本科论文抽检档案整理:Python批量文件查找、打包、改名
本文介绍了如何利用Python脚本自动化处理毕业论文抽查的材料整理工作。作者原本需要手动为10名学生逐个重命名论文、查重报告并打包支撑材料,耗时30分钟且易出错。通过ChatGPT辅助编写Python程序,实现了:1)自动读取Excel中的学生信息;2)查找并重命名论文和查重报告文件;3)自动打包支撑材料。经过多次优化,最终代码解决了子目录遍历、文件精确匹配等问题,将30分钟的手工操作缩短至3秒完
一、问题的由来
刚开学,学校教务办下达了进行毕业论文抽查的通知。根据通知的要求,我们需要把指导学生的论文材料根据毕业档案进行整理,每个学生的毕业档案内容如下:
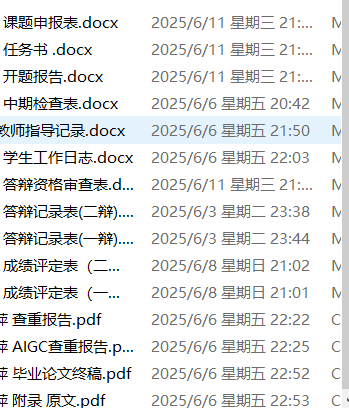
论文抽检要求主要包括以下要求:
1.重命名论文原文pdf,命名方式与《XX学院论文信息汇总表》表X列一致
2.生成支撑材料zip文件,命名方式与《XX学院论文信息汇总表》表Y列一致。
压缩包内含:开题报告(学生姓名+开题报告,word格式)
中期检查表(学生姓名+中期检查表,word)翻译原文(仅翻译专业,学生姓名+翻译原文,pdf)
3.重命名查重报告 pdf,命名方式与《XX学院论文信息汇总表》表Z列一致
以前准备这些资料时,我都是先打开汇总表,复制文件名,然后去更改学生的毕业论文资料信息,如果只是三四个人还好说,可是今年我指导了10个人的论文,每个学生我要复制三个文件名,一个个去改,还要找到压缩包中要求的支撑材料,打包成指定文件名的zip包,一个学生平均花费我3分钟时间,10个人就是30分钟,真的是耗时费力,而且极易出错。怎么能够快速、准确地完成这项任务呢?
二、问题的解决
考虑到这个操作过程主要是读取文件夹、查找文件名、重命名文件、压缩成指定文件名这些操作,而且还是一个重复的过程,并且有规律可循。我又审查了我要处理的文件,虽然文件名中有空格或者+号,同一类文件如论文pdf文件,都有”论文“这个关键词,因此可以通过查找关键词来锁定文件名,然后进行改名等操作。
首先,我先把我指导学生的信息从学院汇总表中复制出来,清除里的格式,单独存放为data.xlsx, 如下图所示。这样做的目的是让Python更好地从本地读取数据信息。
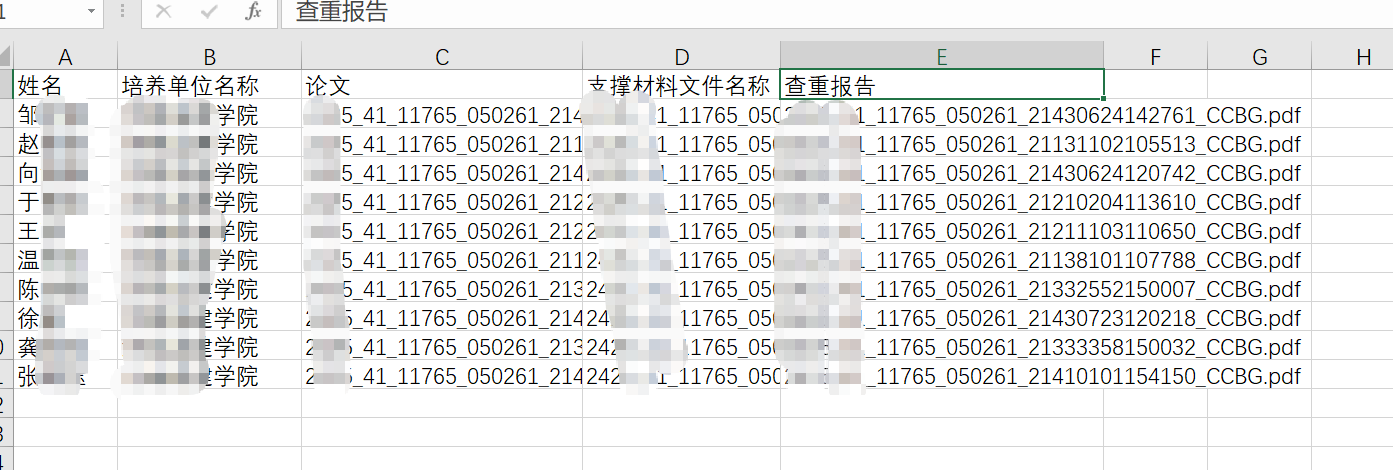
data.xlsx
然后,我把准备好的毕业生的档案信息压缩包解压,这样可以看到每一个文件夹下面都放有一个毕业生所有的毕业论文信息,每些文件夹中都包含有学生的姓名,我们就通过关键词姓名来让程序找到目的文件夹。
接着,我打开ChatGPT,描述我们要操作的过程,由于起初我并不知道要打包那三个文件,所以我在提示词中是要求建一个空的zip,我通过拖动的方法把指定的文件拖进压缩包。所以,我的提示词是这样的,为了准确读取数据,我还把Excel数据表贴了上去,这样便于ChatGPT准确编写数据读取代码。:
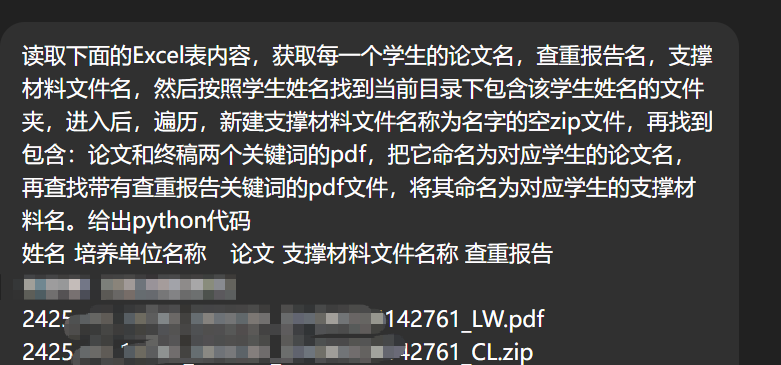
ChatGPT辅助编写代码
ChatGPT很快就给出了我想要的代码,而且对每一行代码都进行了清晰地注释,并能实现以下功能:
1. 读取 Excel 表格中的内容;2. 获取每位学生的 姓名、论文名、支撑材料名、查重报告名;3.在当前目录下找到以学生姓名命名的文件夹;4.学生论文文件夹中:新建一个空的 zip 文件,命名为支撑材料名;5. 查找包含 “论文”和“终稿” 的 pdf,重命名为论文名;6. 查找包含 “查重报告” 的 pdf,重命名为查重报告名。
最终代码如下:
import os
import pandas as pd
import zipfile
import shutil
# Excel 文件路径
excel_file = "students.xlsx" # 替换成你的实际 Excel 文件名
# 读取 Excel
df = pd.read_excel(excel_file)
# 当前工作目录
base_dir = os.getcwd()
for _, row in df.iterrows():
name = row["姓名"]
thesis_name = row["论文"]
support_zip = row["支撑材料文件名称"]
report_name = row["查重报告"]
# 找到学生文件夹
student_dir = os.path.join(base_dir, name)
if not os.path.exists(student_dir):
print(f"未找到 {name} 的文件夹,跳过。")
continue
# 进入学生文件夹
os.chdir(student_dir)
# 1. 新建空 zip 文件
if not os.path.exists(support_zip):
with zipfile.ZipFile(support_zip, "w") as zf:
pass
print(f"已创建 {support_zip}")
# 2. 遍历文件,重命名论文和查重报告
for file in os.listdir(student_dir):
lower_file = file.lower()
# 找论文文件:包含 "论文" 和 "终稿"
if file.endswith(".pdf") and ("论文" in file or "终稿" in file):
new_path = os.path.join(student_dir, thesis_name)
shutil.move(file, new_path)
print(f"{file} 已重命名为 {thesis_name}")
# 找查重报告文件
elif file.endswith(".pdf") and "查重报告" in file:
new_path = os.path.join(student_dir, report_name)
shutil.move(file, new_path)
print(f"{file} 已重命名为 {report_name}")
# 回到上级目录
os.chdir(base_dir)
print("处理完成!")以上代码在测试中,我发现程序找不到【论文】这个key,经过研判原来是data.xlsx数据表中表头中有论文名称列,而没有论文列,造成文件中数据与代码不匹配,所以就报错了。我把数据表中论文名称列改名为论文,然后运行代码成功。但也发现了几个小问题:
1. 当前代码只能遍历当前包含指定人名的目录,如果里面还有子目录就无法遍历,需要把os.listdir()改为os.walk(),这样就能找到子目录里的文件了。
2. 没有对包含有指定关键词的三个PDF文件进行打包重命名,只是生成了一个空压缩包文件。
3. 学生档案中有两个查重报告,其中有一个是AIGC的查重报告,所以改名时还要排除掉AIGC这个关键词。
4. 源代码中数据表名是students.xlsx,改为正确的data.xlsx后,程序就可以成功读取了。
三、代码的优化
针对以上问题,我们对代码进行了优化,主要解决以下三个问题:
1. 利用os.walk()遍历子目录,代码如下:
for root, dirs, _ in os.walk(base_dir):
for folder in dirs:
if name in folder:
student_dir = os.path.join(root, folder)
break
if student_dir:
break2. 确定打包文件名中包含:"开题报告", "中期", "原文"这三个关键词,并且不需要改名。因此可以首先建立一个压缩包,再遍历子目录找到包含三个关键词的不同文件,将它们写入到指定文件名的zip文件中。代码如下所示
# 关键词列表,用于支撑材料打包
keywords = ["开题报告", "中期", "原文"]
# 创建/覆盖 zip 文件
zip_path = os.path.join(student_dir, support_zip)
with zipfile.ZipFile(zip_path, "w") as zipf:
# 遍历学生文件夹及子文件夹
for root, _, files in os.walk(student_dir):
for file in files:
if any(keyword in file for keyword in keywords):
file_path = os.path.join(root, file)
# 添加到 zip,保留相对路径
arcname = os.path.relpath(file_path, student_dir)
zipf.write(file_path, arcname)
print(f"{file} 已加入 {support_zip}")
3. 排除包含AIGC关键词的查重报告,可以通过if判断来实现。
# 3. 重命名查重报告文件(排除 AIGC)
for root, _, files in os.walk(student_dir):
for file in files:
if file.endswith(".pdf") and "查重报告" in file and "AIGC" not in file:
file_path = os.path.join(root, file)
new_path = os.path.join(student_dir, report_name)
shutil.move(file_path, new_path)
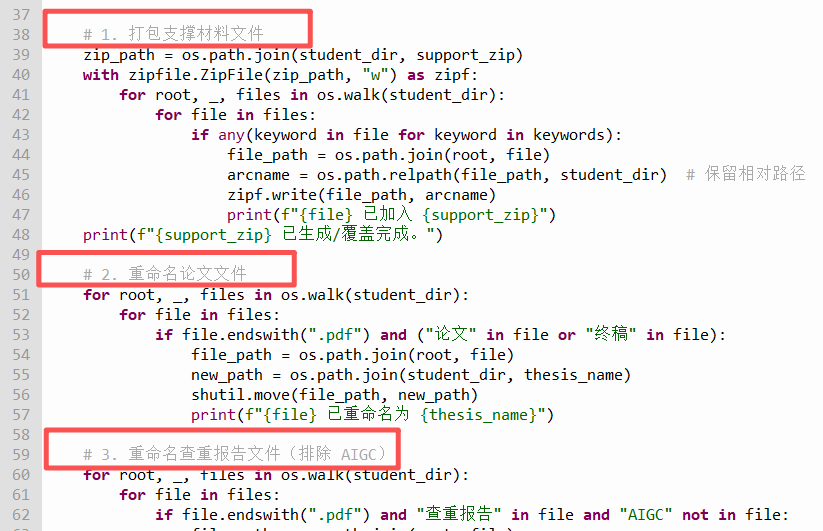
print(f"{file} 已重命名为 {report_name}")四、代码展示
最终,我们借助ChatGPT,自定义了一个60余行Python代码实现了毕业论文的全自动归档,把30分钟的工作任务压缩到3秒钟来完成,工作效率和准确度成倍提升。最终代码如下:
import os
import pandas as pd
import zipfile
import shutil
# Excel 文件路径
excel_file = "data.xlsx" # 替换成你的实际 Excel 文件名
# 读取 Excel
df = pd.read_excel(excel_file)
# 当前工作目录
base_dir = os.getcwd()
# 关键词列表,用于支撑材料打包
keywords = ["开题报告", "中期", "原文"]
for _, row in df.iterrows():
name = row["姓名"]
thesis_name = row["论文"]
support_zip = row["支撑材料文件名称"]
report_name = row["查重报告"]
# 查找包含学生姓名的文件夹(递归)
student_dir = None
for root, dirs, _ in os.walk(base_dir):
for folder in dirs:
if name in folder:
student_dir = os.path.join(root, folder)
break
if student_dir:
break
if not student_dir:
print(f"未找到包含 {name} 的文件夹,跳过。")
continue
# 1. 打包支撑材料文件
zip_path = os.path.join(student_dir, support_zip)
with zipfile.ZipFile(zip_path, "w") as zipf:
for root, _, files in os.walk(student_dir):
for file in files:
if any(keyword in file for keyword in keywords):
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, student_dir) # 保留相对路径
zipf.write(file_path, arcname)
print(f"{file} 已加入 {support_zip}")
print(f"{support_zip} 已生成/覆盖完成。")
# 2. 重命名论文文件
for root, _, files in os.walk(student_dir):
for file in files:
if file.endswith(".pdf") and ("论文" in file or "终稿" in file):
file_path = os.path.join(root, file)
new_path = os.path.join(student_dir, thesis_name)
shutil.move(file_path, new_path)
print(f"{file} 已重命名为 {thesis_name}")
# 3. 重命名查重报告文件(排除 AIGC)
for root, _, files in os.walk(student_dir):
for file in files:
if file.endswith(".pdf") and "查重报告" in file and "AIGC" not in file:
file_path = os.path.join(root, file)
new_path = os.path.join(student_dir, report_name)
shutil.move(file_path, new_path)
print(f"{file} 已重命名为 {report_name}")
print("全部学生处理完成!")
五、结语
1. 对于一些批量的、有规律的文件操作包括:查找、改名、移动、删除、创建、打包等操作均可以使用Python来替代人工来解决。解决问题的关键是准确向人工智能工具描述你要做的工作,预期要达到什么目标,涉及的文件名、路径等信息都要明确给出,提升代码的准确率和适用性。
2. 即使是你再准确描述,可能由于实际情况的复杂性,运行代码时也难免出错,或者出现执行不到位、不全面的情况,此时要认真查看报错信息,明确出错的代码位置,通过人工智能辅助排查、个人独立判断来解决。
3. ChatGPT-5的辅助代码生成功能更强,它会把执行步骤清楚地注释出来 ,结构化的编程过程大大提升了编程者的逻辑思维和解决问题的能力,我们可以学习它代码编写的逻辑为我们独立完成任务积累宝贵的经验。
4. 如果由于网络原因无法使用ChatGPT,可以找它的平替如:DeepSeek、豆包、质普清言来实现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)