问题:流水线中如何控制在同一时钟内各流水段中执行不同的指令?
流水线并行通过划分指令执行阶段(如五级流水线)实现指令级并行,各阶段由专用硬件单元处理并受统一时钟控制。关键技术包括数据冲突的旁路技术、控制冲突的动态分支预测(准确率>95%)和结构冲突的硬件资源调度。优化设计涵盖超流水线(如20级流水线)和多发射流水线,但面临功耗、异常处理和时钟偏移等挑战。前沿趋势包括异构流水线(如GPU的SIMT)、AI加速指令集和量子流水线探索。
·
一、流水线并行执行的基本原理
-
流水段划分与时钟同步
- 指令执行被拆分为多个阶段(如五级流水线:取指IF、译码ID、执行EX、访存MEM、写回WB),每个阶段由专用硬件单元处理。
- 时钟周期统一控制:所有流水段以同一时钟信号为基准,每个周期结束时将当前处理结果存入流水线寄存器(或锁存器),下一周期自动传递至下一阶段。
- 示例:
- 时钟周期1:指令A在IF段,指令B在ID段,指令C在EX段。
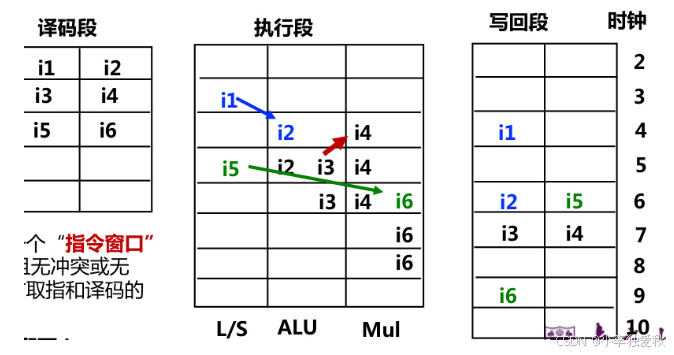
- 时钟周期2:指令A进入ID段,指令B进入EX段,指令C进入MEM段,同时新指令D进入IF段。
- 时钟周期1:指令A在IF段,指令B在ID段,指令C在EX段。
-
硬件资源隔离
- 各流水段使用独立的功能单元(如ALU、存储器接口),避免资源争用。
- 关键设计:为易冲突资源(如存储器)设置多端口或复制单元。例如,采用分离的指令Cache与数据Cache,解决取指与访存的结构冲突。
二、控制并行执行的核心技术
-
数据冲突的深度解决方案
-
旁路技术(Bypassing)硬件实现:
// 硬件描述示例:EX段结果直送下一指令EX段输入 if (EX_MEM_RegisterRd == ID_EX_RegisterRs) ALU_input1 = EX_MEM_ALU_Result; // 旁路前一条指令结果 -
性能对比:旁路技术减少60%以上流水线停顿(数据来源:Hennessy《计算机体系结构》)。
-
Load-Use冲突特殊处理:
- 必须插入1周期气泡(Stall),因LOAD指令结果在MEM段结束才有效,无法旁路到EX段。
-
-
控制冲突的前沿优化
- 动态分支预测进阶:
- 两级自适应预测器:
- 局部历史表(LHT)记录单条指令跳转历史。
- 全局历史表(GHT)记录最近n条指令跳转模式。
- 如Intel Core i7的预测准确率>95%。
- 分支目标缓冲区(BTB) :缓存跳转地址,减少目标计算延迟。
- 两级自适应预测器:
- 延迟槽的局限性:RISC-V已弃用,因编译器难以填充有效指令。
- 动态分支预测进阶:
-
结构冲突的硬件级规避
- 资源动态调度:
- 保留站(Reservation Station) :监控功能单元状态,指令就绪时立即发射(Tomasulo算法)。
- 案例:IBM PowerPC 970的乱序执行引擎支持200条指令动态调度。
- 资源动态调度:
三、性能优化与扩展设计
-
超流水线设计权衡
- 优势:Intel NetBurst架构(Pentium 4)20级流水线,频率提升至3.8GHz。
- 缺陷:
- 分支误预测惩罚高达20周期。
- 功耗激增(漏电流占比超40%),后续架构回归适中流水线(如Core系列14级)。
-
多发射流水线的实现挑战
- 依赖检测硬件:
- 记分牌(Scoreboard) :监控寄存器依赖,每周期发射指令数≤空闲功能单元数。
- 重排序缓冲区(ROB) :保证乱序执行指令按序提交(如AMD Zen 4的192-entry ROB)。
- VLIW(超长指令字)替代方案:
- 编译器静态打包多指令(如TI DSP),硬件简单但灵活性差。
- 依赖检测硬件:
四、常见问题与挑战
-
异常处理的精确中断
- 问题:异常发生时,流水线中可能含未完成指令。
- 方案:
- 指令提交(Commit)后处理异常:ROB机制确保只有退休指令可触发异常。
- 现场保存:EPC寄存器存储异常指令地址,BadVaddr记录内存异常地址。
-
时钟偏移(Clock Skew)问题
- 成因:时钟信号到达不同流水段的延迟差异。
- 解决:
- 时钟树优化(H树结构)。
- 局部时钟缓冲器减少偏移至<10ps。
-
功耗与热管理
- 动态功耗公式:(α翻转率,C负载电容,V电压,f频率)。
- 优化:
- 时钟门控(Clock Gating):空闲流水段关闭时钟信号。
- 电压频率调节(DVFS):负载低时降频降压(如手机SoC)。
五、总结与前沿趋势
- 异构流水线:NVIDIA GPU的SIMT流水线,单指令多线程掩盖访存延迟。
- AI加速指令集:ARM SVE2的可变向量长度指令,动态分配流水线资源。
- 量子流水线探索:IBM Qiskit中的量子操作分段执行,面临退相干时间约束。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)