大模型泛化能力揭秘:从死记硬背进化到举一反三、触类旁通!
大模型泛化能力是指AI从死记硬背进化到举一反三、触类旁通的能力。其底层逻辑在于通过统计学习在高维空间中捕捉模式,通过损失函数最小化学习鲁棒特征,构建层次化抽象表示。具体表现为指令、任务、语言和推理泛化。提升泛化能力的关键策略包括高质量数据、Transformer架构、预训练、指令微调和RLHF等技术。未来AI将朝着更高效、更可靠的方向发展。
简介
大模型泛化能力是指AI从死记硬背进化到举一反三、触类旁通的能力。其底层逻辑在于通过统计学习在高维空间中捕捉模式,通过损失函数最小化学习鲁棒特征,构建层次化抽象表示。具体表现为指令、任务、语言和推理泛化。提升泛化能力的关键策略包括高质量数据、Transformer架构、预训练、指令微调和RLHF等技术。未来AI将朝着更高效、更可靠的方向发展。
回想几年前那些人工智能助手,如果你跟它说“我冷了”,它可能会一本正经地回答:“抱歉,我不理解‘冷了’是什么意思。”然后,我们得像输入密码一样精准地说“把空调温度调到26度”,它才勉强照办。
但现在,可以说 AI 变得“通人性”了。让 ChatGPT “用刘慈欣的风格写一个关于外卖小哥的科幻短篇”,或者和它抱怨一句“周五晚上好无聊,不知道干嘛”,它就能给你推荐电影、设计小游戏,甚至陪你聊聊 MBTI。
AI 已经不再是那个只会背标准答案的“模范生”,而像一个真正聪明的“朋友”,能举一反三、触类旁通。这种让你感觉惊叹的“灵性”,背后其实是一项关键能力在发挥作用——泛化能力。
今天我们就来聊聊,大模型究竟是怎么从“死记硬背”到“融会贯通”的?它真的像看起来那么无所不能吗?
01.何为“泛化”
我们上学的时候会遇到两种同学:一种是经常被称为“书呆子”的,把课本和习题集的答案背得滚瓜烂熟,但考试题目稍微一变,就傻眼了。另一种是大家都羡慕的“学霸”,他可能也刷题,但更注重理解公式背后的原理和逻辑,所以哪怕遇到从来没见过的压轴题,他也能一步步推导出答案。
大模型的“泛化能力”,就是让它从“书呆子”进化成“学霸”的那道关键分水岭。
简单来说,泛化就是指 AI 举一反三、触类旁通的能力。它衡量的是一个模型能否运用在“旧场景”中学到的知识和规律,去巧妙地处理“新场景”中的陌生问题。
这种“新场景”可以是:
- 一种全新的问法:你训练它时用的是“翻译下列英文句子”,但你现在问的是“能把这段话变成中文吗?”,它得明白这俩是同一个意思。
- 一个全新的任务:一个主要靠读小说训练出来的模型,你突然让它写一首诗或者一段广告文案,它不能直接宕机。
- 一个它从未记下的知识:你问它“珠穆朗玛峰有多高”,它并不是从庞大的数据库里把8848.86米这个数字“ctrl+F”搜索出来,而是基于对语言和世界的理解,“推理”或“回忆”出这个答案。
所以,泛化的本质不是“记忆”,而是“理解”;不是“搜索”,而是“应用”。当一个模型真正拥有了泛化能力,它就不再是一个冰冷的数据库,而开始像一个真正“会思考”的大脑了。
02.泛化能力的底层逻辑:模型如何在数据中“悟”出规律?
大模型“举一反三”的泛化能力底层根基深植于现代统计机器学习的核心原理。要理解它,我们需要窥探一下模型是如何从数据中构建出一个“世界模型”的。
一、统计学习与高维空间中的模式捕捉
想象一下,你让一个从没学过语法规则的孩子读完了整个图书馆的书。他虽然没有背下任何一本书,但却能自然而然地掌握语言的规律——比如哪些词常一起出现,句子应该如何组织,概念之间有什么隐含关系。
大模型的学习过程与之惊人地相似。它通过分析海量文本,将自己训练成了一个"语言概率大师"。它的核心能力不是记忆,而是预测:根据你已经写下的内容,计算出下一个最可能出现的词是什么。当你输入"猫喜欢抓…“,它会基于统计规律给出"老鼠"这个概率最高的选择,而不是"钢琴"或"云计算”。
这种预测能力的基础,是模型将自己接收到的所有词汇和概念,映射到了一个看不见的"高维空间"中。在这个空间里:
- 每个词都有自己独特的位置坐标
- 语义相近的词会聚集在一起(比如各种水果名称)
- 有逻辑关联的词之间会形成固定的向量关系(比如"国王→男人"的方向和距离,与"女王→女人"的方向距离几乎完全一致)
正是因为建立了这样一幅精细的"概念地图",模型才能进行类比和推理。它不需要背诵"国王-男人-女王-女人"的关系,只需要在这幅地图上按图索骥:从"国王"出发,沿着"转为女性"的方向移动固定距离,自然就会到达"女王"的位置。
二、优化与损失最小化:习得稳健的特征表示
模型的训练过程,本质上是损失函数(Loss Function) 的最小化过程。通过反向传播和梯度下降等算法,模型不断调整其参数,使得其预测(生成的下一个词)与训练数据中的“正确答案”之间的差异(损失)越来越小。
- 如何导致泛化:在这个最小化损失的过程中,模型被迫使去捕捉数据中最具判别性和鲁棒性的特征与规律,而不是记忆噪声和特定样本。例如,为了准确预测“国王”之后的词,模型必须学习到“君主”、“国家”、“男性”等抽象特征,并将其与“女王”、“女性”等特征在某种高维空间中进行对齐。这种对底层特征的学习,而非对表面字符串的记忆,是泛化能力的根本来源。
- 需要 DataFlow:这里,数据质量直接决定了优化目标的好坏。如果原始数据充满噪声、重复和毒性信息,模型最小化损失函数时,就不得不去学习这些无意义或有害的模式(例如,学习复制重复段落、生成带有偏见的关联),这会严重损害其学到的特征表示的质量和纯洁性。DataFlow 所构建的自动化数据预处理流水线,其核心使命就是为优化过程提供干净、高信噪比的“燃料”。通过去重(Deduplication)、基于启发式或模型的质量过滤(Quality Filtering)、毒性内容移除(Detoxification) 等关键技术,Dataflow 确保了模型是在一个平滑、纯净的数据分布上进行学习,从而极大增加了其收敛到一个更优、更泛化解的可能性。
三、表示学习与涌现:抽象层次的构建
最令人惊叹的是,大模型通过上述过程,自发地学会了层次化的特征表示。
- 底层技术现象: 在模型的深层网络中,单个神经元或神经元集群学会了对应特定的语义概念(如“城市”、“科学概念”)、语法功能(如“宾语”、“从句开头”)甚至情感色彩。这些表示是在高维向量空间中的一系列点和方向。
- “悟”的体现: 模型之所以能处理新任务,是因为它可以将新输入分解并映射到它已经学会的这些基础特征上,然后重新组合出答案。当你问它“请解释量子计算”,它激活的是“科学”、“技术”、“复杂解释”等特征神经元;当你让它“写一首诗”,它则激活了“文学”、“抒情”、“押韵”等特征。这种组合爆炸的能力,使得它能够泛化到无数未明确训练过的任务上。
总的来说,泛化的底层逻辑是一个多层级的构建过程:
高质量的数据基础 -> 通过优化损失函数学习鲁棒的特征表示 -> 构建层次化的抽象语义空间 -> 最终涌现出对未见数据的强大推理和生成能力(即泛化)。
03.大模型泛化能力的具体表现
上面的理论可能有些抽象,但当泛化能力在现实中展现时,你就会感受到它的不可思议。这种泛化能力不再是实验室里的指标,而是变成了我们能与之感同身受的“智慧”火花。以下是几个最直观的表现:
一、指令泛化
这是最常用也最实用的能力。模型不仅能理解你明说的指令或是“弦外之音”,还能理解你没说出来的意图。
- 示例:
- 直接指令:“总结一下这篇文章的主要内容。”
- **泛化表现:**如果你换成“你能帮我划一下这篇文章的重点吗?”或者“用几句话告诉我这篇文章说了啥”,它都能明白你想要的是“摘要”这个核心任务,并能执行。
- **高级示例:**你甚至可以说:“我是个五年级学生,能用简单易懂的话给我讲讲什么是黑洞吗?” 模型不仅能理解你要解释“黑洞”,还能捕捉到“五年级”和“简单易懂”这两个关键约束条件,调整其回答的语言复杂度和专业深度。
二、任务泛化
传统的 AI 模型是“一个萝卜一个坑”:训练一个翻译模型,它就只会翻译;训练一个情感分析模型,它就只会判断正负面。而具备强大泛化能力的大模型,则像一个“全能型选手”。
你可以要求同一个模型:“把上面这段中文翻译成英文”(翻译任务),紧接着问“那你觉得作者写这段话时情绪怎么样?”(情感分析任务),然后再让它“把分析结果用表格列出来”(格式生成任务)。
它没有为“做表格”进行过专门训练,但它从海量数据中学习到了“表格”是一种结构化数据的呈现方式,并能将前一步的情感分析结果成功地“泛化”应用到生成表格这个新任务上。这种无需针对每个任务重新训练就能灵活切换的能力,是泛化最强大的体现之一。
三、语言泛化
语言是灵活的、不断变化的。泛化能力让模型能跟上这种变化,而不是只能理解教科书式的标准语言。
**理解新词与流行语:**当问它“显眼包是什么意思?”或者“EMO了怎么办?”,它不仅能解释,还能在对话中恰当使用。
理解方言与变体:如果写“俺们这旮沓天气真好”,它不会卡住,能理解这是“我们这里”的意思。
创作与幽默:还可以让它“用疯狂星期四文学体写一个促销文案”,它能够捕捉到这种网络文体夸张、叙事、反转的特点并进行模仿。这说明它学习的不是固定的词句,而是语言的风格和模式。
四、推理泛化
这是泛化能力接近“思考”的更高阶表现。模型能够将不同地方学到的知识碎片串联起来,进行逻辑推理,解决全新的、需要多步思考的问题。
- 简单推理: “如果小明比小红高,小红比小兰高,那么谁最高?” 模型需要理解“比…高”的传递关系,而不是搜索现成答案。
- 复杂推理: “我要煮饭3个人吃,每人一碗,米和水的比例大概是1:1.2,请问我需要多少毫升水?” 要回答这个问题,模型需要知道“一碗米大约是多少克”、“体积单位毫升与克如何转换”(常识知识),并运用“比例”进行数学计算(逻辑推理)。它成功地将“常识”和“数学”两个领域的知识泛化应用到了“烹饪”这个新场景中。
这些表现都体现出大模型不再是一个简单的“问答机器”,而是一个能够适应未知、处理模糊、理解意图的灵活系统。这正是泛化能力所赋予它的、看似拥有“魔力”的根源。
04.提升泛化能力的关键策略
大模型的泛化能力并非凭空而来,而是工程师们通过一系列策略“雕琢”而成的。这些策略环环相扣,共同奠定了模型的“智慧”基石。主要可分为三大方面:
一、数据策略:构建模型认知的“优质知识库”
如果说模型是“学生”,那数据就是它的“教材”。教材的质量直接决定了学生的知识面和思维深度。这远不止是把整个互联网下载下来那么简单。想象一下,如果你要培养自己的孩子成为一位科学家,你会只丢给他一堆未经筛选的、包含错误信息和重复内容的书籍吗?当然不会。你会为他精心挑选图书馆的藏书。
这就是现代 AI 实践中的关键一步:构建高质量数据集。这个过程,就像一条高度自动化的智能食品加工流水线,如 DataFlow,它默默地执行着至关重要的工作:
- 海量采集:首先,我们需要尽可能多的原始数据,让模型“读书破万卷”,见识足够多的语言现象。这是泛化能力的广度基础。
- 清洗与筛选:raw 数据中充满了“垃圾”——重复的文本、低质的内容、爬虫错误和无效信息。自动化流水线会像“洗菜”一样,过滤掉这些噪音,只保留干净、有用的文本。
- 去重与平衡:防止模型对某些常见但无意义的文本(比如重复出现的法律免责声明)产生“过拟合”。同时,要有意识地混合代码、新闻、故事、对话等不同类型的数据,确保模型营养均衡,不会变成一个只懂某个领域的“偏科生”。
- 安全过滤:识别并移除包含暴力、仇恨言论和严重偏见的有毒内容,从源头上尽力保证模型输出结果的安全性。
经过这条流水线的处理,我们得到的就不再是杂乱无章的原始数据,而是一个精心策划的“知识库”。这才是模型能够学到纯净、通用规律的根本前提。
二、模型策略:打造一个更强“大脑”
有了优质的粮食,还需要一个足够强大和结构合理的“大脑”来消化吸收,这就引出了模型架构。
当前所有大模型的基石,都是 Transformer 架构。你可以把它理解为一个为处理语言而生的“超级大脑结构”。它的核心优势在于其自注意力机制。
简单来说,传统模型理解一个句子就像用手电筒照着一排字,一次只能看清几个词。而 Transformer 的大脑则像拥有一种“全局视野”,它在读到一个词(比如“它”)的时候,能瞬间判断出这个“它”指的是句子开头提到的哪个名词,并赋予不同的关注权重。
这种先天性的结构优势,使得模型能极其高效地捕捉词语之间遥远的依赖关系和复杂的上下文语境,为理解和生成连贯、合乎逻辑的文本提供了基础。一个更大的 Transformer 模型(拥有更多参数),就像拥有更大容量和更多神经元的大脑,能够存储和处理更复杂的模式,其泛化潜力自然更大。
三、缩放定律(Scaling Laws):“更大容量的脑洞”
最后,也是最精妙的一环,就是我们如何将“知识”灌输给这个“大脑”。粗暴地填鸭式教学只会培养出死记硬背的“书呆子”,我们需要更高级的教学方法。
- 预训练(Pre-training):打牢知识基础
这是最初也是耗时最长的阶段。我们让模型进行“无监督学习”,其实就是把它扔进我们准备好的优质数据海洋里,让它自己去完成“完形填空”(例如,给定上文预测下一个词)。通过这个过程,模型自发地学会了语法、事实知识和各种语言统计规律,打下了深厚的知识基础。
- 指令微调/有监督微调**(Instruction Tuning****/Supervised Fine-tuning****):学会听话和办事**
仅有知识还不够。预训练后的模型可能学富五车,但你不一定能跟它有效对话。它不知道你问“总结一下”是想要摘要。 指令微调就是解决这个问题的关键。我们使用大量(指令,期望回复)的样本对来进一步训练它。比如:
- 指令:“把这句话翻译成英语。”
- 回复:“Translate this sentence into English.”
这个过程就像给学生做大量的模拟题,教会它如何理解人类千奇百怪的指令意图,并按照要求格式进行回应。这是直接激发其泛化能力的一步,让它学会如何调用内部知识来解决具体任务。
- 人类反馈强化学习(RLHF):学习“好”的标准
最后,我们还要教它“好坏”与“分寸”。通过让人类标注员对模型的多个答案进行评分(哪个更好、更无害、更有用),我们训练出一个“奖励模型”来模拟人类的偏好。
然后,就像训练小狗做动作一样,当模型输出一个符合人类偏好的答案时,它就得到“奖励”(通过强化学习算法),鼓励它以后多这样做;反之则进行修正。这个过程确保了模型的输出不仅是正确的,而且是有用、诚实、无害的,使其泛化行为与我们的价值观对齐。
总结一下, 构建一个强大的大模型,就像培养一位天才:
我们先它提供一个精心筛选的巨型图书馆(高质量数据),它天生有一个善于联想和记忆的超凡大脑(Transformer架构),最后我们通过模拟题训练(指令微调) 和名师指点(RLHF) 教会它如何与人交流并输出有价值的内容。这三根支柱合力,才最终造就了我们所见到的、惊艳的泛化能力。
四、GRPO:突破泛化瓶颈的关键
在大模型训练中,一个常见的问题是:模型在训练任务上表现很好,但一旦遇到新的任务或场景,能力就会明显下降。传统的偏好优化方法(RPO)虽然能让模型在特定任务中“对齐”用户需求,但容易出现“过度迎合”的情况,导致模型缺乏跨任务的迁移能力。
为了解决这一问题,DeepSeek 提出了 GRPO(Group Relative PolicyOptimization****)。**GRPO 的核心思想,是让模型不再局限于学习单一的“标准答案”,而是通过自我生成多个答案,并在其中通过可验证的奖励函数,比较每个答案的“分数”,越精准的答案分数越高。随后,通过反向传播优化促使模型尽可能生成分数高的答案。从而是模型学习到更通用、而精准的解决问题策略。这有点像让一个学生不再死记硬背一道题的解法,而是尝试用多种方法解题,然后自己判断哪种方法最有效、最可靠。
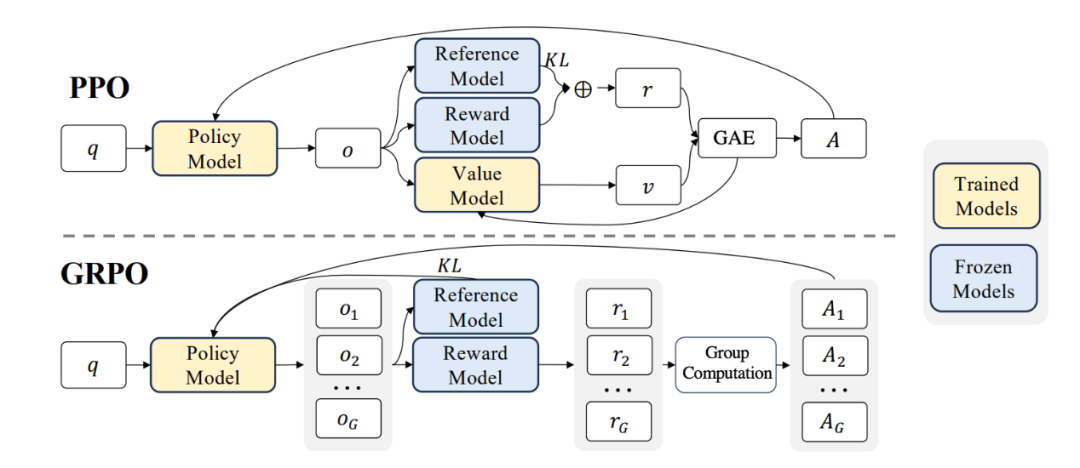
这样训练出来的模型,不仅在已知任务上表现更好,更能在陌生任务里举一反三,展现出更强的泛化能力。这也是 DeepSeek 能在多种测试中都表现突出的关键所在。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献212条内容
已为社区贡献212条内容

所有评论(0)