看、听、记与推理:具备长期记忆的多模态智能体
这篇论文的创新是提出 M3-Agent,把视频/音频流转成“实体中心”的情节记忆+语义记忆,并用RL训练的多轮检索-推理控制器在记忆上迭代推理(模型生成问题去查询,优于单轮RAG),并以 M3-Bench 长视频跨模态基准验证其有效性。
文章目录
Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
字节跳动 Seed;浙江大学;上海交通大学
arxiv’25’08
这篇论文的创新是提出 M3-Agent,把视频/音频流转成“实体中心”的情节记忆+语义记忆,并用RL训练的多轮检索-推理控制器在记忆上迭代推理(模型生成问题去查询,优于单轮RAG),并以 M3-Bench 长视频跨模态基准验证其有效性。
摘要
我们提出了 M3-Agent,这是一种新型的具备长期记忆的多模态智能体框架。与人类相似,M3-Agent 可以处理实时的视觉和听觉输入,以构建和更新其长期记忆。除了情景记忆外,它还会发展语义记忆,从而能够随着时间的推移积累世界知识。其记忆以实体为中心的多模态形式组织,从而对环境形成更深入和一致的理解。在接收到指令时,M3-Agent 会自主地执行多轮迭代推理,并从记忆中检索相关信息来完成任务。
为了评估多模态智能体的记忆有效性和基于记忆的推理能力,我们提出了 M3-Bench,这是一项新的长视频问答基准。M3-Bench 包含 100 段新录制的从机器人视角采集的真实世界视频(M3-Bench-robot)以及 920 段来自网络、涵盖多样场景的视频(M3-Bench-web)。我们为其标注了问答对,以测试智能体应用中的关键能力,如对人的理解、通用知识提取和跨模态推理。实验结果表明,经过强化学习训练的 M3-Agent 优于最强基线——基于提示的 Gemini-1.5-pro 和 GPT-4o 代理,在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上的准确率分别提高了 6.7%、7.7% 和 5.3%。
我们的工作推动了多模态智能体向更接近人类的长期记忆发展,并为其实际设计提供了新的见解。模型、代码和数据已在以下地址开源:
https://github.com/bytedance-seed/m3-agent
日期: 2025 年 8 月 18 日
通讯作者: linyuan.0@bytedance.com
项目页面: https://m3-agent.github.io
250904:他这个摘要在写的时候,没有针对现有一个任务存在某种挑战去写,而是直接说自己做了什么,能实现什么。

1 引言
设想在未来,一台家用机器人能够在没有明确指令的情况下自主完成家务;它必须通过日常经验学习到你家中的运行规则。早晨,它会递给你一杯咖啡,而不会问“要咖啡还是茶?”,因为它在长期交互中逐渐形成了对你的记忆,追踪你的偏好和日常习惯。对于多模态智能体而言,实现这样的智能水平根本上依赖于三种能力:(1)通过多模态传感器持续感知世界;(2)将其经验存储在长期记忆中,并逐步构建关于环境的知识;(3)在这些积累的记忆上进行推理,以指导其行动。
为实现这一目标,我们提出了 M3-Agent,这是一种具备长期记忆的新型多模态智能体框架。如图 1 所示,它通过两个并行过程运行:记忆(memorization),持续感知实时多模态输入以构建和更新长期记忆;以及控制(control),解释外部指令、在存储的记忆上进行推理,并执行相应任务。
在记忆阶段,M3-Agent 处理输入的视频流,通过生成两种类型的记忆来捕捉细粒度细节和高层抽象,这类似于人类的认知系统 [42, 43]:
-
情景记忆(Episodic memory):记录视频中观察到的具体事件。例如,“Alice 拿起咖啡并说:‘早晨没有这个我可不行,’” 和 “Alice 把一个空瓶子扔进了绿色垃圾桶。”
-
语义记忆(Semantic memory):从视频片段中提炼出一般知识。例如,“Alice 喜欢在早晨喝咖啡” 和 “绿色垃圾桶用于回收。”
生成的记忆随后被存储在长期记忆中,该记忆支持多模态信息,如人脸、声音和文本知识。此外,记忆以以实体为中心的结构进行组织。例如,与同一人相关的信息(如面部、声音和相关知识)会以图的形式相连接,如图 1 所示。随着智能体提取和整合语义记忆,这些连接会逐步建立。
在控制阶段,M3-Agent 利用其长期记忆进行推理和完成任务。它能够自主地从长期记忆中跨越不同维度(如事件或人物)检索相关信息。而不是使用单轮的检索增强生成(RAG)来将记忆加载到上下文中 [20],M3-Agent 采用强化学习,以支持多轮推理和迭代记忆检索,从而获得更高的任务成功率。
记忆任务与长视频描述相关 [11, 16, 55],但更进一步,引入了两个关键挑战:(1)无限信息处理(Infinite information processing)。记忆需要处理无限长的输入流。现有方法通常优化架构效率以处理更长的输入,但仍然是离线视频 [12–38, 40, 56]。相比之下,M3-Agent 可以持续处理任意长的多模态流,更加贴近人类通过持续经验和逐步整合形成长期记忆的方式。(2)世界知识构建(World knowledge construction)。传统的视频描述 [1, 22, 24, 25, 53] 往往侧重于低层次的视觉细节,而忽略了高层次的知识建模 [10, 17, 34],例如角色身份和实体属性,这在长期语境下可能导致歧义和不一致。M3-Agent 通过在以实体为中心的记忆结构中逐步构建世界知识来解决这一问题,从而形成丰富的关键实体多模态表征,使得上下文连贯且一致。
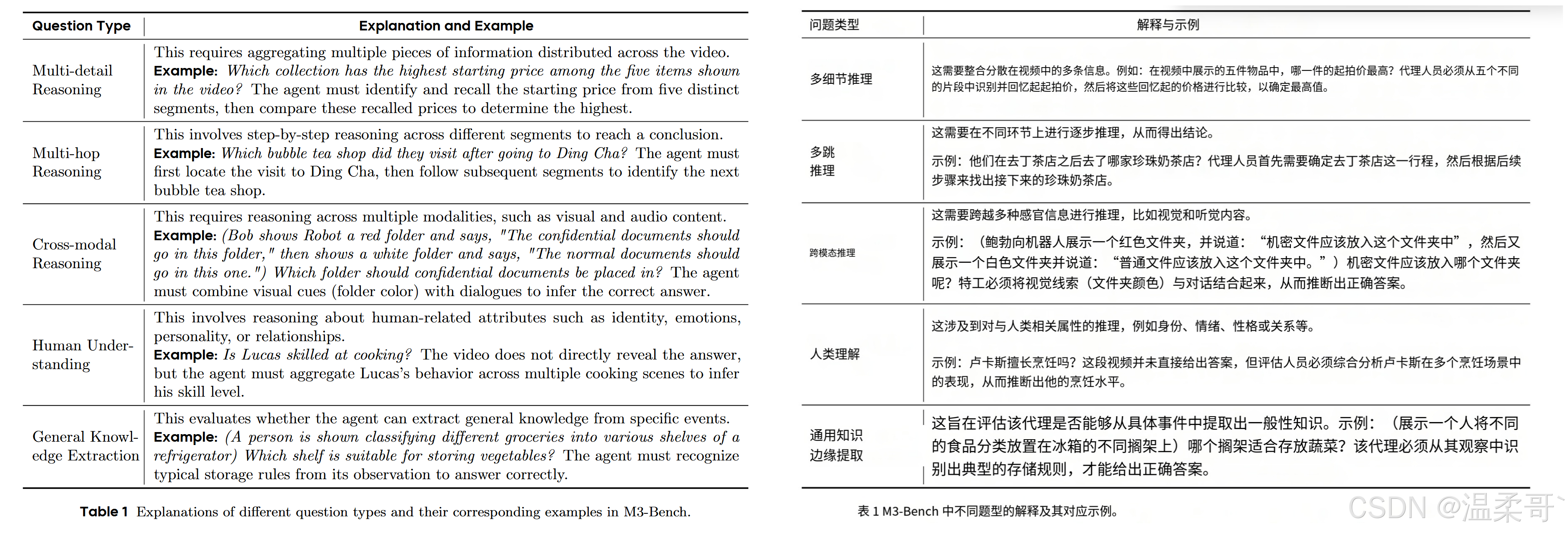
我们在长视频问答(LVQA)任务上评估 M3-Agent,其中视频模拟了智能体接收的多模态输入流(视觉和听觉)。大多数现有的 LVQA 基准 [2, 9, 48, 60] 主要集中于视觉理解,如动作识别和空间/时间推理,从而在评估依赖长期记忆的高层次认知能力方面留下空白,而这些能力对于现实世界中的智能体至关重要,如理解人类、提取通用知识和执行跨模态推理。为弥补这一差距,我们引入了 M3-Bench,这是一个新的 LVQA 基准,旨在评估多模态智能体利用长期记忆进行推理的能力。M3-Bench 包含来自两个来源的视频:(1)M3-Bench-robot,包括 100 段从机器人视角录制的真实世界视频;(2)M3-Bench-web,包括 920 段涵盖广泛内容和场景的 YouTube 视频。我们定义了五类问题类型,如表 1 所示,针对记忆推理的不同方面。总体而言,我们为 M3-Bench-robot 标注了 1,276 个问答对,为 M3-Bench-web 标注了 3,214 个问答对。
我们在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long [9] 上进行实验。结果表明,经过强化学习训练的 M3-Agent 在所有基准上均优于所有基线。与最强的基线 Gemini-GPT4o-Hybrid 相比(该方法通过提示 Gemini-1.5-Pro [41] 完成记忆、GPT-4o [15] 完成控制来实现 M3-Agent 框架),M3-Agent 的准确率在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上分别提升了 6.7%、7.7% 和 5.3%。我们的消融实验表明语义记忆的重要性:去除语义记忆会分别在三个基准上导致 17.1%、19.2% 和 13.1% 的准确率下降。此外,我们还研究了强化学习训练、多轮指令和推理模式对控制性能的影响。具体来说,强化学习训练在三个基准上的准确率分别提升了 10.0%、8.0% 和 9.3%;去除多轮指令导致准确率下降 10.5%、5.8% 和 5.9%;而禁用推理模式则导致准确率下降 11.7%、8.8% 和 9.5%。
本文的主要贡献总结如下:
-
我们提出了 M3-Agent,这是一种具备长期记忆的新型多模态智能体框架。M3-Agent 能够持续处理实时多模态输入(看与听),通过生成情景记忆和语义记忆来逐步构建世界知识(记),并在这些记忆上进行推理以完成复杂指令(推理)。
-
我们提出了 M3-Bench,这是一个新的 LVQA 基准,旨在评估多模态智能体记忆和基于记忆推理的有效性。
-
我们的实验表明,经过强化学习训练的 M3-Agent 在多个基准上持续优于基于提示的商业模型。
2 相关工作
2.1 人工智能体的长期记忆
长期记忆对人工智能体至关重要 [8],它使智能体能够保留远距离的上下文信息,并支持更高级的推理。一种常见的方法是将整个智能体轨迹(如对话 [27, 31, 44, 59] 或执行轨迹 [14, 27, 29, 35, 36, 46])直接附加到记忆中。除了原始数据之外,一些方法还引入了摘要 [14, 21, 44, 59]、潜在嵌入 [6, 28, 40, 56] 或结构化知识表征 [33, 50]。最新的系统进一步构建了复杂的记忆架构,使智能体能够更精细地控制记忆管理 [5, 18, 44]。
然而,大多数现有方法主要集中于大语言模型(LLM)智能体。相比之下,多模态智能体需要处理更广泛的输入,并在记忆中存储更丰富的多模态内容和概念。这也带来了新的挑战,特别是在保持长期记忆一致性方面。此外,正如人类通过经验获取世界知识一样,多模态智能体也应在记忆中形成内部的世界知识,而不仅仅是存储经验的描述。
2.2 在线视频理解
对于多模态智能体而言,记忆的形成与在线视频理解密切相关。在线视频理解是一项具有挑战性的任务,它要求对视频流进行实时处理,并基于过去的观察进行决策。传统的长视频理解方法,如扩展多模态模型的上下文窗口 [4, 58] 或压缩视觉 token 以增加时间覆盖范围 [19, 47, 47],无法有效扩展到无限长的视频流。在实际场景(如交互式智能体任务)中,为每个新指令重新处理整个视频历史在计算上是不可行的。
为提升可扩展性,基于记忆的方法 [12, 40, 56, 57] 引入了记忆模块,用于存储编码的视觉特征以供未来检索。这些架构适用于在线视频处理。然而,它们面临一个根本性限制:维持长期一致性。由于这些方法仅存储视觉特征,因此难以在长期内保持对实体(如人类身份或不断演变的事件)的连贯追踪。
随着大规模多模态和语言模型的快速发展 [1, 15, 41, 51, 53],Socratic Models 框架 [26, 54, 55] 已成为在线视频理解的一种有前景的方法。通过利用多模态模型生成视频描述作为基于语言的记忆,该方法提高了可扩展性。然而,它在保持复杂、动态演变的视频内容的长期一致性方面仍然面临挑战。
3 数据集
在本节中,我们介绍 M3-Bench,这是一个 LVQA 数据集,旨在评估多模态智能体在长期记忆上的推理能力。M3-Bench 中的每个样本包含一段模拟智能体感知输入的长视频,以及一系列开放式的问答对。该数据集分为两个子集:(1)M3-Bench-robot,包含 100 段从机器人第一视角录制的真实世界视频;(2)M3-Bench-web,包含 920 段从网络收集的视频,涵盖更广泛的内容和场景。为了全面评估智能体回忆过去观察并进行基于记忆推理的能力,我们设计了五类不同的问题,如表 1 所示。总体而言,M3-Bench 的特点是:(1)长时长的真实世界视频,涵盖多样的现实场景,与多模态智能体的部署密切相关;(2)具有挑战性的问题,这些问题超越了浅层的感知理解,要求在长期语境下进行复杂推理。
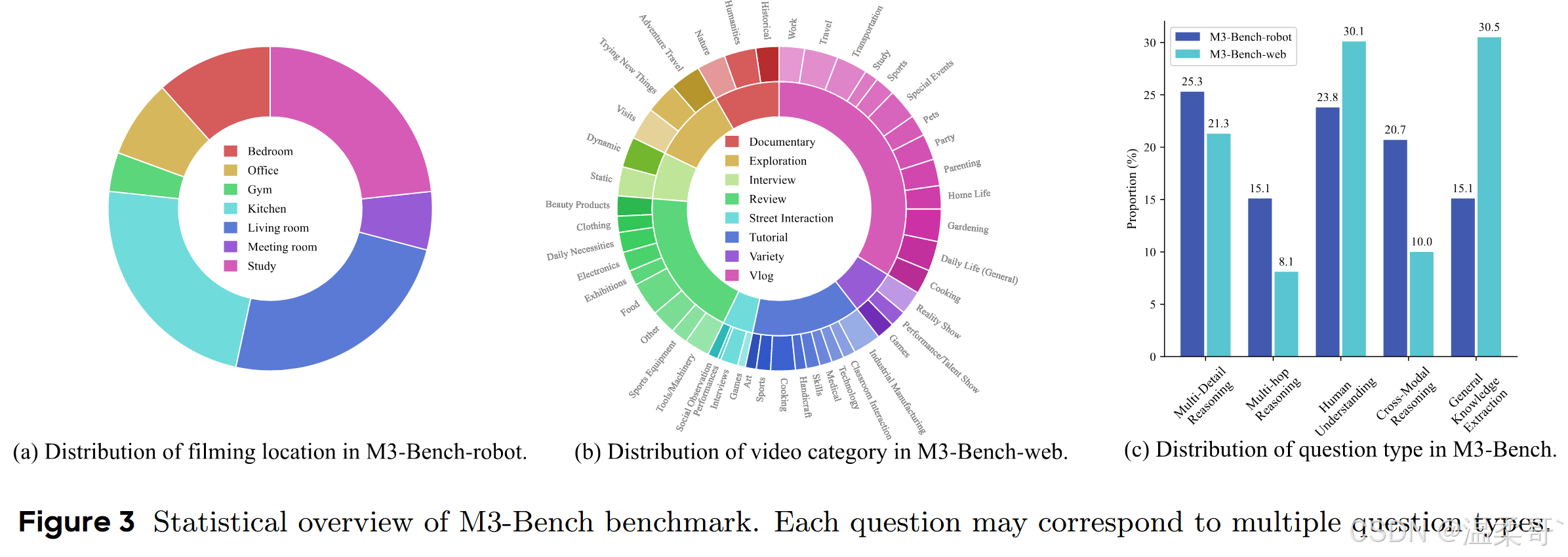
图 2 展示了来自 M3-Bench 的示例。M3-Bench 的总体统计信息如图 3 所示。表 2 提供了与现有 LVQA 基准的对比分析。本节的其余部分将分别阐述 M3-Bench-robot 和 M3-Bench-web 的数据收集与标注过程。

250904:“O/C” 表示题目形式里既有开放式(Open-ended)也有封闭式(Close-ended/选择题);
“Agent Present”指的是:视频里是否有一个具身的“智能体”在场并作为情境的核心参与者——通常就是拿着相机/第一人称视角的机器人或助手,它会在环境中感知、行动、并持续记忆(而不是纯第三人称的旁观式录像)。
3.1 M3-Bench-robot
机器人是多模态智能体的典型代表。通用服务机器人应当能够维持长期记忆并基于记忆进行推理,以指导其行动。例如,在处理观察信息时,机器人可能会记住一个人的名字、他们放外套的位置,或他们的咖啡偏好。基于长期记忆的推理能够支持更高层次的认知功能,如推断一个人的性格、理解人与人之间的关系,或识别周围物体的功能。为了系统地评估这些能力,我们录制了一组新的机器人视角视频,并手动标注相应的问答对。
脚本设计(Scripts Design) 我们首先为 M3-Bench-robot 设计视频脚本,涵盖七个日常场景,机器人通常被期望在这些场景中运行:客厅、厨房、卧室、书房、办公室、会议室和健身房。每个脚本涉及一个机器人与两到四个人类的互动。标注者被要求设计出反映通用服务机器人理想能力的人机交互。
为保证脚本内容的多样性,我们为每个场景引入了多个主题变体。例如,客厅场景可能包括与朋友见面、进行家庭对话或举办感恩节聚会等主题。标注者会为每个主题撰写一个脚本,从而确保脚本的广覆盖性和高变异性。具体来说,每个脚本被设计为一系列离散的事件和问题。一些事件被设计为参考事件,包含与未来问题相关的信息。问题可能出现在事件序列中的任意时刻或脚本的末尾。当问题出现在事件序列中时,它们通常与当前情节紧密相关;移动这些问题可能会改变其答案或影响难度。一个示例脚本在表 8 (§ A.5) 中给出。
为保证视频内容的复杂性和下游视频拍摄与标注的质量,标注者必须满足以下标准:
- 标注至少 15 个问题,每个问题都要标注用于回答它的参考事件。
- 确保每个问题至少对应表 1 中列出的一个问题类型。
- 每个脚本必须包含至少 70 个事件,以保证视频时长不低于 30 分钟。
视频拍摄(Video Filming) 使用真实机器人进行视频拍摄会带来显著挑战,包括高昂的运行成本、硬件限制和部署复杂性。为解决这些约束,我们采用了一种实用替代方案:使用人类演员来模拟机器人行为。这种方法简化了数据采集,同时保留了机器人第一视角和基准所需的多模态质量。
每个脚本涉及多个演员,其中一人被指定模拟机器人。该演员佩戴头戴式摄像设备,从而捕捉机器人的自我中心视觉和听觉视角。最终生成的画面构成了 M3-Bench-robot 的视频。为确保多样性并尽量减少场景偏差,我们共招募了 67 名演员,并在 51 个不同地点拍摄,每个地点不超过三段视频。
我们为每段视频采集了两种音轨。第一种由头戴设备直接录制,反映了机器人自然接收到的原始听觉输入,包括环境声音和空间声学变化。第二种通过每位演员佩戴的领夹麦克风采集,提供高保真语音录音,以补充主要的音频流。
标注(Annotations) 在录制视频后,标注者为每个视频制作 QA 对。尽管部分问题是预先编写的,但由于真实拍摄条件,最终视频内容可能偏离原始脚本。因此,并非所有脚本问题都依然适用。标注者会仔细审查每个脚本问题,以决定是否保留、修改或删除,并在必要时提供对应答案。对于所有保留或修改的问题,标注者必须指定该问题应被提出的精确时间戳。需要注意的是,时间戳必须早于机器人的相应动作或反应,以避免无意间暴露答案。
除了基于脚本的问题外,标注者还需创建新的问题,以确保每个视频包含至少 12 个 QA 对。所有新增问题也必须对应表 1 中列出的一个或多个问题类型。
除了 QA 对的创建之外,标注者还为视频生成字幕,以增强数据集的可用性。具体而言,他们手动标注每段对话的起止时间戳,以及说话者身份和转写的对话内容。
M3-Bench-robot 的完整标注指南、标注者信息以及质量控制细节见附录 A。
3.2 M3-Bench-web
为进一步增加视频的多样性,我们依据现有实践 [7, 9, 32],从 YouTube 收集了额外的视频。
视频收集(Video Collection) 视频收集采用了一种问题驱动的方法:标注者选择能够支持设计至少五个问题(问题类型见表 1)的视频。这一策略自然地引导我们选择叙事丰富、实体间关系复杂的视频,非常适合用于评估智能体的长期记忆推理能力。
为促进视频多样性并避免易于标注内容的过度代表,我们向标注者提供了一份视频类别参考清单,重点突出信息密度高且与现实世界多模态智能体应用相关的类别。标注者需要为每个类别提交最多 20 个视频,并被允许提出新的类别。如果作者认为这些新类别与现有类别足够不同,则会将其纳入。最终数据集包含 46 种不同的视频类型,如图 3 所示。
问答标注(QA Annotations) 收集视频的标注者还需为每个视频生成至少五个对应的问答对。每个问题必须对应表 1 中定义的至少一种类型。在 M3-Bench-web 中,所有问题的时间戳都设置在视频的结尾。所有问题都必须具体、客观,并且有一个单一且明确的答案,该答案应当能够合理地从视频线索中推导出来,以确保后续评估的有效性和公平性。例如,涉及多重视角或含糊指代的问题(如 “the man” 或 “in the middle part of the video”)不被视为有效问题。
附录 B 提供了 M3-Bench-web 的完整标注指南、标注者信息和质量控制细节。
3.3 自动评估
我们使用 GPT-4o 作为 M3-Bench 的自动评估器,通过提示它来判断生成答案的正确性,即将其与同一问题的参考答案进行比较。提示模板如表 18 (§ H.1) 所示。
为验证 GPT-4o 作为可靠评估者的有效性,我们构建了一个包含 100 个随机抽取样本的测试集,每个样本由一个问题、其参考答案,以及来自我们方法或各种基线 (§ 5.1) 的生成答案组成。三位作者独立评估每个生成答案的正确性,并将 GPT-4o 的判断与人工标注的多数投票结果进行比较。GPT-4o 与人工评判的一致率达到 96%,从而确认了其作为自动评估器的有效性。
4 方法
如图 1 所示,M3-Agent 由一个多模态大语言模型(LLM)和一个长期记忆模块组成。它通过两个并行过程运行:记忆(memorization),用于持续处理任意长的视频流并构建终身记忆;以及控制(control),用于基于长期记忆进行推理并执行指令。在接下来的小节中,我们将分别详细介绍长期记忆存储、记忆过程和控制过程。
4.1 长期记忆
长期记忆被实现为一个外部数据库,用于以结构化的多模态形式(文本、图像、音频)存储信息。具体来说,记忆条目被组织为一个记忆图,其中每个节点代表一个独立的记忆项。每个节点包括唯一 ID、模态类型、原始内容、权重、嵌入以及其他元数据(如时间戳)。详情见表 3。节点之间通过无向边相连,这些边捕捉记忆项之间的逻辑关系,并作为检索相关记忆的线索。
智能体通过逐步添加新的文本、图像或音频节点及其连接边,或通过更新现有节点的内容和权重来构建记忆。在构建过程中可能会引入相互冲突的信息。为解决这一问题,M3-Agent 在推理时采用了一种基于权重的投票机制:被更频繁强化的条目会累积更高的权重,从而能够覆盖权重较低的冲突条目。该机制确保了记忆图随时间推移的鲁棒性和一致性。
检索工具(Search Tool) 为方便记忆访问,我们提供了一套搜索工具,使智能体能够根据特定需求检索相关记忆。具体来说,我们实现了两类在不同粒度水平上运行的搜索机制,概要见表 4。这些检索机制的详细实现见附录 C。
4.2 记忆过程
如图 1 所示,在记忆阶段,M3-Agent 逐段处理输入的视频流,生成两类记忆:情景记忆,捕捉来自原始视频的视觉和听觉内容;以及语义记忆,提取角色身份、属性、关系及其他世界知识等一般性知识。语义记忆不仅丰富了记忆内容,还提供了额外的检索线索,从而增强了控制过程中的检索效果。
一致的实体表征(Consistent Entity Representation) 构建高质量长期记忆的关键挑战在于如何在任意长的时间跨度中保持核心概念(如主要角色和对象)的稳定表征。现有方法通常会生成基于语言的描述,如“一个留胡子的男人”或“一个穿红裙子的女人”。然而,这类文本描述本身存在歧义,并且在长期累积时容易出现不一致性。为解决这一问题,M3-Agent 保留了原始的多模态特征,并在长期记忆中构建持久的身份表征。这种方法为长期一致性提供了更稳定和鲁棒的基础。
具体而言,我们为 M3-Agent 配备了一套外部工具,包括人脸识别和说话人识别。这些工具会提取片段中出现的面部和声音,并返回它们在长期记忆中的对应身份。每个提取到的人脸或声音都会与现有节点(通过 search_node 函数)对应,或被分配到一个新创建的节点。生成的标识符(face_id 或 voice_id)作为持久的引用与对应角色相连接。通过利用全局维护的记忆图作为统一结构,M3-Agent 能够保证来自不同片段的局部记忆之间的身份映射一致,从而形成连贯的长期记忆。
这种方法还可以推广到更多概念的编码,如关键位置或对象,从而进一步提高记忆生成的一致性。两类工具的详细实现见附录 C。
记忆生成(Memory Generation) 在获取了人脸和声音的身份后,M3-Agent 会继续生成情景记忆和语义记忆。每个角色必须通过其 face_id 或 voice_id 被引用。例如:
"<face_1> wears a red hat and blue top,""<voice_2> speaks to <face_3>, 'How are you doing today?'"
这种机制确保每个角色都能够与存储在长期记忆中的物理特征明确对应。特别是在语义记忆中,M3-Agent 能够执行跨模态推理,从而推断不同实体 ID 之间的关系(例如,将一张人脸与其对应的声音关联为同一人)。这些推断出的等价关系随后可用于更新记忆图中人脸节点与声音节点之间的连接。一旦建立连接,该对实体会被视为一个统一的角色。在检索过程中,连接的节点会统一到共享的 <character_id> 下,使模型能够更一致地在跨模态条件下进行角色推理。
在输出格式方面,M3-Agent 将情景记忆和语义记忆均生成为文本条目的列表。每个条目都作为文本节点存储在记忆图中,实体 ID 关系则作为边表示。如在记忆存储中所述,冲突信息通过投票机制来解决。例如,<voice_3> 对应 <face_0>,但在一些具有挑战性的片段中,系统可能会临时将其链接到另一张人脸。随着时间推移,正确的关联不断积累,正确映射的权重(如 <voice_3>, <face_0>)会增加并占据主导。这使得系统能够在存在局部错误时依然稳健地学习并保持准确的知识。
4.3 控制过程
当接收到指令时,控制过程会被触发。如图 1 所示,在控制阶段,M3-Agent 会自主地执行多轮推理,并调用搜索函数从长期记忆中检索相关信息,最多可执行 H H H 轮。M3-Agent 可以自主决定调用哪种搜索函数,例如使用 search_clip 来检索特定的记忆片段,或使用 search_node 来获取某一特定角色的角色 ID。
具体来说,M3-Agent 中的多模态大语言模型(MLLM)可以被视为策略模型 π θ \pi_\theta πθ。给定一个问题 q q q 和当前的长期记忆 M \mathcal{M} M,控制过程会按照算法 1 来执行。为支持该过程,我们设计了三类提示词:(1)系统提示(system prompt):在每个会话开始时添加,用于指定整体任务目标;(2)指令提示(instruction prompt):在每一轮开始时(最后一轮除外)添加,用于提供问题和详细指导;(3)最后一轮提示(last-round prompt):仅在最后一轮使用,用于提示智能体这是最后一次作答机会。具体的提示词如表 22 (§ H.3) 所示。

4.4 训练
我们采用强化学习来优化 M3-Agent。尽管记忆和控制在概念上由单一模型处理,但我们训练了两个独立的模型以实现最佳性能。记忆依赖于强大的多模态理解能力,而控制需要强大的推理能力。因此,我们分别使用不同的基础模型来初始化:Qwen2.5-Omni [49](一种先进的开源多模态模型,支持视觉和音频输入)用于记忆;Qwen3 [51](一种具备强大推理能力的开源大语言模型)用于控制。
训练数据来自我们自有的视频数据集,我们已获得使用许可。我们收集视频及其对应的问答对,并遵循与 M3-Bench-web 相同的标注标准。总体而言,训练数据集包含 500 段长视频,相当于 26,943 个 30 秒片段,以及 2,736 个问答对。
记忆(Memorization) 为提高模型生成期望记忆的能力,我们在 Qwen2.5-Omni-7b 上进行模仿学习,构建 memory-7b-sft。该过程首先构建一个高质量的合成示范数据集。我们将数据集中的每个视频分割为 30 秒片段,并通过三阶段流程生成对应的记忆标注:
- 情景记忆合成(Episodic memory synthesis):我们通过联合调用 Gemini-1.5-Pro 和 GPT-4o 执行混合标注策略。其中 GPT-4o 提供帧级线索,作为 Gemini-1.5-Pro 的先验,两者的输出合并以生成更丰富的叙事摘要。
- 身份等价检测(Identity equivalence detection):我们提出一种算法,能够自动挖掘高置信度的 meta-clips(仅包含一个人脸和一个声音的短独白片段),并利用它们从长视频中构建全局的人脸-声音对应关系。这些 meta-clips 提供清晰的身份线索,使人脸-声音配对更准确。一旦全局映射建立,就可以用于自动标注任意 30 秒子片段中的人脸-声音关联。
- 其他语义记忆合成(Other semantic memory synthesis):我们设计提示模板,从不同角度提取语义记忆,引导语义记忆涵盖表 10 (§ D) 所列的信息。

数据合成过程的详细信息见附录 D。总体上,我们合成了 10,952 个样本,其中 10,752 用于训练,200 用于验证。
微调训练进行了 3 个 epoch,学习率为 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5,batch size 为 16,使用 16 块 80GB 显存的 GPU。
控制(Control)
我们首先为强化学习(RL)训练搭建环境。对于数据集中的每个视频,我们使用 memory-7b-sft 生成对应的长期记忆。对于任意给定的问题,智能体仅能在由该视频生成的记忆中进行检索。
随后,我们使用 DAPO [52] 训练策略模型 π θ \pi_\theta πθ,其初始化来源于 control-32b-prompt。对于训练数据集 D \mathcal{D} D 中采样的每个问答对 ( q , a ) (q, a) (q,a),策略 π θ \pi_\theta πθ 会 rollout 一组 G G G 条轨迹 τ i G \tau_i^G τiG,并使用算法 1 进行推理。对于每条轨迹 τ i \tau_i τi,最终提交的答案 y i y_i yi 会被提取,并使用第 3.3 节介绍的 GPT-4o 评估器进行评估。第 i i i 条轨迹的奖励定义如下:
R i = { 1 , 若 g p t 4 o _ e v a l u a t o r ( q , a , y i ) = True 0 , 否则 (1) R_i = \begin{cases} 1, & \text{若 } gpt4o\_evaluator(q, a, y_i) = \text{True} \\ 0, & \text{否则} \end{cases} \tag{1} Ri={1,0,若 gpt4o_evaluator(q,a,yi)=True否则(1)
接着,通过对组级奖励 { R i } i = 1 G \{R_i\}_{i=1}^G {Ri}i=1G 进行归一化来计算第 i i i 个回答的优势函数:
A ^ i , t = R i − mean ( { R i } i = 1 G ) std ( { R i } i = 1 G ) . (2) \hat{A}_{i,t} = \frac{R_i - \text{mean}(\{R_i\}_{i=1}^G)}{\text{std}(\{R_i\}_{i=1}^G)}. \tag{2} A^i,t=std({Ri}i=1G)Ri−mean({Ri}i=1G).(2)
需要注意的是,在训练过程中,我们仅对 LLM 生成的 token 计算损失。其优化目标为:
J DAPO ( θ ) = E ( q , a ) ∼ D , { τ i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) [ 1 ∑ i = 1 G ∑ t = 1 ∣ τ i ∣ I ( τ i , t ) ∑ i = 1 G ∑ t = 1 ∣ τ i ∣ I ( τ i , t ) ⋅ min ( π θ ( τ i , t ∣ τ i , < t ) π θ old ( τ i , t ∣ τ i , < t ) A ^ i , t , clip ( π θ ( τ i , t ∣ τ i , < t ) π θ old ( τ i , t ∣ τ i , < t ) , 1 − ϵ low , 1 + ϵ high ) A ^ i , t ) ] , ( 3 ) \mathcal{J}_{\text{DAPO}}(\theta) = \mathbb{E}_{(q,a)\sim \mathcal{D}, \{\tau_i\}_{i=1}^G \sim \pi_\theta^{\text{old}}(\cdot|q)} \left[ \frac{1}{\sum_{i=1}^G \sum_{t=1}^{|\tau_i|} \mathbb{I}(\tau_{i,t})} \sum_{i=1}^G \sum_{t=1}^{|\tau_i|} \mathbb{I}(\tau_{i,t}) \cdot \min \left( \frac{\pi_\theta(\tau_{i,t}|\tau_i,<t)}{\pi_\theta^{\text{old}}(\tau_{i,t}|\tau_i,<t)} \hat{A}_{i,t}, \text{clip}\left(\frac{\pi_\theta(\tau_{i,t}|\tau_i,<t)}{\pi_\theta^{\text{old}}(\tau_{i,t}|\tau_i,<t)}, 1-\epsilon_{\text{low}}, 1+\epsilon_{\text{high}}\right) \hat{A}_{i,t} \right) \right],(3) JDAPO(θ)=E(q,a)∼D,{τi}i=1G∼πθold(⋅∣q) ∑i=1G∑t=1∣τi∣I(τi,t)1i=1∑Gt=1∑∣τi∣I(τi,t)⋅min(πθold(τi,t∣τi,<t)πθ(τi,t∣τi,<t)A^i,t,clip(πθold(τi,t∣τi,<t)πθ(τi,t∣τi,<t),1−ϵlow,1+ϵhigh)A^i,t) ,(3)
其中,指示函数 I ( τ i , t ) = 1 \mathbb{I}(\tau_{i,t}) = 1 I(τi,t)=1 表示 τ i , t \tau_{i,t} τi,t 是一个由 LLM 生成的 token,否则为 0。
在 0 < ∑ i = 1 G R i < G 0 < \sum_{i=1}^G R_i < G 0<∑i=1GRi<G 的条件下进行训练。表 14 (§ F) 给出了 DAPO 训练过程中使用的超参数。
250905:DAPO与GRPO的主要区别在于 ①clip方式不同,DAPO是非对称裁剪,比如本文low=0.2,high=0.28,这样的话模型就会学的更快;②DAPO没有显示KL 项,靠剪切与组内标准化稳定训练;③组内标准化时,GRPO会强制一组回答中,不能全对或全错(对全对/全错的组进行重采样或跳过),避免模型退化。
5 实验
5.1 基线
我们将 M3-Agent 与三类基线方法进行比较:
Socratic Models 该基线改编自 Socratic Models 框架 [54],该框架使用多模态模型来描述 30 秒视频片段。这些描述被存储为长期记忆。为回答问题,大语言模型执行检索增强生成(RAG)[20]:首先调用 search_clip 函数来检索与问题相关的记忆,然后基于检索到的内容生成回答。
我们在记忆生成中实现了闭源和开源的多模态模型:
- Gemini-1.5-Pro [41]:将完整的 30 秒视频片段作为输入。
- GPT-4o [15]:由于它不处理音频,我们提供以 0.5 fps 采样的视频帧和 ASR 转录文本作为输入。
- Qwen2.5-Omni-7b [49]:一种先进的开源多模态模型,支持视觉和音频输入。它接收完整的视频作为输入。
- Qwen2.5-VL-7b [1]:一种在视觉-语言任务中达到 SOTA 结果的开源视觉语言模型。与 GPT-4o 类似,它接收采样为 0.5 fps 的视频帧和 ASR 转录文本。
对于所有变体,GPT-4o 作为 RAG 基于问答的 LLM 使用。我们为每个设置进行了广泛的提示词工程以优化性能。所有提示词见附录 H.2。
在线视频理解方法(Online Video Understanding Methods) 我们进一步将我们的方法与三种在线视频理解框架进行比较:MovieChat [40]、MA-LMM [12] 和 Flash-VStream [56]。除非特别说明,否则我们采用其官方预训练权重和默认配置。
- MovieChat [40]:使用滑动窗口提取帧级特征,并将其存储在混合记忆中;LLM 在此记忆上进行问答。
- MA-LMM [12]:以在线方式处理帧,包括特征提取(1 fps)、时间建模(100 帧输入)和 LLM 解码。
- Flash-VStream [56]:采用两阶段异步流水线:视频流压缩(1 fps),然后基于压缩特征进行 LLM 问答。
智能体方法(Agent Methods) 我们还将 M3-Agent 与通过提示实现的闭源商业模型进行比较。具体来说,我们考虑以下两个基线:
- Gemini-Agent:Gemini-1.5-Pro 被分别用于记忆访问和控制过程。在记忆访问过程中,它接收完整的视频、音频、人脸识别结果和说话人识别结果,以生成情景和语义记忆,记为 memory-gemini-prompt。在控制过程中,它执行记忆检索和答案生成,记为 control-gemini-prompt。
- Gemini-GPT4o-Hybrid:我们还评估了一种设置,其中 GPT-4o 被提示用于执行记忆检索和生成答案(control-gpt4o-prompt),而记忆访问仍由 memory-gemini-prompt 处理。
所有提示词见附录 H.3。
我们将 M3-Agent 和所有基于智能体的基线方法的最大执行轮数 H H H 设置为 5。在实现 search_clip 时,如果存在相关视频片段,则返回前 2 个最相关的片段(即 k = 2 k=2 k=2);若没有找到相关片段,则返回空结果。
5.2 数据集与评估
我们在 M3-Bench-robot 和 M3-Bench-web 上对 M3-Agent 及所有基线方法进行评估。为了展示我们方法的通用性,我们还在长视频理解基准 VideoMME-long [9] 上测试了 M3-Agent,并遵循其官方评估协议。
https://github.com/thanku-all/parse_answer/blob/main/eval_your_results.py
5.3 主要结果
如表 5 所示,M3-Agent 在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上均优于所有基线。具体来说,在 M3-Bench-robot 上,M3-Agent 的准确率相比表现最好的基线 MA-LMM 提高了 6.3%;在 M3-Bench-web 和 VideoMME-long 上,分别相比表现最好的基线 Gemini-GPT4o-Hybrid 提高了 7.7% 和 5.3%。
我们还在 M3-Bench 的不同问题类型上将 M3-Agent 与所有基线进行了比较。M3-Agent 在人类理解和跨模态推理方面表现突出。具体来说,与 M3-Bench-robot 上表现最好的基线 MA-LMM 相比,M3-Agent 在人类理解上提升了 4.2%,在跨模态推理上提升了 8.5%。在 M3-Bench-web 上,M3-Agent 优于表现最好的基线 Gemini-GPT4o-Hybrid,在相应类别中分别提升了 15.5% 和 6.7%。这些结果表明,M3-Agent 具备更强的能力来保持角色一致性、深化人类理解并有效整合多模态信息。
5.4 消融实验
为评估记忆对整体性能的影响,我们将控制模型固定为 control-7b-rl,并比较了不同的记忆方法,如表 6 所示。首先,我们将记忆替换为由 memory-gemini-prompt 生成的版本,结果在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上的准确率分别下降了 2.0%、2.6% 和 9.1%。这表明 memory-7b-sft 生成的记忆质量高于 memory-gemini-7b。接着,我们评估了 memory-7b-prompt,在相同基准上的准确率下降了 5.4%、9.0% 和 11.0%,凸显了模仿学习在生成有效记忆中的重要性。最后,我们对记忆生成过程中的关键组件进行了消融,结果显示去除角色身份等价关系或语义记忆会显著降低问答性能。
250905:控制模型到底是7B还是32B呢?而且这句话感觉也写错了“这表明 memory-7b-sft 生成的记忆质量高于 memory-gemini-7b”,应该是memory-gemini-prompt吧?
接下来,我们研究了控制过程对最终性能的影响。我们将记忆模型固定为 memory-7b-sft,并评估了多种控制过程模型,如表 7 所示。首先,我们比较了两种强化学习算法:GRPO 和 DAPO。GRPO 的训练细节见附录 F。结果表明,使用 DAPO 训练的 control-32b-rl 在所有测试集上都稳定优于 control-32b-grpo。其次,我们分析了 DAPO 的性能随模型规模的变化。结果显示,经过 DAPO 训练后,control-32b-rl 相比 control-32b-prompt 在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上的准确率分别提升了 10.0%、8.0% 和 9.3%。
最后,我们对两个设计进行了消融:多轮指令(inter-instruction) 和 推理(reasoning)。两者均被证明至关重要。去除多轮指令会导致在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上的准确率分别下降 10.5%、5.8% 和 5.9%;去除推理会导致相同基准上的准确率分别下降 11.7%、8.8% 和 9.5%。
5.5 案例研究
记忆(Memorization)
表 15、16 (§ G) 展示了两个示例,用于说明在记忆访问过程中生成的情景记忆和语义记忆。与 memory-gemini-prompt 相比,memory-7b-sft 展现出以下优势:(1)更详细的情景记忆生成,包括更丰富的场景描述、角色动作、表情和对话;(2)改进的身份等价识别,能够在长期内保持对人物身份的一致追踪;(3)更丰富的语义记忆提取,能够主动生成关于角色和环境的知识。
控制(Control)
为了更详细地展示控制过程,表 17 (§ G) 给出了 control-32b-rl 的完整生成轨迹。输入问题为:“Tomasz 是一个富有想象力的人,还是缺乏想象力的人?”
在第一轮中,智能体在记忆中搜索 Tomasz 的角色 ID。第二轮中,确定 Tomasz 是 <character_4> 后,它尝试了一个直接查询:“<character_4> 在想象力方面的性格是怎样的?” 在第三轮中没有找到相关记忆后,智能体基于 <character_4> 的 CTO 身份进行推理,并生成了一个更有针对性的查询:“<character_4> 的创造性问题解决方法是什么?” 这次检索到一个相关记忆:“<character_4> 是一个富有创新精神和前瞻性思维的人,这体现在他对无人机技术规模化应用于个人飞行的兴趣上。” —— 这是一条语义记忆。到第四轮时,智能体已经收集到足够的信息,并结合上下文生成了最终答案。
M3-Bench 中的难例(Hard Case in M3-Bench)
各种方法的准确率表明,M3-Bench,尤其是 M3-Bench-robot,提出了显著的挑战。我们在 M3-Bench 上对 M3-Agent 进行了详细的错误分析,识别出两类具有代表性的难例及其对应的挑战,这些问题需要进一步研究。
第一类难例涉及对细粒度细节的推理。例如,问题 “谁想吃火腿香肠?” 或 “Emma 的帽子应该挂在哪个衣帽架上,高的还是矮的?” 要求智能体从观察中提取精确的信息。然而,将所有这类细节都保存在记忆中既不现实,还可能导致认知过载。为解决这一问题,智能体必须使用注意力机制,支持选择性记忆。在执行过程中,它能够发展任务特定的世界知识,从而专注于相关细节并忽略无关信息,提高任务表现。
另一类难例与空间推理相关。在 M3-Bench-robot 中,一些问题会挑战智能体的空间认知能力,例如空间布局理解和空间变化跟踪。示例包括:“机器人在哪里可以拿到零食?” 或 “Leo 的水杯现在在架子上从上往下数第二层还是第三层?” 由于语言记忆在保留空间信息方面通常不如视觉内容(如快照)有效,因此长期记忆应当被设计为融合更丰富的视觉内容,以更好地支持空间推理。
6 结论与未来工作
在本文中,我们提出了 M3-Agent,这是一种具备长期记忆的多模态智能体框架。M3-Agent 能够感知实时的视频和音频流,以构建情景记忆和语义记忆,从而逐步积累世界知识,并在时间维度上保持一致且具备上下文丰富性的记忆。在响应指令时,M3-Agent 能够自主地进行推理,并从记忆中检索相关信息,以更高效地完成任务。
为评估记忆的有效性和推理能力,我们提出了 M3-Bench,这是一个 LVQA 基准,包含真实场景和机器人视角视频,覆盖实际环境中的任务,以及围绕人类理解、知识提取和跨模态推理的挑战性问题,同时高度贴近现实需求。我们将方法与多种基线进行比较,包括 Socratic Models、在线视频理解方法以及基于闭源模型提示的 M3-Agent。实验结果表明,在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上,M3-Agent 均显著优于所有基线,展现了其在记忆和推理能力上的优势。
此外,通过详细的案例研究,我们识别出了一些关键局限性,并指出了潜在的未来研究方向。这些方向包括:增强语义记忆形成中的注意力机制,以及开发更丰富但更高效的视觉记忆。
7 致谢
我们感谢字节跳动的 Xiran Suo、Wanjun Wang 和 Liu Ding 在数据标注方面的帮助,以及 Peng Lin 在插图制作上的支持。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)