AI新智力 | 大模型入门14:DeepSeek的系统级工程应用创新
DeepSeek的出现,以其“开源+⾼性价比+强推理力”的模式,打破了过去闭源⼤模型垄断、疯狂砸算力才能出成果的固有观念。它在不依赖顶级GPU资源的情况下,通过多层次创新(数据⾃学习、MoE架构、HAI-LLM框架、PTX底层编程)打造出与GPT-4等闭源⼤模型接近或相当的竞争力。通过“算法-硬件-软件”协同创新优化,以百倍性价比提升改写行业规则,训练成本仅为GPT-4的1/100,推动全球AI研
本文来源公众号“AI新智力”,仅用于学术分享,侵权删,干货满满。
原文链接:大模型入门14:DeepSeek的系统级工程应用创新
“DeepSeek的出现为什么会带来这么大的影响力,有哪些技术创新,对大模型的发展有哪些深刻影响?”

在有限的算力条件下,DeepSeek却训练出了与国际顶尖大模型性能相当甚至在某些方面领先的模型。DeepSeek并没有进行颠覆性的理论创新,仍是基于Transformer架构的大模型,但是在算法、模型、系统和硬件等进行了系统级工程应用创新,将有限的硬件资源性能压榨到极致。DeepSeek的出现打破了大语言模型以大算力为核心的固有发展思路和预期,为受限资源下探索通用人工智能(AGI)开辟了新的道路。DeepSeek的成功归功于其在工程技术上创新应用以及商业模式上的大胆创新。
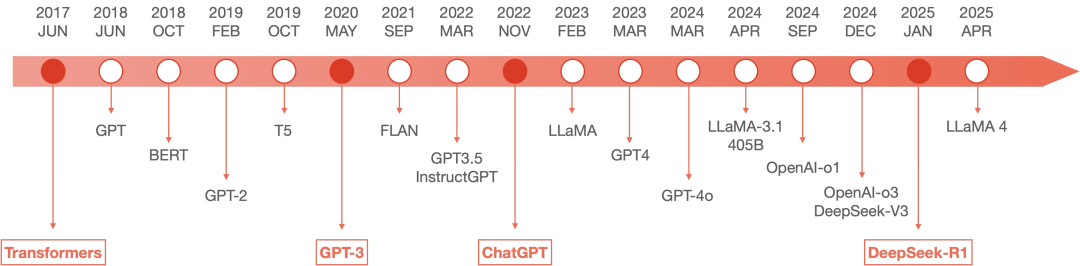
注:上图为截至2025年4月6日的大模型简史,含4月6日MetaAI发布的最新大模型Llama 4。
4月6日,MetaAI发布了最新大模型Llama 4。有意思的是,Llama4全面转向了MoE架构,它发布的Llama 4 Scout、Llama 4 Maverick两个大模型均采用了与DeepSeek相同的MoE架构,这也直接反映了DeepSeek MoE架构的含金量,借此机会本文系统性总结了DeepSeek的技术创新和优势。
模型训练架构创新:MLA+MoE+MTP
DeepSeek在核⼼架构层⾯创新应用了多头潜在注意力(MLA)、混合专家模型(MoE)和Token并行预测机制(MTP),达到了性能和效率兼顾的升级版Transformer架构。虽然没有理论上的核心突破,但是把已知理论方法进行巧妙的组合应用,达到了意想不到的效果。
1. 多头潜在注意⼒(MLA, Multi Head Latent Attention)
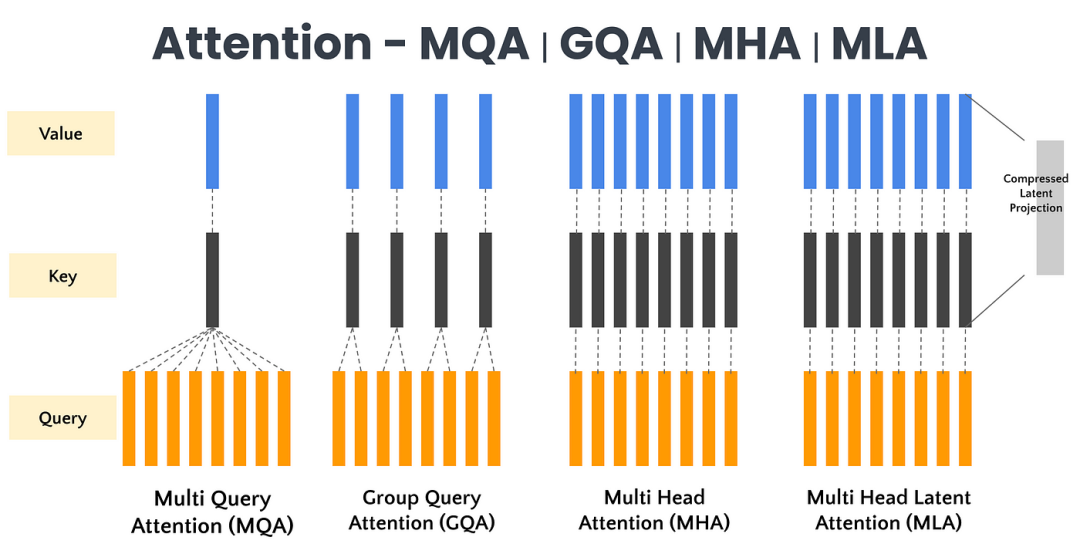
传统多头自注意力需要在长文本时保存庞大的Key/Value矩阵。MLA(Multi-Head Latent Attention,多头潜在注意力)将潜在表示引入注意力机制,以降低计算复杂度并改善上下文表示。与直接处理输入标记的标准注意力机制不同,MLA引入了一组可学习的潜在嵌入,它们在查询、键和值之间起中介作用。这些潜在嵌入捕获高级抽象模式,并实现更有效的跨标记交互。MLA先将Key/Value投影(Projection)到更低维的“隐空间”(Latent Space),大大减少了存储空间和计算量。
MLA降低显存占用,提升运算效率。减少注意力开销,注意力不是关注所有输入标记,而是聚焦在潜在嵌入上,因为Key/Value在投影前就已降维,后续注意力计算量随之降低,从而实现更快的计算。
2. 混合专家模型(MoE, Mixture of Experts)
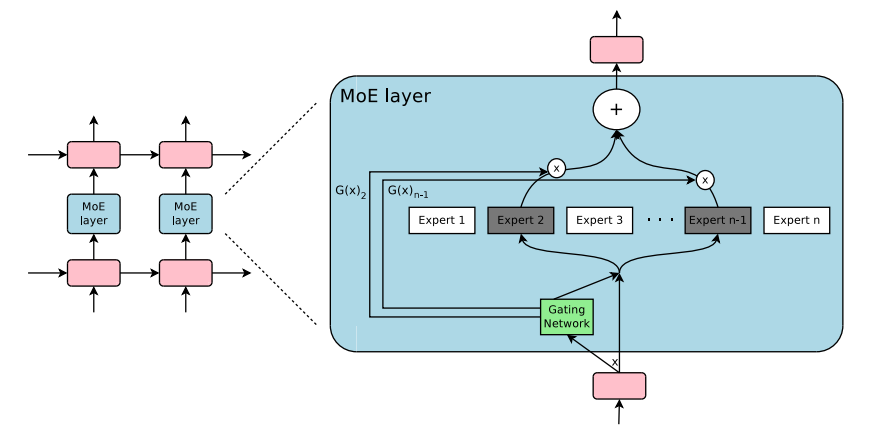
注:图片源自https://huggingface.co/blog/moe
模型规模是提升模型性能的关键因素。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
在传统MoE基础上,DeepSeek进一步进行了改进:
-
无辅助损失的负载均衡策略:传统MoE模型常需额外引⼊均衡损失(如Auxiliary Loss)来防止“热门专家”过载。
-
DeepSeek设计了⼀套可训练偏置(TrainableBias)与动态路由机制,让各专家⾃动分配流量,减轻了额外超参的调优负担。
在⼀次前向推理时,仅激活少数专家来处理输入Token,大大降低实际计算量。例如,DeepSeekV3基座模型总共有6710亿参数,但是每个token仅激活8个专家、370亿参数(仅约为总量的5.5%)。
3. 多Token并行预测优化(MTP, Multi-Token Prediction)
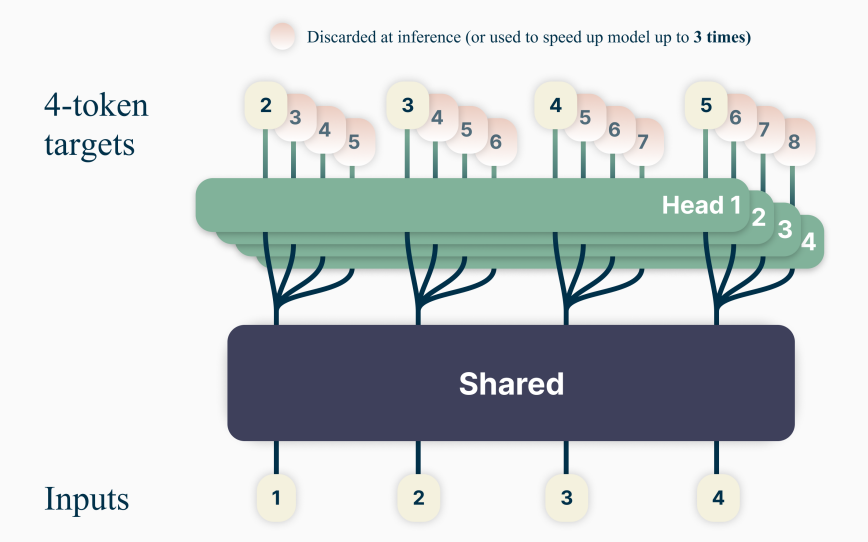
注:图片源自https://arxiv.org/pdf/2404.19737
常规Transformer在训练阶段一次仅生成下⼀个Token,需重复多轮前向传播,MTP则允许在⼀次前向中并⾏预测若⼲后续Token,显著提升训练效率。
4. 达到的效果
-
加速收敛:更多训练信号在同⼀时间段内产⽣;
-
增强连贯性:模型同时考量多个后续Token的交互,有利于生成端的全局语义⼀致性;
-
减少重复计算:在训练阶段显著缩减迭代次数,降低总算力开销。
MLA、MoE、MTP三者结合使得DeepSeek既降低了资源使用量又提升了训练效率,同时又保持了在长序列或复杂推理中的性能表现,这对提升模型质量与降低训练成本起到了决定性作用。
算力调配系统创新:自研轻量级框架
DeepSeek自研HAI-LLM框架(Highly Automated & Integrated LLM Training),极限压榨硬件性能,大幅提升了集群利用率与通信效率。1. 分布式并行框架
DualPipe:将模型拆分为若⼲流⽔段(Pipeline Stage),前向和反向可在流⽔线上重叠执⾏;减少传统流⽔线的空跑时间,避免使GPU在正反向切换时处于空闲状态。
专家并行:反亲和部署专家系统,针对MoE的子网络分配进行并行优化操作,让不同节点处理不同专家;Warp级别对Token路由进⾏调度,保证负载均衡与通信效率。
ZeRO:利用ZeRO(Zero Redundancy Optimizer)原理,将模型的优化器状态、梯度等分块存储在各节点,最⼤化减轻单节点显存压力。通过CPU Offload等技巧进⼀步节省显存,为稀疏激活的超⼤参数规模提供可能。
2. 通信优化与负载均衡
Warp级通信内核:DeepSeek为跨节点All-to-All与路由交换编写了⾃定义CUDA/PTX内核,精确控制Warp级并行度;与InfiniBand+NVLink硬件深度结合,减少“毫秒级延迟”对⼤规模训练的影响。
路由局部化:MoE中各Token只需要路由到少数几个“候选专家”,避免在每⼀步都进行全节点广播,显著降低通信流量;内部监控各专家GPU利用率,动态调度Token流,以防止出现局部过载或闲置。
3. FP8 混合精度与内存管理
FP8混合精度:为进⼀步提升矩阵运算和通信带宽利⽤率,DeepSeek采用FP16+FP8或BF16+FP8混合精度方案。在保持模型收敛稳定性的前提下,大幅提升运算速度,减少显存占⽤。
使用FP8混合精度,DualPipe算法提升训练效率,将训练效率优化到极致,显存占用为其他模型的5%-13%。
激活重计算(Activation Checkpointing):为减小显存负担,正反向计算时只存储必要的激活,在反向需要时再进⾏前向重算;与ZeRO数据并行、CPU Offload相结合,实现超大模型在受限GPU环境下进行训练。
3. 达到的效果
-
算力利用率显著提升。DeepSeek团队宣称在2048张H800 GPU集群上可稳定维持高于85%的GPU使用率;
-
训练周期缩短。DeepSeek V3、R1等级别的超⼤模型训练在约55天内完成,远低于传统⼤模型通常需要的2-3个月或更长时间;
-
通信瓶颈显著降低。Warp级并行和路由局部化的结合,有效减少了大规模All-to-All操作,使每个节点的通信闲置时间降至最低。
底层硬件调用创新:PTX编程优化
1. MoE路由内核
DeepSeek直接在PTX层实现Token-to-Expert的动态分配和通信调度,跳过了高级库可能带来的额外开销。Warp级路由与融合核(Fusion Kernel),减少了不必要的内存拷贝和同步操作。
2. FP8矩阵运算内核
针对混合精度场景,DeepSeek开发了自定义GEMM(通用矩阵乘法)内核,支持FP8/FP16转换及保留必要的数值精度校正;GPU的寄存器和共享内存利用率提升,理论上可比标准CUDA库快10%-20%。
强化学习方法创新:GRPO
训练过程只是提升了大模型的“智商”,训练完成后,我们还要通过强化学习以提升大模型的“情商”。强化学习技术可训练软件做出可最大限度地提高回报的决策,使其结果更加准确、合规。在传统的大模型训练中,都是通过SFT+RLHF的方式进行强化学习,但这需要大量的人工标注和干预,效率低下。DeepSeek引入GRPO并进行创新应用,显著降低对人工标注数据的依赖,大大提高了强化学习的效率和效果。
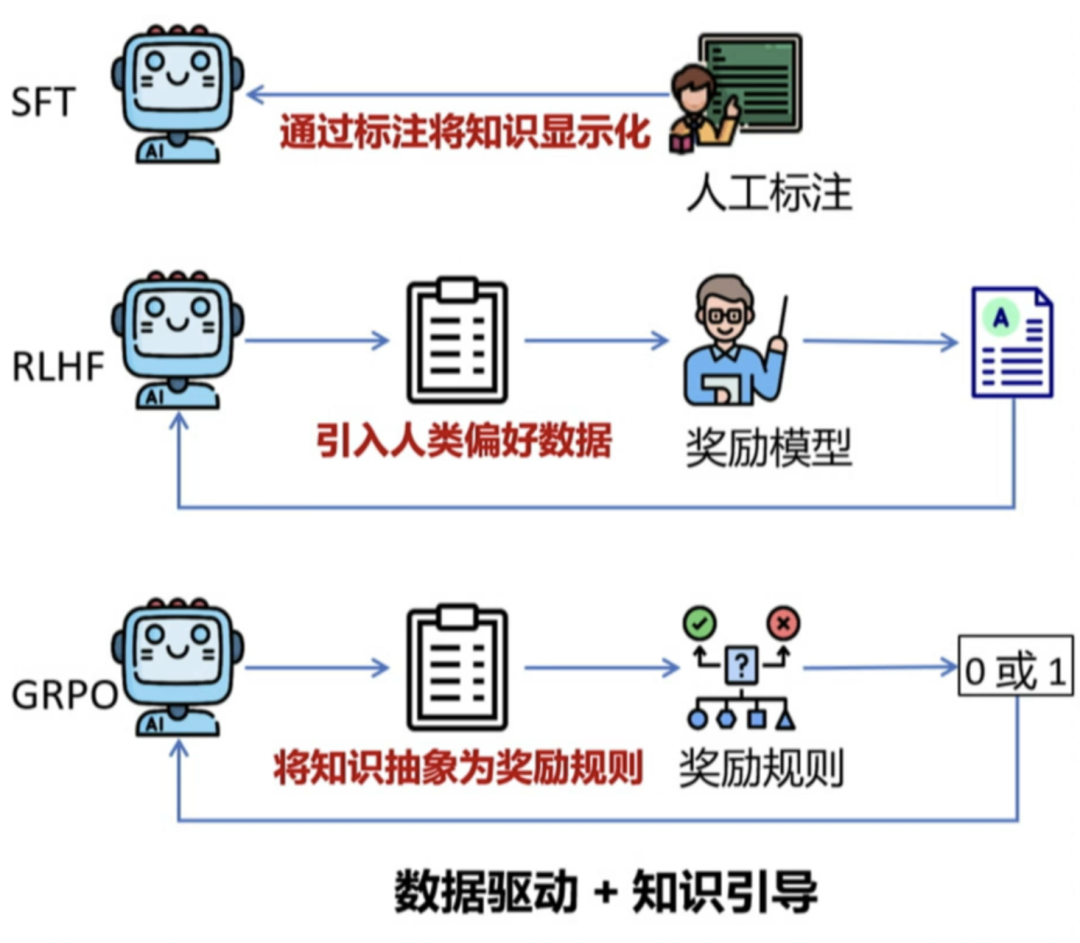
1. GRPO强化学习
DeepSeek使用GRPO进行强化学习来提升模型的推理性能,主要分为四个阶段:
阶段1:初步监督微调。
DeepSeek-R1-Zero生成少量推理数据+SFT=>为V3植入初步推理能力(冷启动)
DeepSeek通过较少量的人工标注数据(仅占总训练样本的极小比例)完成模型的基本对齐。
阶段2:根据规则奖励直接进行强化学习(GRPO)训练,提升推理能力(多轮迭代,获取大量推理数据)。
GRPO并非传统大规模RLHF需要大量人类反馈,而是将新旧策略的回答两两对比,让模型自主选择更优答案,逐步淘汰较差策略,减少对人工干预的依赖。
阶段3:迭代循环自增强。迭代生成推理/非推理样本微调,增强全场景能力:
模型自生成样本:在某些逻辑推理场景里,DeepSeek也会调用自家先前或其他版本模型(如R0、V3的专家组件)生成初步解答,再由新模型进行对比学习或判分。
数据规模与多样性:通过机器自学习机制,可快速扩展到海量的问答/推理对,让模型面对多样化场景;强化学习过程中,“有错误的样本”也能成为宝贵素材,帮助模型持续纠错与收敛。
阶段4:全场景强化学习=>人类偏好对齐(RLHF)。
2. 达到的效果:
-
大幅减少人工成本。传统⼤模型往往需要数百甚⾄上千人进行标注,DeepSeek则依赖机器生成、自动判分,大幅削减了人力投⼊。
-
加速模型自适应。通过自动化强化学习流程,模型能够持续“自纠自学”,更新迭代速度提高。
-
更深度的推理能力。数学、编程等可客观判定的任务特别适合机器评分,让模型得到更丰富、准确的训练反馈,推动了DeepSeek‐R1在严谨推理领域的表现。
总结与展望
DeepSeek的出现,以其“开源+⾼性价比+强推理力”的模式,打破了过去闭源⼤模型垄断、疯狂砸算力才能出成果的固有观念。它在不依赖顶级GPU资源的情况下,通过多层次创新(数据⾃学习、MoE架构、HAI-LLM框架、PTX底层编程)打造出与GPT-4等闭源⼤模型接近或相当的竞争力。通过“算法-硬件-软件”协同创新优化,以百倍性价比提升改写行业规则,训练成本仅为GPT-4的1/100,推动全球AI研发从“暴力计算”转向系统级工程创新。这种“平权化”与“普惠化”路径,对我们国家的大模型发展意义重大,以惊人的速度改写全球科技竞争的格局,也在国际AI竞争格局中提供了宝贵范例。
我们可以大胆的预测,多Token预测(MTP)、MoE架构在很长一段时间都会是大模型架构研究和优化的热门方向(如MetaAI最新发布的Llama4就是一个很好的证明),软硬件协同也会越来越受到重视,开源与闭源的博弈也会继续演化。真切希望DeepSeek及其社区能持续迭代为用户和行业带来价值,为国产大模型再续辉煌。
参考文献:
1. https://huggingface.co/blog/moe
2. https://arxiv.org/abs/2404.19737
3. https://arxiv.org/abs/2501.12948
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献138条内容
已为社区贡献138条内容

所有评论(0)