在于 "算法不够智能",而在于我们没有给它提供足够好的 "思考素材"。
正如烹饪的精髓在于对食材的理解和处理,机器学习的灵魂在于特征工程。在追求更先进模型的同时,我们不应忽视这个基础而又关键的环节。毕竟,能把简单食材做出美味的,才是真正的大师;能从平凡数据中挖掘价值的,才是优秀的数据科学家。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)